一种单模型多风格快速风格迁移方法
2021-06-23朱佳宝张建勋陈虹伶
朱佳宝,张建勋,陈虹伶
重庆理工大学 计算机科学与工程学院,重庆400054
在短视频兴起的时代,各种风格滤镜效果备受人们喜爱,图像风格迁移技术已经广泛地被人们熟知。然而,许多图像风格迁移方法一个模型都只能针对一种风格,在应用上效率低下。
Gatys等人[1]在2015年首次提出一种基于卷积神经网络的统计分布参数化纹理建模方法,他们发现VGG(Visual Geometry Group)网络的高层能够很好地表达图像的语义风格信息,网络的低层能够很好地表示图像的内容纹理特征信息,通过计算Gram矩阵来表示一种风格纹理,再利用图像重建的方法,不断优化迭代来更新白噪声图像的像素值,使其Gram矩阵与风格图Gram矩阵相似,最后重建出既具有风格图的风格又具有内容图像的内容,这一研究引起了后来学者的广泛研究,并成功使用深度学习技术来进行风格迁移。
文献[2]从理论上验证了Gram矩阵为什么能够代表风格特征,认为神经风格迁移的本质是匹配风格图像与生成图像之间的特征分布,并提出一种新的在不同层使用批归一化统计量对风格建模方法,通过在VGG网络不同层的特征表达的每一个通道的均值和方差来表示风格,为后续研究提供了风格建模的参考。这些方法都是在CNN(Convolutional Neural Networks)网络的高层特征空间提取特征,高层特征空间是对图像的一种抽象表达,容易丢失一些低层次的信息,比如边缘信息的丢失会造成结构上形变。文献[3]提出在风格迁移的同时应该考虑到像素空间和特征空间,在Gatys提出的损失函数基础上,将在像素空间的内容图进行拉普拉斯算子滤波,得到的结果与生成图之间的差异作为一个新的损失添加进去,弥补了在抽象特征空间丢失低层次图像信息的缺点。文献[4]分别将内容图像与风格图像进行语义分割,来增强图像的边缘真实性。
文献[5]提出了一个取代Gram损失的MRF损失,将风格图与生成图分成若干块,对每个生成图中的块去寻找与其最接近的风格块,这种基于块匹配的风格建模方法比以往的统计分布方法有的主要优势在于,当风格图不是一幅艺术画作,而是同样的摄影作品,可以很好地保留图像中的局部结构等信息,提高了模型的泛化能力。文献[6-7]在Gatys的方法基础上,提出一种快速风格迁移方法,通过一个前向网络去学习一个风格,前向网络基于残差网络设计,损失函数依然采用Gatys的算法。文献[8]对基于块匹配的风格迁移算法做了改进,引入生成对抗网络,使用鉴别器来替代块匹配这一过程,加速了风格迁移的效率。
这些方法在静态图像的风格迁移任务中,对于每一个风格都需要单独训练一个模型,不利于工业的落地使用。对于有很多种风格的应用来说,每一个模型都会占用大量的存储空间,鉴于此,很多学者就开始研究利用一个模型去学习多种风格。文献[9]提出通过发掘出不同风格网络之间共享的部分,然后对于新的风格只去改变有差别的部分,共享的部分保持不变,他们发现在训练好的风格网络基础上,只通过在Instance Norlization层做一个彷射变换,每个新风格只需要去训练很少的参数,就可以得到一个具有完全不同网络风格的结果。文献[10]提出一种自适应实例正则化层(AdaIN),通过权衡内容特征与风格特征之间的均值和方差,实现了一种多风格迁移模型,但是这种方法会对迁移纹理呈现块状干扰。文献[11]提出将任意风格图像的语义信息对齐风格特征来重建内容特征,不仅在整体上匹配其特征分布,又较好地保留了细节的风格信息。但是这种方法会在一定程度上造成模糊的情况。文献[12]把风格化网络中间层称为StyleBank层,将其与每个风格绑定,对于新风格只去训练StyleBank层,其余层保持不变。文献[13]通过预测实例正则化的参数来适应不同的内容与风格样式,虽然实现了任意内容与风格的转换,却降低了风格化的效果。
假设应用需要有n种风格化迁移场景,就需要有n种模型堆砌在应用中,势必会造成应用占用大量资源,并且用户体验也会下降。针对这种问题,本文提出一种可学习的线性变换网络,可以接受任意的一对内容图像和风格图像,使用两组CNNs网络来作为转换网络模块,以此来拟合被风格迁移广泛使用的Gram矩阵,一组用来拟合内容特征,另一组用来拟合风格特征。通过实验得出,本文的风格迁移方法具有更高的灵活性,风格化效果也大有提示,并能够很好地应用在视频风格化领域。
1 单模型单风格迁移方法
单模型是指训练一个模型,单风格是指这个模型只能迁移一种风格。文献[7]在Gatys等人的方法基础上,提出去训练一个特定的前馈网络,来改善Gatys等人提出的风格迁移方法耗时的问题。主要是针对一张风格图去训练模型,在测试阶段只需要输入一张内容图像,就可以得到一个固定风格样式的图像。其网络结果如图1所示。
这种模型结构由两个网络组成,一个图像转换网络和一个损失网络。其中图像转换模型由一个下采样层、中间残差块层、后一个上采样层构成。训练阶段风格图像是固定的,只有一张,而内容图像则是使用COCO数据集,试图用一张风格图像来拟合多种内容图像,来达到一个快速迁移的效果。
其中x是输入图像,经过图像转换模块得到了风格化图ŷ,y s表示风格图像,yc表示的是输入的内容图像,其实yc=x。而后通过一个损失函数网络,分别计算ŷ与y c在不同网络层之间的内容损失,ŷ与y s之间的风格损失。网络中内容损失选择的是relu3_3层,风格损失是多层的组合,越低层风格化的效果越清晰,与内容纹理相近;越高层风格化的效果就越抽象,内容纹理越扭曲。
虽然基于训练前馈网络的方法能够提高风格迁移的速度,但是一个模型只能处理特定的风格,在实际应用上严重不足。因此,研究一种单模型多风格迁移方法有实际的应用意义。本文在该方法的基础上,提出一种改进方法,使得一个模型可以迁移多种风格。
2 改进的单模型多风格快速风格迁移方法
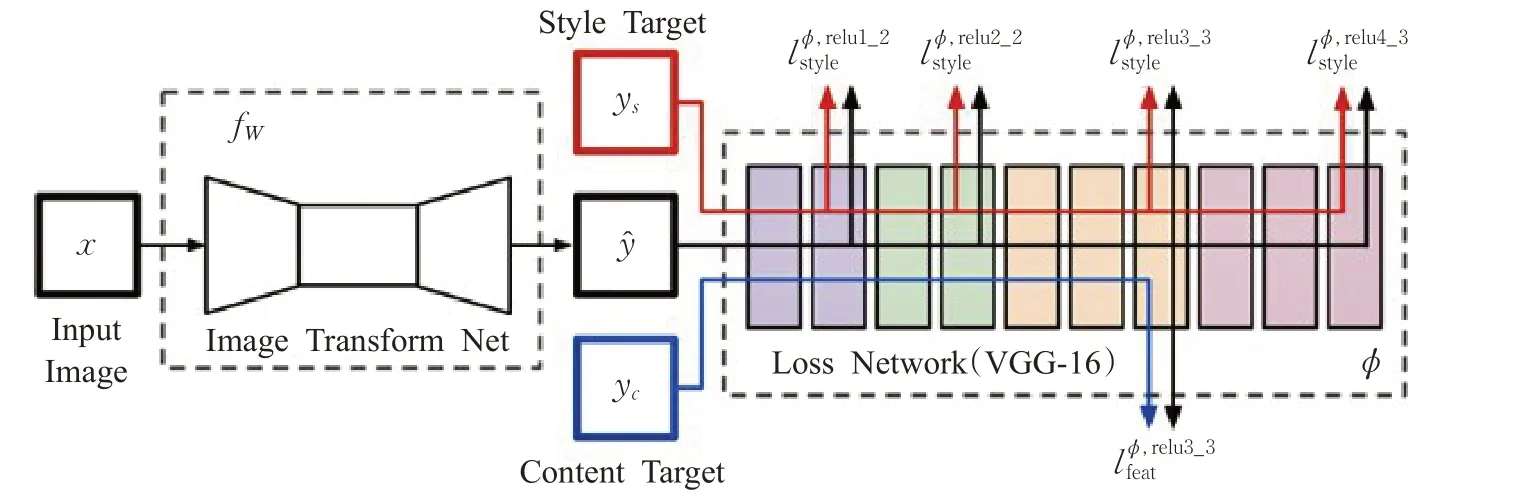
图1 单模型单风格迁移模型示意图
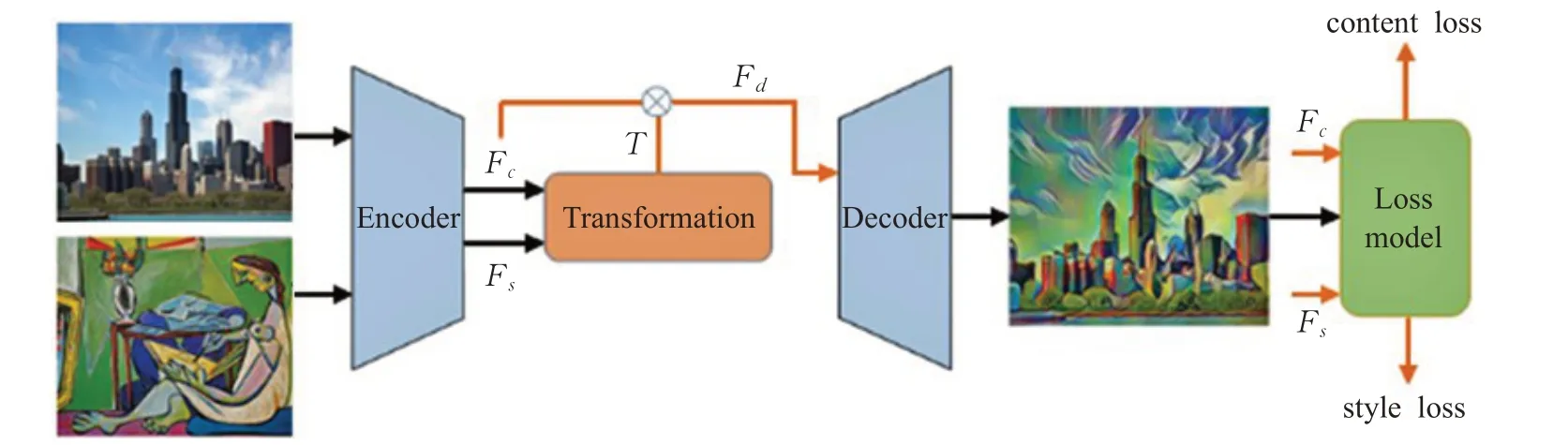
图2 改进的网络结构图
在风格迁移任务中,通常都是在一个网络中分别对内容图像和风格图像进行处理,通过一个预训练好的VGG分类网络,从网络提取出的高层特征,两张图像的欧式距离越小,说明两张图在内容上是相似的;从网络提取的低层特征,用Gram矩阵统计的共同特性越多,则表示两张图像的风格是越接近的。
但是,风格图像往往有其共同的相似性,比如印象派的风格拥有相似的笔触,它们只是色彩上有差异,梵高的画作与莫奈的画作也有很多相似之处。本文希望通过学习到不同风格之间的共同特性,使用线性变化来将任意风格迁移到内容图像上。
2.1 改进的网络结构
本文网络结构由三部分组成,一个是预训练好的编码器解码器模块,用来提取图像特征和重建图像,风格转换模块用来学习任意风格之间的线性变换,损失函数网络模块用来约束重建网络,生成出高质量的图像。本文网络的结构图如图2所示。
其中的Encoder、Decoder和loss model都是采用VGG网络结构,网络的输入是一对256×256大小的图片,通过Encode分别提取出内容特征F c和风格特征F s。文献[6]中直接将Fc与F s直接通过转换网络来重建图像,这些重建的图像细腻度较低,越低层的特征重建出的效果会越好,所以本文通过跳跃连接的方式,将Fc与转换网络输出结果进行连接,以此重建出更加细腻,更加符合内容图像特征的风格化结果。
2.2 多风格转换模块
大多数风格迁移研究人员都直接将F s作为风格的提取特征来和Fc进行对比计算,这种方式会随着风格图像的增多,风格化的质量逐渐下降。本文使用了一个中间虚拟函数ϕs来表示风格特征,ϕs可以对F s做非线性映射,即ϕs=ϕ(F s)。本文的优化目标是获得最小的F d,使得编码器输出的特征图与所迁移的风格特征图尽可能的匹配,其优化公式如下:

其中,N是像素个数,C是通道数,表示将特征向量F进行零均值化,表示F d与ϕs之间的最小中心协方差。并且,由公式(1)可知,当且仅当F向量模的平方最小时,才有最小值,即:
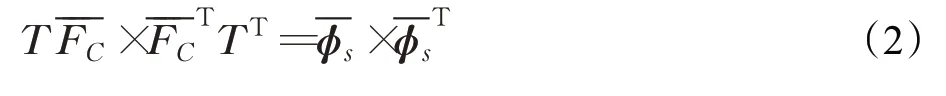
由奇异值分解可得:
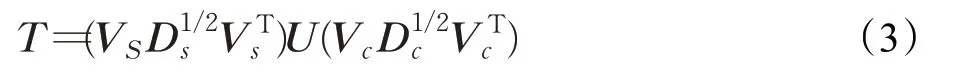
其中,U是一组正交基,可知转换迁移特征向量T都是由内容特征向量与风格特征向量之间的协方差矩阵决定的。为了避免大量的协方差之间的矩阵运算,本文设计的转换网络模块能够直接地输出结果矩阵,并将内容特征与风格特征项分开,网络转换模块设计如图3所示。
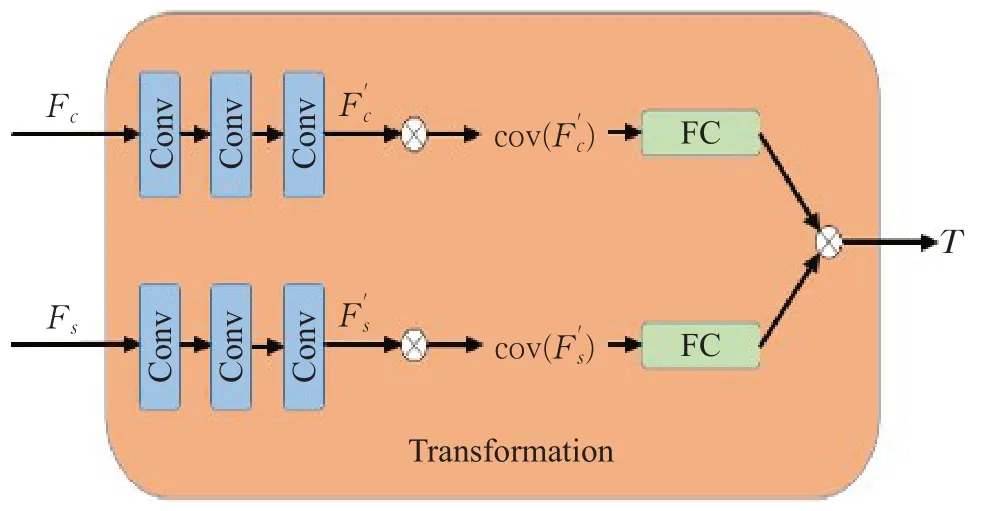
图3 转换网络设计图
对编码器输出的内容特征F c与风格特征F s设置单独的通道,包含3个卷积层,卷积核大小都是3×3,卷积核数量依次减半,将卷积操作得出的与其转置矩阵进行相乘得到其对应的协方差矩阵,在将得出的协方差矩阵通过一个全连接层,再与风格特征通道进行内积,得出转换矩阵T。
2.3 损失模块
本文采用组合的多级风格损失函数,风格特征损失主要将VGG网络的relu1_2、relu2_2、relu3_3三层进行合并,通过组合的多层次风格损失,用来增强转换网络的泛化能力。内容特征损失主要来自VGG网络的第relu3_3和relu4_3层。

风格损失计算方法与内容损失计算一致,都是采用二者特征激活值做距离差平方计算,是风格损失在三层网络中的平均值,其公式如下:
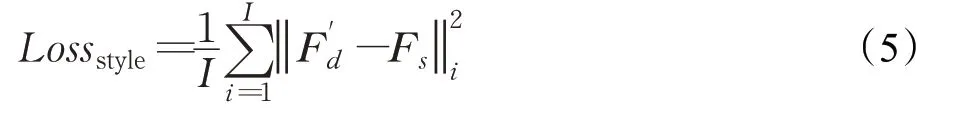
因此,本文的总损失函数为:

本文的损失模块设计图如图4所示。
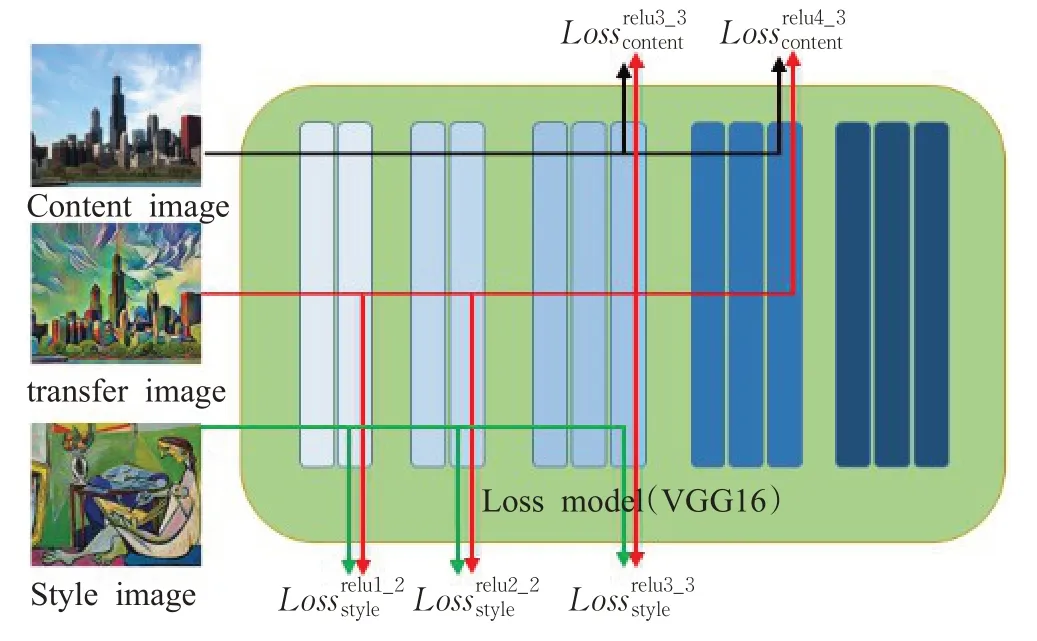
图4 损失模块设计图
高层的内容特征信息能够够重建出原图的内容,低层的风格特征信息能够更好地表示风格,所以本文没有取第5层的特征信息。本文的风格重建损失是VGG网络前三层损失之和,内容重建损失分别使用的是relu3_3层和relu4_3层,为了验证本文的转换模块是否能够灵活地适应不同层的风格损失,本文将使用不同的内容重建损失的生成效果进行展示,如图5所示。

图5 不同层内容损失与组合风格损失效果
根据图5实验结果,使用的组合风格损失能够很好地表现出风格图像的风格;使用relu4_3层的内容损失重建出来的图像,在纹理上更清晰,色彩上更加平滑。
3 动态视频风格迁移
动态视频风格化迁移通常是将视频拆分成一帧一帧的图像,将每一帧图像送入训练好的模型,得到风格化效果的帧图像,然后再将风格化帧图像重新组合成视频。但是这种方式特别依赖模型的规模,若是模型特别繁重,风格化过程会特别耗时,且容易造成抖动和闪烁的问题。
视频中的抖动和闪烁问题,多数领域都是添加光流[14]来加强时间一致性约束。Ruder等人[15]采用基于迭代优化的方式,通过添加光流一致性约束,来重点计算运动物体的边界,以此来保持风格化后视频的连续性,虽然这种方法能够解决视频闪烁的问题,引入光流的计算会带来更大的计算开销,会降低风格化速度。
第2章所介绍的模型,证明了本文的线性变换能够快速地适用于风格变换,并且网络是轻量的,它只有两组CNNS结构,共6个卷积层,2个全连接层,轻量的网络能够快速地完成风格迁移过程,能够产生稳定传输的视频。这是因为内容视频与风格化后的视频应该存在某种相似性,这种相似性应该是二者在像素和特征信息之间具备某种一定的相似性。在风格化过程中,这种信息相似关系会被保留下来。
事实上,静态图像风格迁移与视频迁移中的相似性保留是一致的,只是属于不同形式的矩阵表示关系,它们都可以用特征信息之间的线性变换表示。令Sim(F)表示特征之间的相似性保留,其相似性关系表示为:
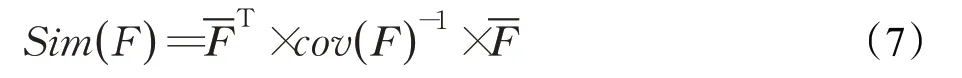
在本文的设计中,网络每层中输出的特征图大小决定了这种相似性所保留的尺度,为了使得这种相似性能最大化地保留,本文选择了更浅层的网络,在自编码器结构中,使用VGG网络relu3_1层作为输出,仅对风格样式进行一次特征提取,然后将其应用在所有帧上,这样可以减少大量的计算,且能够有效保持帧间的内容关联性,这是因为视频迁移中,帧间的内容关联性主要依赖于内容特征。其应用结果在本文的4.4节展示。可以发现,使用线性变换来映射风格迁移能够有效地应用在动态视频迁移,并且对于运动物体也能有效地解决闪烁和抖动的问题。
4 实验结果与分析
下面介绍本文实验的相关软硬件环境及训练细节:
(1)硬件环境:处理器为Intel®CoreTMi7-8750H CPU@2.20 GHz,8 GB DDR4内存,显卡为NVIDIA GeForce GTX1050Ti 4 GB独立显卡。
(2)软件环境:Linux Mint19.2操作系统,Python3.6,CUDA9.2,troch0.4.1-cu92,opencv3.6等相关工具包。
4.1 数据集
本文实验内容数据集使用MS-COCO,使用Kaggle比赛上的Painter by numbers WikiArt数据集作为本文的风格数据集。其中内容数据集有80 000多张图片,图像内容多种多样,包括人物照、风景照、建筑照等;风格数据集有8 000张图片。
4.2 训练细节
由于数据集里面图片大小不一,所有图片送入网络前都需进行预处理,保持图像之间的比例关系,将大小重新调整为300×300,然后从中随机裁剪出256×256大小区域作为训练样本输入,因此网络可以处理任意大小的输入。
本文将网络分为两步训练,首先训练对称的编码器、解码器结构来重建任意输入图像,使用在ImageNet上预训练好的VGG网络作为初始化参数,当训练损失稳定时结束训练,然后将其参数固定,最后训练转换网络。本文BatchSize设置为1,其中内容损失权重为α=1,风格损失权重β=0.02,这是为了使得重建出的风格图像能够保留更多的内容信息,学习率为0.000 1。
4.3 实验对比结果
为了验证本文方法的有效性,本文分别与Johnson[6]、AdaIN[10]、Avatar-net[11]和Ghiasi[15]的方法进行比较,风格化实验效果如图6所示。分别测试了三种风格类型的迁移效果,第一行是对梵高的油画作品进行风格迁移,从图中可以看到,Johnson和AdaIN方法的风格化纹理迁移过重,导致生成图片天空处显得杂乱,Avatar-net方法能够较好地匹配内容与风格特征,只是生成效果显得暗淡,Ghiasi的方法在天空区域风格纹理过重,本文的方法能够更好地匹配内容与风格特征,且生成效果更具观赏性。第二行是对素描风格类型进行迁移,输入的是一张年轻女性头像,其中Johnson的方法在眼睛处风格效果不佳,AdaIN方法在纹理上显得粗糙,Avatar-net方法风格化后在嘴角鼻子出显得扭曲,Ghiasi的方法在头发脸颊等处迁移效果不够细腻,而本文方法能够在脸部细节与头发纹理上都有着最好的表现。第三行是对密集风格块类型进行迁移,其中Johnson的方法纹理迁移过重,AdaIN方法纹理已变得模糊,Avatar-net方法在建筑边界区已信息丢失,Ghiasi的方法对风格样式的模块化迁移纹理太重,导致风格化效果有很多杂乱的小方块,而本文的方法重建出的图像纹理信息保存完整,风格化效果也比较完整,没有出现大的扭曲现象。
本文的生成效果能够更好,得益于转换网络采用了双通道结构,将内容特征与风格特征分开处理,减少了噪声的引入,所以生成的图像内容与风格之间才能有较少的干扰。
4.4 视频风格化效果
本文选用了一段健身爱好者跑步的视频作为实验数据,时长共33 s,首先使用ffmpeg将视频拆分成一帧一帧的图像,总计拆分为338帧图像。本文将该动态视频转换为具有梵高画作的风格视频,并对关键帧的结果进行展示,如图7所示。
该实验数据包含镜头的变换,镜头从前往后在拉近,从结果可以看出,本文的风格迁移算法在运动物体上具有很好的稳定性,不需要添加光流等方法,就可以迁移出具有稳定的帧图像,也没有出现迁移过度的问题,帧图像上的影子等场景也没有被风格化侵蚀,整体上来说,本文方法的迁移效果质量完成度高,内容图像特征保留完整,风格化效果适中,风格化速度快。
为验证本文方法在视频风格迁移中更具有效性,分别与Avatar-net和AdaIN方法进行对比,抽取上述视频中第10帧、第224帧与第329帧图像进行展示,其结果如图8所示。

图6 三种风格类型的迁移效果实验结果对比图

图7 关键帧风格迁移效果

图8 关键帧效果对比图
从结果展示可以看出,本文的方法出现的伪影较少,风格化效果最佳。
4.5 评价指标
由于风格化难以有定量的实验值来作为评价,其好坏的评价受个人主观因素的影响。大多数的研究人员都是采用与其他实验结果进行对比来作为评价方法。本文主要采用峰值信噪比(PSNR)与结构相似性(SSIM)来作为度量方法。
PSNR用来衡量图像的生成质量,SSIM用来衡量图像的结构相似性,这两个值越大表示风格化的图像质量越高,以运行时间复杂度为指标,本文以256×256大小的图像作为测试数据,以i7-8750H CPU作为计算处理器,分别与Johnson、AdaIN、Avatar-net和Ghiasi的方法进行比较,其结果如表1所示。
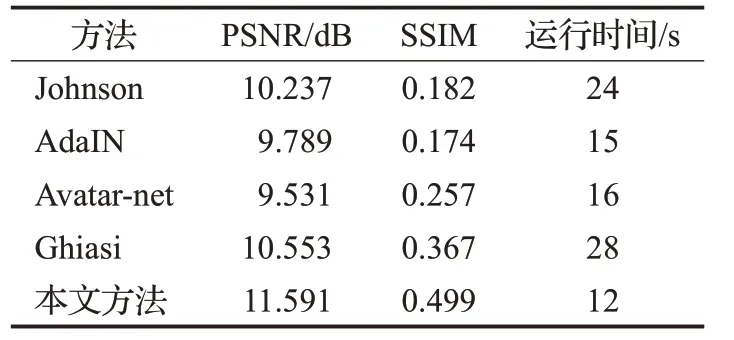
表1 定量分析结果及运行时间对比
从表1中可以观察出,峰值信噪比本文得到11.591的分数,比其他四种都要高一些,说明本文方法生成的图像质量最高。结构性本文方法获得0.499的分数,同样比其他方法要高,说明本文方法生成的图像与内容图像具有更高的相似性。
由于本文方法没有使用Gram矩阵,减少了大量的矩阵运行,所以本文方法在所需要使用的运行时间更少。
5 结束语
以往的风格迁移模型,每个模型只能对应一种风格,当迁移其他风格图像的时候就需要重新去训练模型,使得应用效率低下。本文通过提出一种线性变换的轻量网络结构,使得单个模型可以迁移任意风格,大大改善了在实际应用上的能力;且在实验效果上相比其他方法有一定的提升,并且对动态视频帧也有一定的风格约束能力。
