基于视频和人体姿态估计的老年人摔倒监测研究*
2021-05-18黄展原李庚浩
黄展原,李 兵,李庚浩,3
(1.对外经济贸易大学信息学院,北京 100029;2.东北大学计算机学院,加州 圣荷西 95136,美国;3.中国人民大学汉青经济与金融高级研究院,北京 100872)
1 引言
据中国国家统计局2018年发布的统计数据显示,我国目前老年人(65岁及以上人群)超过1.58亿人。这一数字在未来几年将持续增长。老年人由于平衡能力和视力等身体机能的退化,摔倒事件经常发生。具体来说,每年约有三分之一的老年人发生过摔倒[1]。摔倒对年轻人来说并不要紧,但对老年人却是非常危险的。它可能导致一些严重的疾病,如髋部骨折、头部受伤或心脏病发作。故而,摔倒成为中美两国老年人因伤致死的头号原因[2]。幸运的是,就医时间与摔倒死亡率之间存在明显的正相关。换句话说,如果能在很短的时间内就医,摔倒的老人可能不会有严重的后果。因此,自动化的摔倒监测越来越受到研究者和医护人员的关注。它可以在监测到老年人摔倒时自动发出警报,其家人或附近的医院可以迅速做出反应,以挽救生命或降低摔倒受伤的严重程度。
摔倒监测并不是一个全新的研究领域,早在20世纪80年代就有学者做过关于老年人摔倒的统计研究[2]。进入21世纪以来,也有学者借助机器学习方法,尝试实现自动化的摔倒监测[3,4]。最近两年,随着硬件能力的提升和深度学习的崛起,摔倒监测重新受到人们的关注。一些学者借助新出现的人工神经网络提升摔倒监测的准确率[5]。从目前摔倒监测的3种主流方法看,基于穿戴式传感器的方法和基于环境传感器的方法,都有设备复杂昂贵、操作不方便以及识别率低等缺陷;而基于3D视频的摔倒监测方法,由于计算复杂度较高导致处理速度过慢,实时性较差。基于2D视频的摔倒监测研究作为一个新兴的研究方向,具有计算量小、处理速度快等特点,但积累的数据集规模较小,模型的泛化能力和实际应用效果都有待于在实践中进一步验证和提升。总之,与包含深度数据的3D摄像头相比,基于2D视频的摔倒监测性价比更高,并且可以直接应用于现有的监控系统当中,更具实际价值。本文基于2D视频来进行摔倒监测研究,并将人体姿态特征[6]引入到摔倒监测中,尝试对本文算法的敏感性和实效性进行提升。
2 相关工作
目前,摔倒监测有3种主流方法,包括基于穿戴式传感器的方法、基于环境传感器的方法和基于视频的方法。
2.1 基于穿戴式传感器的方法
基于穿戴式传感器的摔倒监测方法的设备又可以分为按键设备和自动式设备。按键严格意义上不算传感器,它在老年人摔倒后被按下,类似一键报警设备。按键式设备在老年人摔倒丧失行动能力后不适用,自动式的穿戴传感器则更具实用价值。其中,自动式的穿戴传感器监测又可以分为基于人工设定阈值的方法和基于机器学习的方法。早在2007年,Chen等人[7,8]就已经相继提出了基于人工设定阈值的方法。他们通过对三轴加速度传感器数据设定阈值,进而进行摔倒事件的判定。Zhang等人[9,10]则相继提出了基于机器学习的摔倒监测方法。他们利用SVM对加速度传感器的数据进行训练,建立可靠的分类器。基于可穿戴传感器的方法经过多年的研究,可以实现相对可靠的监测,但其本身固有的缺点依然存在。比如虽然它的漏检率较低,但是容易出现假阳性,即容易将坐下、蹲下和躺下等动作判定为摔倒。同时,移动设备的携带和充电也是一个问题。这并不适合应用在老年人的摔倒监测上,因为老年人可能会忘记佩戴设备及为其充电。
2.2 基于环境传感器的方法
基于环境传感器的方法由于不影响老年人的生活,曾经受到许多关注。在2006年,Alwan等人[11]就引入了一种基于地面振动的摔倒监测方法,它几乎不会影响老年人的正常生活。Rimminen等人[12]也采用了地面传感器,利用近场成像进行摔倒监测,在少量数据的测试中取得了90%左右的敏感性和特异性。这些环境传感器被安装于地面下方。尽管这类研究取得了较高的准确率,但由于每台设备成本过高、监测范围小,很难将其应用于现实环境中。因此,我们可能需要性价比和准确率更高的方法。Zhuang等人[13]使用远场话筒将摔倒与家庭环境中的其他噪音区分开来,并利用高斯混合模型分类,但该研究的准确率并不高,在实验室环境中也只能达到67%左右的准确率,同样无法在现实环境中使用。
2.3 基于视频的方法
基于视频的摔倒监测研究由来已久,不少学者将精力放在3D视频的摔倒监测上。早在2010年,Zambanini等人[3]利用多个摄像头进行3D建模,尝试引入人体的3D特征来提高准确率,但效果差强人意。一年之后,Rougier等人[14]把人体形状轮廓和3D建模结合起来,达到了看似精准的检测效果,但由于当时用于测试的数据集太小,并没有很强的说服力。Rougier等人[15]尝试提出鲁棒性更好的算法,即通过计算3D人体加速度来减小摔倒事件将要结束时被家具遮挡的影响。2015年,Stone等人[16]别出心裁地使用了Microsoft为Xbox游戏机开发的Kinect体感设备来进行摔倒监测,并取得了不错的效果。但是,基于3D视频的摔倒监测有很大的局限性,首先,成本较高;其次,若利用成本较低的深度摄像头,又会受限于它对被测物体位置的严格要求;最后,计算复杂性高,会导致处理速度过慢。
另一个研究思路是基于2D视频的摔倒监测研究。Chen等人[17]在2010年就将前景提取算法应用于2D图像,并将人体形状轮廓的变化作为摔倒的主要特征进行摔倒监测,但由于测试数据过少,我们很难评判这种方法在现实场景中的应用效果。Liu等人[18]利用KNN分类器将人体轮廓边界的高度和宽度的比值和临界时间差进行分类,对跌倒和躺下事件检测的准确率为80%左右。Charfi等人[19]手动选择了一些基于人体边界框的高度和宽度及比例、人体的轨迹及其方向等特征,并利用SVM分类器分类,取得了超过90%的准确率。然而与此同时,他们的研究是基于自己制作的小规模数据集,这导致其模型并没有很好的说服力。但是,这些研究在特征选择和分类器的多样性上仍然取得了不小的进步。总之,与包含深度数据的3D摄像头相比,基于2D视频的摔倒监测性价比更高,实时性更好,并且可以直接应用于现有的监控系统当中,更具实际价值。本文也将基于2D视频来进行摔倒监测。
在2016年,Wang等人[20]提出了一个全新的研究框架,即把摔倒监测分为2个阶段。第1步训练一个静态分类器,即将每一帧图像用支持向量机进行分类并为其标注相应的3种标签,包括未摔倒、摔倒中和已摔倒。第2步训练一个动态分类器,即将上一步骤生成的标签序列作为第2个支持向量机的输入,进而达到分类视频的目的。这个序列的长度因研究而异,该研究的序列速度被设定为30 fps,而另一项研究的序列速度被设定为16 fps[19]。Wang等人[20]的研究使用了当时较为流行的神经网络PCANet作为特征提取算法。最后他们在公开的摔倒数据集上实现了89.2%的敏感性和90.3%的特异性。一年之后,Wang等人[21]尝试改进这个方法,他们将方向梯度直方图和局部二值模式提取的低层特征和用Caffe提取的高层特征相结合,再进行二阶段摔倒监测。然而,这项研究对结果的提升并不显著。2018年,Zerrouki等人[22]认为摔倒是一个与时间序列紧密相关的事件,在利用支持向量机作为分类器的基础上,将隐马尔可夫模型引入摔倒监测领域。在实验中,他们只给出了测试集最后的总体准确率,没有足够说服力。
综上,基于视频的摔倒监测具有成本低、实时性好和可靠性高等优点,且不需要老年人佩戴外部设备或为其充电,方便快捷;但另一方面,一些调查指出,可能会有部分老年人在实际应用中有一种被监控的不适感。总体来说,在利大于弊的同时,基于2D视频的摔倒监测方法仍然有一定的提升空间。先前的大部分研究都没有考虑到人体姿态对摔倒的影响,故本文引入人体姿态特征,尝试对本文算法的敏感性和实效性进行提升。
3 数据基础
3.1 人体姿态信息抽取数据集
本文在基于2D视频的摔倒监测研究中,需要将人体关节位置信息作为特征项,引入到摔倒监测模型中。本文利用OpenPose提取原始数据中人体关节的位置[6],该数据集和开源框架是由卡内基·梅隆大学的感知计算实验室建立的,可以检测包含多人图像(2D和3D)中的人体关节点。该数据集和开源框架可以提供2D多人实时人体关节点监测,是第1个可以同时检测人体、手、面部和足部关键点(总共135个关键点)的实时多人系统。
3.2 模型效果验证数据集
为了验证引入人体姿态数据的模型准确性和泛化能力,本文选取了3个在摔倒监测领域常用的公开数据集进行模型效果验证,如表1所示。
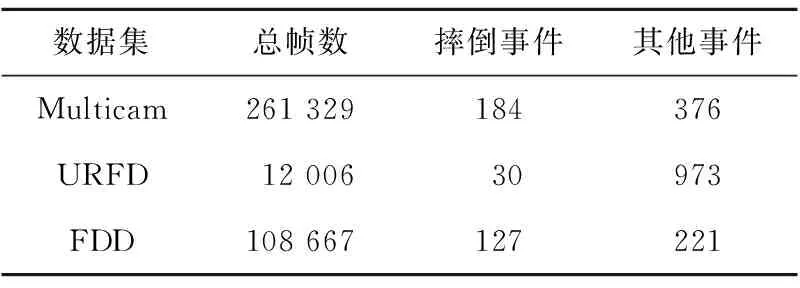
Table 1 Fall dataset statistics表1 摔倒数据集统计信息
第1个数据集Multicam(Multiple cameras fall dataset)包含24个不同的场景,每个场景的视频都由8个不同方位的摄像头进行录制[23]。其中22个视频包含了摔倒事件,剩下2个视频只有一些迷惑性的事件,比如坐下、蹲下和躺下等。这些视频拍摄的速率为30 fps,分辨率为720×480,每段视频长度在30 s~1 min不等,共31.2 GB。每个场景的1~7号视频都被作为训练集,而8号视频则作为测试集。
第2个数据集URFD(UR Fall Detection)包含70个视频序列,其中30个视频中包含摔倒事件,剩余40个视频是一些日常生活中的迷惑性事件,比如坐下、蹲下和躺下等[24]。这些视频拍摄的速率为30 fps,分辨率为640×480,每段视频长度在3 s~30 s不等,共8.5 GB。随机选取50个视频序列作为训练集,剩余20个视频作为测试集。
第3个数据集FDD(the Fall Detection Dataset)包含191个视频序列,有家庭、咖啡馆、办公室和教室等场景[25]。这些视频是以25 fps的速率录制的,分辨率为320×240,每段视频长度在30 s~1 min不等,共16.3 GB。随机选取130个视频作为训练集,剩余61个视频作为测试集。
4 技术方案
4.1 技术路线
基于视频的摔倒监测通常都由3个步骤实现,分别是数据预处理、特征提取和分类。本文提出的基于2D视频的摔倒监测方法的技术路线如图1所示。具体步骤如下:
(1)数据预处理,即规范图像大小并合理去除部分冗余的帧数,以提升整体实验的效率。
(2)特征提取,即利用OpenPose提取原始数据中人体关节的位置[6]。
(3)构建静态分类模型,即利用这些具有增强特征的数据和支持向量机分类每一帧的状态[4]。
(4)构建动态分类模型,即引入时间维度的特征进行摔倒监测。
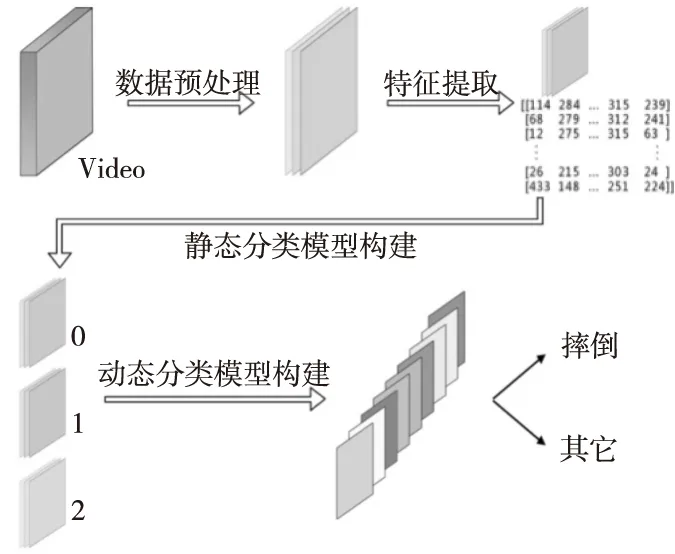
Figure 1 Research technology roadmap图1 研究技术路线图
4.2 关键步骤
4.2.1 数据预处理
在摔倒监测的问题中,数据预处理是最重要的步骤之一[20,21]。本文的数据预处理共分为2个步骤,如图2所示。
第1步,将所有原始数据切分为单帧图像,以便于后续处理。
第2步,对原始数据的帧进行抽取,以加速训练和测试过程。通过对原始数据的研究,我们发现摔倒事件的完整展现并不一定需要每秒25帧或30帧。在很多情况下,保留大约一半的帧数便可以区分摔倒与否。如图2所示,按照每相邻2帧保留1帧的方式删除多余的帧数,在不大幅降低准确率的前提下,最大化地提升本文算法运行效率。
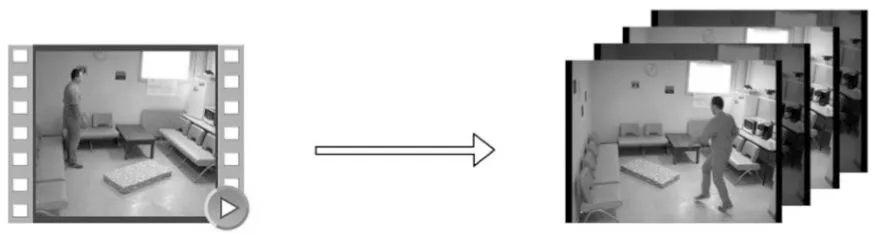
Figure 2 Schematic diagram of data preprocessing图2 数据预处理示意图
通常来说,许多研究会在数据预处理阶段采用各种前景提取算法将动态的人体和静态的背景区别开[3,17],比如混合高斯模型和ViBe算法[26,27]。
4.2.2 特征提取
在特征提取部分,将经过预处理的每一帧图像(如图2所示)作为输入,利用OpenPose开源库,输出效果图和15个关节点的坐标。其中,效果图是为了用于检验结果,而坐标数据是用于构建静态分类模型。
如图3所示,3个数据集中每个人的15个关节点位置均可正确表示。尽管这些数据集中图像序列只包含一个人,但本文提供的算法可以在一个房间中进行多人监测。当人们跌倒时,他们的身体关节点开始剧烈扭曲,姿势非常不自然。这导致了OpenPose输出的关节坐标会发生异常,这可能是一个很好的特征。

Figure 3 Feature extraction diagram图3 特征提取效果图实例
4.2.3 静态分类模型构建
摔倒是在一段连续时间内发生的事件,要想直接分类并不容易。通过对比各种算法对计算资源和数据集规模的要求[4,20,28 - 30],以及相应的评价效果等,本文确定了采用2个SVM分类模型实现时间和空间维度上分类的方案。建立静态分类模型,即对每一帧图像进行分类。由于摔倒是一个过程,每一帧都有一种状态。在本文中,状态可以分为3种,包括正常状态、摔倒进行中的状态和摔倒已结束的状态。
静态模型的核心算法为支持向量机SVM[4]。在许多实际问题中,样本并非线性可分的,因此可以采用基于核方法的SVM[1]。核方法即利用一些核函数将样本从原始的特征空间映射到更高维度的空间中,使得样本线性可分。本文研究的摔倒监测问题,由于特征维数并不多且样本适中,在没有足够先验知识的情况下,在实验中选择使用高斯核函数(RBF)[1]。
在摔倒监测的问题中,样本类别是不均衡的。例如,图4中状态1(摔倒中)和状态2(已摔倒)在视频中占帧数的百分比大致为3%~7%,所以需要采用不同方法平衡分类器。通常可以从样本和算法2个角度入手,比如可以通过欠抽样,即只使用部分多数类样本进行训练。但是,目前已有的摔倒数据集样本量较小,因此本文考虑从算法层面来进行处理,即利用惩罚系数和类别权重参数分别控制对错分样本的损失度量和不同类别样本的权重。同时,按照样本数据集的大致比例,来缓解样本不平衡和过拟合所带来的问题。

Figure 4 Data schematic diagram of static classification model图4 静态分类模型的数据示意图
4.2.4 动态分类模型构建
建立动态分类模型即对多帧序列进行分类。静态分类模型已经将每一帧图像分类至某种状态,包括正常状态0、摔倒进行状态1和摔倒已结束状态2。根据这3种状态,可以描述视频中的所有过程,比如标签“0011122”很可能表示一个摔倒事件的发生。而对于整个视频,其间可能发生了若干次摔倒,则动态模型每次只需要将视频中一段时间所包含的内容进行分类即可。通过计算发现,在数据集中发生摔倒的平均所需帧数为14帧左右(视频录制条件为每秒30帧),考虑到要让动态模型分类必须保证每次输入的帧数包含一部分摔倒前和摔倒后的影像,所以每次输入20帧左右即可。同时考虑到数据预处理中只保留了视频中一半的帧数,则每次输入10个连续的标签序列即可。
动态模型的核心算法依然为支持向量机。动态模型与静态模型的训练没有前后关系,因为原始数据集中已经标注好了0,1或2的标签,所以本文在训练阶段不使用由静态模型产生的标签序列,而直接使用原始数据集中的标签(ground truth)进行训练,即可最大化地避免静态模型的错误分类结果影响动态模型的建立。
5 实验评估
本文选取3个摔倒监测领域常用的公开数据集Multicam、URFD和FDD进行实验验证。实验硬件平台为一台Windows 10 64位操作系统的笔记本电脑。处理器为Intel i7-4710mq,4核8线程,最大频率为3.5 GHz。搭配三星 8 GB DDR3内存和NVIDIA GTX960m显卡。硬盘为1 TB机械硬盘搭配128 GB固态硬盘。实验使用Python 3.6.5版本,并预先安装好实验所需的OpenCV,OpenPose, cntk, Scikit-learn和NumPy等开源库,同时搭建了基于Visual Studio Code代码编辑器的开发环境。整个实验过程如下所示:
第1步,将所有以视频形式存储的原始数据按帧切分成图像,并按照每相邻2帧保留1帧的方式删除多余的帧。
第2步,在特征提取部分,将经过预处理的每一帧图像作为输入,利用OpenPose开源库输出效果图和15个关节点的坐标。每一帧图像的关节点坐标为一个包含2×15个整数(int)类型的对象,将每个数据集的对象合并为若干个文件(.json),以便分类步骤使用。
第3步,在静态分类模型构建阶段,首先,将上一步骤得到的坐标数据对象作为模型的输入;其次,对输入的特征进行缩放(Feature Scaling),以减少取值范围对模型结果的影响;再次,调整本文算法参数,对于实验中的不平衡样本,需要调整不同类别的权重,使得损失函数能够更好地发挥作用,即让每一次漏检摔倒中1和摔倒后2类别的损失变得比漏检摔倒前0(或者说是正常状态)要大很多。在实验中,经过反复地调参优化后,将3个类别的权重分别设为0.05, 0.45, 0.45。其中损失函数loss采用默认的Hinge损失函数,核函数选取默认的RBF Kernel,即高斯径向基核函数。对于RBF Kernel,必须选择合适的Gamma参数,因为它决定了核函数的形状,即数据映射到新的特征空间后的分布。Gamma值越大,则支持向量越少,反之则支持向量越多。惩罚参数默认为1.0,如果增大即表示对分类错误容忍更小,但过大将增加模型过拟合的可能性。对于惩罚参数和Gamma的确定,最稳妥的方式应该是采用网格搜索(Grid Search)进行枚举,但由于本文实验数据集较小,若使用交叉验证法,很可能会由于没有足够的数据训练造成过拟合等现象,故本文参考Charfi等人[19]和Wang等人[20]的一些实验方法和参数,将惩罚参数设置为5,Gamma设置为默认值。

Figure 5 Data schematic diagram of dynamic classification model图5 动态分类模型的数据示意图
在摔倒监测研究中,由于数据集本身的不平衡,传统的准确率无法作为可靠的性能指标来衡量算法的效果。敏感性将成为本文研究的重点,因为对于摔倒监测,本文的首要任务就是把摔倒事件的发生检测出来,即召回。由于在静态分类模型构建中有3个类别,本文重点关注标签1和标签2,即摔倒中和摔倒后的分类效果。这里的召回率即标签1和标签2样本的平均召回率,如式(1)所示:
(1)
其中,TP表示真正例的个数,即被模型预测为正的正样本个数;FN表示假负例的个数,即被模型预测为负的正样本个数。
3个数据集上的实验结果如表2所示。URFD数据集取得了最好的分类效果,这可能是由于URFD数据集统一由一个摄像头在固定位置固定场景进行拍摄,所以训练与测试并没有很大区别;FDD数据集的表现一般,这可能是由于FDD数据集包含了办公室、教室和卧室等不同场景,虽然录制角度相差无几,但仍然影响分类器效果;而Multicam数据集表现稍逊,这可能是由于Multicam数据集中每一个视频序列都是由8个不同摄像头拍摄,导致数据集噪声较大。
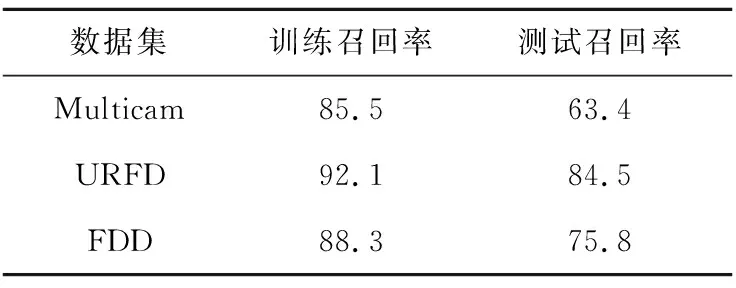
Table 2 Recall rate of static classification model表2 静态分类模型召回率 %
对于本文没有检测出的摔倒事件,我们人工地分析了部分错误案例产生的原因:(1)有过半的错误案例并没有出现特殊干扰,因此我们认为除了人体姿态特征以外,还需要引入其他重要特征。(2)有少部分将摔倒中判定为摔倒前(即正常)的案例是由于出现了家具等遮挡物,导致一开始的特征提取就出现了问题。
第4步,在动态分类模型构建阶段,将10个连续的输入作为特征,进行二分类,即对同一个滑动窗口,每10帧对应一个分类结果,即摔倒或是未摔倒。动态分类模型所用视频帧如图5所示。实验调用sklearn包实现SVM算法,以用于分类[31]。对于实验中的不平衡样本,需要调整类别权重,使得损失函数能够更好地发挥作用,即让每一次漏检摔倒事件(标签为1)的损失变得比未摔倒事件(标签为0)要大很多。具体实验中,经过参数优化将2个类别的权重设置为0.9和0.1。损失函数与核函数在前文研究框架中有详细解释,其中损失函数loss采用默认的Hinge损失函数,核函数参考其他研究,选取线性核函数(Linear Kernel)[19,20]。在确定好相关参数后还需要导入静态模型,以便测试最后的动态模型分类效果。测试结果用敏感性(召回率)作为衡量指标,如表3所示。
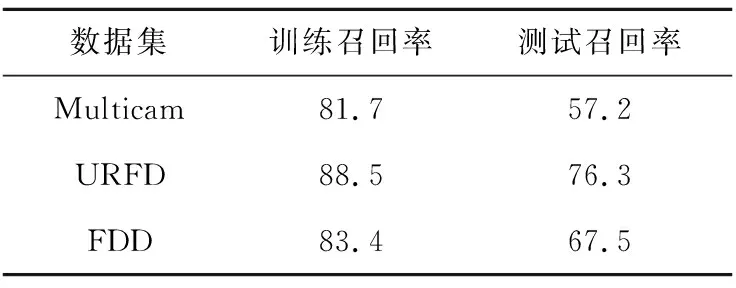
Table 3 Recall rate of dynamic classification model表3 动态分类模型召回率 %
本文人工分析了部分错误分类的案例的原因:(1)从特征提取部分就开始出错,即由于家具的遮挡无法正确识别人体姿态;(2)有不少摔倒前的滑动窗口中,坐下或蹲下的情况被判定为摔倒,这样在动态分类时输入的本来就是错误结果,最后的动态分类结果自然也不会正确;(3)最后的动态分类出错,比如在摔倒事件发生之前就判定摔倒开始,在摔倒事件结束后很多帧才判定摔倒结束。
对于整个摔倒监测流程而言,动态模型的构建完毕也就标志着整个实验的结束。更进一步地,本文通过上限分析(Ceiling Analysis)发现,动态分类模型的提升空间并不大,而特征提取和静态分类模型部分有更大的提升空间,这可能也是接下来需要改进的部分。因为许多研究并未公布每个数据集的准确率,而是公布了3个数据集的平均准确率,所以我们很难参考和对比他们的研究成果。但总的来说,本文仅使用人体姿态特征就取得了不错的分类效果,因此,进一步结合其他特征的摔倒检测研究值得期待。
除了对模型的分类效果进行评估以外,本文对模型的实时性也进行了评估分析。因为摔倒监测的实时性对于人工干预效果具有较大影响,因此模型测试运行的实时性也是一个重要指标。由于实验条件的限制(单机普通笔记本电脑的情境下),数据处理速度为30 fps,大概有3倍左右的延迟,即视频播放1 s,判断摔倒与否的结论会在3 s后得出,无法实现完全实时的摔倒监测。如果在云计算平台应用该方法,视频连接到互联网进行摔倒监测,应该能够实现实时的摔倒监测。这也是未来的研究方向之一。
6 结束语
本文提出了一种基于人体姿态估计的2D视频摔倒监测算法。首先,使用OpenPose提取原始数据中人体关节的位置;其次,利用这些具有增强特征的数据和支持向量机算法构建静态分类模型,以有效区分每一帧的状态;最后,构建动态摔倒监测分类模型。本文算法在3个公共摔倒数据集上进行摔倒监测,取得了不错的效果。
本文的主要贡献有:(1)将人体姿态估计方法引入到2D摔倒监测领域;(2)采用基于人体状态特征的静态分类和动态分类相结合的方法进行摔倒监测研究。
基于视频的摔倒监测是一项非常有潜力的研究。在未来,将从以下方面深入研究摔倒监测问题:(1)搜集更多的真实环境下的摔倒视频,这是目前所缺乏的;(2)引入神经网络的方法提取一些高层特征,以提高召回率。同时,采用并行计算技术,将可能在更短时间内得出监测结果。
