基于OPS的计算流体力学软件多平台自动并行*
2021-05-18车永刚徐传福王正华
王 巍,车永刚,徐传福,王正华
(国防科技大学计算机学院量子信息研究所兼高性能计算国家重点实验室,湖南 长沙 410073)
1 引言
当前,除了通用处理器之外,通用图形处理单元GPGPU(General-Purpose Graphic Processing Unit)、Intel集成众核MIC(Many Integrated Core)、通用数字信号处理器GPDSP(General- Purpose Digital Signal Processing)等加速部件被广泛应用于高性能计算机系统中,高性能计算机变得越来越异构和多样化[1 - 3]。因此,高性能计算应用软件的开发将面向多样化的体系结构。而高性能计算应用软件的生存期通常比硬件长得多[4],针对不同体系结构的并行编程与性能优化导致极大的开销。因此,使所研制的高性能计算应用软件具有性能可移植性(即代码无需经过大量修改或使用不同的编程语言重写,就可移植到不同体系结构平台上并获得可接受的性能),是发展高性能数值模拟的迫切需求[5]。
现今主流的并行软件开发方法是由开发人员根据软件的算法特点和流程等设计程序并行结构,在源代码中手工添加MPI、OpenMP、CUDA、OpenCL等并行编程语句的代码,进行手工并行编程。手工并行编程要求开发人员熟练掌握前述等并行编程规范和语言,并深入了解底层硬件体系结构才能编写高效率的代码,且开发工作量大、周期长,很难获得性能可移植性。
基于高性能库(如BLAS(Basic Linear Algebra Subroutine)、FFTW(Faster Fourier Transform in the West)等)编程的方法在一些情况下可以方便地获得性能可移植性,但是可用的高性能可移植库非常有限,并且对实际应用软件来说库调用通常只能覆盖其部分计算任务。基于可移植编程框架的方法是另一种途径。例如美国E级计算计划中Kokkos项目[6]提供了共享存储和分布存储编程模型以及相应的C++库,使用Kokkos编写的单个并行代码经过少量面向体系结构的修改,就可在多种体系结构平台上编译执行[5],但可移植编程框架通常只支持C++编程语言,并且其针对不同体系结构的优化能力还比较弱。
基于领域特定语言DSL(Domain Specific Language,或称领域专门语言)的并行化方法提供了一种较为可行的途径,得到研究界的关注。领域特定语言针对某一领域的特定问题,提供一套简洁抽象的高层语义结构,开发人员使用其来编程描述所要计算的问题,然后由一个低层软件来自动将这些描述转换成不同平台上的实现,使软件具有良好的性能可移植性。目前研究人员提出了许多面向高性能计算的DSL框架。如牛津大学开发的结构网格下并行求解库OPS(Oxford Parallel library for Structured mesh solvers)[7,8]和非结构网格问题求解的DSL框架OP2[9]、斯坦福大学开发的Liszt[10]、弗吉尼亚理工大学等开发的基于网格的语言与自动并行化框架GLAF(Grid-based Language and Auto-parallelization Framework)[11]、日本东京工业大学等开发的针对层次式多体算法的隐式并行编程框架Tapas[12]、路易斯安那州立大学等开发的基于高性能计算机体系结构的偏微分方程求解DSL框架Chemora[13]等。
本文旨在探索基于领域特定语言OPS实现计算流体动力学CFD(Computational Fluid Dynamics)软件面向多平台自动并行编程技术,评估OPS针对CFD应用软件在各种并行体系结构上的并行能力,探索高性能计算应用开发的新途径。本文选择了一个结构化网格下基于有限差分的高精度CFD应用软件HNSC (High order Navier-Stokes simulator for Compressible flow),使用OPS API对其进行了转换,基于OPS前端和后端面向纯CPU平台和GPU平台生成了并行代码,并与其手工实现的并行版本的性能进行了测试比较。测试结果说明,对所评价的应用软件,基于OPS的方法获得的性能与手工版本性能可比,并且具有跨CPU与GPU可移植的优势。
2 OPS简介
OPS是英国牛津大学等开发的一套嵌入在C/C++及Fortran语言中,可为多区结构网格应用程序生成底层并行代码的DSL。它包含源到源的转换程序,可将基于OPS框架开发的源代码转换成在各种并行编程模式下实现的并行代码。用户提供包含所要进行计算的全部代码和对OPS函数的调用,而OPS负责控制对给定体系结构上的各个计算循环的并行化。在使用上,OPS类似于传统的编程框架,包括相应的接口以及支持这些接口的库。
2.1 结构网格下计算过程的抽象
OPS将多块结构网格下的科学计算抽象成4个主要元素,即:网格块、定义在网格块上的数据集、数据交换区和格式计算操作。OPS将有序排列的多块结构网格看作是一系列无序排列的网格块的组合,通过相应的接口定义网格块之间的数据交换行为,使其能正确地描述多块网格下的计算,网格块给出所计算问题的维度,计算规模则是通过数据集的定义给出的,数据集是计算的操作对象,数据交换区则是网格块之间的数据交换行为的具体定义,格式计算操作是对数据集中网格点数据访问方式和操作的描述。
OPS在结构网格上描述格式计算操作时,先定义一个计算格式,即计算一个网格点数据时,要访问相邻的网格点的个数以及这些相邻网格点相对于要计算的网格点的索引偏移。这种描述契合有限差分等科学计算本身的逻辑特点。
2.2 自动代码生成
OPS提供一个源对源的前端代码转换器,可以将基于OPS接口编制的代码自动转换成多种并行模型和规范下的代码,包括针对CPU平台的MPI、OpenMP,针对GPU平台的CUDA、OpenACC和OpenCL。代码转换器在生成的代码中自动添加上述编程规范的语句指导程序异构和并行,不需要开发者再手工修改代码。进而基于OPS为不同平台提供后端运行时库,采用本地编译器(如GNU编译器、Intel编译器等),将这些代码编译生成面向各种硬件平台的可执行程序。
2.3 OPS的优点
OPS对多块结构网格下科学计算程序的抽象符合科学计算本身的逻辑,容易被特定领域开发者所接受和使用。在当前高性能计算平台向多样化发展的形势下,开发者采用OPS开发维护一套源代码就可以得到面向多种平台的可执行代码,极大地提升了软件开发效率。同时,OPS自动实现多种模式的并行代码,其前端代码转换和后端库实现中都包含了多种性能优化技术,使特定领域开发人员无需掌握并行编程的细节就可以开发出高效的并行代码,从而使其可以将精力集中在自身领域的问题解决上。
3 HNSC软件的OPS实现
HNSC是一个空气动力学数值模拟的In-House软件,该软件基于由斯坦福大学Svärd、NASA兰利研究中心Carpenter等[14]提出的稳定有限差分格式,求解全三维可压缩Navier Stokes方程组,满足能量估计和分部求和规则[16],在航空航天CFD计算领域具有良好的应用背景。前期工作中,我们已经使用手工方式实现了该软件面向CPU的MPI/OpenMP混合并行,使用CUDA进行了面向GPU平台的编程。而本文研究采用OPS 对HNSC进行多平台并行编程,以一个自由剪切流算例来说明HNSC软件实现以及如何基于OPS框架来编程。
3.1 HNSC软件本身的实现
HNSC软件基于结构化网格构建一种具有高阶精度的中心差分格式来计算控制方程中的各阶偏导数项,其时间推进采用的是4阶段龙格库塔显式算法。自由剪切流算例的计算区域可以采用一个二维的矩形区域来表示,并且软件已经基于区域划分手工实现了MPI并行,手工实现的MPI并行构架如图1所示,每一个进程计算一个子区域网格上的数据,相邻的网格块或者进程(如P4和P7进程)之间通过MPI消息传递接口进行数据交换,为了满足自由剪切流的边界条件,边界上的子区域基于周期性MPI拓扑来进行数据交换,如图1中P2和P8进程所计算的子区域。
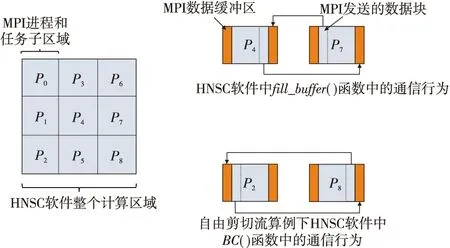
Figure 1 MPI communication involved in HNSC software图1 HNSC软件本身实现的MPI通信行为
基于图1所示的区域划分,在每一个网格区域上,HNSC软件分别对流场数据进行求解,软件的执行过程如图2所示。首先初始化MPI并行环境,Grid函数读入网格,在进行计算前通过Init函数对流场的基本未知量进行初始化,初始化之后的基本未知量通过Solvec函数组装成方便控制方程求解的守恒变量。随后进入主循环迭代,主循环中Compute_dt函数基于场变量的当前值计算时间步长,RK4函数是HNSC软件计算的核心,包含4阶龙格库塔算法的全部计算,并在一个时间步内更新场变量的数值。4阶龙格库塔计算之后,进行收敛检验,进而计算下一个时间步的步长,并将迭代时间值向前推进,如果达到最大迭代步数,计算结束。

Figure 2 Procedure of HNSC software图2 HNSC软件的执行流程
图2右侧是RK4函数内部的具体执行内容,decomp是将基本未知量从守恒变量中还原出来的函数,Flux_vec计算控制方程中的通量项,Flux_der函数计算通量的偏导数。4阶龙格库塔算法的4阶计算具有相似的流程,为了简洁图2中仅展示了第1阶计算的过程,值得注意的是在4阶龙格库塔算法的每一阶计算中,都包含2次边界条件施加函数BC的执行,这对后面将软件和算例基于OPS实现是十分重要的。
3.2 HNSC软件基于OPS的实现
结合二维自由剪切流算例下HNSC软件的行为与流程,基于OPS对其进行实现包括以下步骤和关键技术:
(1)网格块的声明;
(2)定义数据集、数据交换区及通信;
(3)定义计算格式;
(4)差分计算循环的重构;
(5)并行代码编译生成。
3.2.1 网格块的声明
在添加相应的头文件之后,可以使用OPS提供的编程接口声明一个名为grid_block的网格块:
intgrid_dim;
grid_dim= 3;
ops_blockgrid_block=ops_decl_block(grid_dim,“grid_block”);
其类型是ops_block,函数接口ops_decl_block的参数grid_dim是网格块的维度,可以是1,2或3(一般CFD的求解最多针对三维空间来求解),针对HNSC软件,grid_dim设为3。字符型参数“grid_block”是该block的标签名,用于代码转换、编译以及数据I/O时的显示和输出。
3.2.2 定义数据集、数据交换区及通信
HNSC作为CFD软件所求解的基本未知量包括密度、速度的XYZ3个坐标轴分量、压力、温度和内能,分别使用符号rho、u、v、w、p、Temp、e来表示。并且软件还将涉及CFD求解的过程变量,如通量项等。这些变量在软件代码中作为双精度浮点型数组来计算。基于OPS来实现时,也要定义对应的数据集,例如密度rho的定义:
double *rho;
intbuffer;
intsize[]={nx,ny,nz};
intbase[]={0,0,0};
inthalo_pos[]={buffer,buffer,buffer};
inthalo_neg[]={-buffer,-buffer,-buffer};
ops_datops_rho=ops_decl_dat(grid_block,1,size,base,halo_pos,halo_neg,rho,“double”,“rho”);
这样,我们在名为grid_block的网格块上定义了一个名为ops_rho的数据集,元素数据类型和指针rho一致。size是这个数据集的大小或各个坐标方向网格点的数目,注意grid_block本身的维度是3维,所以size应定义3个维度的大小,分别为nx、ny和nz。base是该数据集第1个元素的索引。halo_pos是沿着循环索引增大的方向数据集和数据交换区的大小,halo_neg是沿着循环索引负向的数据交换区的大小,其3个维度的值都是buffer,buffer的取值是由HNSC软件的差分计算的格式确定的,其值不小于坐标轴方向上的差分点个数,一般取等于差分点个数即可,对不参与格式计算的数据集,buffer的值可以是0。值得注意的是,该数据集定义接口中的第2个参数1,这意味着一个网格点对应该数据集的1个值。因为HNSC软件的有限差分法计算中,密度值和网格点是一一对应的。
求解HNSC软件时,采用守恒形式的控制方程,解向量、3个方向的通量和源项分别用符号Uvec、Fvec、Gvec、Hvec和Jvec来表示,对于每一个网格点,这些变量是一个长度nvar=5的列向量,因此对解向量应按以下方式定义数据集:
double *Uvec,*Fvec,*Gvec,*Hvec,*Jvec;
intnvar=5;
ops_datops_Uvec=ops_decl_dat(grid_block,nvar,size,base,halo_pos,halo_neg,Uvec,“double”,“Uvec”);
因为MPI并行是OPS自动实现的,不再需要关注软件实现中的任务划分,所以在定义数据集的时候,数据集的规模nx、ny、nz是图1中整个计算区域所有网格点的规模。OPS实现MPI并行时会根据数据交换区的信息halo_pos和halo_neg来定义MPI通信缓冲区。在网格块的内部,OPS将根据差分计算的循环自行定义MPI通信行为的触发。因此,在定义好数据集和数据交换区大小之后,图1中HNSC软件原本负责MPI通信的fill_buffer函数可以直接去掉。但是,由于自由剪切流算例在区域边界存在通信行为,图1中BC函数不能去掉,该函数涉及到OPS中网格块外部边界的数据交换区通信,需要显式地定义和触发。OPS提供了函数ops_halo_transfer来触发网格块外部边界的数据交换行为,该函数支持将发送和接收数据的网格块设置成同一个网格块的数据集,这样便可以实现HNSC软件中BC函数所定义的数据交换行为:
ops_halogrouprho_halo_xalong;
ops_halopos_rho=ops_decl_halo(ops_rho,ops_rho,xhalo.iter,xhalo.pbase_from,xhalo.pbase_to,xhalo.axes,xhalo.axes);
ops_haloneg_rho=ops_decl_halo(ops_rho,ops_rho,xhalo.iter,xhalo.nbase_from,xhalo.nbase_to,xhalo.axes,xhalo.axes);
ops_halogrp[] ={pos_rho,neg_rho};
rho_halo_xalong=ops_decl_halo_group(2,grp);
ops_halo_transfer(rho_halo_xalong);
上面的代码定义了对grid_block上的数据集ops_rho自身在网格块边界附近X坐标轴方向的数据交换,在pos_rho=ops_decl_halo接口中定义了一个从数据集ops_rho(第1个参数)发送一个在X轴正向侧边界附近,大小为xhalo.iter的数据块到数据集ops_rho(第2个参数),xhalo.pbase_from为数据块发送的起点,xhalo.pbase_to为数据接收的起点,xhalo.axes为发生数据交换行为的数据集之间的坐标轴对应关系。同样,neg_rho=ops_decl_halo定义了数据集ops_rho在X轴负向侧边界附近的数据块交换。OPS要求将同步执行的边界数据交换放在一个ops_halo_group类型中,再使用ops_halo_transfer函数来触发。Y方向、Z方向以及其它的数据集都按照需求定义如上数据交换行为后,将这些内容写入BC函数中,便实现了自由剪切流施加边界条件的BC函数基于OPS的改写,记为ops_BC。
3.2.3 定义计算格式
OPS通过定义计算格式来描述类似于有限差分计算,这样计算某一个网格点数据时,使用周围特定相邻网格点的数据的计算行为。具体如下所示:
ops_stencilS3D_000,S3D_5pt,S3D_25pt;
ints3d_000[] = {0,0,0};
S3D_000 =ops_decl_stencil(3,1,s3d_000,"0,0,0");
ints3d_25pt[] = {0,0,0,1,0,0,-1,0,0,2,0,0,-2,0,0,3,0,0,-3,0,0,4,0,0,-4,0,0,5,0,0,-5,0,0,6,0,0,-6,0,0,0,1,0,0,-1,0,0,2,0,0,-2,0,0,3,0,0,-3,0,0,4,0,0,-4,0,0,5,0,0,-5,0,0,6,0,0,-6,0};
S3D_25pt=ops_decl_stencil(3,25,s3d_25pt,"6,0,0:-6,0,0;0,6,0:0,-6,0");
计算格式为ops_stencil类型,S3D_000 =ops_decl_stencil(3,1,s3d_000,“0,0,0”)定义了一个三维网格块中,包含1个网格点,索引为s3d_000,标签名为“0,0,0”的计算格式,{0,0,0}是该计算格式中心网格点的坐标。计算格式中网格点的坐标是以中心网格点为基准的相对坐标或相对索引。之所以定义一个只有1个网格点的计算格式S3D_000是为了计算时进行赋值操作。S3D_25pt是HNSC软件计算二维问题时使用的计算格式,整型数组s3d_25pt定义了该计算格式中各个网格点相对中心点的索引偏移值。
3.2.4 差分计算循环的重构
OPS对软件中遍历网格点的差分计算循环使用在某个(或多个)数据集上、基于相应计算格式的访问来描述,用户定义一个kernel函数来描述对计算格式的具体操作,供OPS循环接口调用,从而实现原代码中的计算循环。HNSC中计算速度分量u对坐标x的偏导数的原代码片段如下所示:
for(k=kstart;k<=kend;k++){
for(j=jstart;j<=jend;j++){
for(i=istart;i<=iend;i++){
dudx[i][j][k]=a1_24*(u[i+1][j][k]-u[i-1][j][k])+a2_24*(u[i+2][j][k]-u[i-2][j][k])+a3_24*(u[i+3][j][k]-u[i-3][j][k])+a4_24*(u[i+4][j][k]-u[i-4][j][k])+a5_24*(u[i+5][j][k]-u[i-5][j][k])+a6_24*(u[i+6][j][k]-u[i-6][j][k] )/dx;
}
}
}
使用OPS循环接口ops_para_loop改写该计算循环如下:
intloop_range[]={0,nx,0,ny,0,nz};
ops_par_loop(kernel_uderivs,"kernels_uderivs",grid_block,3,loop_range,ops_arg_dat(ops_dudx,1,S3D_000,"double",OPS_WRITE),ops_arg_dat(ops_u,1,S3D_25pt,"double",OPS_READ));
OPS提供接口ops_par_loop来改写需要并行化的循环,它指定该循环是定义在grid_block网格块上执行范围为loop_range的一个3维(层)循环。ops_arg_dat传递该循环需要操作的数据集,并规定了针对该数据集的计算格式为S3D_000或S3D_25pt,访问方式为:OPS_WRITE(写入)、OPS_READ(读取)或OPS_RW(读写)。原循环体内部的具体计算,即对计算格式的具体操作在函数kernel_uderivs中,由用户依照OPS的编程方式来定义:
voidkernel_uderivs(double *dudx_in,const double *u_in)
{
dudx_in[OPS_ACC0(0,0,0)] = (a1_24*(u_in[OPS_ACC1(1,0,0)]-u_in[OPS_ACC1(-1,0,0)])+a2_24*(u_in[OPS_ACC1(2,0,0)]-u_in[OPS_ACC1(-2,0,0)])+a3_24*(u_in[OPS_ACC1(3,0,0)]-u_in[OPS_ACC1(-3,0,0)])+a4_24*(u_in[OPS_ACC1(4,0,0)]-u_in[OPS_ACC1(-4,0,0)])+a5_24*(u_in[OPS_ACC1(5,0,0)]-u_in[OPS_ACC1(-5,0,0)])+a6_24*(u_in[OPS_ACC1(6,0,0)]-u_in[OPS_ACC1(-6,0,0)]) )/dx;
}
OPS_ACC是OPS提供的一个宏定义,在使用的时候要根据函数的形参位置指定序号(如OPS_ACC0),并给出计算格式中网格点的相对索引(如OPS_ACC0(1,0,0))。需要特别注意的是,ops_par_loop循环的范围loop_range为{0,nx,0,ny,0,nz},遍历的是整个网格块,而{istart,iend,jstart,jend,kstart,kend}是HNSC手工进行区域分解的子区域的计算循环边界。
对图2中HNSC软件中的各个函数,都按照这样的模式来改写,并对其进行了封装。本文仅对软件主要的实现技术进行阐述,OPS还提供了相应的接口和数据类型支持HNSC软件中的归约计算操作等,具体使用规范可查阅OPS手册。在HNSC软件的所有函数基于OPS实现之后,OPS提供ops_init和ops_exit来执行相应的初始化和结束工作,MPI并行时进程通信的拓扑结构的建立也是OPS自动完成的。我们将基于OPS编写的HNSC软件称为HNSC_OPS。
3.2.5 并行代码编译生成
OPS约定所有关于格式计算具体操作的kernel函数都以头文件的形式来编写,并将项目中的文件分为HEADERS、OPS_FILE和OTHER_FILES。HEADERS即包含用户kernel函数的头文件,OPS_FILES是包含了ops_par_loop接口描述的需要并行化的循环文件,变量声明、OPS相关定义等所在的文件则放在OTHER_FILES中。用户必须按照这样的分类来使用OPS框架提供的模板化的Makefile,否则不能正确地进行代码转换与编译。模板化的Makefile将调用代码转换器进行代码转换,代码转换器以OPS_FILES作为输入,并根据这些文件中对kernel函数的调用,寻找相应的头文件,并对头文件中的kernel函数进行相应的转换,以生成面向多体系结构平台的代码,再根据不同的平台调用相应的本地编译器生成面向多平台的可执行文件。
基于OPS的前后端,本文生成得到了HNSC软件的纯MPI并行版本HNSC_OPS_MPI、纯OpenMP并行版本HNSC_OPS_OpenMP、MPI/OpenMP 2级混合并行版本HNSC_OPS_MPI_OpenMP、CUDA并行版本HNSC_OPS_CUDA。
4 性能测试与分析
本文在一个配备有2块Intel Xeon E5-2660 v3(Haswell)CPU和1块NVIDIA Tesla K80 GPU的服务器上进行了性能测试,该服务器的硬件和软件配置如表1所示。这里不仅测试了基于OPS生成的HNSC并行代码的性能,也测试了手工实现的HNSC软件的多种并行版本的性能,以进行比较分析,包括手工实现的纯MPI并行版本HNSC_Manual_MPI、手工实现的纯OpenMP并行版本HNSC_Manual_OpenMP、手工实现的MPI/OpenMP 2级混合并行版本HNSC_Manual_MPI_OpenMP,以及手工移植的面向GPU并行的版本HNSC_Manual_CUDA。测试的网格规模分别为2M和4M网格点。
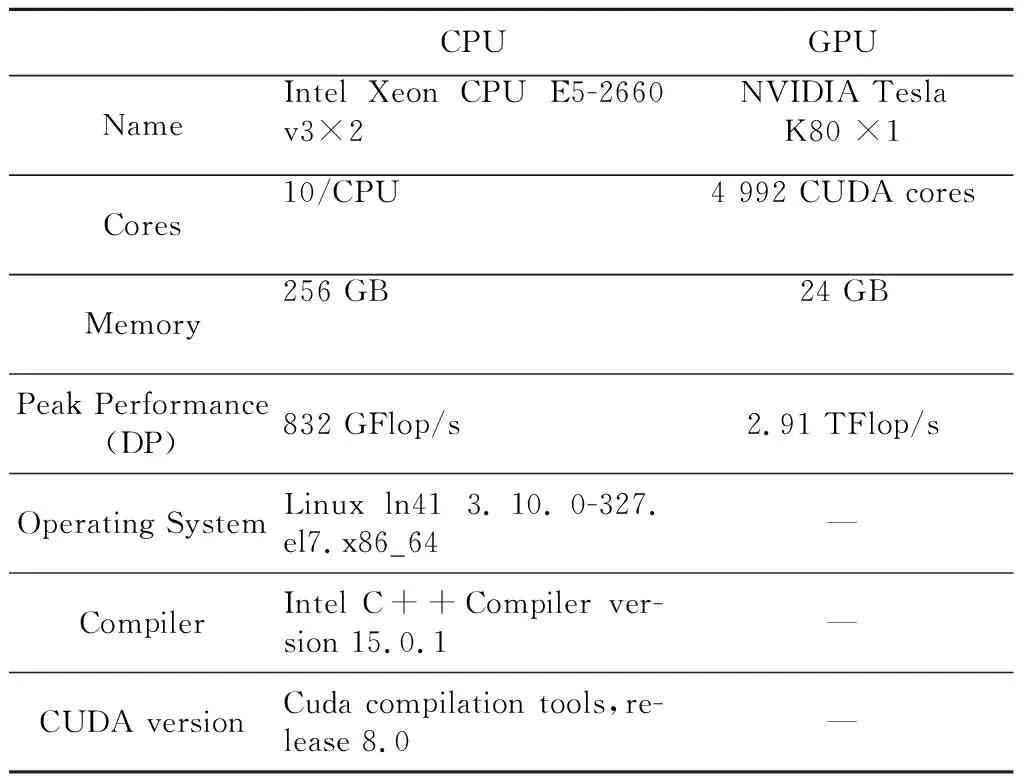
Table 1 Configuration of the server表1 服务器的配置
图3给出了纯MPI并行情况下,OPS生成的MPI并行代码与手工MPI并行代码的性能,2个版本的代码都采用的是表1中的Intel编译器,并且采用相同的编译选项:-no-prec-div-restrict-fno-alias-fma-fp-model fast=2。从图3可以看到,在1,2和4进程情况下,OPS自动生成的并行代码相比手工并行代码的性能稍低。在8,16和20进程情况下,OPS生成代码的性能优于手工并行代码的。在2M网格规模下,OPS生成代码20进程相对单进程的加速比为10.5,手工并行代码20进程相对于单进程的并行加速比为4.2。在4M网格规模下,OPS生成代码20进程相对于单进程的并行加速比为11.3,手工并行代码20进程相对于单进程的并行加速比为4.4。2种网格规模下,OPS生成的代码用满20核时获得的并行加速比都比手工并行代码的高。
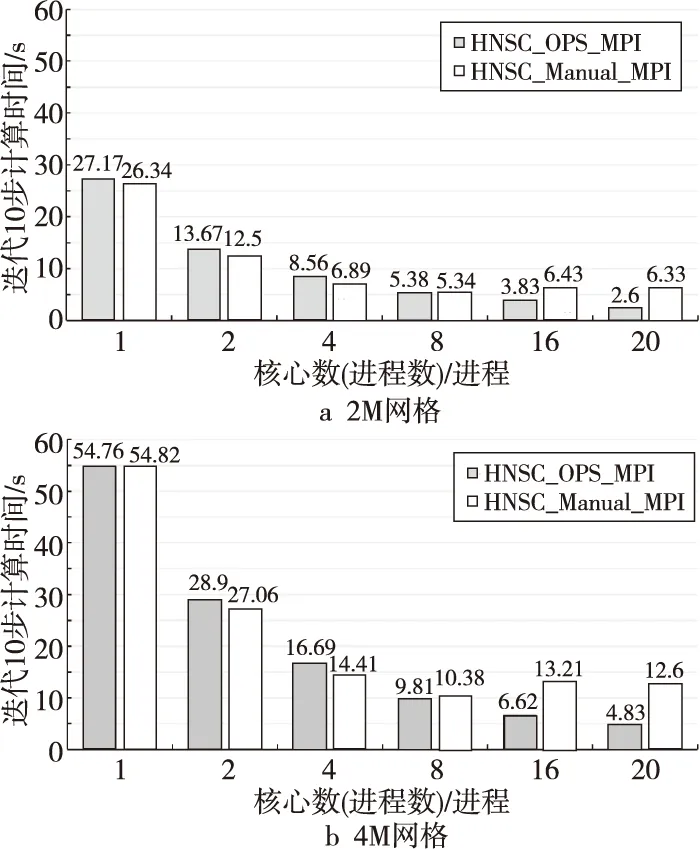
Figure 3 MPI parallel performance comparison of OPS code and manual code 图3 纯MPI并行情况下OPS生成并行代码与手工并行代码的性能对比
图4给出了纯OpenMP并行情况下,OPS生成的代码与手工OpenMP并行代码的性能,同样2个版本的代码都采用的是表1中的Intel编译器,编译选项增加了OpenMP开关:-no-prec-div- restrict-fno-alias-fma-fp-model fast=2-qopenmp,测试时的线程数都是通过环境变量来指定的。从图4中可以看到,在2种网格规模下,随着线程数的增加,OPS生成的并行代码逐渐表现出比手工OpenMP并行代码更好的性能。2M网格规模下OPS生成代码用满20核相对于单核的并行加速比为4.4,高于手工并行代码的3.8。4M网格规模下OPS生成代码用满20核相对于单核的并行加速比为5.7,高于手工并行代码的4.6。

Figure 4 OpenMP parallel performance comparison of OPS code and manual code图4 纯OpenMP并行情况下OPS生成并行代码与手工并行代码的性能对比
图5给出了MPI/OpenMP 2级混合并行情况下,OPS生成的并行代码和手工并行代码的性能对比,也是使用表1中的Intel编译器进行编译,编译选项相同:-no-prec-div-restrict-fno-alias-fma-fp-model fast=2-qopenmp。在2M网格规模下,OPS生成并行代码与手工并行代码的性能在某些进程/线程组合时性能不如手工并行代码的,但整体几乎相当。而在4M网格规模下,OPS生成的并行代码在各种进程/线程组合下的性能都优于手工并行代码的。

Figure 5 MPI/OpenMP parallel performance comparison of OPS code and manual code图5 MPI/OpenMP混合并行情况下OPS生成并行代码和手工并行代码的性能对比
图6给出了OPS自动生成的CUDA代码与手工编写的CUDA代码在NVIDIA K80 GPU上的性能对比,编译时,对于GPU端执行的核函数OPS版本和手工版本都采用表1中CUDA版本中的nvcc编译器,测试的GPU为Kepler架构,所以关于架构信息的编译选项为:-gencode arch=compute_37,code=sm_37,另外添加了性能选项:--use_fast_math,主编译器及选项和MPI版本代码相同:-no-prec-div-restrict-fno-alias-fma-fp-model fast=2。作为参考,图6中也给出了OPS生成MPI并行代码在用满20核时的性能。可以看到,OPS生成的GPU并行代码相比手工实现的GPU并行代码性能更高,在2M和4M网格规模下分别达到手工GPU并行代码的1.6倍和1.5倍。此外,在2M和4M网格规模下,OPS生成GPU并行代码相对于其MPI并行代码分别获得了2.2倍和2.0倍的性能加速。
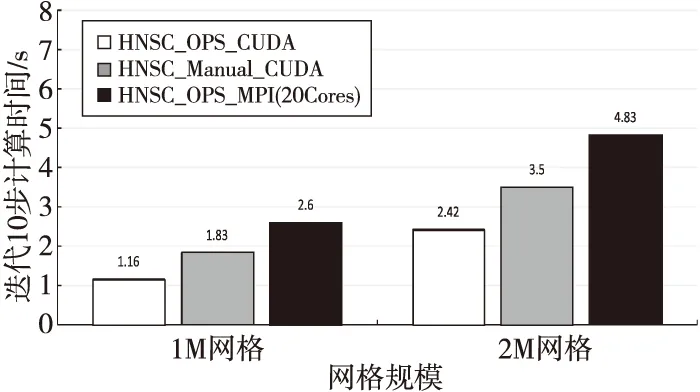
Figure 6 Performance comparison of OPS generated GPU code,manual GPU code and OPS generated CPU code图6 OPS生成的GPU代码和手工GPU代码以及OPS生成的CPU代码的性能对比
对于HNSC软件,OPS代码的性能在纯MPI并行、纯OpenMP并行、MPI/OpenMP 2级混合并行以及GPU并行4种并行模式下相较于手工并行代码能够分别体现出一定或明显的优势,原因包括2个方面:一方面,OPS自动并行和手工并行化是在同一基准代码上进行的,基准代码已经包含了如访存优化、数学计算优化等措施;另一方面,OPS中的并行代码生成过程实现了一系列高级的性能优化。例如,HNSC采用高精度差分格式,差分计算所需的通信缓冲区较宽,通信开销对性能影响较大,而OPS在MPI并行时除了对block进行任务划分并平衡负载以外,还从跨循环的全局层面分析数据依赖关系,以使MPI通信的数量和大小降到最低。OPS中还采取了一种迟滞执行技术(Lazy Execution Technique)来优化全局消息通信[9]。同时,OPS在代码生成时会从循环展开、线程调度和数据访问方面进行OpenMP多线程性能优化。此外,OPS在进行GPU并行时,提供了对Cache数据载入、纹理内存使用等的描述,OPS可以基于这些描述信息来优化GPU上的存储层次访问,而手工版的GPU代码并没有针对存储层次访问进行深入的优化。
5 结束语
本文采用OPS领域特定语言,对高阶精度计算流体力学软件HNSC进行了重构,并面向CPU和GPU平台自动生成了多个版本的并行代码。在一个有双Intel Haswell CPU和1块NVIDIA Tesla K80 GPU的服务器上的性能测试表明,基于OPS自动生成的并行代码性能与手工并行代码的性能可比,有些情况下其性能甚至优于手工并行代码的。并且OPS自动生成的GPU并行代码相对于其CPU并行代码有明显的性能加速,表明了基于OPS方法自动并行代码生成的跨平台性能可移植性。这些结果说明,使用OPS等领域特定语言进行计算流体力学并行软件开发的效率高,并且面向多平台的性能可期,是面向E级计算时代一个很有前景的方向。
