一种多粒度DNS隧道攻击检测方法
2021-08-07陈治昊
陈治昊
(四川大学网络空间安全学院,成都 610065)
0 引言
DNS隧道攻击是指利用DNS请求建立起隧道,绕过防火墙、入侵检测系统等网络安全策略,实现信息窃取、远程命令执行等网络攻击行为。攻击者搭建一个含有恶意软件的DNS权威服务器并注册一个域名后,内网中的受控主机能通过该域名将编码后DNS请求发往攻击者的服务器建立隧道并进行交互,建立隧道后服务器能够将内网主机发送的DNS请求数据包进行解码获取传输数据,同时也能够向受控主机发送编码后的控制指令,达到远程命令执行的目的。根据RFC1034[1]和RFC1035[2]中定义的DNS格式,DNS除了通常解析域名所使用的A类型请求,还存在MX、TXT、CNAME等类型,允许填充任意类型的字符信息,这就使得攻击者能够使用DNS隧道进行信息窃取以及远程命令执行等攻击。同时由于DNS协议受到的监控力度较小,许多木马、僵尸网络和APT攻击也使用了DNS隧道进行控制通信,保持攻击服务器与内网受控主机之间的连接。在2016年5月,在Palo Alto公开的一起APT攻击事件中[3],攻击团队利用DNS请求应答机制作为攻击渗透的命令控制通道。
目前对于DNS隧道攻击的检测方法主要有两类:基于载荷分析与基于行为检测。
基于载荷是指将DNS请求与响应数据包中的有效载荷进行分析。章航等通过请求载荷的域名长度、字符占比、随机性特征和语义特征来检测DNS隧道攻击[4];Homem I等人分析了DNS隧道攻击的内部数据包结构,使用数据包内容信息熵进行检测[5];Lai C M等人使用每个DNS数据包的前512个字节进行检测[6];Liu C等人将DNS数据包的内容压缩为一个字节大小的数据,使用卷积神经网络进行训练学习[7]。但是基于载荷分析的DNS隧道攻击检测方法有着很大的局限性,一些经过URL Encoding编码的合法域名长度较长并且不符合常规的语言习惯,容易产生误报。
基于行为的检测方法主要是针对网络中DNS流量的变化情况与整体特征。罗友强等对DNS会话进行重组,提取了7种DNS隧道攻击行为特征组成特征向量进行检测[8];单康康等人混合了三种常用分类算法并加权求优,构建了基于通信行为的检测模型[9];Liu J等人提取了时间间隔、请求数据包大小、DNS类型和子域名熵四种行为特征进行检测[10];Ishikura N等人提出根据DNS请求命中缓存的情况来判断是否为隧道攻击[11];Pomorova等人使用了域名长度、与域名相关的IP数量、TTL值、DNS查询成功标志等多种行为特征来检测隧道攻击行为[12]。多种行为特征组成特征向量,能很好地表现出攻击流量与正常流量之间的差异性,降低基于载荷方法中因编码导致的误报情况,但是正常网络通信环境中,DNS隧道攻击流量出现频率会远小于正常流量出现的频率,若对每个DNS会话进行重组、计算特征与检测,会消耗大量的计算资源,从而导致检测效率不高。
1 DNS隧道攻击特征提取
针对DNS隧道攻击特征提取,分析了现有研究在特征提取与选择上存在的问题,提出了DNS流量行为的粗粒度特征与细粒度特征,并且使用两种特征相结合对DNS流量进行分类判断。粗粒度与细粒度特征相结合的方式如图1所示,首先将通信流量按时间片划分,使用粗粒度特征判断存在DNS隧道攻击的时间片,再将可疑时间片中的DNS会话进行重组,通过细粒度特征检测出DNS隧道会话流量。
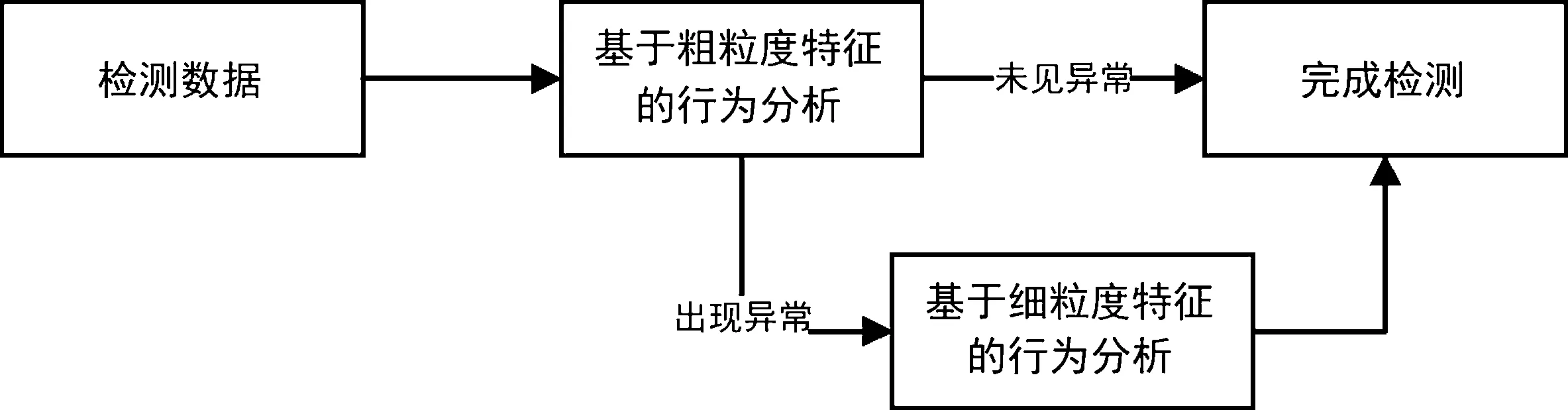
图1 粗细粒度结合方式
1.1 粗粒度特征
由于对每条DNS会话进行重组、计算特征与检测会导致检测效率低下,因此提出了粗细粒度相结合的检测方法。粗粒度特征针对一段时间片内所有的DNS流量,用于判断当前时间片内的DNS流量是否存在异常,而无需重组并定位具体的DNS会话流量。针对时间片内DNS流量,本文选取了7种粗粒度特征,如表1所示。
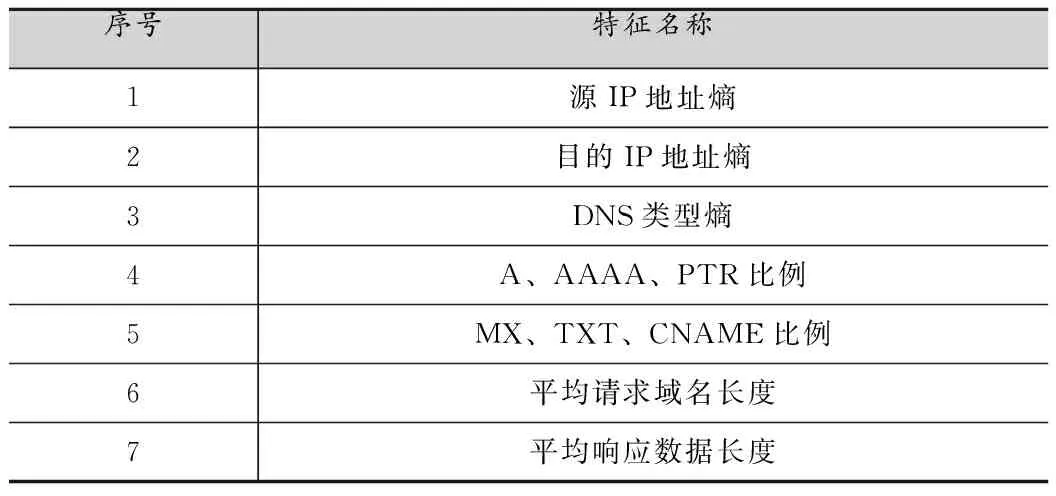
表1 粗粒度特征
(1)熵值计算方法
以源IP地址熵为例,源IP地址熵是使用时间片中不同源IP的数量占总的网络流数量比值来计算信息熵,采用向量X=(x1,x2,…,xn)表示单位时间片中的数据流有n个不同的源IP地址,针对其中任一取值xi,设时间片中存在ki条网络流的源IP地址为xi,主机在该时间窗口中的源IP地址熵H(X)计算公式为式1所示。其中S对应不同源IP地址出现个数,如式2所示。
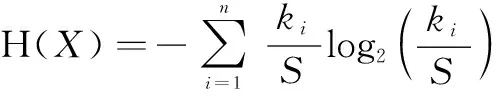
(1)
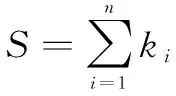
(2)
(2)源IP地址熵
正常内网环境中,大部分DNS会话数据包数量较少,每台主机在正常网络连接中都会产生一些长度相似DNS会话,因此时间片内源IP地址熵值会较高。基于UDP的DNS协议限制载荷最大为512字节,因此DNS隧道攻击发送的数据会被切分为很多DNS请求数据包,因此当有主机与DNS隧道攻击服务器进行交互时,单位时间内该主机产生的DNS请求数量会远大于其他主机,因此时间片内源IP地址熵值会降低。
(3)目的IP地址熵
选取此特征原因类似于源IP地址熵,在内网各个主机没有制定相同的DNS服务器地址时,对存在攻击行为的时间片会有较好的检测效果。
(4)DNS类型熵
正常网络环境中DNS协议是用于域名解析,大部分DNS请求与响应数据包都是A类型(解析为IPv4地址)与AAAA类型(解析为IPv6地址),因此时间片内DNS类型熵值较小。若时间片内存在攻击流量,有大量其他类型的DNS请求时,DNS类型熵值会提高。
(5)A、AAAA、PTR比例
正常DNS请求多为A、AAAA、PTR三种类型,用于返回解析后的IP地址信息,因其载荷小而不适应于作为DNS隧道攻击的类型,DNS隧道攻击使用这三种协议会导致分片过多影响传输速度且容易被侦测到,因此当内网中有主机与DNS隧道攻击服务器进行交互,该时间片内此比例较低。
(6)MX、TXT、CNAME比例
MX、TXT、CNAME为DNS隧道攻击常用的类型,因其载荷较大且可以存储任意字符而易于传输隐蔽数据信息,因此内网中如果有主机与DNS隧道攻击服务器进行交互,大量的MX、TXT、CNAME类型DNS流量会使得时间片内此比例较高。
(7)平均请求域名长度
DNS隧道攻击会将通信的内容编码后作为请求域名的子域名进行传输,因此与DNS隧道攻击服务器进行交互时发出的DNS请求中域名长度较长。内网中如果有主机与DNS隧道攻击服务器进行交互,在通信时间片内会产生大量长域名请求,从而导致平均请求域名长度会大于正常网络请求时间片。
(8)平均响应数据长度
进行DNS隧道攻击时,DNS隧道攻击服务器会将响应控制信息编码进行回传,而正常DNS相应多为解析域名后返回的IP地址信息,因此DNS隧道攻击的响应数据包会大于正常DNS服务器响应数据包。
1.2 细粒度特征
细粒度特征用于粗粒度特征之后,用来定位具体的隧道攻击会话。将时间片内的DNS会话进行重组后,为了保证能够准确定位具体的DNS隧道攻击会话,因此针对每一条DNS会话,本文提取了17种细粒度特征,如表2所示。
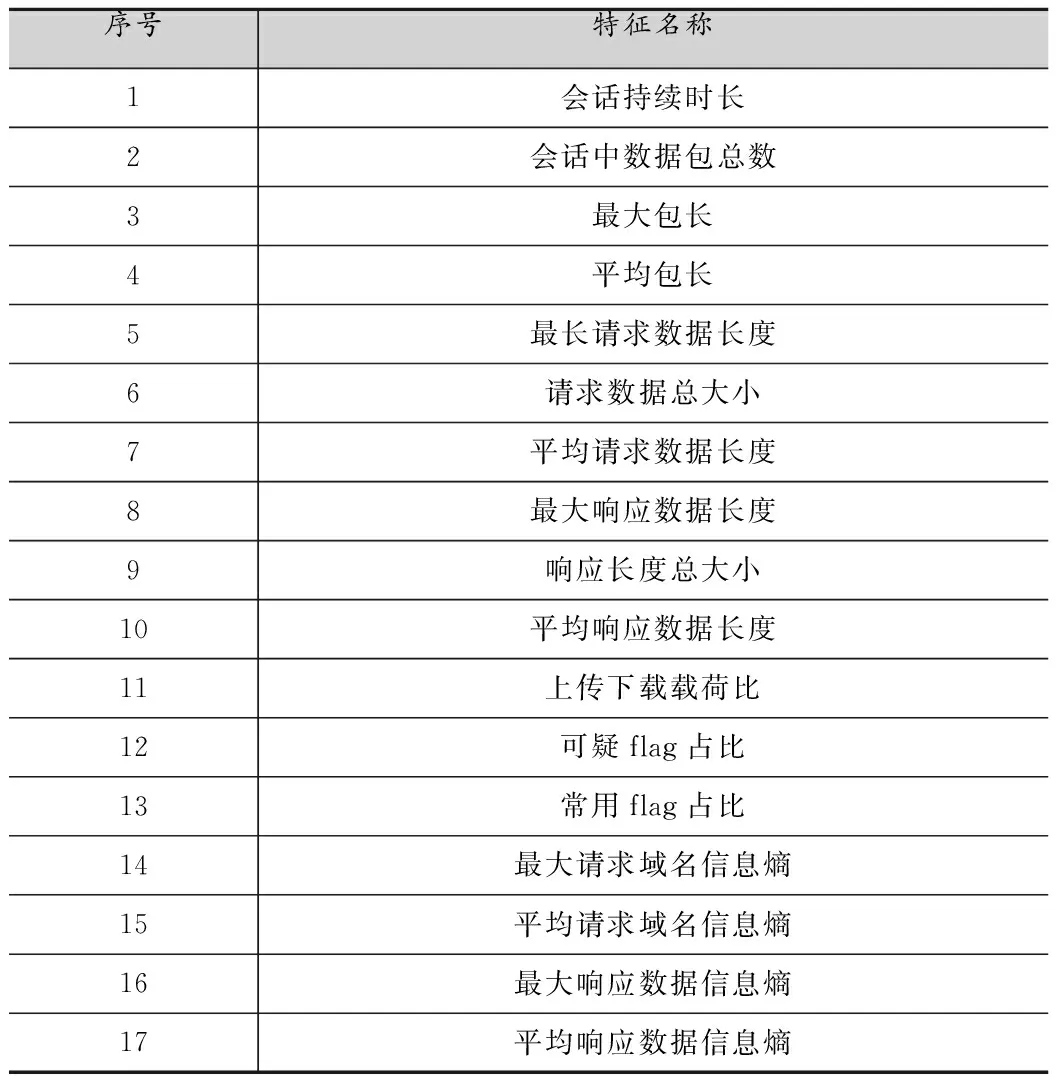
表2 细粒度特征
(1)DNS会话时长与会话中数据包总数
不同于基于TCP协议的会话在通信过程中存在三次握手与四次挥手行为,DNS基于无连接的UDP协议,因此DNS没有严格意义上会话时长的定义。本文将在一次会话中最后一条DNS报文与第一条DNS报文时间的差值作为会话时长的定义。正常情况下的DNS请求,是由请求域名解析的主机在本地开启一个任意端口,向域名服务器的53端口发出请求,服务器响应之后DNS解析过程就结束了,客户机创建的套接字也会在一段时间内关闭。因此DNS隧道攻击会话与正常DNS请求相比,会话时长更长,会话中数据包总数更大。
(2)最大包长与平均包长
在DNS隧道攻击流程中,会存在内网主机向外部攻击服务器发送信息以及外部攻击服务器向内网主机发送指令信息的情况,在传输信息或指令时,通常是将其编码再由DNS协议作为载体传输,因此此时的DNS会话的UDP数据包会较长。
(3)请求数据长度、响应数据长度与上传下载载荷比
对于会话中请求数据长度与响应数据长度,分别计算了其最大值、平均值与总大小。若DNS隧道用于内网信息窃取,则请求数据的长度相比于正常DNS会话会较长;若DNS隧道用于外部远程命令执行攻击,则响应数据的长度相比于正常DNS会话会较长。这种情况下,上传下载载荷比也会与正常DNS会话不同。
(4)可疑flag与常用flag占比
正常DNS请求主要是A、AAAA、PTR类型的DNS报文,而DNS隧道攻击为了提高传输效率,会更多使用TXT、MX、CNAME类型的DNS报文。
(5)域名信息熵
与正常DNS请求的域名信息不同,DNS隧道攻击会采用多种编码方式对传输数据进行编码,因此请求的域名信息熵值会偏高,整个DNS隧道攻击会话中最大与平均域名信息熵会比正常DNS会话要高。
2 多粒度DNS隧道攻击检测方法
基于第1.2小节分析的粗细粒度的特征,可以从DNS会话中提取出两类特征构建两种评估向量。为了减少会话重组与提取过多特征并聚类导致的计算资源消耗,提高检测效率,本文提出了一种多粒度DNS隧道攻击检测方法,使用粗粒度与细粒度特征相结合,在保证检测准确率的同时能够提升特征提取与检测效率。同时根据DNS隧道攻击检测的特性,选择了基于层次的聚类算法BIRCH算法进行聚类分析。
2.1 检测框架
本文提出的多粒度DNS隧道攻击检测方法的基本流程如图2所示。
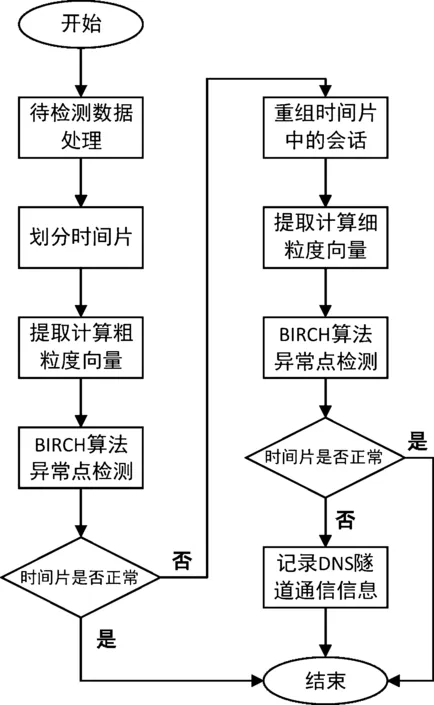
图2 基于网络行为的多粒度DNS隧道检测方法的基本流程
与其他直接重组所有DNS会话,并同时提取所有特征进行检测的方法不同,本方法整体流程分主要分为粗粒度检测与细粒度检测两部分。如图2所示,传入待检测的数据包后,首先进入粗粒度检测阶段,此阶段不会进行重组DNS会话这一耗费大量计算资源的行为,而是先将数据包按时间片切分,对切分后的每一时间片内的数据提取粗粒度特征构建特征向量,使用BIRCH算法对异常时间片进行检测,正常时间片内的数据包放行,不做下一步检测,若发现异常时间片,记录异常时间片内的数据包进行下一检测阶段,因此在粗粒度检测阶段需要保证较低的漏报率,确保异常时间片都能进入下一检测阶段;进入细粒度的检测阶段后,先对异常时间片内的各个DNS会话进行重组,提取更多的细粒度特征构建向量,进而更准确地定位DNS隧道攻击会话。由于通常网络环境中,正常DNS会话数量远大于DNS隧道攻击数量,因此采用了多粒度检测方法后,绝大多数DNS数据包在粗粒度阶段判断为正常被放行,减少了大量重组会话与提取特征并聚类的时间;同时相较于其他行为检测方法,能够实现细粒度阶段提取更多特征而不降低检测效率的效果,为较好地集成到实时入侵检测系统提供了可能。
2.2 方法实现
根据处理的先后顺序以及对数据包的处理方法,整个流程分为粗粒度与细粒度两个模块。
2.2.1 粗粒度检测模块
粗粒度检测模块输入为从网络环境中获取的数据包文件,输出为存在DNS隧道攻击的时间片信息。具体实现步骤如下:
①提取pcap格式数据包中所需的数据。此步骤仅从输入的pcap数据包中按条提取出所需要的基本数据并记录,例如数据包时间戳、源目的地址与端口、数据包长度、分片标志位、递归标志位和TTL值等数据,特征的计算过程交由后续步骤处理以缩短时间;
②划分时间片并计算粗粒度特征。根据预设的时间窗口大小与数据包的时间戳,将数据包数据按照切分成多个时间片,对于每一个时间片计算出2.1小节中选取的粗粒度特征,提取出所有时间片的粗粒度特征后进行归一化处理并进入下一步骤;
③选取适合的算法进行检测并记录异常时间片。此步骤选取了BIRCH算法进行聚类,将少数存在攻击行为的异常时间片作为异常点进行检测,标记异常时间片并将其基本数据送入细粒度检测模块进行下一步检测。
2.2.2 细粒度检测模块
细粒度检测模块输入为异常时间片中数据包的基本信息,输出为DNS隧道攻击信息。具体实现步骤如下:
①将时间片中的数据包按会话进行重组。根据预设的会话延时时间与四元组信息,将时间片内的数据包重组成多组会话,每组会话中包含多条数据包的信息,每个时间片以三维矩阵的形式记录;
②计算细粒度特征。对于时间片中的每一组会话计算出2.2小节中选取的细粒度特征,提取出所有会话的细粒度特征后进行归一化处理并进入下一步骤;
③选取适合的算法进行检测并记录DNS隧道攻击信息。此步骤同样选取了BIRCH算法进行聚类,将少数DNS隧道攻击会话作为异常点进行检测,记录下其信息完成DNS隧道攻击检测。
2.2.3 算法选择
对于上述模块第三步中算法的选择,分析了本方法的整个检测流程后,总结出了以下几个特点:
①正常DNS请求行为单一,提取特征聚类轮廓近似球形;
②只抓取了DNS流量,噪声数据或突发情况较少;
③提升粗细粒度检测速度,算法效率尽可能高;
④正常样本与DNS隧道数量差别过大,可以将正常样本聚类成簇、将隧道样本作为异常点进行检测。
针对以上特点,本文选取了BIRCH算法作为检测算法,BIRCH算法虽然抗干扰性不佳,但其有着聚类形状为球形、算法效率高、能够实现无监督异常点检测的特点,能够较好地满足本方法的要求。
BIRCH算法是一种基于层次的聚类算法,其使用了一个树型结构来快速聚类,这个树型结构类似于B+树,称为聚类特征树,树的每一个节点都是若干个聚类特征(CF),内部节点的CF的指针指向其孩子节点,所有的叶子节点用一个双向链表链接起来。其构建过程也类似于B+树的构建,每个节点中CF数需设定上限,达到上限该节点进行分裂,因此BIRCH算法的训练过程就是建立聚类特征树的过程[14]。
BIRCH算法的CF是一个三元组,用(N,LS,SS)表示,其中N代表了这个CF中拥有样本点的数量,LS代表了这个CF中拥有的样本点各特征维度的和向量,SS代表了这个CF中拥有的样本点各特征维度的平方和。若聚类特征中有N个D维数据点如式(3)所示,则LS与SS的计算方法分别为式(4)和式(5)。
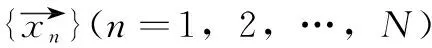
(3)

(4)

(5)
可以发现CF满足线性关系,从而在聚类特征树中,父节点CF是由其所有子节点CF线性相加所得到的,因此BIRCH算法能够很好地表示成一个层次树型结构。
在构建BIRCH算法模型时我们需要调整的参数为内部节点的最大CF数B、叶子节点的最大CF数L、叶节点每个CF的最大样本半径阈值T,读入让样本点时根据T值决定是否聚为同一个CF,再根据B与L值决定该节点是否分裂。
从BIRCH的定义我们就能看出此算法的特性:聚类速度快,只需要一遍扫描训练集就可以建立CF Tree,CF Tree的增删改都很快;聚类结果分布簇为超球体;BIRCH除了聚类还可以做一些异常点检测和数据初步按类别规约的预处理[15]。因此能够较好的满足本方法的要求。
3 实验与分析
为验证此方法能够有效地检测出DNS隧道攻击会话,以及验证使用粗细粒度相结合的方法后能够提高检测效率,设计了两组实验来对本文提出方法的有效性与检测效率进行试验。第一组实验为使用多种聚类算法来验证本方法的有效性,并验证BRICH算法为最适用于此类情景的算法;第二组实验对比了重组所有DNS会话并同时提取特征与使用多粒度模型进行检测的时间消耗,验证使用多粒度模型对检测效率提升的效果。
3.1 实验数据
本次实现所使用的DNS数据为四川大学某实验室内部网络拓扑下的收集的实验数据。在实验室内部网络中的两台主机上分别使用dns2tcp、iodine搭建环境,不定期与搭建在外部阿里云服务器上的DNS隧道攻击服务器进行交互,期间实验室内网络通信正常使用,使用Tcpdump在出口网关上抓取流出与流入的所有数据包,过滤其余协议只保留DNS协议数据包,最后收集了包含隧道攻击流量的DNS数据包共计1,007,883条。
3.2 评价标准
为了验证该方法在具有较好检测效果的同时能够提高检测效率,将召回率、误报率以及检测时长作为衡量实验结果的指标。召回率、误报率具体计算公式如式(6)与式(7)所示。检测时长为从划分时间片开始到输出结果的总时长。

(6)
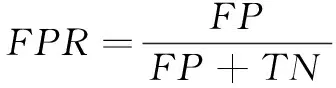
(7)
在实验中由于DNS隧道攻击流量为检测主体部分,所以隧道攻击流量为正样本,正常流量为负样本。因此召回率能够很好地反映从大量正常DNS会话中检测出少量隧道会话的能力。
3.3 实验结果
本文实验采用Python sklearn模块对数据集进行聚类分析,设定粗粒度时间片间隔为300秒,分别使用BIRCH算法、DBSCAN算法、K-means算法进行聚类,验证其召回率、误报率与处理时间;同时采用BIRCH算法,比较使用多粒度模型与不使用多粒度模型的召回率、误报率与处理时间对差异。
将含有DNS隧道流量的数据包按日期分成五份,使用多粒度模型,BIRCH算法、DBSCAN算法、K-means算法的召回率、误报率与处理时长如表3所示。其中时长为划分时间片、重组DNS回话以及检测的总时长,单位为秒。

表3 三种算法检测效果对比
因为DBSCAN算法与K-means算法在粗粒度检测阶段误报率略高,因此更多的时间片被用于细粒度检测,导致检测时长增加。
为了更好地对比,其召回率、误报率与时长如图3、图4与图5所示。
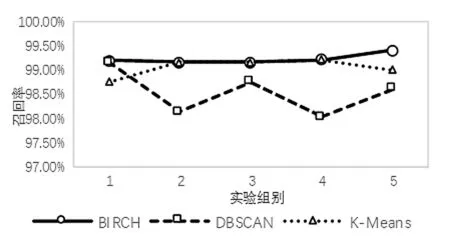
图3 三种算法召回率对比
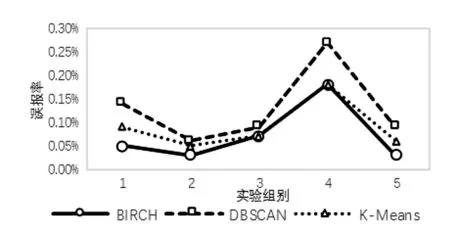
图4 三种算法误报率对比
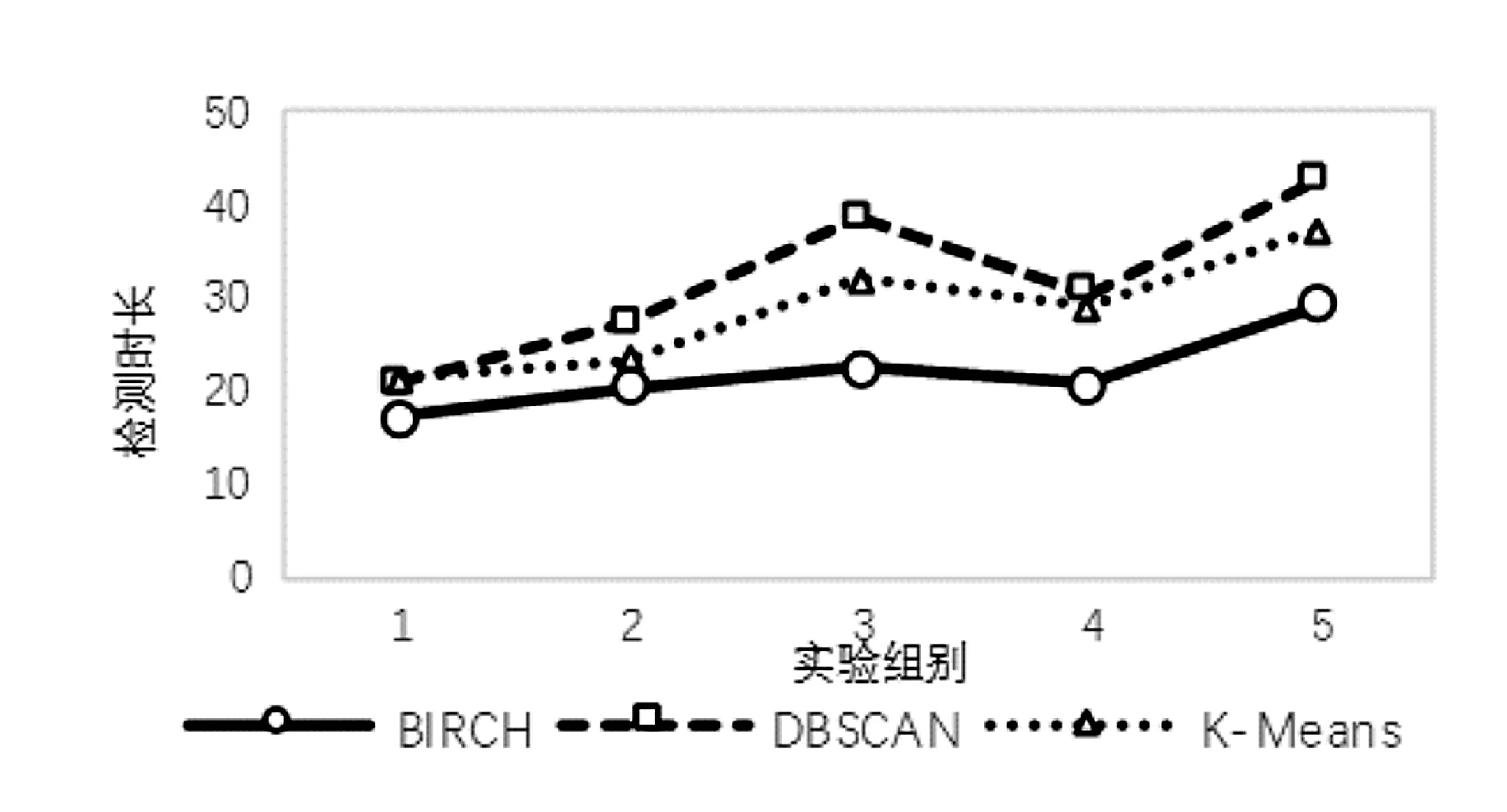
图5 三种算法检测时长对比
对于BIRCH算法,不使用多粒度模型对每个DNS会话进行检测,与使用多粒度模型进行检测的实验结果如表4所示。其中时长为划分时间片、重组DNS回话以及检测的总时长,单位为秒。
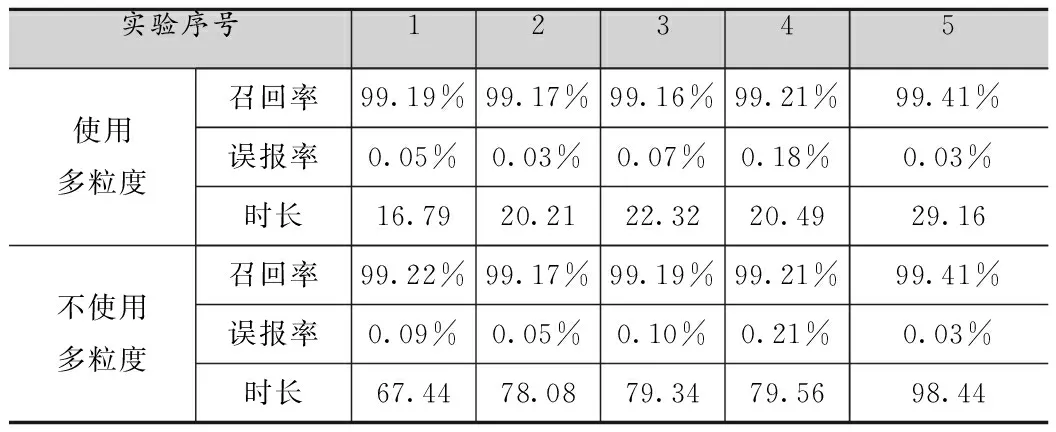
表4 使用与不使用多粒度识别效果对比
为了更好地对比,其检测时长如图6所示。
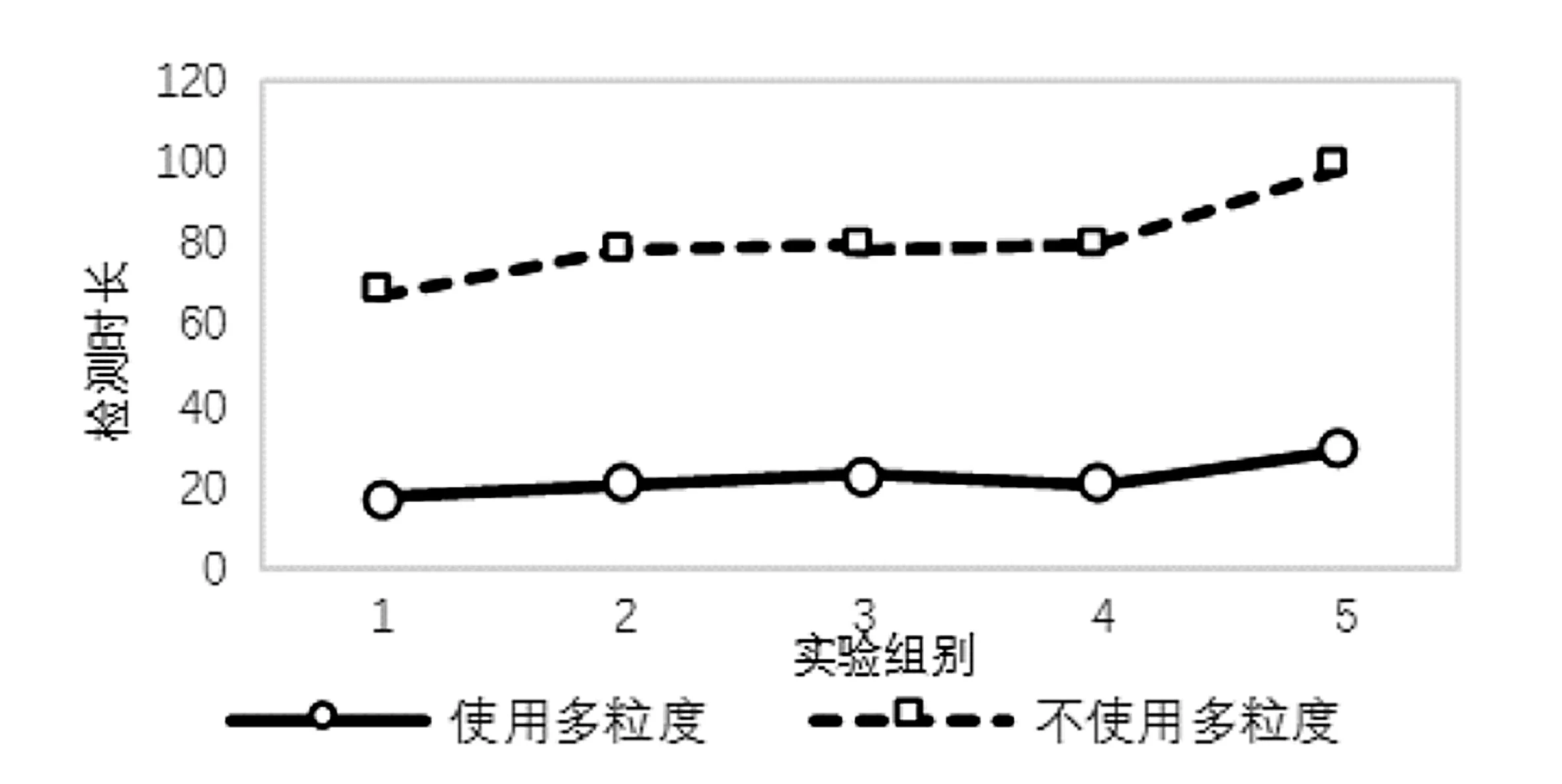
图6 使用与不使用多粒度模型检测时间对比
通过表3的实验结果可以看出,对于从大量正常DNS会话中检测出少量隧道攻击流量,使用多粒度模型进行检测能够取得较高的召回率以及较低的误报率,并且对于DNS这一种单一类别的协议进行检测,BIRCH算法在检测时长上较有优势,与之前分析相符。
同时从图6可以发现,采用了多粒度模型后,能够减少大量DNS会话重组与细粒度特征提取的次数,节省计算资源,能够在不降低检测准确率的情况下,极大提高检测速度。
4 结语
本文提出的方法在保持良好的检出率的情况下,检测效率有了很大的提升,为较好地集成到实时入侵检测系统提供了可能。进一步挖掘可用于DNS隧道检测的新特征、改进算法性能、应用于实时入侵检测系统将是下一步的研究重点。
