子域适应无监督轴承故障诊断
2021-08-11吴静然刘建华
吴静然,刘建华,崔 冉
(1.中国矿业大学 信息与控制工程学院,江苏 徐州 221008;2.中国矿业大学 徐海学院,江苏 徐州 221008)
滚动轴承作为旋转机械设备减少各部件间摩擦的重要组成部分,广泛应用于现代机械设备中。然而在恶劣环境下工作,滚动轴承易遭受磨损,故障率较高。准确识别轴承的故障,判断故障类型,可以有效指导维修工作,提高维修效率,提高机械设备的可靠性和安全性,减少经济损失,保护工作人员的人身安全[1-2]。
随着智能制造技术的快速发展,基于滚动轴承振动信号分析的方法成为研究热门。传统的方法主要通过频谱分析、时频域变换分析进行特征提取,利用K近邻、人工神经网络、支持向量机、随机森林构建分类器进行故障诊断识别[3-5]。特征提取过程依赖于专家知识和人工经验,通过频谱分析或从振动信号中提取统计特征,无法从原始的振动信号中挖掘出有效的故障特征,获得的诊断模型结构简单,无法应用于大容量高维数据。当工况发生变化后,诊断准确率降低。
鉴于深度学习能够从输入的数据中自动学习特征,基于卷积神经网络(convolutional neural network, CNN)的端到端故障轴承诊断方法[6-7]被广泛应用。然而大多数研究要求训练样本和测试样本具有相同特征空间、概率分布和大量的可用标签。考虑到实际工况改变时,收集的故障数据分布会随之改变,大部分数据没有标签;同时由于设备故障很难发生,很难收集足够的信息来反映完整的健康状态。利用现有大量标记数据进行无标签变工况下的轴承故障诊断变得非常重要。
无监督领域适应(unsupervised domain adaptation, UDA)作为迁移学习的分支,能够探索领域不变特征,弥合领域间分布差异。鉴于UDA在图像处理领域的广泛应用,UDA也被广泛应用于跨领域故障诊断。文献[8]以深度学习为主要结构,通过最小化多核最大均值差异,减少卷积网络的多层特征分布差异,提取域不变特征,实现滚动轴承故障诊断。文献[9]采用对抗域自适应学习策略,提出了一种机器故障诊断网络,该网络学习通用的域不变特征,有助于增强特征表示的鲁棒性,提高训练模型的泛化能力。文献[10]提出一种跨设备故障诊断模型,采用卷积神经网络提取数据特征,使用最大均值差异和域对抗减少源域和目标域全局分布。虽然上述方法取得了较好的效果,但是仅仅试图进行全局对齐,未考虑源域和目标域间的关系,可能会丢失每个类别的细粒度信息。如图1(a)所示,全局域适应后,生成的源域和目标域空间的特征基本一致,但是子域间数据过分接近,分类正确率低[11]。
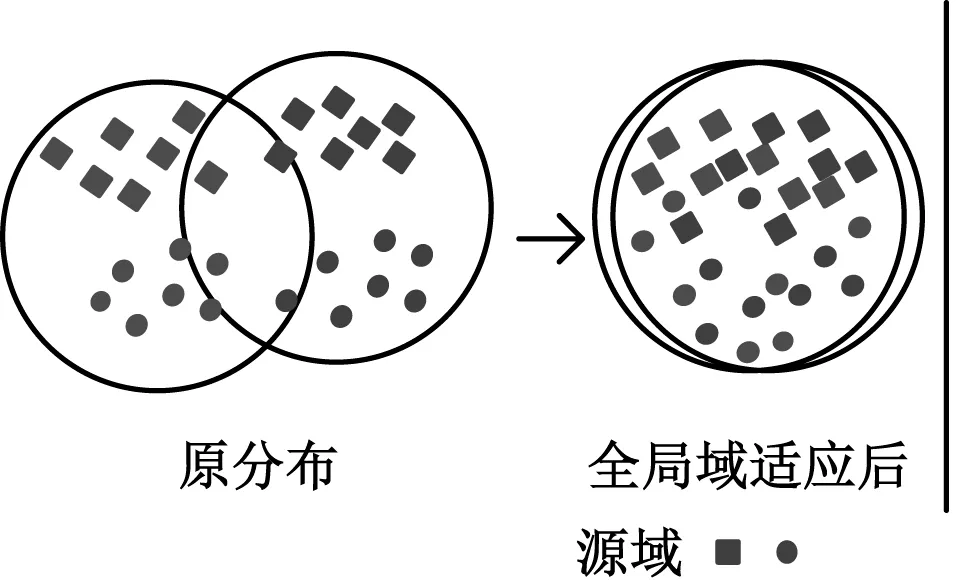
(a)全局域适应
为了解决上述问题,本文提出了一维卷积子域适应网络(subdomain adaptation networks,SDAN)进行准确的无监督故障诊断。该网络包括特征提取器和健康状态分类器,特征提取器用于处理原始故障数据,进而获得故障诊断分类特征。引入局部最大平均偏差(local maximum mean discrepancy, LMMD)[11]来度量源域和目标域数据嵌入相关子域的差异,调整相关子域同一类别下的分布,捕获每个类别的细粒度信息,实现子域对齐。经过子域适应后,局部分布近似相同,全局分布也近似相同,如图1(b)所示。使用江南大学JNU轴承故障数据集进行该方法的有效性验证,与现有5种领域自适应算法进行对比,SDAN网络具有更好的诊断性能,结果表明该方法在滚动轴承故障诊断上的可行性和有效性。
1 无监督网络自适应
1.1 无监督迁移学习

1.2 卷积神经网络
鉴于CNN在图像处理、计算机视觉等领域的成功应用,CNN也被广泛应用于振动信号分析的故障诊断领域。典型的CNN包含有卷积层、池化层和全连接层[12]。
卷积层(Conv):用于提取复杂的高维输入特征,由多个卷积内核(过滤器)组成, 当每个核在输入映射上滑动时,权值保持不变,通过将输入信号与卷积核进行卷积运算获得特征图。卷积操作完成后,使用激活函数实现非线性映射,在本研究中,采用了直线单元(ReLU)函数[13]。卷积层数学模型可表示为:
δ(x)=max(0,x)
(1)

池化层(Pool):每个卷积层后面会连接一个池化层,通过池化内核对得到的特征图进行下采样,实现数据降维和进一步特征提取。本文采用最大池化函数,返回池化核区域最大值。
全连接层(FC):用于分类和识别故障类别。本文采用softmax函数将全连接层输出映射到(0,1)区间,实现故障识别分类[14]。softmax公式可表示为:
(2)
式中:C为数据集类别个数;φi为全连接层的第i类的输出值;αi为φi经过softmax运算后第i类的概率。
1.3 最大均值差异
最大均值差异(maximum mean discrepancy, MMD)是用来衡量两个分布差异的指标[15]。给定两个数据集Xs、Xt,利用核函数进行内积形式的希尔伯特空间的非线性映射,MMD表示式如式(3)所示。
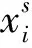
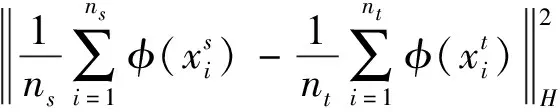
(3)
2 子域适应轴承故障网络
本节介绍网络结构和损失函数,用于实现无监督轴承故障类别诊断。
2.1 网络结构
SDAN网络主要包含有特征提取器、健康状况分类器2部分。为了简化复杂的网络调参过程,本文特征提取器的网络结构和参数与文献[16]基本网络结构保持一致。后续可结合实际应用,优化网络结构和参数,更好地提取轴承故障数据的特征,提高分类正确率。本文SDAN网络结构和参数如表2所示。Conv(x,y)为一维卷积运算,表示x个卷积核,卷积核的大小为y。网络均采用最大池化操作,窗口大小为2,步长为2。FC(n)表示全连接层,包含有n个神经元输出。随机丢弃(Dropout)[17]为0.5,用于提高网络的泛化能力。分类器只包含一个全连接层,其神经元的数目与数据集类别的个数相同。
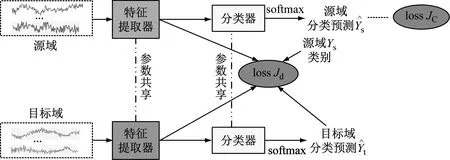
图2 SDAN网络结构

表1 SDAN网络结构
2.2 局部最大平均误差LMMD
MMD被广泛应用于测量源域和目标域分布差异,但是主要关注全局分布对齐,却忽略源域和目标域同一类别子域间关系。由于同一类别有更强的相关性,通过对齐具有相同标签的样本的相关子域可以匹配全局分布和类别局部分布。借鉴文献[11],本文引入LMMD用于对齐同一类别相关子域的分布,公式可表示为:
(4)
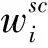
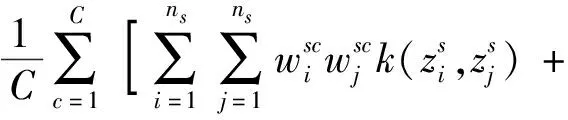
(5)
2.3 优化目标
该网络通过深度特征表示学习和局部最大平均误差学习来提取域可转移的特征表示。训练过程中有2个优化目标。
(1)最小化源域数据集上轴承故障类别分类器的损失函数Jc,引导分类器输出正确预测标签。
(2)最小化源和目标域数据集间的LMMD距离Jd。
其中Jc的表达式可表示为:
(6)
式中:Ga为特征提取器输出;Gc为源域分类器预测输出;Jy为交叉熵损失函数。
则总的损失函数J如下所示,其中α为平衡超参数。
J=Jc+αJd
(7)
3 实验
对江南大学(Jiang Nan University, JNU)轴承故障数据集[18]进行了对比实验,用以验证所提出模型的有效性。
3.1 江南大学JNU轴承数据集
该数据集为江南大学采集的轴承故障数据集,采样频率为50 kHz,包含有正常状态、内圈故障、外圈故障和滚动体故障四种健康状况。根据轴承故障位置不同,将故障数据分为4类,如表2所示。

表2 JNU轴承故障数据集说明
实验过程中使用加速度计在600、800和1 000 r/min三种不同转速下采集振动信号。不同转速被认为为不同任务,分别将转速为600、800和1 000 r/min的数据定义为任务A、B、C。例如A->B表示源域为转速为600 r/min的振动数据,目标域为转速为800 r/min的振动数据。
实验采用重叠采样的方式,每间隔200个点采样1 024个点,即每个样本有1 024个数据点。每个故障类别500个样本。其中100%的源域样本和50%的目标域样本作为训练集,目标域剩余的50%的样本作为测试集。
3.2 对比基准及实验参数
为了验证本文方法的有效性,本文选择5个受欢迎的领域自适应学习方法,DCORAL[19]、JAN[20]、DDC[15]、DANN[21]、CDAN[22]进行对比实验。JAN、DDC等方法均采用高斯核函数进行损失函数计算。以上所有的方法均采用与本文相同的CNN基本网络框架进行数据特征提取,便于更合理的测试模型性能。

3.3 JNU轴承故障数据集变工况诊断结果
为了评估模型的性能,将本方法与其他5种常用算法进行比较,诊断的平均结果及对比如表3、图3所示。其中DCORAL自适应方法效果最差,识别正确率平均值为72.61%,准确率波动较大,标准差更大。其中DDC、DANN两种方法考虑对齐全局分布,方法识别正确率平均值分别为94.24%和93.64%,正确率明显高于DCORAL。而JAN和CDAN方法考虑特征表示和标签分类输出特征进行特征对齐,识别正确率分别为94.26%和92.88%。本文提出的方法平均准确率为95.86%,都具有相对较小的标准差和较好的鲁棒性,明显优于其他5种方法,表明本文方法可以通过对齐子域分布,捕获各类别细粒度信息,学习更多可转移的表示,验证了模型的有效性。
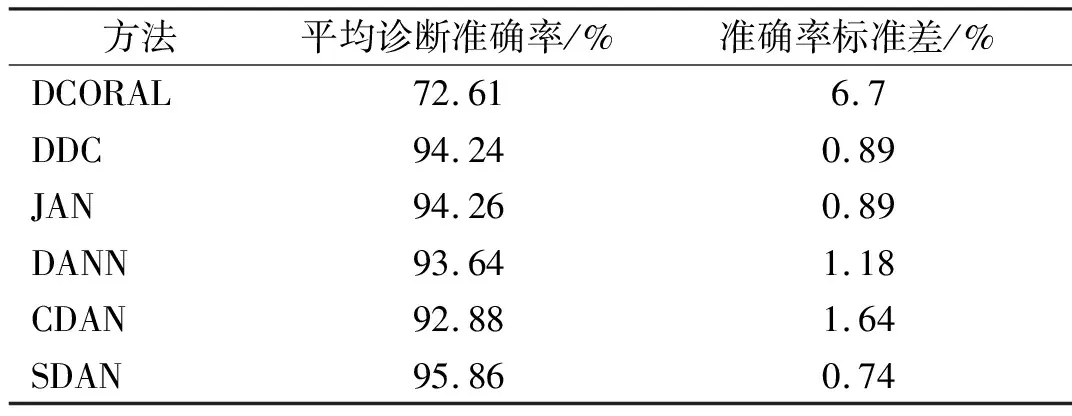
表3 实验平均诊断结果

图3 JNU轴承故障数据集不同方法故障识别正确率对比
为了更直观地分析本文方法的优点,随机选择迁移任务B->A,采用t分布随机邻居嵌入(t-distributed stochastic neighbor embedding,t-SNE)算法[23]对目标域数据特征表示进行可视化,不同方法的特征表示如图4所示。图例中包含源域和目标域的4类故障类型,s代表源域,t代表目标域,如s-NA指的是源域的正常数据。由图可知,通过深度迁移学习,各网络学习到源域和目标域特征全局对齐较好。但是由4(a)可知DCORAL网络学习存在严重的类别间的重叠问题,部分点很难分类,正确率偏低。由4(b)可知,DDC网络重叠问题相较DCORAL改善明显,但是各类别特征对齐较差。由4(d)可知,DANN虽然全局分布对齐效果良好,但是外圈故障类别特征相对分散,子域对齐效果一般。由4(c)、4(e)可知,虽两种方法考虑不同域之间特征和输出标签的联合分布差异进行轴承故障诊断,子域对齐效果却差强人意。由4(f)可知,本文SDAN不仅可以很好的对齐全局分布,同时可以有效的对齐同类别子域的分布,各类别间具有明确的边界,便于更好地识别目标域的故障类。
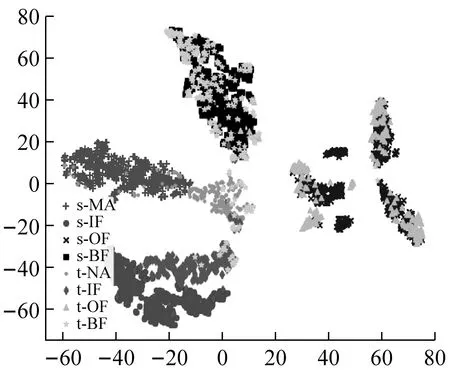
(a)DCORAL
本文同时计算了6种方法在迁移任务B->A的混淆矩阵,详细地分析每个类别的分类精度,分类结果如图5所示。由图可知,本文方法仅有35个错误样本,识别正确率为96.5%,明显高于其他5种方法,说明了该方法的优越性。
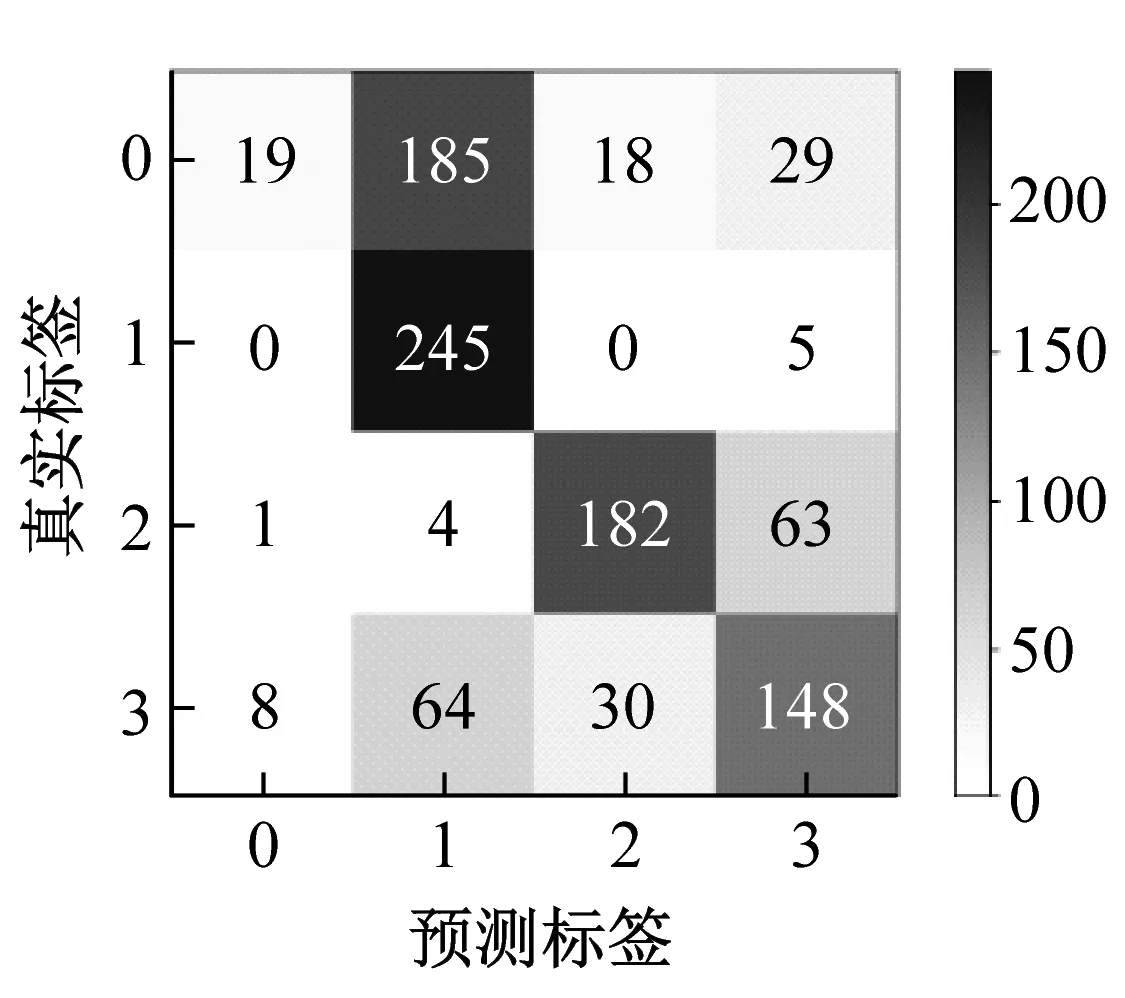
(a)DCORAL
4 结 论
为了提高轴承故障诊断在变工况情况下的分类精度,提出了一种子域适应无监督轴承故障诊断网络SDAN。该网络引入局部最大平均误差LMMD,弥补了现有方法仅仅试图进行全局对齐,未考虑源域和目标域间的关系,可能会丢失每个类别的细粒度信息的缺陷。在江南大学JNU轴承故障数据集,选取5种目前流行的领域自适应故障诊断方法进行对比实验,验证了该方法的有效性。
结果表明:本文提出的端到端无监督轴承故障诊断SDAN网络,仅需在损失函数中引入局部最大平均偏差LMMD,不仅可以很好的对齐全局分布,同时可以有效的对齐同类别子域的分布。本文方法在变工况且数据无标签的情况下,诊断正确率优于现有5种流行的领域自适应故障诊断方法,t分布随机邻居嵌入算法显示该方法可以有效的对齐源域和目标域,验证了该方法良好的可行性和有效性。
