图像数据增强技术研究综述
2021-05-25朱晓慧钱丽萍
朱晓慧,钱丽萍,傅 伟
(北京建筑大学电气与信息工程学院,北京 100044)
0 引言
基于数据驱动的人工智能时代已出现一个明显趋势——那些具有丰富、廉价数据的领域更容易孕育出AI 技术。但目前众多领域现有数据集大都存在规模较小、分布不均衡且采集、标注困难等突出问题,可以说数据的匮乏或昂贵往往是阻碍人工智能发展的直接原因。为解决这一问题,数据增强技术应运而生。数据增强的主要挑战是如何将现存的小规模数据集经由变化或学习,使数据拥有“自我繁殖”的能力,从而产生足量、合理且均衡的扩增数据。因此,国内外专家学者对其进行了大量研究,如今数据增强技术在医学影像、视频影音及自然语言处理等领域都有着广阔的应用前景。
目前,国内针对数据增强技术进行全面综述的文献较少。文献[1]对基于深度神经网络的少样本学习方法进行全面总结,将数据增强作为其中一类方法进行介绍,但缺乏重点性和全面性;文献[2]对基于生成对抗网络的数据增强方法进行综述,但只介绍了数据增强中的生成对抗网络技术,同样不够全面。本文则对不同种类的数据增强技术进行全面调研,重点分析所采用的典型策略。根据数据增强方式的不同,将现有数据增强技术分为有监督和无监督两大类,对这两个类别的研究分别进行讨论,并将每个类别作进一步细分,对各个子类别进行具体介绍,最后阐述各种数据增强技术在图像领域的应用。
1 数据增强及其典型分类
1.1 数据增强
数据增强也称为数据扩增,是一种扩充数据规模的有效方法。该技术的发展主要具有以下3 方面重要意义:
(1)丰富数据集本身。将不断发展的数据增强技术应用于各种数据集上,很好地解决了目前数据集存在的规模小、质量差、不均衡且难以获取等问题,从数量和性能方面丰富了数据集本身,这是数据增强对数据集起到的最直接的作用。
(2)提升相应分类检测系统性能。通过数据增强获得大量结构合理、种类多样的数据,很好地满足了深度学习模型对数据集数量和质量的高要求,减少了网络过拟合现象,从而得到泛化性能好的网络模型,对相应分类器、检测器等准确率的提升具有一定促进作用。
(3)拓展延伸价值。数据增强技术不断发展,现已广泛应用于众多领域。在数据至上的时代,从数据角度推动多个行业发展,这是数据增强技术带来的附加延伸价值,具有深远的意义。
1.2 典型分类
现有数据增强技术按照不同标准可划分为不同种类。其中较为典型的分类包括:根据数据集处理阶段分类、根据数据增强方式分类以及根据数据增强应用领域分类,具体如图1 所示。

Fig.1 Typical classification of data enhancement methods图1 数据增强方法典型分类
2 有监督数据增强
2.1 单样本数据增强
2.1.1 几何变换类
几何变换类主要从图像数据形态出发进行数据增强,包括翻转、旋转、裁剪、缩放变形以及仿射等操作。
(1)翻转(Flip)。包括水平翻转和垂直翻转,将图像的左右(或上下)部分以图像垂直(或水平)中轴线为中心进行镜像对换,显然该操作可以简单地增加样本数量。
(2)旋转(Rotation)。旋转操作是对翻转的进一步提升,一般以图像中心为旋转中心进行随机旋转(有正负角度约束),以此获得更多形态的图像数据。
(3)裁剪(Crop)。随机定义感兴趣区域,截取该区域图像并调整为原始图像尺寸。该操作相当于增加随机扰动,可获取大批量的新数据。随机裁剪几乎是所有深度学习框架训练都会采用的数据增强方法,在LeNet、AlexNet 及VGG 等经典深度学习网络训练中均有所涉及。
(4)缩放变形(Zoom)。按照设定的比例缩小或放大图像数据,但该操作会改变图像大小,存在失真问题,但全卷积网络对于尺度没有严格要求。
(5)仿射。仿射类操作包括视觉变换操作和分段仿射操作,前者通过对图像应用随机的四点透视变换加以实现,后者则通过移动图像中点网格上的点及点周围区域加以实现。
上述方法都属于几何变换类数据增强方法,以此扩增数据最为简单、常用。但过多地使用这些变换方法会导致扩增的数据样本较为单一,且会产生大量无实际应用价值的数据样本,因此研究者们又从其他角度出发提出很多变换方法。
2.1.2 颜色变换类
上述几何变换类操作没有改变图像本身内容,只是选择图像的一部分或对像素进行了重布置,因此在增强样本的多样性方面存在欠缺。若通过改变图像本身的内容实现增强,则属于颜色变换类数据增强,常见操作包括噪声、模糊、颜色变换、随机擦除以及超像素法等。
(1)噪声。基于噪声的数据增强是指在原始图片基础上随机叠加一些噪声,主要包括高斯噪声、CoarseDropout、SimplexNoiseAlpha 以及FrequencyNoiseAlpha 等。其中,添加高斯噪声是最简单、常用的方法,其通过对图像添加符合高斯分布的噪声来实现;CoarseDropout 方法则相对复杂,其通过在位置随机且面积大小可选定的矩形区域上丢失部分信息实现转换;SimplexNoiseAlpha 方法是在产生连续单一噪声的掩模后,将掩模与源图像进行混合;Frequency⁃NoiseAlpha 方法是在频域中用随机指数对噪声映射进行加权后,再向空间域进行转换。
(2)模糊。该操作通过减少各像素点值的差异实现像素的平滑化,主要包括简单、常见的高斯模糊,以及根据扭曲场平滑度与强度逐一移动局部像素点实现模糊效果的ElasticTransformation 方法。
(3)颜色变换。颜色变换是指通过多种方法实现图像视觉角度可见的明显改变,包括向HSV 空间每个像素添加或减少V 值来改变色调饱和度的HSV 对比度转换法、将图片从RGB 颜色空间转换到另一颜色空间增加或减少颜色参数后再返回RGB 颜色空间的RGB 颜色扰动法、按给定概率值将部分或全部通道像素值从v 设置为255-v 的转换法,以及将图像从RGB 转换为灰度空间再借由某一通道与原图混合的GrayScale 法。
(4)随机擦除。顾名思义,该方法就是对图片上随机选取的一块区域进行图像信息擦除操作。
(5)超像素法。从像素角度出发,在最大分辨率处生成图像的若干超像素并调整到原始大小,再将原始图像中所有超像素区域按一定比例替换为超像素,其他区域不变。
上述为颜色变换类的数据增强方法,该方法一定程度上增加了数据样本的多样性与变化性。文献[3]采用颜色变换方法对从千岛湖海参养殖场采集的数据进行数据增强,提高了模型识别的准确率;文献[4]使用色彩增强方法对CompCars 数据集进行增强处理;文献[5]利用增强模型对道路图像进行颜色空间转换,得到突出车道线的高对比度增强图像。颜色变换类数据增强方法在各领域研究中应用较为广泛,也取得了比较突出的成果。
2.2 多样本数据增强
2.2.1 SMOTE
SMOTE 通过人工合成新样本处理样本不平衡问题,该方法基于插值,可以有针对性地为小样本类合成新样本。其作为多样本数据增强方法的一种得到了有效应用,并在不断优化完善的过程中涌现出大量改进方法。针对SMOTE 在合成少数类新样本时存在的不足,文献[6]提出一种改进的SMOTE 算法GA-SMOTE,将遗传算法与SMOTE 相结合,通过选择算子对少数类样本进行有区别的选择,并使用交叉、变异算子控制合成样本质量。该改进方法不仅能出色地实现新样本的整体合成,还能有效提高分类器性能。文献[7]介绍SMOTE 算法在处理不平衡数据集过程中,存在采样有效性不足、模糊正负类边界、影响原始数据分布等缺陷。之后以此为基础,提出KM-SMOTE 和RM-SMOTE 两种优化策略。文献[8]在SMOTE 算法及其改进版本BSMOTE 两个具有代表性方法的基础上,提出DBSMOTE 算法进行新的少数类样本生成。该方法以边界样本及其最邻近多数类样本的中点作为新样本合成来源,在拓宽少数类分类边界的同时,降低了生成噪声数据的可能性。
1.1.1 试验材料 2017年5月9日在浙江省杭州市临安区浙江农林大学平山试验基地种植徐薯22.每个小区面积3.6 m2,扦插60株,3次重复.8月5日开始采收,测定小区内的甘薯叶和叶柄,间隔10 d再进行一次采收,至8月25日,共采收3次;采收的甘薯叶片叶柄在45 ℃烘干至恒质量,粉碎,过90目筛,低温保存待测.
2.2.2 SamplePairing
SamplePairing 方法主要用于数据增强,其核心原理简单,即随机从原训练集中抽取两张不同类别的图片,将其分别经过如翻转、移动等基础数据增强操作后,采用像素取平均值的方式叠加合成新数据样本,并选择原数据样本标签中的一种作为新数据标签。SamplePairing 是一种高效的数据增强手段,满足奥卡姆剃刀原理,经其处理后的训练集规模可由N 扩增为N*N。但该方法因可能引入不同标签样本而导致训练误差明显增加,且可解释性不强、缺少理论支撑,故对其的应用研究相对较少。
2.2.3 Mixup
Mixup 是基于邻域风险最小化原则的数据增强方法,其使用线性插值得到新样本数据,是对SamplePairing 的进一步延伸,也是一种对图像进行混类增强的算法,可将不同类别的图像混合以扩增训练数据。目前采用Mixup 方法进行数据增强的研究已有很多,如文献[9]从对抗训练角度解释了Mixup 工作机制,既证明了其有效性,又提出在其基础上改进的方案系列;文献[10]通过对Mixup 的深入分析,确定其“manifold intrusion”的局限性,并针对此问题提出一种新颖的自适应版本Mixup,对原方法进行了一定改进;文献[11]也对Mixup 方法进行了介绍与应用,由其训练的模型都具有很好的泛化能力。大量实验结果表明,Mix⁃up 可以改进深度学习模型在ImageNet 数据集、CIFAR 数据集、语音数据集和表格数据集中的泛化误差,减少模型对已损坏标签的记忆,增强模型对对抗样本的鲁棒性和稳定性。尽管有着较好的改进效果,但Mixup 在偏差与方差平衡方面尚未有较好的解释。
3 无监督数据增强
传统数据增强方法大多是有监督形式,但这类方法完全由使用者定义,不是所有任务都适合。故为了获得更好的训练模型,无监督方式引起了人们关注,目前主要从生成新数据和学习增强策略两个方向进行探究。
3.1 生成新数据
通过模型学习数据分布,随机生成与训练数据集分布一致的数据是无监督数据增强方法的重要组成部分。为了实现这种方式,生成对抗网络(Generative Adversarial Networks,GAN)因具有强大的学习与生成能力受到了部分专家学者关注[12]。生成对抗网络思想的诞生是受到博弈论中二人零和博弈的启发,通过两个参与者的对抗互相提升,其中包含两个模型:生成模型G 和判别模型D。具体网络模型结构如图2 所示。
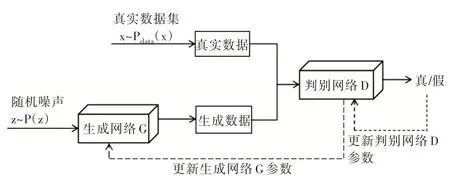
Fig.2 Generative adversarial network model图2 生成对抗网络模型
GAN 模型相比于FVBNs 模型能够并行生成样本,而不需要逐维产生;相比于玻尔兹曼机、非线性ICA 等生成模型对生成器的限制较少,能够收敛到纳什平衡,从而生成高质量的数据样本。正因具有这些优点,GAN 在数据增强领域已得到广泛应用。如文献[13]提出使用生成对抗网络进行数据增强以解决不平衡数据问题,其生成的图像样本具有较好的多样性;文献[14]将生成对抗网络应用于生物领域癌症数据样本的生成,实现训练集样本规模的扩增,相比传统方法提高了识别准确率。生成对抗网络的应用使数据增强领域迎来了突破性发展。
3.2 学习增强策略
作为无监督数据增强的另一类研究方向,学习增强策略不需要人工干预,而是通过模型自主学习出适合当前任务的数据增强方法,其中以近年来提出的AutoAugment 和PBA(Population Based Augmentation)方法最具代表性与创新性。
4 图像领域应用及性能分析
4.1 医学图像
由于医学数据本身的隐私性、复杂性以及添加专家标注的困难性,探究恰当、有效的数据增强方法是十分必要的。目前数据增强技术已被应用于肝脏组织CT、脑部MRI及胸部X 射线等医学图像增强。
文献[18]利用DCGAN 成功生成肝脏病变组织CT 图像,并与经典数据增强方法进行比较,实验结果表明,利用GAN 生成的图像对数据集进行增强能够将分类准确率提升7%;文献[19]在肺结节病变组织生成过程中,使用DC⁃GAN 生成真实性较高的结节图像;同样,文献[20]针对肺结节病变问题,也提出使用DCGAN 进行数据增强,该方法不仅克服了随机剪裁、图像缩放等操作造成的图像尺寸与病变位置变化的问题,而且还能生成质量高、形状多样的肺结节图像,且该方法生成速度更快、成本更低。针对脑部MRI 图像样本数量少的问题,文献[21]通过具有跳跃连接结构的自编码器对脑部MRI 图像进行降噪处理,并采用DCGAN 生成图像,在病理特征和图像质量两方面都与真实图像具有较高相似度;文献[22]采用左右翻转和旋转方法对MRI 图像进行增强,然后将增强后的数据样本用于医学图像分割领域,极大地提高了分割精度。另外,文献[23]运用改进的GAN 方法扩充胸部X 射线数据集,并通过图灵测试验证其有效性;文献[24]运用GAN 增强胸部X 射线图像数据集,并将其应用于卷积神经网络训练,可实现对心血管异常的分类,相较于传统数据增强方法,用GAN 进行数据增强能实现更高的分类准确率。数据增强在医学领域的具体应用远不止这些,但由此足以看出数据增强在该领域运用的广泛性和必要性。
医学图像数据增强汇总分析如表1 所示,可看出目前生成对抗网络数据增强在医学领域应用较多,且效果很好。
4.2 人脸表情图像
人脸表情识别方法使得计算机能够感知人类情感,如今在计算机视觉、模式识别、心理学及认知科学等领域都得到了广泛应用。然而,现有的人脸表情数据库规模较小且数据量不均衡。为解决该问题,文献[25]采用添加噪声、裁剪等传统方法合成新样本,为识别系统的训练提供大量数据;文献[26]比较了分别采用调整大小、裁剪、添加噪声及调整对比度等单一方法取得的效果,还分析了结合使用这些技术实现的性能提升;文献[27]的模型中也引入图像随机翻转、旋转和裁剪等数据增强方法以克服小数据问题。
传统针对图像识别任务的数据增强方法,如进行几何或像素颜色变换存在图像相似度过高的问题,无法增加图像特征的多样性。因此,文献[28]提出一种基于约束性循环一致生成对抗网络(CCycleGAN)的方法,从本质上扩展人脸表情数据集;文献[29]提出的StarGAN 模型架构有效解决了现有方法在处理两个以上域时扩展性和鲁棒性有限的问题,实现了仅依靠单个模型对多个域中图像转换生成的目标。基于此,文献[30]提出一种静态图像数据增强方法,通过修改StarGAN 模型的重构误差构造新目标函数,利用生成器生成同一个人的不同面部表情,以更好地实现多种人脸表情图像风格之间的转换。人脸表情图像数据增强汇总分析如表2 所示。

Table 1 Summary analysis of medical image data enhancement表1 医学图像数据增强汇总分析

Table 2 Summary analysis of facial expression image data enhancement表2 人脸表情图像数据增强汇总分析
4.3 行人监控安防图像
在自动驾驶、智能监控、行人分析和智能机器人等领域,行人检测技术是其中的关键环节。目前基于深度学习的行人检测方法都需要在大量有标注数据的情况下进行训练才能取得理想效果。如文献[31]使用随机颜色失真、随机扩展、随机裁剪、随机插值调整图片大小、水平翻转等传统方法增加训练量,以提高行人检测模型的准确率。然而行人样本图像的生成不仅需要行人图像自身足够真实,还要能够与背景环境自然融合,鉴于这两点要求,若直接采用普通生成式模型将难以满足实际需求;文献[32]提出一种新颖的自动化生成带标注行人数据的方法——PSGAN,其是第一个把生成对抗网络用于行人或物体检测类任务的数据增强模型,可提高检测准确率;文献[33]提出基于生成对抗网络的铁路周界行人样本生成算法,生成图像与原图像基本相似,有较好的泛化性能且能更好地兼顾环境;文献[34]为解决行人数据集规模小的问题,也提出基于GAN 的数据增强方案。行人样本图像数据增强汇总分析如表3 所示。

Table 3 Summary analysis of pedestrian sample image data enhancement表3 行人样本图像数据增强汇总分析
4.4 讨论
无论是医学还是行人安防等领域图像,数据增强方法本质上都是相似的:传统直观的方法是对不同信号进行裁剪、拼接、交换、旋转、拉伸等,基于深度学习模型的方法主要是生成与原数据相似的数据。有监督增强方法大多应用于各领域的分类检测任务,而无监督增强方法既在分类检测任务中有所应用,也在独立数据样本生成任务中有所涉及。但无论在哪个领域,只要选取适合的数据增强方法,均能起到一定的效果。
5 结语
本文综述了数据增强技术采用的主要方法及其应用研究,具体从有监督和无监督两方面进行介绍,并介绍了数据增强技术在图像领域的应用。数据增强技术作为快速解决数据不平衡或数据缺失问题的一种强有力的工具,展现出极大的价值和潜力。数据增强方法作为缓解图像数据集不足等问题的有效措施已得到较广泛的应用,对具体方法的选择与已有数据及任务目标息息相关。在后续研究中,如何通过分析已有数据及要完成任务,选择更合适或运用更恰当的数据增强方法成为研究者们需要进一步探究的问题。
