超像素低秩高光谱稀疏解混
2021-07-09李璠
李 璠
(南昌工程学院 江西省水信息协同感知与智能处理重点实验室,江西 南昌 330099)
受遥感器空间分辨力限制,高光谱图像中存在大量的混合像元,阻碍了高光谱数据的精细化解译[1-2]。高光谱解混旨在提取高光谱图像中的纯净光谱(端元提取)并估计每种端元在混合像元中的占比(丰度估计)[3]。假设所有端元光谱都存在于一个大的可用光谱库中,则解混过程可等同于在光谱库中寻找可以有效表达混合像元的最佳光谱特征子集[4]。由于一幅图像中所含端元数量通常远少于光谱库中的端元个数,丰度系数自然表现出稀疏特性,因此,稀疏线性回归算法常用于解决这一优化问题,称为稀疏解混[5]。例如,基于变量分裂和增广拉格朗日的稀疏解混算法(Sparse Unmixing algorithm via variable Splitting and Augmented Lagrangian,SUnSAL)采用l1范数约束丰度系数的稀疏性[4],协同SUnSAL算法(Collaborative SUnSAL,CLSUnSAL)采用l2,1范数约束丰度矩阵的行稀疏性[6]。此外,迭代加权稀疏策略通过惩罚丰度系数中的非零值来增强解的稀疏性,取得了良好效果,如双重加权稀疏解混算法(Double Reweighted Sparse Unmixing,DRSU)在l1范数正则项中引入两种加权因子促进丰度矩阵在光谱域和空间域的稀疏性[7]。这些算法只考虑丰度系数的稀疏特征,而忽视了像元的空间结构。
利用高光谱图像丰富的空间信息可以有效约束丰度估计优化问题的解空间,因此一系列空间先验稀疏解混方法被提出[8]。例如,基于变量分裂增广拉格朗日和全变差稀疏解混算法(Sparse Unmixing via variable Splitting Augmented Lagrangian and Total Variation,SUnSAL-TV)通过各向异性全变差正则项刻画相邻像元之间的平滑性[9],谱—空加权稀疏解混算法(Spectral-Spatial Weighted Sparse Unmixing,S2WSU)利用包含像元邻域信息的空间加权因子促进图像的连续性[10],非局部稀疏解混算法(Non-Local Sparse Unmixing,NLSU)采取空间结构自相似正则化方法挖掘图像的空间高阶结构信息[11]。融入空间信息的稀疏解混方法在解混性能方面表现出巨大的潜力,但采用固定形状和大小的窗口探索像元之间的相关性限制了对图像空间结构信息的精确描述。
高光谱图像中相似像元的丰度向量具有相关性,反之,对丰度矩阵施加低秩约束可以保持图像的空间一致性[12]。例如,交替方向稀疏低秩解混算法(Alternating Direction Sparse and Low-Rank Unmixing,ADSpLRU)和联合稀疏块低秩解混算法(Joint-Sparse-Blocks and Low-Rank Unmixing,JSpBLRU)分别利用3×3滑动窗口和全局的丰度加权核范数实现丰度系数的低秩逼近,以保留高光谱图像的低维空间结构[13-14]。事实上,相对于预定义窗口或整幅图像,局部同质区域内的像元具有更高的相似度。超像素分割技术以像元的光谱特征相似度和空间距离为度量,将像元聚类为不同的空间组,自适应生成互不交叠的不规则同质区域,每个区域称为一个超像素[15]。超像素分割已广泛应用于高光谱图像处理,如分类[16]、去噪[17]、超分辨率[18]等。
综上,受低秩表示理论和迭代加权稀疏思想的启发,结合超像素分割技术,本文提出一种超像素低秩稀疏解混算法(SupLRSU),该算法将基于超像素的低秩约束和光谱加权稀疏约束联合施加在丰度矩阵上,既保持了图像内在的局部低维空间结构,促进图像的空间一致性,又诱导丰度矩阵的行稀疏性,促使图像中所有像元的丰度向量联合稀疏。
1 相关工作
1.1 线性光谱混合模型
线性光谱混合模型假设每个像元光谱都可以表示为端元光谱的线性组合[3],其矩阵形式记为
Y=MX+N, s.t.X≥0,1Tx=1.
(1)
其中,Y=[y1,y2,…yn]∈d×n表示高光谱图像,d为波段数,n为像元数,M=[m1,m2,…,ml]∈d×l表示端元矩阵,l为端元数,X=[x1,x2,…xn]∈l×n表示丰度矩阵,N∈d×n表示噪声或模型误差,X≥0为丰度“非负性”约束(Abundance Nonnegative Constraint,ANC),1Tx=1为丰度“和为一”约束(Abundance Sum-to-one Constraint,ASC)。
1.2 高光谱稀疏解混
稀疏解混用已知光谱库A∈d×m代替端元矩阵M∈d×l。同一场景中存在的地物种类一般少于20种,远小于光谱库中光谱特征的数量(l≪m),因此丰度矩阵X∈m×n表现出稀疏特性[4]。稀疏解混模型可表示为
(2)
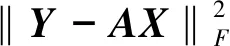
式(2)中l0范数的求解是典型的NP(Non-deterministic Polynomial)难问题,在满足有限等距性质(Restricted Isometry Property,RIP)的条件下,l0与l1优化问题有相同的最优解,式(2)可转化为
(3)
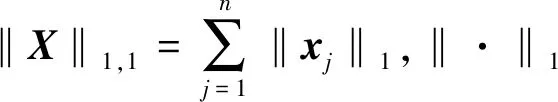
1.3 基于低秩先验的高光谱稀疏解混
高光谱图像邻域像元通常由相同的几种端元按照相同或相近的比例组合而成,因而丰度矩阵表现出低秩性。为捕获这种低秩稀疏的数据结构,在式(3)中加入丰度秩约束项,得到丰度估计的稀疏减秩回归问题[13],表示如下:
(4)
其中,rank(X)表示X的秩,τ≥0是正则化参数。式(4)中rank(X)不易求解,常用其核范数‖X‖*替代,记为
(5)
其中,σi(X)表示X的第i个奇异值,r=rank(X)。加权核范数最小化方法(Weighted Nuclear Norm Minimization,WNNM)通过为每个奇异值分配不同的权值实现奇异值收缩[20],其计算方式如下:
(6)
综上,基于低秩先验的高光谱稀疏解混模型表示如下:
(7)
模型(7)通过最小化加权核范数实现丰度系数的低秩矩阵逼近,促使丰度向量线性相关,虽提高了解混精度,但忽略了图像的空间细节信息。
2 本文方法
2.1 超像素分割
为更准确地描述高光谱图像的空间相关性,采用超像素分割技术将图像划分为若干个互不交叠的同质区域。简单线性迭代聚类算法(Simple Linear Iterative Clustering,SLIC)是一种结构简单、快速有效的超像素生成算法[21]。SLIC算法基本思想是局部区域k-均值(k-means)聚类,具体流程为:初始化p个种子点,并将搜索空间限定在以种子点为中心、与超像素大小成比例的区域,计算搜索区域内各个像元到种子点的加权距离,将每个像元归类至距离最近的种子点。每轮归类结束,以同一类像元的均值为新的种子点重复上述步骤,迭代至收敛。SLIC算法一方面限定了k-均值的搜索空间,减少了优化过程中距离的计算次数,降低了算法的复杂度,另一方面以像元的颜色接近度与空间位置关系为指标设置加权距离,灵活控制超像素的紧凑性和大小。
原始的SLIC算法主要面向CIELAB颜色空间的彩色图像,需要修改加权距离的计算方式以适应三维的高光谱数据[15]。为保持一个超像素区域内像元的相似度,改进的SLIC算法同时考虑像元的光谱距离和空间距离,定义中心像元(xi,yi)与搜索区域内任一像元(xj,yj)的加权距离如下:
(8)
其中,zi和zj分别表示像元(xi,yi)和(xj,yj)的观测光谱向量,dspe表示像元的光谱距离,采用光谱角距离(Spectral Angle Distance,SAD)度量,dspa表示像元的空间距离,采用欧式距离度量,常数ω>0表示空间距离和光谱距离之间的权重,D表示像元(xi,yi)和(xj,yj)的加权距离。
采用改进的SLIC算法对高光谱图像进行空间预处理,将整幅图像标记为一组不规则的空间异构区域,而每个区域内像元的观测光谱高度相似。
2.2 超像素低秩高光谱稀疏解混模型
为更有效地利用图像的空间上下文信息,用每个超像素区域的丰度低秩约束取代全局性或固定窗口的低秩约束,仅使每个同质区域内的像元共享相同的稀疏结构。此外,为促使图像中所有像元共享光谱库相同的活动端元子集,我们还在稀疏正则项中引入光谱加权因子诱导丰度矩阵的行稀疏性。基于上述考虑,提出超像素低秩高光谱稀疏解混模型(SupLRSU),表示如下:
(9)
其中,X(s)表示图像中第s个超像素,p为超像素个数,H∈m×m是一个对角矩阵,表示光谱权重,H中第i行的值计算如下:
(10)
其中,X(i,:)表示X的第i行向量,‖·‖2表示l2范数。光谱权重H迭代更新,其每一行的权值与丰度矩阵相应行向量的l2范数成反比,因此,每次迭代将更大程度地惩罚丰度系数中具有较小值的行,引导丰度矩阵只保留少数的非零行,提高丰度矩阵的行稀疏性。
2.3 模型求解
受文献[10]启发,我们采用内外双循环迭代方案求解式(9)模型,在外循环中根据式(10)更新光谱权重H,在内循环中利用交替方向乘子法(Alternating Direction Method of Multipliers,ADMM)更新丰度矩阵X,具体过程如下。
引入5个辅助变量U,V1,V2,V3,V4,将式(9)改写为如下形式:
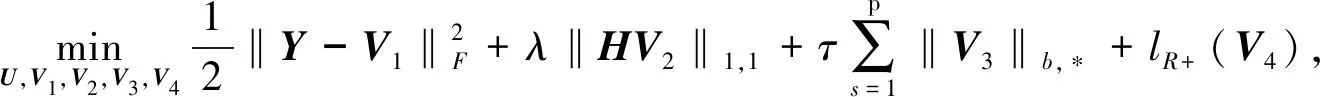
(11)
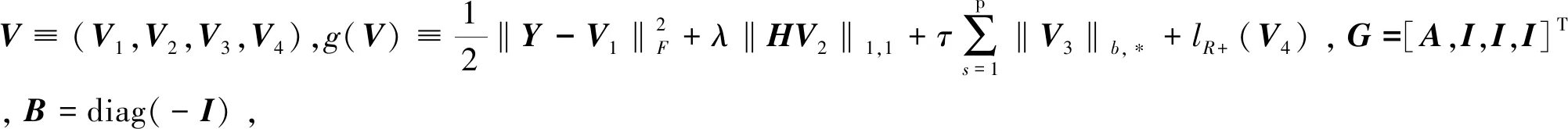
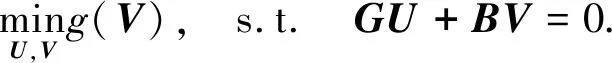
(12)
其增广拉格朗日函数为
(13)
其中,μ>0为罚参数,D=(D1,D2,D3,D4)为约束条件GU+BV=0相关的拉格朗日乘子。
根据ADMM方法,对式(13)中U和V分别迭代求解下列优化问题,更新拉格朗日乘子D:
(14)
计算式(14)得到各个变量的迭代更新公式。SupLRSU算法流程如下所示。其中,sof r(α,β)≡sign(α)max(|α|-β,0)表示软阈值函数,svtb,β(X)≡U(σ(X)-βdiag((b))+VT表示加权奇异值阈值算子。

算法1:SupLRSU算法1.Initialization:set t,k,s=0,λ,τ,μ,ε>0,U(0),V(0)1,V(0)2,V(0)3,V(0)4,D(0)1,D(0)2,D(0)3,D(0)42.Repeat:3.Update the spectral weighting facor:h(t+1)=1‖(U(t)-D(t)2)(i,:)‖2+ε,i=1,…,m4.Repeat:5.U(k+1)←(ATA+3I)-1(AT(V(k)1+D(k)1)+V(k)2+D(k)2+V(k)3+D(k)3+V(k)4+D(k)4)6.V(k+1)1←11+μ[Y+μ(AU(k+1)-D(k)1)]7.V(k+1)2←softU(k+1)-D(k)2,λμH(t)()8.for s=1:p9.(V(k+1)3)(s)←svtb,τμ((U(k+1)-D(k)3)(s))10.end for11.V(k+1)4←max(U(k+1)-D(k)4,0)12.Update the Lagrange multipliers:13.D(k+1)1←D(k)1-AU(k+1)1+V(k+1)114.D(k+1)2←D(k)2-U(k+1)2+V(k+1)215.D(k+1)3←D(k)3-U(k+1)3+V(k+1)316.D(k+1)4←D(k)4-U(k+1)4+V(k+1)417.Update iteration:k←k+118.Until stopping condition19.U(t+1)←U(k)20.D(t+1)←D(k)221.Update iteration:t←t+122.Until stopping condition
3 实验结果与分析
为了验证本文所提超像素低秩高光谱稀疏解混算法(SupLRSU)的性能,本节采用模拟和真实高光谱数据进行实验,与SUnSAL,CLSUnSAL,DRSU,ADSpLRU,JSpBLRU算法进行对比,分析实验结果。模拟实验采用信号与重建误差比(Signal Reconstruction Error,SRE)和丰度重构正确率(Probability of Success,Ps)进行定量评价。SRE(dB)定义如下:
(15)
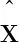
(16)
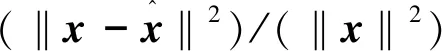
3.1 模拟数据实验
从美国地质勘探局(United States Geological Survey,USGS)发行的splib06波谱数据库中随机选择240条端元光谱组成光谱库A∈224×240(光谱波段数为224)。从光谱库A中随机选取9种端元,按照M.D.Iordache等制作的丰度分布图线性组合生成模拟数据。随后加入信噪比(SNR)为30dB、40dB和50dB的高斯噪声,形成三组模拟数据集。实验涉及算法的正则化参数均已调优,最大迭代次数均设为500次,残差阈值均设为1e-5。9种端元的真实丰度分布如图1所示。

图1 模拟数据中9种端元的真实丰度图
表1展示了不同解混算法对三组模拟数据集进行丰度估计所获得的SRE(dB)和Ps值。从表1可以看出,在低SNR情况下,所提SupLRSU算法的SRE(dB)值和Ps值均优于其他算法,并展现出显著优势,证明SupLRSU算法具有良好的抗噪性能。在高SNR情况下,所有算法的Ps值均大幅提升,SupLRSU算法的SRE(dB)值略高于其他算法或与其他算法基本持平。
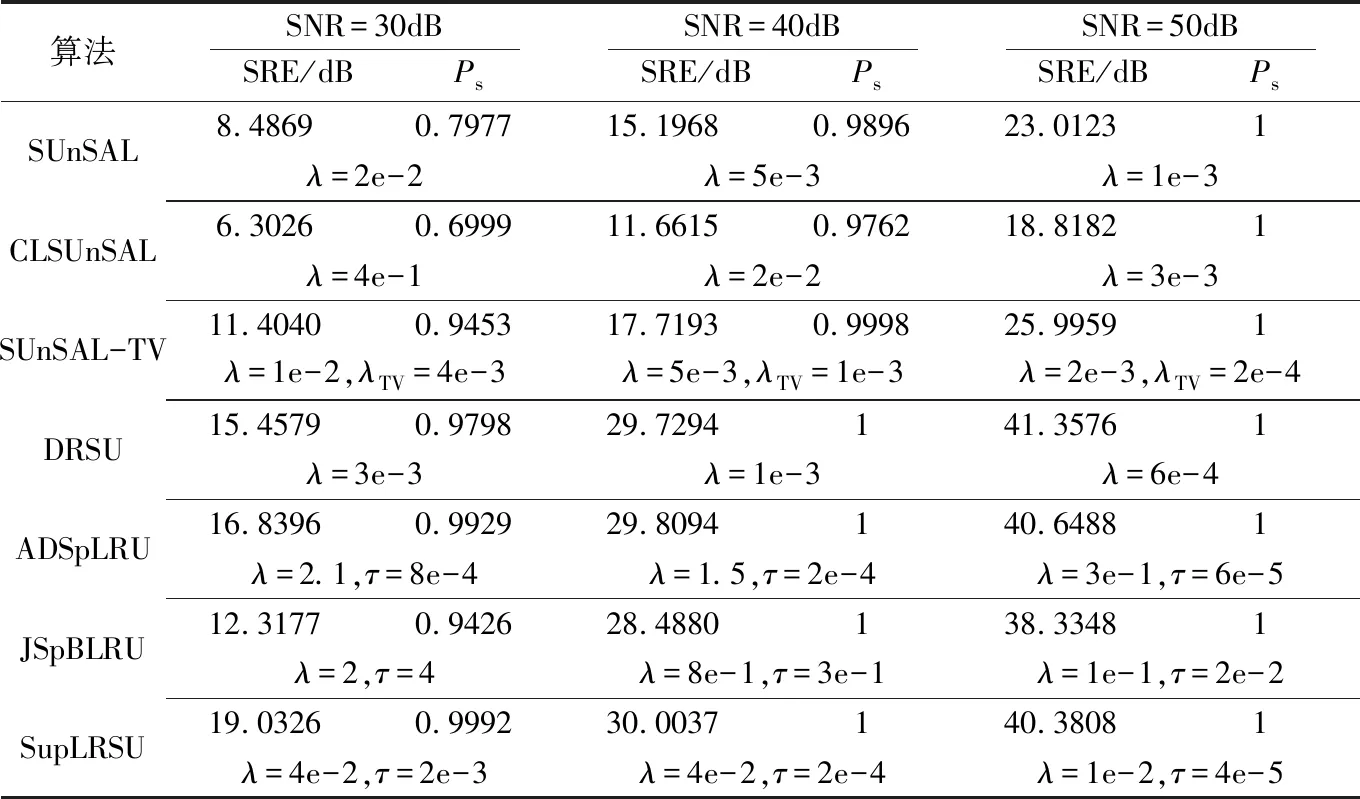
表1 不同解混算法丰度估计结果的SRE(dB)和Ps值(30次平均)及相应正则化参数设置
图2展示了模拟数据真实丰度图和SNR=30dB时不同解混算法的估计丰度图。为使视觉效果更加清晰,从结果中随机选择500个像元进行展示。此外,从表1可知SUnSAL和CLSUnSAL算法的丰度估计结果较差,因而这两种算法的估计丰度图在本文中不做展示。从图2可以看出,每种算法基本都能从光谱库中识别出9种端元,但所提SupLRSU算法对端元的识别更加准确。SUnSAL-TV估计丰度图中有明显的代表错误端元的异常丰度线,DRSU估计丰度图中有较多异常点,ADSpLRU和JSpBLRU的丰度估计图包含少量具有较小值的异常丰度线。
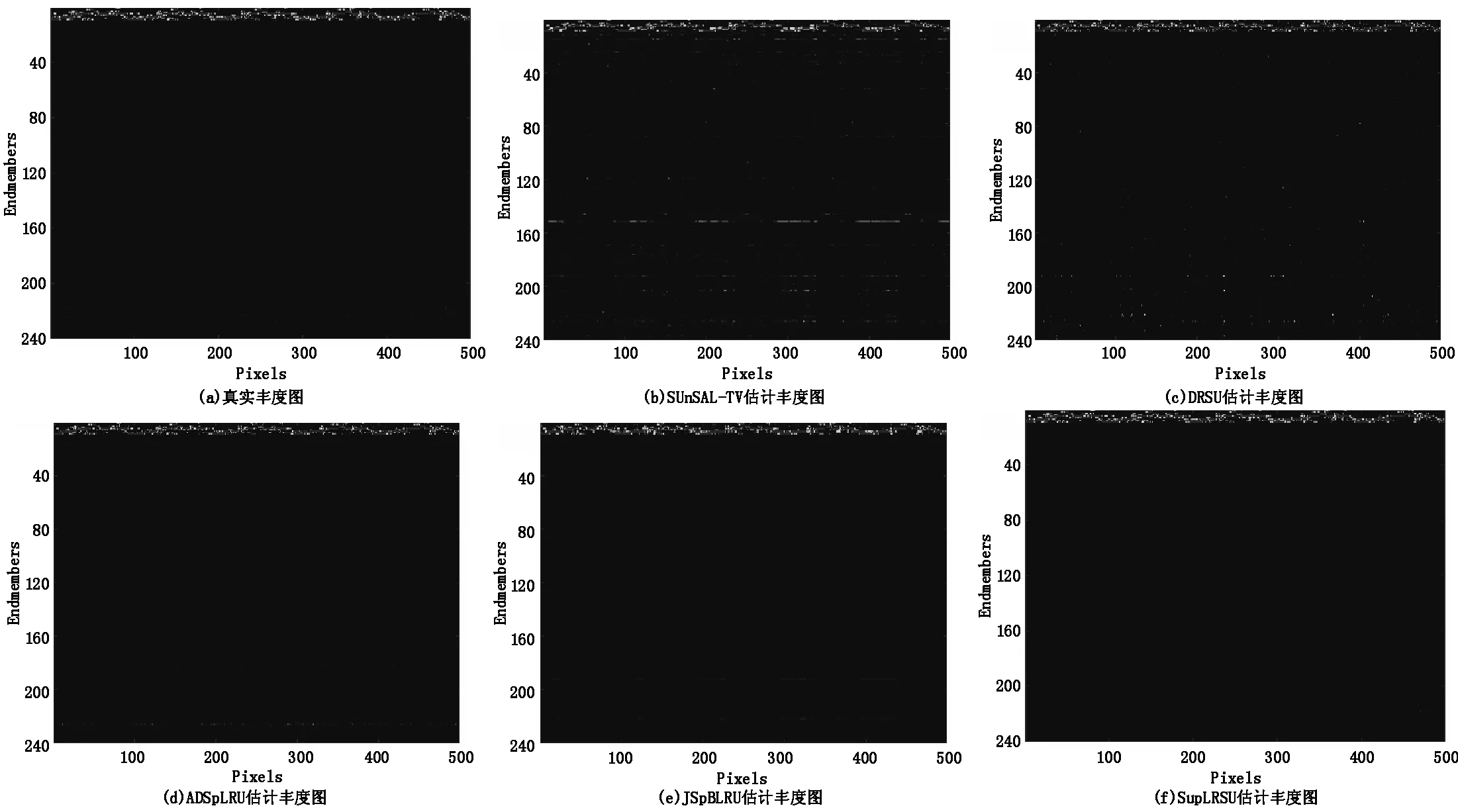
图2 真实丰度图及不同解混算法获得的估计丰度图(SNR=30dB)
为直观比较丰度估计的精确性,图3展示了SNR=30dB时不同解混算法获得的端元9的丰度分布图,其他端元丰度图的表现与端元9基本一致,因此不做展示。从估计丰度与真实丰度的差值图很容易看出,所提SupLRSU算法的丰度图与端元9的真实丰度图最接近。SUnSAL-TV得到的丰度图出现了较明显的过平滑现象,DRSU的丰度图含有大量噪声点,与同样引入低秩约束的ADSpLRU和JSpBLRU算法相比,SupLRSU算法的估计丰度图在保证分段平滑的同时保持了空间异质性结构,并且保留了更多的细节信息。

图3 不同解混算法获得的端元9的丰度图以及与真实丰度的差值图(SNR=30dB)
3.2 真实数据实验
真实数据实验采用机载可见红外成像光谱仪(Airborne Visible Infrared Imaging Spectrometer,AVIRIS)采集的Cuprite 矿区数据。该数据集光谱波段数为224,波长范围为0.4~2.5μm,光谱分辨率为10nm,大小为250×191像素。剔除数据中低信噪比和低吸水率波段(1~2、105~115、150~170和223~224),实验数据的实际波段数为188。实验所用的端元光谱库来源与模拟实验一致,删除相应的低信噪比和低吸水率波段后,保留188个波段。实验参考图4所示Tricorder软件[22]制作的矿物分类图,对不同算法的丰度估计结果进行定性分析。
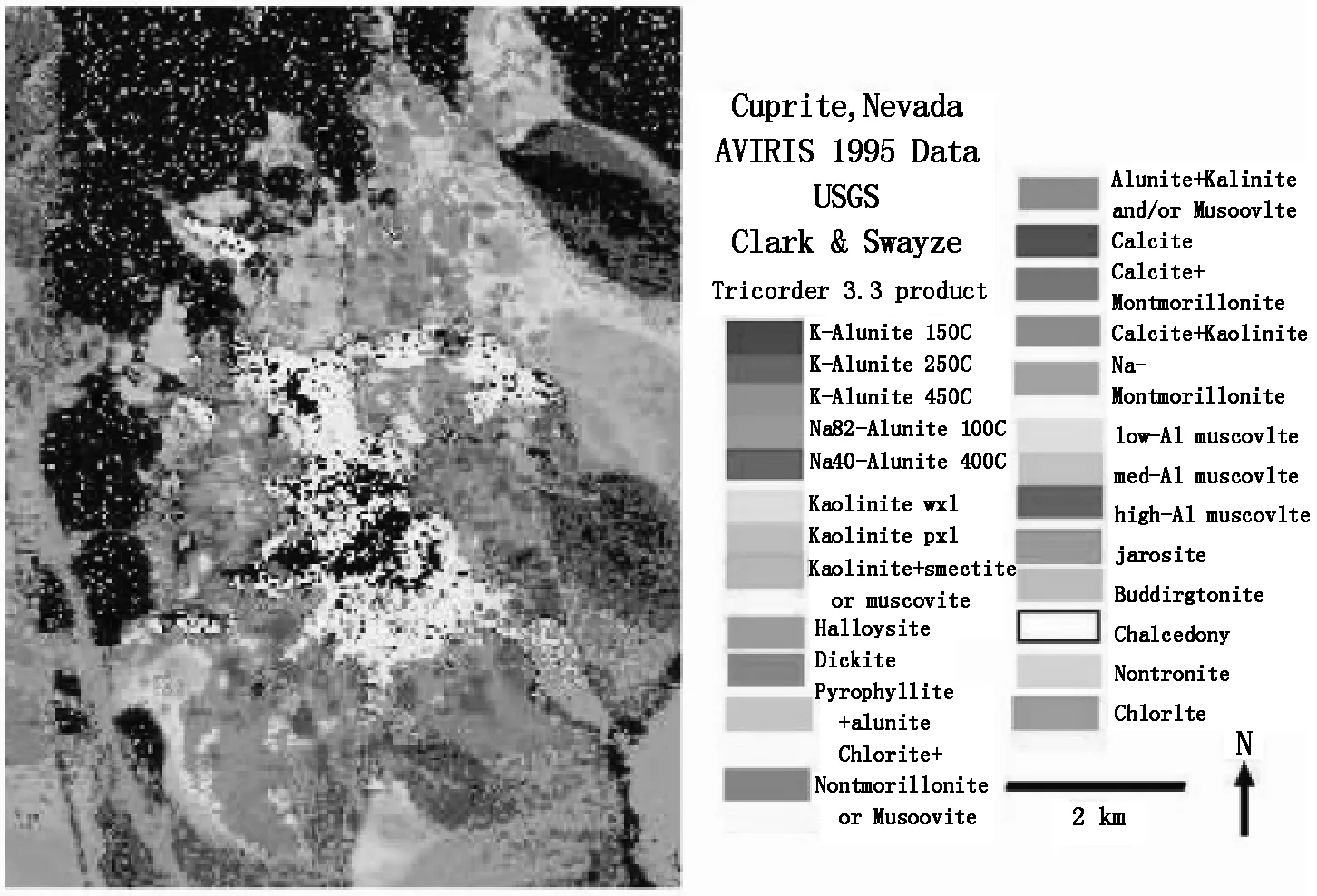
图4 USGS获得的内华达州Cuprite矿区数据
图5以明矾石(Alunite)、水铵长石(Buddingtonite)和玉髓(Chalcedony)三种矿物为例,展示不同算法对Cuprite数据集的解混结果。可以看出SUnSAL-TV算法得到的丰度图均不同程度地存在过平滑现象,DRSU算法的丰度图空间一致性较差(如玉髓)。所提SupLRSU算法的估计丰度图噪声更少(如水铵长石),更接近Tricorder参照图,表明该算法能有效处理真实数据。
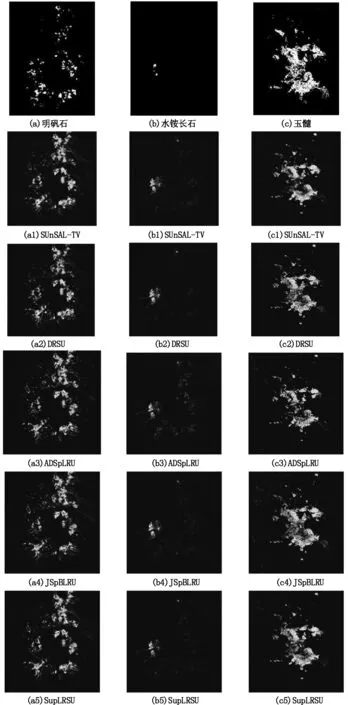
图5 不同算法对Cuprite数据集解混得到的丰度图
4 结论
本文在空间先验稀疏解混方法的基础上,一方面利用改进的SLIC算法对高光谱图像进行分割,生成像元光谱高度相似的不规则同质区域,对同质区域的丰度向量组施加低秩约束,在促进图像空间一致性的同时,保护图像的空间异质性结构。另一方面,在l1范数正则项中引入光谱加权因子,提高丰度矩阵的行稀疏性,增强算法从光谱库中识别实际端元的能力。模拟数据和真实数据实验证实,与SUnSAL,CLSUnSAL,DRSU,ADSpLRU,JSpBLRU算法相比,在大多数情况下,本文提出的SupLRSU算法在丰度估计方面能够获得更高的精度,特别是在低信噪比情况下,具有明显优势,同时能更准确地从光谱库中识别端元。
