基于SSD的目标车辆检测算法研究
2021-07-01吴韶波
杨 帆,吴韶波
(北京信息科技大学 信息与通信工程学院,北京 100101)
0 引 言
近年来,智能驾驶越来越受到广大消费者的青睐,该技术控制车辆在无人类干预的情况下安全地完成驾驶任务。车辆目标检测就是其中的重要一环:利用传感器采集的信息检测周围车辆和智能驾驶车辆的相对位置。随着深度学习算法的发展,通用目标检测技术也逐渐发展成熟。但对于智能驾驶场景而言,通用目标检测技术存在实时性差、易受天气和光照等变化的影响等缺点,需要做进一步的改善才能满足需求。深度学习中的SSD(Single Shot MutiBox Detectior, SSD)算法[1]采用卷积层替代全连接层,实现了特征提取和定位,克服了由于车辆数据集问题带来的各种困难,具有一定的泛化能力。该算法较传统目标检测算法计算效率更高,在性能上有了极大提升,然而仍存在下列缺陷:
(1)在现实交通环境中,车辆较为集中,普遍存在遮挡问题,检测结果仍有所欠缺;
(2)由于交通场景视野较远,存在许多尺寸较小的目标,且交通场景环境多变,容易出现误检、漏检等现象[2]。
针对以上问题,还需要在SSD算法的基础上做进一步优化,才能使模型在更加复杂的场景下提高判断和检测能力,减少误判和漏检等现象。
1 相关理论基础
1.1 SSD算法原理
SSD网络架构是由VGG16[3]和大小不同的卷积层组成,由于一张图片中可能会有多个目标需要检测,所以之前的全连接层(FC6和FC7)便体现出很大的局限性。考虑到卷积层提取特征的作用,产生了用卷积层替代全连接层的想法,相应的最后做预测时也需要使用卷积层。SSD架构如图1所示。

图1 SSD架构
最初的输入数据为300×300×3的可见光图像,经过VGG16基础特征提取层后,依次使用不同的卷积层Conv6、Conv7、Conv8_2、Conv9_2、Conv10_2进行处理。因为不同层的特征图(feature map)对应到原图上的感受野存在差异,所以在不同层上生成的默认框(default box)大小不同,可以检测到不同大小的车辆目标。每个检测层后接上2路3×3卷积用做分类与回归,之后运用NMS(非极大值抑制)选择出置信度最大的候选框作为最终的检测结果。
1.2 SSD的anchor机制
SSD网络模型中共使用了6个不同尺度的特征,相应分别产生了6个不同形状的anchor,底层的特征图尺度较大,点也较密集,适合使用较小的anchor检测小目标;高层的特征图尺度较小,点也比较稀疏,适合使用较大的anchor检测大目标。假设用m个特征图进行预测,那么对于每个特征图而言,其anchor尺度的计算方式如下:
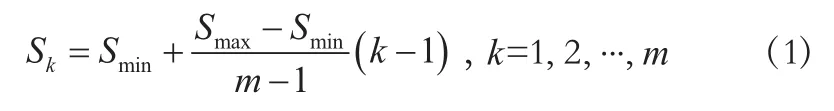
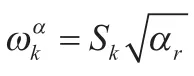
1.3 SSD损失函数
SSD算法的匹配策略:首先给每个anchor分配一个真实标签,通过anchor与Groundtruth box比较计算最佳重叠。IOU大于阈值0.5,则该anchor为正样本,反之为负样本。实际上,每张图片中负样本的数量远多于正样本,为避免负样本主导整个loss,按照预设正负样本比例1∶3挑选出一定数量的负样本,即对负样本按照loss从大到小排序,只选择前n个loss较大的负样本进行梯度更新[5]。SSD对正负样本比例进行了一定控制,能够提高训练结果的稳定性和优化速度。总体目标损失函数是置信损失(conf)和位置损失(loc)的加权和:
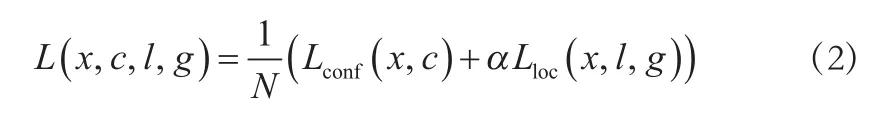
式中:N为匹配的anchor的数量(正负样本的数量之和);c为置信度;置信损失是Softmax对多类别的损失;l为预测框;g为真实框;位置损失是l和g之间的smoothL1损失,α为两者的权重。
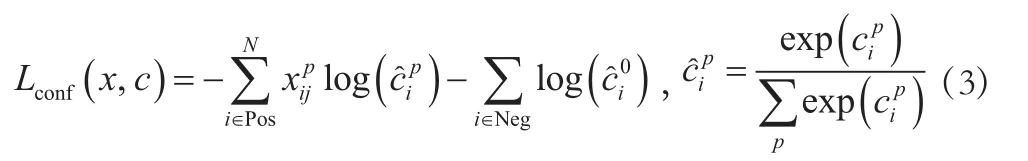
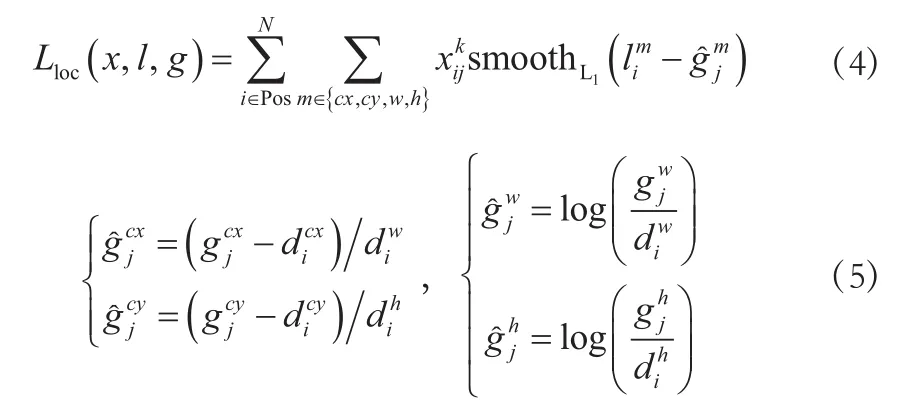
SSD选用的位置损失函数smoothL1计算方式如下:
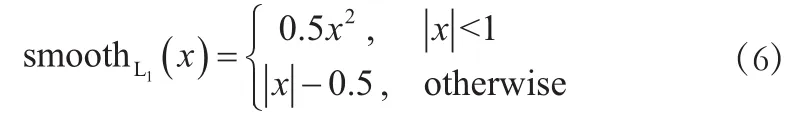
2 SSD算法的改进
2.1 anchor的优化
SSD用了6个不同尺寸的特征图进行预测,每层都会先得到默认框的尺寸,然后再在默认边界框的基础上添加不同的长宽比得到不同的anchor,如图2所示。anchor的设置通常会有几个像素偏移中心位置,未与感受野对齐。大目标对于这样的现象不会太敏感,IOU变化不会太大(IOU计算方法见式(7));而小目标不同,尤其当感受野不够大时,anchor甚至会偏移出感受野区域,影响最终的检测性能。

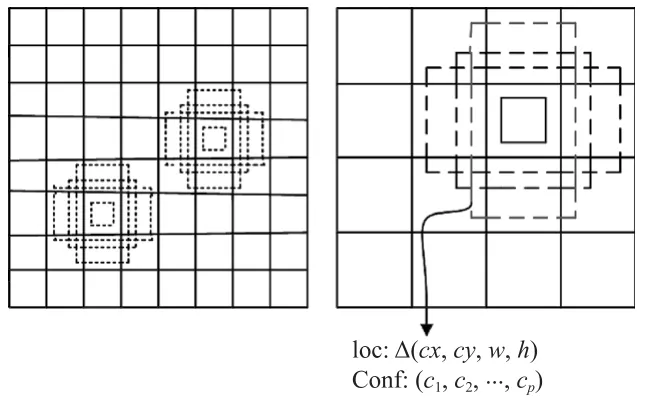
图2 8×8和4×4特征图
为了使小目标的检测效果更好,充分利用最底层的特征图,将各特征层对应的anchor种类数[6]由之前的[4,6,6,6,4,4]提升至 [6,6,6,6,4,4]。SSD模型中 anchor的数量计算方式为:各层的像素点数×各层anchor的类别数,由之前的8 732增加到11 620。
增加底层特征图anchor的类别数能够更好地捕捉到一些易被漏检的小目标,提升模型对车辆检测的整体准确率。
2.2 引入红外热像图
考虑到特殊场景下,如夜晚或大雾天气时,单凭可见光图像进行训练具有一定的局限性,而红外热成像不受光源的影响,特别是光线不足的情况下依然可以有效成像,因此本实验利用红外热成像的特点[7],在可见光的基础上引入红外热像图。红外热像图的特点如下:
(1)包含移动物体的温度信息;
(2)不受周围环境的影响,例如强光、雾霾等;
(3)对比度低,有利于关键特征的提取。
综合以上特点,将对红外热像图提取的特征与对可见光图像提取的特征进行融合,经过分类和回归计算出最终检测结果。两组图像数据可视化如图3所示。
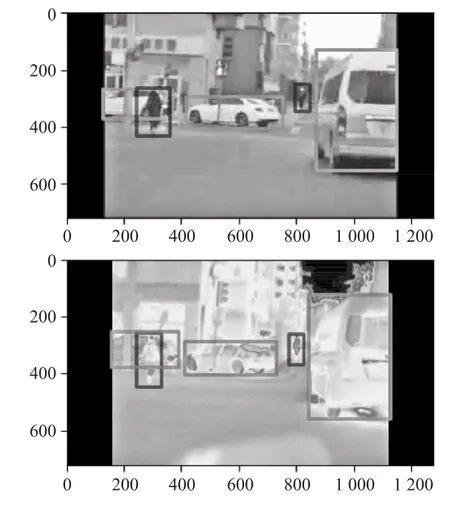
图3 两组图像数据可视化
3 实验过程
3.1 实验数据准备
本实验数据集选取了城市道路、普通公路、高速公路和乡村道路多个场景,分别进行下采样、标注及数据增强等操作。车辆数据来源于实景拍摄,普遍存在车辆之间相互重叠、遮挡的现象,检测难度较大。数据集处理流程如图4所示。
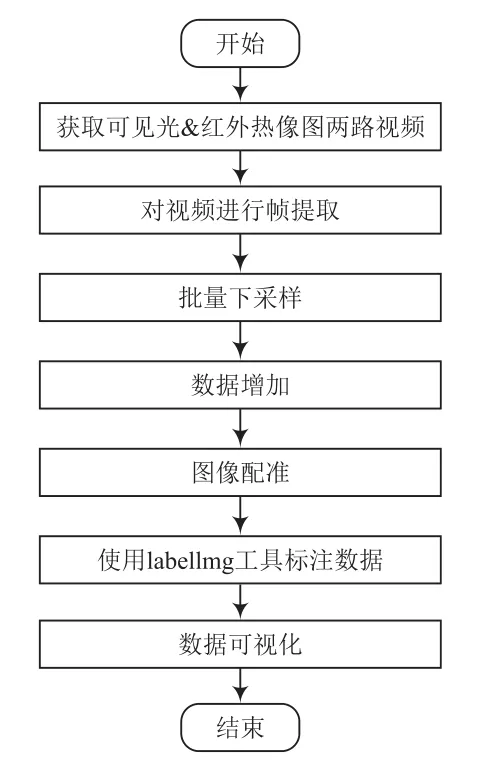
图4 数据集处理流程
在本实验训练过程中,大量使用了数据增强的方法进行水平翻转、缩放、随机裁剪,并调整亮度、对比度、饱和度和色调等。经过数据增强,对于不同大小、不同尺度的物体均有较好的检测性能,有效提升了SSD模型的鲁棒性[8];数据增强对待测目标进行变形后,有助于丰富数据,防止模型过拟合,提高泛化性。
3.2 实验过程
本文在自己制作的数据集上对网络进行训练,车辆检测网络基于SSD算法,训练环境为Tensor flow,对特征层anchor数量进行调整,学习率设置为0.000 1,weight decay为0.000 04,momentum为0.9,batch为32,正负样本比例为1∶3。将车辆检测实验的系统流程总结如下:
(1)配置文件和环境变量;
(2)制作数据集,对2路数据进行预处理,如批量修改图片名称、下采样、校准对齐及对数据集标签进行标注等;
(3)修改脚本,训练可见光数据得到模型1;
(4)重新设计网络结构,加入红外热像图,融合可见光数据和红外热像图数据经过卷积层提取的特征,训练得到模型2;
(5)将预测图片分别输入训练好的模型1和模型2,输出检测结果。
3.3 结果分析
本文使用典型评价指标—平均精度均值(mean Average Precision, mAP)对车辆检测模型的精度进行衡量,mAP是各类别平均精度(Average Precision, AP)的均值。平均精度结合精确率(Precision)和召回率(Recall),可以评估模型在某一类别上的好坏,精确率和召回率计算方法分别见式(8)、式(9)所示:
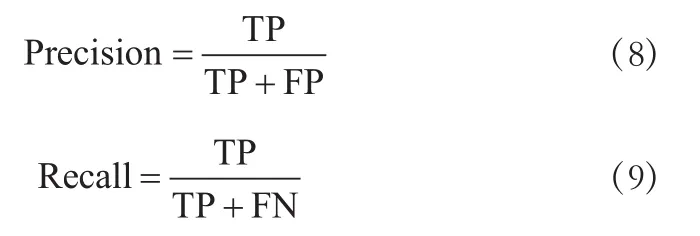
式中:TP为IOU>0.5的预测框的数量;FP为IOU≤0.5的预测框或是检测到同一个ground truth的多余检测框的数量;FN为未检测到ground truth的预测框的数量。
实际上,AP为Precision和Recall构成的曲线下的面积,mAP即各类别AP的平均值,如有n个类,则mAP用式(10)表示:

本实验中,模型1的mAP计算为76.5%,引入红外热像图模型2的mAP计算为79.3%,提高了2.8%,最终的车辆检测效果如图5所示。

图5 车辆目标检测效果
通过以上结果可看出,本文实验较好地完成了车辆检测的任务,anchor在卷积层上数量的改进,以及在普通数据集基础上增加红外热像图,都有效提高了目标检测的精确率。这是因为光线不足时,网络难以从可见光数据中提取足够的特征,而红外热像图的加入更有利于昏暗环境下目标特征提取。但本文的实验环境不一定是最佳的,还需要进一步完善。
4 结 语
本文基于SSD模型在采集的可见光和红外热像图两路数据集上进行车辆目标检测,该方法使用全卷积网络进行特征提取、回归和分类,具有一定的鲁棒性。首先,在SSD模型的基础上对anchor进行改进,有效降低了小目标漏检的概率。然后,增加红外热像图数据集进行特征补充,不仅提高了小目标检测的准确率,更有利于夜晚等特殊环境下的大目标检测。从实验结果可以得出结论,该模型的检测效果还有提升空间,今后的工作方向为进一步改进模型性能,提高车辆目标检测的精确度。
