区块链存储可扩展性研究进展*
2021-05-18孙知信
孙知信,张 鑫,相 峰,陈 露
1(南京邮电大学 国家邮政局邮政行业技术研发中心(物联网技术),江苏 南京 210003)
2(宽带无线通信与传感网技术教育部重点实验室(南京邮电大学),江苏 南京 210003)
3(物流信息互通共享技术及应用国家工程实验室(圆通速递股份有限公司),上海 201705)
区块链技术起源于2008 年,由一名叫中本聪(Satoshi Nakamoto)的日本人在《比特币:一个点对点电子现金系统》[1]中首次提出比特币的概念.比特币等数字加密货币的核心技术便是区块链技术.2015 年之前,大家更关注的是比特币的“币”而不是底层的区块链技术.2015 年,以太坊(Ethereum)[2]的出现以及之后的日渐成熟,使得区块链这一概念为更多人所了解和研究,并且朝着更加光明和广泛的应用场景不断发展.
区块链技术的不断发展,给信息共享[3]、版权保护[4]、供应链[5]、物联网[6,7]、医疗[8]、社交[9]以及文件存储[10]等领域提供了更多的可能.但是与传统货币相似,区块链技术同样存在三元悖论,即去中心化、安全性和可扩展性,三者只能得其二.当追求安全性和去中心化时,则无法顾及可扩展性;当追求安全性和可扩展性时,则无法实现去中心化;当追求去中心化和可扩展性时,则需要牺牲安全性.比特币和以太坊都是优先追求去中心化和安全性,而牺牲可扩展性.比特币的吞吐量为每秒处理7 次交易,以太坊则是每秒10~20 次.可扩展性已成为区块链应用落地的最大瓶颈.区块链可扩展性可分为性能可扩展性和功能可扩展性,其中,性能可扩展性包含吞吐量扩展、存储扩展以及网络扩展:吞吐量扩展与每个区块中的交易数及产生两个区块的时间间隔有关;存储扩展与区块链生成的数据有关;网络扩展与区块链网络中的数据传输有关[11].
当前,区块链的应用领域[12]可分为:(1)加密数字货币领域,如比特币、以太币等;(2)数据记录及管理领域,如数据存储[13]、数据鉴证[14]等;(3)信息安全领域,如认证技术[15]、访问控制[16]等;(4)其他领域,如共享经济[17]、智能交通[18]和能源网络[19]等等.区块链在不同场景下的应用,都因高冗余存储(每个节点存储一份完整的数据)增强了数据的公开性、透明性,提高了系统的可用性;但另一方面,每个节点都需要同步最新的账本,这会给区块链带来性能问题和巨大的存储压力.在加密数字货币比特币中,节点需要对全球账本进行同步,才能通过检索本地副本以验证交易的发起者是否拥有足够的“币”发起这笔交易.如图1 所示,截至2019 年第2 季度末,比特币大小约为221.29GB.潜在的用户如果没有足够的存储空间,那么它将无法加入到区块链网络中作为全节点来验证新交易.当区块链试图解决物联网领域的问题时,会遇到物联网设备作为区块链节点时节点数量增速快、自身体量小以及计算、存储等能力不足[20]的问题.从应用开发的角度看,基于区块链的应用开发需要满足可扩展性要求和一致性要求[21].区块链的一致性是指存储在区块链不同节点中的数据副本的取值必须一致,它通过共识算法、数据的可靠传输、高冗余存储和加密技术来实现[22].由于高冗余存储会增加节点的存储压力,导致存储可扩展性问题.因此,如果需要高一致性,那么就会降低存储可扩展性.综上,从区块链的应用领域和区块链的应用开发角度来看,区块链的存储可扩展性问题已成为制约区块链应用落地的一大问题[23].
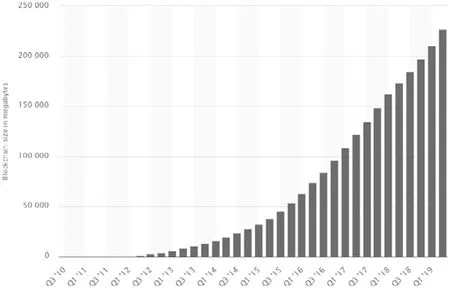
Fig.1 Bitcoin blockchain size from 2010 to 2019 in MBytes图1 从2010 年~2019 年比特币区块链的大小(以MBytes 为单位)
潘晨等学者[24]从性能扩展和功能扩展两个角度,详细介绍了当前3 类主流提升区块链吞吐量的技术和4类扩展区块链功能的技术.Xie 等学者[11]给出了目前区块链吞吐量、存储以及网络这3 方面所面临的挑战,并介绍了一些解决办法.Zhang 团队[25]提出了一种低开销的区块链存储架构,架构包含3 种机制,分别是将原始数据转换为关键词的语义信息模板机制、将区块链账本划分为多个切片的滞后数据切片机制以及将低价值数据存储到中央数据库的历史数据归档机制.Wang 团队[26]建立了关于空间占用率和平均搜索时间之间的数学模式,并设计了一个数据分配策略,以实现在区块链网络中节约存储空间.现有文献一类是应对区块链存储可扩展性问题,提出了相应的解决方案;另一类则是对区块链可扩展性的综述,虽然归纳得较为完整,但更偏重性能、网络、吞吐量等方面的可扩展性.两者都没有对区块链的存储可扩展性问题进行详细、系统的分析,没有体现出在解决存储可扩展性问题时,数据存储方式、节点间的相互关系等角度的差异分析.本文首先介绍区块链所面临的存储可扩展性问题和区块链的存储模型,然后系统性地对链上存储(on-chain storage)和链下[27]存储(offchain storage)的基本原理、现存问题进行了分析(如图2 所示),并对未来的发展加以展望,希望能给当前及未来的相关研究工作提供一定的参考与帮助.
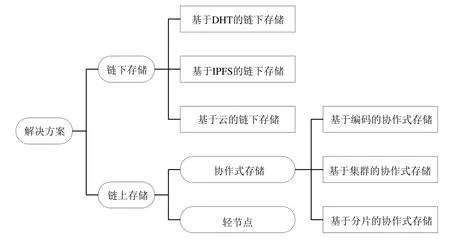
Fig.2 Solutions to improve the storage scalability of blockchain图2 提高区块链存储可扩展性方法分类
本文第1 节概述区块链技术和区块链的存储模型.第2 节和第3 节分别综述目前提升区块链存储可扩展性的两大类解决方案——链下存储和链上存储.第4 节指出当前解决方案所面临的问题,并给出未来可能的研究方向.
1 区块链概述和存储模型
1.1 区块链概述
区块链是一种结合分布式共识、加密、时间戳以及经济激励等方法,在一个完全无信任的环境下,实现去中心化的点对点交易、协调与协作的技术[7].区块链技术有许多优点,例如去中心化、安全性、匿名性、透明性以及自动化等.去中心化的特性解决了在传统中心化场景下成本高昂、效率低下、安全性不可靠等问题[28].区块链将前一块的hash 值添加至后一区块的区块头中,从而实现链式结构.当经过6 个区块确认后,这笔交易几乎没有被破解的可能性.通过使用匿名地址并将现实世界地址或标识隐藏,区块链实现了匿名的特性.在中本聪设计的区块链中,任何人都可以查询区块链世界中的每一笔交易信息,从而实现了透明性.区块链技术可以提供灵活的编程特性,支持用户创建可在区块链上自动运行的高级程序,包括智能合约、加密货币及去中心化应用(DApp).通过共识算法[29],区块链中的节点们确保了数据的一致性.
区块链根据其应用场景或开放程度[30]可分为 3 种:公有链(public blockchain)、联盟链(consortium blockchian)和私有链(private blockchain).三者的差异主要体现在网络结构(是否完全去中心化)、共识机制、激励机制等方面.根据不同场景下的信任构建方式[31],区块链可分为“非许可链(permissionless blockchain)”和“许可链(permissioned blockchain)”.非许可链又称为公有链,是一种完全开放的区块链,彼此间不需要信任;许可链可分为联盟链和私有链,彼此间需要通过一定的方式建立信任关系,具有非完全去中心化的特点.
1.2 区块链存储模型
在区块链系统中,节点作为完全节点存储完整的区块链数据,能够有效地保证区块链的数据安全[32],即,通过高冗余存储机制保证区块链的数据安全.但是,对于具有高冗余存储特点的任何类型的区块链,现在或未来都将有可能遇到存储可扩展性问题.本节将通过结合典型的采用高冗余存储机制的比特币模型来介绍区块链存储的基本模型和关键技术,区块链的存储模型如图3 所示.区块链存储模型可抽象为两层,分别是数据层和网络共识层[33].区块链网络本质上是一个P2P 网络[34],节点地位相同.区块在矿工节点计算出正确的nonce值后,由矿工节点广播至整个区块链网络,其余节点收到区块后验证,通过后将新区块链接至自己存储的区块链之后.
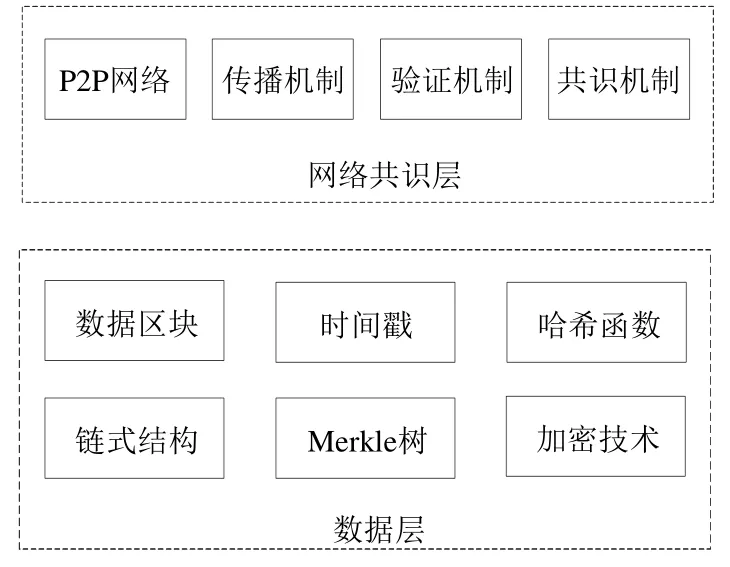
Fig.3 Storage model of blockchain图3 区块链存储模型
(1)数据层
一个完整的区块由区块头和区块体构成.区块头中包含版本号、前一区块的哈希值;当前区块的难度、当前区块经过PoW 解出的随机值Nonce;当前区块的时间戳以及当前区块所有交易的Merkle 根.区块体中包含当前区块内的交易数量以及所有经过验证后的交易.区块结构如图4 所示.
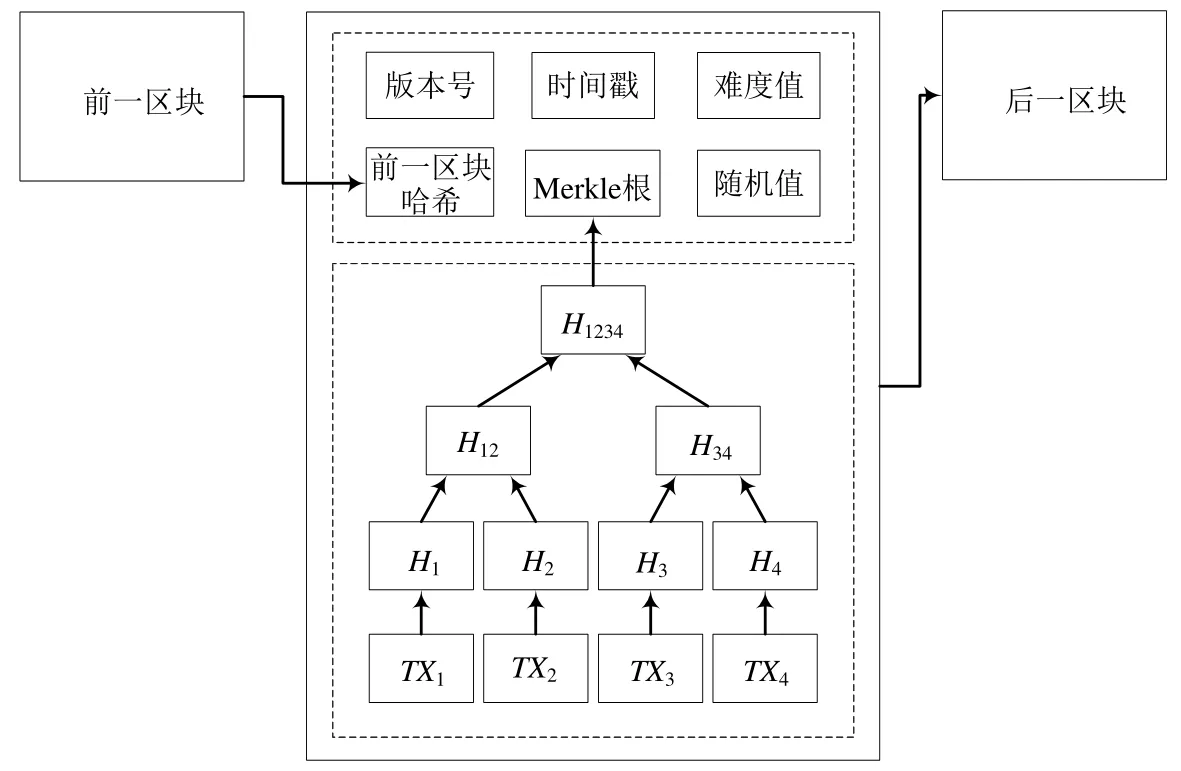
Fig.4 Structure of blocks图4 区块结构
链式结构是区块链数据结构的核心.当新区块被生成后,矿工将其添加至区块链的尾端.区块间依次链节,从而形成完整的区块链数据.当需要访问任意数据时,都可以通过链式结构依次向前溯源.Merkle 根是连接区块头和区块体的重要组件.Merkle 根可以快速归纳和检查区块中交易的存在性和区块的完整性.首先,将区块中所有交易进行分组哈希;然后,将计算出的哈希值插入到Merkle 树中;接着,对这些哈希值再次分组哈希.如此递归,直至最后生成Merkle 根并保存至区块头中.时间戳表明当前区块的生成时间,因此,区块链中的所有区块依照时间顺序排列.时间戳可作为区块存在的证明,提高了区块链的不可伪造性和不可篡改性,进而有利于区块链应用到公证、存证等领域.哈希函数具有单向性、易计算性以及抗碰撞性等良好的性质.此外,数据经过哈希函数计算后产生定长的哈希值.这些特性使得哈希函数非常适合应用至区块链中.加密技术,特别是非对称加密,用于保护区块链数据的安全性.
(2)网络共识层
网络共识层包括区块链网络的组成方式、消息传播机制、数据验证机制和共识机制.比特币等公有链网络中的节点具有分布式以及可自由进出等特点,因此采用P2P 网络构成区块链网络.P2P 网络中每个节点地位相等,每个节点的功能完全一样,并且不存在任何中心化的机构管理网络.消息传播机制是指当新区块被生成后,将被生成它的矿工广播至区块链网络中的其他节点处验证.数据验证是指任意节点任意时刻都监听区块链网络中广播的交易和新区块.节点在接收到其他节点广播来的交易后,验证其有效性:若交易有效,则将其加入用以存储尚未添加至区块的有效交易的交易池中;若交易无效,则将其删除.共识机制是存储模型中网络共识层的核心,它可以使得区块链网络中的节点高效地达成共识并保持区块链的一致性.在比特币网络中,节点们通过比拼算力,以解决一个计算困难但验证简单的数学问题,最先解答出该问题的节点拥有记账权,并可获得一定的经济奖励.
2 链下存储
链下存储是一种将区块体中数据内容从原区块体转移到链下存储系统,区块体中仅存储指向这些数据的“指针”和其他非数据信息,以解决区块链存储可扩展性问题的方法.当需要存储完整数据时,将原始数据保存至非区块链系统中,同时,按照一定规则生成该数据的唯一标识,并返回给区块链系统;当需要访问完整数据时,通过数据的唯一标识在非区块链存储系统中寻找原始数据,如图5 所示.
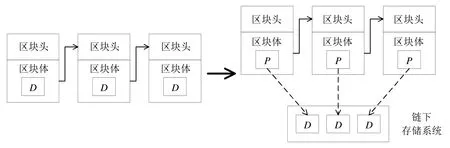
Fig.5 Off-chain storage图5 链下存储
定义区块为B,区块头为H,区块体为Body,区块体中的数据为D,P为指向链下存储系统的“指针”,链下存储系统为OffChainSS,则有:
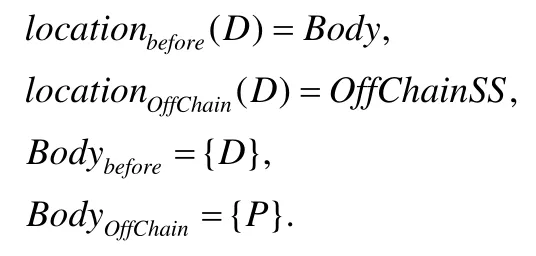
• 基于DHT 的链下存储
分布式哈希表(distributed hash table,简称DHT)是一种分布式存储方法[35].DHT 在不需要中心服务器的情况下,每个节点负责一个小范围内的路由,同时存储一小部分数据,从而实现DHT 网络的寻址和存储.Zyskind 等学者[36]改变了传统区块链网络(例如比特币)存储所有交易的存储模式,将数据与数据引用进行分离式存储,设计了一种使用DHT 的链下存储模式,其中,DHT 由Kademlia[37]实现,如图6 所示.原始数据的引用(即原始数据经SHA-256 计算后的散列值)保存在区块链中,而原始数据则保存在链下的DHT 中,如图6 所示.DHT 由与区块链网络无关的节点维护,这些节点履行经区块链网络批准的读写操作.数据在DHT 网络中的节点位置足够随机,并且保持一定的重复率,从而确保了高效的可用率.
据美国高德纳公司之前的估计,到2020 年,世界上有约200 亿个设备互联到物联网中.这些设备数量巨大,给数据的安全存储带来了挑战.为了有效地存储大规模的物联网数据,Li 等学者[38]提出了一种适用于大规模物联网数据的存储与保护方案,如图7 所示.该方案利用边缘计算技术克服了物联网设备计算能力不足的问题,并且将数据转发到链下的DHT 存储系统中.当实体需要访问数据时,在区块链中广播已添加由无证书密码体制[39]生成的公钥的数据请求,并由区块链的矿工节点负责对实体的认证工作.
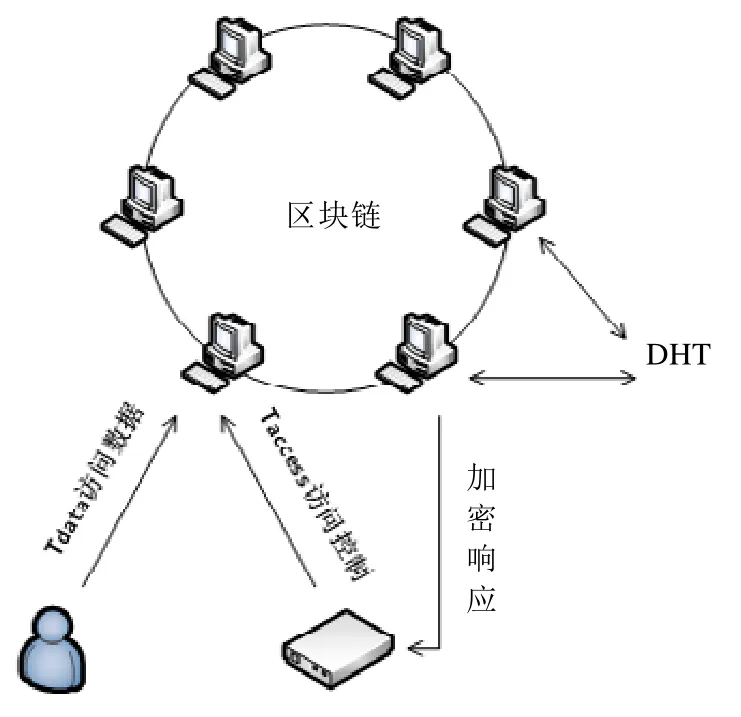
Fig.6 Overview of the decentralized platform图6 平台结构示意图
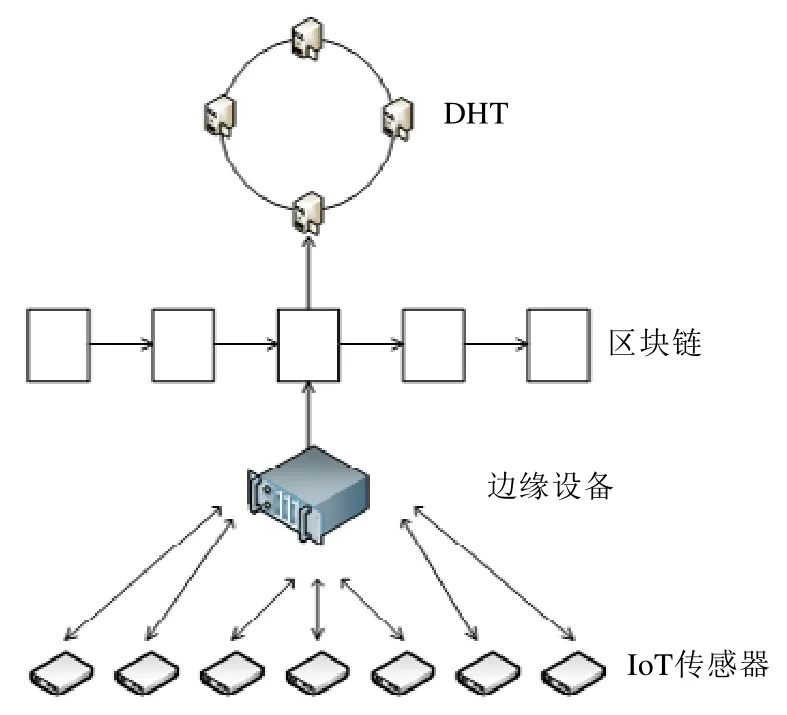
Fig.7 Structure of data storage scheme with blockchain图7 基于区块链和边缘计算的物联网数据的存储方案
• 基于IPFS 的链下存储
星际文件系统(inter planetary file system,简称IFPS)是一种旨在将所有计算设备与相同文件系统连接起来的点对点分布式文件系统[40].IPFS 是内容寻址的,即内容本身决定了内容的位置[41].文件存储到IPFS 后,将会得到一个IPFS hash.IPFS hash 既可以作为访问文件的索引,又可以检验文件内容是否被篡改.基于IPFS 的这一特性,IPFS 作为区块链的存储方案(即区块中只保存IPFS hash)是目前链下存储中使用较多的一种方案.
Zheng 等学者[42]设计了一种基于IPFS 的区块链存储模型,矿工检查待验证的交易是否有效:如果有效,则将其存入IPFS 中,并将IPFS 返回的哈希加入至交易池.当新区块产生后,其他节点验证新区块:如果新区块中的交易哈希与本地交易池中的交易哈希相同,则代表这些节点同样验证过这笔交易;如果本地交易池中没有,则通过哈希从IPFS 中下载并确认.Ali 等学者[43]针对物联网数据隐私问题提出了一种基于区块链和IPFS 的“模块化联盟架构”,既解决了传统区块链网络无法存储海量数据的缺点,又消除了IoT 数据的中心化管理模式.Desema[44]是一个基于Ethereum 和IPFS 的分布式服务市场系统.在Desema 中,服务的元数据和大型数据都存储在IPFS中,而区块链中仅存储这些数据的散列值.Xu 团队[45]提出了一种基于Ethereum 和IPFS 的社交媒体应用,其中,Ethereum 用于保存用户数据,IPFS 用于保存大型文件数据.这既保证了用户数据的完整性和真实性,又解决了文件存储的冗余.以太坊创建智能合约时,需要将智能合约代码保存至以太坊中.这意味着老旧的或者不再使用的智能合约都保存在以太坊中,从而极大地增加了创建智能合约时的存储消耗.Norvill 等学者[46]在创建智能合约时,把智能合约源码存储到IPFS 中,从而显著地减少了这类存储消耗.
• 基于DHT 和IPFS 的链下存储
PingER(ping end-to-end reporting)是一个由SLAC 国家加速器实验室美国开发和管理的全球端到端互联网性能测量框架[47].PingER 由遍布全球20 个国家的50 个MA(monitoring agent)组成.每个MA 每天将ping 统计信息存储到本地MA 上,然后SLAC 再将每个MA 的数据归档至中心服务器.为了防止未来SLAC 支持的消失,文献[48]提出了一种基于区块链和DHT 的去中心化的数据存储和访问框架.MA 的身份由客户端转变为节点,因此,MA 的作用不再仅限于收集数据,而是成为数据存储、处理的节点.区块链中存储数据文件的元数据信息以管理身份和访问控制,数据文件的引用存储在链下的DHT 中,而数据文件本身则存储在IPFS 中,如图8 所示.
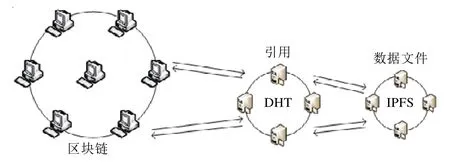
Fig.8 Off-chain storage pattern using DHT and IPFS图8 DHT 与IPFS 共同作为链下存储
• 基于云的链下存储
Ali[49]提出了一种方法,通过把实际数据存储到云端,数据的散列值保存在区块链中,从而解决区块链的存储扩展性问题.Chameleon[50]是一个动态适应、可扩展的私有链架构.Chameleon 架构由控制和认证层、云存储层、共识和处理层以及访问层组成.与文献[49]不同,Chameleon 不是将所有的数据都存储在云上,而是将数据的散列值存储在区块链中.而Chameleon 认为:在一些场景下,数据与之前的数据几乎是没有关联的.因此,它将最近一段时期(一天或者一周)的数据存储在区块链中,以前的数据存储到云上.存储在云上的以前的数据中,最新的一个区块的散列值将被保存至区块链中,从而实现数据的一致性(见表1).
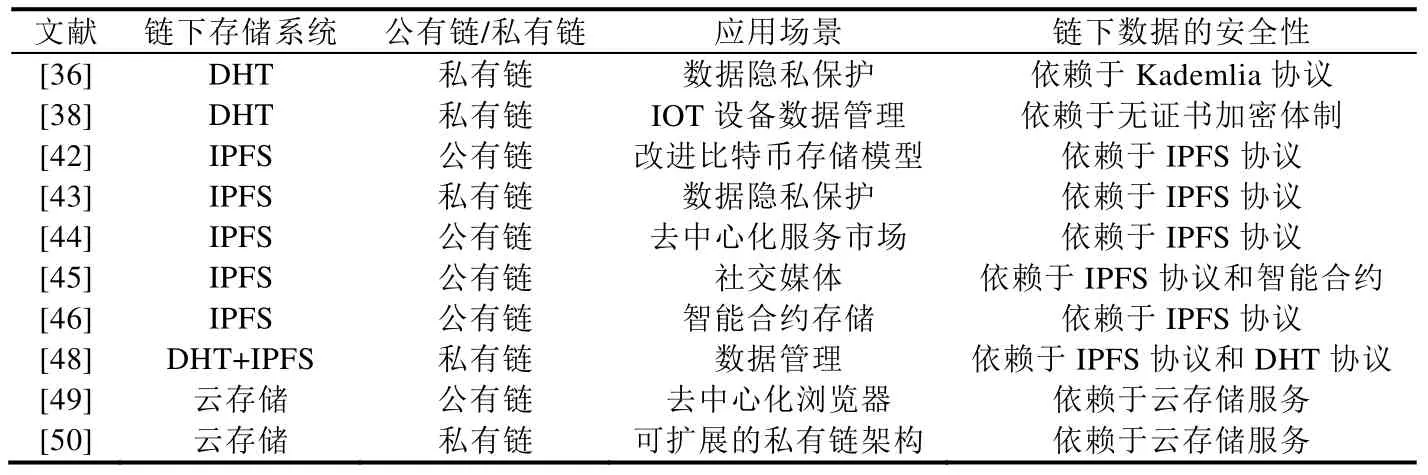
Table 1 Comparison of off-chain storage patterns表1 链下存储对比
在链下存储方式中,区块头或重要数据依然保存至区块链账本中,原始区块体以及其他数据由链下存储系统负责存储.新区块体中可存储访问链下存储系统的访问记录等信息,而指向链下存储系统的“指针”信息可存储于新区块体中,也可存储于区块头中.由比特币区块的结构可知:一个区块所占的大小约为1M,而一个区块的区块头的大小为80byte[1].因此,从存储效率的角度看,链下存储可以大幅度地减轻区块存储的压力.
从所使用的技术角度来看,现阶段链下存储方式主要可分为基于DHT 的链下存储、基于IPFS 的链下存储以及基于云的链下存储.基于DHT 或IPFS 的链下存储与传统分布式存储相似,同样需要考虑存储冗余的问题,以提高位于链下的数据的安全性.但与比特币网络中每个节点保存完整账本的方式不同,这两种改进的链下存储缓解了区块链网络中节点的存储压力,将一部分数据存储的工作量转移到一个与区块链网络并行的分布式存储系统中.该系统节点既可以由区块链网络中的节点,也可以由不在区块链网络中的节点组成.若链下的分布式系统全部由区块链网络中的节点组成,这样仅仅减轻了那些在区块链网络中但不在链下分布式存储系统的节点的存储压力.因此,通常的做法是链下分布式存储节点由两部分构成:一部分是区块链网络中的节点,另一部分是非区块链网络中的节点.这种做法缓解了大部分区块链网络中节点的存储压力,由一些具有足够存储能力的节点同时负责链下的分布式存储系统.然而,这种做法也并不是完美的:一方面,在需要考虑如何挑选具有足够存储能力节点的同时维护链下存储系统,但又要保证这些节点不是恶意节点而控制区块链的数据真实性;另一方面,需要考虑如何确定链下分布式存储系统中的区块链节点和非区块链节点之间的比例,以确保存储系统的安全.基于云的链下存储将存储压力转移到云,区块链的去中心化属性将被减弱.基于云的链下存储方案与前两者的不同在于,区块链节点无法参与到云存储中.云存储服务往往都由大型的服务商提供,依赖于中心化机构的服务.此时,区块链仅能验证数据是否被篡改,而不能保证数据的真实性.另一方面,从经济角度来看,云存储所产生的成本由谁承担,以及如何控制减轻区块链节点存储压力所带来的收益大于云存储所需要的额外经济成本,都是需要慎重考虑的.链下存储可以显著减轻区块链节点的存储压力,但需要考虑新的安全问题.
3 链上存储
链上存储,不需要每个节点都存储完整的区块链账本,也不依赖于额外的链下存储系统,只需要每个节点根据预先约定的规则存储对应的部分账本即可.链上存储与前一节所述链下存储的不同在于:数据仍然存储在区块链上,而不是非区块链存储系统中.根据预先约定的规则中节点间的相互关系,链上存储可分为协作式存储模式和轻节点模式.定义区块体中的数据为D,Bodyi-1为第i至第j个节点同一区块的区块体,其中,j≥i,为原数据根据链上存储规则确定的存储内容,≤.D那么,链上存储可表达为
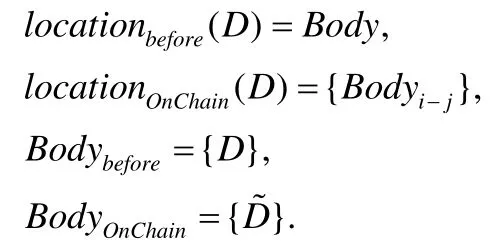
3.1 协作式存储
与比特币的经典存储模式相比,链上协作式存储模式不再需要每个节点都保存一份完整的区块链数据备份.节点协作是指若干个不同的节点进行合作,从而使这些节点具有与“全节点”一样的功能.协作式存储根据使用技术的不同,合作的方式也有很多种形式,可分为基于编码的协作式存储、基于集群的协作式存储和基于分片的协作式存储.
• 基于编码的协作式存储
Dai 等学者[51]提出了一种基于网络编码的分布式存储框架(network coding-based distributed storage,简称NC-DS).网络编码是一种将编码和路由信息交换的技术,可以对接收的多个数据包进行编码信息融合,从而提高单次传输的信息量,进而提升网络整体性能[52].NC-DS 有两种实现:一种是码率确定的NC-DRDS,另一种是码率非确定的NC-RLDS.
(1)NC-DRDS 机制取代同时输出数据包的形式,采用顺序输出的形式输出编码后的包.将大小为x的区块(或多个区块)切分成k个包,对其进行Reed-Solomn 编码,得到n个编码包,存放至n个节点中(即一个节点保存至一个包).倘若仍有节点未保存,则继续将k个数据包编码成2n个编码包,存放至2n个节点中.重复上述操作,直至区块链网络中所有节点均保存了一个编码包,如图9 所示.任意k个编码包都可恢复原始数据包;
(2)而NC-RLDS 机制则采用了一种二进制域随机偏移编码,将数据包右移随机位的比特然后按位的方式组合,同样以NC-DRDS 的方式分发至区块链网络中的每个节点.
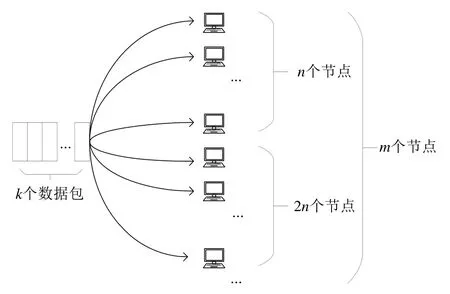
Fig.9 NC-DRDS图9 NC-DRDS 示意图
Perard 等学者[53]基于纠删码(erasure code)提出了一种降低节点存储负担的LS(low storage)节点.区块首先被切分成k个片段,再使用伪随机数生成器生成的系数对原始片段进行线性组合,生成编码片段并发送至节点.当节点需要恢复区块时,只需从其他节点下载超过k个编码片段.对这些编码片段进行逆线性变换,便可恢复出原始区块.当有新节点加入区块链网络中时,首先从全节点或者其他LS 节点处下载完整区块链,然后对每个区块进行验证,并生成编码片段.新节点将完整的区块删除,同时保留区块的哈希和编码片段.因此,LS 节点在不需要存储完整区块链的情况下,仍然可以验证完整区块链.
• 基于集群的协作式存储
文献[54]中提出了一种基于DHT 集群的存储负载均衡方案,DHT 由Chord 协议[55]实现.在该方案中,区块链网络中的节点划分成若干个DHT 集群,一个DHT 集群中的若干个节点共同维护一份完整的区块链数据.区块链中的节点通常需要保存两部分内容,分别是区块数据和区块链状态.在该方案中,DHT 集群中的一个节点只需保存完整区块链副本中区块数据的一部分,而区块链状态部分则需要区块链网络中每个节点都存储.新区块产生后,根据区块的散列值映射到Chord 环的对应位置.根据哈希函数的特性来确定DHT 集群内每个节点存储多少个区块会满足均匀分布的要求.在DHT 集群内,如果需要重复存储R次,则在Chord 环中的节点后面的R个节点同样存储1 次.如果一个区块在DHT 集群内的所有节点都重复存储,那么此时DHT 集群的节点就像全节点一样.
Kaneko 等学者[56]设计了一种基于DHT 集群的负载平衡方法,其中,DHT 由Kademlia[37]实现.在这一方法中,区块链中的节点分为两类:第1 类在纯P2P 网络中挖矿,称为挖矿节点;另一类在DHT 网络中验证新交易和新区块以及保存区块链数据,成为数据节点.当数据节点产生了一个新交易,则首先广播至该节点所在的DHT集群中;然后,集群中的其他节点将该交易广播至其他集群中.所有数据节点对交易进行验证,如果交易有效,将其广播至P2P 网络中,挖矿节点收集交易,并重复该过程直至挖出新区块.根据新区块的哈希得到该区块的ID,与节点ID 进行XOR 运算,得到与区块ID 距离最近的节点所属的DHT 集群.挖矿节点将新生成的区块广播至该集群,集群的节点对区块进行验证,并添加至区块链中.
文献[57]引入了“共识单元”这一概念,共识单元是指一起工作并维护至少一份完整区块链的一组节点.根据前一个单位时间内的区块访问频率,将需要访问的区块优先存储到共识单元内的节点,并考虑一定的冗余.再将所有在前一个单位时间内未被访问的区块分配至相应的节点.至此,共识单元内的存储空间已全部被使用.当共识单元内有新区块需要存储时,需要占用一部分旧区块的空间.根据最优原则,将新区块存储到某个节点上有备份存储的某个或某些区块占用的空间.当有新节点加入共识单元时,分配一定的区块给新节点,从而降低共识单元内的查询消耗.当共识单元内有节点离开时,若该节点存储的区块也存储在其他节点处,那么只需通知查询者更新查询目的地;若该节点存储的区块在其他节点处没有备份,则只需将这些新区块作为需要存储的新节点对待即可.
• 基于分片的协作式存储
分片技术最早被应用于分布式数据库领域,数据库被分割成多个部分并存储到不同的服务器中.在区块链领域中,分片是指节点被分成若干个更小的单元并行地处理交易或维护不相交的区块链账本,前者称为交易分片,后者称为状态分片.Elastico[58]是第一个基于分片的公有链共识协议,Elastico 的思想是交易分片,因此,区块链即使分片后,每个节点仍然需要存储完整的账本.
OmniLedger[59]意识到了Elastico 存在的问题,并做出了改进.OmniLedger 由身份链和多个分片组成,通过RandHound 协议,将节点自动地分配到不同的分片.为了减轻节点的存储消耗,OmniLedger 引入了状态块的概念.当一个共识时代结束时,分片的领导者将UTxO 存储在有序的Merkle 树中,并将Merkle 的根哈希存入状态块的头部.状态块经过验证后,将作为下一个共识时代的创世块.但是,OmniLedger 采用的是分片定期改组策略,所以存在大量的数据迁移消耗.
SSChain[60]将区块链网络划分为根链网络和分片网络.市场激励机制会动态地调整根链网络和区块链网络中的哈希算力,使得哈希算力均匀地分布在不同分片中.节点可以自主选择加入收益较高的分片.一个节点可以同时属于根链网络和分片网络.根链网络负责验证一段时间内的分片区块并生成根区块,同时保存完整的分片区块和根区块.SSchain 采用市场激励机制,因而不需要定期改组分片网络,避免了数据迁移.为了减轻分片内的存储负担,SSChain 将前一时期内的UTxO 保存至有序Merkle 树中,然后将Merkle 树的根哈希保存至检查点的头部中,检查点前的区块便无需再存储.
不同于前两种动态划分分片的方式,Yoo等学者[61]提出了一种基于域的静态分片区块链模型.该模型将区块链网络分为区域分片和全局分片,如图10 所示.区域分片内存在由PoW 决定的委员会,并动态调整.委员会内的节点通过PBFT 验证交易并生成区块.全局分片的委员会同样由PoW 决定,委员会通过PBFT 验证交易.交易通过验证后被传输到相关的区域分片中.区域分片内的节点负责生成区块并保存至区域区块链中.
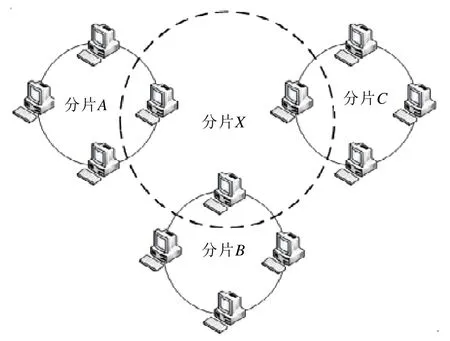
Fig.10 Collaborative storage pattern based on sharding图10 基于分片的协作式存储示意图
为了方便比较和总结3 类协作式存储的区别,下面对一些概念进行定义.
定义1(区域).区块链网络可由若干个区域组成,区域之间可以相互交叉.集群、分片等都可视为一个区域.
定义2(静态区域划分).对于节点ni,根据节点分配机制,当t=t1时,ni被分配到区域Aj1;当t=t2时,ni被分配到区域Aj2.若∀t2≠t1,都有Aj1=Aj2,则称区域划分是静态的;反之,则称为动态.
定义3(区域定期改组).区域定期改组是指节点ni一旦被分配到区域Aj1内,任意时间后都不会被系统重新分配到区域Aj2,其中,Aj1≠Aj2.
定义4.区域账本是指仅记录该区域内交易的区块链账本,记为BCarea.
定义5.对于区块Bk,,则称为区块Bk的子集,称为区块子集的线性组合;对于区块Bk,称为区块的集合.
定义6.当新节点加入区域时,区域内的原节点若需要调整已存储的数据,则称该模型具有自动调整性.
定义7(区块的原子性).若区块完整地存储在一个节点中,则称该存储方式保留了区块的原子性;反之,若一个区块经过切分存储在不同的节点中,则称该存储方式破坏了区块的原子性.
集群是指一组共同工作的节点,而分片则指将账本切分成粒度更小的部分.本文中,集群是从节点的角度切分区块链,分片是从账本的角度切分区块链.因此,本文将集群和分片均看作是区域.基于编码的协作式存储模式没有显式的区域划分,但可以将源于同一个数据包的若干个子包所在的节点看作是一个区域,满足定义1.如果下一个数据包划分成若干个子包后,这些子包所处的节点集与前一数据包时不同,则可看作为区域定期改组,周期为产生一个新区块的时间.
表2 从区域划分思想、划分形式、定期改组、区域存储内容、区块原子性、区域自动调整性、是否有节点存储完整账本以及节点存储大小的角度,详细地对比了8 种不同的协作式存储.动态划分区域有利于防止恶意节点控制某一区域,从而影响整个区块链的网络性能.定期改组区域能够提高一定的安全性,但与此同时,也会存在大量的数据迁移工作.对于文献[54]和文献[57]中的方案,当有新节点加入区域后,模型会自动地调整曾经存储在原节点上的数据,重新分配到新节点上.这种自动的调整方式会占用区域内的通信带宽,增加通信成本.从存储效率的角度看,对于基于编码的协作式存储,编码时切分的数据子包个数越多,节点所需的存储空间越小.对于基于动态分片的协作式存储,区块链分片数越多,节点所需存储空间越少.这两种方式所需的存储空间和比特币存储模型所需存储空间呈线性关系.对于基于集群的协作式存储,节点所需存储空间与集群内节点数量相关,集群内节点数量越多,每个节点所需存储空间越小.对于基于静态分片的协作式存储,当进行初始化划分时,若某一分片规模明显大于其他分片,则日后同样也将面临存储膨胀的问题.
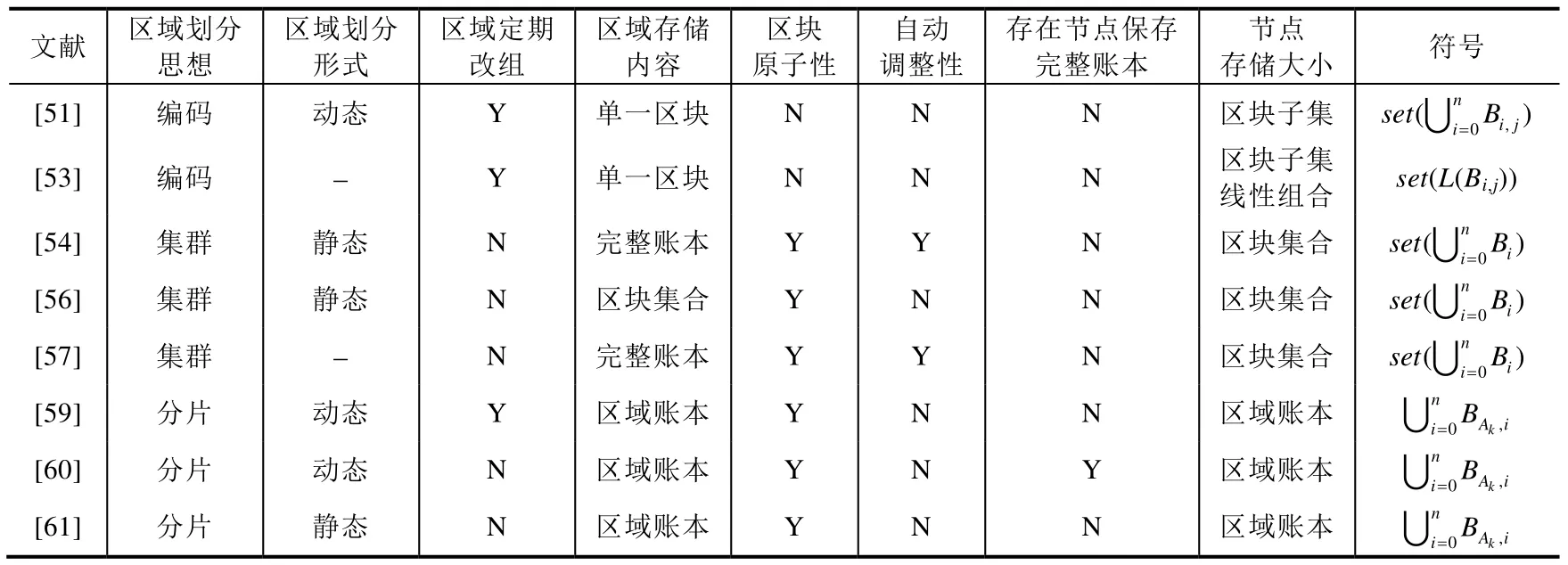
Table 2 Comparison of collaborative storage patterns表2 协作式存储比较
3.2 轻节点
3.2.1 SPV 轻节点
在比特币网络中,大部分用户是普通用户(没有矿机并且只消费比特币的用户).如果这些用户运行一个完整的比特币客户端,那么需要准备大约200G 的空余硬盘.对于比特币手机钱包来说,存储完整的比特币账本是不现实的,因此便有了适用于运行在小型设备的轻量型节点.
全节点是一种存储完整账本、需要同步所有区块链数据、能够独立校验区块链上的所有交易并实时更新区块链的节点.轻节点是一种不需要存储完整账本,每当有新区块出现时,只需要下载区块头的节点类型.SPV 协议(simple payment verification protocol)[1]是最早的轻节点协议,该协议指出:不运行全节点也可验证支付,用户只需要保存所有的区块头即可,如图11 所示.SPV 轻节点只需从区块链网络中下载所有区块的区块头.SPV 轻节点由于自身并不存储区块链中区块的区块体,因此不能独立验证交易,需依赖于全节点.当需要验证支付时,向区块链网络发出请求,进而查找用于支付的那笔交易所在的区块,再根据Merkle 根哈希验证这笔交易是否有效.
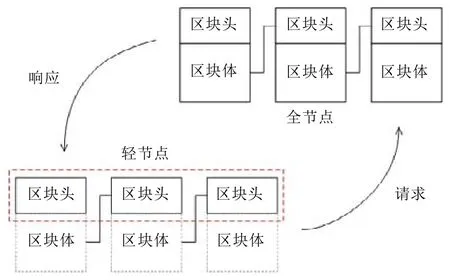
Fig.11 SPV scheme of light node图11 SPV 轻节点协议
第3.2 节所述的轻节点模式与第3.1 节所述的协作式存储模式的区别与联系可见表3.

Table 3 Difference and relation between light node mode and collaborative storage mode表3 轻节点模式与协作式存储模式的区别
3.2.2 改进型轻节点
SPV 轻节点需要存储每个区块的区块头,意味着节点的本地存储上限仍与区块链中区块的数量成正比例关系;另一方面,轻节点需要信赖全节点验证支付或交易,减弱了区块链无需信赖第三方的特质.因此,很多学者从不同的角度对传统的轻节点作了改进.
Xu 等学者[62]提出了一种公有链客户端协议,称为EPBC.这种客户端适用于物联网设备或手机等存储资源有限的设备.与SPV 协议不同,它不用存储所有区块的区块头,而只需存储一个大小定长的数据,并且与区块链账本的大小无关.EPBC 在每个区块的区块头中添加了一个对当前区块链的总结S,但无需参与挖矿的过程.S的生成过程与RSA 类似,需要选取两个质数p和q,生成N.在创世区块的区块头中,添加N和一个随机数g.当轻节点需要验证时,全节点生成一个元组返回给轻节点.轻节点只需验证和一个关于Sn的等式即可.当加入区块链时,轻节点从区块链网络中选取u个节点,并获取S(u).轻节点随机选取一些区块,并与这些节点交互以验证S(u)的有效性.最后选取由最多节点返回的S(u)作为区块链总结.
文献[63]提出了一种存储压缩协议SCC(storage compression consensus).SCC 是一种基于PBFT 的改进协议.当物联网节点申请加入区块链时,首先要通知自己的存储容量和存储上限系数,以便其他节点验证其存储能力.存储能力最小的节点可作为一轮SCC 中的领导者,因其执行压缩的过程表明,它忠诚地维护和紧跟区块链系统.在SCC 中,每轮除了需要处理正常生成的最新区块外,还需要通过Merkle 树的方法生成一个由区块链中所有区块组成的压缩块.压缩块中存储最新区块的hash,最新区块中存储压缩块的hash,如图12 所示.当这两个区块通过验证后,每个节点根据其自身情况进行存储.存储资源受限的轻节点存储最新区块和压缩块,并将之前的区块全部移除.每轮共识结束后,执行相同的过程.
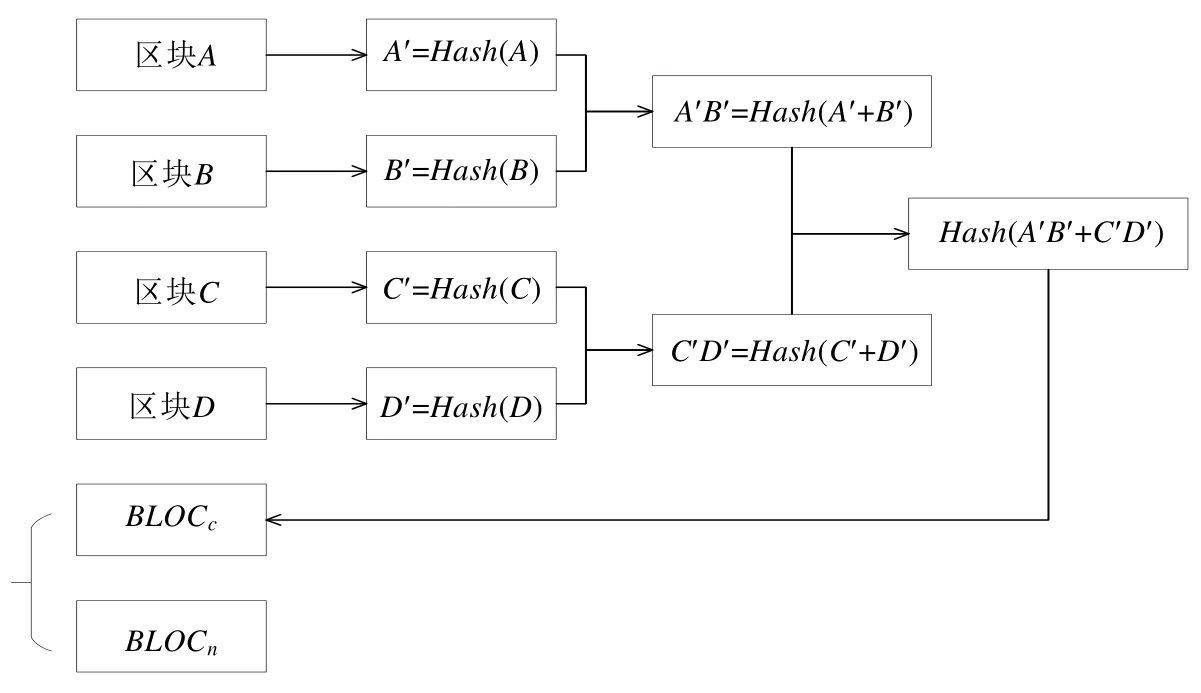
Fig.12 Compression block and next block图12 压缩块和最新区块
传统轻节点依赖于区块链网络中的全节点,同时,这也是轻节点的局限之一.Frey 团队[64]提出了一种模型,这种模型中的轻节点在验证交易时无需依赖于全节点.模型将节点分为5 类角色,分别是挖矿节点、全节点、安全轻节点、传统轻节点和DHT 节点.一个物理节点可以同时是多种角色.为了实现安全轻节点不存储完整账本的目的,区块结构进行了改进.在区块头中额外添加两个值,HUTxO和Hindex,如图13 所示.根据输出地址的前k位,将UTxO 集分割成2k个分片,对它们进行哈希运算,然后再对这些哈希值进行一次哈希,得到HUTxO.对由所有区块的hash 构成的数组进行哈希运算得到Hindex.区块链中的节点以及与区块链无关的节点共同组成DHT.DHT保存UTxO集的分片和最近h个完整区块.在安全轻节点加入区块链网络时,只需下载最近6个区块、UTxO分片哈希列表和区块哈希列表.当安全轻节点验证一笔新交易时,首先从DHT 中找到对应的UTxO 分片.若该UTxO 分片hash 与先前下载的hash 相同,则该交易是有效的.这种方式将原先依赖于全节点的数据转移至若干节点共同维护的DHT 中.对于存储资源充足的全节点,存储负担仅增加了一点点;但对于对于存储资源受限的轻节点来说,减轻了存储负担并不再依赖于全节点.
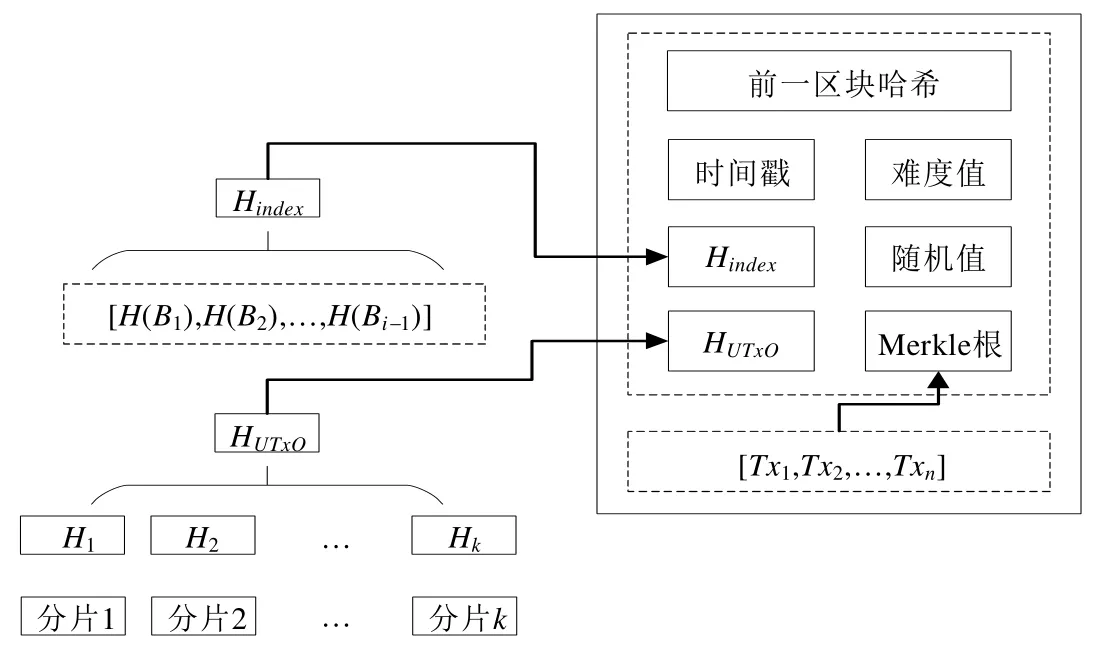
Fig.13 Block index hash and the UTxO hash are added to the block header图13 添加HUTxO 和Hindex 的区块结构
Palai 团队[65]提出一种称为区块总结的方法,该方法既可以获得比SPV 更多的权限,又不需要像全节点那样保存完整账本.区块总结方法将l个原始区块总结成一个新区块,称为总结区块.总结区块中交易的输入与其所包含的原始块中的交易输入一样,输入同理.如果一笔交易的输出是另外一笔交易的输出,那么将根据净效果合并这些交易.总结区块也会包括原始区块的哈希.直接总结区块同样会造成区块链账本大小问题.Palai 使用递归的方式对区块序列进行总结,即对总结区块进行总结.该方法引入了总结深度的概念,原始区块的总结深度为0,原始区块直接总结区块的总结深度为1,以此类推.一个区块长度为n的区块链经过区块递归总结后,将变成先是o个原始区块,再是m个总结深度为1 的总结区块,之后再是m个总结深度为2 的总结区块,以此类推.经过区块总结后的区块链如图14 所示.Nadiya[66]在Palai 团队研究的基础上,使用Deflate 压缩算法对总结区块进行数据压缩,进一步减小了区块链所占用的存储空间.
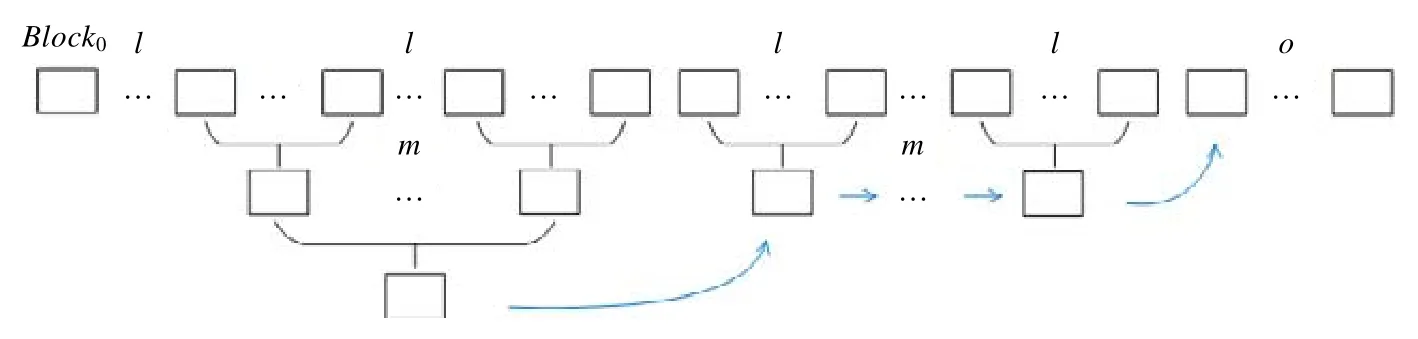
Fig.14 Block summarization图14 区块总结示意图
表4 从轻节点是否依赖全节点以及轻节点存储内容的角度,对比了6 种典型的轻节点协议或模型.根据是否依赖全节点,可将轻节点协议或模型分为两种:一种是依赖于全节点,另一种是不依赖于全节点.与比特币原始存储模型不同的是,SVP 轻节点只需要存储区块链账本中的区块头,因此,当需要区块体时,向全节点请求.同样地,EPBC 轻节点仅存储大小定长的区块总结值,当需要完整区块时,即请求全节点,并通过区块总结值判断全节点返回的区块是否有效.SCC 通过对最新区块前的区块链按照Merkle 树的方式进行压缩,以与完整的区块链账本保持一致性.当全节点不再有空余空间存储完整区块链账本时,可以简单地去除旧区块,仅存储压缩区块和最新区块.另一类不依赖于全节点的轻节点模型,对区块进行总结或者压缩,使这些原始区块合并或组合成一个新区块,新区块远小于原始区块集合的大小.对于使用UTxO 模型而不是余额模型的区块链来讲,一笔交易的输出有可能是另一笔交易的输入,净变化是没有区别的.所谓总结是指,将原始区块集合中交易集进行合并.但这种方式具有局限性,只适合区块体中仅保存金额、数字变化的场景.对于存证、溯源等区块体中存储非数字型数据的领域,区块总结的方式是无法使用的.
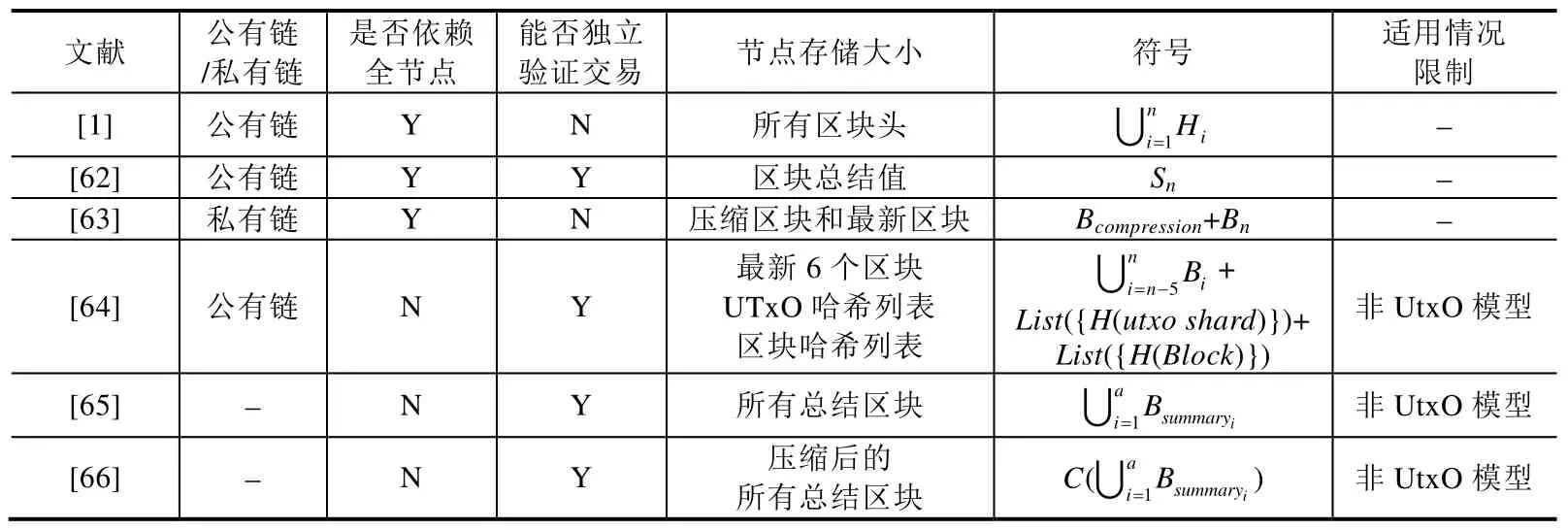
Table 4 Comparison of light node patterns表4 轻节点对比
4 总结与展望
本文从区块链账本存储位置的角度,综述了链下存储和链上存储两种用于提高存储可扩展性方法的研究进展.本节将指出两大类方法目前所面临的挑战,并为未来的研究工作提供一些可能的方向.
4.1 当前解决方案所面临的挑战
(1)应用场景
区块链可分为公有链和非公有链,后者包括联盟链和私有链.公有链是完全去中心化的,任何节点都可以随时加入或退出区块链网络.联盟链是一种部分去中心化的区块链,它由联盟或企业构成组织负责维护.而私有链则是一种中心化的区块链,适合特定的中心化机构控制.
在链下存储的模式中,数据转移至第三方可信赖的存储系统,或由公有链节点负责维护链下存储系统存储.后者易出现提供额外存储空间的超级节点,两者都会破坏公有链的去中心化特质.在非公有链场景下,节点的写入受中心化的机构或联盟控制,并且数据规模较小.此时,链下的存储系统可由负责非公有链的中心化机构或联盟以及非公有链的节点来维护.
链上存储更适合节点众多的公有链、联盟链场景.在协作式存储模式中,节点间的关系不是单向依赖的,而是相互依赖、相互合作.轻节点模式适合存储容量小的智能设备,如手机、PC 以及传感器等.许多学者也提出了不依赖于全节点的轻节点方案,一定程度上提高了轻节点的独立性和安全性,但轻节点仍无法实现全节点的所有功能.利用区块总结方式的轻节点可以节省大量空间,但同时在应用场景上也存在一定的局限性,这些轻节点仅适合于区块体存储货币转移的场景,而无法应用到存证、溯源等领域.
(2)安全性
区块链迄今为止面临的最大挑战便是安全问题,即便是完全去中心化的比特币,对于链下存储模式,如何确保链下的存储系统安全、可靠也仍是一个难点.一种解决方案是维护链下存储系统的都是区块链节点,另一种方案是维护链下存储系统的节点一部分是区块链节点一部分是非区块链节点.前者增加了区块链节点的负担,后者牺牲了公有链的去中心化特性.区块链与链下存储系统之间的通信安全同样需要考虑.
对于协作式存储,如何确保区域中即使存在恶意节点,但不会影响区域内节点的协作或区域间的协作,是设计协作式存储方案首先需要考虑的问题.协作式存储需要考虑一定的数据冗余以确保数据的安全.而轻节点与全节点的关系是轻节点安全性的根本,负责与轻节点通信的全节点如果是恶意节点,那么至少在一个时期内,该轻节点都被恶意节点所欺骗.因此,轻节点应该要么依赖尽可能多的全节点,要么应该依赖区块链整体网络.
无论是链下存储还是链上存储,原先完整的区块链账本都会被拆分.那么当节点需要完整账本时,从链下存储系统或其他节点处获取自身不存储的账本部分后,账本将会被整合.整合后的账本与区块链网络中所存储的账本必须保持完全一致.因此,必须考虑一定的冗余策略和补救策略以保证区块链的一致性在链下存储和链上存储不受影响.
(3)效率
在链下存储方式中,区块链仅需存储区块头和一些重要数据,而区块体或一些普通数据则存储在链下存储系统中.区块链存储负担明显减轻.在许多协作式存储中,节点所需的存储空间往往与区域内节点数量无关,因此与比特币存储模型所需空间近似呈线性关系.当区块不断地增加至区块链的尾端时,这些协作式存储方案慢慢地同样会遇到存储瓶颈.轻节点通常存储区块头或经过总结后的区块链账本.研究者需要考虑如何使得改进后的存储模型所需空间日后不会面临同样的存储问题.
链下存储和链上存储都在一定程度上增加了通信成本,即以时间换取空间.在链下存储模式中,节点需要花费额外的通信成本从链下的存储系统获取区块链数据.对于链上存储模式,当节点需要完整的区块链账本时,则要向区块链网络中的节点或区域内的节点请求自己没有存储的账本部分.因此,研究者们需要考虑区域的划分与时间成本和存储成本之间的关系.对于轻节点而言,当需要完整数据时,无法从本地找到对应区块,而需要请求区块链网络中的全节点或整个区块链网络.在解决存储扩展性问题的同时,需要考虑与通信成本之间的关系,从而做到在可承受范围内,增加一定的通信成本以获得较小的存储压力.
4.2 未来研究方向
第4.1 节提到了区块链存储可扩展性技术主要面临的一些问题,在这些问题的基础上,本文给出了几个未来的研究方向.
(1)研究可节省存储空间的共识机制
目前,大部分提高区块链存储可扩展性的解决方案都是对经过共识后产生的新区块进行处理,以达到减轻节点存储压力的目的.这些解决方案是从区块链基础架构模型的网络层进行改进,不涉及改变区块链的共识机制.未来可从区块链基础架构模型的共识层入手,研究可节省存储空间的共识机制;区块链节点在达成共识的过程中同时考虑如何协作存储区块数据,以解决区块链存储日益膨胀的问题.此外,在公有链场景中,存在经济激励手段鼓励节点参与共识.因此在可节省存储空间的共识机制中,需要在共识机制中添加合理的经济激励措施,奖励付出更多存储资源的节点.
(2)研究与初始节点数量相关联的动态区域划分方法
链上协作式存储模式通过将区块链网络划分成若干个区域,区域内的节点协作地维护区块链账本.目前的链上协作式存储模式中的区域划分方法可分为动态和静态两种方式.然而无论是动态划分还是静态划分,均与初始时节点数量无关.这就导致在区域划分前,区块链网络中的节点即使存在数量的差异,划分方法仍然相同,进而可能导致区域节点间的通信成本增加.未来可从区块链节点数量与通信成本和存储成本之间的关系来加以思考,建立相应的数学模型,实现访问本地和区域内其他节点的区块链数据所花费的时间之和最优,进而实现通信成本和存储成本的最优化.
(3)研究存储定长数据的轻节点模式
随着物联网技术的不断发展,未来物联网与区块链的整合非常重要.链上协作式存储模式会增加物联网节点间的相互依赖,因此,轻节点模式更适合物联网中的轻量级设备.按照当前主流的轻节点协议,这些轻节点所存储的数据大小与完整区块链账本大小之间大致呈线性关系.以这种存储方式,轻节点未来依然会遇到存储瓶颈.因此,研究存储定长数据的轻节点模型是一个值得研究的方向.
(4)研究不同存储模式下的安全机制
目前提高区块链可扩展性的两类解决方案——链下存储和链上存储,仍存在着一定的安全性问题,包括链下存储系统与区块链间的交互安全问题、链上协作式中区域内的恶意节点问题、轻节点与全节点间的信任问题以及区块拆分后重构时的安全问题等.属性加密、同态加密以及零知识证明等技术为提高链下存储和链上存储的安全性提供了方向.未来可研究基于属性加密、同态加密或零知识证明等技术的安全机制,进而提高链下存储及链上存储模式的整体安全性.
5 结束语
区块链存储的可扩展性已成为制约区块链应用落地的一大问题.巨大的存储压力,一方面使得已有的节点可能无法继续参与区块链;另一方面,使得存储能力差的轻型设备无法加入区块链网络.因此,研究提高区块链存储可扩展性的技术具有非常重要的意义.本文首先介绍了区块链所面临的存储可扩展性问题以及区块链的存储模型,其次分析了两大类提高存储可扩展性技术的研究进展,最后对提高存储可扩展性技术所面临的问题和研究方向给出了我们的思考和总结.
