大数据背景python 在网络爬虫框架中的应用
2021-07-30吴道君
吴道君
(广东岭南职业技术学院,广东 广州 510663)
在计算机网络技术的不断发展下,海量数据不断涌现,给人们的生活和工作造成了很大的不便,此时,人们要想从海量数据中找到有价值的信息数据,必须要频繁手动操作,才能找到需要的信息数据,而python 网络爬虫框架的设计和使用的出现和应用可以很好地解决这一问题,不仅模仿人的手动操作行为,快速查找数据,还能缩短信息搜索时间,为进一步提高人们的查找信息数据的效率和效果打下坚实的基础。因此,在大数据时代背景下,如何将python 科学应用于网络爬虫框架中是相关人员必须思考和解决的问题。
1 利用python 实现网络爬虫框架的相关技术
1.1 网络爬虫概念
网络爬虫作为一种常用的脚本,在具体的运用中,需要按照一定的规则,完成对互联网信息的智能化抓取,因此,网络爬虫被广泛地应用于互联网搜索引擎中,为帮助用户快速获取最新网站内容产生积极的影响。此外,通过利用网络爬虫,一旦识别到用户需要访问的页面内容,系统可以自动向服务器发送页面请求,从而将相应的页面内容呈现在用户面前,为提高网站搜索引擎处理效率和效果,满足用户的使用需求创造良好的条件。
1.2 网络爬虫使用Python 编写的优点
通过使用python 语言,编写网络爬虫具有以下优势:(1)python 语言简单易学,降低了开发难度,省略了IDE 的使用,极大地提高了开发效率和效果。(2)仅仅使用文本编辑器,就可以完成对多种中小型应用的设计和开发,同时,还能借助网络爬虫框架,实现对网站信息数据的深入分析、挖掘和存储,以达到科学处理相关信息数据的目的。(3)python 语言含有功能强大的HTML 解析器和网络支持库,通过利用HTML 解析器,可以实现对各个网页标签内容的快速解析,便于用户高效、快捷地抓取网页内容;通过借助网络支持库,可以编写较少的代码实现对相关应用程序的开发。
1.3 网页爬取策略
待抓取URL 队列作为网络爬虫框架的重要组成部分,URL 排列顺序是否合理直接影响了网页抓手顺序,而网络爬取策略的应用可以科学地确定URL 排列顺序。网络爬取策略主要包含以下三种类型:(1)深度优先排序。该排序方式在具体的运用中,需要从根节点入手,实现对叶子节点的快速寻找。在处理网页期间,通过选择合适的超链接,可以实现对网页内容的深度优先搜索。(2)最佳优先排序。该排序方式在具体的运用中,需要精确计算URL 描述文本、主题相关性以及网页相似度,并对最终的计算结果进行抓取。(3)广度优先排序。该排序方式在具体的运用中,同样需要从根节点入手,采用逐一遍历的方式,对当前层次网页内容进行全面搜索,为下一层次网页内容的高效搜索提供重要的依据和参考。
2 大数据背景python 在网络爬虫框架中的应用案例
2.1 网络爬虫框架设计
2.1.1 模型分析
模型分析作为网络爬虫框架设计的首要环节,其分析效果直接影响了网络爬虫框架的设计水平,因此,相关人员要做好对模型的科学分析。首先,要构建URL 任务列表,获取合适的爬取URL 地址,同时,当URL 任务列表构建完成后,还要针对深度爬取网页预先设定的内容,对各个网页进行抓取处理,然后,从各个页面中获取新的URL 地址,并对这些地址存放是队列中,当符合终止条件时,可以对URL 重复情况进行判断和分析,在此基础上,根据已经设定好的微博内容,完成对各个页面的精确搜索,然后,科学、全面分析页面,并从各个页面信息中提取和整理用户需要的URL 地址,最后,将所获得的URL 地址返回到指定的任务列表中,为实现重新爬取,提高网络爬虫运行效率和效果打下坚实的基础。
2.1.2 总体框架设计
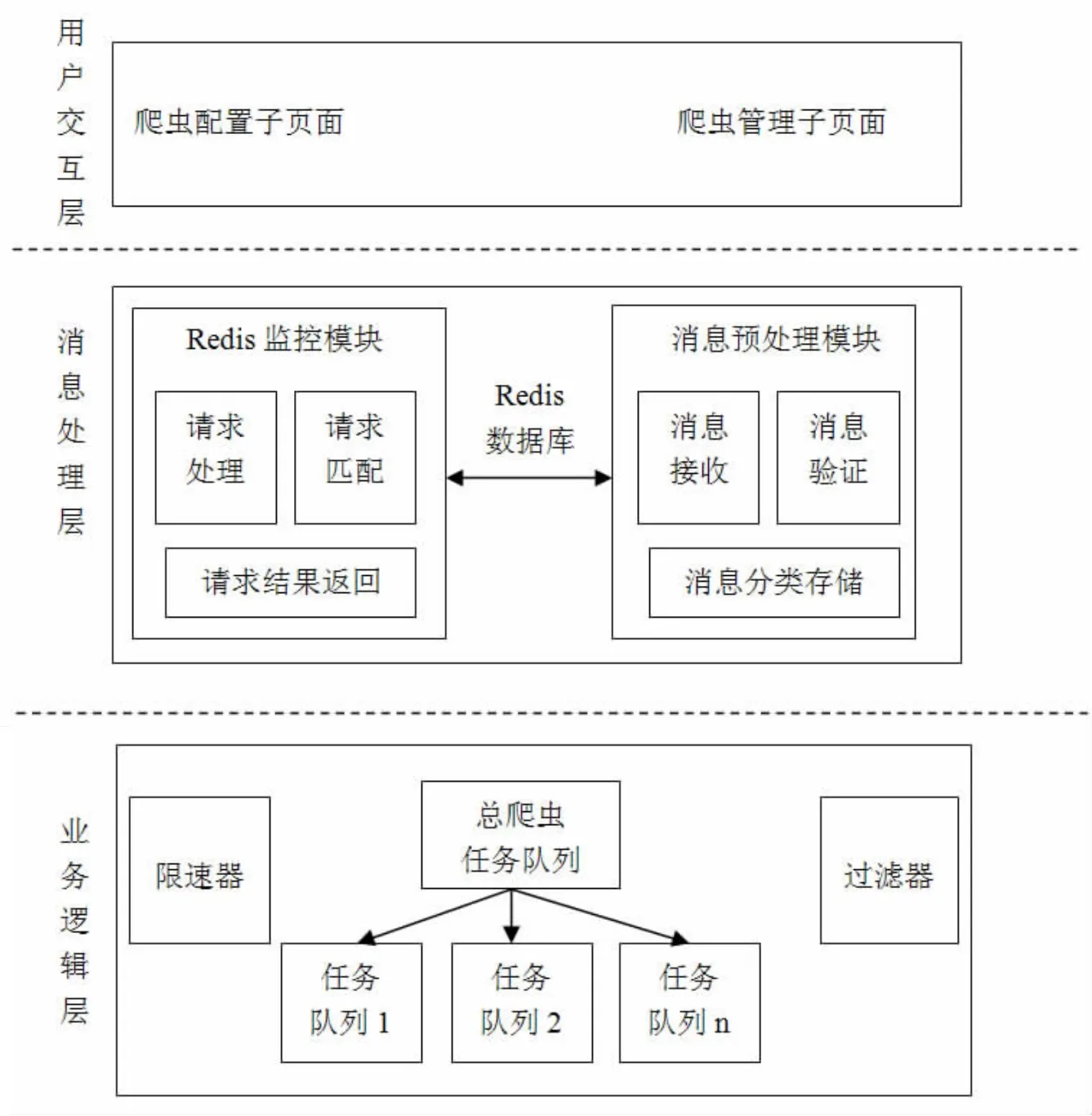
图1 网络爬虫框架设计示意图
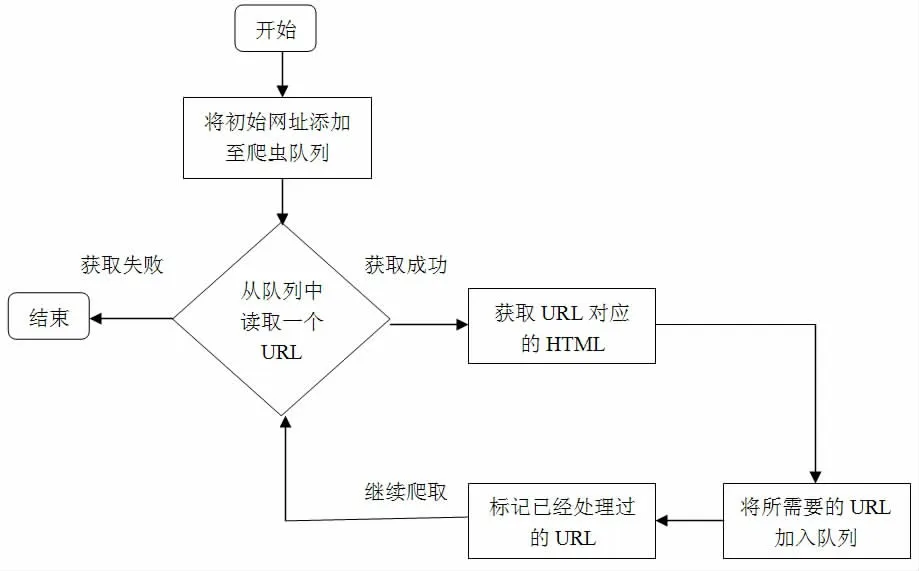
图2 爬虫程序流程图
网络爬虫框架设计示意图如图1 所示。从图中可以看出,该框架主要包含以下三个层次:(1)用户交互层。用户交互层主要由两个子页面组成,一个是爬虫配置子页面,另一个是爬虫管理子页面,通过应用这两个页面,可以提高用户交互效果。其中,爬虫配置子页面主要负责对用户所提交请求的接收和处理,为保证后期消息预处理模块的科学解析打下坚实的基础。此外,在整个集群中,爬虫启动操作或者暂停操作[1],均可以借助爬虫管理子页面,实现对各个节点上爬虫的实时监控。(2)消息处理层。消息处理层主用负责对页面所传递请求消息的验证和处理,实现对海量信息数据的高效处理,以达到有效满足大规模业务需求,系统内部缓存器在具体的设计中,主要使用了Kafka.为保证数据流处理性能,缩短数据流处理时间打下坚实的基础。(3)业务逻辑层。业务逻辑层作为整个系统的核心和关键,主要由若干个节点构成。各种爬虫节点采用任务调度的方式,实现对各个结构的统一管理,提高了任务调度的效率和效果[2],为实时检测和掌握爬虫节点运行状态,取得最佳调度效果创造良好的条件。主节点所执行的爬虫任务队列主要包含以下两种:一种是总爬虫,另一种是节点。其中,总爬虫主要负责对页面请求消息以及爬虫新抓取任务的集中存储,使其安全、可靠地存储于任务队列中;各爬虫节点主要负责对待抓取爬虫任务的存放。对于待抓取爬虫而言,所选用的存放位置主要以内存型数据库为主[3],为实现对爬虫任务的快速获取和提交发挥出重要作用。
2.1.3 程序流程设计
对于网络爬虫框架而言,在python 的应用背景下,需要加强对爬虫程序流程的科学设计,为开发出一款功能强大、实用性强的网络爬虫系统打下坚实的基础。爬虫程序流程图如图2所示。
2.2 网络爬虫框架实现
为了将python 科学应用于网络爬虫框架中,保证网络爬虫框架实现效果[4],相关人员要除了要做好对目标网站URL 的设置外,还要重视对爬取模块、伪装time 模块、数据处理模块的实现,为保证用户搜索信息的高效性,满足用户查询有效信息的需求产生积极的影响。
2.2.1 目标网站URL
网页端新浪微博所选用的反爬虫手段比较先进,为了降低爬虫手段的实施难度,需要将目标网站地址设置为:https://m.weibo.cn/。此外,为了确保用户在最短时间内快速查找到有价值的信息,相关人员需要将目标网站URL 设置为程序读取内容,只有这样,才能充分发挥和利用python 优势,降低网络爬虫框架开发难度,为准确、高效地抓取信息打下坚实的基础,最后,还要将制定的网站URL 更改为微博ID 爬取地址,以满足抓取微博评论信息的需求。
2.2.2 爬取模块
爬取模块作为网络爬虫框架的核心模块,在具体的开发和实现中,需要借助python 语言,采用urllib 编写的方式,利用HTTP 库开发模式,完成对简洁页面的开发[5],以达到缩小开发时间的目的。此外,该模块在整个开发过程中,需要用到两种请求方式:一种是get 请求方式,另一种是post 请求方式,其中,get请求方式主要负责将用户访问请求传递给用户需要访问的微博URL 地址中;post 请求方式主要负责将post 请求发送给HTML 页面。
2.2.3 伪装time 模块
伪装time 模块在具体的开发和实现中,为了实现对网站信息的保护,需要借助网站的爬虫功能,采用IP 封禁的方式,将爬虫程序进行封禁处理,同时,还要将所有访问地址伪装设置为浏览器形式,便于用户数的操作,此外,还要加强对时间限制方式的设置,以确保用户能够快速、精确地访问需要的爬取数据网站,避免系统因抓取程序[6],出现屏蔽IP 现象。伪装time 模块在传递响应参数期间,重点使用了time·sleep()方法。对于网络爬虫框架而言,其伪装time 模块功能主要是根据用户的使用需求,对爬虫程序访问相关参数进行设置,以达到科学控制和调整访问网站时间间隔的目的。最后,还要通过全面提取和整理微博评论详细时间,为后期优化微博功能提供重要的依据和参考。
2.2.4 数据处理模块
数据处理模块主要借助python 语言,对数据进行导入、整理处理,为实现对数据深入分析和挖掘,保证数据的处理效果打下坚实的基础。此外,在python 语言的应用背景下,相关人员好药采用构建numpt 数组的方式,不断优化和完善数据预处理、数据分析和解析过程,为进一步提高数据处理产生积极的影响产生积极的影响。此外,通过利用python 语言,可以时对处理表格、以及重要数据的科学设计[7],为实现对数组数据的统一化处理发挥出重要作用,例如:在对新浪微博评论进行设计期间,需要借助numpy,完成对多种类型数据的处理,pandas 数组主要包含以下三种类型,分别是以为数组、二维数组和三维数组。其中一维数组和二维数组使用范围相对比较广泛,一维数组作为一种常用的数组,携带大量的标签,将整数、浮点数、字符串等所有数据类型包含在内,一维数组采用标签定位的方式,可以实现对多种数据类型的查找和利用[8]。二维数组作为一种常用的二维数据结构,内部含有大量的标签,为完成对各种数据类型的定位,保证网络爬虫框架实现效果提供有力的保障
结束语
综上所述,在大数据时代背景下,通过将python 应用于网络爬虫框架中,不仅可以快速提取多种类型的信息数据,还能有效地分析和挖掘大量的有价值的信息数据,为人们查找有用信息数据提供极大的便利。此外,python 语言适用范围广,功能多样强大,为多种类型的软件工具包提供重要的技术支持。另外,python 语言还可以快速提取Web 信息数据,很好地满足了人们高效搜索信息数据的需求。
