英东油田长井段薄互层油藏储层产能分类及预测研究
2021-06-07马凤春陈晓冬王琳杨成梅华唐丽杨玥王靖茹周艳赵为永杨红刚李兆亮刘遥王生香
马凤春,陈晓冬,王琳,杨成,梅华,唐丽,杨玥,王靖茹,周艳,赵为永,杨红刚,李兆亮,刘遥,王生香
(1.青海油田勘探开发研究院,甘肃 敦煌 736202;2.青海油田采油二厂,甘肃 敦煌 736202;3.青海油田钻采工艺研究院,甘肃 敦煌 736202)
英东油田为柴达木盆地近几年发现的一个纵向叠置的断块油气藏,具有晚期复式成藏的特征(马达德等,2016)。随着注水开发的深入,油藏逐渐成为主力产油区。自开发以来,受纵向沉储层积类型多、变化快以及非均质强的影响,油井同一层段同流体性质的储层按照工区前期传统储层分类(表1)射孔后,呈现出单井及纵向小层产能差异较大、纵向动用不均衡的矛盾,不同类型储层投产符合率较低,影响开发效果。从油藏主力区块油井产液测试与储层类型分布图看(图1),除Ⅳ类储层产能界限较为明显,其他3类储层之间的产能交叉区域较大,各类储层产能分布混乱,应该说当前的储层分类与小层产能对应性不是很理想,对当前低油价下的储层优选和动用指导意义较小,效益生产风险较高。因此,如何在新老井选层投产前对储层产能进行定量评价,降低纵向储层产液矛盾、提高层间储量动用和油井投产符合率,有必要开展对应储层的产能分析和预测。

表1 英东地区储层分类评价表Tab.1 Evaluation table of reservoir classification in Yingdong area
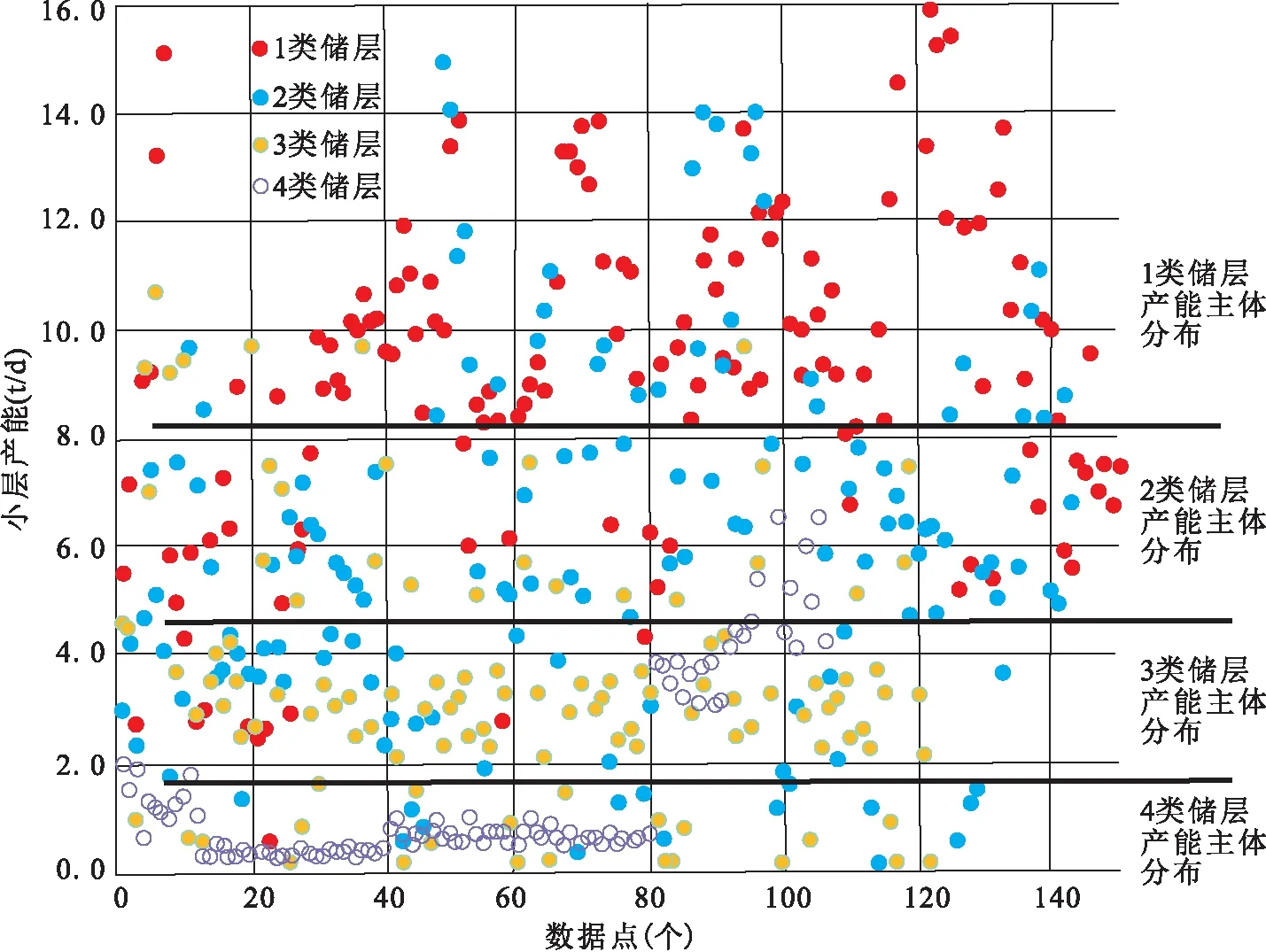
图1 不同类型储层产能分布图Fig.1 Distribution of reservoir productivity of different types
目前,油气储层研究主要集中在储层静态分类评价较多(朱谨谨等,2019;魏笑笑等,2018;张瑞香等,2020),主要产能评价还是通过试油、试采数据或油藏数值模拟等手段来解决,对于产能预测工作还没有一套成熟的方法。欧阳健等人提出用岩石渗透率和含水饱和度来评价油气层的产能指数(欧阳健,1994);Cheng等人利用原状地层电阻率和冲洗带电阻率来对储层流体的流动能力进行表征,从而来对储层的产能进行评价(Cheng M L,1999);毛志强则采用多个油气藏大量试油、测井解释以及岩心分析数据的研究,根据渗流力学的基本原理,分油气藏类型建立了利用测井资料预测产能的方法(毛志强等,2000);谭成仟等人则从平面径向流产量理论公式出发,通过相对渗透率与含水饱和度复杂函数关系的分析以及阿尔奇公式,建立了储层油气产能与储层渗透率、孔隙度和电阻率之间的统计关系,采用神经网络技术对其产能进行预测(谭成仟等,2004)。
而储层产能是油气储层动态特征的一个综合指标,是油气储层生产潜力和各种影响因素之间在相互制约相互影响过程中的一种动态平衡。储层产能的影响因素很多,概括起来有:①储层的基本特性,包括储层岩性、物性、含油性、电性、地层压力等。②储集空间中流体的性质,主要包括原油的黏度、气油比、流体的类型。③外在因素主要包括钻井、井下作业对储层的污染情况、射孔的层段选择及其完善程度、人工措施的选择和规模大小等。因此,储层产能是这些因素共同作用的结果。为此,笔者根据研究工区实际情况,结合测井、试油、试采等动态数据,利用相关判别函数法,动静结合开展储层产能定量评价,一定程度上可以提高长井段多油层油藏不同储层产能预测精度。
1 研究区地质概况
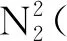
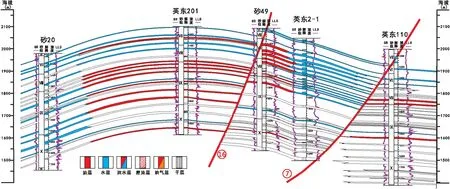
图2 英东油田纵向储层分布示意图Fig.2 Vertical reservoir distribution diagram of Yingdong oiofield
2 Fisher判别方法与原理
判别分析是一种常用的统计分析方法,是根据观察或测量到若干变量值,判断研究对象属于哪一类的方法。SPSS对于分为m类的研究对象,建立m个线性判别函数,当对于每个个体进行判别时,把测试的各个变量值代入判别函数,得到判别分数,从而确定个体属于哪一类。
(1)如果从G(G>2)个总体a1、a2、…、aG中分别取出n1、n2、…、nG个样品,并且每个样品有m个变量,那么样品构成的观测样本为:
(1)
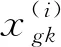
(2)如果把取出的G组样品视为G个总体,并记为:
A=(a1,a2,…,aG)
(2)
那么对于待判别的一个样品X(X∈A)来说,在对它所属的总体作出判定之前,它属于任何一个总体都是可能的,只是归属总体ag(g=1,2,…,G)的概率不同。如果把a1,a2,…,aG视为总体样本空间的一个划分,那么由Bayes公式可以求得样品X属于ag(g=1,2,…,G)的条件(后验)概率:
(3)
上式中的Pg、fg(X)分别是总体ag的先验概率和概率密度。
依据条件概率P(ag/X)的相对大小,则可对位置样品X的总体作出判断。若P(ag/X)是条件概率中的最大者,那么把未知样品X的总体判定为ak,判错的概率就最小。在计算条件概率时,式(3)的分母是一个与g无关的常量C,若取式(3)的分子,记为:
Eg(X)=Pgfg(X)(g=1,2,…,G)
(4)
那么式(4)的函数值仅是条件概率P(ag/X)的C倍,因此按Eg(X)函数值的相对大小判定未知样品X的总体与式(3)是等价的。式(4)是多总体判别的一般判别函数。
3 判别参数的选取
在油气田开采的过程中,产能一般利用平面径向流渗流模型来进行表述,但是由于公式中的流动压力、生产半径及流体黏度等数据在测试之前无法确定,单靠测井资料仅可以得出其静态解释的有效厚度、渗透率、孔隙度等数据。然而该类参数存在单一化,单独的参数很难表征储层的产量贡献能力,预测产能仍然存在较大的风险。为了能有效客观地反应储层的产出,需要重新对基础地质参数进行组合,制定出能较好代表储层储集能力和流动能力的多因素参数,并通过该类参数对储层进行产能综合评价和预测。经过多参数的聚类试验选取,最终采用渗流系数、存储系数与含油饱和度作为判别函数中的参数。
存储系数是孔隙度与有效厚度以及岩石压缩系数的乘积,反映了储层中储集空间的大小,表明了储层对流体的储集能力。
C=φ×Ct×He
式中:C为存数系数(m/Mpa);φ为岩石孔隙度(%);Ct为岩石压缩系数(Mpa-1);He为有效厚度(m)。
渗流系数为渗透率和有效厚度的乘积与流体黏度之比,反映了储层中流体渗流能力的大小,即可以产出多少流体。
S=K×He/μ
式中:S为渗流系数,10-3μm2/(Mpa·s);K为渗透率(10-3μm2);He为有效厚度(m);μ为为流体粘度(Mpa·s)。
而含油饱和度则是反映储层中油气含量多少的一个重要参数。通过这3个参数的选择,可以综合反映出储层的产能。
4 产能判别及预测函数的建立
4.1 数据的选择
建立产能预测判别函数时,采用14口井的14个试采层段第一个月平均日产油的数据,利用储能系数(反映了储层含油气的富集程度,以储层有效厚度、孔隙度及含油气饱和度的乘积来表示,即He×φ×Sog)将平均日产油劈分到试采层段的每个单砂体中,最终共获得67个单砂体日产油数据点。将这67个数据点按照日产油量的大小进行分类,分别分为<0.5 t、0.5 ~2 t、2~5 t以及>5 t四类。
4 .2 分类判别函数的建立
将上述67个数据点分4类分别编为4、3、2、1号,同时将存储系数、渗流系数与含油饱和度参数录入到SPSS软件中,利用其中的判别分析模块,最终确定了分流函数的系数(表2)以及4个类别的散点图(图3)。

表2 分类函数系数表Tab.2 Classification function coefficient
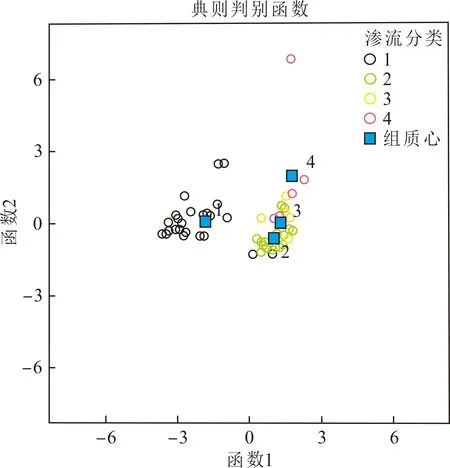
图3 4个类别的散点分布图Fig.3 Scatter distribution of the four categories
由表2分别得到4类fisher线性判别函数。
Y4=-0.000 146 2×S+0.055 5×C+0.129 2×Sog-3.916
Y3=-0.000 839 2×S+0.080 17×C+0.333 6×Sog-13.46
Y2=0.000 333 6×S+0.097 02×C+0.340 5×Sog-15.1
Y1=0.001 894×S+0.153 2×C+0.340 6×Sog-20.99
式中:Y4、Y3、Y2、Y1分别代表着预测产油量<0.5 t、0.5~2 t,2~5 t以及>5 t的4类;S为渗流系数;C为存储系数;Sog为含油气饱和度(%)。
将含有3个自变量的一组数据代入上述4个判别函数中,得出4个函数值,比较这4个函数值的大小,哪个函数值大就可以判断该组数据属于哪一类别。
图3可以看出,各类散点在平面图上的分布具有一定的区域性,基本上样品点得以分开。表3中一类正判率达到88.9%;二类正判率达到90%;三类正判率为80%;四类的样品点数较少,其正判率略低,为60%,主要与三类重叠区域较大。表4为研究区各主力小层的储层产能分类判别统计表。从表4中可以看到,模型与人工产能分类符合率达到了80%以上。

表3 预测结果及正判率Tab.3 Prediction results and positive rate
4.3 储层产能定量预测函数建立
通过实际与理论判别函数的建立和符合率统计,认为当前基于存储系数、渗流系数与含油饱和度参数所建立的判别函数是与油藏实际生产特征相近的,具有较好的定性指导意义。为进一步提高储层利用效果和现实的定量评价作用,在储层判别函数建立的基础上,以4类fisher判别函数值为因变量,实际产能数据为次变量,进行4类储层产能大小与正确判别函数数值的关系拟合。
从拟合曲线看,工区储层产能与正确分类判别函数值关系曲线呈二次函数关系(图4),且函数相关系数达到0.88,说明判别函数数值与储层产能之间有较好的对应关系,即可以间接通过该拟合曲线进行定量获得不同层段储层的产能大小。为进一步验证该函数的可靠性和准确性,油藏在后期部分老井补孔治理中,对20口井65个层进行了函数应用。通过实际产液资料测试和理论产能判别对比(图5),平均绝对误差为0.35 t/d,平均相对误差在12%以内,符合率达到80%以上,基本满足当前油藏效益治理的目标。

表4 判别模型储层产能类型预测与实际产能类型对比表Tab.4 The comparison table between the prediction model and the actual reservoir productivity type
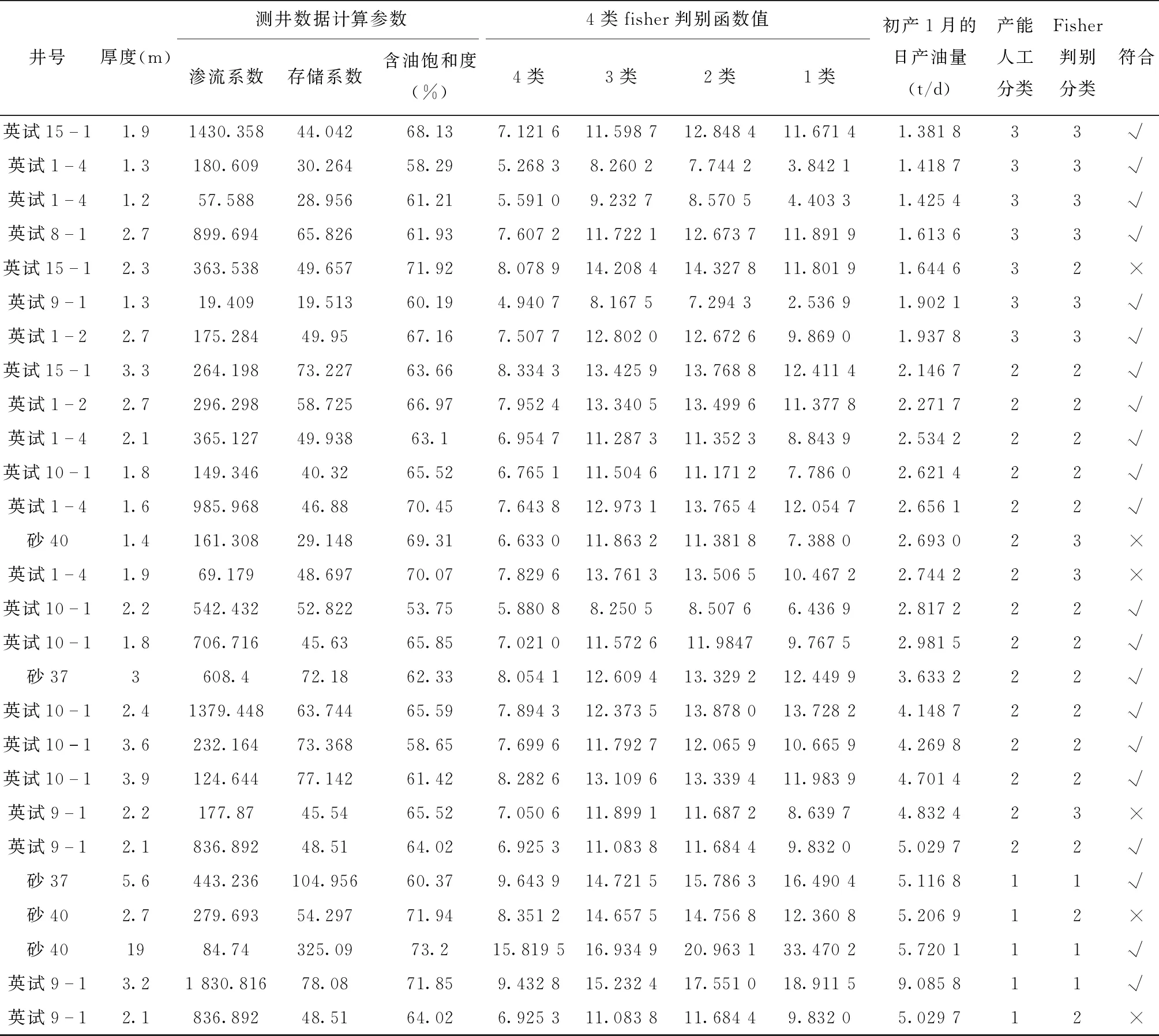
续表4

图4 储层产能与正确分类判别函数值关系曲线图Fig.4 The relationship curve between reservoir productivity and the correct classification discriminant function

图5 储层理论产能与实际产能关系图Fig.5 The relationship between theoretical productivity and actual productivity
5 结论
针对复杂断块长井段薄层油气藏的特点,通过遴选影响储层属性的关键因素,经过参数的聚类试验选取,采用渗流系数、存储系数与含油饱和度作为fisher判别函数中的参数,在一定程度上可以对储层产能定量评价,且模型正判率和产能定量评价符合率较高,基本能满足油藏储层射孔效益开发的要求,可以应用于其他开发井薄油气层的储层产能定量预测,为油藏有效综合治理开发提供依据和决策。
