基于卷积核初始设置的卷积神经网络表格识别研究
2021-07-24梅旭恒马嘉辉陈志轩邓一星杨荣领
梅旭恒,马嘉辉,陈志轩,邓一星,杨荣领
(华南理工大学广州学院,广东 广州 510800)
0 引言
近年来,基于卷积神经网络深度学习中的强大的特征提取能力和泛化能力,在图像识别与分类、目标检测、图像文本及图表的识别与分类、语义分割与自然语言处理、场景分类、人脸识别、音频检索、医疗诊断诸多领域等众多领域都得到了广泛地应用。然而,由于深度卷积神经网络普遍规模庞大、计算度复杂,限制了其在实时要求高和资源受限环境下的应用。因此,对卷积神经网络的计算过程进行优化,提高其计算效果有助于深度学习在更广泛的领域应用,已成为深度学习社区的一个新的研究热点。卷积神经网络深度学习的优化可以分为计算结构的优化、激活函数优化和卷积核初始参数优化等三大类型。目前大多数的优化集中在计算结构的优化[1],针对卷积核初始参数优化研究比较少。然而卷积的过程可以看成是卷积核的图像模式与被分类图像的图像模式的匹配滤波的过程。对于特定的图像识别或分类来说,如果卷积核能表征待分类图像特有的局部几何特性,则这些几何特性就更容易被检测出来。因此在CNN神经网络训练中,卷积核初始化是非常重要的。
卷积神经网络在图像识别领域有着重要地位。卷积神经网络的网络鲁棒性取决于网络的层数,激活函数的选择,权重初始化等因素。在权重初始化方面,近年来人们更多的是使用正态分布初始化(μ=0,σ2= 0 .01),正态分布初始化的优点是适用于大部分图像场景,能够很好地解决网络参数传播的梯度问题。正态分布初始化的方法有许多,目前,该领域中具有代表性的是Xavier[2]初始化和何凯明等[3]提出的针对 Relu激活函数的初始化,在实际场景中具有良好的应用效果。正态分布初始化的好处是可以较好地适应各类训练数据,但容易导致梯度传播的问题,如梯度消失或梯度爆炸,会降低训练速度。
在卷积神经网络中,权重参数与训练样本的关联程度越大,卷积运算的结果输出就越大,该卷积核对于样本的特征提取效果越显著。2019年4月,朱继洪等[4]提出从训练样本中通过局部模式聚类的方法提取卷积核,该方法对通过训练样本得出的卷积核进行筛选,挑选出动态范围和信息熵较大的卷积核作为权重初始值,加速了网络训练初期的收敛速度,对最终网络的识别精度有所提高。
在此之前,对于卷积神经网络的卷积核权重初始化一直是采用随机值。不论是用不同的分布产生的随机数,还是通过自身卷积神经网络训练出来的权重值进行初始化,都缺少了可解释性,在生成的许多卷积核当中,存在着对特征提取贡献较低的无用卷积核。另一方面,卷积核的数量越多,模型计算成本就会大幅提高。若通过卷积神经网络训练卷积核权重值再进行权重初始化,还需要进行二次训练,从经济成本和时间成本的角度而言,都存在着不足之处。
由此带来了两个问题:(1)卷积核初始参数的优化是否能够提高卷积神经网络深度学习的效率与精度?(2)如果卷积核初始参数优化有效,则卷积核初始参数优化的指导原则是什么?针对以上两个问题,本文以图像表格的识别与分类作为实验场景,基于卷积的本质基础,根据大部分表格表单的共有特征,自定义设计卷积核的权值参数,使得网络训练处理能够大概率接近收敛域,引导网络训练更接近全局最优,在减少训练成本的情况下,分类精度仍然较高。
1 表格识别的卷积核初始化方法
二维卷积公式为:
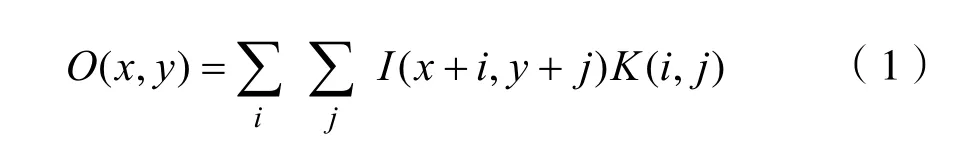
由此可见,卷积中的特征提取过程实质上是匹配滤波的过程。因此,在CNN网络训练中卷积核初始值矩阵与样本特征关联越大,输出就越强,特征提取的效果就越好。在许多场景下,卷积神经网络用于无监督学习过程,样本特征本身是未知的。因此,卷积核初始值采用正态分布初始化可以适用于大部分图像场景,并能够很好地解决网络参数传播的梯度问题。另一方面,在某种特定场合下,其样本特征也是可知的,例如表格识别情形。针对表格样本本身的特征显而易见的特点,基于卷积核初始值与训练样本特征越相似,输出就越强,特征提取的效果就越好的思想,本文提出了一种简化的卷积核初始值的设置方法。其步骤如为:
Step.1确定特征子图片。根据已知的样本特征,选取能够代表该特征的子图片。例如,再表格情形下,可以选取如图1所示的9张子图片来代表表格的9个显著特征。
Step.2划分子图片网格。根据既定的卷积核大小和网格的分布,将选取的子图片按照卷积核网格分布划分网格。
Step.3计算网格指标值。指标值是指能反映图像特征的数值。在图像情况下,通常选择像素点的RGB值来表达。如果不需要考虑色彩,也可以采取像素点的灰度。或者在黑白两色情况下,也可以采用0代表白色,1代表黑色,例如,表格。
Step.4计算网格指标值比例。指标值比例是网格内指标值总和与卷积核内指标值总和之比。
Step.5计算相邻网格的影响。基于相邻网格的特征会对目标网格有一定的扩散影响,指标值应该考虑相邻网格的指标值因扩散而来的影响值。根据实验经验,这个影响值与距离的平方成反比。
Step.6最后在卷积核内对所有网格指标值(包括本地指标值和扩散进来的指标值之和)进行 Z值标准化处理。由此获得的卷积核的标准指标值就是卷积核的初始值。
2 实验设计
2.1 实验场景
为了验证卷积核初始参数的优化对提高卷积神经网络深度学习的效率与精度的效果,本文选择了表格图像作为研究对象。卷积神经网络深度学习的目的是有效地识别表格特征,进而准确地对表格图像进行分类。对于表格表单样本,特征比较简单,李海涛等[4]提出表格普遍存在的特征主要有9种类型(如图1)。在设计卷积核时,为减少网络计算量,采用9个与表格特征相对应的卷积核进行实验。
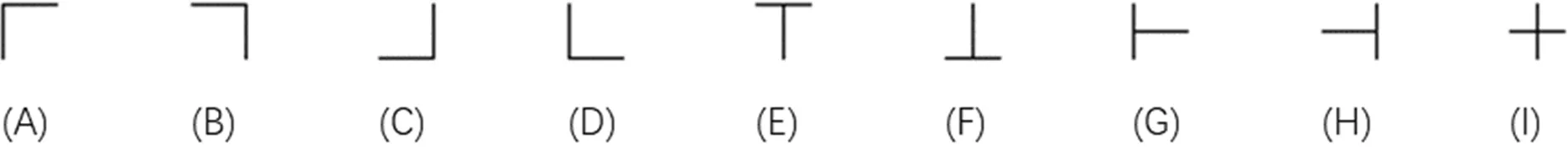
图1 表格的9种基本元素类型Fig.1 The nine basic element types of a table
2.2 卷积核参数的初始化
根据前文的确定卷积核初始值的步骤,对图1中的表格的9种基本元素类型,分别设计了3×3大小的卷积核参数,并进一步验证了其提取效果,如图2所示。
2.3 神经网络结构设计
神经网络的设计如图3,一层输入层(input),一层卷积层(conv1),一层池化层(pooling1),全连接层 1(fc1)、全连接层 2(fc2),输出层(output)。
在conv1层,仅采用9个3×3大小的卷积核来进行表格特征提取,激活函数选择了 Relu函数,在式(2)中可知,Relu在对提取特征的时候可以避免提取负值,即保留相应的特征,消极特征值不保留,在网络前向传播时可以保持网络的一些输出为0,使得网络变得稀疏,更具有鲁棒性。

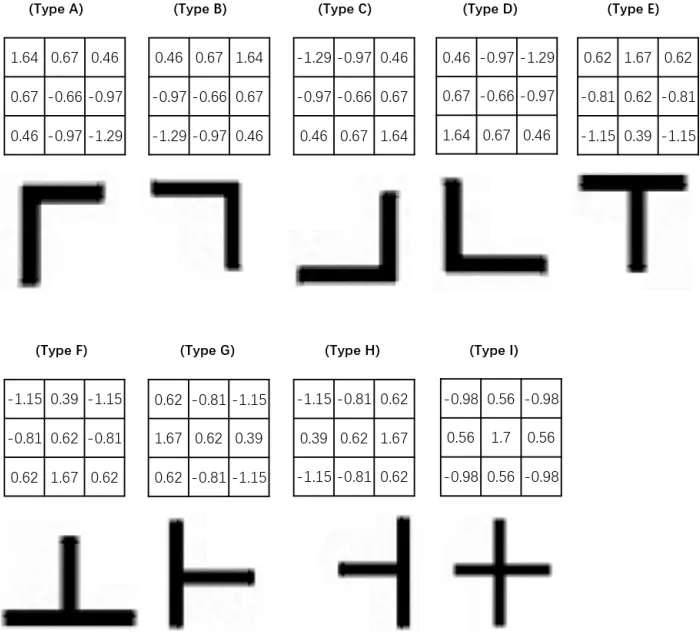
图2 对9种基本表格特征的卷积核权重值和提取效果Fig.2 The weight and extraction effect of convolution kernel for 9 basic table features
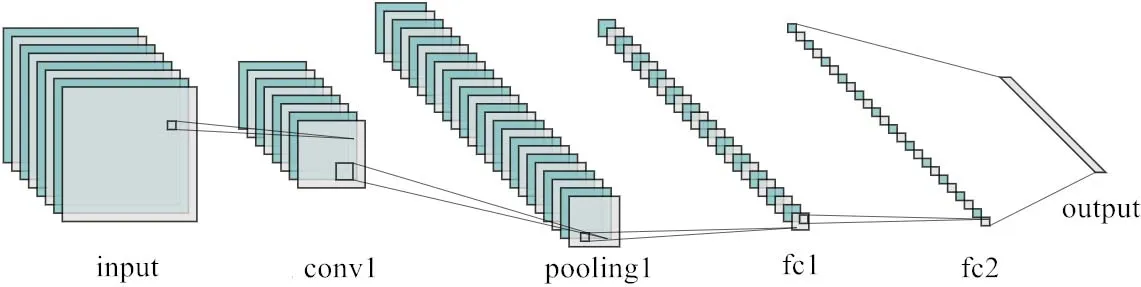
图3 神经网络结构Fig.3 Neural network structure
在 pooling1层采用 2×2大小的 max-pooling方法来进行最大池化采样,网络参数传播复杂度和计算量可以成指数级减少,同时可以很大程度保留特征。在fc1层把网络降到了1 024×1的维度,再用fc2层连接输出层。
网络模型的参数如表 1,为了使模型能够更接近梯度最优解,梯度学习率选择了0.001,epoch只选择了 20次,每一个 epoch的批处理大小为128张。

表1 网络模型参数Tab.1 Ne twork model parameters
3 实验结果分析
3.1 实验数据
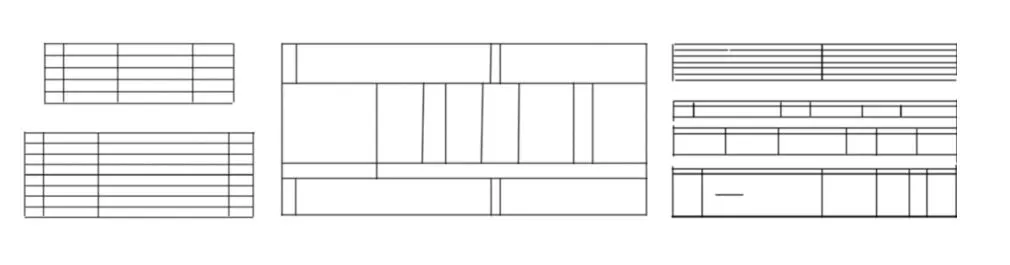
图4 实验数据样本Fig.4 Experimental data sample
实验通过收集各种不同类型的表单,如增值税发票,货运单,快递单等,首先对图片分别进行横竖线的提取,分别将同一张图片提取的横线图片和竖线图片进行合成,形成一张仅有表格线框的表格线框图。最后把经过处理的数据进行平移、缩放和对图片加入噪声等方式对数据集进行数据增强,最终形成约2万张表单线框数据,其中采用1 000张数据作为验证集。
3.2 结果分析
实验通过训练不同类型的表格数据样本,对卷积神经网络中卷积层的第一层卷积核参数分别使用了Normal_init、Xavier_init和根据特征像素分布进行初始化进行对比实验并统计平均值。
从表 2中可以知道,根据表格表单的线框特征初始化卷积核进行训练,准确率相对于μ=0,σ2=0.01的正态分布初始化和Xavier初始化有显著的提升,同时计算出来的平均损失值也较小,这说明该卷积核初始化的方式对表格现况特征提取效果更具有针对性。由于卷积与滤波的相像,在训练的迭代次数中,只要根据特征关联初始化,在前期的迭代中就会有较高的准确率,而在后面的迭代中差距减小,但总体上仍具有较高的分类精度。
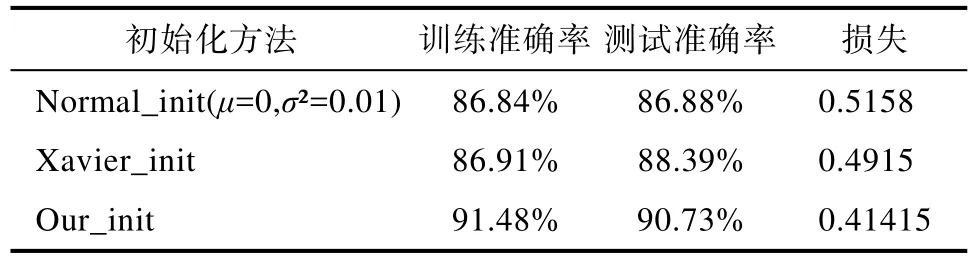
表2 三种初始化方法下的训练准确率、测试准确率和损失对比Tab.2 Training accuracy, test accuracy and loss comparison under three initialization methods
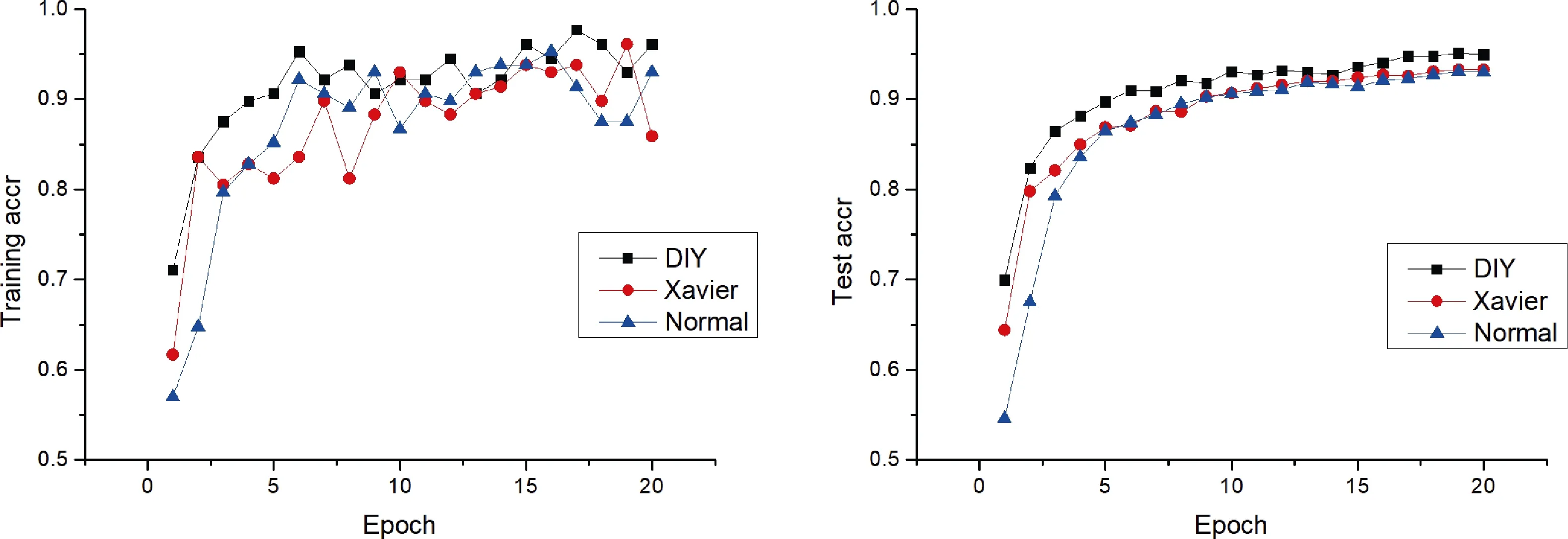
图5 三种初始化方法训练和测试准确率曲线Fig.5 The train and test accuracy curve for three initialization
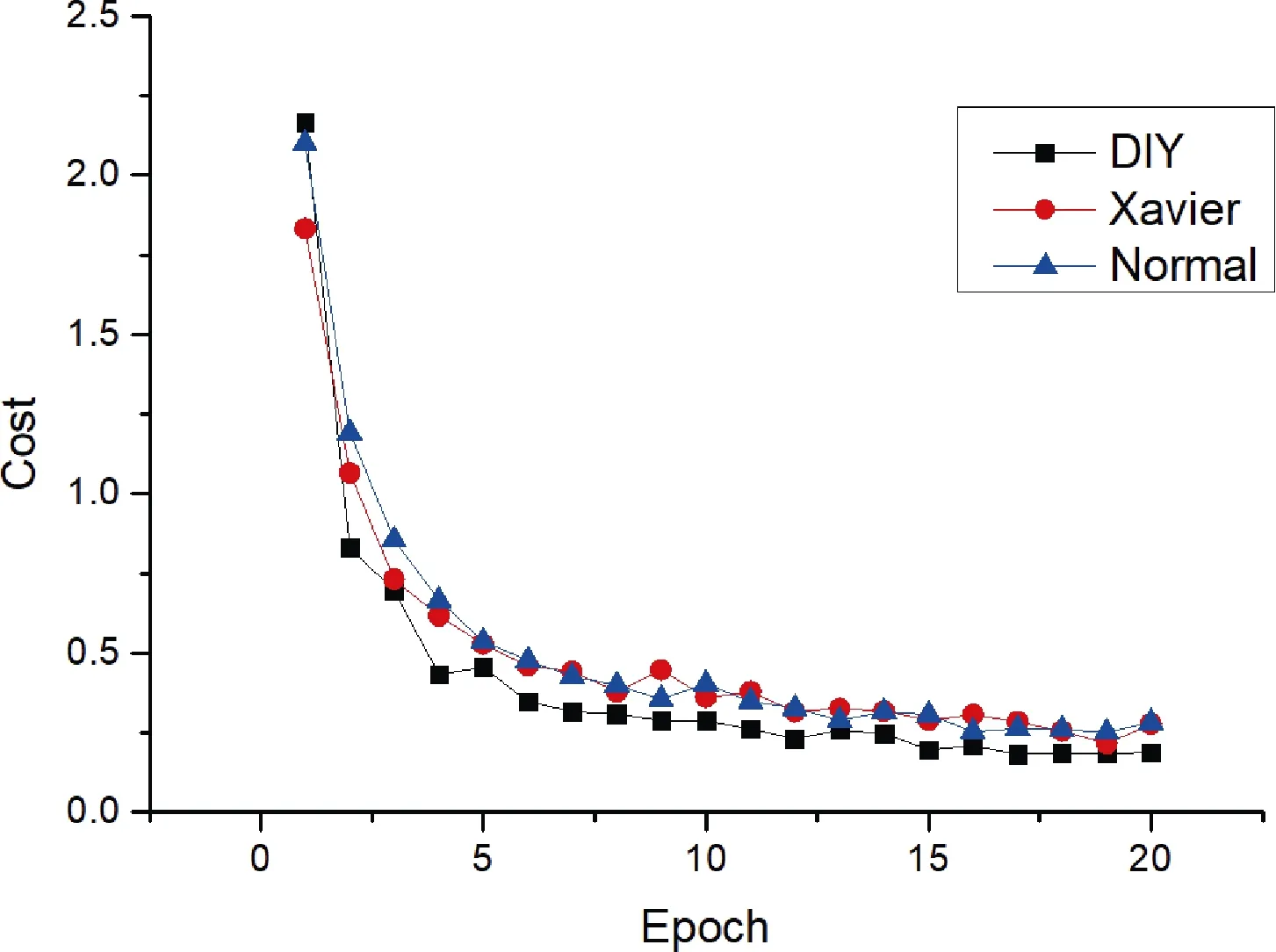
图6 三种初始化方法损失曲线Fig.6 The loss curve for three initialization
通过训练准确率曲线可知,在训练开始迭代初期,DIY初始化保持较高的识别水平,在几次迭代之后,训练准确率略有波动,相对于 Xavier初始化和Normal初始化来说较稳定,整体呈现上升趋势。
为了验证三种不同的初始化方法对于表格分类的能力,在测试模型当中,把提取好表格线框的1 000张测试数据输入模型进行批量验证,在初期优势体现明显,验证分类的正确率可达到约70%,远高于Xavier初始化(约60%)和Normal初始化(约30%)的分类精度,在分类验证完成后,验证分类的准确率仍略高于Xavier初始化和Normal初始化约1%。
在计算损失曲线时采用了交叉熵作为损失进行最小化,在第一步计算交叉熵的时候,计算出的损失在三者中位于最高,经过几次迭代后计算,损失明显降低,在之后的整个迭代过程中的损失都小于其他两者,说明预测值与真实值较其他两种初始化来说更接近。
4 结语
本文针对卷积核初始设计对卷积神经网络深度学习的优化效果进行了实验研究,提出了根据图像局部特征分布对卷积核参数进行初始化,把各种特征对应的卷积核进行组合的初始参数的优化方法,并制定了卷积核初始参数的基本原则。通过以图像表格的识别与分类作为实验场景的实验验证,认为卷积核组成的局部特征模式的网络,在训练过程可明显提高图像样本典型特征的提取质量。实验中,还根据设计原则指定的卷积核初始参数与传统的Normal、Xavier等初始化方法进行了比较。实验结果表明,在同一实验条件下,本文的方法在网络训练初期收敛速度明显更快,引导了网络的优化方向,并且分类精度也有一定程度的提高。在神经网络模型中,这一方式能够加速模型针对表格特征的学习,在迭代次数较少的情况下,准确率也保持较高的水平。尽管本文的验证实验是针对表格图像的处理,但是制定卷积核初始参数的基本原则及其对卷积神经网络深度学习的优化提供了一种新的思路,值得在今后的图像识别与分类研究中借鉴。
