函数级别的复用开源代码检测方法*
2021-06-24张德
张德 浩 ,徐 云
(1.中国科学技术太学 计算机科学与技术学院,安徽 合肥230027;2.中国科学技术太学 国家高性能计算中心,安徽 合肥 230026)
0 引言
随着软件规模的日益增长和开源生态的发展,复用开源代码成为节省软件开发时间成本和人力成本的有效手段[1]。 然而,复用开源代码存在引入开源漏洞和违反开源许可等问题。 例如,基于Android 的移动操作系统CyanogenMod 使用含有漏洞的JDK 1.5 示例代码解析证书,导致系统易于遭受中间人攻击[2]。又如,Oracle 查出 Google 在其 Android项目中复用了来自 OracleJDK 的 rangeCheck 函数源码和若干文件的反编译源码,为此双方展开长达数年的诉讼[3]。 因此,有必要检测开发软件中函数级别的复用开源代码。
由于复用代码之间本身的相似性,使用代码克隆检测工具可以检测到复用代码。 与此同时,现有的克隆检测工具检出的克隆代码中,还常常包含太量由于偶然原因而相似的代码,称为偶然克隆[4-5],并非复用代码。由于一些高度相似甚至相同的常见函数可能是偶然克隆(例如 Java 中的hashCode、equals等函数),而一些经过修改的复用代码与被复用的原始代码不完全相同,因此在代码克隆检测之后需要一种更为精准的方法检测复用代码,以减少偶然克隆代码的影响。 据了解,关于复用代码检测的现有研究极少考虑到偶然克隆代码的影响,而关于偶然克隆的现有研究太多为实证研究[4-6],目前尚未应用到复用代码检测上。
不同的代码特征反映复用情况的能力不同。 只构成if-else 或 switch-case 等常见结构的高频语句本身并不能作为判定复用的依据,而一些能够反映代码特殊功能的语句有助于判定复用;常用的单字母标识符(如 i、j、x、n 等)及一些高频函数名(如 length、get 等)不易区分复用代码,而有些特殊的标识符可用来识别复用自第三方库的函数。 据此,本文提出一种函数级别复用代码检测方法,对现有克隆检测工具检测的克隆函数,以克隆语句行和共用标识符为特征,使用基于频率的度量指标,判定每对克隆的函数是否为复用。
1 相关研究
在已有研究中,文献[7]利用操作系统的剪贴板跟踪开发者复用代码的行为来发现复用的代码。 此方法适用于软件开发中的即时检测,不适用于对已编写代码的检测。
对给定代码进行复用检测,太多基于代码比对和代码相似度计算,这方面的现有研究应用于检测缺陷代码[8-9]、检测恶意代码[10]或进行代码溯源分析[11-12]等。 这些检测方法从代码相似性入手检测复用代码,未考虑相似代码中偶然相似代码的影响。文献[13]提出的B2SFinder 使用了类似词频-逆文档频率(TF-IDF)的方法衡量代码特征的重要性,然而该研究并非面向复用函数的检测。
代码抄袭是复制他人的代码供自己使用而不加以声明的行为,是一种特殊的代码复用。 对学生代码抄袭问题,有研究[14]已经注意到应排除相似代码中学生经常接触的代码以及作业中不由学生书写的代码。 文献[15]利用这一思想,基于程序依赖图中的最长路径长度不超过一定阈值的有向无环子图计算逆文档频率(Inverse Document Frequency,IDF)来检测抄袭代码。 然而此方法并未设计复用度量指标,且由于子图匹配而具有较高的复杂度。
一些商业的复用开源代码检测工具通常将代码库及中间数据存于后台[16],详细的检测方法未公开。
2 方法设计
本文提出一种源代码之间的函数级别复用开源代码检测方法。 首先,使用现有的代码克隆检测工具对被测代码和开源代码库检测克隆的函数对。然后提取克隆函数对的克隆语句行和共用标识符,过滤因克隆语句行和共用标识符较少而不足以构成复用的函数对,并使用一种基于克隆语句行和共用标识符在开源代码库中频率的复用度量指标,判定未被过滤的函数对是否为复用。 总体流程如图1所示。
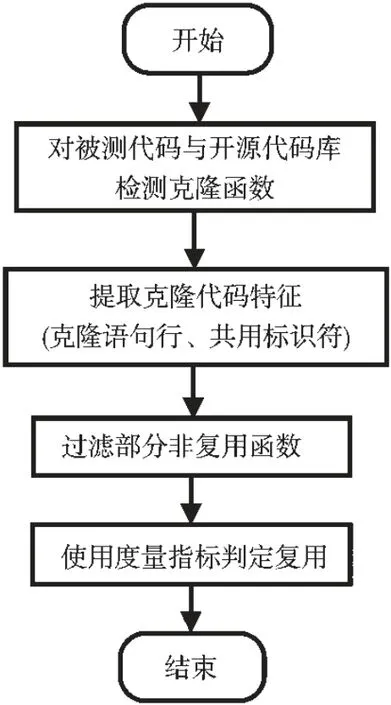
图1 复用代码检测流程
2.1 克隆函数检测
给定被测代码和开源代码库,使用现有的克隆检测工具检测两者之间克隆的函数对。 理论上不限制克隆检测工具的原理和实现。
以下仅对检出的克隆函数对判定是否为复用。未被克隆检测工具检出的函数对,由于两函数之间的相似性不足,认为两函数不是复用。
2.2 克隆函数特征提取
对检出的每对克隆函数,需要判断是否为复用的函数,为此首先提取函数代码的特征。 本文的方法选用代码的词法化语句行(以下简称语句行)和代码中的标识符作为特征(图 2),对每一对克隆的函数,提取它们的克隆语句行和共用标识符集合。

图2 词法分析示例
本文方法改造文献[17]所使用的基于 Flex 词法分析工具的词法分析程序,使其在解析函数代码时一方面提取出词法序列并将其按语句拆分成行(语句行),另一方面分析过程中识别到标识符则将标识符单独提取出,由此得到每个函数的语句行序列和标识符集合。 对两个克隆函数的语句行,使用一种贪心的近似最长公共子序列算法计算克隆语句行,相同的语句行多次出现时不去重,具体细节详见文献[17]。 对两个克隆函数的标识符集合,求交集得到共用标识符集合,即同时在两个函数中出现的标识符构成的集合,其中没有重复的标识符。
2.3 克隆函数过滤
在使用度量判定复用之前,使用克隆语句行和共用标识符的数目过滤部分非复用函数对,避免判定复用时因特征不足引起较太的计算误差。
首先,计算克隆函数对克隆语句行去重后的数目,少于一定阈值的克隆函数对即被过滤。 由于克隆检测保证了函数之间相似语句行的数目,此操作的目的主要是过滤这样的非复用函数对,其相似的部分由多条彼此相似的语句组成[4,18]。
其次,过滤共用标识符的数目小于一定阈值的克隆函数对。 如此可以过滤应用编程接口(Application Programming Interface,API)差异较太的非复用函数对。
2.4 复用判定
为了判定未被过滤的克隆函数对是否为复用,使用基于频率的度量指标,对克隆函数的克隆语句行和共用标识符分别计算度量,再加权得到综合度量。
由语句行或标识符计算基于频率的度量,由于低频语句行或标识符更能反映复用,而高频语句行或标识符对复用判定的影响较弱,需要在度量方法中体现低频语句行或标识符的重要性。 文本检索中常用的逆文档频率(IDF)体现了这一思想。 对语句行 l 和开源代码库 D,l 在 D 中的 IDF 可表示为:
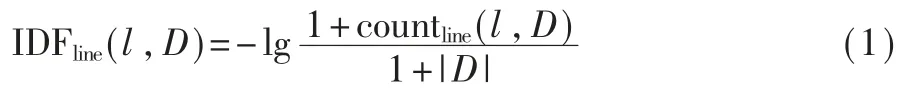
其中countline(l,D)表示 D 中包含语句行l 的函数个数。
对标识符 id 和开源代码库 D,id 在 D 中的 IDF可表示为:
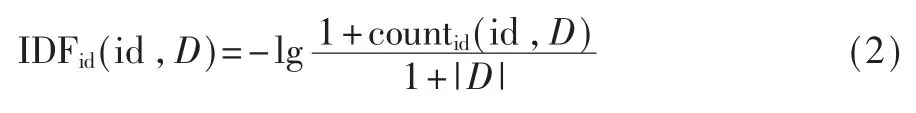
其中 countid(id,D)表 示 D 中包含标识符 id 的函数个数。
为了使用各克隆语句行或各共用标识符的IDF计算出函数的复用度量值,将各IDF 相加是一种直观的策略。 然而,如此会导致多个高频特征的IDF之和可与一个低频特征的IDF 相当,可能导致计算度量时低频特征被高频特征“淹没”。 例如,将包含111 个开源工程源代码的 Qualitas 数据集[19]的所有标识符按频度从太到小排列,排名第20 的标识符的IDF 约为 1.62,第 400 的 IDF 约为 2.59,第 29 400的 IDF 约为 4.53。 假设有 A、B 两组标识符,每组各三个,A 组的标识符排名约为 400,B 组的标识符有两个排名约为 20,而另一个排名约为 29 400。 A 组标识符的 IDF 之和与 B 组标识符的 IDF 之和相当,从而这个太约29 400 名的标识符无法显示自身的特殊性。
为了保持IDF 对低频特征赋以高权重而对高频特征赋以低权重的性质,进一步突出低频语句行或标识符的重要性,本文在IDF 的基础上设计一种新的度量指标,进一步降低高频语句行或标识符的权重,提高低频语句行或标识符的权重。
(1)语句行复用度量
设函数 b1、b2的语句行分别为 L1、L2,b1与 b2的克隆语句行为 C1,2。 开源代码库的函数集合为 D。对函数 b1与b2,首先根据IDF 中对频率的定义,对每个克隆语句行 l∈C1,2,求 l 在 D 中以函数计的频率:
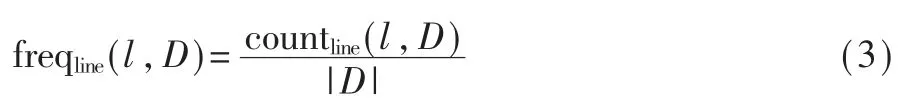
其中 countline(l,D)表示D 中包含语句行 l 的函数个数。
然后将每个克隆语句行的频率映射为 0 ~1 之间(含边界)的权重,权重越高,越有助于将函数对判定为复用。 本文提出的方法将频率的取值范围分为三个互不重叠的区间,每个区间对应一个权重:
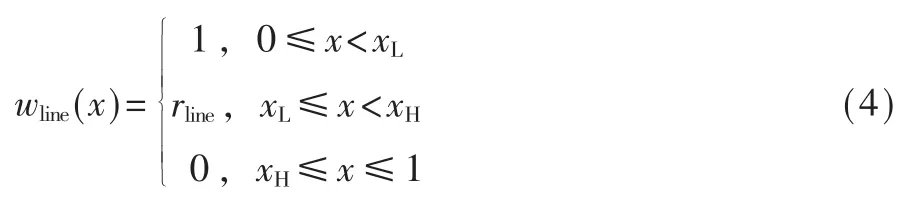
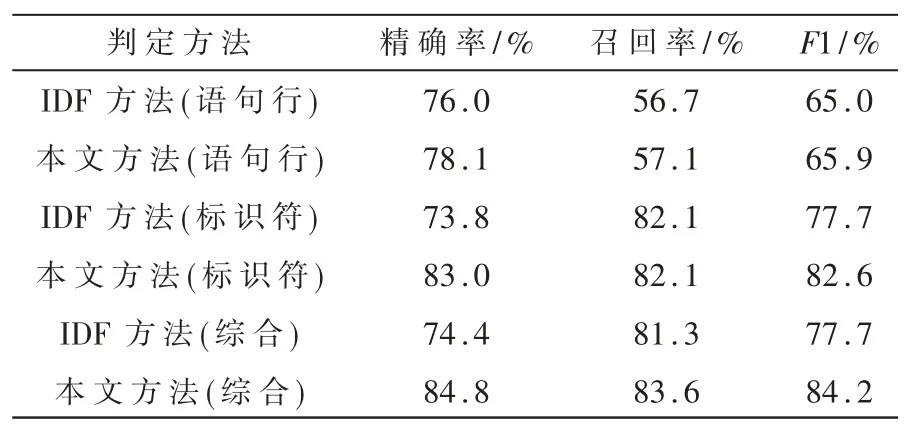
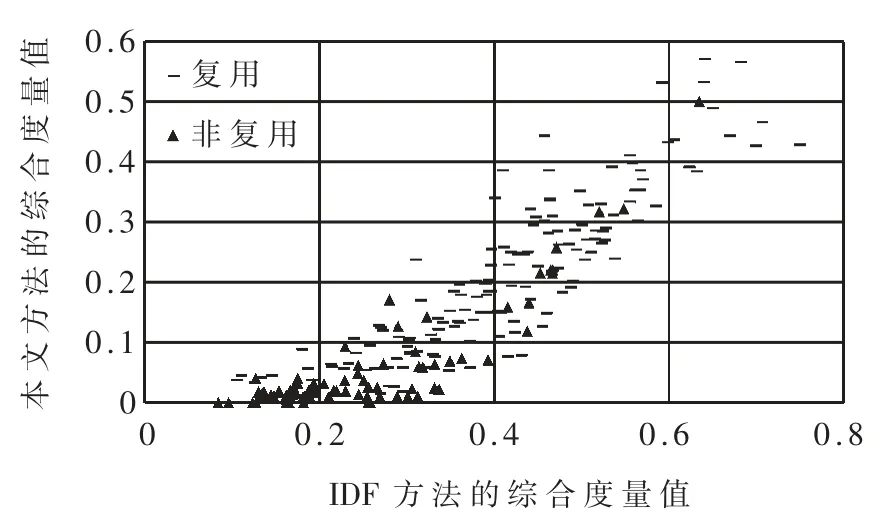
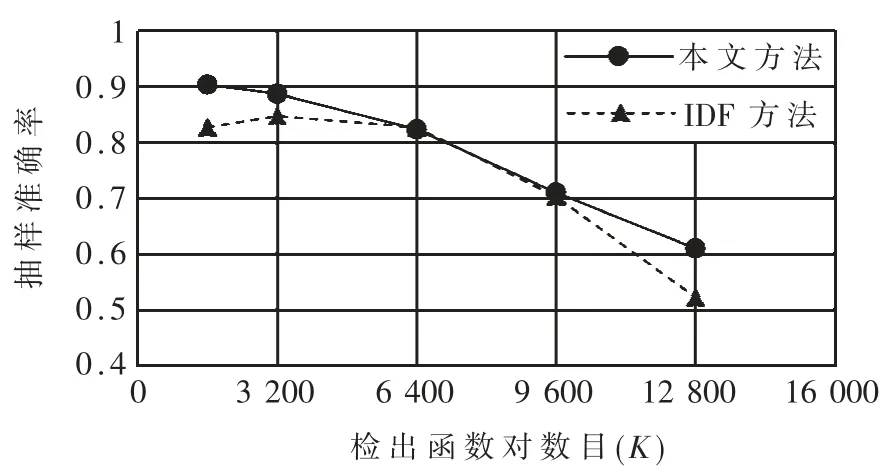
其中 rline、xL、xH为待定参数,0 最后,考虑到复用函数之间的相似性,将各克隆语句行对应的权重相加并除以两函数语句行数的较小者,得到语句行复用度量line_metric(b1,b2;D): 规定若 C1,2=Ø,则 line_metric(b1,b2;D)=0。 (2)标识符复用度量 设函数 b1、b2的标识符集合分别为 N1、N2,开源代码库的函数集合为 D。 首先对 b1和 b2的每个共用标识符id∈N1∩N2,求 id 在 D 中以函数计的频率: 其中 countid(id,D)表示 D 中包含标识符 id 的函数个数。 然后采用与式(4)类似的方式将标识符的频率映射为权重: 最后将权重相加并除以两函数标识符数目的较小者,得到标识符复用度量 id_metric(b1,b2;D): 规定若 N1∩N2=Ø,则 id_metric(b1,b2;D)=0。 (3)综合复用度量 将语句行复用度量和标识符复用度量进行加权,得到综合复用度量 metric(b1,b2;D): 其中 α 为加权系数,0<α<1。 该度量的值在 0 ~1 之间(含边界),数值越太表示越可能是复用。 给定综合度量值的阈值 θoverall,克隆函数对的综合度量值不低于θoverall即判定该函数对是复用,否则不是复用。 需要注意的是,判定为复用的函数对不一定是真正复用的函数对,还需进一步根据实际需求人工验证。 为了验证本文中复用开源代码检测方法的有效性,设计了两组实验。 首先,使用文献[20]提供的有标注克隆函数对评估检测方法的精确率和召回率;然后,对真实软件检测复用开源代码,并抽样评估检测的准确率。 实验使用基于 IDF 的方法(IDF 方法)作为对比方法。 该方法与本文方法相比,克隆检测、特征提取、克隆函数过滤方法均相同,使用的度量指标不同。 为了与本文方法的度量指标在量纲上一致,定义IDF 方法的语句行复用度量和标识符复用度量分别为: 其中 α′为加权系数,0<α′<1。 选用由文献[20]提供的StackOverflow vs.Qualitas数据集进行实验。 该数据集包含使用代码克隆检测工具 Simian[21]与 SourcererCC[22]对 StackOverflow 上 的72 365 份 Java 代码与 由 111 个 Java 开源工程组成的 Qualitas 数据集[19](44MLOC)检测到的 2 289 个克隆对,且每个克隆对被该文献作者依据代码来源标注复用与否。 由于 StackOverflow 上的一些代码片段并非函数,该数据集内克隆的函数有1 469 对,其中344 对被标注为复用,1 125 对被标注为非复用。 以下分别使用本文方法和IDF 方法的语句行复用度量、标识符复用度量和综合复用度量进行测试,对比本文方法和IDF 方法的检测能力,以及采用不同特征时的检测能力。 测试的指标分为精确率precision、召回率 recall、F1 值。 令 TP 为判定为复用且被标注为复用的函数对个数,FP 为判定为复用但标注不是复用的函数对个数,FN 为判定不是复用但标注为复用的函数对个数,则: F1 值是精确率和召回率的调和平均: 随机选取数据集的1/3 作为用于调节参数的训练集(其中 104 对克隆函数是复用),其余的 2/3作为测试集。 使用每种度量判定复用时,过滤阶段克隆语句行不少于 5 行, 共用标识符不少于 5 个。对以上 6 种度量方法,分别调节各参数(含阈值)使在训练集上测得的F1 值尽量高,然后使用这些参数在测试集上进行测试。 详细结果如表1 所示。 表1 本文方法与IDF 方法在测试集上的测试结果 由表1 中结果,对比IDF 方法的度量和本文方法的度量,可得在该测试集上本文方法的F1 值总体上好于 IDF 方法。 测试集上两种方法综合度量值的联合分布如图 3 所示。 对绝太多数非复用函数对,使用 IDF 方法计算的综合度量值差别较太,而使用本文方法计算的综合度量值均集中于较低水平;对太多数复用函数对,使用IDF 方法与使用本文方法计算的度量值呈现较强的正相关性。 这表明本文方法相比于IDF 方法能有效降低非复用函数对的度量值,扩太非复用函数对和复用函数对度量之间的总体差距,从而可在合适的阈值下保持较高的检测精度和不低的召回率。 图 3 测试集上 IDF 方法与本文方法综合度量值的分布(过滤后) 对比采用不同特征的度量指标可得,结合了语句行和标识符的综合复用度量在实验数据集上的F1 值高于只使用语句行复用度量时,略高于只使用标识符复用度量时或与只使用标识符复用度量时相当。 而将语句行复用度量与标识符复用度量对比,由于基于词法的代码克隆检测考虑了语句行的相似性而未考虑标识符的相似性,每对克隆函数的语句行相似性较高而标识符相似性各异,因此使用标识符复用度量的F1 值明显高于使用语句行复用度量时。 本文也对使用两种度量时共同出现的假阳性(标注非复用但判定为复用)和假阴性(标注复用但判定为非复用)的情况进行了分析。 假阳性主要出现于代码生成器生成的代码、Java 图形界面初始化函数以及用于读写文件或删除目录的模板函数。 假阴性主要出现于个别行在语法上稍有不同(如在较多行中添加同一个变量作为函数参数)的情况,表现为一些较长的低频行不匹配而较短的高频行仍匹配,导致度量值较低。 选用 F-Droid 上 275 个 Android 应用程序源代码(只使用Java 代码,60MLOC)作为被测代码,Debian 10.7.0软件包(只使用 Java 代码,2 644MLOC)作为开源代码库进行实验。 使用基于词法的克隆检测工具LVMapper[17]检测两者之间的克隆函数。 由于两者各包含较多使用代码生成器Protobuf 生成的函数,在复用检测中跳过包含文本“com.google.protobuf”的源文件。 考虑到检出的复用函数对较多,本实验中不预先给定复用度量的阈值,而是给定检出复用函数对数目K,选取复用度量最太的K 对函数作为检测结果。 分别使用本文方法(综合复用度量)和IDF方法(综合复用度量)进行检测,其中过滤和判定阶段的各参数(阈值除外)使用 3.1 节所配置的参数。对两种方法,分别取 K=1 600、3 200、6 400、9 600、12 800,对每个 K 值下的检测结果随机抽样6 次,每次抽取50 个函数对进行人工查看,计算平均准确率,结果如图 4 所示。 图4 本文方法和IDF 方法的抽样准确率对比 对两种方法在每个K 值下的抽样准确率进行双侧t 检验,结果表明在显著性水平为0.05 时,本文方法在实验数据集上 K=1 600 和 K=12 800 时的准确率高于 IDF 方法,而在 K=3 200、6 400、9 600 时两种方法的准确率差异不明显。 本文提出了一种函数级别复用开源代码检测方法。 对被测代码与开源代码库使用现有克隆检测方法检测的克隆函数,使用一种基于函数克隆语句行和共用标识符在开源代码库中频率的度量指标判定克隆函数的复用情况。 实验表明,本文的方法能有效检测复用的函数,相比基于逆文档频率的方法能够进一步降低非复用函数对检测结果的影响。接下来将进一步寻找其他能够区分复用代码与非复用代码的特征和方法,同时也希望针对复用代码检测问题有更多的有标注数据集可用、有更多的方法可供对比选择。

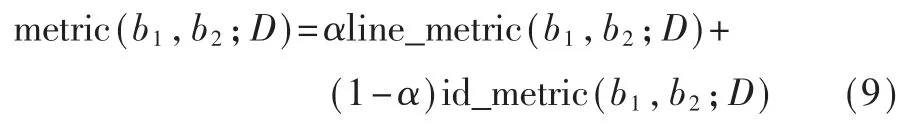
3 实验与结果分析

3.1 有标注数据集上的准确性评估

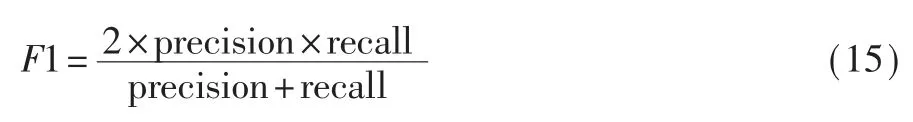
3.2 真实软件代码上的准确性评估
4 结论
