豆瓣大连电影票信息爬取与存储
2021-07-04孙爱婷


摘 要:针对爬取工作量较重,分析内容繁杂的网站而言,利用正则表达式的re模块实现爬虫是较困难的,此时需要更高效的BeautifulSoup分析工具來解决这一问题。爬取豆瓣电影票-大连城市网站中的全部电影列表,首先进行网页源代码分析,采用python自带的html.parser解析器解析网页,爬取所需电影信息,然后采用5种不同方式进行存储,方便进行不同需求的数据挖掘和分析。
关键词:网页爬取;BeautifulSoup;解析器
一、BeautifulSoup
BeautifulSoup是网络爬虫必学的技能之一,是一个可以从HTML或XML文件中爬取数据的python库。BeautifulSoup主要功能是从复杂的网页解析和爬取HTML或XML内容,哪怕此时使用BeautifulSoup实现的是海量的网站源码的分析工作,我们会发现,它的实现过程也非常简单,极大地提高了分析源码的效率。
同时,BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方库的解析,如果不进行特殊的解析器安装,Python则会使用默认的解析器。基于以上特性,BeautifulSoup已成为和Lxml一样出色的Python解析器,为用户灵活提供不同的网站数据爬取和解析策略。
二、基于BeautifulSoup的独立数据爬取
1.实例分析
本实例的爬取目标是豆瓣电影票-大连城市网站中的全部电影列表,网站内容见图1,网站地址如下:https://movie.douban.com/cinema/nowplaying/dalian/,部分网页源代码如图2所示,需要说明的是,由于网站内容不断地动态更新,因此每次运行得到的结果可能会有差异。
2.源代码分析
我们的目标是电影列表,首先从图2中搜索到目标位置,然后通过“soup.find_all(‘li’,class_=’list-item’)”,找到全部class_属性为“list-item”的<li>标签,爬取需要的电影信息。例如,item[‘data-title’]获取<li>标签中的指定属性data-title(电影名)对应的value值,item[‘id’]对应属性id(电影ID)的value值等,最后依次爬取需要的内容即可。
3.具体代码实现
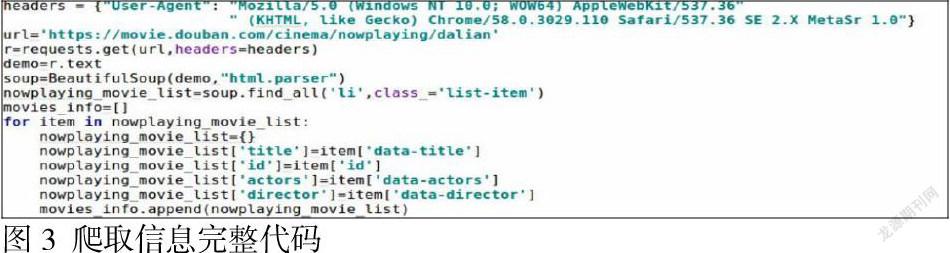
本实例实现了爬取豆瓣电影票-大连城市网站中的全部电影列表,爬取信息完整代码如图3所示。
4.爬取信息存储
通过以上程序可以得到所有大连城市电影信息,紧接着可以采用不同存储方式进行存取,以下列出了5种存储方式:
(1)存储于.txt文档
使用python读写文本数据,需要使用open()方法,用于打开一个文件,将爬取内容写入当前打开的文件中。注意,open()方法打开文件后,一定不要忘记关闭文件对象,即结束文件的使用时调用close()方法。具体代码见图4所示。
(2)存储于.csv文件
CSV文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不包含二进制数字。CSV文件由任意数量的记录组成,记录之间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。使用该存储方式之前需要import csv,实现过程具体代码见图5所示。
(3)存储于.xls表格
在python中,xlwt是读取Excel文件的一个常用扩展模块,可以实现创建表单、写入指定单元格、指定单元格样式等常见功能,人为使用Excel实现的绝大部分写入功能,都可以使用这个扩展包实现。xlwt模块同样需要用户单独安装:pip install xlwt,使用前导入xlwt包:import xlwt,实现过程如图6所示。
(4)存储于.json文件
JSON作为一种轻量级的数据交换格式,可作为读写数据的对象使用,通常使用JSON模块,首先需要导入JSON库:import json。在JSON模块中,主要涉及json.dumps()、json.load()和json.loads()方法,实现过程如图7所示。
(5)存储于MongoDB数据库
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库中功能最丰富的、与关系数据库最相近的NoSQL数据库。使用前需要安装MongoDB服务器端,然后安装PyMongo模块,该模块是Python对Mongodb操作的接口包,它能够实现对MongoDB的增、删、改、查及排序等操作。由于PyMongo模块来源于第三方,因此未包含在Python的标准库中,需要自行安装:pip install PyMongo,然后导入PyMongo包:import pymongo,实现过程如图8所示。
参考文献:
[1]奚增辉等.应用主题爬虫的电力网络舆情数据采集[J].西安工程大学学报, 202003).
[2]高雅婷,刘雅举. 基于Python的网上购物数据爬取[J].现代信息科技,2020(5):16.
[3]王彦雅. 基于Python的廊坊市二手房数据爬取及分析[J].电脑知识与技术,2020(29).
[4]于学斗,柏晓钰.基于Python的城市天气数据爬虫程序分析[J].办公自动化. 2020,27(07).
作者简介:孙爱婷(1984-),女,汉族,辽宁大连人,讲师,硕士,辽宁轻工职业学院,信息工程系大数据技术专业主任,主要研究方向:大数据技术。
