基于残差密集块与注意力机制的图像去雾网络
2021-08-02李硕士刘洪瑞甘永东朱新山张军
李硕士 刘洪瑞 甘永东 朱新山 张军

摘 要:基于卷积神经网络的单幅图像去雾算法虽然取得了一定进展,但仍然存在去雾不完全和伪影等问题. 基于这一现状,提出了一种以编码器-解码器结构为基本框架,融合注意力机制与残差密集块的单幅图像去雾网络. 首先,利用网络中的编码器、特征恢复模块和解码器三个部分直接对去雾后的图像进行预测;然后,在网络中引入本文所设计的带有注意力机制的残差密集块,提升网络的特征提取能力;最后,基于注意力機制提出自适应跳跃连接模块,增强网络对去雾图像细节的恢复能力. 实验结果表明,与现有去雾方法相比,提出的去雾网络在合成有雾图像数据集和真实有雾图像上均取得了较为理想的去雾效果.
关键词:图像去雾;深度神经网络;编码器-解码器;注意力机制
中图分类号:TP391.4 文献标志码:A
Image Dehazing Network Based on Residual Dense
Block and Attention Mechanism
LI Shuoshi1,2,LIU Hongrui1,GAN Yongdong1,ZHU Xinshan1,2?,ZHANG Jun1
(1. School of Electrical and Information Engineer,Tianjin University,Tianjin 300072,China;
2. State Key Laboratory of Digital Publishing Technology,Beijing 100871,China)
Abstract:Although the single image dehazing algorithms based on the deep convolutional neural network have made significant progress,there are still some problems, such as poor visibility and artifacts. To overcome these shortcomings,we present a single image dehazing network, taking the encoder-decoder structure as the basic frame and combining the attention mechanism and residual dense block. First,the scheme integrates an encoder, a feature recovery module and the decoder to directly predict the clear images. Then, the residual dense block with attention mechanism is introduced into the dehazing network so as to improve the network's feature extraction ability. Finally, based on the attention mechanism, an adaptive skip connection module is proposed to enhance the network recovering ability for the clear images details. Experimental results show that the proposed dehazing network provides better dehazing results on synthetic datasets and real-world images.
Key words:image dehazing;deep neural networks;encoder-decoder;attention mechanism
在雾、霾等天气下,雾气中悬浮颗粒会对光线的散射造成影响,导致图像传感器所捕捉到的图像出现对比度下降等图像质量退化问题. 这些退化的图像无法真实反应场景中所存在物体的结构、颜色等信息,降低了其在图像分类[1]、目标检测[2]等计算机视觉任务中的应用价值. 因此,图像去雾是目前计算机视觉研究中的一个重要问题.
目前已有的图像去雾方法主要可以分为两类,一类是基于先验知识的去雾方法,另一类是基于深度学习的去雾方法. 基于先验知识的去雾方法通常对有雾图像进行统计以获取先验知识,然后利用先验知识对大气散射模型[3-4]中的传输图与大气光值这两个未知参数进行求解以实现图像去雾. 该类方法中最具有代表性的是He等[5]提出的暗通道先验(Dark Channel Prior,DCP)去雾方法,该方法利用其统计得到的暗通道先验,对大气散射模型中的传输图进行了估计,在不引入额外参数的情况下较好地达到了图像去雾的目的,但是当有雾图像整体趋于白色时,该方法将不能取得良好的去雾效果,并且该方法有着相对较大的计算量. Zhu等[6]通过对大量有雾图像的远景、中景、近景进行分析发现雾的浓度与图像的亮度和饱和度之差呈正比,并利用这一规律提出了一个简单但有效的线性去雾模型. Tan[7]发现无雾图像相比于有雾图像有着更高的局部对比度,于是使用了马尔可夫随机场对有雾图像的局部对比度进行了最大化以实现图像的去雾. Berman等[8]指出无雾图像中的像素点的颜色在RGB空间上可以聚类成几百个紧致的团簇,并提出了基于该先验知识的去雾算法. 基于先验知识的去雾方法近年来取得了一定的进展,并比较好地完成了基本的图像去雾任务,但是这些方法提出的先验知识并不是在所有的场景都成立的,所以基于先验知识的去雾方法具有很大的局限性.
随着深度学习的不断发展与大型去雾数据集[9]的建立,研究人员开始采用基于深度学习的方法对单幅图像进行去雾. 最初,研究人员主要通过构建神经网络对大气散射模型中的未知参数进行估计,然后利用估计的参数实现图像的去雾. Cai等[10]提出的DehazeNet去雾模型,通过特征提取、多尺度特征映射、局部极值求取与非线性回归四个步骤实现了对大气散射模型中传输图的估计. Ren等[11]提出了多尺度深度去雾网络(Multi-Scale CNN,MSCNN),使用多尺度神经网络实现了传输图由粗到细的估计. Li等[12]将大气散射模型进行了转化,将大气光值与传输图这两个未知参数合并为了一个未知参数,并设计了一种轻量的具有多尺度融合的一体化网络(All-in-One Network,AOD-Net),对该未知参数进行了估计. Zhang等[13]提出的密集金字塔去雾网络(Densely Connected Pyramid Dehazing Network,DCPDN) 将大气散射模型的公式嵌入到了其所构建的神经网络之中,在网络中分别对大气光值与传输图两个参数进行了估计. 由于在现实中,雾的形成并不是严格符合大气散射模型,所以有一些研究人员脱离物理模型,使用卷积神经网络直接学习有雾图像与无雾图像中的映射关系. Ren等[14]首先对有雾图像分别进行了白平衡操作、对比度增强与伽马变换,得到了三幅增强后的有雾图像,然后使用其所提出的门控融合网络(Gated Fusion Network,GFN)对这三幅图像进行融合,恢复出了最终的去雾图像. Liu等[15]设计了一种基于注意力机制的多尺度神经网络GridDehazeNet,实现了多尺度的特征融合,进一步提升了单幅图像去雾的效果.
目前,基于深度学习的去雾方法在公开数据集上取得了良好的效果,但是仍有一些不足之处. 作为一个低级视觉任务,图像去雾网络除了要对图像中的雾进行去除之外,还需要保留原始图像的色彩与细节等信息. 这就要求网络在设计时综合利用各个尺度的特征信息,使用深层次的特征恢复出无雾图像的主体,并结合底层的特征对图像的细节信息进行丰富. 在对深层次的特征进行提取时,若使用下采样操作,则会在一定程度上丢失图像的特征信息,若不使用下采样操作,则有着较低的特征提取效率与较高的运算复杂度. 如何高效率地进行特征提取与多尺度特征融合是目前需要解决的一个重要问题. 针对这个问题,本文基于注意力机制,提出了一个端到端的单幅图像去雾网络. 该网络使用带有注意力机制的残差密集块(Residual Dense Block with Attention,RDBA)作为模型的基本模块,有效地提升了网络的特征提取能力. 此外,本文基于注意力机制设计了一种自适应跳跃连接(Adaptive Skip Connection,ASC),有侧重地从编码器中提取特征信息以对图像的细节进行补充. RDBA模块与ASC模块的使用,有效提升了网络的恢复能力,使得网络取得了良好的去雾效果.
1 模型框架
1.1 网络的整体结构
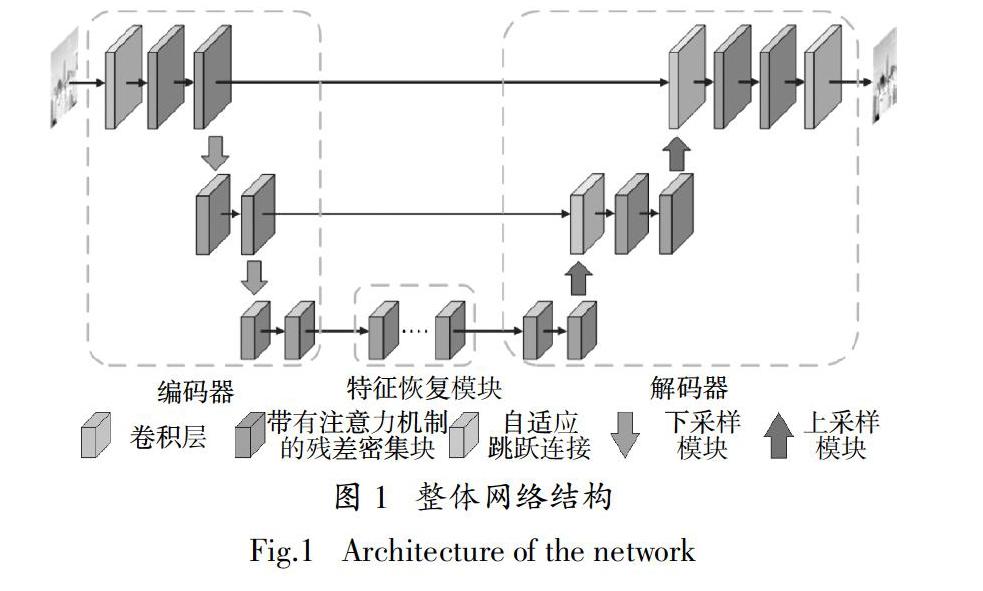
由于编码-解码结构在图像超分辨率[16-17]等低级视觉任务中取得了极大的成功,所以本文采用了U-net[18]这一被广泛使用的编码-解码结构作为了模型的基本框架. 如图1所示,模型由编码器、特征恢复模块与解码器三部分组成. 模型的输入是一张有雾图像,该图像依次经过3个模块,得到最终的去雾图像.
编码器由卷积层、带有注意力机制的残差密集块、下采样模块组成. 残差密集块[19] (Residual Dense Block,RDB)与普通的卷积层相比,在同等参数下具有更复杂的结构和更好的特征提取能力,所以本文使用改进的带有注意力机制的残差密集块作为网络的基本块. 下采样模块的作用是降低特征图的尺寸以增大感受野,同时减少后续计算的复杂度,在本文中,下采样模块是通过卷积核大小为3、步长为2的卷积操作实现的. 特征恢复模块由多个带有注意力机制的残差密集块串联组成,其作用是对编码器得到的特征进行进一步的处理,以便于更好地恢复出无雾图像的内容信息. 在本文中,残差块的数量为9. 解码器与编码器的结构对称,由卷积层、带有注意力机制的残差密集块、上采样模块组成. 上采样模块的作用是在空间上将特征恢复到输入图像的大小,在该模块中,本文首先将输入的特征图进行双线性插值,然后使用卷积核大小为3、步长为1的卷积层对插值后的特征进行进一步转化. 卷积层的作用是从特征图中恢复出无雾的图像,得到网络的输出.
由于高级特征更关注图像的整体风格而不是图像的纹理等内容信息,为了使得模型所恢复的图像具有丰富的细节信息,本文在编码器与解码器之间使用了本文所设计的自适应跳跃连接. 此外,在超分辨率等以峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似性(Structural Similarity Index,SSIM)为主要评价指标的低级视觉任务中,去除批量归一化(Batch Normalization,BN)层[20]已经被证明有助于增强网络的性能和减少计算的复杂度,同时也对生成图像伪影的去除有一定的幫助,因此在本文所提出的网络中,所有的模块都没有使用BN 层.
1.2 通道注意力机制
卷积神经网络的核心在于使用卷积算子对特征图所包含的特征信息进行提取,在这里,将特征图记为F,F∈RC × H × W,其中,H与W分别为特征图的高度与宽度,C为特征图的通道数. 由于特征图的各个通道往往具有不同的重要程度,所以如果平等地对各个通道的特征信息进行利用,难免会造成计算资源的浪费,限制网络的特征表达能力. 因此,本文引入了通道注意力机制[21],有区别地对待特征图中不同通道的特征信息. 通道注意力机制的计算过程表示为:
FA = βF (1)
式中:β为特征图中各个通道的权重,β∈RC × 1 × 1;FA为经过通道注意力操作后,得到的加权后的特征图; 表示元素相乘. 为了通过F得到β,首先对F进行全局池化,然后使用卷积等操作,对β进行求取,该过程可以表示为:
β = σ(Conv(δ(Conv(G)))) (2)
式中:G是对F全局池化得到的结果,G∈RC × 1 × 1;Conv表示卷积操作;δ为ReLu激活函数;σ表示sigmoid激活函数,用来将权重限制到0~1.
1.3 带有注意力机制的残差密集块
残差密集块同时使用了残差连接[22]与密集连接[23]两种网络设计方式,其中,密集连接部分充分使用了各个层级的卷积所提取的特征,有较高的特征提取能力,并且可以防止因网络过深而出现梯度消失的现象. 残差连接使得正向传播的特征得以保留,即每一层的结果都是在之前的结果的基础上得到的,这样的连接方式不仅可以防止网络梯度的消失,还有益于网络的收敛. 本文在残差密集块的基础上增加了注意力机制,在本文中,每个RDBA包括4个卷积核大小为3的卷积层,1个卷积核大小为1 的卷积层与1个通道注意力模块. 如图2 所示,RDBA的前四层卷积层采用了密集连接的方式以获取更多的特征信息,最后一层卷积层将这些特征信息进行融合,融合后的特征通过通道注意力模块对不同的通道进行加权,加权后的特征作为残差与RDBA的输入以对应通道相加的形式进行融合. 和大多数文献一样,本文将密集连接部分的增长率设置为16. 在不同尺度下,RDBA输入的特征图的通道数是不同的,特征图的大小越大,其通道数越少. 在本文中,RDBA在输入图像尺度、1/2输入图像尺度与1/4输入图像尺度下输入输出的特征图的通道数分别为16、32、64.
1.4 自适应跳跃连接
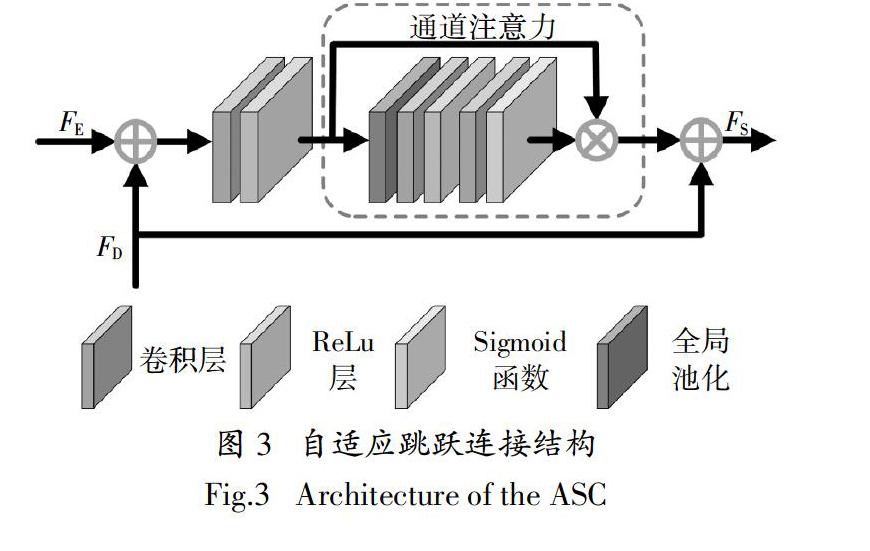
为了获得足够大的感受野,获取更多的上下文信息,编码器中常常使用下采样操作,但是下采样操作常常会带来特征图的细节信息丢失的问题. 在U-net等编码解码结构中,编码器与解码器之间往往采用跳跃连接的方式对解码器中的特征进行增强. 一般来讲,跳跃连接主要有两种形式,一种是将编码器中的特征信息与对应的解码器中的特征信息以通道相加的方式进行融合;另一种是将编码器中的特征信息与对应的解码器中的特征信息进行堆叠,然后使用堆叠的特征进行后续处理. 这两种跳跃连接的方式均起到了细节补充的效果,但是同时也引入了许多的无用信息. 针对这一问题,本文设计了一种自适应跳跃连接方式,如图3所示,该方式主要包括以下4个步骤.
1)特征的初步融合. 将编码器中的特征信息FE与对应的解码器中的特征信息FD以通道相加的方式进行初步融合.
2)特征提取. 使用卷积核大小为3的卷积层对融合后的特征进行提取.
3)通道加权. 使用通道注意力机制对提取的特征各个通道进行加权,进一步提取出有用的特征信息.
4)特征增强. 将通道加权后的特征与步骤1中的解码器中的特征信息FD以通道相加的方式融合,得到增强后的特征FS.
自适应跳跃连接可以有侧重地进行特征融合,使得解码器获取到其所需要的增强信息,取得更好的特征融合效果.
1.5 损失函数
为了得到一个好的模型,需要设计合适的损失函数来衡量模型所预测的结果与训练数据中的真实值的吻合程度. 由于目前图像去雾的评价指标主要为客观评价指标PSNR,所以大多数去雾网络采用均方差(Mean Square Error,MSE)损失或MSE损失与感知损失[24]、生成对抗损失[25]相结合的方式作为模型的损失函数以取得更好的客观评价质量. 为了减少计算量,提升模型的训练速度,本文采用了简单的均方差损失对输出图像的各个像素点进行监督,模型的损失函数为:
LMSE = ‖Ji(x) - Ii(x)‖2
2 (3)
式中:Ji(x)与Ii(x)分别表示去雾图像与真实无雾图像中像素x的第i个颜色通道的像素值;N为单个通道内像素的总个数.
2 实验结果与分析
2.1 实验数据与评价指标
为了与其他的模型进行对比,模型的训练是在公开数据集RESIDE[9]上进行的,该数据集由合成的室内有雾图像集与合成的室外有雾图像集组成. 对于室内图像去雾,本文直接使用了RESIDE中的室内训练集(Indoor Training Set,ITS)作为训练集,该数据集由1 339张原始的图像与13 990张有雾图像组成,有雾图像是由原始图像使用大气散射模型合成的,其中,全局大气光值的取值范围为0.8~1.0,大气散射参数的取值范围为0.04~0.2. 对于室外图像去雾,RESIDE中的室外训练集(Outdoor Training Set,OTS)中有部分原始圖像与测试集的标签是一致的,这些图像可能影响实验结果,不能真实体现模型的性能,所以本文采用了文献[15]对OTS清洗后的数据集进行了训练,该数据集共包含296 695张合成有雾图像与8 447张原始图像. 本文以RESIDE中的合成客观测试集(Synthetic Objective Testing Set,SOTS)为测试集对所提出的模型进行了客观与主观评价,该测试数据共包括500张室内合成图像与500张室外合成图像. 在评价指标的选择上,本文采取了两种最常用的图像客观质量评价指标PSNR与SSIM. 此外,本文还在文献[14]所提供的真实有雾图像上对提出的模型进行了主观评价.
2.2 训练细节
本文方法使用pytorch实现,运行环境为Ubuntu,模型训练是在NVIDIA 1080Ti GPU上完成的. 训练时,对图像以随机裁剪方式进行处理,模型输入的圖像块大小为240×240. 使用批尺寸为24 的ADAM优化器对模型进行训练,其中,动量参数β1与β2分别采用默认值0.9和0.999. 模型的初始学习率为0.001,对于ITS 的训练,进行了100次迭代,每20个迭代学习率衰减为之前的一半;对于OTS 的训练,进行了10次迭代,每2个迭代学习率衰减为之前的一半. 选取了具有代表性的去雾方法进行了对比,包括经典的去雾方法DCP[5]以及基于深度学习去雾方法AOD-Net[12]和GridDehazeNet[15]. 其中,AOD-Net和GridDehazeNet采取了和本文相同的训练方式.
2.3 在合成数据集上的测试结果
从SOTS中选取了4张有雾图像以进行主观质量评价,图4展示了使用上述几种去雾方法所得到的去雾结果,其中,第1行和第2行为室内图像的去雾结果,第3行和第4 行为室外图像的去雾结果. 由图4(b)与图4(f)可以看到,DCP方法所生成的去雾图像相较于真实无雾图像有时会出现色彩的失真(如图4(b)第1幅图像的地板)与边缘的模糊(如图4(b)第1幅图像的标记区域),这是因为该方法的去雾是依赖于其所提出的先验知识的,当先验知识不满足时,该方法便会出现较差的去雾效果. 由图4(c)可以看到,AOD-Net也取得了一定的去雾效果,但是该方法生成的去雾图像在物体的边缘处有时会出现一些明显的伪影(如图4(c)第1幅图像的标记区域). 由图4(d)和图4(e)可以看到,GridDehazeNet和本文提出的方法都取得了相对较好的去雾效果,但是GridDehazeNet所生成的去雾图像有时会出现一些比较小的伪影(如图4(d)第2幅图像的墙面与第3幅图像的路面),而本文所提出的去雾方法所生成的去雾图像在各个方面均比较接近真实的无雾图像.
此外,表1 给出了各方法在SOTS上的客观评价结果. 可以看到,在室内测试集ITS上,本文所提出的方法取得了最高的PSNR值与次高的SSIM值,其中,PSNR值相较于GridDehazeNet有着0.5 dB的提升. 在室外测试集OTS上,本文提出的方法在PSNR与SSIM上均优于其他方法,其中,PSNR值为33.21 dB,比排在第2名的去雾方法高将近2.5 dB.
2.4 在真实数据集上的测试结果
图5展示了各去雾模型在真实数据集中的测试结果. 可以看到,上述几种去雾方法基本完成了去雾任务,最终生成的图像相较于有雾图像有着更高的清晰度,但是各个方法也存在一些不足之处. 由图5(b)可以看到,DCP方法在处理天空等区域时,容易出现颜色的失真. 由图5(c)可以看到,AOD-Net方法所生成的去雾图像有着较低的亮度,并且在物体的边缘处会出现伪影(如图5(c)的第1幅去雾图像的屋顶区域). 由图5(d)可以看到,GridDehazeNet的主要缺点是经常会产生一些小的、暗的伪影(见图5(d)第2幅图像的路面与第3幅图像的标记区域). 相比之下,本文提出的方法在恢复图像清晰度的同时,具有更真实的色彩效果和更少的伪影,但是本网络仍存在去雾不彻底的问题,对于场景中远处的雾以及浓雾不能很好地去除.
2.5 消融研究
本文设计了4个消融实验对所提出模型各个模块的有效性进行验证:1)以RDB为基本模块的网络模型(模型Ⅰ);2)以RDBA为基本模块的网络模型(模型Ⅱ);3)以RDB为基本模块并带有自适应跳跃连接的网络模型(模型Ⅲ);4)以RDBA为基本模块并带有自适应跳跃连接的网络模型(模型Ⅳ). 4种模型在SOTS中室内数据集的表现如表2所示,可以看到,相较于模型Ⅰ,单独使用RDBA模块的模型Ⅱ和单独使用ASC模块的模型Ⅲ在PSNR指标上都有着超过1 dB的提升,在SSIM指标上也有着一定的改进. 综合使用RDBA模块与ASC模块的模型Ⅳ相较于模型Ⅰ则有着更大的提升,在PSNR指标上有着将近2 dB的提升,在SSIM指标上也有着明显的提升. 综上所述,RDBA模块与ASC模块的引入,有效地提升了模型的去雾性能.
3 结 论
本文提出了一种基于注意力机制的多尺度单幅图像去雾网络,该网络不依赖于大气散射模型,可以直接对无雾图像进行预测. 为了充分发挥网络的性能,本文分别设计了RDBA模块和ASC模块,其中,RDBA模块有效提升了网络的特征提取性能,在一定程度上避免了特征信息的冗余;ASC模块的引入实现了解码器中细节信息的针对性补充,在引入少量参数的情况下提升了模型的精度. 实验结果表明,在公开数据集上,本文提出的去雾网络相对于所比较的方法有着更高的客观评价指标与更好的视觉效果. 但是,本文提出的网络也具有一定的局限性,当雾的浓度过大时,本文的模型同样会出现去雾不彻底的问题.
参考文献
[1] 薛亚东,李宜城.基于深度学习的盾构隧道衬砌病害识别方法[J]. 湖南大学学报(自然科学版),2018,45(3):100—109.
XUE Y D,LI Y C. A method of disease recognition for shield tunnel lining based on deep learning[J]. Journal of Hunan University(Natural Sciences),2018,45(3):100—109. (In Chinese)
[2] 夏燁,陈李沐,王君杰,等. 基于SSD的桥梁主动防船撞目标检测方法与应用[J]. 湖南大学学报(自然科学版),2020,47(3):97—105.
XIA Y,CHEN L M,WANG J J,et al.Single shot multibox detector based vessel detection method and application for active anti-collision monitoring[J]. Journal of Hunan University(Natural Sciences),2020,47(3):97—105. (In Chinese)
[3] NARASIMHAN S G,NAYAR S K. Vision and the atmosphere[J]. International Journal of Computer Vision,2002,48(3):233—254.
[4] NARASIMHAN S G,NAYAR S K. Chromatic framework for vision in bad weather[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Hilton Head Island,SC,USA:IEEE,2000:598—605.
[5] HE K M,SUN J,TANG X O. Single image haze removal using dark channel prior[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(12):2341—2353.
[6] ZHU Q S,MAI J M,SHAO L. A fast single image haze removal algorithm using color attenuation prior[J]. IEEE Transactions on Image Processing,2015,24(11):3522—3533.
[7] TAN R T. Visibility in bad weather from a single image[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Anchorage,AK,USA:IEEE,2008:1—8.
[8] BERMAN D,TREIBITZ T,AVIDAN S. Non-local image dehazing [C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,NV,USA:IEEE,2016:1674—1682.
[9] LI B Y,REN W Q,FU D P,et al. Benchmarking single-image dehazing and beyond[J]. IEEE Transactions on Image Processing,2019,28(1):492—505.
[10] CAI B L,XU X M,JIA K,et al. DehazeNet:an end-to-end system for single image haze removal[J]. IEEE Transactions on Image Processing,2016,25(11):5187—5198.
[11] REN W Q,LIU S,ZHANG H,et al. Single image dehazing via multi-scale convolutional neural networks[C]// Proceedings of 2016 European Conference on Computer Vision. Amsterdam,The Netherlands:Springer,2016:154—169.
[12] LI B Y,PENG X L,WANG Z Y,et al. AOD-Net:all-in-one dehazing network[C]// Proceedings of 2017 IEEE International Conference on Computer Vision. Venice,Italy:IEEE,2017:4780—4788.
[13] ZHANG H,PATEL V M. Densely connected pyramid dehazing network[C]// Proceedings of 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA:IEEE,2018:3194—3203.
[14] REN W Q,MA L,ZHANG J W,et al. Gated fusion network for single image dehazing[C]//Proceedings of 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA:IEEE,2018:3253—3261.
[15] LIU X H,MA Y R,SHI Z H,et al. GridDehazeNet:attention-based multi-scale network for image dehazing [C]//Proceedings of IEEE International Conference on Computer Vision. Seoul,Korea (South):IEEE,2019:7313—7322.
[16] LIM B,SON S,KIM H,et al. Enhanced deep residual networks for single image super-resolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu,HI,USA:IEEE,2017:1132—1140.
[17] WANG X T,YU K,WU S X,et al. Esrgan:enhanced super-resolution generative adversarial networks [C]//Proceedings of 2018 European Conference on Computer Vision Workshops. Munich,Germany:Springer,2018:63—79.
[18] RONNEBERGER O,FISCHER P,BROX T. U-net:Convolutional networks for biomedical image segmentation[C]//Proceedings of International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich,Germany:Springer,2015:234—241.
[19] ZHANG Y L,TIAN Y P,KONG Y,et al. Residual dense network for image super-resolution[C]//Proceedings of 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA:IEEE,2018:472—481.
[20] IOFFE S,SZEGEDY C. Batch normalization:accelerating deep network training by reducing internal covariate shift [C]//Proceedings of IEEE International Conference Machine Learning. Lille,France:IMLS,2015:1—11.
[21] HU J,SHEN L,ALBANIE S,et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011—2023.
[22] HE K M,ZHANG X Y,REN S Q,et al. Deep residual learning for image recognition[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,NV,USA:IEEE,2016:770—778.
[23] HUANG G,LIU Z,VAN DER MAATEN L,et al. Densely connected convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI,USA:IEEE,2017:2261—2269.
[24] JOHNSON J,ALAHI A,LI F F. Perceptual losses for real-time style transfer and super-resolution[C]//Proceedings of 2016 European Conference on Computer Vision. Amsterdam,The Netherlands:Springer,2016:694—711.
[25] GOODFELLOW I J,POUGET-ABADIE J,MIRZA M,et al. Generative adversarial nets [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge:MIT Press,2014:2672—2680.
