改进LSTM-RF算法的传感器故障诊断与数据重构研究*
2021-05-18王建君
林 涛,张 达,王建君
(河北工业大学人工智能与数据科学学院,天津 300130)
1 引言
传感器广泛应用于能源化工、危险可燃气体监测等领域。这些应用场景的工况复杂,导致传感器的敏感元件十分容易受到灰尘等各种因素的干扰,这些干扰会使得传感器的输出值偏离实际值。将偏离实际值的数据用于系统控制会给系统造成灾难性的后果。因此,对传感器的运行状态进行评估,并对其故障时输出的数据进行重构显得十分重要[1]。
文献[2]利用小波变换来判断传感器是否发生故障,如果发生故障则用误差反向传播BP(Back Propagation)神经网络对传感器输出数据进行预测,通过计算预测值与实际输出值之间的残差大于阈值的频率进行故障类型的识别。该方法的小波基函数一旦选定,就会使得模型的转换特性固定,从而导致模型的自适应能力变弱。文献[3]对传感器的输出信号进行经验模态分解,得到一组模态函数,将每个模态函数的样本熵作为传感器的故障特征,将这些特征通过稀疏表达分类器SRC(Sparse Representation-based Classifier)进行分类得出传感器的故障状态。该方法分类效果优异,但容易受到噪声干扰产生虚假分量的影响,不适用于噪声干扰大的场合。文献[4,5]分别通过径向基函数RBF(Radial Basis Function)神经网络和广义回归神经网络GRNN(General Regression Neural Network)对时序数据进行预测,如果预测值与传感器实际输出之间的差值超过阈值,就将传感器的运行状态判定为故障,并用预测值重构传感器的输出值。这2种方法可以实现传感器的故障诊断与数据重构,且故障诊断的准确率较高。但是,由于只是将残差与固定值进行比较,所以只能诊断出传感器是否发生故障,而无法诊断出传感器发生了何种故障,在故障诊断功能上具有一定的局限性。
传感器采集的数据为时序数据,其在时间上具有很强的关联性,长短期记忆LSTM(Long Short-Term Memory)网络可以将之前的状态、现在的记忆和当前输入的信息结合在一起,特别适用于处理时间、空间序列上有强关联的信息[6]。同时,对于LSTM细胞核来说,传感器所采集的信息在通过细胞核内各个门时其信息的遗忘和保留是相对的,所以可以通过对LSTM细胞核的改进来提高算法的收敛速度和准确率。通过预测值与传感器采集值的残差序列来获得传感器工作状态的过程,可以看作对残差序列进行分类的过程,由于残差序列的维度较高,所以此分类过程是对高维数据分类的过程。随机森林RF(Random Forest)算法通过建立的多个决策树共同投票来决定分类结果,特别适用于高维数据分类[7]。基于此,本文提出一种改进的LSTM-RF的算法,用于传感器的故障诊断与故障数据重构。该算法将传感器故障诊断与故障数据重构分别看作分类和回归的问题,并将二者合二为一。判断传感器属于哪种工作状态的依据为预测值与实际值残差序列的幅值与排序;数据是否重构的依据取决于传感器的工作状态,如果状态为故障,则重构故障数据。最后,本文利用NO2传感器采集的数据,通过实验表明了所提算法的有效性。
2 算法简介
2.1 标准的LSTM
LSTM是增加了记忆功能的循环神经网络。在组成结构上LSTM的隐藏层有3个门,分别为输入门、遗忘门和输出门。这些门的输出值大小都在0~1,输出值的大小决定了通过门的输入量的大小[8]。当门的输出值为0时,表示门关闭,此时任意量都无法通过;当门的输出值为1时,此时任意量都可以通过。LSTM通过这3个门来实现对输出值状态和隐藏层状态的保护和控制。
图1为标准的LSTM隐藏层细胞结构,其中ft为遗忘门的激活值,ot为输出门的激活值。ht和ht-1分别为t时刻和t-1时刻记忆单元的输出。ct和ct-1分别为t时刻和t-1时刻记忆单元的状态,为记忆单元候选状态[9]。设输入时间序列为(x1,x2,…,xt,…,xn),则在t时刻有式(1)~式(6):
it=σ(Wi*[ht-1,xt]+bi)
(1)
其中,it为输入门的激活值,σ为激活函数,Wi为输入门的权重向量 ,ht-1为t-1时刻记忆单元的输出,xt为t时刻记忆单元的输入,bi为输入门输入控制的偏置。
gt=tanh(Wc*[ht-1,xt]+bc)
(2)
其中,gt为记忆单元的候选状态,Wc为输入门候选状态的权重向量,ht-1为t-1时刻记忆单元的输出,xt为t时刻记忆单元的输入,bc为输入门候选状态的偏置。
ft=σ(Wf*[ht-1,xt]+bf)
(3)
其中,ft为遗忘门的激活值,σ为激活函数,Wf为遗忘门的权重向量,ht-1为t-1时刻记忆单元的输出,xt为t时刻记忆单元的输入,bf为遗忘门的偏置。
ct=it*gt+ft*ct-1
(4)
其中,ct为t时刻记忆单元的状态,it为输入门的激活值,gt为记忆单元的候选状态,ft为遗忘门的激活值,ct-1为t-1时刻记忆单元的状态。
ot=σ(Wo*[ht-1,xt]+bo)
(5)
其中,ot为输出门的激活值,σ为激活函数,Wo为输出门的权重向量,bo为输出门的偏置,ht-1为t-1时刻记忆单元的输出,xt为t时刻记忆单元的输入。
ht=ot*tanh(ct)
(6)
其中,ht为记忆单元的输出,ot为输出门的激活值,ct为t时刻记忆单元的状态。
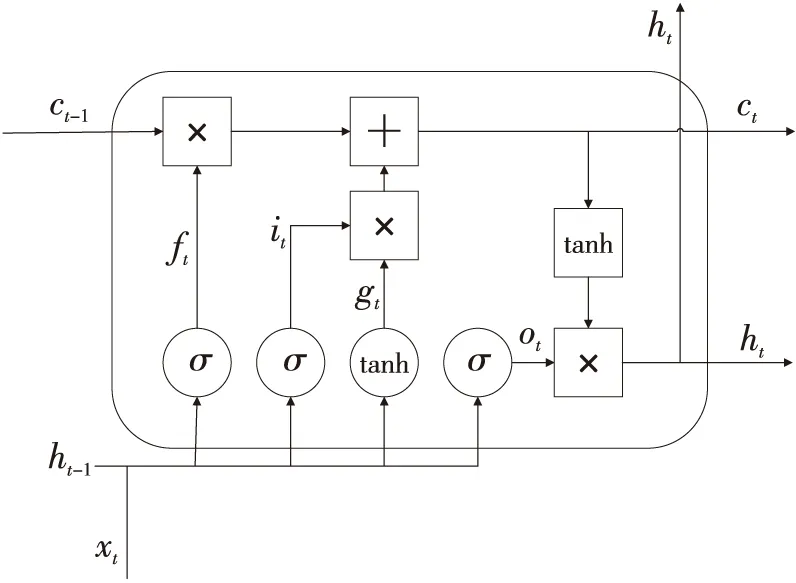
Figure 1 Standard LSTM hidden layer cell structure图1 标准LSTM细胞结构
2.2 改进型LSTM
改进型LSTM的细胞核如图2所示。通过与图1对比可知,本文主要对标准的LSTM细胞核做了以下2点改进:(1)在标准LSTM的遗忘门和输出门上增加了孔连接,使遗忘门和输出门都能接受上一时刻的记忆单元ct-1作为输入。改进后的结构使得模型能够更加充分地选择将要保留和遗忘的历史信息。(2)与标准的LSTM模型相比,改进的LSTM的记忆单元耦合了输入门和遗忘门,因为传感器采样的历史值是时序数据,对于此类时序数据来说,遗忘的信息和保留的信息是相对的,当遗忘的信息被确定后,那么剩下的信息就是需要保留的信息[10],即输入门激活值=1-遗忘门激活值,这使得之前被遗忘的信息状态仅受新的输入值的影响,模型的逻辑更加直观,效果也更好。经过对LSTM细胞核的改进,此时式(3)为变为式(7),式(5)变为式(8),式(4)变为式(9):
ft=σ(Wf*[ct-1,ht-1,xt]+bf)
(7)
其中,ft为遗忘门的激活值,σ为激活函数,Wf为遗忘门的权重向量,ct-1为t-1时刻记忆单元的状态,ht-1为t-1时刻记忆单元的输出,xt为t时刻记忆单元的输入,bf为遗忘门的偏置。
ot=σ(Wo*[ct-1,ht-1,xt],bo)
(8)
其中,ot为输出门的激活值,σ为激活函数,Wo为输出门的权重向量,bo为输出门的偏置,ct-1为t-1时刻记忆单元的状态,ht-1为t-1时刻记忆单元的输出,xt为t时刻记忆单元的输入。
ct=ft*ct-1+(1-ft)gt
(9)
其中,ct为t时刻记忆单元的状态,gt为记忆单元的候选状态,ft为遗忘门的激活值,ct-1为t-1时刻记忆单元的状态。
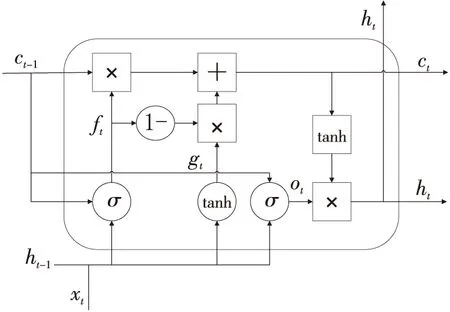
Figure 2 Improved LSTM hidden layer cell structure图2 改进LSTM的细胞结构
2.3 随机森林RF算法
随机森林是由一系列决策树组合而成的分类器,由Breiman在Bagging算法上改进而成的[11]。
随机森林的训练过程包括2个步骤,第1步是采用bagging抽样技术,从原始的训练集中随机生成具有一定重复性的K个训练子集为每棵树生成一个训练集。第2步是在得到每棵树的训练集后,从总特征中随机选取一些特征来训练每个训练集,生成K个决策树,从而形成一个随机森林[12]。
传感器故障分类所使用的随机森林算法结构图如图3所示,构造的多棵决策树组成了随机森林分类器,通过多棵决策树共同投票,从而使故障分类的准确率有了很大的提高。
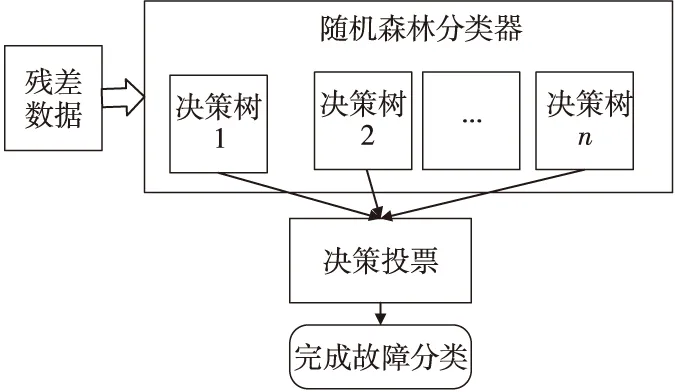
Figure 3 Structure of random forest algorithm图3 随机森林算法结构
3 改进LSTM-RF算法
3.1 故障诊断与故障数据重构的原理
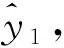
3.2 改进LSTM-RF算法训练的步骤
对改进LSTM-RF故障诊断模型与数据重构的建模过程如图4所示,其步骤可以总结如下:
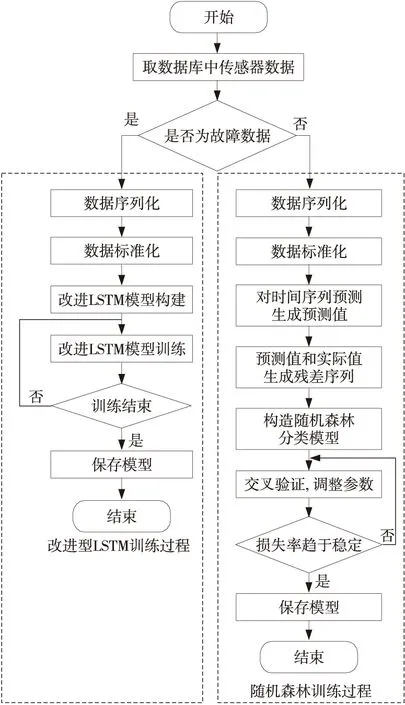
Figure 4 Training flowchart of the improved LSTM-RF algorithm图4 改进LSTM-RF算法训练流程图
(1)取训练样本中无故障数据,生成集合(x1,x2,…,xn)。
(2)构造时间序列。时间序列的样本和标记分别为(X1,X2,…,Xm)和(y1,y2,…,ym)。其中X1为(x1,x2,…,xk-1)组成的向量,y1为xk,X2为(x2,x3,…,xk)组成的向量,y2为xk+1。依次类推:Xm为(xm,xm+1,…,xm+k-1)组成的向量,ym为xm+k。
(3)针对时间序列进行归一化处理,本文所用的归一化的方法为X′=(x-xmin)/(xmax-xmin)。
(4)构建改进LSTM网络模型。模型的输入与输出分别为时间序列的样本和标记。损失率为均方根误差k。
(5)针对构建的改进LSTM模型,使用BPTT反向传播法对其进行训练。
(6)损失函数设定为均方根误差,激活函数为adam,当模型的损失率趋于稳定后,停止训练,并保存训练完的改进LSTM模型M1。
(7)取训练样本中有故障数据,生成集合(e1,e2,…,en)。
(8)针对故障数据集合(e1,e2,…,en),与步骤(2)所示方法一致,生成故障序列的样本(E1,E2,…,Ej)和标记(l1,l2,…,lj),Em为(em,em+1,…,em+k-1)组成的向量。
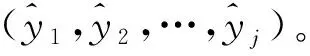
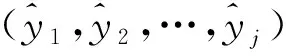
(11)构造随机森林分类器。
(12)训练随机森林模型,输入为残差数据集合(r1,r2,…,rj)和标记集合(l1,l2,…,lj)。
3.3 故障诊断与数据重构的步骤
对传感器的运行状态进行故障诊断与故障数据重构的步骤如图5所示,其步骤总结如下:
(1)取传感器测量数据,生成传感器测量数据集合(x1,x2,…,xn)。
(2)构造时间序列,时间序列的样本和标记分别为(X1,X2,…,Xm)和(y1,y2,…,ym)。其中X1为(x1,x2,…,xk-1)组成的向量,y1为xk,X2为(x2,x3,…,xk)组成的向量,y2为xk+1。依次类推:Xm为(xm,xm+1,…,xm+k-1)组成的向量,ym为xm+k。
(3)针对时间序列进行归一化处理,本文所用的归一化的方法为X′=(x-xmin)/(xmax-xmin)。

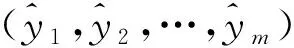
(6)残差数据集合中数据的幅值和排序蕴含着传感器的运行状态,使用随机森林模型M2对残差数据集合进行分类,分类的结果为当前传感器的运行状态。
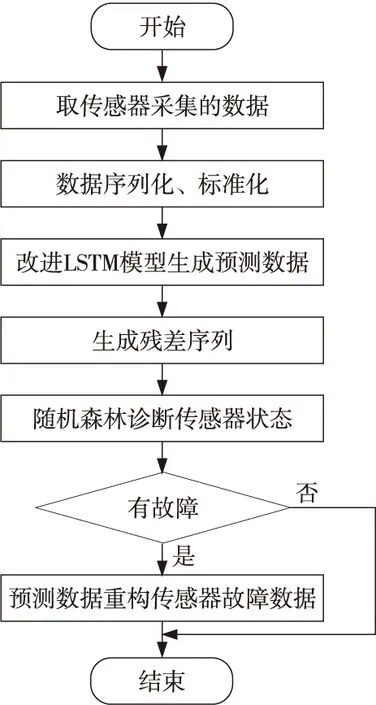
Figure 5 Flowchart of sensor fault diagnosis and fault data reconstruction based on improved LSTM-RF algorithm图5 改进LSTM-RF算法故障诊断与数据重构流程图
4 实验与结果分析
4.1 数据集
本文使用2种不同类型的传感器产生的数据集来验证所提的改进LSTM-RF算法在传感器故障诊断与数据重构中的有效性,这2个传感器分别为NO2传感器与风机齿轮箱温度传感器。2个数据集分别标注了传感器在7种状态下采集的数据,7种状态分别为传感器正常状态、传感器偏差故障、传感器冲击故障、传感器周期性干扰故障、传感器漂移故障、传感器噪声干扰故障和传感器输出恒定值故障。在故障严重程度上风机齿轮箱温度传感器数据集的故障幅度和漂移的偏移量要小于NO2传感器数据集中的相应值。
4.2 超参数的选择
本文采用网格搜索法来确定改进型LSTM和随机森林的超参数。限于文章篇幅,以NO2传感器数据集为例展开分析。图6为改进型LSTM的Epoch参数值对训练集和测试集上均方根误差的影响。从图6中可以看出,当Epoch值小于4时,训练集和测试集的均方根误差都在减小;当Epoch大于4时,训练集的均方根误差在缓慢地下降,但是测试集的均方根误差却在增加,并出现了很大的振荡,这说明由于模型的训练过度而导致了其在训练集上的精度不断提升,而在测试集上的精度却发生了下降。训练过度会造成模型发生过拟合,因此本文选定超参数Epoch为4来训练模型。图7为随机森林所包含决策树的数量对传感器故障诊断准确率的影响。从图7中可以看出,在训练集上,随着决策树数量的增多,训练集的准确率一直在增加,而测试集上的准确率在决策树数量为22之后出现了明显的下降,并且发生了很大的振荡,这说明随机森林模型由于决策树数量过多而导致模型训练过度,从而使得模型发生了过拟合。因此,本文所构建的随机森林里决策树数量的大小选为22。
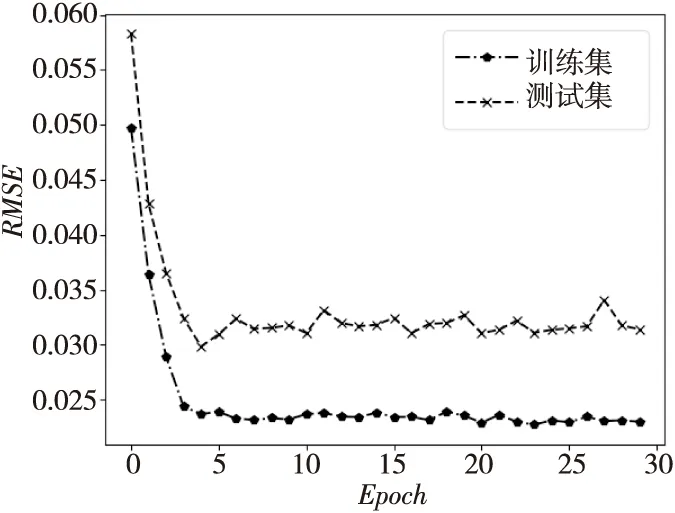
Figure 6 Different forest accuracy based on improved LSTM under different Epoch图6 改进LSTM预测精度随Epoch变化曲线
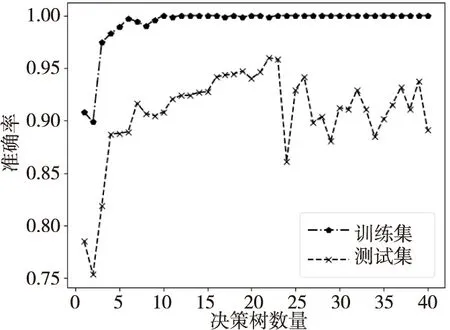
Figure 7 Different diagnosis accuracy under different numbers of decision trees图7 故障诊断准确率随决策树数量变化曲线
4.3 实验结果

传感器故障数据重构是指传感器发生故障后,对传感器故障时输出的数据进行重构,使得输出数据更加符合真实数据。限于文章篇幅,本文仅以NO2传感器数据重构为例进行分析,NO2传感器故障数据重构如图8所示。从图8中的传感器输出值和实际值这2条曲线可以看出,由于传感器发生了偏置故障,传感器的输出值与实际值之间的偏差非常大。相较于传感器的输出曲线,数据重构曲线更加靠近实际值曲线,这说明重构后的数据比传感器的输出数据更加靠近实际值,所建模型取得了

Table 1 Accuracy of sensor fault diagnosis表1 传感器故障诊断的准确率 %

Figure 8 Curve of fault data reconstruction图8 故障数据重构曲线
良好的故障数据重构效果。
4.4 对比分析
近年来梯度提升树GBDT(Gradient Boosting Decision Tree)、支持向量机SVM(Support Vector Machine)和朴素贝叶斯NBM(Naive Bayesian)等机器算法在很多数据集中都被证明具有很强的分类能力[13]。本文在相同的残差数据集上将随机森林算法与这3种算法的准确率和在测试集与训练集上所用的时间进行了对比,结果如图9所示。由图9可知,在2个数据集上朴素贝叶斯分类算法的训练时间和测试时间要小于随机森林、梯度提升树和支持向量机的,但是在准确率上随机森林的准确率要高于梯度提升树、朴素贝叶斯和支持向量机的。综合考虑模型故障诊断的时间和所需消耗的时间,随机森林算法在传感器故障诊断上的综合性能更好。
为了说明改进型LSTM在故障数据重构上的优越性,本文使用改进型LSTM与标准的LSTM、门控循环单元GRU(Gated Recurrent Unit)对2个故障数据集进行了故障数据重构,实验结果如图10所示。从图10中可以看出,对于相同的数据集,改进的LSTM的收敛速度更快,这与其将输入门与遗忘门相融合简化了模型相吻合。同时比较3个算法的收敛值,发现改进型LSTM在故障数据重构时的均方根误差要小于标准的LSTM和GRU的,这说明改进型LSTM的故障数据重构效果更好。
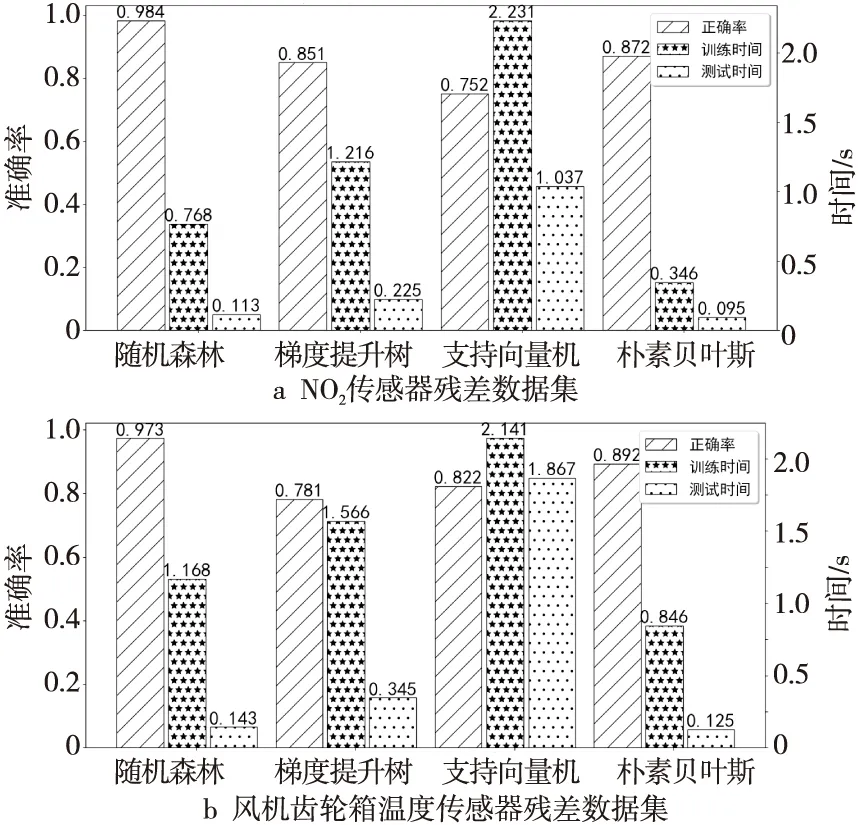
Figure 9 Comparison of different accuracy and required time with different recurrent neural networks图9 各算法对相同残差序列分类的准确率与分类使用的时间对比图

Figure 10 Curve of fault data reconstruction with different algorithms图10 多种算法的数据重构误差曲线
5 结束语
为了提高传感器系统在运行过程中的稳定性和可靠性,本文结合长短期记忆(LSTM)网络在时序数据预测上的优势与随机森林RF在分类上的优势,提出了改进型LSTM-RF算法,用于传感器的故障诊断与数据重构。
本文提出的改进型LSTM-RF算法对于不同的传感器检测效率不同。对于NO2传感器,本文算法的故障诊断平均准确率达到了98.4%,对于风机齿轮箱温度传感器平均诊断准确率达到97.3%,所提算法在2个数据集上的综合效果优于梯度决策树、SVM和朴素贝叶斯算法。在2个数据集上故障数据重构的均方根误差均小于4%,数据重构的效果优于标准的LSTM和GRU算法。
综上所述,本文通过对LSTM细胞核结构的改进以及与随机森林算法的组合使用,在传感器故障诊断与数据重构上取得了较为理想的效果。但是,本文在寻找改进LSTM和随机森林超参数时,采取的是网格搜索方法,缺少相应的理论依据。后续可以进一步研究如何有效地选取各个机器学习算法的超参数,更好地解决本文所提的问题。
