为什么这么强?深度观察苹果M1 SOC
2021-06-20张平
张平

苹果在2020年作出的最重要举动就是推出了搭载自研M1芯片的全新系列笔记本电脑。相比英特尔的产品,苹果宣称这款名为M1的芯片拥有更为出色的效能和更低的电力消耗。随后的实测结果显示,苹果M1的确展示出了卓越的性能,甚至一度超越了英特尔的旗舰产品。那么,苹果是如何做到这一点的?这款SoC的设计有何独特之处呢?
苹果是全球移动产业最强大的企业之一,这一点也反映在苹果旗下的产品上。虽然在每次发布会上,苹果都很少从技术层面介绍自家的SoC产品,但是其强悍的性能、极高的性能功耗比往往会在实际产品上市后给用户和业界带来震惊,甚至部分性能超过了相近时间发布的其他厂商的SoC的生能的数代之多。
在M1发布后,各大媒体迅速对这款产品进行了测试,测试数据表明,M1的CPU性能在包括CineBenchR23、GeekBench 5、GFXBench等多种、多类型的测试中都取得了卓越的成绩。在CineBench R23的单线程性能、GeekBench 5的单线程性能测试中,M1的CPU性能甚至可以和全新的Zen 3架构的锐龙9 5950X以及英特尔第11代酷睿系列处理器打得有来有回,甚至部分性能还能有所超越。
那么,一个值得探讨的问题就出现了。苹果的M1的CPU性能为什么这么出色?它真的超越了目前的桌面顶级产品吗?对于这一些问题,本文尝试通过一些探讨和数据来予以解释。需要提前说明的是,由于苹果在产品细节和技术细节上的缺失,本文的部分内容属于探讨性质,可能和实际情况存在差异,建议大家参考阅读。
苹果M1:一颗复杂的SoC产品
首先需要明确的一点是,苹果M1芯片并不是一个单一的CPU或者GPU,它是一个包含了包含了CPU、GPU、ISP、NPU、DSP、缓存等诸多单元模块的SoC产品。它采用的是台积电的5nm工艺,包含了大约160亿个晶体管。
在相关组成部分方面,M1包含了4个Firestrom高性能CPU核心和4个Icestrom低功耗CPU核心,以及一个规模较大的、拥有8个核心的GPU(包含了1024个EU单元),此外还有拥有16核心的NPU单元、所有核心共享的系统级别缓存。内存方面支持双通道64bit LPDDR4X 2133内存,还拥有包括PCle总线控制器和雷电4接口控制器这样的外部链接单元模块等。
从M1的设计和规模来看,苹果的目的是要在一个芯片上达成几乎所有的功能,同时实现性能和功耗的平衡。作为面向性能市场的产品,M1这样的做法在之前其他厂商那里完全没有出现。因此,必须很深入地了解苹果在M1的CPU部分做了什么又做对了什么,才能理解为什么M1的CPU部分为何拥有如此出色的性能表现。但是令人遗憾的是,苹果现在公布的资料远远不足,我们依旧只能通过第三方手段和报道才能管中窥豹了解M1这颗堪称划时代产品的一角。
多就是好:Firestrom核心晶体数量巨大
苹果一直以来几乎不发布任何有关产品的内部细节设计,尤其是芯片类产品。因此,这部分的分析将从第三方资料入手。可能和实际情况存在差异。
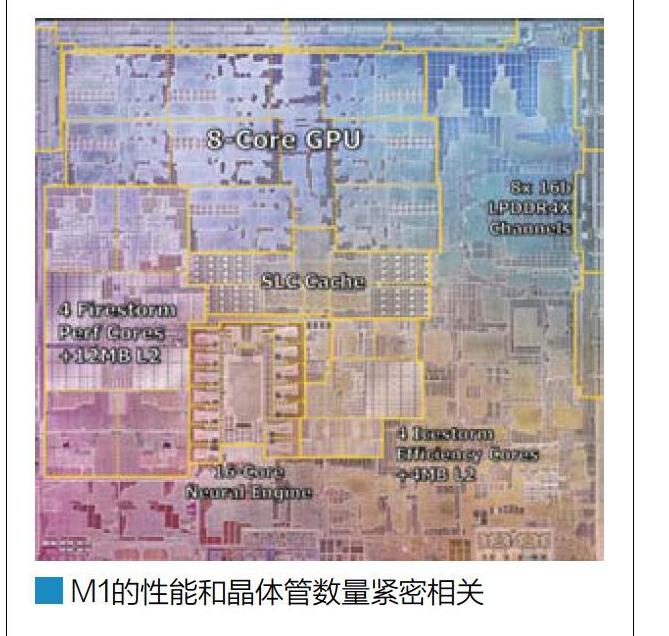
从现在第三方媒体公布的M1的晶圆照片来看,其中最大部分的面积是GPU,大概占据了整个M1 lg%的面积。接下来则是4个FireStrom大核心和12MB L2缓存,大约占据了13%的芯片面积。
考虑到整个M1 SoC拥有160亿晶体管,并假设整个SoC上晶体管密度是均匀分布的。那么,M1的GPU部分大约有30亿晶体管,与此类似的是,M1 SoC的4个高性能CPU搭配12MB L2缓存则占据了20亿晶体管。
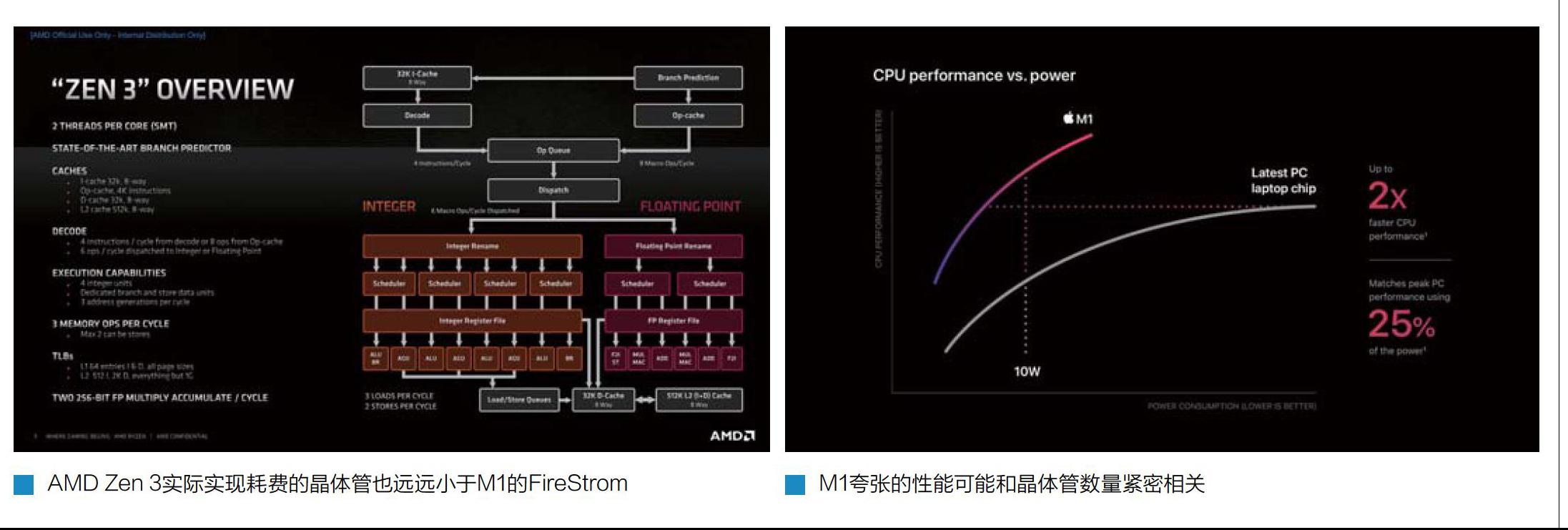
在晶体管数量明确后,我们可以用于对比目前比较主流的处理器了。比如AMD之前公布过Zen 3架构的每个CCD的晶体管数量为41.5亿,拥有8个核心和总计约36MB缓存( 12+13)。如果这个数据减半的话,比如4个核心搭配18MB缓存,那么大约占据20.5亿晶体管。相比M1 CPU部分的数据,AMD Zen 3在缓存多了6MB的情况下,晶体管数量基本持平,这也意味着苹果的M1的FireStrom大核心的每一个核心所使用的晶体管数量是显著大于AMD Zen3的,也就是说M1的CPU架构要比Zen3更为庞大。
从台积电公开的一些数据来看,台积电的7nm工艺每平方毫米大约可以容纳0.9亿个晶体管。对苹果而言,根据同为5nm工艺的A14芯片的最终效果,台积电的5nm工艺密度相比7nm提升了49%,为每平方毫米1.34亿,每平方毫米约1.34亿晶体管。考虑到1MB SRAM在6T的情况下拥有约5000万个晶体管,但往往SRAM在实际使用中可能会使用8T或者10T的版本,因此综合来看,1MBSRAM以0.7亿晶体管计算,那么可以估计出7nm工艺下1MB SRAM的面积约为0.8平方毫米,5nm工艺下为约为0.5平方毫米。
有了上文的数据,本文再度假设这些数据和AMD、苹果最终产品呈现出来的实际数据是基本相当的。
这样一来,Zen 3每个核心除去L2+L3缓存的话,大约拥有(41.5-36x0.7) /8=约2亿晶体管,占据核心面积是2.2平方毫米。苹果的M1的高性能核心每个核心则拥有( 20-12x0.7) /4=2.9亿晶体管,每个占据核心面积为2.16平方毫米。在这种粗略的计算下,苹果的高性能核心每个核心的晶体管数量比AMD的Zen3多出了接近1亿。也就是说,苹果M1 Firestrom核心的晶体管用量,是AMD Zen 3晶体管用量的大约1.5倍左右。当然,这个数据是估计值,极有可能和实际情况差别很大,但无论怎样,苹果M1使用的Firestrom核心史无前例地大,那是肯定跑不掉的。
这样的结果就很有意思了。因为对现代CPU设计来说,其基本的设计理念和道路都是非常明确的,在当前物理条件下,AMD、苹果乃至英特尔、ARM等厂商在CPU在设计中获取最大化的性能或者性能功耗比的手段是基本是一样的,因此很难或者基本不存在某个厂商擁有突破级别的技术。之所以市场上存在各种独特的CPU产品,那是因为其面向的对象、竞争优势的区间以及成本衡量存在巨大差异。当然,部分厂商依旧拥有自己独特的优势,比如英特尔在分支预测方面一直独步业界,但是综合来看,如果约束条件相当的话,这些厂商设计出来的处理器综合性能应该是基本相同的。唯一能有所突破的地方就是使用更多的晶体管构建更大规模的架构。显而易见的是,苹果之前在这样做,现在也持续在这样做。
仅仅从晶体管数量来看的话,苹果M1的Firestrom核心强悍不是没有理由的,肆无忌惮堆资源,不强悍也难。那么,苹果将这些晶体管资源用在了哪里呢?
大就是好:来自苹果8宽度CPU构架
苹果在CPU架构设计方面拥有接近十年的历史。苹果首个定制化的SoC是2012年发布的A6,随后的每一年,苹果都会推出一个全新的CPU微架构。早在2013年,苹果便推出了一个名为Cyclone的微架构并宣称其为“桌面级别”微架构,这也是业界史上首个在移动设备上实现64bit计算的CPU架构,ARM和安卓世界要在一年以后才能赶上苹果的步伐。最新的苹果处理器是2020年发布的iPhone 12系列手机的A14 SoC中使用的名为Firestrom的大核心架构,和M1芯片中使用的Firestrom架构基本一致。
还是那个原因,苹果不发布所有有关处理器架构的信息,因此外界一般无从得知苹果对CPU微架构都干了些什么。好在作为业内老牌技术网站的anandtech通过深入测试和合理推测,给出了有关Firestrom核心架构的简图。
根据anandtech的资料显示,苹果Firestrom核心是一个8宽度的超宽、超标量、乱序的核心。相比之下,X86处理器比如AMD Zen 3依1日只有4宽度,英特尔的产品也只有4+1宽度设计,和其他ARM处理器相比的话,ARM出品的最新Cortex-X1拥有5宽度,其余都采用4宽度,三星M3虽然是6宽度,但是实际表现并不出色。
在乱序执行能力方面,通过测试可以看出,苹果的ROB单元能够允许的指令排序容量大约是630条目左右,虽然并不是很确定苹果在这部分是否采用了和其他处理器类似的设计,否则如此巨大的容量,显示苹果Firestrom拥有庞大的乱序执行排序能力和调度能力,当然这也对应着后端庞大的执行单元部分。作为对比的是,英特尔的Sunny Cove和Willow Cove的ROB容量仅仅352,这已经是目前除了Firestrom外我们知道的处理器中最大的了,AMD的Zen3仅为256条目,ARM的Cortex-X1仅为224条目。
在后端来看的话,整数执行部分,有关重命名寄存器的容量估计为354条目,这也是非常巨大的容量,此外还拥有至少7个执行端口用于计算相应的算术计算,包括4个具有ADD执行能力的ALU,2个可以执行MUL的复杂计算单元和可能存在的专用整数除法单元。
在浮点和矢量部分,Firestrom带来了全新的第四条执行管道,进一步提升了浮点计算的理论性能。浮点重命名寄存器容量约为384条目,还包含4个128b.t的NEON浮点流水线。此外,Firestrom每周期还可以执行4个FADD和4个FMUL,延迟分别是3个和4个周期。这样庞大的浮点计算规模是AMD Zen 3的2倍、是英特尔和AMD之前架构每周期吞吐量的大约4倍。
在加载存储方面,目前的测试显示Firestrom可能会有4个执行端口,1个加载存储单元、1个专用存储单元和2个专用家在单元。每个周期可以执行3个负载任务,每个周期最多可以执行2个存储,但是最多只能同时执行2个负载和2个存储。
在TLB方面,L1的TLB从1 28页增加了一倍至256页,L2 TLB从2048页增加到了3072页。由于每个TLB页面大小为16KB,因此3072的TLB可以覆盖48MB的缓存,这实际上是超过了现在的M1 SoC或者之前的A14的缓存容量的。因此这部分的设计具体如何实现还有待进一步探查。
最后来看缓存体系结构。之前A13的设计的有关推测中,苹果就设计了高达128KB的L1指令缓存和128KB L1数据缓存,从处理器设计角度来看这是极为不可思议的,因为一般处理器的L1缓存不会超过32KB(新的Sunny Cove是48KB),甚至部分处理器只使用16KB。当然,更大的缓存能显著帮助处理器内核快速获取指令,不过成本代价和晶体管数量代价非常高昂。在新的Firestrom上,可能这个容量已经进一步提升至192KB,这可以解释为什么苹果的处理器在高指令压力工作负载中表现出色。
在高速缓存的速度方面,Firestrom的L1数据缓存可以以3个周期的延迟载入,对于如此巨大的缓存架构而言这是非常难得的数据。相比之下,英特尔Sunny Cove只是增加至48KB,就需要5个周期载入,AMD 32KB的L1缓存则需要4个周期,相比苹果的设计还是存在一定的差异。L2方面,苹果一直以来都直接选择一个容量较大且快速的L2缓存设计,比如2个内核共享8MB缓存。在早前的A14芯片上,L2的延遲为16个周期。
另外值得注意的是,苹果在M1设计中还设计了一个SLC缓存,这个缓存位于整个芯片的中央部位,考虑到M1的内存带宽较小,因此这个SLC缓存可能是用于暂存部分数据信息,充当整个M1芯片的缓存使用。不过苹果没有公布SLC的使用方法和容量,一些测试显示,SLC的缓存容量可能为32MB,延迟可能为40ns,这个数据如果属实的话,那么M1 SoC在缓存设计上应该还有更多的信息可供挖掘。
最后则是Firestrom架构的有关时钟频率方面的内容。对Firestrom这种比较宽大的体系架构来说,一般认为其频率难以达到比较高的水平。不过在苹果的A14上,Firestrom的频率可以达到最高3GHz,2个Firestrom核心启用的时候频率会降低至2.89GHz。在M1处理器商,Firestrom能达到的最高频率为3.2GHz,也没有太大的提升。
总的来看,苹果在A14和M1处理器上实现了一个宽度高达8,并且缓存、执行资源非常充裕的超大核心,这也是前文提及的Firestrom核心可能单核心的晶体管数量就要比包括Zen 3、Sunny Cove、Zen 2等架构高出许多的原因。从苹果在架构方面的努力来看,苹果致力于“频率不够、规模来凑”,并且较低的频率能够带来较低的功耗和极高的性能功耗比。这也是苹果一贯以来的操作策略了。
苹果在M1的Firestrom设计中采用了高达8解码的前端,那么为什么X86处理器难以做到这一点呢?实际上,这里很可能是由于CISC指令集天生的痼疾导致这个问题的出现,现在难以解决。
对Firestrom架构来说,采用的是RISC精简指令集,所有的指令都是等长的,因此可以将整个指令序列按照一定的等长规则进行分割再交由解码器解码,就可以实现同时并发多个指令。不过这一点对CISC复杂指令集来说却很困难,X86使用的CISC指令集是不等长的,在前一个指令没有读完之前不知道后部的指令头位置在哪里,难以并行解码。当然,现代X86 CPU往往通过各种手段绕开CSIC指令集的不等长缺陷,比如通过经验来猜测指令的结尾,或者对指令可能存在的起点都进行一次解码并抛弃完全错误的部分。由于CSIC不等长指令集的问题,X86目前可以做到4个解码器或者4+1解码器已经是极限了。不仅如此,这种不等长的复杂指令还影响到了CPU乱序执行和的部分,因为不等长和不可预测性,乱序执行变得很困难。鉴于此,在现代X86 CPU的内部,所有的CSIC指令集都会被翻译为成为uOP也就是“微指令”或者“微码”( Micro Operations),通过规整的微码来统-CPU内部的流程。也正是由于uOP的出现,X86处理器才有可能在效率和性能上赶上RISC架构。
当然,CISC也不是没有优点,那就是一个指令可以执行更多的操作,整体效率相对较高,占用内存较少。RISC需要多条指令完成的任务,CSIC可能只用一条指令就可以实现,这也是CSIC相对RISC的优势所在。
统一内存架构的实现:苹果的全新创举
上文我们提到了苹果在CPU设计上的一些独特之处。在这一部分,我们将从更为宏观的角度来审视苹果M1处理器的设计。
正如前文所说,苹果M1处理器内部包含了大量的不同单元,除了CPU、GPU、NPU等外,还有最重要的,就是统一内存架构。
在M1处理器中,CPU、GPU、NPU和所有的单元都使用了一个统一的、和芯片紧密靠近的统一内存架构。这个架构的好处在于,CPU和GPU之间可以互相访问数据,这样可以大大降低数据搬运和复制的时间,也能够缩减各个不同的处理模块之间等待数据准备的时间。M1在硬件和软件上首次统一,完成了迄今为止首个真正进入商业化和民用市场的统一内存架构。
对传统PC而言,CPU的数据存放在内存中,GPU的数据存放在本地存储(显存)中。当GPU需要做什么事情的时候,或者说CPU需要让GPU去做什么事情的时候,数据会从内存中经过总线拷贝至GPU的显存中,这个拷贝的过程带来了比较明显的延迟和功耗的提升。反过来,GPU在计算完成后,需要将数据放置在CPU的内存中,再告诉CPU数据的位置,这个过程也存在延迟和功耗提升。不过,现在存在一些技术可以让CPU读取GPU显存中的数据,或者反过来GPU也可以访问CPU的数据,但受制于兼容性和各个厂商之间的协调以及操作系统、软件适配、软件生态等原因,这样的技术并不成熟。
在M1上,由于CPU、GPU、NPU等等计算核心包括操作系统、软件等都来自苹果公司自己,因此这样的问题可以在一个体系下进行协调,最终我们看到的是一个完整的、基于统一内存架构的SoC-M1。整个M1内部所有的硬件模块都拥有统一的内存地址,数据不再需要额外转移,这在很大程度上提升了整个系统的效率。
另外,在内存的部署中,M1芯片采用的是目前移动SoC惯用的“Package-on-Package”的方法,也就是让内存芯片尽可能靠近应用处理器,让他们之间的距离尽可能缩小。这样的优势在于,—方面尽可能地降低了内存传输的能耗,另一方面可以降低内存传输的延迟。M1的内存理论带宽为68.2GB/s,从这个数据来看,和目前桌面主流的比如AMD Zen 2、英特尔十代酷睿,是显著更低的,比如AMD Zen 2的内存带宽可达100G B/s以上。但是,考虑到苹果在统一内存架构、内存POP封装上以及本身处理器内部超大缓存的设计等,因此整体性能表现还是非常出色的。
异构计算的上马:专业的人做专业的事情
作为一个拥有1 60亿晶体管的庞大SoC,M1内部包含的各个功能模块是非常多而且复杂的。除了前文深入分析的CPU外,还包括进行3D图像计算的GPU、进行神经网络计算的NPU、视频编解码器、音频处理单元、HDR视频处理单元、HDR图像处理单元、常开处理器、矩阵协处理器等。在M1的设计中,苹果贯彻了能用专业单元就不用通用单元的思想,“让专业的人做专业的事情”,这会让性能表现更加高效。
在苹果对M1相关产品的宣传中,有针对M1在视频处理计算上优势的专门介绍。实际上,由于苹果在M1内部专门设置了HDR视频处理单元和视频编解码单元,在经过操作系统和专业软件的调用后,就能够地轻松发挥出这些专用单元的效能,从而获得极为优秀的性能表现。另外值得一提的是苹果的矩阵协处理器,它可以用于执行一些常规代码加速而不是专门调用GPU或者NPU。换句话说,苹果通过这样的设置,带来了非常出色的性能功耗比表现。
对M1采用大量专用单元进行针对性加速的方法,业内往往以异构计算对其进行归类和称呼。一般来说,异构计算是指拥有多种不同类型计算能力和优势的模块在统一调度下进行计算的方式。对于M1来说,苹果的软件和M1的硬件,以及其他相关软件配合,实现了迄今為止业内面向消费者最为出色的异构计算架构。
不过,虽然M1在异构计算上做得非常出色,但是异构计算还存在一个致命的问题,那就是由于硬件固定了计算路径,未来如果算法和应用升级的话,那么相关的异构计算单元可能就无法发挥作用。考虑到苹果同时控制了操作系统和软件开发环境,这样的问题可能短时间内不会出现,但依旧需要进一步观察。
开辟一条全新的道路?
到这里,本文对M1处理器的分析就基本告一段落了。从苹果在M1处理器中的设计来看,依托于5nm的强大优势,苹果通过集成高达160亿个晶体管资源,超大规模的CPU核心、大量专用的模块以及缓存设计,在较低的功耗下取得了相对于现有高端X86处理器部分相当的性能,甚至在部分测试中还有所超出,这是非常了不起的成绩,凸显了苹果强大的软硬件技术实力。
从M1以及苹果在软件、系统上的努力可以看出,似乎苹果正在开辟一条全新的道路来挑战X86在个人电脑中的领导地位。之前RISC阵营也曾经挑战过X86在PC上的领导地位,但是显然失败了。苹果则借由移动计算开始,现在通过统一移动和桌面端的架构,模糊移动设备和个人电脑之间的界限,并借由M1这样性能卓越、功能强劲的产品来吸引消费者关注,这不得不说是一招秒棋。从技术角度来看,M1充分发挥了RISC CPU架构的优势,再加上苹果不惜工本地投入大量晶体管资源、统一内存架构、异构计算、定制各种不同功能的计算单元以及全新的操作系统、软件生态,都给人带来了耳目一新的感觉。接下来,苹果要怎么走呢?是推出更强大的M2、M3以及更加紧密的生态系统?还是进一步统一移动端和桌面端呢?这都让人相当期待。
