基于XGBoost算法的汽轮机转子故障原因定位方法
2021-06-19王新伟冷述文杨宝清
王新伟, 钱 虹,2, 冷述文, 杨宝清
(1.上海电力大学 自动化工程学院,上海 200090;2.上海市电站自动化技术重点实验室,上海 200090;3.华能山东发电有限公司,济南 250014;4.华能临沂发电公司,山东临沂 276016)
汽轮机承担着能源转换的作用,是电站最重要的旋转设备。由于汽轮机结构和系统的复杂性,以及运行环境的特殊性,导致其故障发生率较高[1-2],因此在复杂环境下实现精准快速的故障识别和故障原因定位,从而采取有效措施及时修复故障对于保证汽轮机系统的安全稳定运行具有重要意义。
目前,汽轮机故障诊断技术在信号采集与分析[3]、故障机理[4-5]、故障特征提取[6-9]和故障模式识别[10-13]等方面取得较多进展。然而,关于如何准确快速地进行故障原因定位识别的研究较少。目前,在实际的故障诊断过程中,主要依靠经验进行故障原因分析。大量汽轮机故障案例表明,不同故障原因导致的不同类型故障发生时,会伴随运行参数的异常变化,诊断专家在进行故障原因分析时可通过这些异常来确定发生故障的具体原因[14],然而这些具有较强区分性的运行参数故障特征却很少被用于建立智能诊断模型。因此,通过挖掘汽轮机运行参数的故障特征进行故障原因定位识别,具有现实的价值意义。然而,汽轮机运行参数很多,数据集样本较大,且各运行参数之间可能存在相互关联和相互耦合关系。因此,可使用机器学习算法处理和分析汽轮机运行参数的相关数据,提高故障原因定位模型的分类准确率。钟敏慧等[15]将梯度提升决策树(GBDT)模型用于铁路事故类型的预测,并根据模型中的特征重要度排序实现了铁路事故成因分析。极端梯度提升(XGBoost)算法在GBDT模型的基础上对损失函数、正则化和并行处理等方面进行改进,具有更强的分类能力[16]。XGBoost算法具有不易被噪声干扰、准确性高和运算速度快等优点,可对多维和多特征数据进行快速有效处理。在旋转机械故障预测[17]和故障诊断[18-19]等方面已有关于XGBoost算法的研究。
笔者首次基于XGBoost算法并结合运行参数对不同汽轮机故障类型进行多种故障原因定位,利用汽轮机转子故障类型和运行参数的异常变化特征,对多种故障原因进行定位识别。首先,对包含故障类型和汽轮机运行参数的原始数据集进行预处理,提升模型样本的适应性;将训练集样本送入XGBoost模型进行建模,采用网格搜索法优化模型参数,以提高分类准确率;通过测试集样本验证所提方法的有效性;最后,针对具体故障原因,根据对应的故障知识库提供故障修复措施,从而提高故障诊断和故障修复的效率。
1 XGBoost算法
为实现精准快速的故障原因定位,使用XGBoost算法构建汽轮机转子故障原因定位模型。XGBoost模型是基于树集成的学习模型,其基分类器是分类树和回归树(CART)[20]。
首先,对采集的汽轮机转子故障原始数据集D={(Xi,yi)}进行预处理,其中yi表示实际故障原因类别,Xi为第i个样本的特征参数矩阵,Xi由故障类型Fi(i=1,2,…,p)和运行参数矩阵xi(xi=[x1,ix2,i…xl,i])2部分构成,即
Xi=[Fix1,ix2,i…xl,i]
(1)
其中,p为故障类型数量;l为运行参数的数量。
将预处理后的数据集进行随机分类,得到含有n个样本和m个特征参数的训练集D′={(Xi,yi)},Xi∈Rm,yi∈R,其中Rm为含有m个特征参数的特征集。
将训练集代入到XGBoost模型中对其进行训练,可得到由多个决策树函数相加的集成模型。
(2)
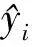
模型目标函数L为:
(3)
式中:ls为损失函数项;Ω为正则项。

(4)

(5)
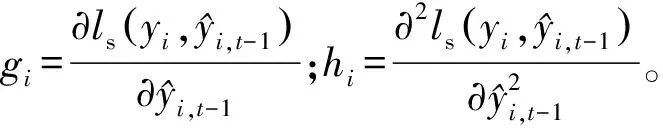
定义Ij={i|q(Xi)=j}为叶节点j的样本集,其中q(Xi)为树结构,将正则项Ω(fk)展开为:
(6)
式中:T为叶节点的数量;ωj为叶节点j的权重;γ和λ均为正则化系数。
将式(6)代入式(5),得:
(7)
(8)
(9)

叶节点的分裂是基于特征参数(即模型的输入变量)进行的,某特征参数被应用于叶节点分裂的次数可认为是该特征参数的重要度得分,反映了该特征参数与输出结果之间的相关性[21]。因此,可根据特征参数重要度得分来选择XGBoost模型的输入变量。XGBoost模型的流程图见图1。
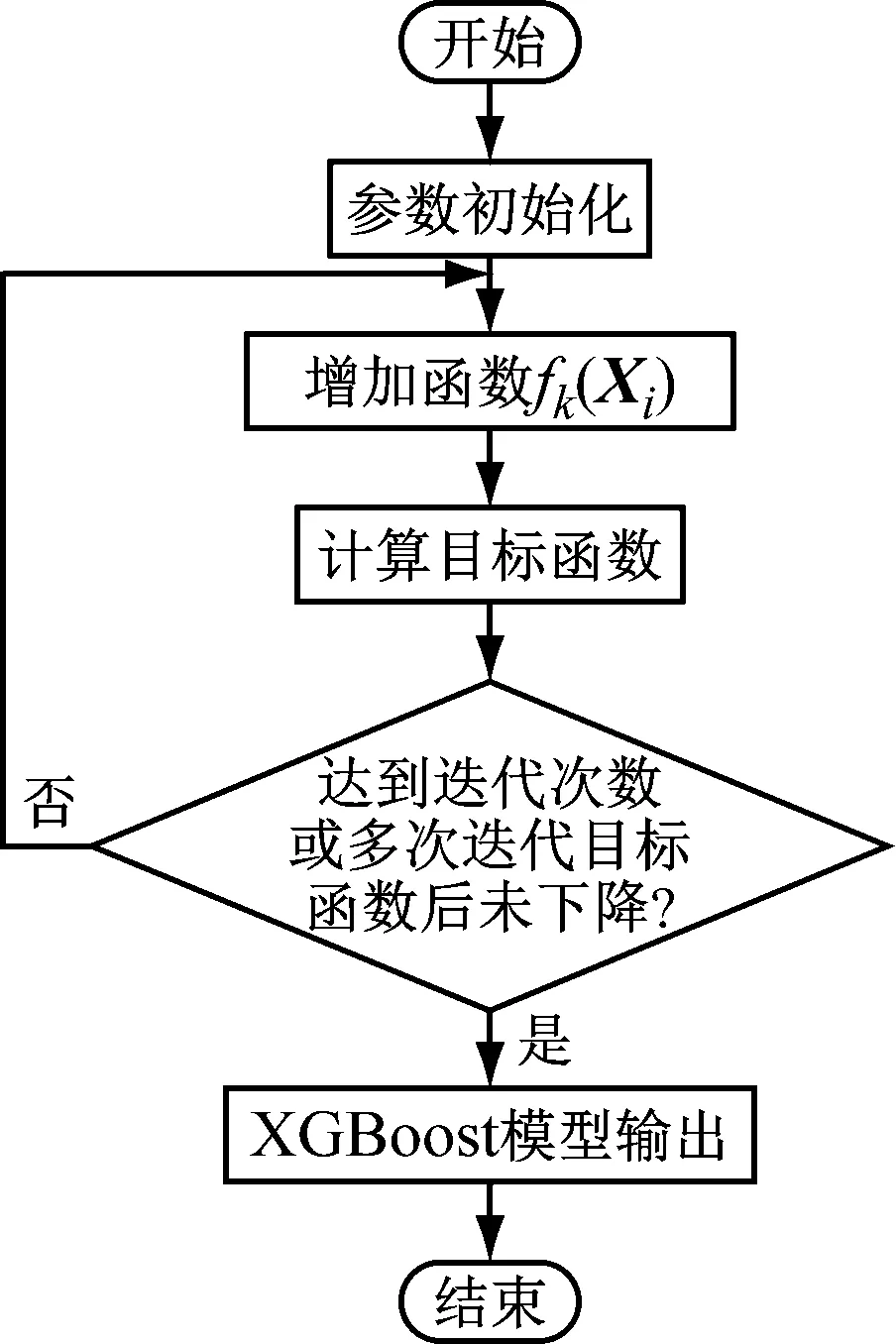
图1 XGBoost模型的流程图
2 基于XGBoost算法的汽轮机转子故障原因定位
在已知故障类型的基础上,基于XGBoost算法的汽轮机转子故障原因定位结合了故障类型和相关运行参数信息,对多种故障原因进行定位识别,其流程见图2。
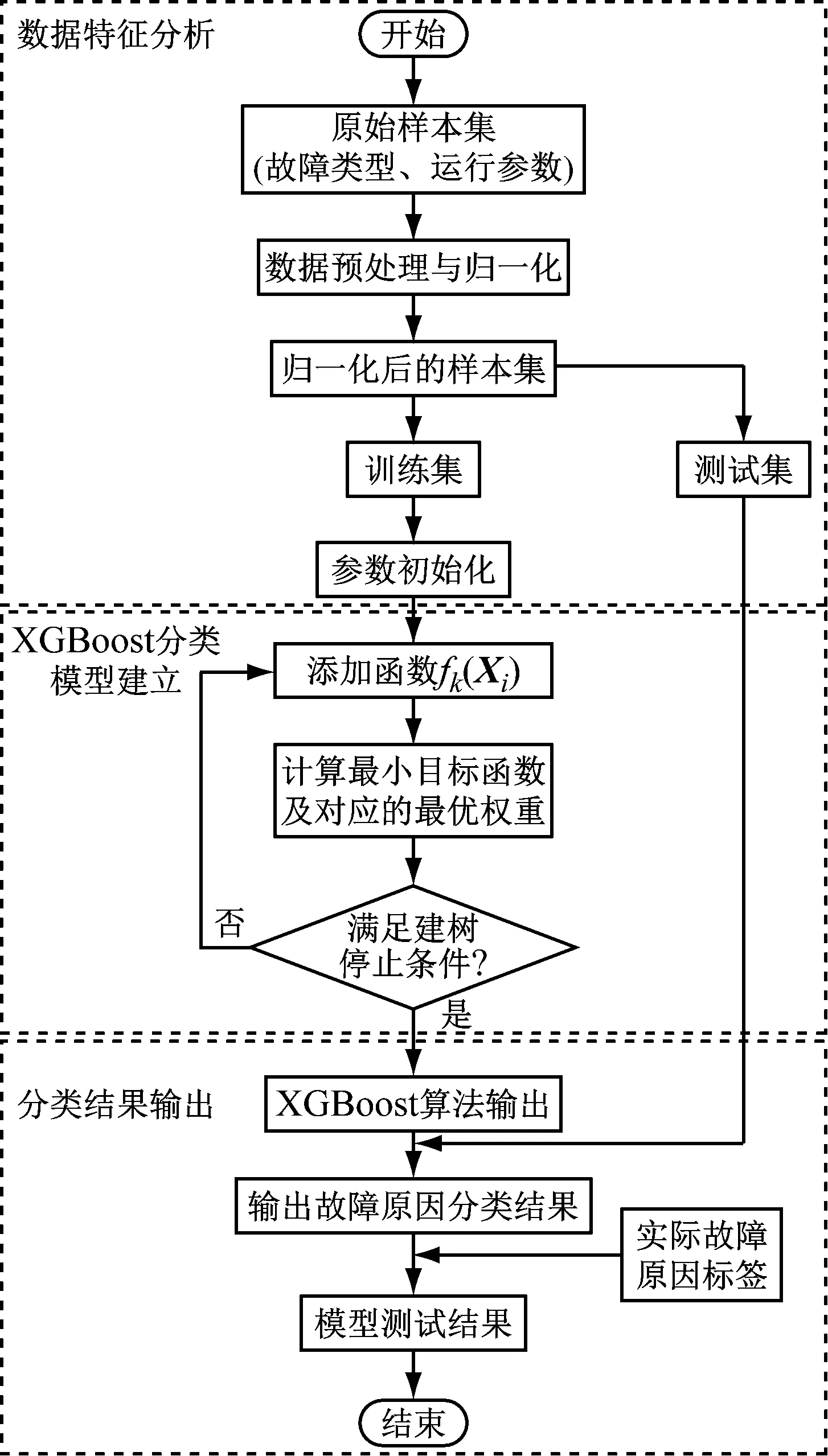
图2 基于XGBoost算法的汽轮机转子故障原因定位流程图
汽轮机转子故障原因定位方法如下:获取汽轮机转子故障类型和运行参数数据,组成原始数据集;对原始数据集进行数据预处理与特征工程构建;将预处理后的数据集进行随机分类,得到训练集样本和测试集样本;利用训练集样本构建XGBoost模型,并优化模型参数,提高模型分类的准确率;利用测试集样本对XGBoost模型进行测试,输出测试集分类结果,结合原始数据集实际故障原因类别标签得到模型分类的准确率;针对不同原因导致的故障,链接到相应的故障知识库,采取对应措施快速修复故障;无法确定具体原因时,通过总结故障案例列出可能的故障原因,并按照原因导致故障发生的次数进行排序,检修时优先检查次序靠前的故障原因。
3 实例分析
3.1 数据来源
以汽轮机高压转子动静碰摩故障(F1)、质量不平衡故障(F2)和自激振荡(包括油膜半速涡动和油膜振荡)故障(F3)为对象,整理汇总电厂330 MW机组3种故障相关的运行参数数据[13](450组)进行实例验证。各故障原因和类别标签见表1。
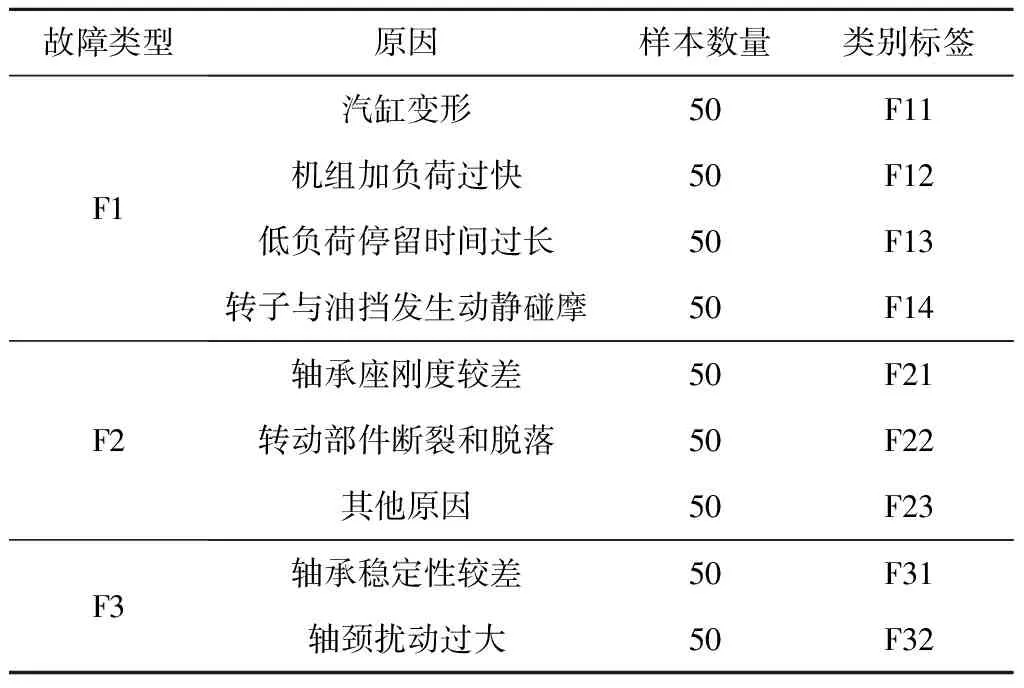
表1 故障原因和类别标签
3.2 故障原因数据特征分析
特征分析的目标是最大限度地从原始数据中提取特征,其有效性很大程度上决定了模型的准确率。特征处理是特征工程的核心部分,包括数据预处理、特征选择和降维等操作[17]。
3.2.1 特征参数选择
选取与F1、F2和F3相关性较高的10个运行参数,主要包括高压缸轴封蒸汽温度、高压缸汽缸膨胀值等,如表2所示。

表2 汽轮机高压转子故障原因特征参数
3.2.2 数据预处理
数据预处理主要包括数据缺失值处理、数据无量纲化(包括中心化处理和缩放处理)、分类型特征处理(字符型数据转化为数字型)和连续型特征处理等。
(1)缺失值处理。
针对数据的缺失值,采用均值填补法来处理数值型特征,采用众数填补法来处理字符型特征。
(2)字符型特征编码。
在原始数据集中,分类特征中的故障类型(如F1、F2和F3)以及故障原因类别标签(如F11、F12等)均不是以数字来表现的,为了让数据适应XGBoost模型,必须将数据进行编码,即将字符型数据转化为数字型。对于相互独立的故障类型(F1、F2和F3),采用独热编码将故障类型转变为哑变量形式;对于故障原因类别标签,将其直接转化为数字形式。
(3)数据标准化。
将特征数据x按均值中心化后,再按标准差缩放,则处理后数据将服从标准正态分布,即x~N(μ,σ2)。
(11)
式中:μ为均值;σ为标准差;x*为标准化的特征数据。
经过预处理后的数据集如表3所示。主要特征重要度排序见表4。

表3 预处理后的数据集

表4 特征参数重要度排序
3.3 模型训练和参数优化
将预处理后的数据样本集进行随机分类,得到训练集样本和测试集样本。利用训练集样本对XGBoost模型进行训练,并优化模型参数,提高模型准确率。采用网格搜索法(GS)和k折交叉验证[22]确定最优XGBoost模型参数。模型参数的评价标准采用误差函数,误差小的参数更优。
对迭代次数进行设置。如图3所示,利用5折交叉验证得到训练集和测试集的迭代次数-误差学习曲线,对迭代次数进行估计,取迭代次数的范围为25~75。从图3还可以看出,XGBoost模型在训练集上的表现优于在测试集上的表现,即模型处于过拟合状态。为达到更理想的分类效果,需要对XGBoost模型的其他参数进行设定,以提高其泛化能力。
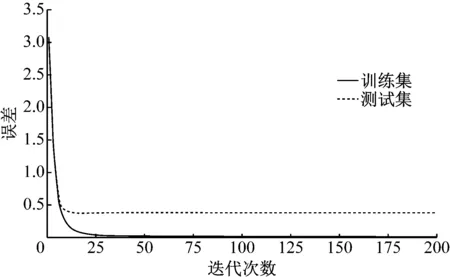
图3 迭代次数-误差学习曲线
模型主要参数设定值见表5,优化后的模型迭代次数-误差学习曲线如图4所示。从图4可以看出,模型的过拟合现象得到很大改善,但模型的准确率略有下降。
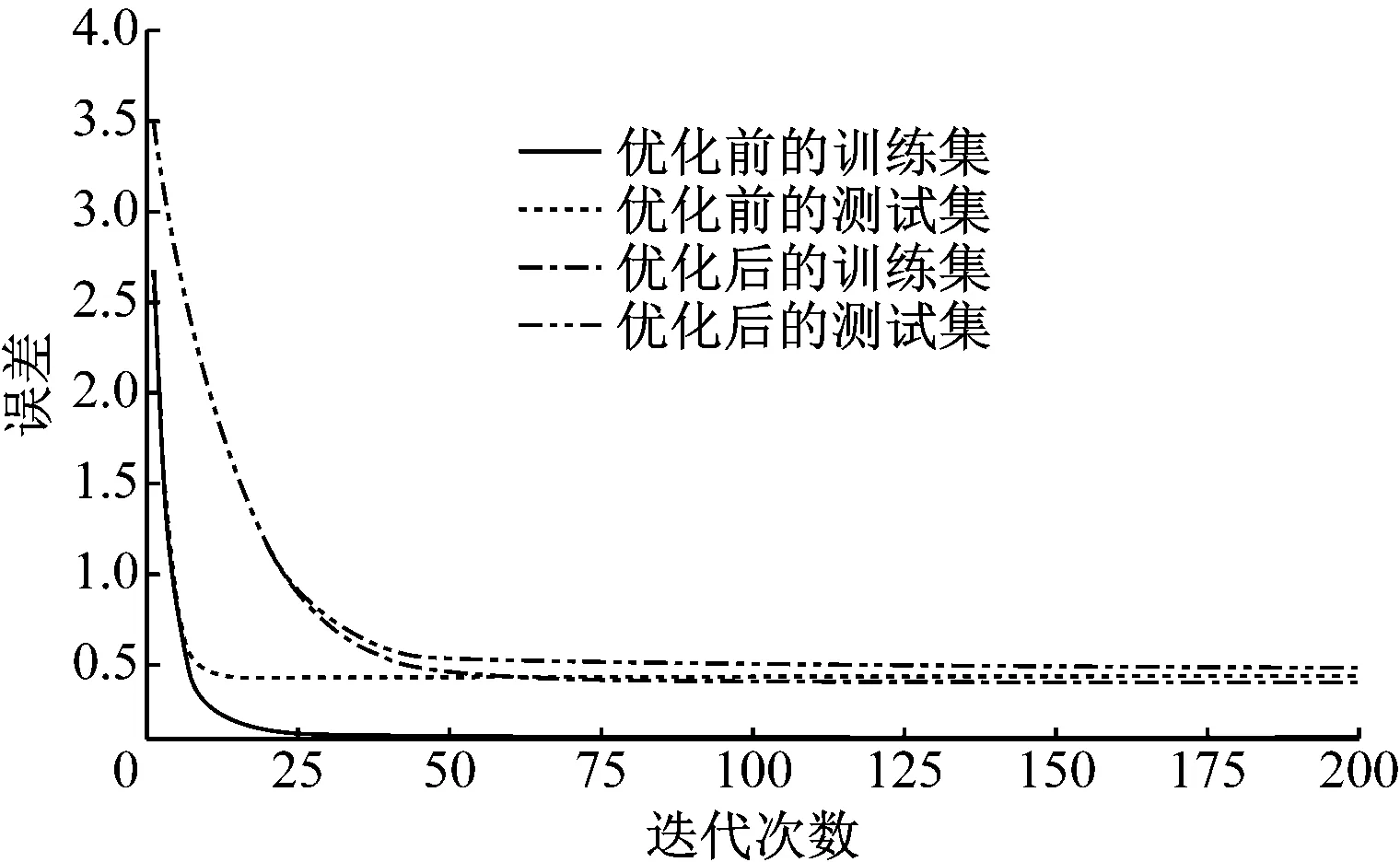
图4 优化后的迭代次数-误差学习曲线

表5 XGBoost模型主要参数设定
3.4 XGBoost模型的分类结果
利用测试集对构建好的XGBoost模型进行分类准确率验证,如图5所示。结果表明,XGBoost模型整体分类准确率为95.56%。其中,汽缸变形导致的动静碰摩故障分类准确率为64.3%,机组加负荷过快导致的动静碰摩故障分类准确率为92.3%,其他故障原因导致的动静碰摩故障、质量不平衡故障和自激振荡故障分类准确率均为100%。整个诊断过程的计算时间为0.520 7 s。测试集的混淆矩阵见表6。

图5 采用XGBoost模型时测试集的分类结果

表6 XGBoost测试集的混淆矩阵
3.5 对比分析
将XGBoost模型与决策树(DT)模型、支持向量机(SVM)、随机森林算法(RF)和梯度提升决策树算法的分类结果进行对比,采用预处理后的数据集分别对各算法进行训练和测试。
采用DT模型时,首先画出树最大深度参数学习曲线,并测试出决策树最大深度最优取值为5,使用网格搜索法确定其他参数的最优组合为:min_sample_leaf=2;min_sample_split=1;crition= entro-py。DT模型的分类结果如图6所示。
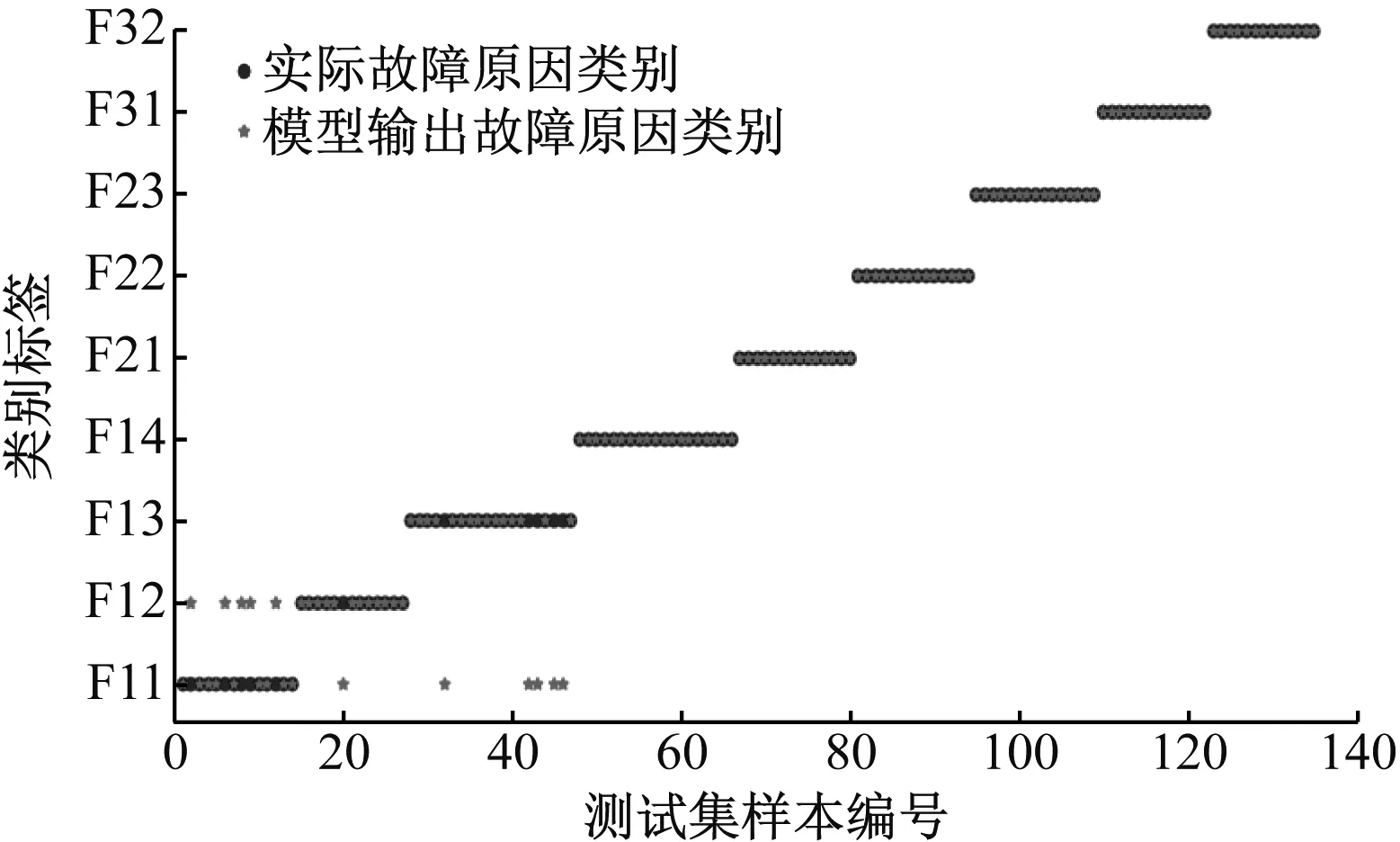
图6 采用DT模型时测试集的分类结果
采用SVM模型时利用径向基核函数(RBF)进行训练。由于核参数和惩罚系数对训练结果的影响较大,所以采用网格搜索法对2个参数进行寻优,核参数和惩罚系数分别取1.234和0.095。SVM模型的分类结果如图7所示。
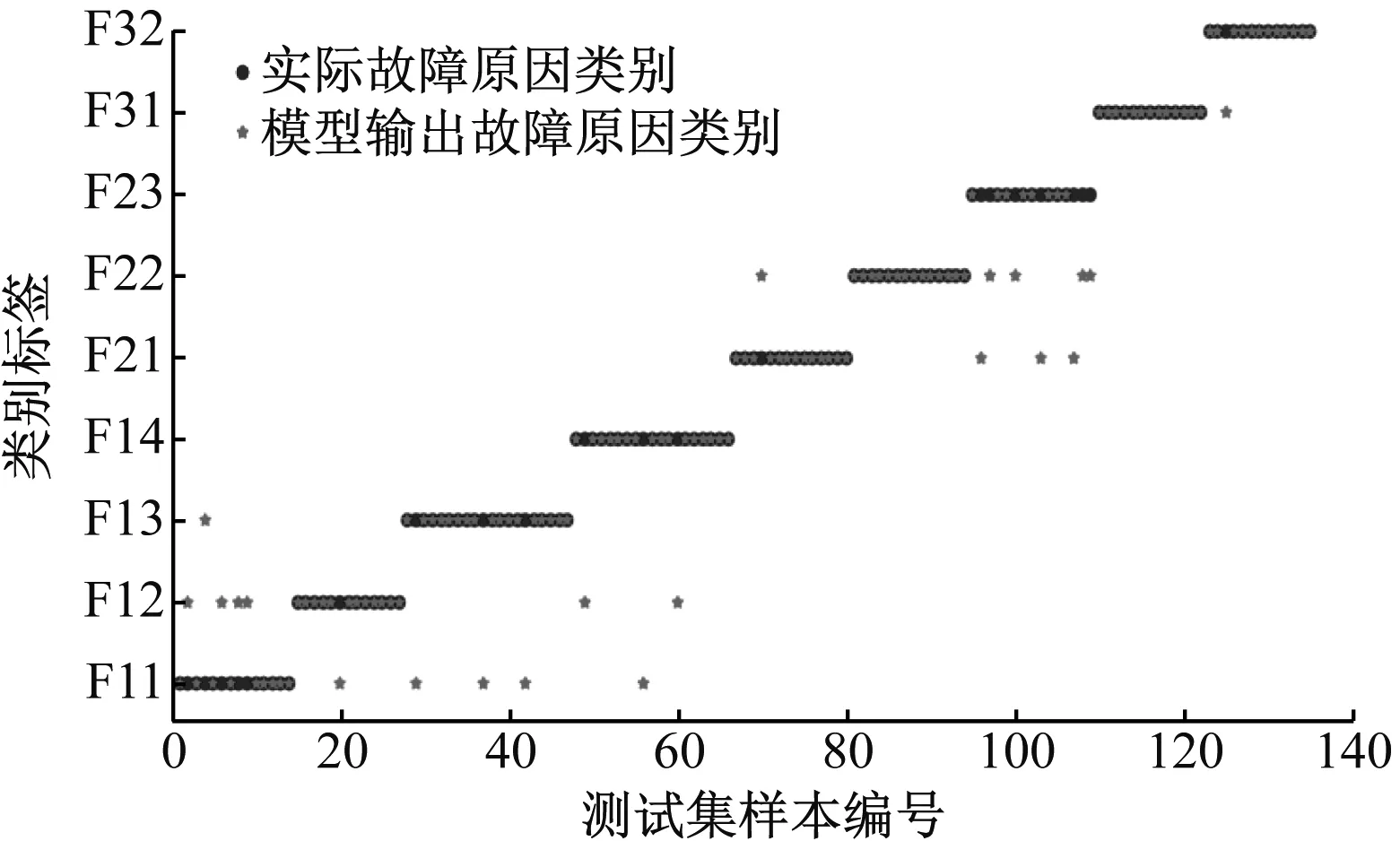
图7 采用SVM模型时测试集的分类结果
分别对随机森林和梯度提升决策树模型的参数进行寻优。表7给出5种模型故障分类结果的对比情况。
由表7可知,XGBoost模型比其他模型具有更高的分类准确率,而DT模型和RF模型训练耗时较XGBoost模型更短。这是因为DT模型复杂度低,RF模型和GBDT模型均是基于DT模型的算法,其准确率均略差于XGBoost模型,由此验证了XGBoost模型用于汽轮机转子故障原因定位的有效性。
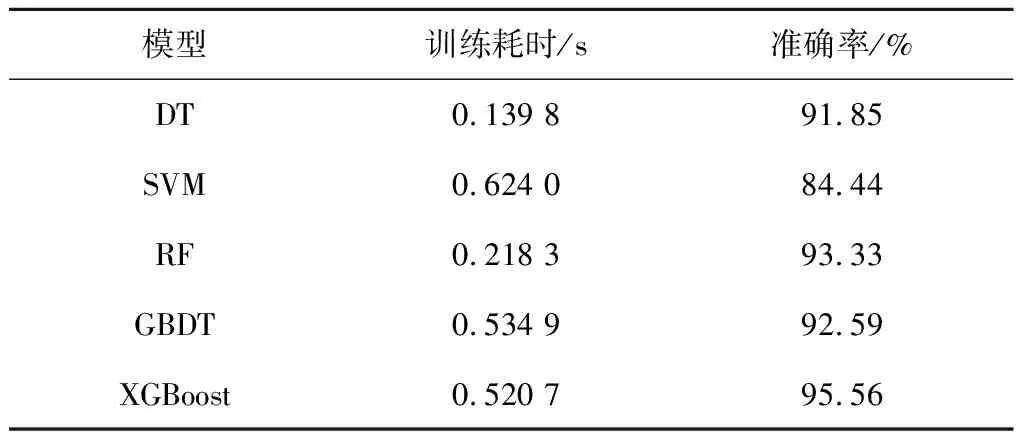
表7 不同模型的故障分类结果
3.6 故障知识库
针对不同故障原因导致的汽轮机转子动静碰摩、质量不平衡和自激振荡3种故障,其相应的故障知识库见表8。汽轮机高压转子故障知识库给出了故障原因定位算法中涉及的相关运行参数、故障类型和故障原因等信息,并针对具体故障原因给出相应故障解决措施,为故障修复提供建议,从而提高故障诊断与修复的效率。

表8 汽轮机高压转子故障知识库
4 结 语
(1)XGBoost模型能对多维和多特征数据进行快速有效处理,可以对多种故障原因进行快速准确分类。
(2)XGBoost模型可有效识别出汽轮机转子3种故障类型下的9种故障原因,分类准确率可达95.56%。相较于DT、SVM、RF和GBDT模型,XGBoost模型具有更好的分类准确率。
