深度学习模型压缩与加速综述*
2021-05-18田育龙许封元
高 晗,田育龙,许封元,仲 盛
(计算机软件新技术国家重点实验室(南京大学),江苏 南京 210023)
深度学习模型的压缩和加速是指利用神经网络参数的冗余性和网络结构的冗余性精简模型,在不影响任务完成度的情况下,得到参数量更少、结构更精简的模型.被压缩后的模型计算资源需求和内存需求更小,相比原始模型能够满足更加广泛的应用需求.
本文系统地介绍模型压缩与加速方面的进展.第1 节主要介绍深度学习模型压缩与加速技术提出的研究背景和研究动机,以及本文的主要贡献.第2 节主要对目前主流的模型压缩与加速方法进行分类总结,从参数剪枝、参数量化、紧凑网络、知识蒸馏、低秩分解、参数共享、混合方式这7 个方面探究相关技术的发展历程,并分析其特点.第3 节主要比较各类压缩与加速技术中一些代表性方法的压缩效果.第4 节探讨模型压缩与加速领域未来的发展方向.第5 节对全文进行总结.
1 简介
1.1 研究背景
神经网络的概念在20 世纪40 年代提出后,发展一直不温不火.直到1989 年,LeCun 教授提出应用于手写字体识别的卷积神经网络[1],取得了良好效果,才使其得到更广泛的发展和关注.卷积神经网络(CNN)的得名即来自于其使用了卷积运算的结果.如图1 所示,特征图(feature map)是输入数据的中间抽象表示结果,输入特征图(input feature map)是由Cin个Hin×Win的2D 输入特征图组合而成,每一个滤波器(filter)与输入特征图的通道数相同,由Cin个d×d的卷积核(kernel)构成,输出特征图(output feature map)的每个通道(channel)都是由输入特征图与每一个filter 通过卷积运算而得到.但是由于当时数据集规模较小,容易出现过拟合问题,卷积神经网络并没有引起足够的重视.随着大数据时代的到来,数据集的规模不断扩大,计算硬件,特别是GPU 的飞速发展,神经网络重新获得关注.2009 年,Deng 等人发布当时世界上最大的通用物体识别数据库——ImageNet 数据库[2].从2010年开始,每年都会举办基于该数据库的大规模图像识别比赛——ILSVRC[3].2012 年,Hinton 的研究小组采用深度学习模型AlexNet[4]赢得了该比赛,突破性地将错误率从26.2%降到15.3%.此后,深度学习模型开始广泛用于人工智能的各个领域,在许多任务中得到了超越人类的正确率,在自动驾驶、医疗影像分析、智能家居等领域给予人们的生产和生活以更大的帮助.
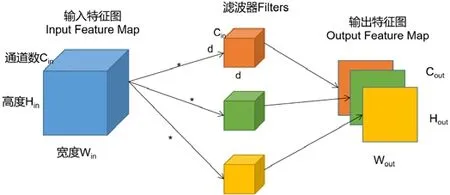
Fig.1 Convolutional operator图1 卷积计算
深度学习模型性能提高的同时,计算也越来越复杂,计算开销和内存需求逐渐增加.仅8 层的AlexNet[4]需要0.61 亿个网络参数和7.29 亿次浮点型计算,花费约233MB 内存.随后的VGG-16[5]的网络参数达到1.38 亿,浮点型计算次数为1.56 亿,需要约553MB 内存.为了克服深层网络的梯度消失问题,He 提出了ResNet[6]网络,首次在ILSVRC 比赛[3]中实现了低于5%的top-5 分类错误,偏浅的ResNet-50 网络参数就达到0.25 亿,浮点型计算次数高达3.9 亿,内存花费约102MB.庞大的网络参数意味着更大的内存存储,而增长的浮点型计算次数意味着训练成本和计算时间的增长,这极大地限制了在资源受限设备,例如智能手机、智能手环等上的部署.如表1 所示,深度模型在Samsung Galaxy S6 的推理时间远超Titan X 桌面级显卡,实时性较差,无法满足实际应用的需要.

Table 1 Inference time of different deep models[7] (unit:ms)表1 不同深度模型的推理时间[7] (单位:毫秒)
在深度学习技术日益火爆的背景下,对深度学习模型强烈的应用需求使得人们对内存占用少、计算资源要求低、同时依旧保证相当高的正确率的“小模型”格外关注.利用神经网络的冗余性进行深度学习的模型压缩和加速引起了学术界和工业界的广泛兴趣,各种工作层出不穷.
1.2 研究动机
综述能为读者省去大量阅读时间,以高屋建瓴的视角对该领域技术进行了解.然而截止到目前,在技术不断推陈出新的背景下,关于模型压缩的综述文章数量不多且年代久远,分类简单,难以展示新的趋势和方法.表2 是本文与目前国内外最新相关综述进行方法分类的种类以及与该分类下的文章数量进行对比的情况,从中可以看出:无论是方法分类还是涉及到的文章数量,已有的综述文章都难以展示新的趋势,对参数剪枝、参数量化和紧凑网络这3 类方法介绍得都较为粗略,对于混合方式这一新型加速方法未给出详细介绍,不能满足新进入这一领域的初学者了解整体发展方向的需求.
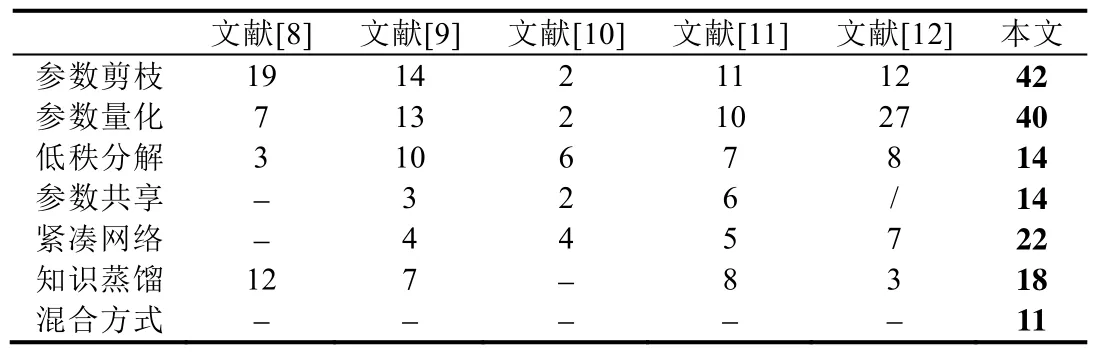
Table 2 Literature classification and quantity of the reviews表2 综述的文献分类与数量
根据图2 所示的文章发表年份来看,文献[8-11]的最新文章发表于2017 年,对近年来热门研究方向和新方法的介绍较少.
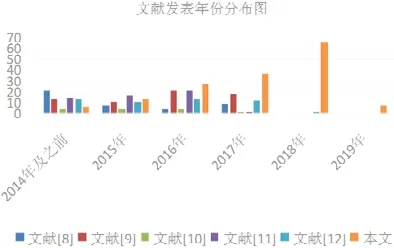
Fig.2 Article publication time and quantity of the reviews图2 综述的文章发表时间与数量
根据我们的最新整理,2018 年之后,发表在各大顶级会议上的文章达到64 篇,占本文统计文章总数的大约40%,其中,文献[13]首先提出在裁剪权重时加入能耗、延迟等硬件限制作为优化约束,为后续工作[14-16]提供了启发.Network Trimming[17]将激活值为0 的通道数量作为判断filter 是否重要的标准,是结构化剪枝领域最有影响力的工作,开创了设置filter 评价因子的技术分支.文献[18]提出的依据参数对应损失函数(loss)的梯度来自适应确定每个参数量化位数的方法,打破了固有的手工确定量化位数的观念,引领了新的自适应量化技术体系.由此可以看出:近年来出现的热门文章提供了不少新的研究方向,极大地促进了模型压缩与加速领域的发展,非常值得收录到我们的综述中,从而为读者带来新的思考.
1.3 主要贡献
对比模型压缩与加速领域已有的综述文章,本文提出的技术分类更加齐全,收录的文章更新颖、热门,对于主流研究方向进行了重点介绍和分析.本文调研了近年来发表在国际顶级会议上的近200 篇文章,对主流模型压缩与加速方法分类进行了总结和详细分析;同时对一些具有代表性的方法在公开模型上进行了性能对比,探讨了模型压缩与加速领域未来的研究方向.希望本文能给研究者对模型压缩与加速领域有一个全面的了解,抓住热门研究方向,推动未来模型压缩与加速的研究,促进深度学习模型的实际应用.
2 压缩方法概览
本节主要介绍目前主流的模型压缩与加速方法,见表3,从压缩参数和压缩结构两个角度可以将压缩方法分成以下7 类.

Table 3 Summarization of methods for deep learning models compression and acceleration表3 深度学习模型压缩与加速方法总结
2.1 参数剪枝
参数剪枝是指在预训练好的大型模型的基础上,设计对网络参数的评价准则,以此为根据删除“冗余”参数.根据剪枝粒度粗细,参数剪枝可分为非结构化剪枝和结构化剪枝.非结构化剪枝的粒度比较细,可以无限制地去掉网络中期望比例的任何“冗余”参数,但这样会带来裁剪后网络结构不规整、难以有效加速的问题.结构化剪枝的粒度比较粗,剪枝的最小单位是filter 内参数的组合,通过对filter 或者feature map 设置评价因子,甚至可以删除整个filter 或者某几个channel,使网络“变窄”,从而可以直接在现有软/硬件上获得有效加速,但可能会带来预测精度(accuracy)的下降,需要通过对模型微调(fine-tuning)以恢复性能.
2.1.1 非结构化剪枝
LeCun 在20 世纪80 年代末提出的OBD(optimal brain damage)算法[19]使用loss 对参数求二阶导数,以判断参数的重要程度.在此基础上,Hassibi 等人不再限制于OBD 算法[19]的对角假设,提出了OBS(optimal brain surgeon)算法[20],除了将次重要权重值置0 以外,还重新计算其他权重值以补偿激活值,压缩效果更好.与OBS 算法[20]类似,Srinivas 等人[21]提出了删除全连接层稠密的连接,不依赖训练数据,极大地降低了计算复杂度.最近,Dong 等人[22]提出了逐层OBS 算法,每一层都基于逐层loss 函数对相应参数的二阶导数独立剪枝,修剪后,经过轻量再训练以恢复性能.
如图3 所示,卷积层和全连接层的输入与输出之间都存在稠密的连接,对神经元之间的连接重要性设计评价准则,删除冗余连接,可达到模型压缩的目的.Han 等人[23]提出:根据神经元连接权值的范数值大小,删除范数值小于指定阈值的连接,可重新训练恢复性能.为了避免错误删除重要连接,Guo 等人[24]提出了DNS(dynamic network surgery)方法,恢复被误删的重要连接.Lin 等人[25]利用生物学上的神经突触概念,定义突触强度为Batch Normalization(BN)层放缩因子γ和filter 的Frobinus 范数的乘积,用突触强度来表示神经元之间连接的重要性.不同于其他方法在预训练模型上做剪枝,Lee 等人提出的SNIP(single-shot network pruning)方法[26]在模型初始化阶段,通过对训练集多次采样判断连接的重要性,生成剪枝模板再进行训练,无需迭代进行剪枝-微调的过程.
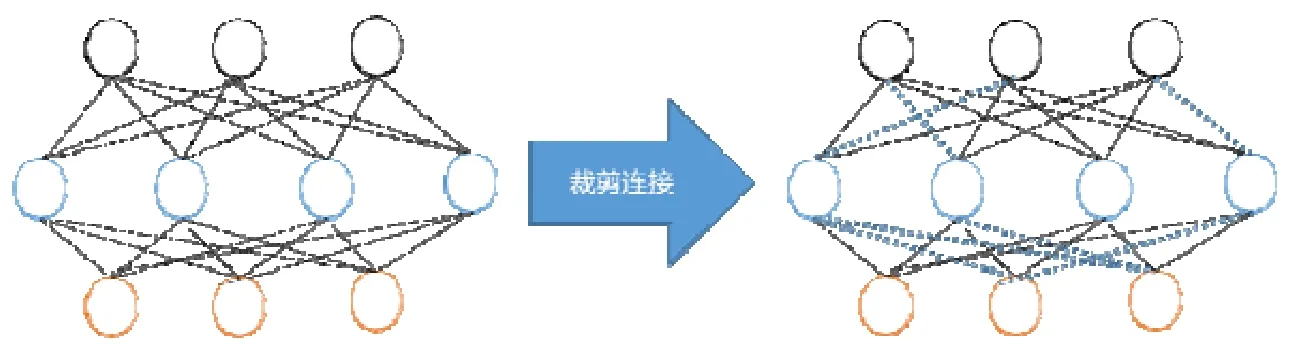
Fig.3 Pruning connections图3 裁剪连接
除了对神经元之间的连接进行评估以外,也可以如图4 所示,直接对神经元权重进行评估,相比原始权重,3个 filter 各自进行权重置零操作(即删去某几个小方块),置零的神经元可能各不相同.行列式点过程(determinantal point process,简称DPP)[27]常用来解决机器学习中的子集选择问题,Mariet 等人[28]将DPP 应用于神经元的选择,再通过重新加权将删除神经元的信息直接融合到剩余神经元中,这种方法不需要再微调模型.受Kingma 等人提出的变分dropout 技术[29]的启发,Molchanov 等人[30]将其用于模型压缩,同时对卷积层和全连接层进行稀疏化.另外,正则化项作为机器学习中loss 函数的惩罚项常用于对某些参数进行限制,所以关于权重参数的正则化项也可以用于惩罚次重要参数的存在,达到模型压缩的目的.由于参数的L0 范数不可微分,很难与loss 共同优化,Louizos 等人[31]对权重设置非负随机门来决定哪些权重设置为0,转化为可微问题,门上参数可以与原始网络参数共同优化.Tartaglione 等人[32]量化权重参数对于输出的敏感度,将其作为正则化项,逐渐降低敏感度较低的参数值.延迟、能耗等硬件约束条件也可以作为模型压缩的惩罚项,Chen 等人[13]引入硬件约束(例如延迟),使任务目标(如分类精度)最大化,基于权重大小删除范数值较低的权重.Yang 等人[14]利用加权稀疏投影和输入遮蔽来提供可量化的能耗,将能耗预算作为网络训练的优化约束条件,并且由于手工设置的压缩阈值对网络的自适应性不好,使用能恢复误删重要连接的动态剪枝法可获得稀疏网络.Carreira-Perpinán 等人[33]提出交替使用“学习”和“压缩”步骤,探索使loss 最小化的权重子集的方法.Liu 等人[34]证明卷积可以通过DCT 域乘法来实现,然后对filter 的DCT 系数进行动态剪枝.
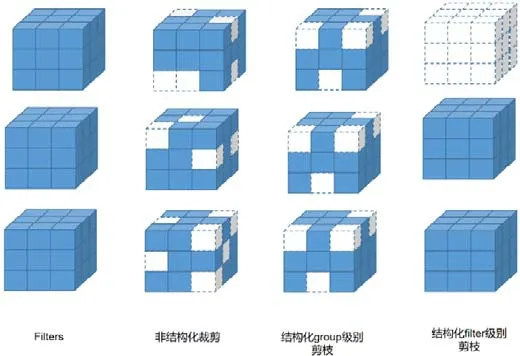
Fig.4 Parameter pruning图4 参数剪枝
2.1.2 结构化剪枝
(1)group 级别剪枝
如图4 所示,group 级别剪枝是指对每一层的filter 设置相同的稀疏模式(即图中每个立方体都删去相同位置的小方块),变成结构相同的稀疏矩阵.Wen 等人[35]利用group Lasso 回归进行正则化规约,探索filter、channel等不同层次的结构稀疏性.Alvarez 等人[36]提出不需要预训练模型,加入组稀疏正则化项,而是在网络训练的同时自动选择各层神经元数目.Figurnov 等人[37]提出Perforatedcnns,使用不同策略遮蔽激活值,被遮蔽的值用邻近值表示.Lebedev 等人[38]利用文献[19]中提出的OBD 算法,将卷积操作视作矩阵乘法计算,以group 方式稀疏化卷积核,变为稀疏矩阵乘法,提高运算速度.Zhou 等人[39]提出引入稀疏约束,减少最后一个全连接层的参数数量.
(2)filter 级别剪枝
filter 级别剪枝也可以看作channel 级别剪枝.如图4 所示,删去该层的某些filter(即图中删去整个立方体),相当于删去其产生的部分feature map 和原本需要与这部分feature map 进行卷积运算的下一层部分filter.对filter 的评价准则可分为以下4 种.
• 基于filter 范数大小
Li 等人[40]提出计算filter 的L1 范数,过滤掉较小L1 范数的filter 对应的feature map,剪枝后再训练.Yang等人[15]利用Chen 等人的工作[41]提出的模型能耗工具Eyeriss 计算每一层能耗,对能耗大的层优先剪枝;同时,为了避免不正确的剪枝,保留剪枝后精确度下降最大的权重.Yang 等人在其另一项工作[42]中提出的Netadapt 同样也是将硬件度量指标(延迟和能耗等)作为剪枝评价准则,但与文献[15]不同的是:使用经验度量来评估,不需要对平台有详细的了解.算法在移动平台上自动迭代对预训练网络进行剪枝,直到满足资源预算.He 等人[43]提出设置剪枝概率删去L2 范数最小的几个卷积核,即将该filter 置0.其特殊之处在于:每次训练完一个epoch 进行剪枝,但在上一个epoch 中被剪枝的filter 在当前epoch 训练时仍然参与迭代.
• 自定义filter 评分因子
Hu 等人[17]提出了Network trimming 方法,他们认为激活值为0 的神经元是冗余的,所以统计每一个filter中激活值为0 的数量,将其作为判断一个filter 是否重要的标准.Liu 等人[44]根据BN 层放缩因子γ来判断channel的重要性.Huang 等人的工作[45]可以看作是文献[44]的泛化,引入了额外的放缩因子对channel 加以评价.Ye 等人[46]在文献[45]的基础上进行优化,提出了基于ISTA 和重标技术的梯度学习算法.Dai 等人[47]提出了基于变分信息瓶颈剪枝方法,在每一层只提取与任务相关的信息,将冗余神经元的激活值推向0.He 等人[48]利用强化学习(reinforcement learning)提供压缩策略,相比于手动启发式方法,效果更好.
• 最小化重建误差
设神经网络中某一卷积层权重为W,通道数为C,输入为X,输出为Y,忽略偏置项B,则有:

令:

则有:

令S作为从C个通道中取得的最优子集,裁剪过程其实就是使子集S的最终输出与原始C个通道的最终输出Y的差别最小.即:

Luo 等人[49]提出了Thinet,“贪婪地”剪去对下一层激活值影响最小的channel.He 等人[50]并没有像文献[49]那样直接使用贪心策略,而是通过Lasso 回归对channel 进行选择性删除,然后利用最小二乘法重构feature map.Yu 等人[51]定义最后一个与softmax 层相连的hidden layer 为final response layer(FRL),通过特征选择器来确定各个特征的重要性得分,反向传播,得到整个网络各层的得分,再根据裁剪比率进行裁剪.裁剪的原则是,FRL 输出的重建误差最小.Zhuang 等人[52]引入额外的识别感知loss,辅助选择真正有助于识别的channel,联合重建误差共同优化.
• 其他方法
Molchanov 等人[53]将剪枝问题当作一个优化问题,从权重参数中选择一个最优组合,使得loss 的损失最小,认为剪枝后预测精度衰减小的参数是不重要的.Lin 等人[54]工作的独特之处在于:能够全局性地评估各个filter的重要度,动态地、迭代地剪枝,并且能够重新调用之前迭代中错误剪枝的filter.Zhang 等人[55]将剪枝问题视为具有组合约束条件的非凸优化问题,利用交替方向乘法器(ADMM)分解为两个子问题,可分别用SGD 和解析法求解.Yang 等人[16]的工作与文献[55]的工作相比,加入能耗作为约束条件,通过双线性回归函数进行建模.
2.2 参数量化
参数量化是指用较低位宽表示典型的32 位浮点网络参数,网络参数包括权重、激活值、梯度和误差等等,可以使用统一的位宽(如16-bit、8-bit、2-bit 和1-bit 等),也可以根据经验或一定策略自由组合不同的位宽.参数量化的优点是:(1)能够显著减少参数存储空间与内存占用空间,将参数从32 位浮点型量化到8 位整型,从而缩小75%的存储空间,这对于计算资源有限的边缘设备和嵌入式设备进行深度学习模型的部署和使用都有很大的帮助;(2)能够加快运算速度,降低设备能耗,读取32 位浮点数所需的带宽可以同时读入4 个8 位整数,并且整型运算相比浮点型运算更快,自然能够降低设备功耗.但其仍存在一定的局限性,网络参数的位宽减少损失了一部分信息量,会造成推理精度的下降,虽然能够通过微调恢复部分精确度,但也带来时间成本的增加;量化到特殊位宽时,很多现有的训练方法和硬件平台不再适用,需要设计专用的系统架构,灵活性不高.
2.2.1 二值化
二值化是指限制网络参数取值为1 或-1,极大地降低了模型对存储空间和内存空间的需求,并且将原来的乘法操作转化成加法或者移位操作,显著提高了运算速度,但同时也带来训练难度和精度下降的问题.
(1)二值化权重
由于权重占据网络参数的大部分,一些研究者提出对网络权重进行二值化,以达到压缩网络的目的.Courbariaux 等人[56]提出了Binaryconnect,将二值化策略用于前向计算和反向传播,但在使用随机梯度更新法(SGD)更新参数时,仍需使用较高位宽.Hou 等人[57]提出一种直接考虑二值化权重对loss 产生影响的二值化算法,采用对角海森近似的近似牛顿算法得到二值化权重.Xu 等人[58]提出局部二值卷积(LBC)来替代传统卷积,LBC 由一个不可学习的预定义filter、一个非线性激活函数和一部分可以学习的权重组成,其组合达到与激活的传统卷积filter 相同的效果.Guo 等人[59]提出了Network sketching 方法,使用二值权重共享的卷积,即:对于同层的卷积运算(即拥有相同输入),保留前一次卷积的结果,卷积核的相同部分直接复用结果.McDonnell 等人[60]将符号函数作为实现二值化的方法.Hu 等人[61]通过哈希将数据投影到汉明空间,将学习二值参数的问题转化为一个在内积相似性下的哈希问题.
(2)二值化权重和激活值
在二值化网络权重的基础上,研究人员提出可以同时二值化权重和激活值,以加快推理速度.Courbariaux 等人[62]首先提出了Binarized neural network(BNN),将权重和激活值量化到±1.Rastegari 等人[63]在文献[62]的基础上提出了Xnor-net,将卷积通过xnor 和位操作实现,从头训练一个二值化网络.Li 等人[64]在Xnor-net[63]的基础上改进其激活值量化,提出了High-order residual quantization(HORQ)方法.Liu 等人[65]提出了Bi-real net,针对Xnor-net[63]进行网络结构改进和训练优化.Lin 等人[66]提出了ABC-Net,用多个二值操作加权来拟合卷积操作.
2.2.2 三值化
三值化是指在二值化的基础上引入0 作为第3 阈值,减少量化误差.Li 等人[67]提出了三元权重网络TWN,将权重量化为{-w,0,+w}.不同于传统的1 或者权重均值,Zhu 等人[68]提出了Trained ternary quantization(TTQ),使用两个可训练的全精度放缩系数,将权重量化到{-wn,0,wp},权重不对称使网络更灵活.Achterhold 等人[69]提出了Variational network quantization(VNQ),将量化问题形式化为一个变分推理问题.引入量化先验,最后可以用确定性量化值代替权值.
2.2.3 聚类量化
当参数数量庞大时,可利用聚类方式进行权重量化.Gong 等人[70]最早提出将k-means 聚类用于量化全连接层参数,如图5 所示,对原始权重聚类形成码本,为权值分配码本中的索引,所以只需存储码本和索引,无需存储原始权重信息.Wu 等人[71]将k-means 聚类拓展到卷积层,将权值矩阵划分成很多块,再通过聚类获得码本,并提出一种有效的训练方案抑制量化后的多层累积误差.Choi 等人[72]分析了量化误差与loss 的定量关系,确定海森加权失真测度是量化优化的局部正确目标函数,提出了基于海森加权k-means 聚类的量化方法.Xu 等人[73]提出了分别针对不同位宽的Single-level network quantization(SLQ)和Multi-level network quantization(MLQ)两种方法,SLQ 方法针对高位宽,利用k-means 聚类将权重分为几簇,依据量化loss,将簇分为待量化组和再训练组,待量化组的每个簇用簇内中心作为共享权重,剩下的参数再训练.而MLQ 方法针对低位宽,不同于SLQ 方法一次量化所有层,MLQ 方法采用逐层量化的方式.
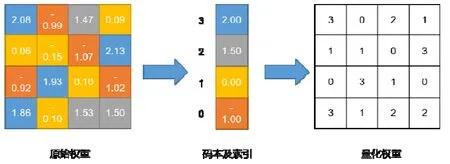
Fig.5 Flow chart of clustering quantization图5 聚类量化流程图
2.2.4 混合位宽
(1)手工固定
由于二值网络会降低模型的表达能力,研究人员提出,可以根据经验手工选定最优的网络参数位宽组合.Lin 等人[74]在BNN[62]的基础上,提出把32-bit 权重概率性地转换为二元和三元值的组合.Zhou 等人[75]提出了DoReFa-Net,将权重和激活值分别量化到1-bit 和2-bit.Mishra 等人[76]提出了WRPN,将权重和激活值分别量化到2-bit 和4-bit.Köster 等人[77]提出的Flexpoint 向量有一个可动态调整的共享指数,证明16 位尾数和5 位共享指数的Flexpoint 向量表示在不修改模型及其超参数的情况下,性能更优.Wang 等人[78]使用8 位浮点数进行网络训练,部分乘积累加和权重更新向量的精度从32-bit 降低到16-bit,达到与32-bit 浮点数基线相同的精度水平.除了权重和激活值,研究者们将梯度和误差也作为可优化的因素.这些同时考虑了权重、激活值、梯度和误差的方法的量化位数和特点对比可见表4.表中的W、A、G和E分别代表权重、激活值、梯度和误差.

Table 4 Comparison of several mixed bit-width quantization methods表4 几种混合位宽量化法对比
(2)自主确定
由于手工确定网络参数位宽存在一定的局限性,可以设计一定的策略,以帮助网络选择合适的位宽组合.Khoram 等人[18]迭代地使用loss 的梯度来确定每个参数的最优位宽,使得只有对预测精度重要的参数才有高精度表示.Wang 等人[84]提出两步量化方法:先量化激活值再量化权重.针对激活值量化,提出了稀疏量化方法.对于权重量化,将其看成非线性最小二乘回归问题.Faraone 等人[85]提出了基于梯度的对称量化方法SYQ,设计权值二值化或三值化,并在pixel 级别、row 级别和layer 级别定义不同粒度的缩放因子以估计网络权重;至于激活值,则量化为2-bit 到8-bit 的定点数.Zhang 等人[86]提出了Learned quantization(LQ-nets),使量化器可以与网络联合训练,自适应地学习最佳量化位宽.
2.2.5 训练技巧
由于量化网络的网络参数不是连续的数值,所以不能像普通的卷积神经网络那样直接使用梯度下降方法进行训练,而需要特殊的方法对这些离散的参数值进行处理,使其不断优化,最终实现训练目标.Zhou 等人[87]提出了一种增量式网络量化方法INQ,先对权重进行划分,将对预测精度贡献小的权重划入量化组;然后通过再训练恢复性能.Cai 等人[88]提出了Halfwave Gaussian quantizer(HWGQ)方法,设计了两个ReLU 非线性逼近器(前馈计算中的半波高斯量化器和反向传播的分段连续函数),以训练低精度的深度学习网络.Leng 等人[89]提出,利用ADMM[90]解决低位宽网络训练问题.Zhuang 等人[91]针对低位宽卷积神经网络提出3 种训练技巧,以期得到较高精度.Zhou 等人[92]提出一种显式的loss-error-aware 量化方法,综合考虑优化过程中的loss 扰动和权值近似误差,采用增量量化策略.Park 等人[93]提出了价值感知量化方法来降低训练中的内存成本和推理中的计算/内存成本,并且提出一种仅在训练过程中使用量化激活值的量化反向传播方法.Shayer 等人[94]展示了如何通过对局部再参数化技巧的简单修改,来实现离散权值的训练.该技巧以前用于训练高斯分布权值.Louizos 等人[95]引入一种可微的量化方法,将网络的权值和激活值的连续分布转化为量化网格上的分类分布,随后被放宽到连续代理,可以允许有效的基于梯度的优化.
2.3 低秩分解
神经网络的filter 可以看作是四维张量:宽度w×高度h×通道数c×卷积核数n,由于c和n对网络结构的整体影响较大,所以基于卷积核(w×h)矩阵信息冗余的特点及其低秩特性,可以利用低秩分解方法进行网络压缩.低秩分解是指通过合并维数和施加低秩约束的方式稀疏化卷积核矩阵,由于权值向量大多分布在低秩子空间,所以可以用少数的基向量来重构卷积核矩阵,达到缩小存储空间的目的.低秩分解方法在大卷积核和中小型网络上有不错的压缩和加速效果,过去的研究已经比较成熟,但近两年已不再流行.原因在于:除了矩阵分解操作成本高、逐层分解不利于全局参数压缩,需要大量的重新训练才能达到收敛等问题之外,近两年提出的新网络越来越多地采用1×1 卷积,这种小卷积核不利于低秩分解方法的使用,很难实现网络压缩与加速.
2.3.1 二元分解
Jaderberg 等人[96]将w×h的卷积核分解为w×1 和1×h的卷积核,学习到的字典权重线性组合重构,得到输出feature map.Liu 等人[97]使用两阶段分解法研究filter 的通道间和通道内冗余.Tai 等人[98]提出一种计算低秩张量分解的新算法,利用BN 层转换内部隐藏单元的激活.Masana 等人[99]主要解决在大数据集上训练的网络在小目标域的使用问题,证明在压缩权重时考虑激活统计量,会导致一个具有闭型解的秩约束回归问题.Wen 等人[100]提出了Force regularization,将更多权重信息协调到低秩空间中.Wang 等人[101]提出了定点分解,再通过伪全精度权重复原,权重平衡和微调恢复性能.与其他基于filter 空间或信道数的低秩分解算法不同,Peng 等人[102]的工作基于filter 组近似,达到降低参数冗余的目的.Qiu 等人[103]提出将filter 分解为带预固定基的截断展开,展开系数从数据中学习.Novikov 等人[104]提出Tensor train 分解来压缩全连接层的稠密权值矩阵,而Garipov 等人[105]将其推广到卷积层.Wang 等人[106]提出了Tensor ring 分解,用于压缩卷积层和全连接层.
2.3.2 多元分解
对filter 的二元分解会引入w×h×c×d张量和d×n张量,由于第1 个张量w×h×c×d很大并且耗时,三元分解提出对其进行分解.Kim 等人[107]提出了Tucker 分解,对第1 个张量沿输入通道维进行二元分解,得到w×1、1×h和1×1 的卷积.由于第2 个分量d×n也需要大量计算,但其在输入和输出通道维数上的秩已经很低,Wang 等人[108]提出了基于低秩和群稀疏分解的块项分解(BTD),用一些较小的子张量之和近似原始权重张量.在三元分解的基础上,Lebedev 等人[109]提出了CP 分解,即位tensor 分解,将四维卷积核分解成4 个:1×1、w×1、1×h和1×1的卷积,即,将1 层网络分解为5 层低复杂度的网络层.
2.4 参数共享
参数共享是指利用结构化矩阵或聚类等方法映射网络参数,减少参数数量.参数共享方法的原理与参数剪枝类似,都是利用参数存在大量冗余的特点,目的都是为了减少参数数量.但与参数剪枝直接裁剪不重要的参数不同,参数共享设计一种映射形式,将全部参数映射到少量数据上,减少对存储空间的需求.由于全连接层参数数量较多,参数存储占据整个网络模型的大部分,所以参数共享对于去除全连接层冗余性能够发挥较好的效果;也由于其操作简便,适合与其他方法组合使用.但其缺点在于不易泛化,如何应用于去除卷积层的冗余性仍是一个挑战.同时,对于结构化矩阵这一常用映射形式,很难为权值矩阵找到合适的结构化矩阵,并且其理论依据不够充足.
2.4.1 循环矩阵
如果一个大小为m×n的矩阵能够用少于m×n个参数来描述,这个矩阵就是一个结构化矩阵.循环矩阵作为结构化矩阵的一种,是参数共享法常用的一种映射形式.令向量:

循环矩阵的每一行都是由上一行的各元素依次右移一个位置得到,即:
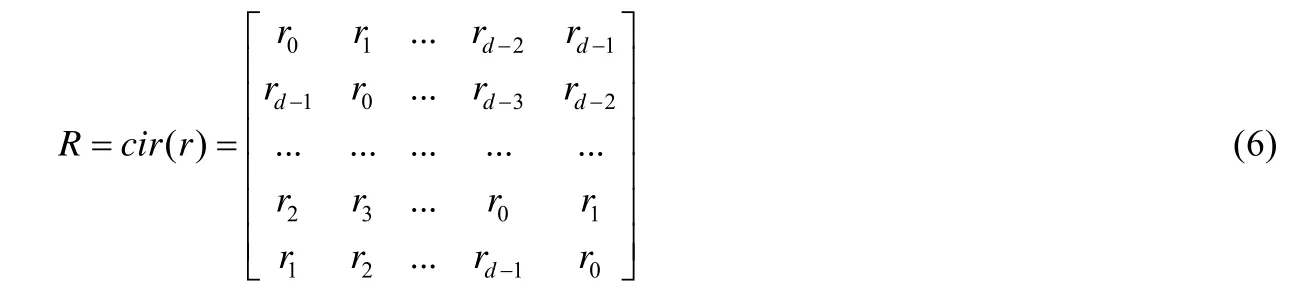
Cheng 等人[110]提出用循环投影代替传统的线性投影.对于具有d个输入节点和d个输出节点的神经网络层,将时间复杂度从O(d2)降低到O(d×logd),空间复杂度从O(d2)降低到O(d).Wang 等人[111]利用循环矩阵来构造特征图,对filter 进行重新配置,建立从原始输入到新的压缩特征图的映射关系.Sindhwani 等人[112]提出一个统一的框架来学习以低位移秩(LDR)为特征的结构参数矩阵.Zhao 等人[113]证明:具有LDR 权值矩阵的神经网络,在保持较高精度的同时,可以显著降低空间和计算复杂度.Le 等人[114]提出Fastfood 变换,通过一系列简单矩阵的乘法来代替稠密矩阵与向量的乘积,这些简单矩阵通过规则一次生成,后面无需调整.Yang 等人[115]在文献[114]的基础上提出自适应Fastfood 变换,对全连接层的矩阵-向量乘法进行重新参数化,替换成Fastfood 层.
2.4.2 聚类共享
Chen 等人[116,117]使用哈希函数将网络参数随机分组到哈希桶中,同一个桶的参数共享一个通过标准反向传播学习到的值.Wu 等人[118]提出对权值进行k-means 聚类,并引入一种新的频谱松弛的k-means 正则化方法.Son 等人[119]将k-means 聚类应用于3×3 卷积核,一个filter 用放缩因子×聚类中心来表示.
2.4.3 其他方法
Reagen 等人[120]提出了有损权值编码方案Bloomier filter,以引入随机误差为代价来节省空间,利用神经网络的容错能力进行再训练.Havasi 等人[121]提出了放松权重决定论,使用权重上的全变分分布,实现更加有效的编码方案,以提高压缩率.Jin 等人[122]提出了Weight Sampling Network (WSNet),沿着空间维度和通道维度进行加权采样.Kossaifi 等人[123]提出了Tensorized-network(T-net),使用单个高阶张量来参数化地表示整个网络.
2.5 紧凑网络
以上4 种利用参数冗余性减少参数数量或者降低参数精度的方法虽然能够精简网络结构,但往往需要庞大的预训练模型,在此基础上进行参数压缩,并且这些方法大都存在精确度下降的问题,需要微调来提升网络性能.设计更紧凑的新型网络结构,是一种新兴的网络压缩与加速理念,构造特殊结构的filter、网络层甚至网络,从头训练,获得适宜部署到移动平台等资源有限设备的网络性能,不再需要像参数压缩类方法那样专门存储预训练模型,也不需要通过微调来提升性能,降低了时间成本,具有存储量小、计算量低和网络性能好的特点.但其缺点在于:由于其特殊结构很难与其他的压缩与加速方法组合使用,并且泛化性较差,不适合作为预训练模型帮助其他模型训练.
2.5.1 卷积核级别
(1)新型卷积核
Iandola 等人[124]提出了Squeezenet,使用1×1 卷积代替3×3 卷积,为了减少feature map 的数量,将卷积层转变成两层:squeeze 层和 expand 层,减少了池化层.Howard 等人[125]提出了 MobileNet,将普通卷积拆分成depth-wise 卷积和point-wise 卷积,减少了乘法次数.Sandler 等人[126]提出的MobileNetV2 相比MobileNet[125],在depth-wise 卷积之前多加了一个 1×1 expand 层以提升通道数,获得了更多的特征.Zhang 等人[127]提出了ShuffleNet,为克服point-wise 卷积的昂贵成本和通道约束,采用了逐点组卷积(point-wise group convolution)和通道混洗(channel shuffle)的方式.Ma 等人[128]提出的ShuffleNetV2 相比ShuffleNet[127],为了减少内存访问成本,提出了通道分割(channel split)这一概念.Zhang 等人[129]提出了交错组卷积(IGC),引入第2 次组卷积,其每组输入通道来自于第1 次组卷积中不同的组,从而与第1 次组卷积交替互补.Xie 等人[130]在文献[129]的基础上进行泛化,提出交错的稀疏化组卷积,将两个结构化稀疏卷积核组成的构建块扩展到多个.Wan 等人[131]提出了完全可学习的组卷积模块(FLGC),可以嵌入任何深度神经网络进行加速.Park 等人[132]提出了直接稀疏卷积,用于稠密的feature map 与稀疏的卷积核之间的卷积操作.Zhang 等人[133]证明:高性能的直接卷积在增加线程数时性能更好,消除了所有内存开销.
(2)简单filter 组合
Ioannou 等人[134]提出了从零开始学习一组小的不同空间维度的基filter,在训练过程中,将这些基filter 组合成更复杂的filter.Bagherinezhad 等人[135]提出对每层构建一个字典,每个filter 由字典中的某些向量线性组合得到.将输入向量和整个字典里的向量进行卷积,查表得到该输入向量和filter 的卷积结果.Wang 等人[136]提出了构建高效CNN 的通用filter,二级filter 从主filter 中继承,通过整合从不同感受域提取的信息来增强性能.
2.5.2 层级别
Huang 等人[137]提出了随机深度用于类似ResNet 含残差连接的网络的训练,对于每个mini-batch,随机删除block 子集,并用恒等函数绕过它们.Dong 等人[138]为每个卷积层配备一个低成本协同层(LCCL),预测哪些位置的点经过ReLU 后会变成0,测试时忽略这些位置的计算.Li等人[139]将网络层分为权重层(如卷积层和全连接层)和非权重层(如池化层、ReLU 层等),提出了将非权重层与权重层进行合并的方法,去除独立的非权重层后,运行时间显著减少.Prabhu 等人[140]使用同时稀疏且连接良好的图来建模卷积神经网络filter 之间的连接.Wu 等人[141]通过平移feature map 的形式取代传统的卷积,从而减小了计算量.Chen 等人[142]引入稀疏移位层(SSL)来构造高效的卷积神经网络.在该体系结构中,基本块仅由1×1 卷积层组成,对中间的feature map 只进行少量的移位操作.
2.5.3 网络结构级别
Kim 等人[143]提出了SplitNet,自动学会将网络层分成多组,获得一个树形结构的网络,每个子网共享底层权重.Gordon 等人[144]提出了Morphnet,通过收缩和扩展阶段循环优化网络:在收缩阶段,通过稀疏正则化项识别效率低的神经元从网络中去除;在扩展阶段,使用宽度乘数来统一扩展所有层的大小,所以含重要神经元更多的层拥有更多计算资源.Kim 等人[145]提出了嵌套稀疏网络NestedNet,每一层由多层次的网络组成,高层次网络与低层次网络以Network in network (NIN)的方式共享参数:低层次网络学习公共知识,高层次网络学习特定任务的知识.
2.6 知识蒸馏
知识蒸馏最早由Buciluǎ 等人[146]提出,用以训练带有伪数据标记的强分类器的压缩模型和复制原始分类器的输出.与其他压缩与加速方法只使用需要被压缩的目标网络不同,知识蒸馏法需要两种类型的网络:教师模型和学生模型.预先训练好的教师模型通常是一个大型的神经网络模型,具有很好的性能.如图6 所示,将教师模型的softmax 层输出作为soft target 与学生模型的softmax 层输出作为hard target 一同送入total loss 计算,指导学生模型训练,将教师模型的知识迁移到学生模型中,使学生模型达到与教师模型相当的性能.学生模型更加紧凑高效,起到模型压缩的目的.知识蒸馏法可使深层网络变浅,极大地降低了计算成本,但也存在其局限性.由于使用softmax 层输出作为知识,所以一般多用于具有softmax 损失函数的分类任务,在其他任务的泛化性不好;并且就目前来看,其压缩比与蒸馏后的模型性能还存在较大的进步空间.
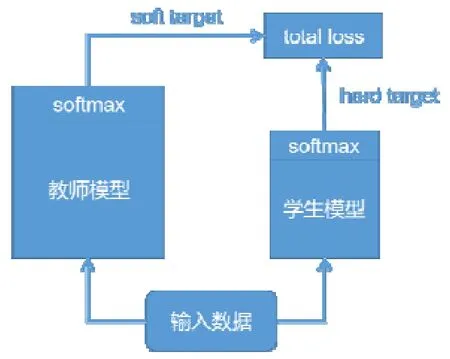
Fig.6 Flow chart of knowledge distillation图6 知识蒸馏流程图
2.6.1 学生模型的网络结构
知识蒸馏法的研究方向之一就是如何为学生模型选择合适的网络结构,帮助学生模型更好地学习教师模型的知识.Ba 等人[147]提出:在保证教师模型和学生模型网络参数数量相同的情况下,设计更浅的学生模型,每一层变得更宽.Romero 等人[148]与文献[147]的观点不同,他们认为更深的学生模型分类效果更好,提出Fitnets 使用教师网络的中间层输出Hints,作为监督信息训练学生网络的前半部分.Chen 等人[149]提出使用生长式网络结构,以复制的方式重用预训练的网络参数,在此基础上进行结构拓展.Li 等人[150]与文献[149]观点一致,提出分别从宽度和深度上进行网络生长.Crowley 等人[151]提出将知识蒸馏与设计更紧凑的网络结构相结合,将原网络作为教师模型,将使用简化卷积的网络作为学生模型.Zhu 等人[152]提出基于原始网络构造多分支结构,将每个分支作为学生网络,融合生成推理性能更强的教师网络.
2.6.2 教师模型的学习信息
除了使用softmax 层输出作为教师模型的学习信息以外,有研究者认为,可以使用教师模型中的其他信息帮助知识迁移.Hinton 等人[153]首先提出使用教师模型的类别概率输出计算soft target,为了方便计算,还引入温度参数.Yim 等人[154]将教师模型网络层之间的数据流信息作为学习信息,定义为两层特征的内积.Chen 等人[155]将教师模型在某一类的不同样本间的排序关系作为学习信息传递给学生模型.
2.6.3 训练技巧
Czarnecki 等人[156]提出了Sobolev 训练方法,将目标函数的导数融入到神经网络函数逼近器的训练中.当训练数据由于隐私等问题对于学生模型不可用时,Lopes 等人[157]提出了如何通过extra metadata 来加以解决的方法.Zhou 等人[158]的工作主要有两个创新点:第一,不用预训练教师模型,而是教师模型和学生模型同时训练;第二,教师模型和学生模型共享网络参数.
2.6.4 其他场景
由于softmax 层的限制,知识蒸馏法被局限于分类任务的使用场景.但近年来,研究人员提出多种策略使其能够应用于其他深度学习场景.在目标检测任务中,Li 等人[159]提出了匹配proposal 的方法,Chen 等人[160]结合使用文献[148,153]提出的方法,提升多分类目标检测网络的性能.在解决人脸检测任务时,Luo 等人[161]提出将更高隐层的神经元作为学习知识,其与类别输出概率信息量相同,但更为紧凑.Gupta 等人[162]提出了跨模态迁移知识的做法,将在RGB 数据集学习到的知识迁移到深度学习的场景中.Xu 等人[163]提出一种多任务指导预测和蒸馏网络(PAD-net)结构,产生一组中间辅助任务,为学习目标任务提供丰富的多模态数据.
2.7 混合方式
以上这些压缩与加速方法单独使用时能够获得很好的效果,但也都存在各自的局限性,组合使用可使它们互为补充.研究人员通过组合使用不同的压缩与加速方法或者针对不同网络层选取不同的压缩与加速方法,设计了一体化的压缩与加速框架,能够获得更好的压缩比与加速效果.参数剪枝、参数量化、低秩分解和参数共享经常组合使用,极大地降低了模型的内存需求和存储需求,方便模型部署到计算资源有限的移动平台[164].知识蒸馏可以与紧凑网络组合使用,为学生模型选择紧凑的网络结构,在保证压缩比的同时,可提升学生模型的性能.混合方式能够综合各类压缩与加速方法的优势,进一步加强了压缩与加速效果,将会是未来在深度学习模型压缩与加速领域的重要研究方向.
2.7.1 组合参数剪枝和参数量化
Ullrich 等人[165]基于Soft weight sharing 的正则化项,在模型再训练过程中实现了参数量化和参数剪枝.Tung 等人[166]提出了参数剪枝和参数量化的一体化压缩与加速框架 Compression learning by in parallel pruning-quantization(CLIP-Q).如图7 所示,Han 等人[167]提出了Deep compression,将参数剪枝、参数量化和哈夫曼编码相结合,达到了很好的压缩效果;并在其基础上考虑到软/硬件的协同压缩设计,提出了Efficient inference engine(Eie)框架[168].Dubey 等人[169]同样利用这3 种方法的组合进行网络压缩.
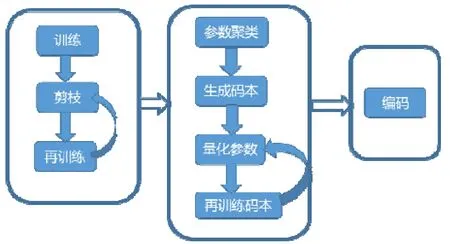
Fig.7 Flow chart of Deep Compression[167]图7 Deep Compression[167]流程图
2.7.2 组合参数剪枝和参数共享
Louizos 等人[170]采用贝叶斯原理,通过先验分布引入稀疏性对网络进行剪枝,使用后验不确定性确定最优的定点精度来编码权重.Ji 等人[171]通过重新排序输入/输出维度进行剪枝,并将具有小值的不规则分布权重聚类到结构化组中,实现更好的硬件利用率和更高的稀疏性.Zhang 等人[172]不仅采用正则化器鼓励稀疏性,同时也学习哪些参数组应共享一个公共值以显式地识别出高度相关的神经元.
2.7.3 组合参数量化和知识蒸馏
Polino 等人[173]提出了加入知识蒸馏loss 的量化训练方法,有浮点模型和量化模型,用量化模型计算前向loss,并对其计算梯度,用以更新浮点模型.每次前向计算之前,用更新的浮点模型更新量化模型.Mishra 等人[174]提出用高精度教师模型指导低精度学生模型的训练,有3 种思路:教师模型和量化后的学生模型联合训练;预训练的教师模型指导量化的学生模型从头开始训练;教师模型和学生模型都进行了预训练,但学生模型已经量化,之后在教师模型的指导下再进行微调.
3 压缩效果比较
我们从以上介绍的7 种主流网络压缩技术中选出其中一些具有代表性的方法,按照文献中声明的压缩与加速效果进行对比.通过对相关文献中使用较多的数据集和模型的统计,我们使用MNIST[175]、CIFAR-10[176]和ImageNet[177]这三大常用数据集,在LeNet、AlexNet、VGG-16、ResNet 等公开深度模型上进行压缩方法测试,比较其压缩效果.图表中的Δaccuracy=压缩后模型accuracy-原始模型accuracy,#Params↓=原始模型参数量/压缩后模型参数量,#FLOPs↓=原始模型浮点计算次数/加速后模型浮点计算次数.Weight bits 和activation bits 分别代表权值和激活值被量化后的表示位数.T-accuracy代表教师模型的accuracy,S-accuracy代表学生模型的accuracy.T-#Params代表教师模型的参数数量,S-#Params代表学生模型的参数数量.
表5 展示了参数剪枝、紧凑网络、参数共享、知识蒸馏和混合方式这5 类压缩技术的一些代表性方法使用MNIST 数据集在LeNet-5 上的压缩效果,可以看出,除了文献[157]带来较大的accuracy损失以外,其他方法的压缩效果都不错.从accuracy的角度来看,自适应fastfood 变换[115]的效果更好,在达到压缩效果的同时,还提升了accuracy;从参数压缩量的角度来看,混合方式在accuracy轻微下降的情况下,都实现了较大的压缩比,其中,文献[169]的效果最好.
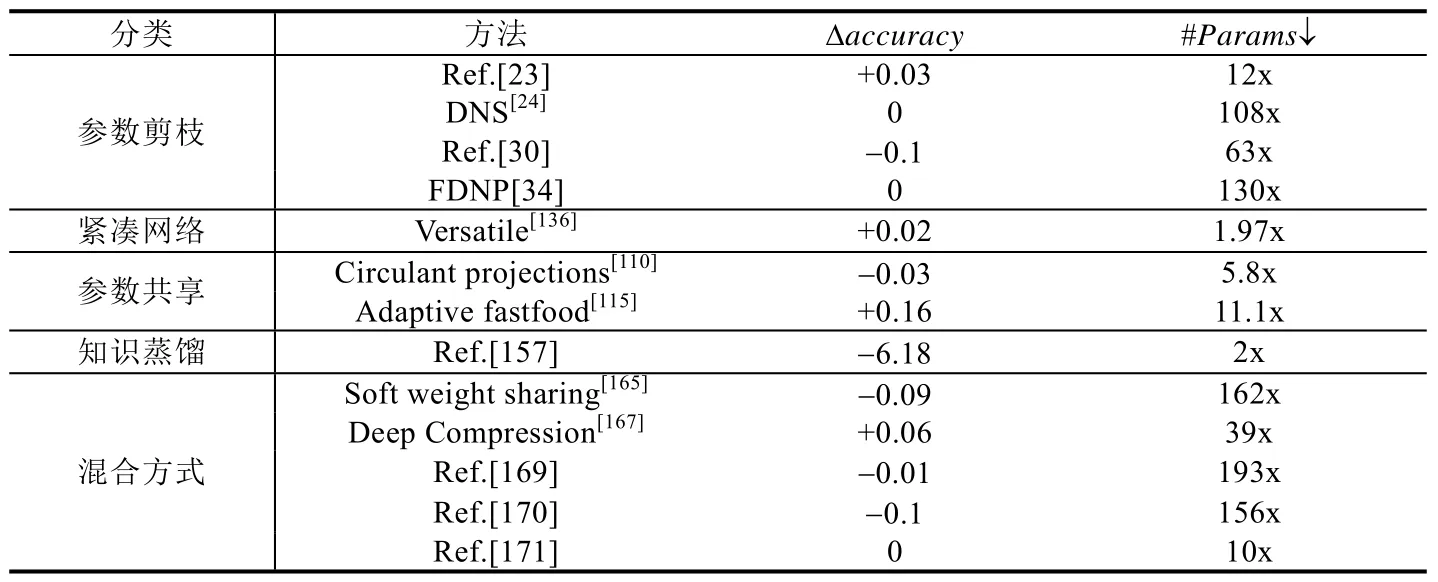
Table 5 Compression effects of different compression methods on LeNet-5 on MNIST表5 不同压缩方法在LeNet-5 on MNIST 上的压缩效果
表6 展示了参数剪枝、紧凑网络、参数共享和混合方式这4 类压缩技术的一些代表性方法使用CIFAR-10数据集在VGG-16 上的压缩效果,可以看出,这4 类方法的压缩效果差别比较大.整体来看,结构化剪枝[40]效果更好,同时起到了网络压缩和加速的效果,accuracy甚至有些提升.权值随机编码方法[121]能够实现高达159x 的参数压缩比,accuracy略有下降.
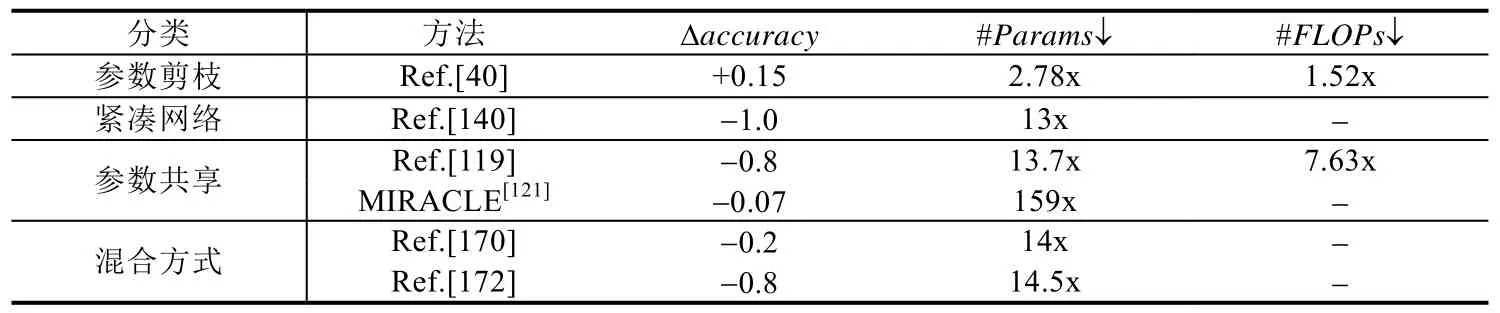
Table 6 Compression effects of different compression methods on VGG-16 on CIFAR-10表6 不同压缩方法在VGG-16 on CIFAR-10 上的压缩效果
表7 展示了参数剪枝、紧凑网络、低秩分解、参数共享和混合方式这5 类压缩技术的一些代表性方法使用ImageNet 数据集在AlexNet 上的压缩效果.整体来看,5 类方法达到的压缩效果和加速效果比较均衡,accuracy都略有下降.其中,参数剪枝和混合方式能够实现更大的压缩比,但低秩分解的加速效果更好;另两类方法都有不同程度的accuracy下降.
表8 展示了参数剪枝、低秩分解、参数共享和混合方式这4 类压缩技术的一些代表性方法在使用ImageNet数据集在VGG-16 上的压缩效果.整体的压缩与加速效果都很明显,其中,剪枝方法的accuracy略微有所提升;混合方式达到的压缩比最高.另外两类方法虽然accuracy有所下降,但加速效果更优秀.
表9 展示了参数剪枝、紧凑网络、参数共享和混合方式这4 类压缩技术的一些代表性方法在使用ImageNet数据集在ResNet-50 上的压缩效果.整体来看,accuracy的下降趋势比较明显,压缩与加速效果不如其他网络在ImageNet 上的好.其中,混合方式压缩效果最好,文献[169]达到15.8x 的压缩比;而在参数共享方法中,循环矩阵[111]达到了最高加速比5.82x.
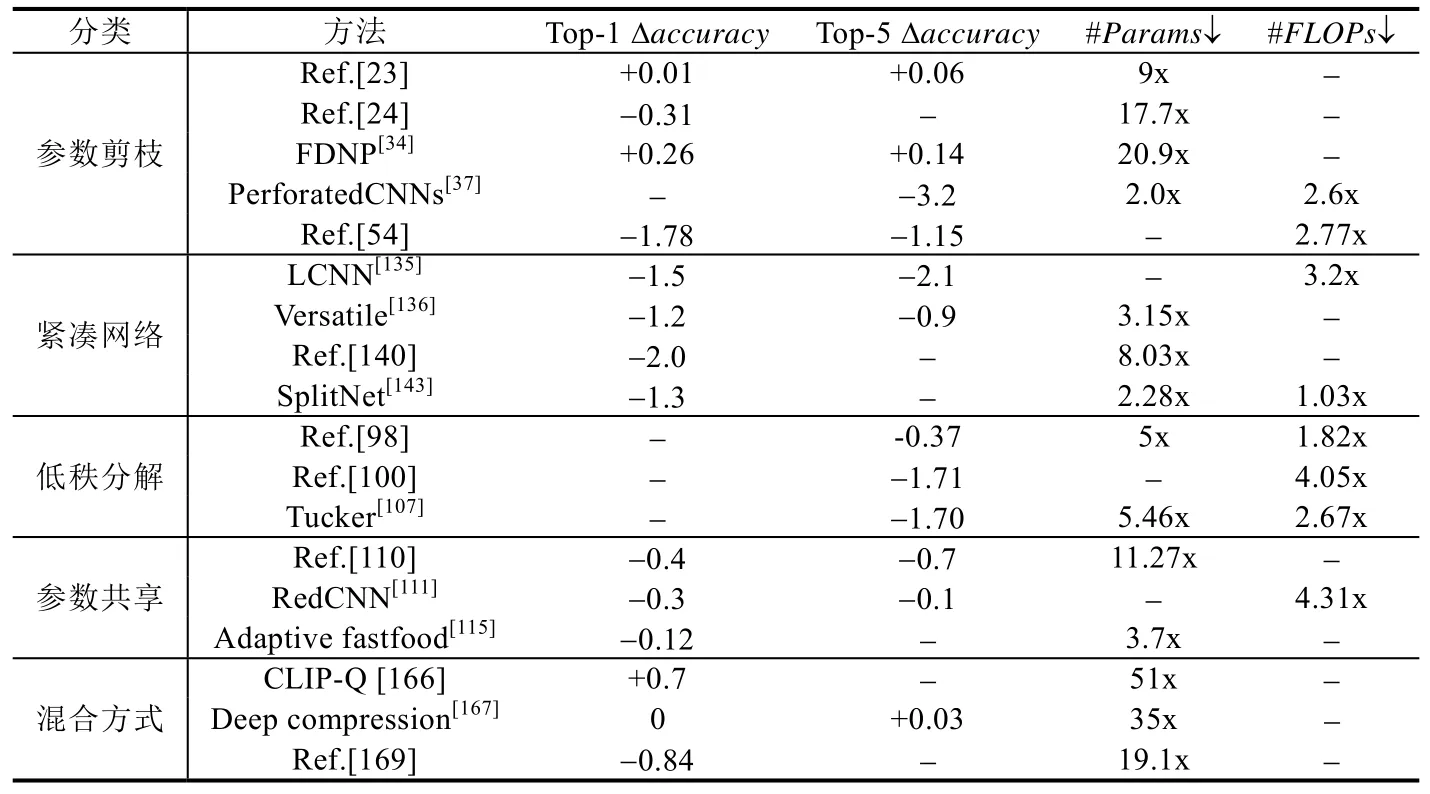
Table 7 Compression effects of different compression methods on AlexNet on ImageNet表7 不同压缩方法在AlexNet on ImageNet 上的压缩效果
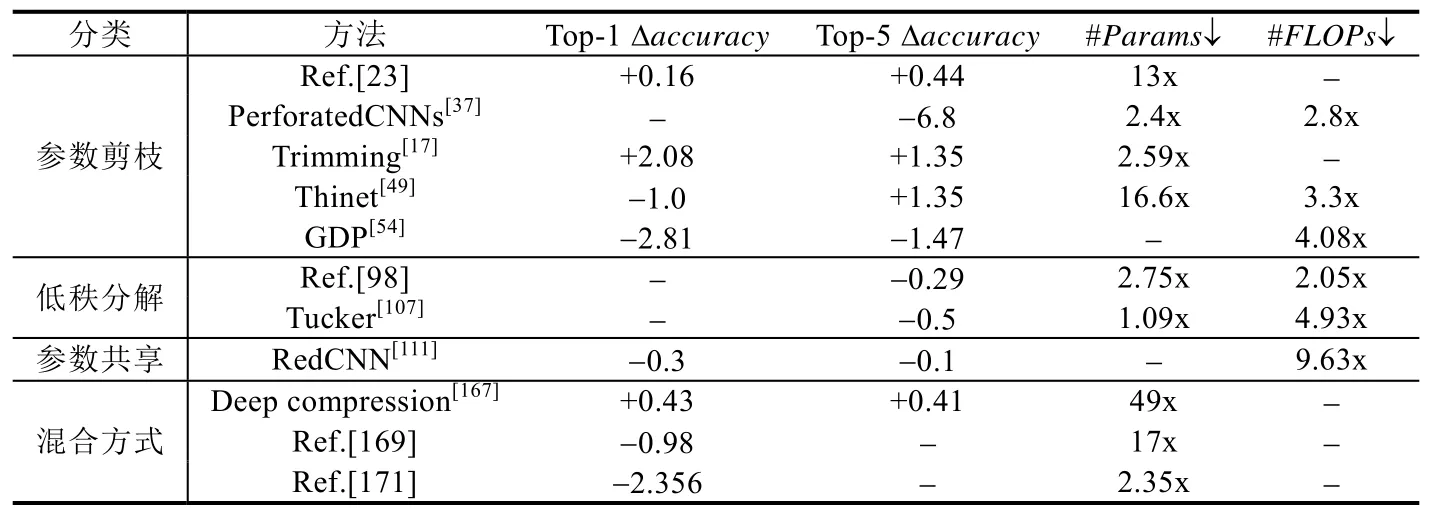
Table 8 Compression effects of different compression methods on VGG-16 on ImageNet表8 不同压缩方法在VGG-16 on ImageNet 上的压缩效果
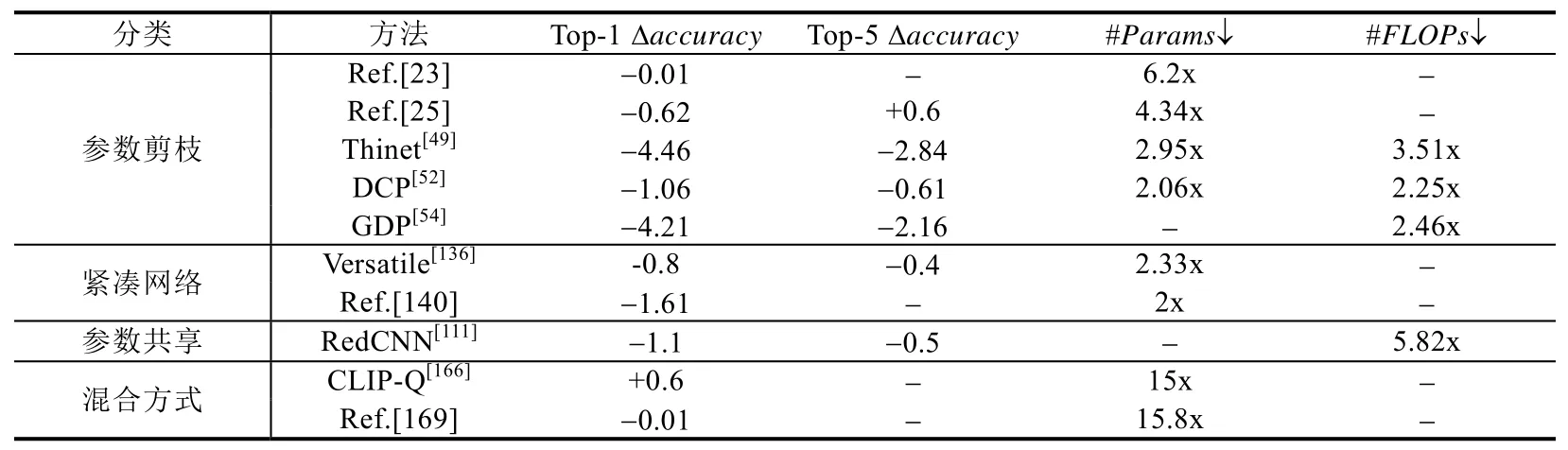
Table 9 Compression effects of different compression methods on ResNet-50 on ImageNet表9 不同压缩方法在ResNet-50 on ImageNet 上的压缩效果
表10 展示了一些主流量化技术使用ImageNet 数据集在AlexNet 上的压缩效果,其中,weight bits 为1 表示二值化网络,weight bits 为2 表示三值化网络.除此之外还有一些特殊位宽,其中,文献[89]中的3{±2}表示权值从{0,±1,±2}中选择,3{±2 ±4}表示权值从{0,±1,±2,±4}中选择.XNOR-Net[63]虽然能够达到比较好的压缩性能,但accuracy损失太大.SYQ[85]在实现权重二值化、三值化的同时,将激活值也量化到8 位,accuracy几乎没有损失,还略有提升.
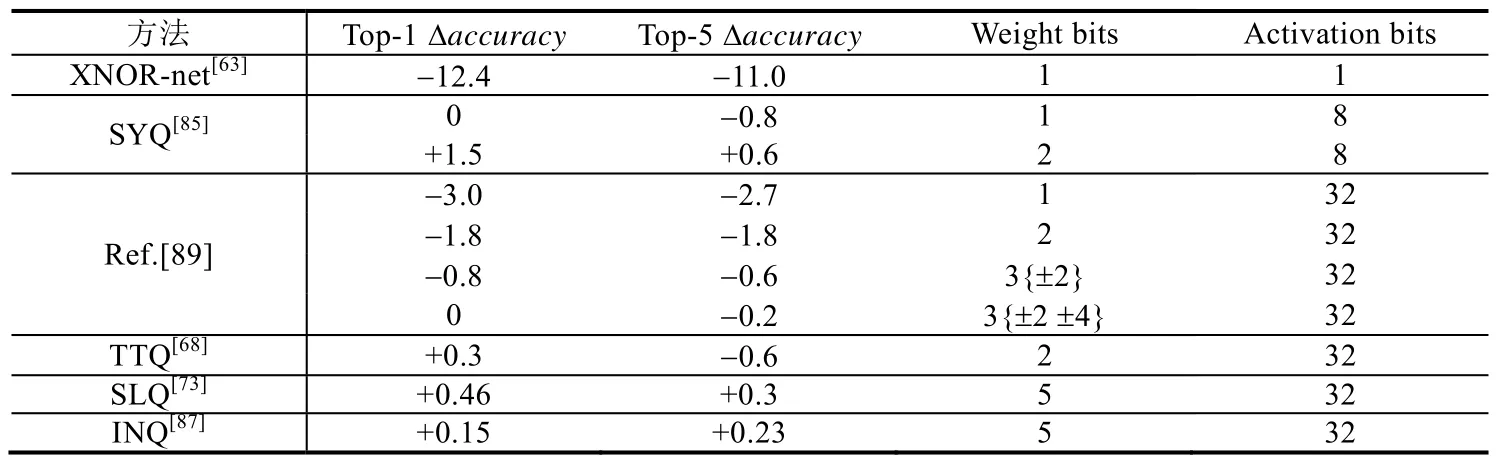
Table 10 Compression effects of different quantization methods on AlexNet on ImageNet表10 不同量化方法在AlexNet on ImageNet 上的压缩效果
表11 展示了一些主流量化技术使用ImageNet 数据集在ResNet-18 上的压缩效果.整体来看,accuracy的下降程度更大,对权值和激活值的大尺度量化带来不同程度的精度损失,SLQ[73]和INQ[87]将权值量化到5 位,accuracy略有提升.
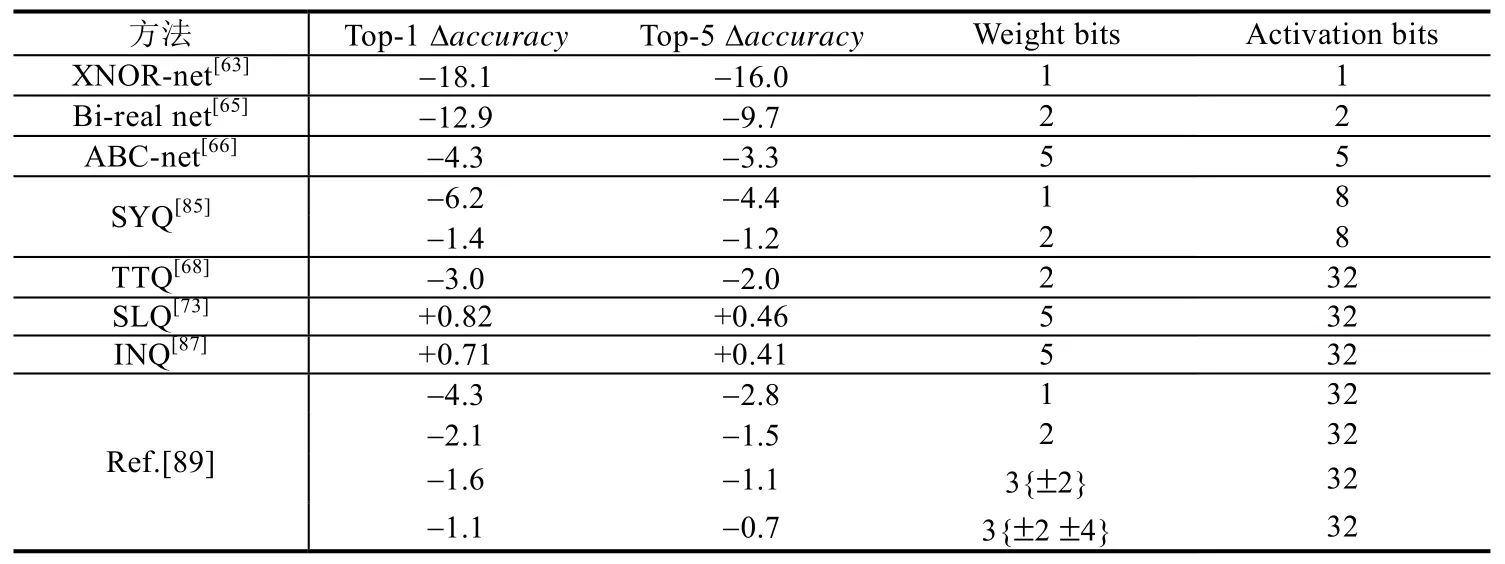
Table 11 Compression effects of different quantization methods on ResNet-18 on ImageNet表11 不同量化方法在ResNet-18 on ImageNet 上的压缩效果
表12 展示了一些有代表性的知识蒸馏方法在MNIST、CIFAR-10、CIFAR-100 和ImageNet 数据集上的压缩效果.由于使用的教师模型和学生模型的网络结构不同,所以我们将两个模型的accuracy和参数数量都展示出来,以方便读者对比.可以看出,相比其他方法,知识蒸馏的模型accuracy下降更多,压缩比更小.目前来看,未来知识蒸馏在模型压缩与加速领域还有很大的发展空间.
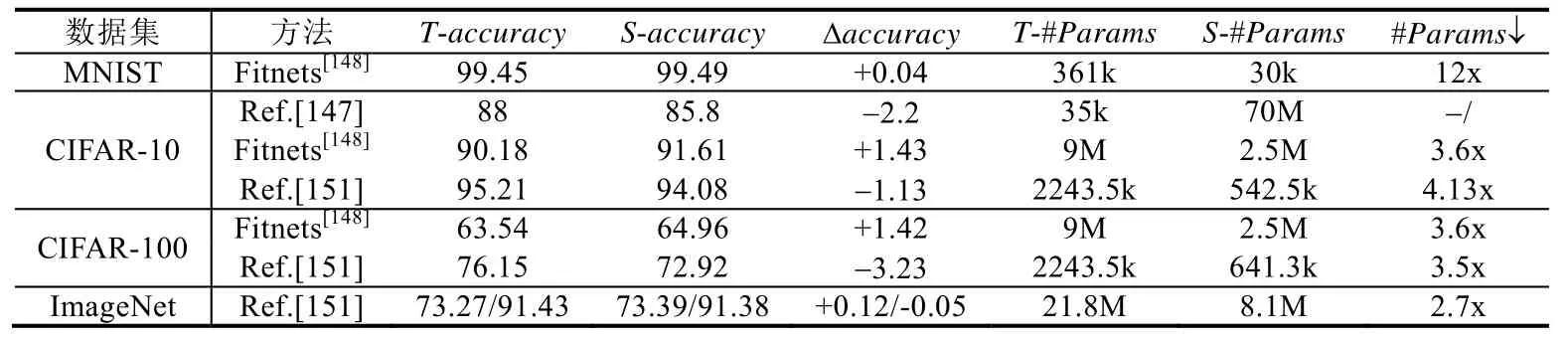
Table 12 Compression effects of different knowledge distillation methods表12 不同知识蒸馏方法的压缩效果
结论:我们总结的7 类压缩与加速方法各有利弊,由于实验使用的硬件平台不同,并不能量化地确定孰优孰劣.依据不同的应用场景和现实需要,可以进行方法的选取.例如:对于存储有限的嵌入式设备,可以使用非结构化剪枝或者二值、三值量化,以大幅度地减少模型占用的内存大小.对于没有预训练模型的情况,可以考虑紧凑网络法,直接训练网络.对于期望较高压缩比与加速比的应用场景,可以使用混合方式,组合使用几种压缩与加速方法.
4 未来研究方向
截止到目前,深度学习模型压缩与加速技术尚未发展成熟,在实际部署和产品化水平上还有很大的进步空间.下面介绍几个值得关注与讨论的研究方向.
(1)知识蒸馏作为一种迁移学习的形式,可使小模型尽可能多地学习到大模型的知识,具有方法灵活、不依赖硬件平台的特点,但目前,其压缩比和蒸馏后性能都有待提高.未来知识蒸馏可从以下几个方向展开研究:打破softmax 函数的限制,结合中间特征层,使用不同形式的知识;在选择学生模型的结构时,可以与其他方法集成;打破任务的限制,例如将图片分类领域的知识迁移到其他领域;
(2)将模型压缩技术与硬件架构设计相结合.目前的压缩与加速方法大多仅从软件层面对模型进行优化,并且不同方法由于使用的硬件平台不同,也很难比较其加速效果的好坏.未来可针对主流的压缩与加速方法专门设计硬件架构,既能在现有基础上加速模型,又方便不同方法的比较;
(3)制定更智能的模型结构选择策略.目前,无论是参数剪枝方法还是设计更紧凑的网络结构,都是基于现有模型作为主干网络,手动选择或使用启发式策略进行结构缩减,缩小了模型搜索空间.未来可以利用强化学习等策略进行自动网络结构搜索,得到更优的网络结构;
(4)将模型压缩技术推广到更多任务和更多平台.目前的压缩与加速方法多是为图片分类任务的卷积神经网络模型设计,然而实际应用中,还有大量其他模型应用于人工智能领域,例如语音识别和机器翻译领域常使用的递归神经网络(RNN)、知识图谱领域的图神经网络(GNN).为卷积神经网络模型设计的压缩与加速方法能否直接用于RNN 与GNN,还需要探索.同时,小型移动平台(如智能手机、机器人、无人驾驶汽车等)的硬件限制及其有限的计算资源阻碍了深度学习模型的直接部署,如何为这些平台设计独有的压缩方法,仍是一个巨大的挑战;
(5)模型压缩后的安全问题.由于当前压缩与加速方法更注重压缩完成后的任务完成度(例如分类任务accuracy是否有降低),而忽略了模型压缩可能带来的安全隐患,例如:相比原模型,是否更容易被对抗样本攻击.所以,未来在提升模型性能的同时,也应注意模型是否安全.
5 总结
本文首先介绍深度学习模型压缩与加速技术的研究背景;其次,对目前主流的方法进行分析,从参数剪枝、参数量化、紧凑网络、知识蒸馏、低秩分解、参数共享、混合方式这7 个方面进行分类总结;然后,对各类压缩技术中的一些代表性方法进行压缩效果比较;最后,探讨了模型压缩领域未来的发展方向.希望本文能够给研究者带来关于模型压缩与加速技术的更多了解,促进和推动模型压缩与加速技术的未来发展.
