移动端儿童数字阅读行为采集与可视化研究
2021-06-03杭州电子科技大学刘娟娟杨根福
◇杭州电子科技大学 刘娟娟 杨根福
本文主要设计利用爬虫技术爬取移动端儿童数字阅读类APP的评论区中家长以及儿童对数字阅读的评论。通过对移动端使用抓包工具截获APP数据包,并利用爬虫程序模拟浏览器访问网页,获取文字、音频两种格式的数据,借助图形化手段将清洗后的数据可视化,从而得到有价值的结论,以此分析数字化阅读对于人们的意义和价值,帮助儿童数字化阅读更健康地发展和优化。
随着网络技术的发展,数字化阅读开始出现在人们的视野。十几年前也有录音机听书,但是目前儿童数字化阅读通常以移动端为载体,会由于人们的阅读行为产生各种阅读数据,这些数据对于研究者,对于产品本身,和对于用户都是非常有价值的。而对于数字化阅读行为方面的研究,国内外通常采用问卷调查法、访谈法、文献分析法、测试法、实验法、日志法等非技术方法,在研究仪器上多用眼动记录仪、功能性核磁共振仪、面部识别仪器等[1-2],而专门针对儿童评论数据进行分析的研究还比较欠缺。
1 数字阅读行为研究价值和意义
数字化阅读相对于纸质阅读不再是以静态的、扁平化的方式呈现,对于低龄儿童,会有声音辅助,优美动听的声音和丰富多彩的音效让儿童能较早地就能够接受书本上的知识,动画的效果也会让儿童更加关注于阅读内容,从而在阅读载体的方式上进化使儿童超前阅读。而有实验也表明,儿童确实是喜欢动态的事物,而且儿童的想象力是非常丰富的,儿童虽然接受了各种书本知识,但此时儿童的想象力会让他不局限于书本,而是拥有了大量阅读材料使得儿童的想象力得到完全的释放。从而,儿童的阅读兴趣和认知能力将得到前所未有的提高[3]。
数字阅读行为数据是指儿童在进行数字化阅读过程中所产生的可见和不可见的并且可以被记录的数据。可以概括为总括性阅读行为数据、过程性阅读行为数据、结果性阅读行为数据[4]。总括性阅读行为数据主要是指APP的一些基本数据,比如用户登录了多少次、一次在线多久、阅读一本书要多久、一般会阅读基本书、总共会阅读多少字等;过程性阅读行为数据,也就是在阅读过程中产生的详细数据,比如点击某个按钮的次数、在某页面停留了多久、数字图书和音频下载了多少次、音频类图书收听了多少次等。结果性阅读数据,主要是指有分享与评论性质的数据,对数字图书阅读完以后的反馈,比如对某一个数字阅读内容的分享与评论,还有一些APP会有阅读后的带有答题性质的小游戏,以此生成阅读数据报告,反馈给家长可以监控孩子的阅读情况和效果[5]。由于数字阅读的多媒体性质,儿童的阅读行为也变得丰富起来。因此,本文的研究目标是对家长及儿童的评论文本和语音信息进行挖掘与可视化分析,以便进一步了解家长及儿童的偏好有重要的意义。
2 数据采集方式与实现
在所要采集数据类型方面,限于第三方基本上只能抓取到可见型数据,因此本设计将会采集故事类APP的评论区数据,数据类型包括文本数据和音频数据,数据主体包括家长和儿童对于音频故事的反馈;基于移动端数据抓取的多种抓包工具和抓取方法,在抓包工具上选择Fiddler抓包工具获取移动端APP的数据包;在抓取方法上选择Python的Requests库、Selenium库来实现移动端数据的抓取;在爬取效率方面,用多进程的方法,提升爬虫程序爬取的速度和效率,实现高并发[6]。
爬虫的原理就是模拟浏览器访问网页,然后获取网页中我们想要获取的数据。浏览器访问网页的过程:在搜索栏输入网页地址后,经过域名服务器向服务器发送请求,服务器经过解析后会向用户发送浏览器HTML、JS、CSS渲染后的结果,所以用户看到的渲染后的结果就是由HTML代码构成的,爬虫就是为了获取想要获取的那部分内容,例如文本、图片、视频等资源,就要分析和过滤HTML代码,编写爬虫程序,实现爬取。一个爬虫程序的基本流程就是:
(1)发起请求。通过HTTP库向所要访问的站点发起请求,也就是发送一个request请求。
(2)获取响应内容。服务器如果正常响应,我们就会得到一个response,这个response的内容便是要获取的页面内容,比如本设计要获得的文本,就是json格式的字符串。
(3)解析内容。获取json格式的网页内容后,需要转换为json对象解析。
(4)保存数据。解析出来的内容需要保存到本地,可以保存为Excel表格里,也可以保存在数据库里,各有优势。
3 可视化分析
在数据存储和分析方面,本文使用MySQL数据库来存储大量数据,使用词云图来进行词频分析并作词义分析,并用抓取到的数据对儿童数字化阅读的特点、使用状况及阅读行为进行分析;此外,为了便于第三方使用,发挥该设计的价值,增加爬虫工具以及使用界面的设计。
3.1 可视化界面设计
Python是一种高级程序设计语言,可用于界面开发。界面程序选择使用tkinter库,tkinter是python标准的GUI库,可用于建立GUI应用程序,同时这是python的内置库,不需要额外安装。
GUI程序主要导入了两个库,一个库是GUI库tkinter,用于实现GUI的编写,另外一个库是线程库threading,用于控制爬虫的线程,如果爬虫挂掉,则重新启动一个线程。这里实现一个名叫thread_it的函数,函数首先创建线程,并且判断线程是否存在,不存在线程,则重新启动线程。实现另一个名叫helloCallBack的函数,使用try-except语句捕获异常,调用实例化且设置好的tkinter窗口,执行程序,则显示框显示爬取中,同时取出输入框中的爬取的故事网站,并把程序的输出显示到tkinter产生的窗口中。最终GUI界面如图1所示,在框中可以输入故事名,输入故事网站,就可以实现对故事评论的爬取。
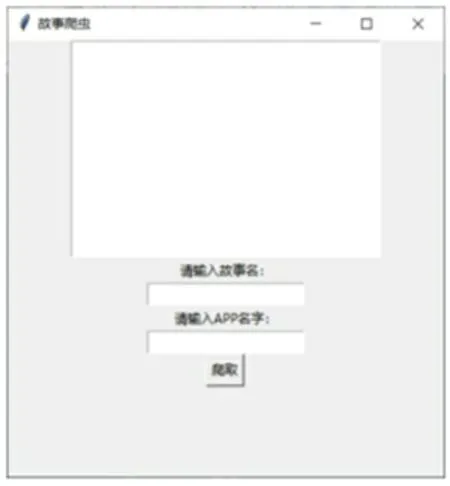
图1 采集工具界面
3.2 数据分析
词云是对文本中出现频率较高的一些词语进行突出的显示,可以过滤掉许多无关紧要的词语。实现词云图之前,需要进行简单的数据清洗工作,打开爬取的评论文本文件,评论文本包含了用户名和对应的评论,其中它们以 分隔,因为只是对评论进行词云图可视化,因此,写程序首先实现数据清洗,写入新的文件中,且只保留评论。词云图程序的实现需要三个包,分别是jieba库、wordcloud库、matplotlib库,jiaba库实现对评论的分词,wordcloud库实现词云图的配置,matplotlib库用于显示词云图。
首先,用jieba库对评论进行分词,因为分词后的结果是生成器,因此需要转换成字符串,接着设置词云图,设置字体为黑体,背景色为白色,最大词语数为2000,最大字体为50,随机值为42。设置完后,用generate语句产生词云图,用matplotlib库显示词云图,并保存词云图,程序结果见图2。

图2 数据分析结果
4 结语
数字化阅读的兴起,在给儿童带来新的阅读体验的同时,也让研究人员对数字化阅读行为的研究成为一种必然的趋势。本文以研究儿童数字化阅读行为数据为主要目的,通过采用爬虫技术爬取有代表性的数字化阅读类APP的家长以及儿童的评论进行采集并分析,对儿童及家长的偏好有了较为深入的认识,得到了有益的结论。
