新浪微博社交网络用户影响传播预测方法
2021-07-24黄维,王梅
黄 维,王 梅
(东华大学,上海 201620)
0 引言
随着互联网行业的快速发展与普及,在线社交网络也得到了快速的发展,例如新浪微博、Twitter、Facebook等,在线社交网络也成为了信息传播和人与人之间相互影响的主要途径。对用户间影响关系和用户影响的传播进行估计,具有广泛的应用,如商品营销[1]、广告投放策略[2]、事件发展预测[3]、谣言检测[4]等均利用了社交网络中用户的相互影响。因此,对该问题的研究具有重要意义。
新浪微博作为目前国内最大的微型博客社交平台,其注册用户接近四亿,活跃用户超过一亿。用户可以通过发布微博等方式来分享信息,其它用户也可以通过评论转发等方式来对信息做出反馈。即用户通过微博的形式来对其它用户产生影响,其它的用户通过评论和转发的形式对其影响进行扩散。基于此,在新浪微博中可以很方便的获得用户与用户之间的直接的影响记录,从而能够比较准确的建立起用户之间的影响关系。
本文基于新浪微博下社交网络的特点,提出一种用户影响传播预测学习方法。该方法包括数据预处理、影响概率计算、影响力传播三个主要模块。数据预处理模块首先对评论数据丢失的问题进行处理,影响概率计算模块使用评论和转发数据作为输入来学习用户的表征,并在此基础上学习用户与用户之间的影响概率。影响传播模块通过传播动力学过程模拟了社交网络中的影响扩散过程,最终输出初始活跃用户影响的用户,其数量标示了初始活跃用户的影响力。在新浪微博实际数据集上的实验结果表明,本文对用户影响传播预测的效果,相比较传统 DTIC-Jaccard[5]、DTIC-Credit[5]方法,其F1值分别提升了26.7%和51.4%。
1 相关研究
由于社交媒体用户数量的不断增长以及社交媒体为影响传播提供的便利,社交网络中的影响关系成为研究的热点。基于用户之间的影响关系,可以对社交网络中的影响力扩散进行建模。对影响关系的研究主要有两类:统计方法和嵌入方法。统计方法利用传统的统计学方法直接进行影响关系的计算,得到用户与用户之间的影响概率。嵌入方法通过相应的算法来学习得到用户的表征向量,从而通过用户的表征向量来学习到用户之间的影响概率。
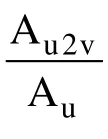
嵌入方法。受自然语言领域的单词嵌入方法的启发[7],人们对网络嵌入进行了一些研究,将网络中用户嵌入到一个连续的潜在空间中,并根据潜在空间中的相对距离推断用户关系。Grover[8]提出“node2vec”算法,使用一个参数来平衡随机游走的策略,通过该方法可以探索给定区域的不同邻域节点。Feng[9]利用网络结构和传播事件来学习网络嵌入,通过网络表征来界定社会影响。然而,这些学习方法依赖于网络结构,在大多数情况下,网络结构是动态变化的。Bourigault[10]首先提出只从扩散事件中学习了网络嵌入,即无网络结构模型。在他们的研究中,他们模拟了像热扩散一样的影响扩散。然后他们将模型[10]扩展到另一个基于级联过程的模型[11]。但是由于 EM算法的消耗,这个模型的可伸缩性受到影响。
相比于统计方法,嵌入方法有普遍有两个好处:1)参数量少。每个用户用一个稠密的向量来表示,相对于维持一个n×n的二维用户矩阵来说,参数量大大减少。2)发现新关系。嵌入方法可以找到没有直接交互的,但可能存在影响关系的用户。3)嵌入方法不容易出现过拟合的现象。因此,本文的模型是基于网络嵌入的思想提出的。
2 本文方法
2.1 相关定义
本文将微博下的用户社交网络图定义为 G =(V, E, P),其中,V为社交网络中的用户集合,E为社交网络中的边集合,P为用户间的影响概率(也称为用户间影响关系或社交网络边的权重)。一条有向边(u, v)∊E代表用户u对v有影响概率p(u, v)∊P。V集合中用户所发布的微博集合记为M。具体地,用户 u∊V发布的微博记为 M(u)。对于每个微博 m∊M,其转发列表和评论列表分别记为 R(m)和 C(m),分别记录了转发和评论该微博的用户。在新浪微博的数据集中,转发列表记录了全部的转发用户,而评论列表由于数据限制,只记录了部分评论用户。
基于上述定义,本文影响传播学习的基本思想是给定一个用户 u和一个用户 v,如果用户 u发布了一条信息(微博),用户v转发或评论了这条信息(微博),认为用户u影响了用户v。一旦用户被影响,他将成为活跃用户。影响传播过程是基于独立级联模型的,在独立级联模型,用迭代的过程去模拟影响力传播。
2.2 框架介绍
本文针对微博平台下的社交网络形式提出Inf-embedding模型,其中包括数据预处理、影响概率计算、影响力传播三个部分。图1展示了整体的模型框架。一共分为三个部分。在第一部分(数据预处理)中,该模型首先处理了评论数据丢失的问题,并利用最大似然估计将丢失的数据处理成一种可以在后面使用的形式。在第二部分(影响概率计算)中,构建相应算法使用评论和转发数据作为输入来学习用户的表征。在对用户进行特征化之后,进一步构建社交网络,也就是学习到用户与用户之间的影响概率。在第三部分(影响传播)中,通过传播动力学过程模拟了社交网络中的影响扩散过程,最终输出初始活跃用户影响的用户。在下面的每个小节中,将详细描述本文模型的每一部分的具体细节。

图1 模型框架Fig.1 Model framework
2.3 数据预处理
由于微博平台的限制,微博下的社交网络数据是存在缺失的,所以将根据后面学习算法的需要,本文通过极大似然估计的思想来进行缺失数据的估计。对于第 i条微博,首先计算得到能获得的评论用户数量占真实微博的评论数量比例。进一步,对于用户u的K条微博来说,可以构建用户v对用户u微博的评论情况的似然函数,通过极大似然估计算法,估计用户v对用户u微博评论概率。
2.4 影响概率计算

通过用户u作为影响发出者时的表征向量Iu和用户v作为影响接收者时的表征向量Sv可以计算得到用户u对v的影响概率:
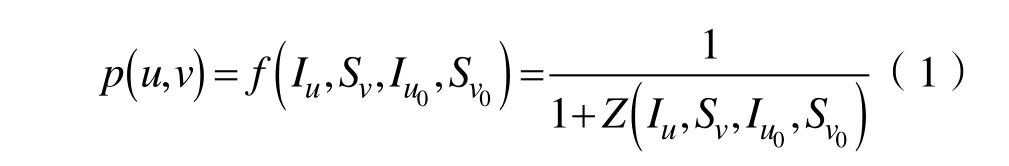
其中,
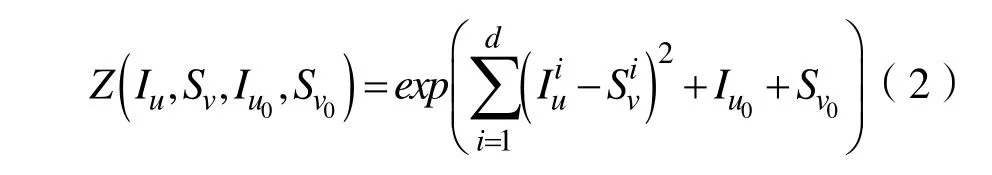
这里通过Sigmoid函数,可以将用户间影响概率映射到(0,1),这也符合真实的社交网络环境。

将上式扩展成为所有用户的微博转发列表和评论列表的对数似然函数:
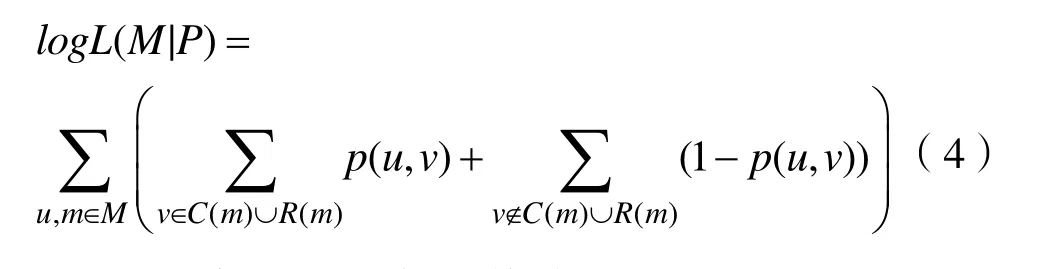
同样使用极大似然估计的思想,最终的学习目标就是最大化上式的对数似然函数。本文使用随机梯度下降法去更新用户表征从而最大化该对数似然函数,从而得到每个用户的表征。基于用户表征通过公式(1)计算得到每对用户间的影响概率的集合P输入到算法1。
2.5 影响传播估计
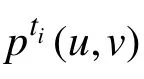
对于用户对(u,v),当用户 u在任意一个时间戳影响用户v时,则用户u成功影响用户v。因此,用户u在每个时间戳成功影响用户v的概率与用户 u在所有时间戳成功影响用户 v的概率p(u,v)有如下关系:
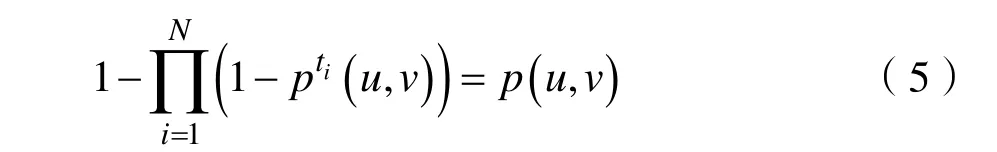
算法1影响传播过程
输入:种子用户节点集合S,影响概率集合P,用户集合V,时间戳的个数N
输出:被影响的用户集合f(S)

计算:用T代表整个发散过程持续的时间,t代表时间戳的长度。假定每个时间戳是相等的,那么时间戳的个数为。图 2绘制了在本文数据集中,用户被微博影响的数量,随着距离微博发布的时间的变化。图 3进一步绘制了在数据集中,用户被影响的概率密度随微博发布时间的变化。用函数f(x)来拟合图3曲线,则不同时间戳里,用户 u对用户 v的影响概率有如下关系:
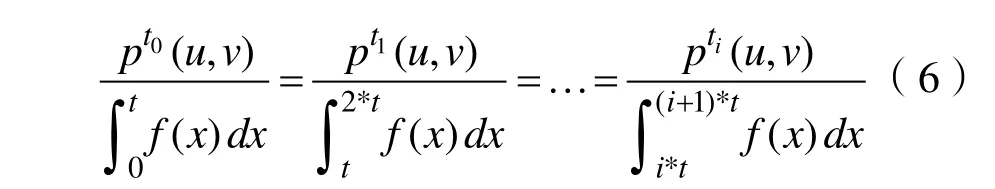
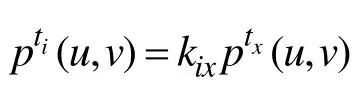

图2 交互数量随时间变化Fig.2 Nu mber of interactions vs. the time difference

图3 交互频率随时间变化Fig.3 Frequency of interactions vs. the time difference
3 实验
影响力传播是影响力分析研究中重要的一个领域。对于每条微博,将最开始发布这条微博的人视为种子用户。基于蒙特卡洛模拟来模拟影响传播的过程。实验中将对比在数据集中用户真实影响的人和模拟结果所影响的人。从一个初始的种子用户开始,活跃的用户会尝试去影响他的非活跃的邻居,一个节点一旦被影响,便会重复这种尝试。
3.1 数据集
本文通过构建爬虫程序来获得新浪微博下的数据。首先获取微博中的若干用户。根据这些用户,来获取这些用户所发的微博。根据所获得的微博,获取转发或评论这些微博的用户。最终数据集中共有6792个用户,本文获取了这些用户从2020年8月1日到2020年8月4日的发布微博。微博总数为 159 879,所有的这些微博共收到了507 014条转发和177 888条评论。但是,评论列表能看到的评论只有50 369条,剩余的为缺失评论。本文将2020年8月1日到2020年8月3日的数据设定为训练集,将2020年8月4日的数据设定为测试集。具体数据集的统计信息见表1。

表1 数据集统计信息Tab.1 Statistical information of dataset
3.2 对比方法
1. DTIC-Jaccard[5]。该模型利用Jaccard index来进行影响关系进行计算。
2. DTIC-Credit[5]。该模型是基于信用分配的方法来计算用户之间的影响关系。
3. Inf-embedding。由本文提出的影响力嵌入方法。
3.3 实验结果
本文通过正则化平方误差[12]、精确率、召回率、F1、参数数量等评价指标评估本文学习得到的影响力与真实影响力的接近程度以及所提方法的参数复杂度。具体结果如表2所示。
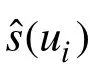
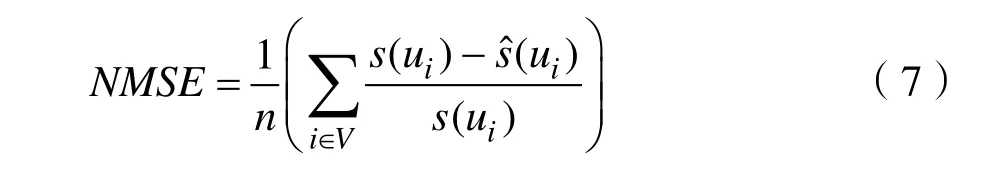
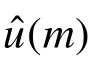
测试集中真实的受影响的用户集合:Inf(u) =u(m1) ∪u(m2)… ∪u(mn)
定义以下情况为 True Positive (TP), True Negative (TN), False Positive (FP), False Negative(FN):
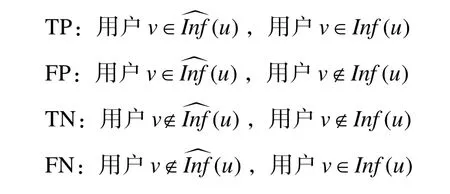

表2 影响传播模型对比Tab.2 Comparison of influence diffusion model
表2呈现了三个模型在影响传播预测任务中的表现。Inf-embedding模型在各项评估指标上表现均优于另外两个。由于数据集的时间跨度较短,用户之间的实际交互历史并不能充分包含在内。基于这种情况,通过对短期训练集的学习,来对影响传播的结果进行召回,得到 0.142的召回率相对其它模型已经有一定的提升。另外由于社交网络中用户行为本身存在的偶然性,所以对用户影响力传播的预测具有诸多不确定性。因此,对用户影响力的传播是十分有挑战性的工作,例如在twitter环境下只能达到的0.013[11]的F1,在Digg环境下的 0.18[9]的平均准确率。本文所提出方法所达到的精确率 0.400相较于其它模型有了大幅度的提升。以 F1值作为评价标准,相比较传统DTIC-Jaccard、DTIC-Credit方法,其 F1值分别提升了 26.7%和 51.4%。另外正则化平方误差指标最低说明了,本模型对影响传播范围的预测更接近于真实的传播范围,能对用户影响力有更准确的估计。最后作为嵌入学习的方法,本文在参数量上明显少于基于统计的模型。综合来看,本文模型相较于其它模型更适用于新浪微博下社交网络的影响力分析。
4 结语
本文提出了微博社交网络影响力预测学习方法,通过所提方法可以对用户的影响传播过程进行模拟并学习得到用户的影响力。基于对用户的历史行为进行学习,训练出用户表征向量,从而建立起用户间的影响关系,进而模拟影响传播的动力学过程。利用该嵌入方法对用户间影响概率进行计算,能够很大程度的减少参数的复杂度。并且,该模型在微博的真实数据中各评估指标表现也明显优于其它模型。
