基于双编码器的会话型推荐模型
2021-08-05方军管业鹏
方军,管业鹏,2
(1.上海大学通信与信息工程学院,200444,上海; 2.上海大学新型显示技术及应用集成教育部重点实验室,200072,上海)
encoder; recommendation model
随着互联网的高速发展和通信技术的不断进步,信息过载在各种网络应用上成为了一个严重的问题,而推荐系统是缓解信息过载和提升用户体验必不可少的工具。无论用户是否注册或登录,会话都能够记录一段时间内用户的行为信息(如点击)。会话型推荐的任务是根据当前会话中已知用户的行为来预测用户的下一次行为。
由于会话型推荐有着较高的实用价值,所以吸引了很多学者进行了相关研究。马尔可夫链是一种经典的方法,它假定下一个行为取决于最后若干个行为,但这使得基于马尔可夫链的模型[1]无法利用长序列中行为之间的依赖,并且可能会出现数据稀疏的问题。
近年来,基于深度学习的方法取得了突飞猛进的进展,其中基于循环神经网络(RNN)的研究相比传统方法取得了长足的进步。门控循环推荐模型(GRU4REC)[2]将RNN用于建模用户的顺序行为以捕获用户当前对物品的偏好。神经注意力推荐机(NARM)[3]采用两个RNN,其中一个用于捕获用户的顺序行为,另一个RNN与注意力机制结合以捕获主要意图。类似NARM,短期记忆优先模型(STAMP)[4]同样利用注意力机制捕获用户的当前兴趣和总体兴趣,但它用多层感知机来替代RNN。重复网模型(ReapeatNet)[5]考虑了重复消费现象,提出重复-探索机制。协同会话推荐机(CSRM)[6]将RNN与记忆网络相结合,将相邻会话表示存储在记忆网络之中,然后将存储在记忆网络的中的协同信息与用RNN编码的当前会话表示通过融合门相结合。个性化分层循环模型(PHRM)[7]采用3个RNN分别捕获会话级、区块级和用户级兴趣。图表示学习的会话感知模型(GESP)[8]将RNN与图表示学习结合以缓解用户的兴趣漂移问题。但RNN难以捕获长范围的依赖。
由于图神经网络(GNN)能够捕获节点间的依赖关系和以此带来的出色性能表现,近年来越来越多的工作采用了GNN来解决会话型推荐问题。图神经网络会话推荐模型(SR-GNN)[9]将会话序列构建成会话图,使用GNN来捕获物品间的转移。目标注意力图神经网络模型(TAGNN)[10]在SR-GNN模型[9]的基础上提出一种目标注意力网络,它通过将候选物品的嵌入作为注意力机制的查询向量来发现当前会话中的物品与候选目标物品间的相关性。无损边序保留聚合及捷径图注意力会话推荐模型(LESSR)[11]提出边顺序保留聚合层来解决基于GNN的顺序信息丢失问题。但GNN只能捕获邻节点间的局部依赖。
尽管以上方法取得了不错的推荐效果[12-14],但是难以准确捕获远距离物品间的依赖。最近,在自然语言处理领域,出现了一个叫做Transformer的基于注意力机制的模型[15]。它在WMT 2014[16]翻译的任务上取得了优异的成绩。它所采用的自注意力网络是它成功的关键因素之一。自注意力网络能够有效捕获所有物品间的全局依赖,但它缺少捕获相邻物品间局部依赖性的能力,这限制了它捕获序列的上下文信息。图情境自注意力网络模型(GC-SAN)[17]将GNN与自注意力网络级联来捕获长距离依赖。然而,节点输入自注意力网络前使用GNN对邻节点间进行的图卷积使得每个节点变得平滑,这导致输入自注意力网络后不能准确的捕获物品间的全局依赖。
综上所述,已有的会话型推荐研究并不能有效捕获物品间的全局依赖与局部依赖。对此,本文提出了SR-BE模型,该模型利用了自注意力网络和图神经网络之间的互补性,采用基于自注意力网络作为全局编码器和基于图神经网络为局部编码器的双编码器结构来捕获物品间的依赖。最后将全局编码器和局部编码器输出的线性组合作为会话表示,再通过预测层解码会话表示得到每个候选物品被点击的概率。为使实验结果可复现,源代码网址为https:∥github.com/GalaxyCruiser/SR-BE。
1 SR-BE会话型推荐模型
1.1 问题描述
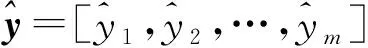
1.2 模型概述
SR-BE由嵌入层,全局编码器,局部编码器和预测层组成。嵌入层将输入映射到低维密集空间。基于自注意力网络的全局编码器用于捕获全局依赖,基于图神经网络的局部编码器用于捕获局部依赖。全局编码器与局部编码器输出的线性的组合作为预测层的输入,预测层输出每个物品被点击的概率。模型的架构如图1所示。
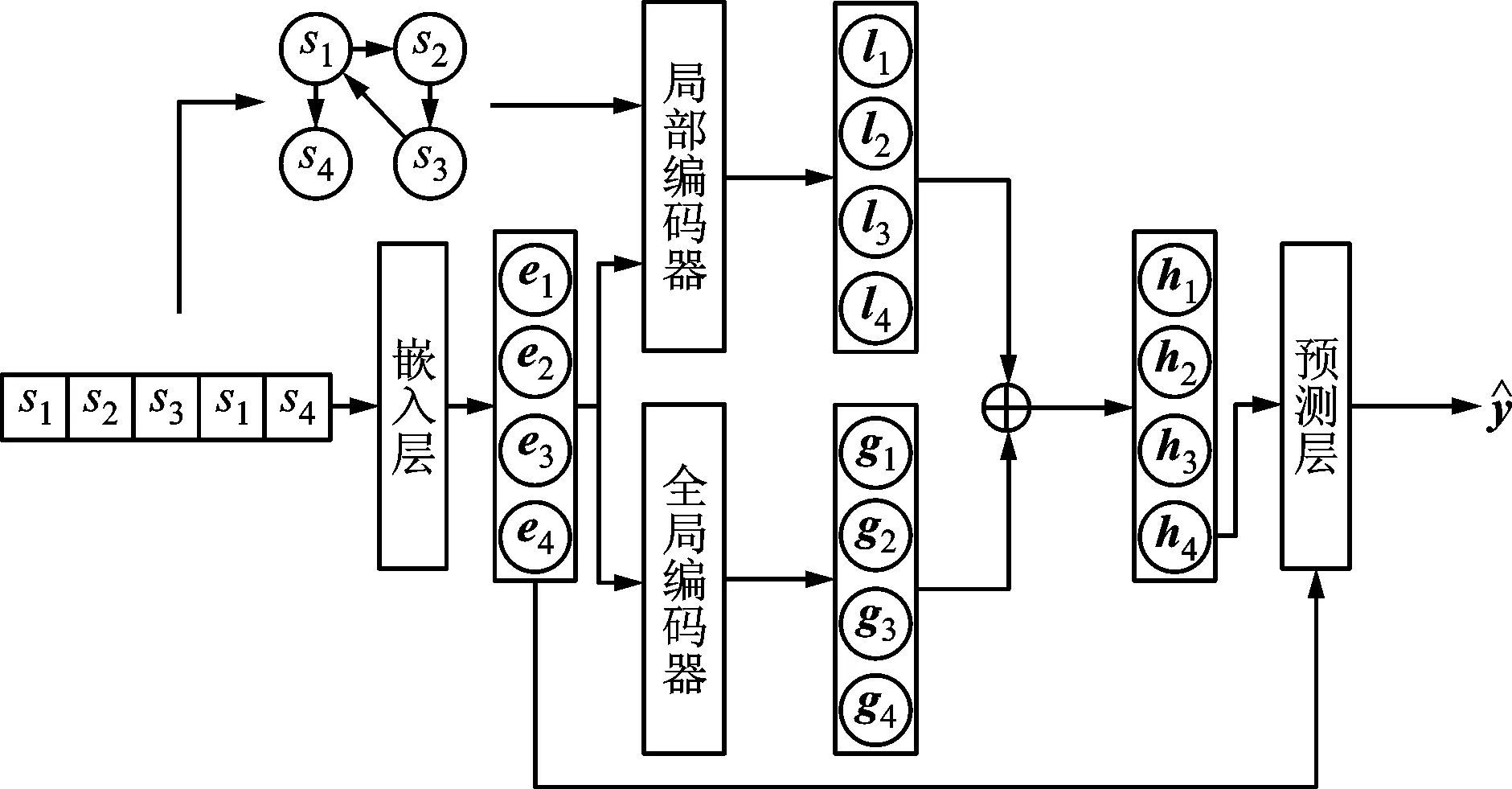
图1 基于双编码器的会话型推荐模型的架构Fig.1 The architecture of the session recommendation model based on dual encoder
1.3 嵌入层
嵌入层可以理解为一个字典,它将物品的索引映射为密集向量,将接收物品的整数索引作为输入,并在字典中查找整数索引,然后返回对应的向量。将会话序列S=[s1,s2,…,sn]输入嵌入层来得到对应的嵌入序列E=[e1,e2,…,en],嵌入的维度为d,即ei∈Rd。
1.4 基于自注意力网络的全局编码器
自注意力是注意力机制的特例,它将同一个输入用于注意力机制的查询向量、键向量和值向量。因此,每一个物品对应的输出都能获取所有输入物品的信息[15]。这使得自注意力机制能够捕获当前会话中所有物品间的全局依赖且不受物品间的距离影响。
将通过嵌入层得到的嵌入序列E输入自注意力层来捕获物品间的全局依赖[15]
(1)
式中:WQ、WK和WV∈Rd×d分别为查询、键、值参数矩阵。当嵌入维度d取一个较大的数时,点积的结果可能会是一个绝对值很大的数,为防止softmax函数进入梯度很小的区域[15],将查询向量与键向量的点积除以d1/2。为保留低层信息,自注意力层采用了残差连接[15]。
然后,将F按元素输入到一个前馈神经网络当中,该网络由两个线性变换组成,两个线性变换间包含了一个Relu激活函数。前馈神经网络同样采用了残差连接[15]
G=max(0,FW1+b1)W2+b2+F
(2)
式中:G=[g1,g2,…,gn]为会话中物品的全局隐向量;W1∈Rd×f;W2∈Rf×d为参数矩阵;b1∈Rf、b2∈Rd为偏置向量,f为前馈神经网络的维度;G为全局编码器的输出。
1.5 基于图神经网络的局部编码器
1.5.1 图构建 对于给定的会话序列S=[s1,s2,…,sn],序列里每个物品si可以看作是一个节点,si在si-1后的点击可以看作是两节点间的一条有向边。因此一个会话序列可以构建成一个有向图。对于在会话S中出现多于一次的物品,边的权重通过除以节点的度来归一化。设AI,AO∈Rn×n分别为入矩阵和出矩阵。入矩阵和出矩阵的每一行分别表示该节点与其他节点的入边与出边关系,其值大小为边的权重。当会话序列S=[s1,s2,s3,s1,s4]时,其对应的会话图、入矩阵和出矩阵如图2所示。

(a)会话图

(b)入矩阵AI

(c)出矩阵AO
以节点s1为例,该节点仅有一条来自节点s3的入边,故入矩阵对应的第1行第3列为1;有两条去往节点s2和s4的出边,出度为2,因此出矩阵对应的第1行第2和第4列为1/2。
1.5.2 局部隐向量学习 局部编码器采用门控图神经网络[18]来学习局部隐向量。对于会话图中第t个节点st,其图卷积为[9]
(3)

zt=σ(Wzat+Uzet)
(4)
rt=σ(Wrat+Uret)
(5)
ct=tanh(Woat+Uo(rt⊙et))
(6)
lt=(1-zt)⊙et+zt⊙ct
(7)
式中:Wz、Wr、Wo∈Rd×2d;Uz,Ur,Uo∈Rd×d为参数矩阵;σ(·)为sigmoid函数;⊙表示按对应元素相乘;zt和rt是更新门和重置门,分别用于控制信息的保留和遗弃;ct为候选态;lt为节点t的局部隐向量。会话中物品的局部隐向量L=[l1,l2,…,ln]为局部编码器的输出。
1.6 预测层
会话表示h是会话中第n个物品的全局隐向量gn和局部隐向量ln的线性组合
h=ωgn+(1-ω)ln
(8)
式中,ω为权重因子,控制全局编码器和局部编码器在会话表示中所占的比重。

(9)

(10)
1.7 模型训练
损失函数定义为真值与预测值之间的交叉熵
(11)
式中,y表示真值物品的独热编码,该损失函数通过随时间反向传播(back-propagation through time)算法来优化。
2 实验结果与分析
2.1 数据集
为验证所提模型的有效性,本文在两个代表性的公开数据集Yoochoose[19]和Diginetica[20]上进行了评估实验。Yoochoose[19]是来自RecSys Challenge 2015的一个包含电商网站6个月点击记录的数据集。由于Yoochoose数据集十分庞大,本文遵循对比方法将其最近一段时间的1/64数据用作实验,记为Yoochoose 1/64。Diginetica[20]是来自CIKM cup 2016比赛的数据集,其中的transaction数据适用于本次实验。为公平比较,将长度为1的会话和在数据集中出现次数少于5次的物品滤除[2-11,17],并且采用相同的数据增强方法[20]。采用Yoochoose 1/64数据集[19]最后一周的数据和Diginetica[20]最后一天的数据分别作为各自的测试集。数据集的统计信息如表1所示。
2.2 对比模型
为客观定量评价本文模型的有效性,将本文模型与下述代表性模型进行比较。因子分解个性化马尔可夫链(FPMC)[1]是基于马尔可夫链的下一篮(basket)推荐,为适用于会话型推荐,下一个物品被看作下一篮。基于物品的近邻方法(Item-KNN)[22]推荐基于当前会话已点击物品的余弦相似度。基于矩阵分解的贝叶斯个性化排序(BPR-MF)[23]利用随机梯度下降法优化对排序目标函数。GRU4REC模型[2]首次将RNN用于会话型推荐。NARM模型[3]将RNN与注意力机制结合以捕获用户的主要意图和顺序行为。STAMP模型[4]利用注意力机制和多层感知机捕获会话的总体兴趣和当前兴趣。ReapeatNet模型[5]考虑了重复消费现象,提出重复-探索机制。CSRM模型[6]将RNN与记忆网络相结合,使得模型在推荐时可以利用协同信息。SR-GNN[9]将会话序列构建成会话图,使用GNN来捕获物品间的转移。TAGNN模型[10]提出一种目标注意力网络,能够发现当前会话物品与目标物品间的相关性。LESSR模型[11]采用边顺序保留聚合层来解决基于图神经网络的顺序信息丢失问题。GC-SAN模型[17]将图神经网络与自注意力网络级联来捕获长距离依赖。

表1 实验数据集统计数据
2.3 评价指标
由于推荐系统每次只能推荐少量的物品,故采用以下在相关工作中广泛使用的评价指标。
命中率(hit rate,HR)表示在所有测试样例中正确推荐的比例,目标标签出现在推荐列表的前20个物品中即为命中,其表达式为
(12)
式中:N表示测试集中会话的数量;nhit表示命中的数量。
排名倒数均值(mean reciprocal rank,MRR)表示目标标签在推荐列表中排名倒数的平均值,通常用百分数表示,当排名超过20时,排名倒数设为0。设一组数据含有4个会话,正确结果出现在各自推荐列表的排名分别为4、1、2、4,则其对应的排名倒数分别为1/4、1、1/2、1/4,这组数据的平均倒排名为(1/4+1+1/2+1/4)/4,等于0.5。该指标能够反映出推荐的精度,推荐的结果排名数值越小,则排名倒数越大,推荐精度越高。排名倒数均值的计算公式为
(13)
式中:N表示测试集中会话的数量;vlabel是会话的标签;Slabel为测试集的标签集;rank(·)为排名函数,用于获取标签在推荐列表中的排名。
2.4 实验设置
SR-BE的所有参数都采用平均值为0、标准差为0.1的高斯分布初始化。采用初始学习率为0.001、每3个epoch衰减0.1的Adam优化器。batch大小设为100。Yoochoose 1/64[19]和Diginetica[20]数据集的嵌入维度分别设为96和72。自注意力网络中的前馈神经网络的大小f设为嵌入维度的4倍[15]。L2正则化设为10-5以缓解过拟合。
2.5 与对比模型比较
为客观定量评价本文模型的有效性。选取以上对比模型在两个公开数据集Yoochoose 1/64[19]和Diginetica[20]以命中率和排名倒数均值为指标进行比较,实验结果如表2所示,最优结果以加粗字体突出。从表2可以看出,本文模型在两个评价指标上都优于其他对比模型。
传统方法[1,22-23]性能较为一般,这些方法仅仅基于物品相似度或者物品间的转移,忽略了会话顺序上的信息。基于神经网络的方法显著超过传统方法,说明了深度学习的方法在会话型推荐领域的有效性。GRU4REC[2]是首个采用RNN的会话型推荐模型,尽管在Diginetica数据集[20]上的性能不如Item-KNN[22],但依然能够体现出RNN在构建序列模型的能力。NARM[3]和STAMP[4]都利用注意力机制来捕获全局偏好,性能都显著优于GRU4REC[2],表明全局偏好对于提高推荐不可忽视。RepeatNet[5]根据重复消费现象,提出重复-探索机制,显著提升了目标标签出现在当前会话物品中的情形下的性能,总体上优于NARM[3]和STAMP[4],然而在非重复物品场景下效果有所下降。CSRM[6]性能优于NARM[3],说明了利用其他会话里的协同信息的有效性,但CSRM[6]的存储网络所存储相邻会话是基于顺序的,没有区分这些会话与当前会话的关联性。基于RNN的方法,当物品距离远时会产生梯度消失或者梯度爆炸,难以捕获到远距离物品间的依赖。
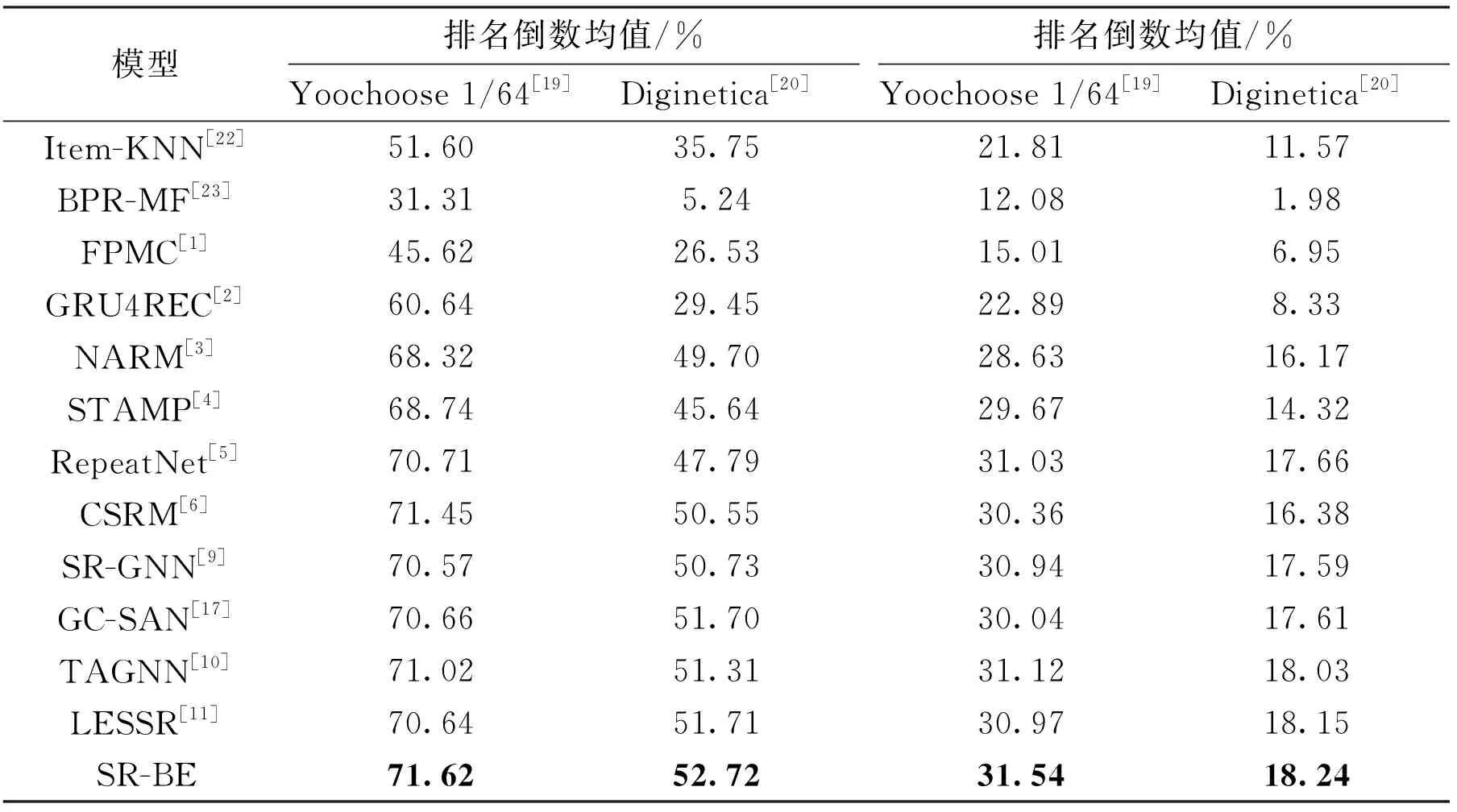
表2 本文SR-BE模型与对比模型的性能比较
基于GNN网络的方法总体上优于基于RNN网络的方法。SR-GNN[9]将会话序列构建成图,再使用GNN网络能够捕获到邻节点之间的依赖,性能总体优于多数基于RNN的方法。TAGNN[10]在SR-GNN[9]基础上提出了目标注意力模块,使得模型能够发现当前会话物品与目标物品之间的关联性,性能上超越了SR-GNN[9],但由于需要对每个候选项做注意力计算,使得TAGNN[10]在训练过程中十分缓慢。由于LESSR[11]未提供在Yoochoose数据集上的结果,本文利用LESSR[11]所提供的源代码和默认设置完成了在Yoochoose 1/64数据集[19]上的实验。LESSR[11]通过解决会话序列转化为图网络时顺序信息丢失的问题,使得性能较SR-GNN[9]更佳,表明保留会话的序列信息的有效性,但它仅考虑了节点的入边依赖,忽略了节点的出边依赖。GC-SAN[17]性能与SR-GNN[9]相近。虽然本文与GC-SAN[17]都采用了自注意力网络来捕获物品间的全局依赖关系,但是GC-SAN[17]捕获全局依赖关系时,自注意力网络的查询向量是在GNN网络下聚合了邻节点信息的节点隐向量,这会压制其他非邻节点的注意力权重。因此,采用这种方式不能准确捕获会话的全局依赖关系。而本文模型中的自注意力网络的查询向量中完整保留了对应物品的特征,能够有效捕获物品间的全局依赖。SR-BE在两个数据集上以命中率和排名倒数均值为评价指标都取得了最佳效果。实验结果表明SR-BE采用自注意力网络捕获物品的全局依赖,图神经网络捕获邻近节点间的局部依赖,能够得到更加精准的会话表示,从而有效的提高了会话推荐的准确度。
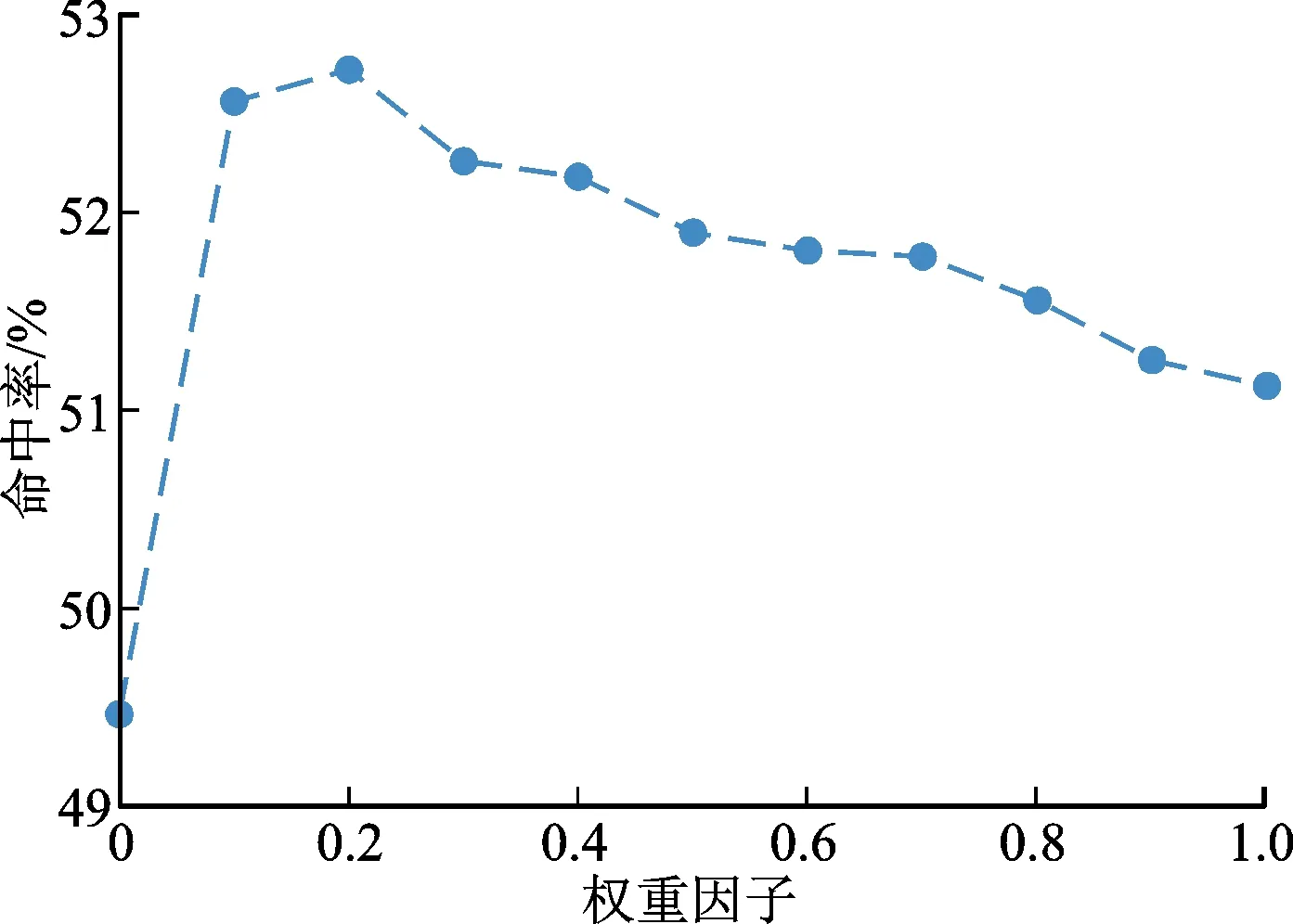
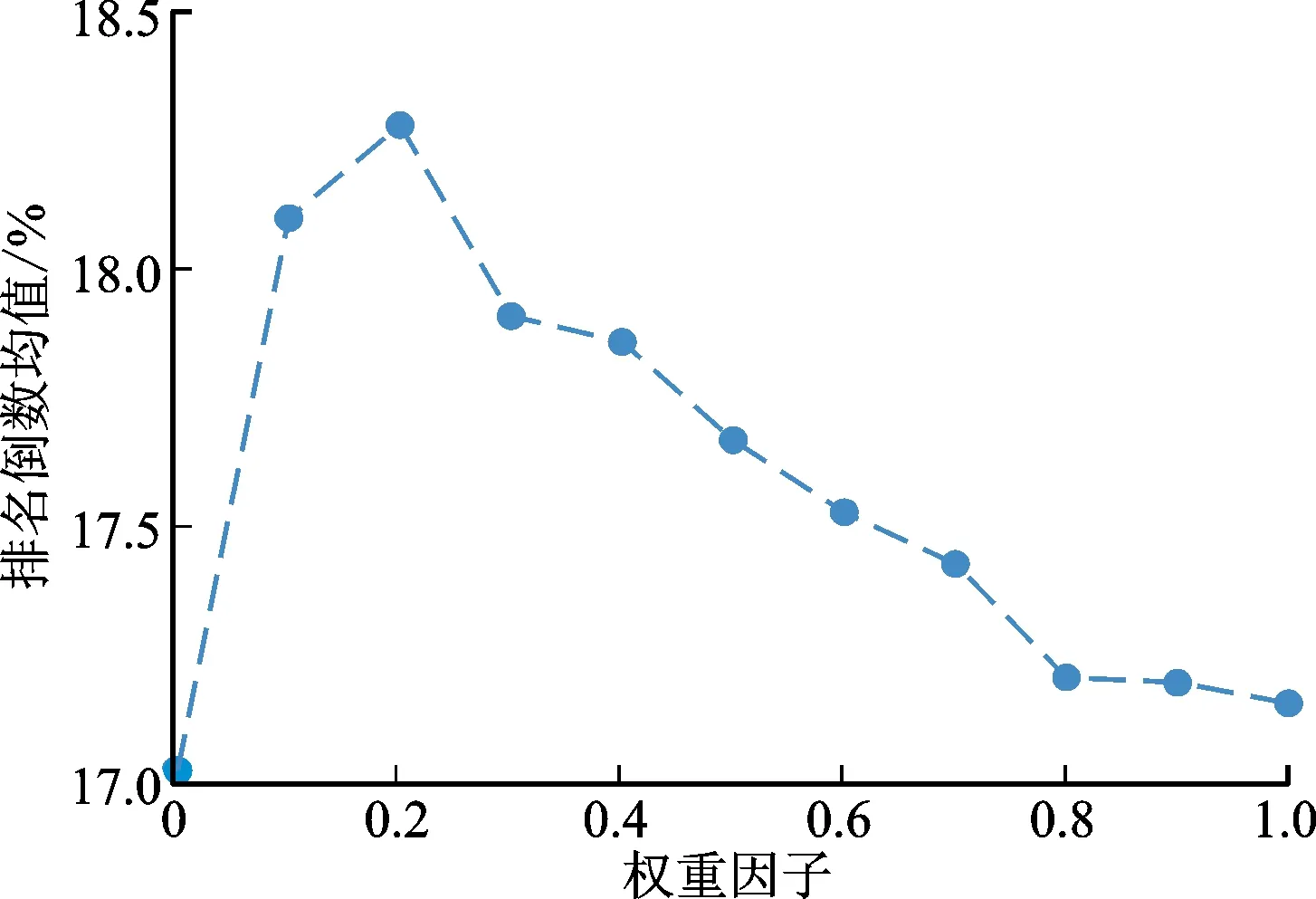
2.6 权重因子的影响
权重因子ω控制了自注意力网络和图神经网络的对会话表示的影响力。图3、图4显示了权重因子对命中率和排名倒数均值的影响。由图3和图4可知,4幅曲线图都呈现出两头低、中间高、右端点高于左端点的态势。这表明仅仅采用全局编码器(ω=1)比仅仅采用局部编码器(ω=0)性能更佳;将基于自注意力网络的全局编码器与基于图神经网络的局部编码器结合在一起,能够比单一使用其中任何一个编码器得到更好的效果。这说明全局编码器能够有效的捕获物品间的全局依赖,但是局部依赖性对于提高推荐性能同样必不可少。对于Yoochoose 1/64数据集[19],在命中率指标上的最佳权重因子在0.5附近,在排名倒数均值上最佳权重在0.7附近。对于Diginetica[20]数据集,在命中率和排名倒数均值上的最佳权重因子在0.2附近。

(a)在Yoochoose 1/64数据集的影响
(b)在Diginetica数据集的影响图3 权重因子对命中率的影响Fig.3 The impact of weight factor on hit rate

(a)在Yoochoose 1/64数据集的影响
(b)在Diginetica数据集的影响图4 权重因子对排名倒数均值的影响Fig.4 The impact of weight factor on mean reciprocal rank
2.7 嵌入维度的影响
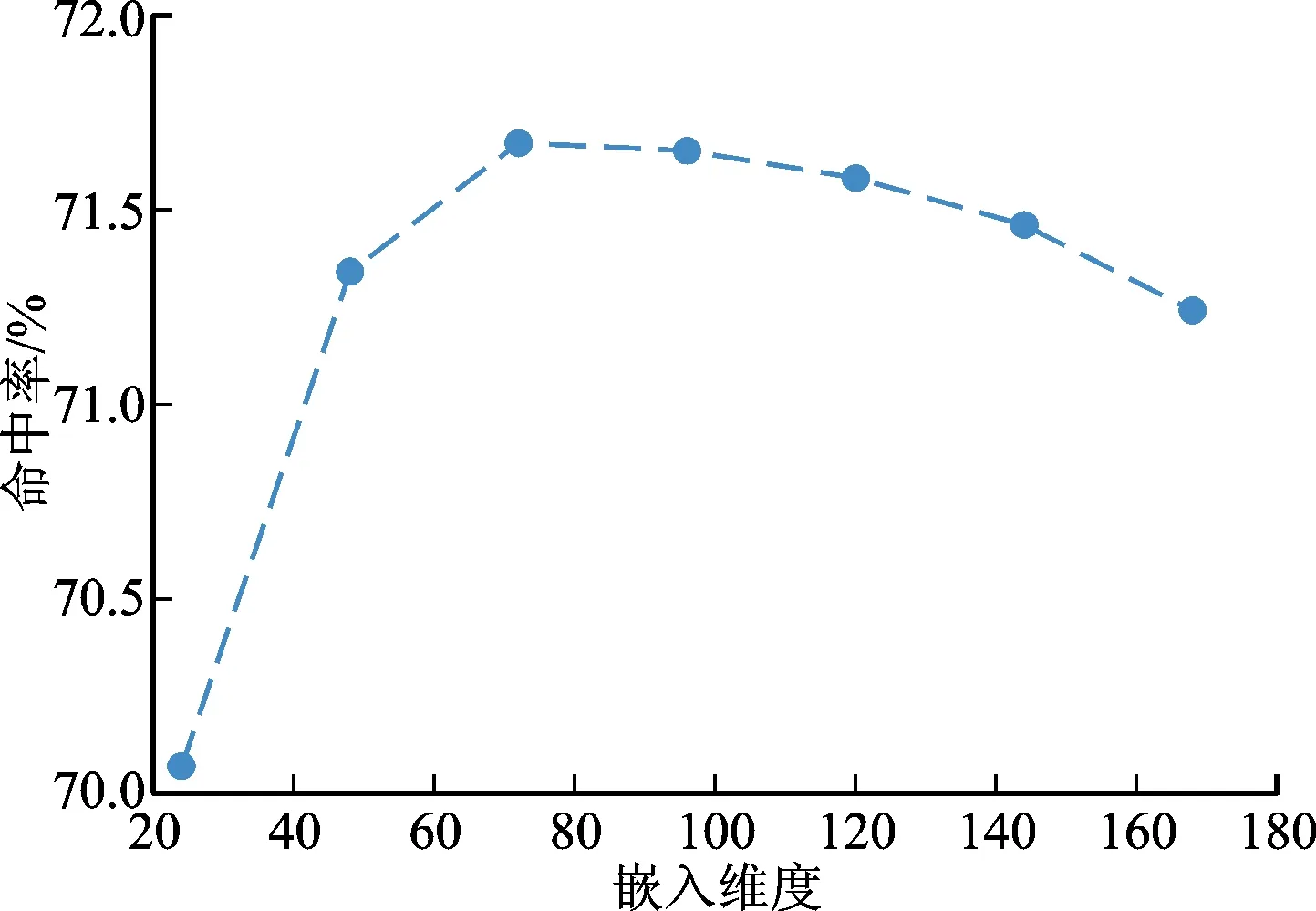
图5、图6分别展示了嵌入维度d在24~168范围内对Yoochoose 1/64数据集[19]和Diginetica数据集[20]的影响,其中Yoochoose 1/64数据集[19]的权重因子设为0.5,Diginetica数据集[20]的权重因子设为0.2。由图5、图6可知,增大嵌入维度并非总是能够提升模型性能。对于Yoochoose 1/64数据集[19],它在命中率指标上的最佳值在72附近,它在排名倒数均值上的最佳值在144附近。对于Diginetica数据集[20],它在命中率指标上的最佳值在72附近,它在排名倒数均值上的最佳值在96附近。当嵌入维度超过最佳值后,模型的性能开始下降,这是因为模型进入了过拟合的状态;当嵌入维度低于最佳值时,模型的性能随着嵌入维度的增加而提高,这是因为更大的嵌入维度为模型提供了更大的学习容量。
(a)对命中率的影响

(b)对排名倒数均值的影响图5 嵌入维度在Yoochoose 1/64数据集的影响Fig5 The impact of embedding size on Yoochoose 1/64 dataset

(a)对命中率的影响

(b)对排名倒数均值的影响图6 嵌入维度在Diginetica数据集的影响Fig.6 The impact of embedding size on Diginetica dataset
2.8 消融实验
为进一步说明局部编码器和全局编码器对会话型推荐的影响,本文比较了SR-BE模型和它的两种变种的性能。其中SR-BE-L表示只使用局部编码器的SR-BE模型,它只捕获邻近物品间的局部依赖关系。SR-BE-G代表只使用全局编码器的SR-BE模型。SR-BE、SR-BE-L和SR-BE-G的实验结果如表3所示。从表3中可以得出以下结论:首先,SR-BE-G性能优于SR-BE-L,这说明基于自注意力网络的全局编码器能够有效捕获物品间的全局依赖,单独使用时较基于图神经网络的局部编码器准确度更高;其次,SR-BE模型在两个数据集的所有评价指标上都优于SR-BE-L和SR-BE-G,这说明将基于自注意力网络的全局编码器与基于图神经网络的局部编码器结合在一起,能够比单一地使用其中任一个编码器取得更好的推荐效果。以Diginetica数据集[20]为例,与SR-BE-L和SR-BE-G相比,SR-BE模型在命中率评价指标上的性能提升分别是6.55%和3.11%,而在排名倒数均值评价指标上的性能提升分别是7.11%和6.29%。

表3 不同编码器对模型的影响
2.9 自注意力可视化分析
为了直观体现自注意力网络在捕获物品间全局依赖时发挥的作用,本文在图7中展示了一些会话实例。这些实例是从Yoochoose 1/64数据集[19]中随机选取的。每个长条代表一个会话,长条的左边标号为会话的ID,长条中每一个方块代表会话中的一个物品。颜色的深度代表着物品对于全局表示gn的重要程度。从图中可以得出以下结论:①对于全局表示重要的物品较多的出现在会话尾部附近。这种现象符合人们的行为模式:用户的下一个行为通常与最近的若干行为高度相关②在某些实例中,权重最大的物品出现在会话的头部或中间。这说明无论这些物品出现在会话中的何种位置,基于自注意力网络的全局编码器能够有效捕获物品间的全局依赖。

图7 自注意力权重可视化示意图Fig.7 A visualization diagram of self-attention weight
3 结 论
本文提出了SR-BE会话型推荐模型。SR-BE采用自注意力网络作为全局编码器来捕获所有物品间的全局依赖,将会话序列构建成会话图,采用图神经网络作为局部编码器来捕获到邻节点间的局部依赖。最后,将通过全局编码器得到的全局隐向量和通过局部编码器得到的局部隐向量的线性组合用来更加准确的表示会话序列。
(1)基于自注意力网络的全局编码器能够有效捕获物品间的全局依赖,单独使用时较基于图神经网络的局部编码器准确度更高。
(2)将基于自注意力网络的全局编码器与基于图神经网络的局部编码器结合在一起,能够比单一地使用其中任一个编码器取得更好的推荐效果。
(3)本文模型能够有效捕获物品间的全局依赖与局部依赖,提高推荐准确度。该模型在公开数据集上验证了性能,实验结果表明SR-BE模型性能明显高于相关对比模型。
