柠条塔煤矿水化学特征及水源识别模型
2021-08-05侯恩科
侯恩科,姚 星,文 强
(1.西安科技大学 地质与环境学院,陕西 西安 710054;2.中煤科工集团 西安研究院有限公司,陕西 西安 710054)
0 引 言
随着煤矿开采越发深入,矿井水文地质条件复杂多样,陕北侏罗纪煤田煤层上覆基岩厚度整体较薄,极易发生表层地下水的溃涌现象[1],形成较为严重的顶板水害问题,困扰着煤矿的安全生产[2-3]。解决矿井水害问题的关键在于对矿井涌水水源进行精确识别,从而解决和进一步降低开采过程中地下水的影响,为矿井防治水工作提供行之有效的依据[4]。
目前,用于矿井涌水水源识别主要包括地下水化学分析法、同位素示踪技术以及水位动态观测等手段[5-7]。井田内不同含水层离子含量的差异使得各含水层间水化学特征存在一定区别,地下水的水化学特征可以反映含水层的内在特质,以往研究中众多学者利用地下水的水化学特征结合多种数学方法建立了矿井涌水水源的识别模型[8]。杨建通过分析葫芦素煤矿不同含水层水化学特征,识别了矿井水的来源[9]。解海军等应用Fisher判别分析法对井下突水水源的类型进行了判别,判别结果较好,但传统Fisher判别分析过于依赖样本间的关联性[10];代革联等将水质分析法与聚类分析法相结合确定了矿井的突水水源,但聚类分析法无法忽略异常值的影响[11];侯恩科等利用水化学分析法结合Logistics回归分析对矿井涌水水源进行了识别,但该方法无法解决数据不平衡的问题[12]。利用机器学习理论对矿井不同含水层水化学组分进行分析从而识别涌水水源这一方法应用已越发广泛,徐星等提出了一种改进粒子群算法优化BP神经网络的水源识别模型,可实现水源的快速判别,但该算法过于依赖训练样本的精度[13]。冯东梅等建立了矿井突水水源的SVM识别模型,实现了高维小样本的评价,但SVM算法对于核函数的选择尚无合适的方法[14]。邵良杉等通过粗糙集理论(RS)进行指标约简,建立了基于RS的水源识别的最小二乘支持向量机模型,但该理论仍不够完善[15]。毛志勇等将改进粒子群算法与极限学习机算法(KPCA-MPSO-ELM)相结合应用到矿井突水水源识别,验证了模型的适用性,但其识别较为繁琐[16]。
上述研究成果对于矿井涌水水源的识别起到了重要的指导作用,对于矿井水化学特征的分析已成为有效识别涌水水源的关键。但由于不同矿井水文地质特征的差异性,较多判别模型未考虑水化学组分间的信息冗余,同时对于判别指标的选取、判别模型的运行速度还有待进一步优化。基于此,为了消除水化学离子间的非线性关系,笔者以柠条塔煤矿为例,通过分析不同含水层的水化学特征,利用逐步回归分析法实现样本类间特征的提取,建立基于水化学特征法和逐步回归-最小二乘支持向量机(SR-LSSVM)的涌水水源识别模型,并对4组待测样本进行水源判别。
1 水文地质特征
柠条塔煤矿位于陕西省榆林市西北部,陕北侏罗纪煤田神南矿区西北部(图1),井田面积119.773 5 km2,主采煤层为2-2煤和5-2煤。地表绝大部分被第四系松散沉积物所覆盖,地形以沙漠滩地为主,地势北高南低。井田地质构造简单。
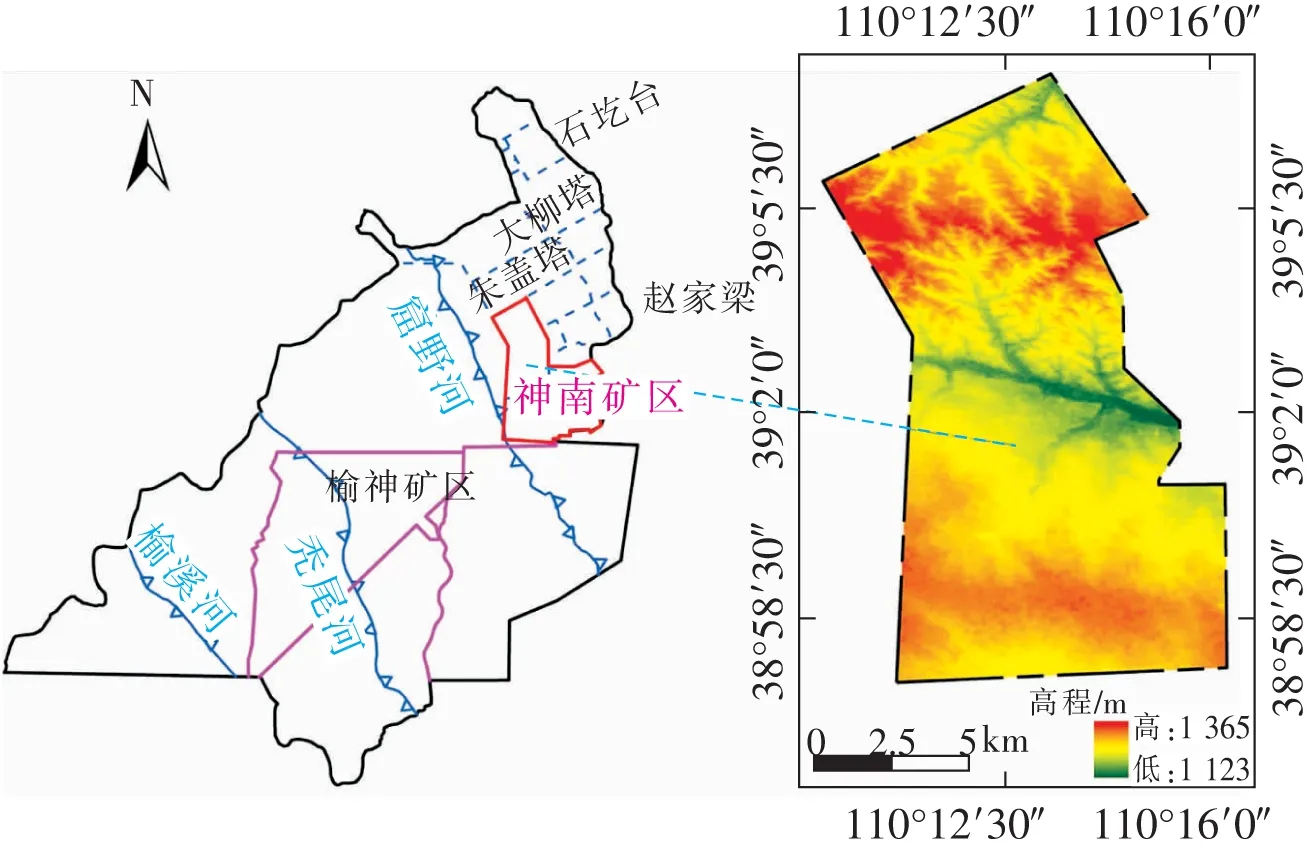
图1 研究区位置及高程
区内地层由老至新依次为三叠系上统永坪组(T3y)、侏罗纪中统延安组(J2y)、直罗组(J2z)、安定组(J2a)、第四系中更新统离石组(Q2l)、上更新统萨拉乌苏组(Q3s)、以及全新统(Q4)(图2)。
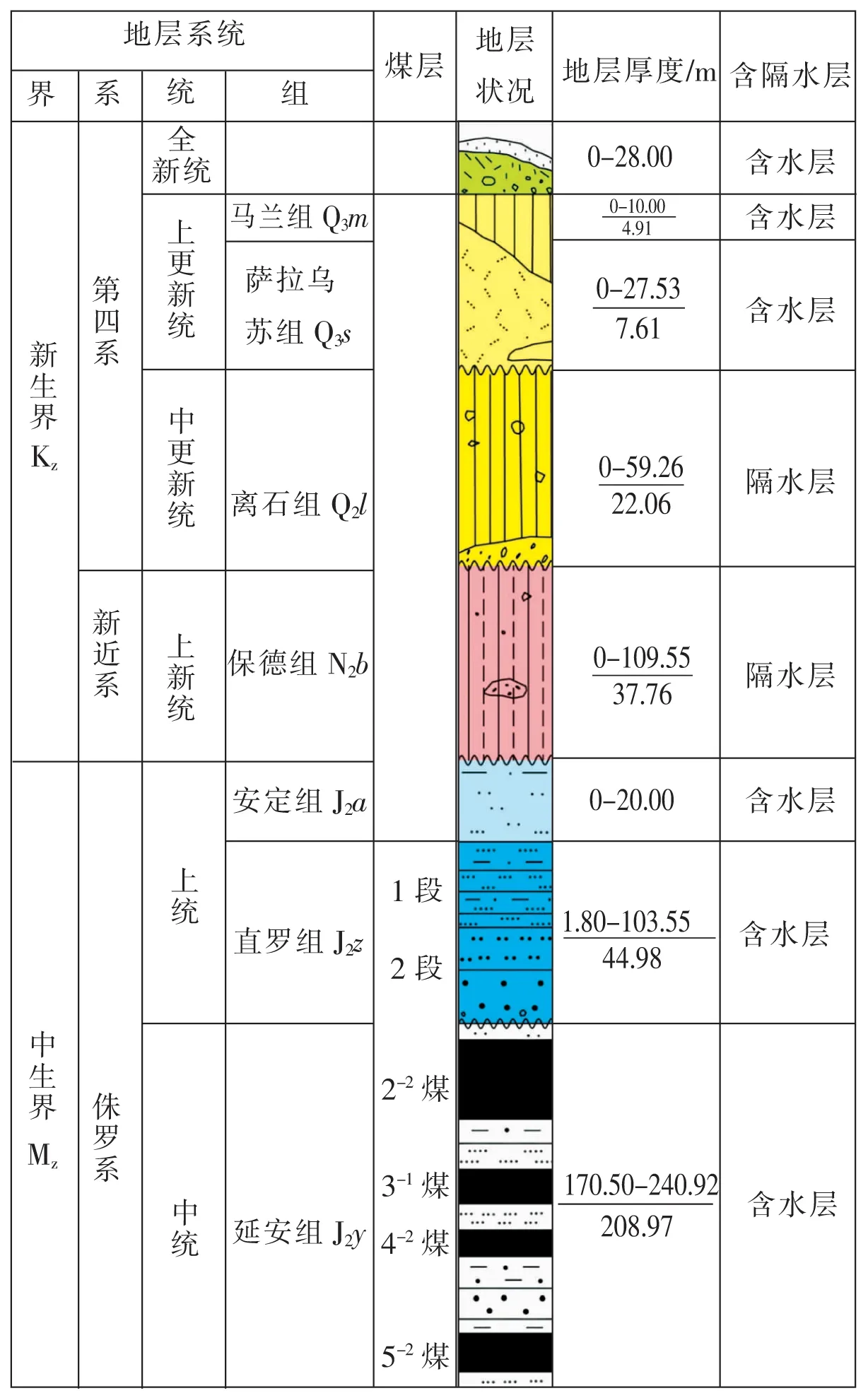
图2 地层发育特征
井田内地下水的形成受地形地貌、地层岩性及古地理环境等因素影响,主要充水含水层包括第四系萨拉乌苏组孔隙潜水含水层、侏罗系直罗组风化基岩裂隙含水层、侏罗系延安组裂隙承压含水层以及烧变岩孔隙裂隙潜水含水层,其水文地质特征见表1。含水层间均存在隔水层,水质类型相对稳定。
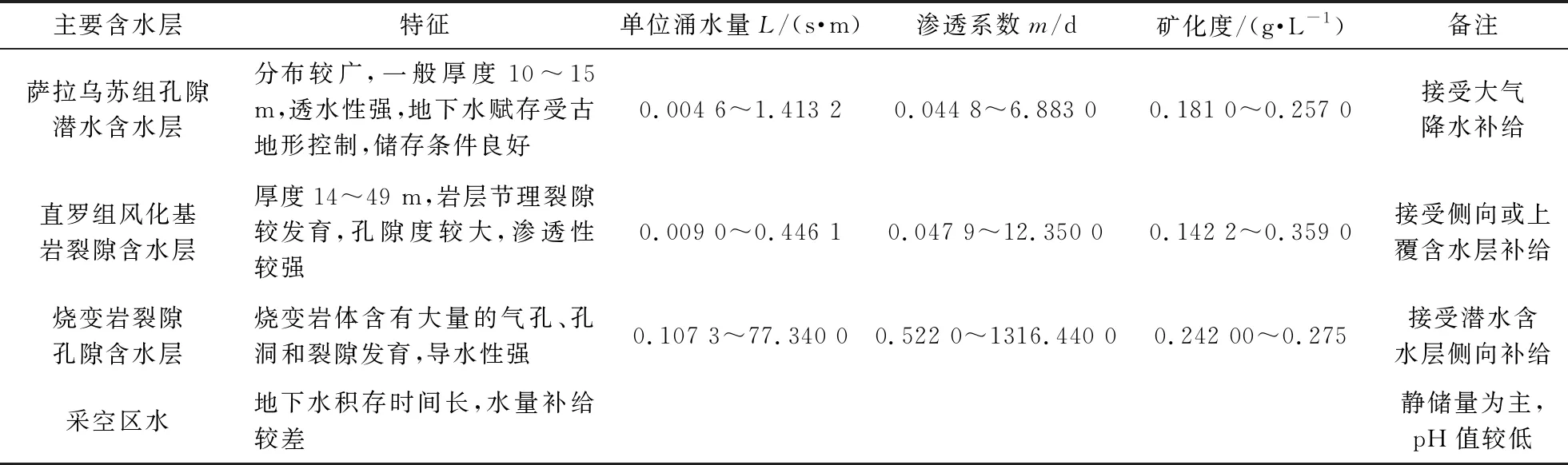
表1 含水层水文地质特征
2 地下水水化学特征
由于地下水含水介质和循环条件的不同,导致各含水层的水化学特征存在差异[17]。根据地下水的水化学成分差异分析其成因,进而确定各含水层的水质类型[18]。
2.1 样品采集
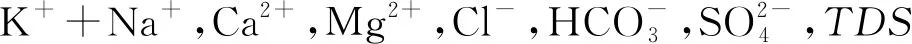
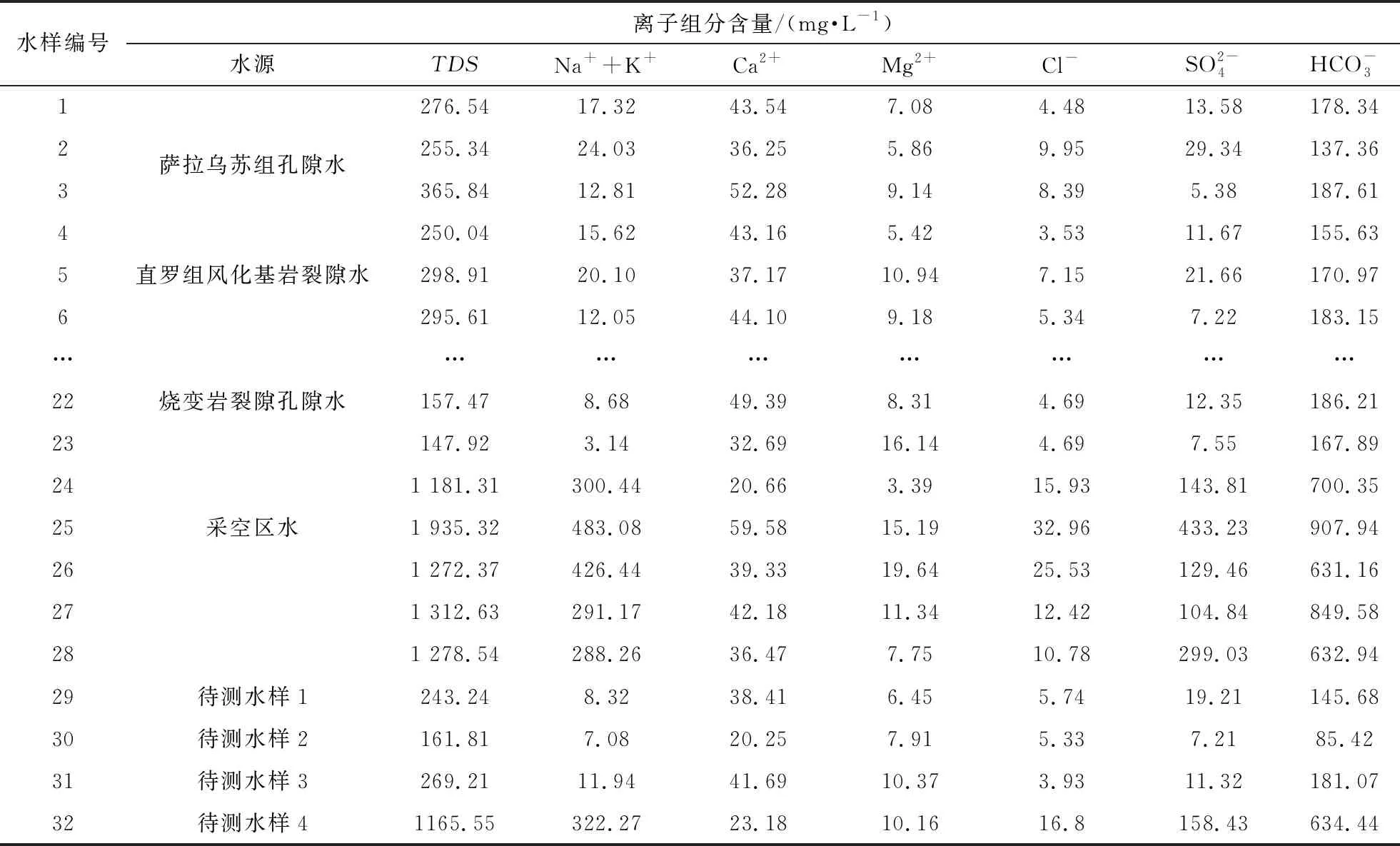
表2 含水层水化学特征
利用收集到的水样数据绘制Piper三线图,依据水样中阴阳离子在菱形区域投影点的位置表示各含水层的地下水的水化学特征[20]。
2.2 结果分析
2.2.1 萨拉乌苏组孔隙潜水
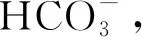
2.2.2 侏罗系直罗组风化基岩裂隙承压水
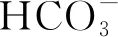
2.2.3 烧变岩裂隙孔隙水
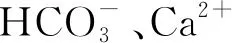
2.2.4 采空区水
2.3 地下水化学特征对比
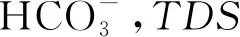
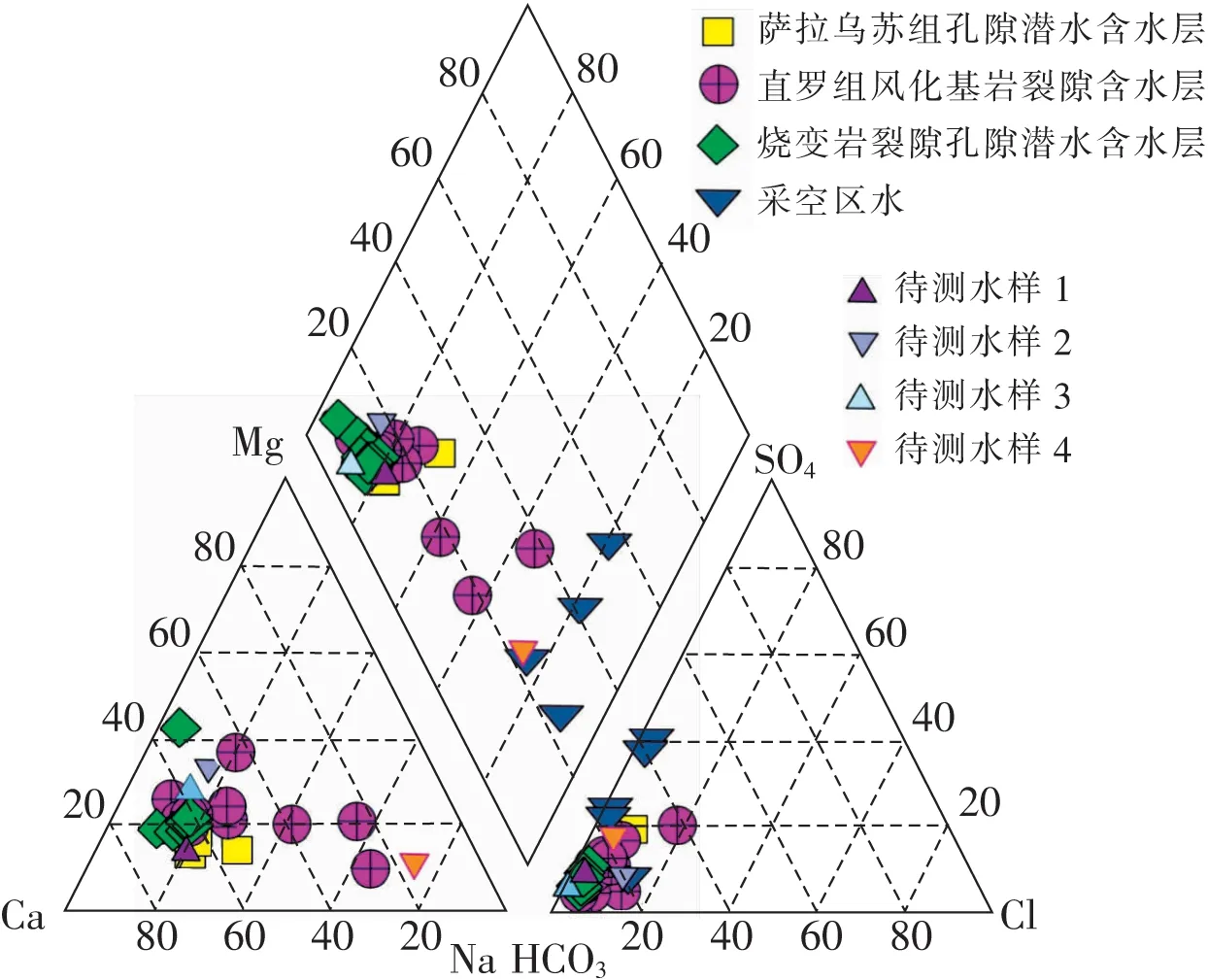
图3 含水层水化学特征
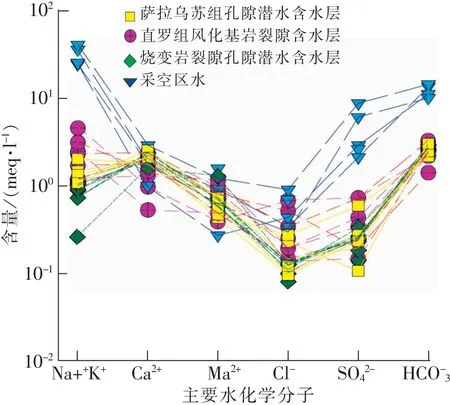
图4 含水层水化学垂向分布特征
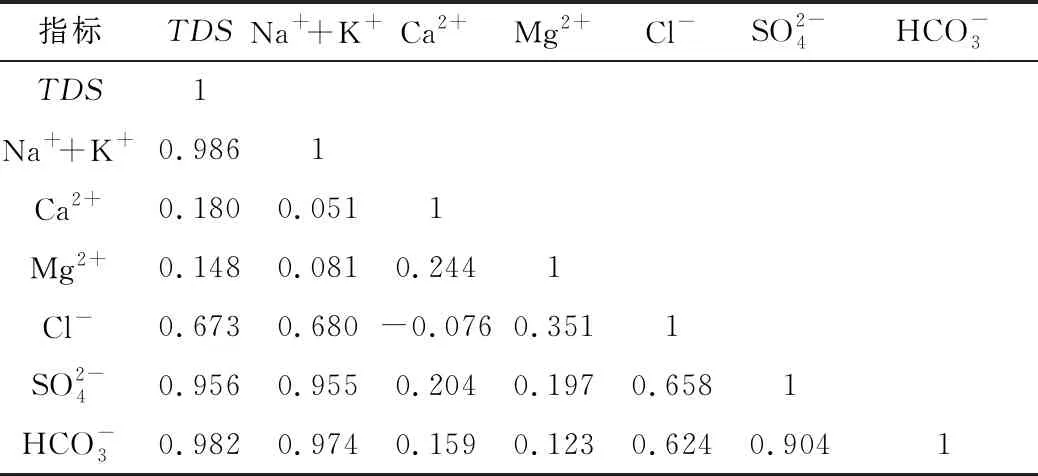
表3 指标间相关系数
3 涌水水源的SR-LSSVM识别模型
3.1 逐步回归(SR)算法
逐步回归分析(SR)是回归分析中一种筛选变量的过程,其基本原理是对自变量进行“有进有出”的动态引入,若原始变量显著,而后续变量不显著,则剔除后者,目的在于按照变量的重要程度只保留显著性变量。重复操作直到结果中既无不显著变量取出又无显著变量进入为止。
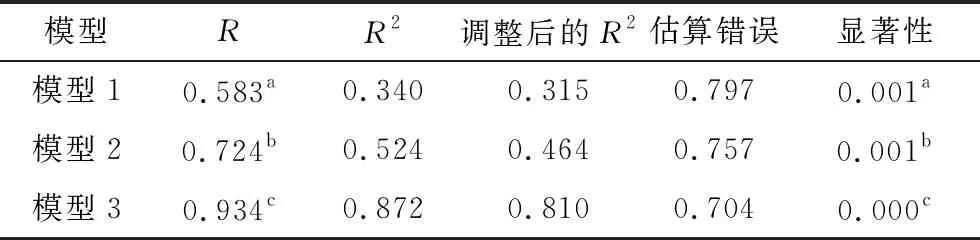
表4 模型拟合精度
3.2 最小二乘支持向量机(LS-SVM)算法
最小二乘支持向量机(LS-SVM)算法是在SVM算法的基础上发展起来的,对非线性高维小样本数据的泛化能力较强。LS-SVM算法通过非线性映射函数将原始数据映射到高维空间,将研究问题转化为不等式约束的二次规划问题,大大减少了计算的复杂性。矿井水源识别问题是一种多分类的非线性问题,因此可以利用最小二乘支持向量机(LS-SVM)模型提高识别结果的准确性。
LS-SVM算法的性能与惩罚参数C和核函数参数σ密切相关,C值过小会造成训练误差较大,预测模型的推广能力增强;而核函数σ则控制着最优解的复杂程度,若该值较小则模型易陷入局部陷阱,反之则拟合度不够。为了减少维度影响,引入拉格朗日算子θ对函数进行约束优化,并对其进行偏微分求导。
3.3 模型参数
通过分析研究区地下水水样数据,选择70%的水样数据作为训练样本,30%作为验证样本。为消除指标间量纲的影响,利用极值化法对原始数据进行归一化处理。
3.4 模型结果
利用建立的SR-LSSVM模型对训练样本进行回判,并将训练完成后的模型应用到8个验证样本的识别中。
为了验证模型的准确率,在同等数据下运用LS-SVM算法、SVM算法分别对验证样本进行识别,3个模型的识别结果如图5所示。
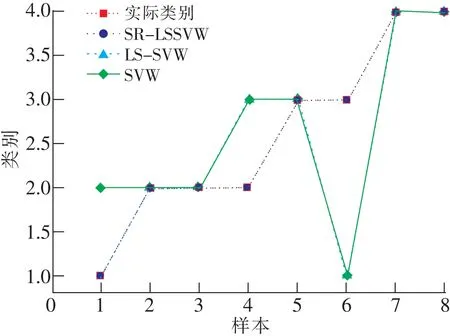
图5 模型预测结果对比
从图5可知,基于SR-LSSVM算法的识别结果与实际类型一致,而利用LS-SVM算法进行回判估计检验,实际水源类型为Ⅱ的水样被误判为Ⅲ类水源,实际类型为Ⅲ类的水样被误判为Ⅰ类水源,正确判别率为75%;利用SVM算法的准确率仅为62.5%。综合分析认为基于SR-LSSVM的矿井水样识别模型具有较好的识别精度。
4 SR-LSSVM模型的应用
利用建立的判别模型对4个待测水样进行识别,识别结果见表6。从表6可知,利用SR-LSSVM模型对预测样本进行分析,得到的结果与实际情况完全一致,回判结果的准确率达到100%。说明逐步回归分析(SR)通过提取水化学特征中的主要变量,弱化了指标间的相互关联;SVM算法可以很好的解决非线性小样本问题,LS-SVM算法通过引入核函数,使用最小二乘法对问题求解,在保证模型精度的同时也降低了计算的难度。逐步回归(SR)-最小二乘支持向量机(LS-SVM)模型的预测准确率高,该方法可以为矿井防治水工作提供一定的参考和依据。

表6 待测水样类型识别结果
5 结 论
1)通过分析矿井各含水层的水文地质条件,揭示不同含水层的水化学特征及其成因,结合各含水层的垂向发育规律和相关系数矩阵对样本数据进行对比分析,认为水化学分析法不能准确区分涌水水源,原始数据间存在着数据冗余。
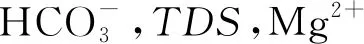
3)利用建立的SR-LSSVM判别模型对20个训练样本进行训练,通过回代估计验证对8个验证样本进行了识别,并对比SVM,LS-SVM和SR-LSSVM模型的识别结果,发现SR-LSSVM识别模型的准确率为100%高于其他模型,说明该方法可以精确高效的对矿井水源进行识别;利用该模型对4个待测样本进行识别预测,判别结果与实际情况吻合。
