农村居民健康差距中的机会不平等
——健康指标选择、模型构建与基于CHARLS的实证研究
2021-05-13胡宗义龚志民
刘 波 胡宗义 龚志民
1 引 言
健康是个人全面发展的前提,是经济社会发展的基础。2016年10月,《“健康中国2030”规划纲要》颁布,提出以农村和基层为重点,推动健康领域基本公共服务均等化,维护基本医疗卫生服务的公益性,逐步缩小城乡、地区、人群间基本健康服务和健康水平的差异,实现全民健康覆盖,促进社会公平。2018年9月,《乡村振兴战略规划(2018-2022年)》进一步明确了“健康乡村建设”,关注农村居民健康、缩小健康差距成为医疗卫生改革与“乡村振兴”的核心要务。2019年7月,《国务院关于实施健康中国行动的意见》提出了“到2030年健康公平基本实现”的愿景。从现实来看,无论是社会经济发展水平,还是医疗卫生资源的数量与质量,农村均落后于城镇。居民健康水平不仅在城乡之间存在巨大的鸿沟,在农村内部,居民之间的健康差距更为突出a按照《大逃亡:健康、财富以及不平等的起源》(Deaton,2013)的观点,死亡率是衡量居民健康水平的重要指标。根据“第六次人口普查”的数据,城镇居民死亡率为3.75‰,乡村居民死亡率为7.03‰;将31个省、市、自治区的分组数据按城、乡汇总,城镇组的死亡率取值范围与标准差为[0.0026, 0.0054]、0.67‰,乡村组的死亡率取值范围与标准差为[0.0053, 0.0096]、1.01‰。。因此,农村是推进健康中国建设的重点领域之一,提升农村居民健康水平、缩小农村居民之间的健康差距对于推进“健康乡村建设”,进而实现“健康公平”目标具有重要现实意义。
个人兼具生物属性与社会属性,健康原本是生物学事件,由于诸多社会因素掺杂到“生老病死”的过程中,从而把纯粹的生物学事件转变为复杂的社会事件(李红文、毛新志,2015[1])。社会因素会直接影响个体是否暴露于营养不良、压力过大、医疗匮乏、被感染等健康风险中,从而影响其是否免受疾病侵害(Solar和Irwin,2010[2];Phelan 等,2010[3];焦开山,2018[4])。因此,促进健康公平不能完全依靠对直接导致疾病的生物因素进行干预(CSDH,2009[5];WHO,2019[6])。居民之间的健康水平差异既受自然法则的影响,也受社会因素的左右,既有合乎正义法则的一面,也有悖于公平的一面。按照机会不平等的研究范式(Roemer,1993、1998、2016[7][8][9]),如果居民之间健康差距是由个人选择或偏好所致,则被认为是合理的差距;但如果健康差距是由个人无法事先选择的外生环境因素所致,则被认为是不合理的差距——健康机会不平等(Fleurbaey和Schokkaert,2009[10];Donni等,2014[11];Fajardo-Gonzalez,2016[12]),而缩小健康差距的首要任务则是缩小不合理的健康机会不平等。因此,如何缓解外部环境对农村居民健康的不利影响、缩小健康机会不平等,是逾越城乡之间的健康鸿沟、缩小农村居民健康差距的着力点。本文的目标在于将农村居民健康差距中的机会不平等分解出来,识别出引致健康机会不平等的主要因素,为“推进健康乡村建设”建言献策。
从已有文献的研究进展来看,在居民健康指标的选择上并未达成一致,在测度模型与分解方法上还存在改进的空间。在笔者的前期研究中,从总体上测度了中国居民健康差距中的机会不平等,本文是笔者前期研究的进一步拓展,边际贡献主要体现在三个方面:一是在健康指标的选择上,综合对比了自评健康、生物标记物、身体功能障碍测试与抑郁得分,从身、心健康两个维度验证了将自评健康作为健康指标的合理性;二是在测度方法上,在参数法的框架下,详细讨论了如何处理环境因素、身份变量与努力程度的相关性问题;三是在分解算法上,针对夏普利值分解算法中的维度灾难问题,本文给出了一种优化思路,显著缩短了夏普利值分解的耗时。
本文其余内容包括5个部分:首先,对健康机会不平等问题的研究进展进行回顾;其次,论证自评健康作为健康指标的合理性,改进测度模型,给出优化夏普利值分解算法的思路;第三,以CHARLS(2015)为样本,测度中国农村居民健康差距中的机会不平等,识别出导致健康机会不平等的主要因素;第四,调整健康决定方程的估计方法,进行稳健性检验;最后,总结研究结论,结合现实提出政策建议。
2 文献综述
健康机会不平等是本文的核心问题,主要涉及什么是健康机会不平等、如何测度健康机会不平等,以下综述将从此两方面展开。
Rawls认为健康是自然的产物,虽然受社会因素的影响,但并不受其控制,因而未将健康作为评价社会公正的核心变量和机会不平等的研究对象(Rawls,1971[13])。虽然健康作为机会平等的研究对象并不恰当,但与健康紧密相关的医疗保健却是恰当的研究对象(Daniels,1985[14];Ruger,2004[15])。随着研究的深入,健康机会不平等的内涵逐渐明确,“健康(及其关键的社会决定因素)不存在与社会优势/劣势(财富、权力或声望)有系统联系的差异,健康不平等系统地使已经处于社会不利地位的人口(如贫困人口、女性、种族、少数族裔、宗教群体)在健康方面处于更不利的地位”(Braveman和Gruskin,2003[16]),据此观点,财富、权力、身份导致的健康差距是不合理的差距。在健康机会不平等的量化研究中,已有文献仍然延续Roemer的“环境-努力”分析框架,其前提假设是居民健康由环境因素和努力因素决定。环境因素泛指无法首先选择的外生因素,努力因素为生活习惯、健康素养等因素(Roemer,1993、1998、2016[7][8][9]),并将环境因素差异导致的健康差距界定为健康机会不平等,将努力因素差异导致的健康差距界定为合理的差距(Rosa Dias,2009[10];Fleurbaey 和 Schokkaert,2009[11];Jusot等,2013[12];Donni等,2014[17];Fajardo-Gonzalez,2016[18])。
测度机会不平等的方法主要有参数法、非参数法两种,而测度健康机会不平等主要采用参数法(Ferreira 和 Gignoux,2011[19];Björklund 等,2012[20];Carrieri和Jones,2018[21])。在参数法的具体应用中有两个核心问题:一是如何构建健康决定方程;二是如何将每个因素对健康差距的贡献度分解出来,从而获取健康机会不平等对健康差距的相对贡献度。
在构建健康决定方程时,首先需要确定健康指标。在已有文献中,通常将自评健康(Self-Report Health)作为量化居民健康状况的健康指标。随着研究的深入,有文献开始质疑自评健康是否能够客观准确地衡量居民的健康状况。如果个人对自身的健康水平预期较高,那么对自身健康水平的评价也将不同(孙祺等,2003[22];Bagod’Uva等,2008[23]),并且自评健康在个人之间与国家之间不具备横向可比性(Carrieri和 Jones,2017[21];Johnston et al.,2009[24])。因此,有越来越多的学者开始将更为客观的生物标记物指标应用到实证研究中。例如,在研究收入与健康的关联性时,诸多学者将自评健康替换成生物标记物指标(Carrieri和Jones,2017[21];Banks 等,2006[25];Davillas 等,2017a[26];Davillas 等,2017b[27]),而血检指标是最为常用的生物标记物指标。由于生物标记物指标包括多个检测指标,因而需要对其进行降维(Cohen等,2014、2015[28][29]),将多维度指标转化为单一维度的健康代理变量(Li等, 2015[30];Brasher等,2017[31])。健康不仅包括身体健康,还包括心理健康,除了利用生物标记物指标反映身体健康之外,还需要通过抑郁指标反映心理健康(焦开山,2014[32])。除此之外,身体健康与否还可以通过预期寿命来测量(Chetty等,2016[4];焦开山,2018[33])。
其次,需要确定健康的影响因素。在选择健康的决定因素时,社会环境与政策调整是重点关注领域,两者首先会因人而异地影响健康风险(Diderichsen等,2012[34]),相比于社会地位低的群体,处于较高社会地位高的群体,其健康风险水平相对较低,其患病风险也相对较低。CSDH对健康的社会决定因素进行了全面讨论(CSDH,2009[5]),社会决定因素对健康的影响路径具体如图1所示(Solar和Irwin,2010[2])。健康不平等的社会决定因素包括结构性决定因素和中介因素两个层次,结构性决定因素对健康的影响会因社会经济地位、社会阶层、性别和种族的异质性而有所不同,具体的传导中介包括三个方面:物质环境(Material circumstances)、社会心理环境(Psychosocial circumstances)、行为和生物因素(Behavioral and Biological Factors)。在物质环境方面,良好的工作环境和生活环境使其遭受健康伤害的可能性较低(Evans和Kantrowitz,2002[35])。在社会心理环境方面,不同社会经济地位群体面临的心理、社会压力不同,较低社会经济地位群体面临着更大的心理压力、更强的社会剥夺感以及缺少控制感,而这些因素与诸多健康问题密切相关(Wilkinson,2005[36])。在行为和生物因素方面,社会经济地位通过多种风险行为(包括吸烟、酗酒、久坐、疾病预防)影响患病风险(Phelan等,2010[3];王甫勤,2017[37]),长寿也与某类基因相关(Zeng 等,2010[38])。
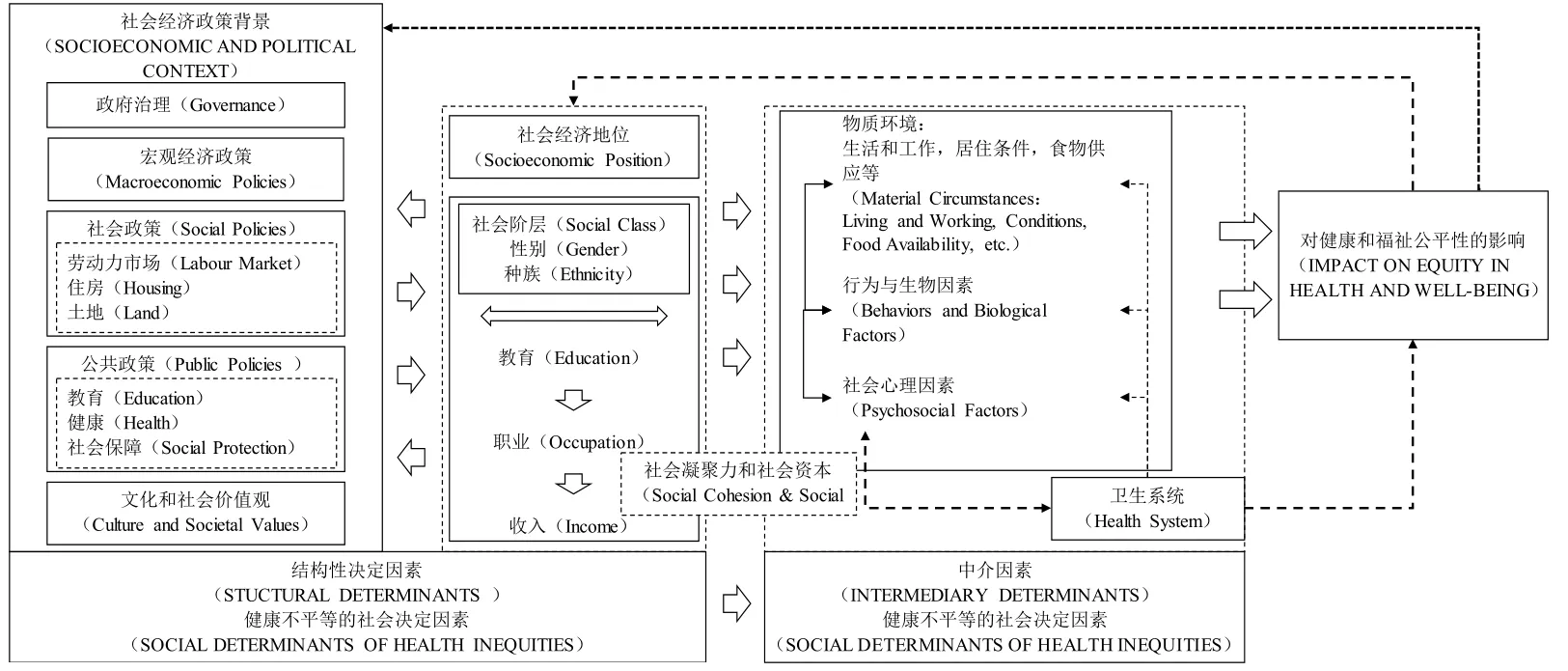
图1 健康的社会决定因素
第三,确定健康决定方程的类型。已有文献多以自评健康作为测度对象(Fajardo-Gonzalez,2016[12];Donni等,2014[11];Rosa Dias,2009[17];O’Donnell等,2015[39];Gallardo等,2017[40]),而自评健康是有序(Ordered)变量,对于有序变量通常采用Ordered Probit/Logit模型。基于有序变量模型仅能得到自评健康水平等于某个层级的概率预测值,而不能得到自评健康的预测值,故不能沿用原有的参数法,继而又发展出三种不同的处理方法。第一种方法为“OLS+基于回归方程的不平等指标分解”(Jones和 Nicolás,2006[41];Carrieri和 Jones,2018[42]),由于变量系数估计值的正负取值和显著性在Ordered Probit/Logit模型的极大似然估计和OLS估计中存在一致性(Ferrer-i-Carbonell & Frijters,2004[43]),因而有文献采用OLS方法估计Ordered Probit/Logit模型(Knight等,2009[44])。在此测度方法中,直接采用OLS方法估计健康决定方程,然后采用基于回归方程的分解方法(如夏普利值分解、Fields分解)测度健康机会不平等。第二种方法为“极大似然估计+基于潜变量的Fields分解”(Jusot等,2013[18]),首先采用极大似然方法估计健康决定方程,然后估计被解释变量(自评健康变量)的潜变量,再结合Fields分解方法分解出健康机会不平等对健康差距的贡献值。第三种方法为“Probit/Logit模型 + 夏普利值分解”(Fajardo-Gonzalez,2016[12];Juárez和 Soloaga,2014[45]),首先将有序变量转化为0-1变量,采用极大似然方法估计Probit/Logit模型,再以概率值估计值为基础,通过夏普利值分解测度健康机会不平等。
最后,在健康决定方程的估计中,需要处理环境因素与努力因素的相关性,以及确定随机扰动项的归属。按照Barry的观点,忽略父母给予的原生环境对子代努力程度的影响,直接将环境与努力变量纳入方程(Barry,2005[46])。而Roemer认为,努力中包含了环境的影响,因而需要将努力中的环境因素剔除(Roemer,1995、1998、2016[7][8][9])。按照 Swift的观点,努力会左右环境,因而需要将环境中的努力因素剔除(Swift,2005[47])。在实证研究中,通过辅助方程将努力中的环境因素剔除是较为常用的处理方式(Fajardo-Gonzalez,2016[12];刘波等,2020[48])。随机扰动项的归属会直接影响测度结果,文献中甚至存在刻意回避常数项和残差项的现象(Wan,2004[49])。在已有文献中,在如何确定随机扰动项的归属上并未达成一致,以Roemer为代表的研究者将残差项归类为努力程度,也有学者将其归类为环境因素(Devooght,2008[50]),或者认为残差项的含义无法明确界定,可将之忽略(Lefranc等,2009[51])。
目前,直接以农村居民的健康机会不平等为主题的文献相对较少,散见于各类主题的研究中。健康在城乡之间的差距是实证研究关注的重点(赵广川,2017;鲁万波等,2018)[52][53],我国中老年人整体健康水平存在显著的城乡差异,健身场所、服务类组织、工业污染源距离和厕所类型是形成健康机会不平等的主要因素,除此之外,收入水平、居住方式与生活能源也是文献关注的影响因素(陈东、张郁杨,2015[54];陈光燕、司伟,2019[55];方黎明、刘贺邦,2019[56])。医疗保障水平在城乡之间存在显著差距,医疗保险对农村居民健康的影响一直是文献关注的重点,“新农合”是近期文献关注的重点(程令国、张晔,2012[57])。新农合有利于减轻医疗负担,有助于改善农村居民身体健康与心理健康(黄晓宁、李勇,2016[58];郑适等,2017[59];赵为民,2020[60]),但却难以发挥全面增进农村居民健康的作用(章丹等,2019[61])。
综上,本文认为关于健康机会不平等的研究还可以从以下方面进行拓展。首先,在健康指标的选择上,已有实证研究多以自评健康作为健康指标,有诸多学者对自评健康能否作为量化居民健康水平的指标提出质疑(Bagod’Uva等,2008[23];Johnston等,2009[24];Carrieri和Jones,2017[42])。本文认为,健康并非单一维度的身体健康,还包括心理健康,因而本文将对自评健康能否真实地反映居民的身心健康进行讨论。其次,在方法层面,夏普利值分解是不平等指标分解中最为常用的方法,但在具体运用中存在维度灾难问题,维度灾难限制了高维度解释变量在实证研究中的使用,因此本文给出了一种优化算法的思路。第三,在研究对象方面,以中国居民健康机会不平等为研究对象的文献有待进一步丰富,鲜有文献讨论中国农村居民的健康机会不平等问题,本文的量化研究能够估计出健康机会不平等对健康差距贡献度,能够为实施“健康中国战略”、“推进健康乡村建设”提供理论参考。
3 研究设计
3.1 健康指标的比较与选择
在实证研究中,自评健康是最为常用的健康指标,自评健康能够较好地反映受访人的健康水平(Hayes等,1995[62]),通常来自于SF-36量表(Short Form 36 health Survey Questionnaire)。然而,有文献质疑自评健康的主观性,在量化收入与健康相关性的研究中,采用更具客观性的生物标记物指标。生物标记物指标包括多个检测指标,因而需要对其进行降维,基于马氏距离(Mahalanobis Distance,DM(x))的降维方法是较为常用的方法(Cohen 等,2014、2015[28][29];Li等,2015[30];Brasher等,2017[31]),具体如式(1)所示。
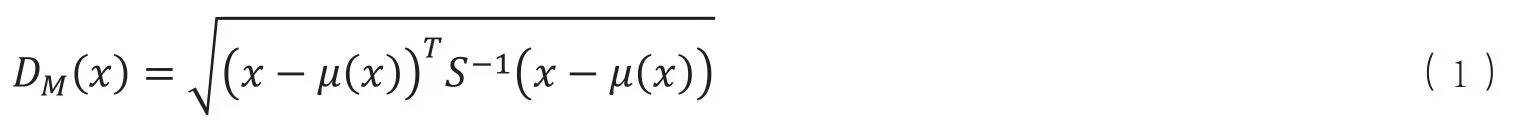
其中,x为生物标记物指标向量,μ(x)为其均值向量,S为生物标记物指标的协方差矩阵。在本文的实证研究中,以CHARLS(2015)农村居民(农村户口)的血检数据、血压与体重指数为样本,指标及其描述性统计结果如表1所示。
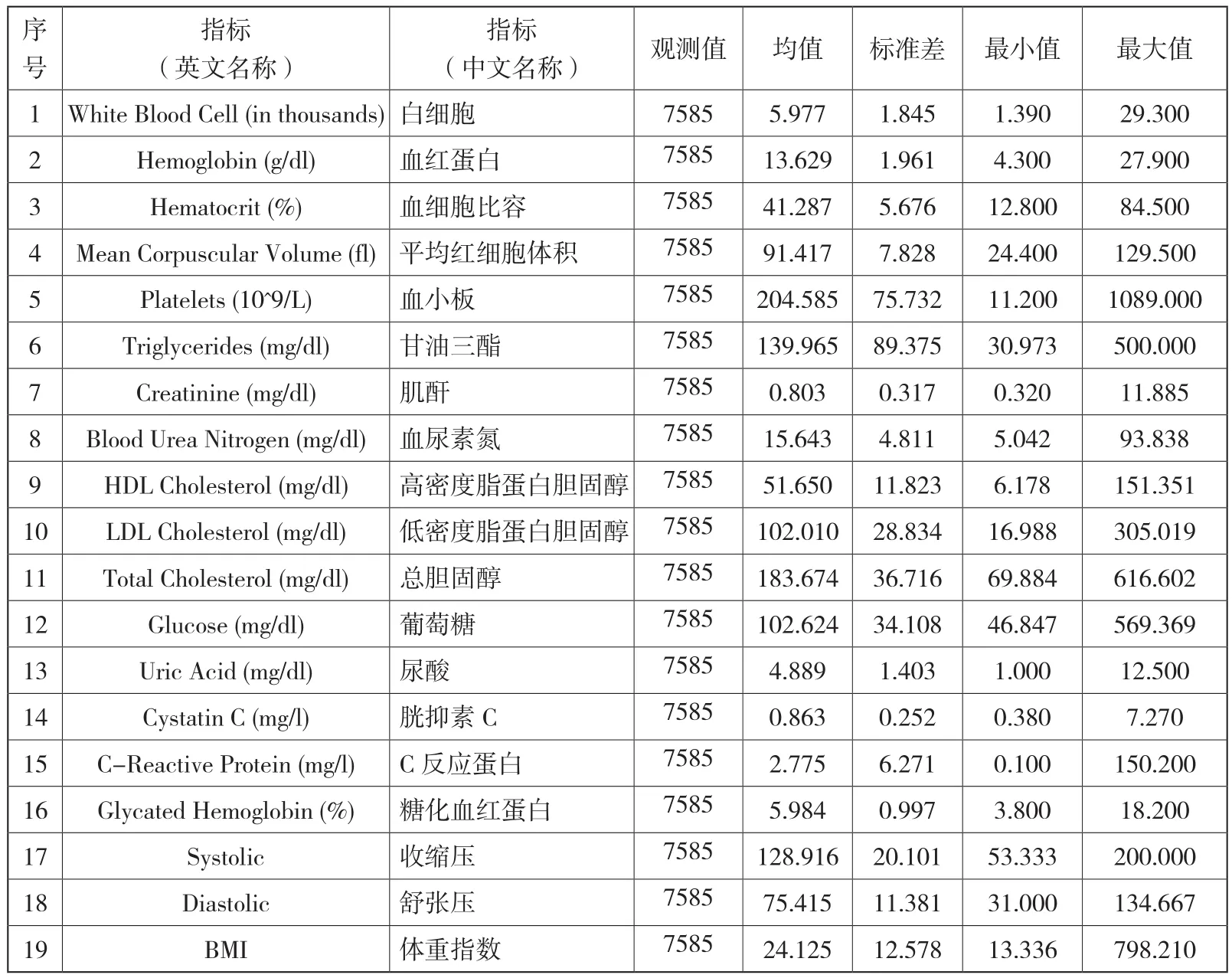
表1 血检数据指标、血压与体重指数
通常而言,判断某项血检指标是否正常需要依据阈值,本文除了通过马氏距离将血检数据综合为单一维度的连续指标之外,还将依据各项血检指标的阈值将其转化为0-1变量,再将转化后的指标求和,从而得到受访人的健康风险水平。如果受访人的各项血检指标不在正常范围内的数量越多,则意味着受访人的健康状况越差,各项指标的取值方式以及描述性统计结果如表2所示,分类统计结果如图2所示。由图2可知,自评健康与马氏距离(DM)、健康风险指标亦呈正相关关系。由此可见,虽然自评健康的主观性较强,但与基于客观的血检指标得到的健康风险具有一致性。
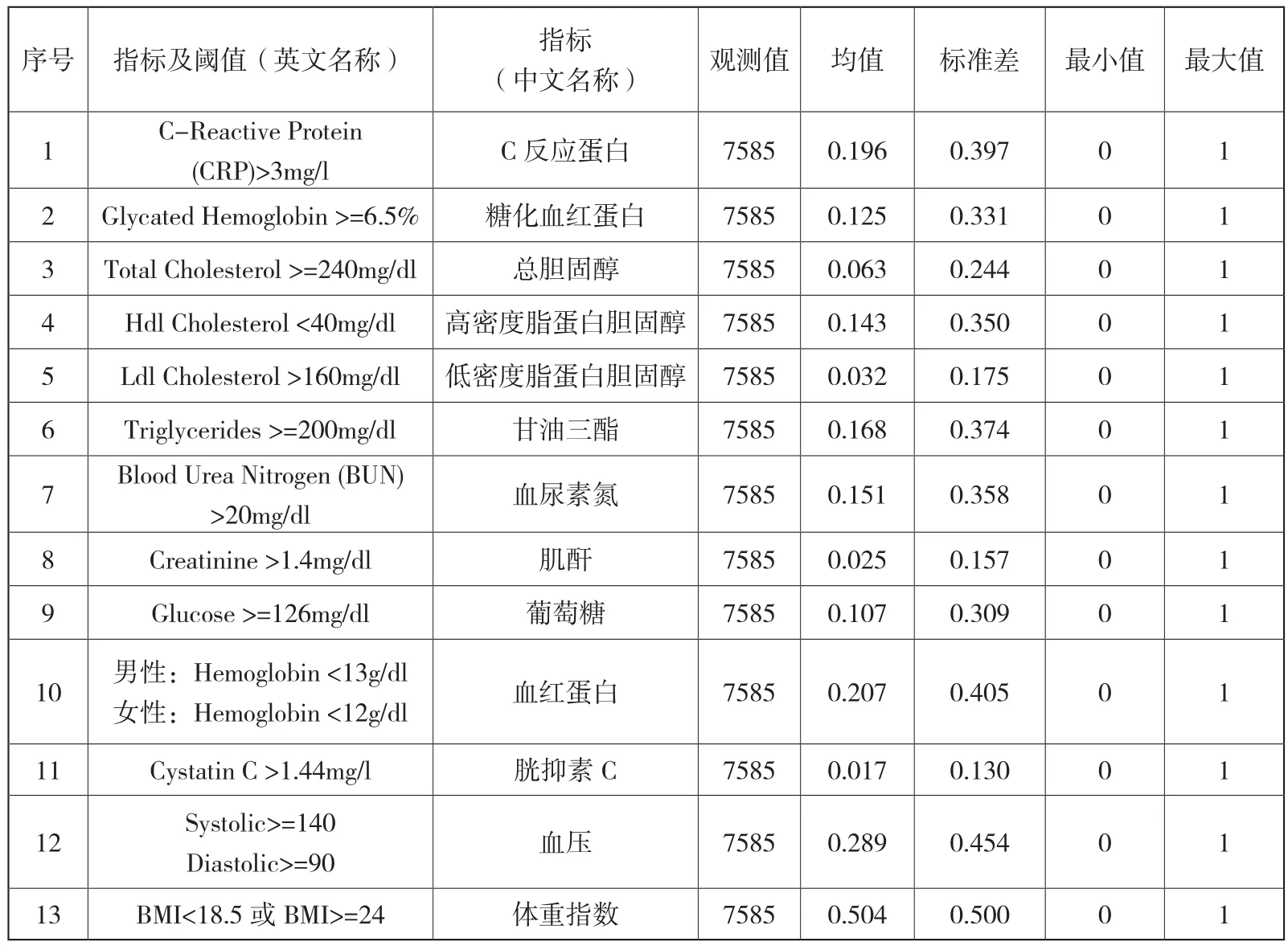
表2 血检指标的阈值及描述性统计结果
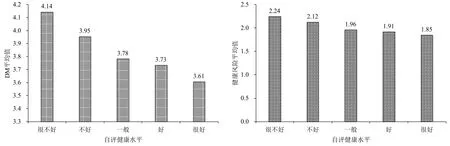
图2 DM、健康风险与自评健康
除了血检指标之外,身体功能障碍测试也可以较为客观地反映受访者的健康状况,身体功能障碍测试包含19个问题,每个问题的选项均为:“1.没有困难;2.有困难但仍可以完成;3.有困难,需要帮助;4.无法完成”,按自评健康等级分类求均值,如表3所示。从总体来看,除个别项目外,其他项目的自评健康为“好”、“很好”的平均值低于“不好”、“很不好”的平均值。可见,自评健康也能够反映出身体功能障碍测试的结果。
更为重要的是,健康不只包括身体健康,还应包含心理健康,基于血检数据得到的DM与健康风险指标,并不能反映受访人的心理健康程度。在CHARLS(2015)中关于心理健康的调查共有10问题,每个问题的赋值方式为“1.很少或者根本没有(<1天),2.不太多(1-2天),3.有时或者说有一半的时间(3-4天),4.大多数的时间(5-7天)”。按心理学问卷的处理方式,可将10个问题的分值加总得到抑郁得分,表4中给出了心理调查数据按自评健康的分类统计结果。从总体来看,自评健康为“好”、“很好”的抑郁得分平均值低于“不好”、“很不好”的平均值,具体的10项调查数据分布亦是如此。由此可见,自评健康也能够反映出受访人的心理健康水平。综上所述,自评健康不仅能够反映受访人身体上的健康状况,还能够反映出受访人的心理健康水平。因此,将自评健康水平作为量化健康的指标具有较强的合理性。
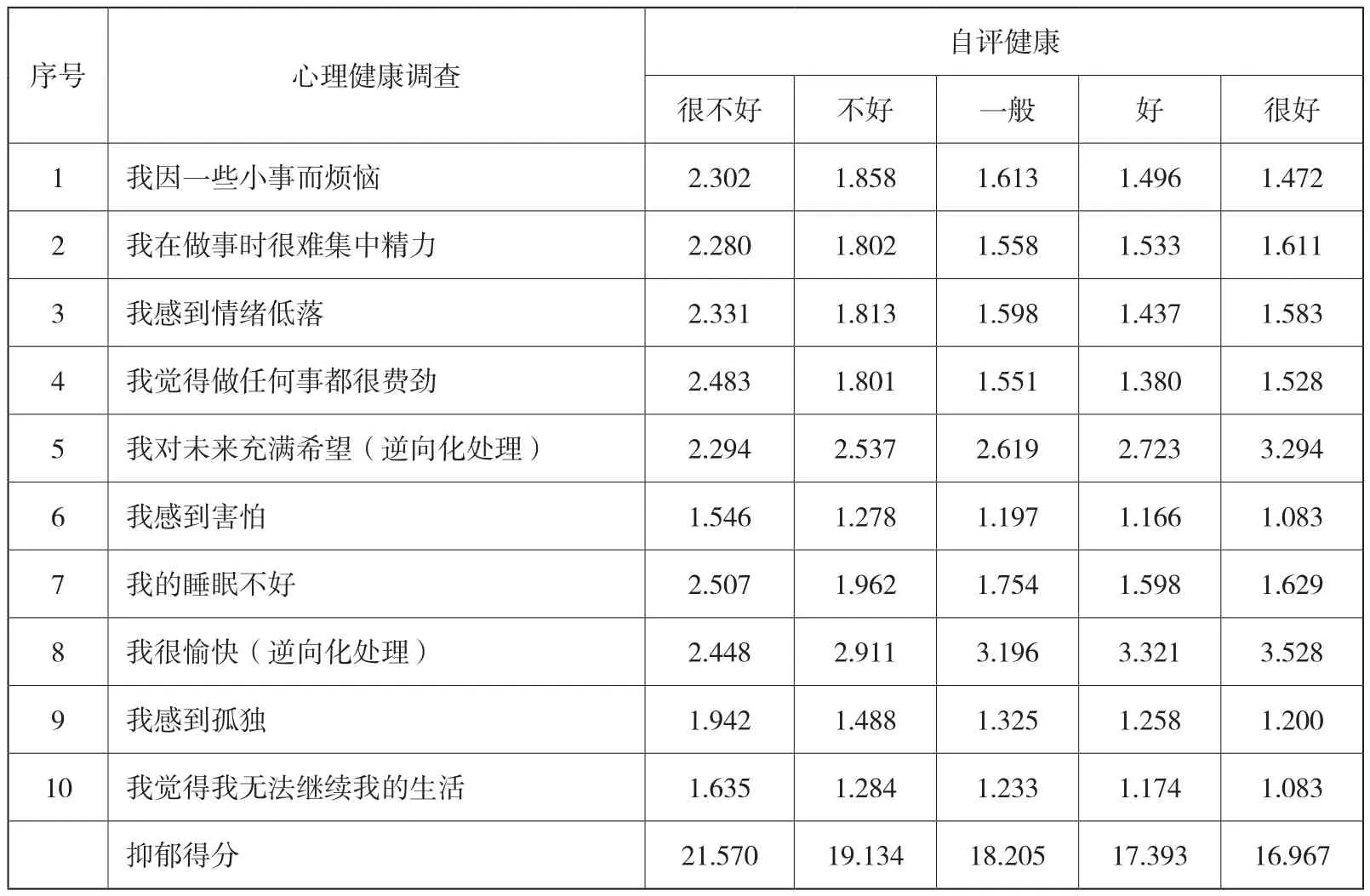
表4 抑郁得分与自评健康
3.2 健康机会不平等的测度模型
本文认为,机会不平等的测度需实现两个目标:一是测度机会不平等对总的不平等(差距)的相对贡献度;二是对机会不平等进行分解,识别出导致机会不平等的主要因素。以此为导向,在现有两种测度方案的基础上,构建测度模型。
(1)测度模型的构建
在近期的文献中,“极大似然估计+基于潜变量的Fields分解”、“Probit/Logit模型 + 夏普利值分解”(Fajardo-Gonzalez,2016[12];Jusot等,2013[18];Juárez和Soloaga,2014[45])是最具有代表性的两种测度方案。第一种方案给出了三种处理环境与努力相关性的方法,虽然采用Ordered Probit/Logit模型构建健康决定方程,却以潜变量的估计值为基础,采用Fields分解方法估计健康机会不平等对健康差距的相对贡献度。且没有进一步分解出每个解释变量对健康机会不平等的相对贡献值,即没有实现第二个研究目标。第二种方案比较契合测度机会不平等的两个目标,但该方案在变量选择上存在较为突出的局限性。没有将努力因素、家庭的经济社会地位或者生活水平、年龄作为健康决定方程的解释变量,努力因素是构建健康决定方程不可或缺的因素,居民健康与其社会地位或者生活水平存在的高度相关性,年龄是影响健康的关键变量。如果遗漏了三者,必然会影响估计结果的一致性,从而会影响测度结果的准确性。更为重要的是,健康公平不仅包括横向公平,还有纵向公平,而年龄增加导致的健康水平下滑是反映纵向公平最为直观的范例。
本文仍然采用参数法测度健康机会不平等,将第一种方案的变量选择方式与第二种方案的分解方法相结合,并在以下三个方面进行改进:
首先,对环境因素和努力因素的范畴进行延伸。遵循“环境-努力”二元框架的假设,假定居民健康是由个人所处的环境与所付出的努力决定,在健康经济学语境下,环境不局限于个人所处的原生家庭环境、当前所处的生活环境与社区环境,而是指代影响个人健康的所有外生因素。外生因素不仅包括环境变量,还包括身份变量等外生指标。努力因素包含两个维度:生活习惯与健康素养,已有文献中通常将抽烟、酗酒等生活习惯作为努力程度的代理变量,诸多文献表明,健康素养与个人健康密切相关(DeWalt等,2004[63];Berkman等,2011[64];Al Sayah等,2013[65]),因而本文认为有必要将健康素养作为努力因素的一个维度。
其次,不局限于使用一种方式构建辅助方程。从现实来看,环境因素与努力因素并不是相互独立的(Roemer,1995、1998、2016[7][8][9];Jusot等,2013[18];Barry,2005[46])。首先,环境因素是决定努力程度的重要因素。吸烟、酗酒的行为会在代际之间传递(Orford和 Velleman,1991[66];Melchior等,2010[67];Schmidt和 Tauchmann,2011[68];Eriksson 等,2014[69]),如果父母抽烟、酗酒,子女吸烟、酗酒的可能性也会增加,原生家庭环境是塑成个人生活习惯的重要因素。自然环境与饮食习惯密切相关,“南人喜米、北人好面”、“靠山吃山、靠水吃水”,自然环境是决定饮食习惯的主要因素。其次,努力程度是影响个人在中、老年时期所处社区环境、生活条件的重要因素。个人所处的环境并不是一成不变的,原生家庭环境会左右个人的努力程度,努力程度会使个人不同程度地脱离原生环境。例如,健康与收入的相关性是健康不平等研究关注的重点,家庭的生活水平或者社会地位是影响个人健康的重要因素,文献中将之总结为“地位综合症”。然而,家庭的生活水平或者社会地位不仅受外生因素的影响,还受个人努力程度的影响。显然,如果环境变量不完全外生,且努力程度并不完全由个人主观决定,则不能只遵循某一种方式处理环境与努力之间的相关性。
第三,剥离环境、努力与随机扰动项的相关性。在Ordered Probit/Logit模型中不能得到与线性回归方程相同的随机扰动项,随机扰动项也不能参与到夏普利值分解中,故在分解过程中将其忽略(Lefranc等,2009[51])。如果随机扰动项严格满足随机性,不将其纳入分解过程中是合理的,但如果随机扰动项与环境、努力存在相关性,将其忽略显然是不合理的。图3中直观地给出了环境、努力、残差项三者的关联关系,假设环境、努力与残差项不相关是比较严苛的。在构建健康决定方程时,无法穷尽所有影响个人健康的变量,而且并不是所有的变量都是可观测、可量化的。与此同时,微观调查数据提供的变量也是有限的,因而所构建的健康决定方程会遗漏某些变量,从而导致模型可能存在异方差问题,而异方差通常表现为解释变量与残差项存在相关性。不同个体对自身的健康预期是不同,那么对自身健康水平的评价也有所不同(Bagod’Uva等,2008[23]),原生家庭环境、生活水平、受教育水平、生活习惯、年龄与性别都可能会影响对自身健康水平的评价,观测误差可能随着环境因素、努力因素的变化而不同。如果模型存在异方差问题,参数估计量不再具备渐进有效性,最终影响测度结果的准确性。由于自评健康是有序变量,在考虑异方差的条件下,需要采用异方差选择模型(Heterogeneous Choice Models)估计健康决定方程(Williams,2016[70]),可将原生家庭环境、生活条件、受教育水平、生活习惯、年龄与性别作为估计方差的变量。
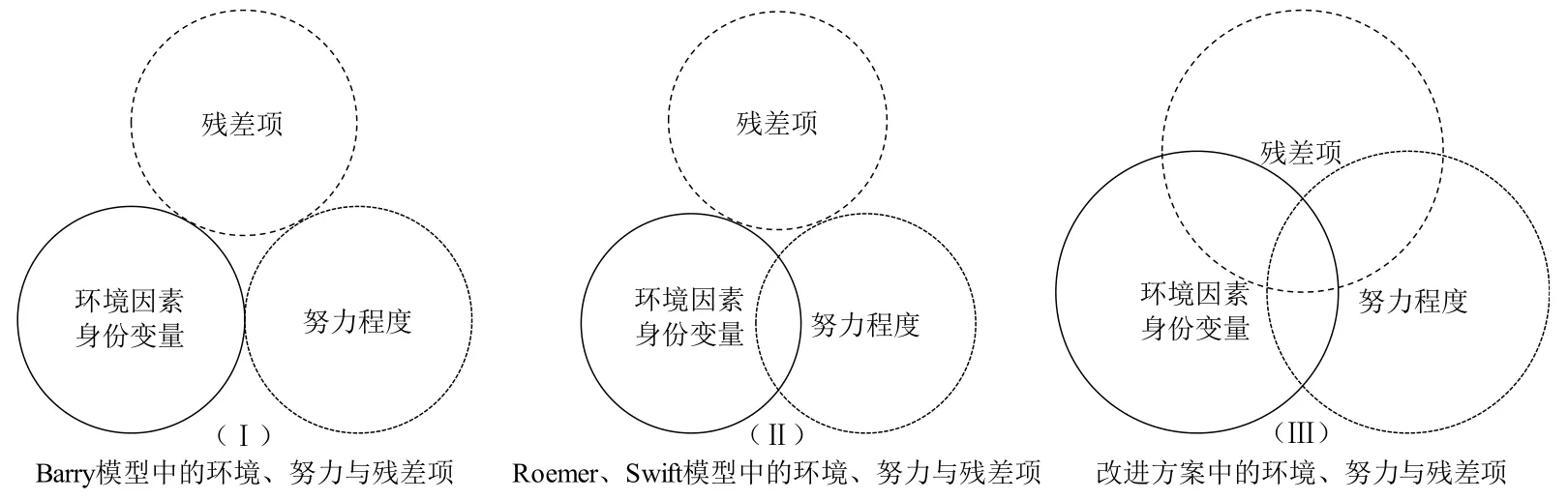
图3 健康机会不平等测度模型中环境、努力与残差项的关系
按照参数法的流程,首先是构建健康决定方程,在“环境-努力”的框架下,健康(Hi)是由环境变量(Ci')、努力程度(Ei)与不可观测的随机因素(ξi)决定,如式(2)所示。

自评健康(Hi)为有序变量,如在CHARLS数据库中,自评健康的取值方式为“5极好、4很好、3好、2一般、1不好”。在中文的语境下,将环境变量称为条件变量更为恰当,条件变量不仅包括完全外生的原生家庭环境(C1i)、生活条件(C2i)、社区环境(C3i),还包括外生的身份变量(Di),即,即。虽然身份变量是外生的,但并非所有身份变量导致的健康差距都是不合理的,比如年龄。因此,本文将年龄(Ai)中身份变量中单列出来,将剩余的身份变量命名为。由此可将式(2)改写为:

由于环境变量与努力变量存在相关性,进一步通过辅助方程对变量进行调整。为了获取环境因素对健康差距影响的上限值,故按照Roemer的方式构建努力方程,如式(4)-(5)所示。
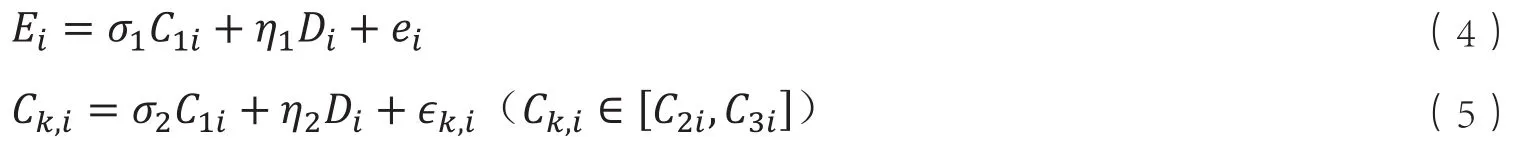
其中,ei与ϵk,i为残差项,Ck,i为生活条件与社区环境变量中受原生家庭环境、身份变量影响的变量,如家庭的生活水平。由于环境变量与努力变量通常为有序变量或者0-1变量,不能获取一般意义上的残差项,但可以获取辅助方程的广义残差项êi、ϵ̂k,i(Gourieroux 等,1987[71])。通过辅助方程将Ei、Ck,i中的外生因素剥离之后,剩下的残差项可以视作纯粹的努力程度变量,将两者带入式(3)中可得:

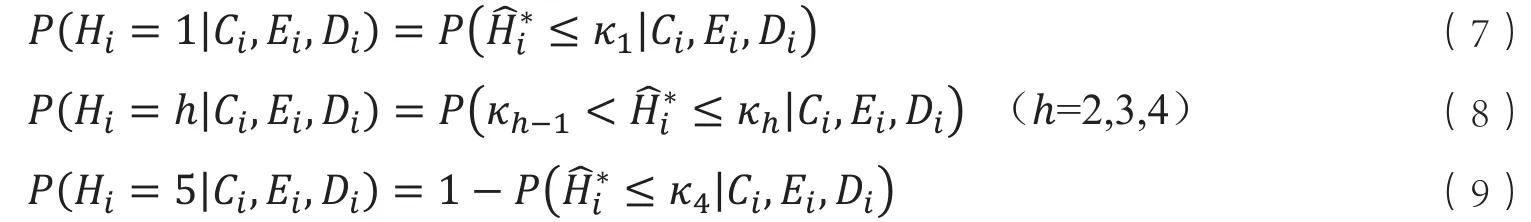
由式(7)-(9)可得P(Hi>h)、P(Hi≤h)(h=1,2,3,4)的概率值:
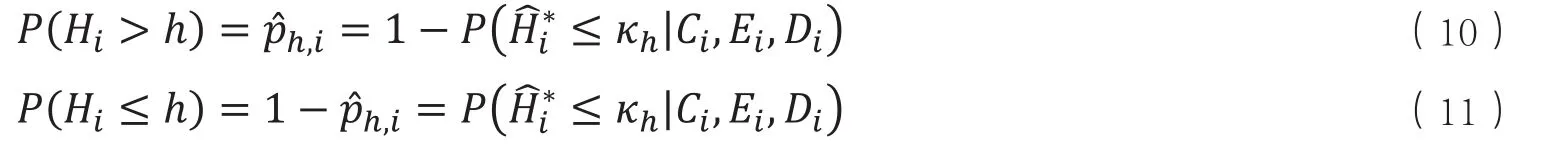
在Ordered Probit模型中,假定随机扰动项(ξi)服从标准正态分布,而在Ordered Logit模型中,假设随机扰动项(ξi)服从Logistic分布,相应的概率值如式(12)-(13)所示:
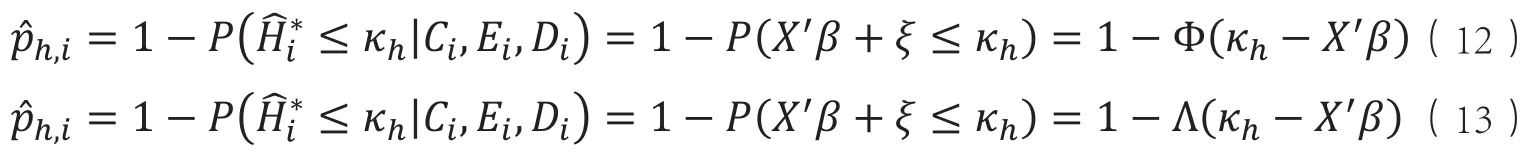

(2)夏普利值分解的算法优化
在现有方法中,夏普利值(Shapley Value)分解方法的应用最为广泛(Shorrocks,2013[72])。按照夏普利值分解的流程,首先需给出健康决定方程与解释变量。按照本文的设定,夏普利值分解的对象为为不平等指标。为了便于表达,假定,变量集共包含个变量,按照夏普利值分解的原理,本文提出一种更为简化的分解算法,主要包括三个步骤:
首先,在变量集Xi中选定一个变量,以第一个变量为例,以剩下的N-1个变量组成变量集X',再以X'为基础,生成子变量集Zi(i=1,,K),K的取值如式(15)所示。

其次,将Zi中所有的变量以其均值替代得到,从而可得第一个变量差异引致的健康差距:
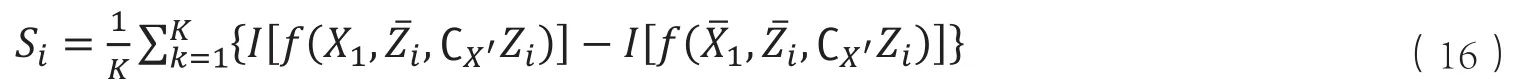
其中,CX'Zi为子集Zi在全集X'中的余集。依次类推,最终可得N个变量对健康差距的绝对值(S1,…,SN)。最后,以绝对贡献值为基础,可得每个变量对健康差距的相对贡献值:
按照本文提出的简化算法,可以有效降低夏普利值的分解时间,运算效率显著提升。
4 实证研究
4.1 变量的选择与赋值
在实证研究中,本文的样本数据为CHARLS(2015),由于本文的测度对象为农村居民,因而选取户口为农业户口的受访人为研究对象。变量的定义与赋值方式如表5所示,变量分为原生家庭背景、生活条件、社区环境、努力程度、身份变量5类,共计21个变量。其中,家庭背景变量包括父母受教育程度、17岁之前的家庭经济状况、童年时期父亲与母亲是否抽烟、童年时期父亲是否酗酒;生活条件包括家里是否有厕所、是否有自来水、做饭用的主要燃料、当前的家庭生活水平;社区环境包括居住地所在经济区域、城市类型、是否有公交车、居住地是否有工业污染、是否有下水道系统、垃圾处理方式;努力变量包括剥离环境因素后的生活水平、受教育程度、是否抽烟、是否喝酒;身份变量包括年龄、性别、民族。
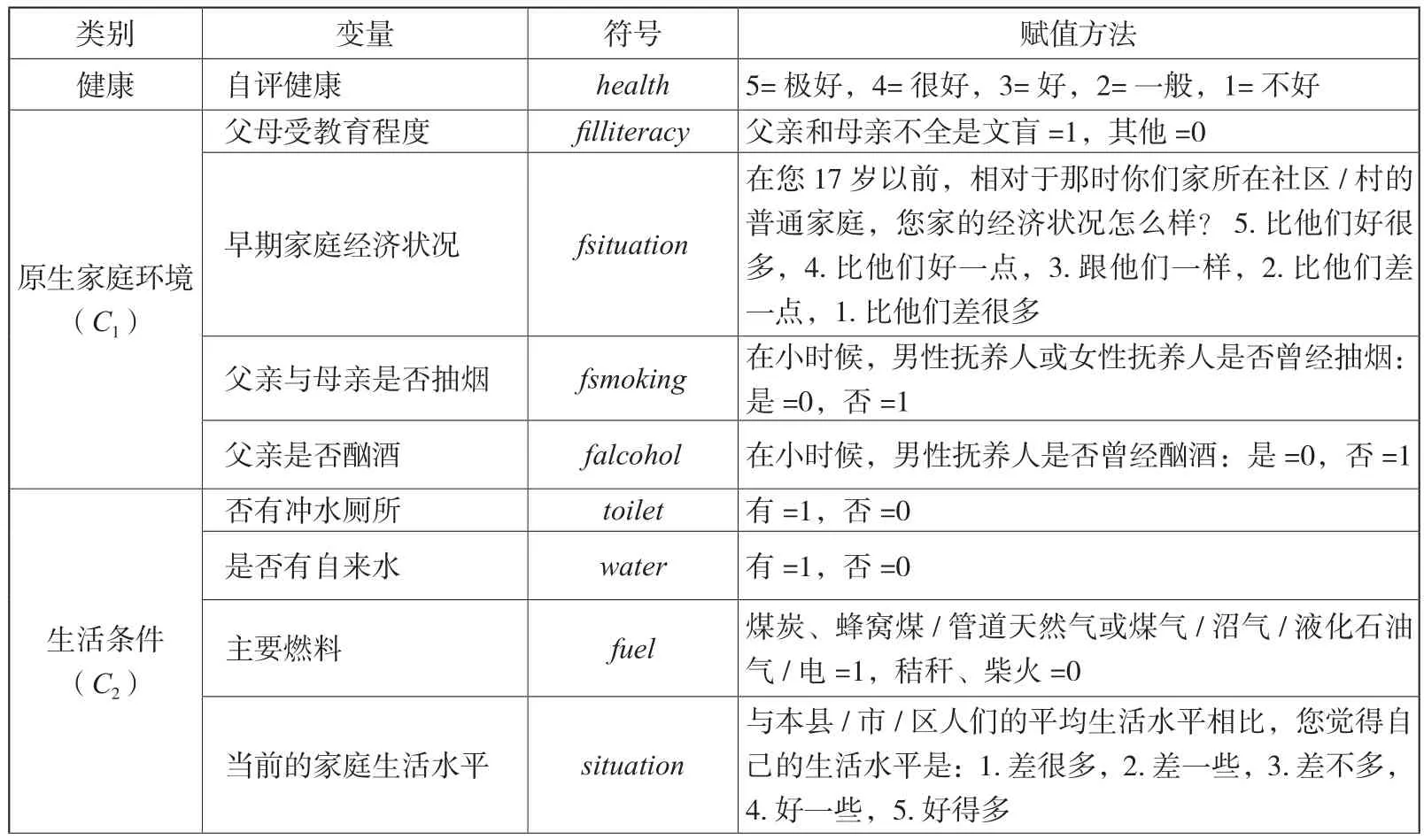
表5 变量的选择与赋值
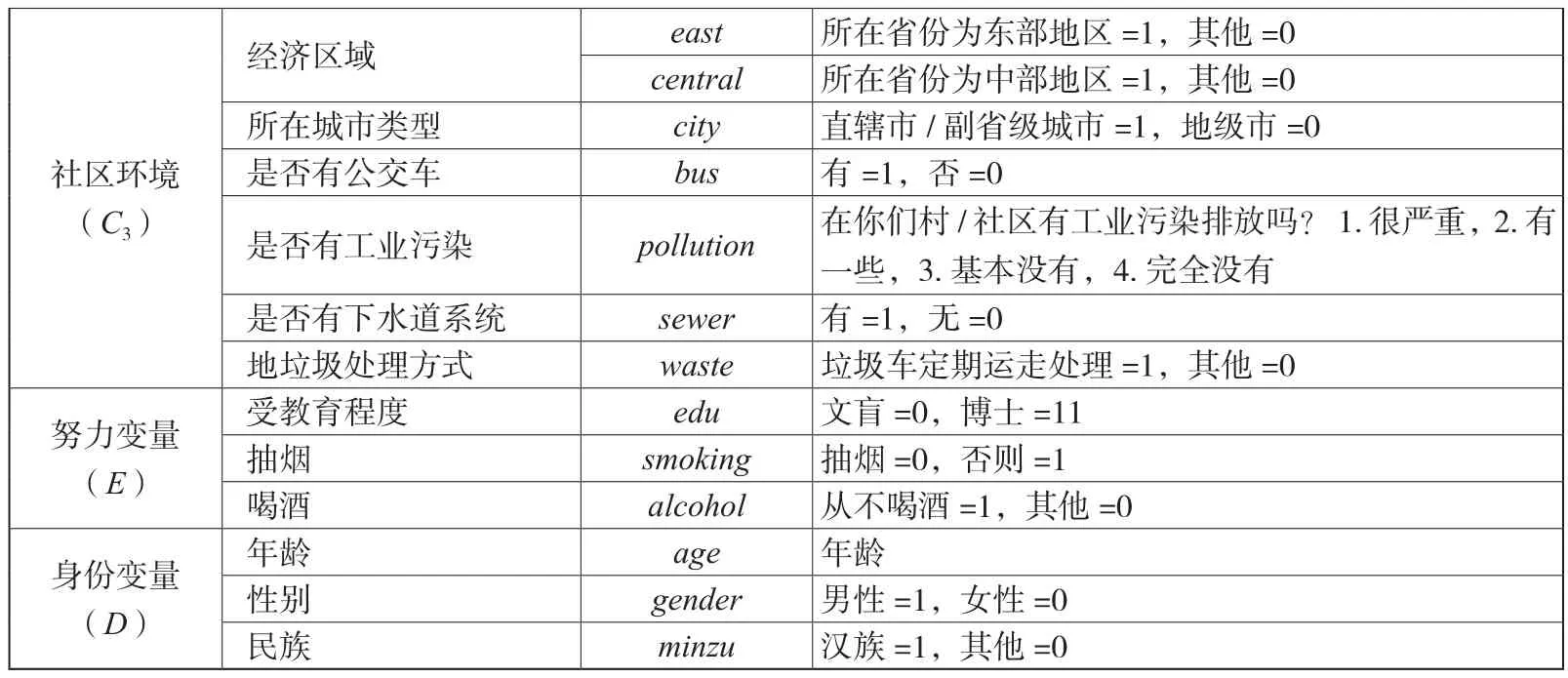
续表
经过数据清洗,有效样本共有5418个,变量的描述性统计详见表6,自评健康的均值为2.5026,众数和中位数均为2,可见自评健康的分布为有偏分布,较多受访人的自评健康在均值以下。具体来看,在样本受访人中,自评健康为“不好”、“一般”、“好”、“很好”、“极好”分别为918人、1985人、1694人、516人、305人,占比依次为16.94%、36.64%、31.27%、9.52%、5.63%;再将“极好”、“很好”、“好”汇总,三者共计2515人,占比46.62%。
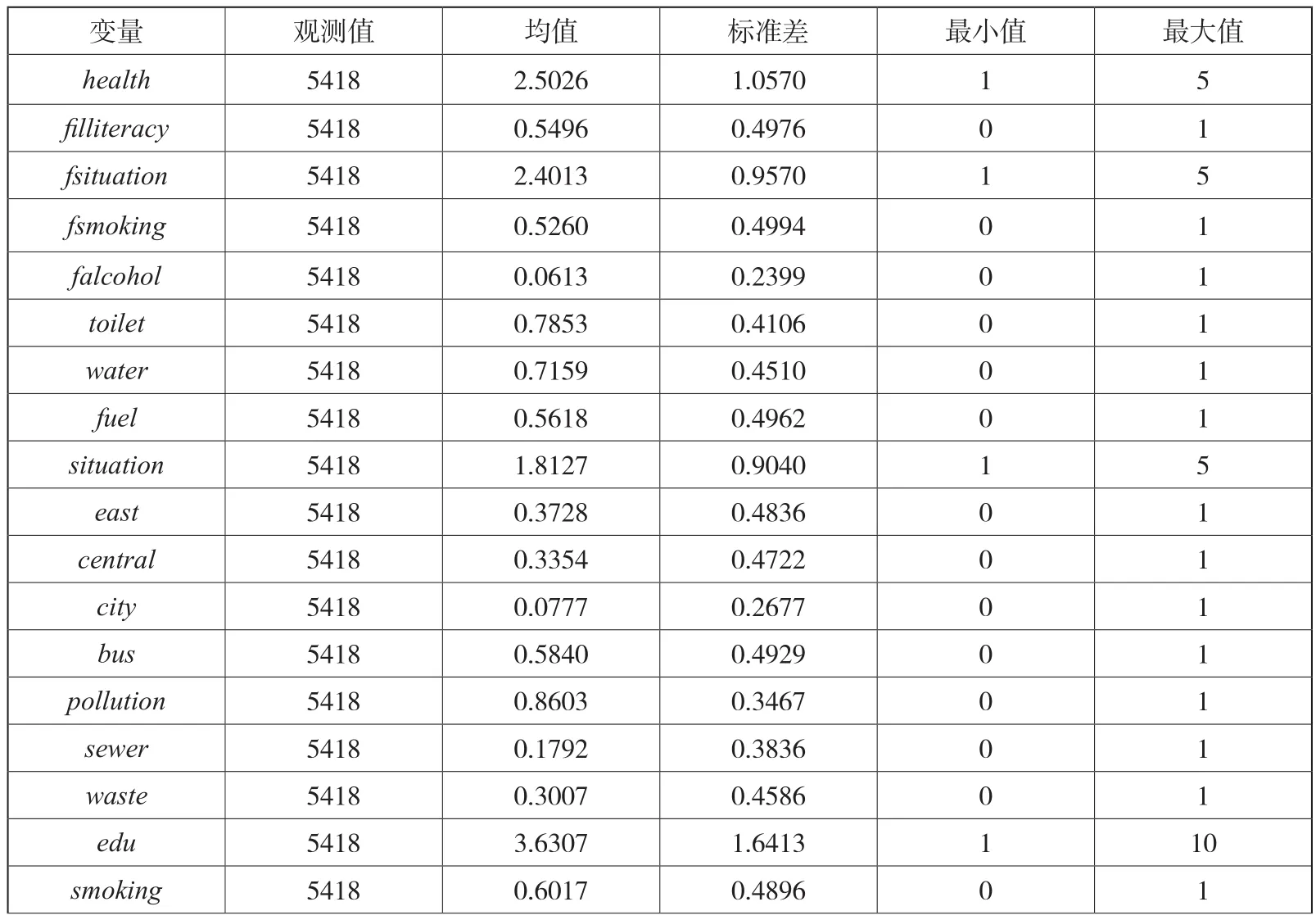
表6 变量的描述性统计

续表
4.2 居民健康决定方程的估计
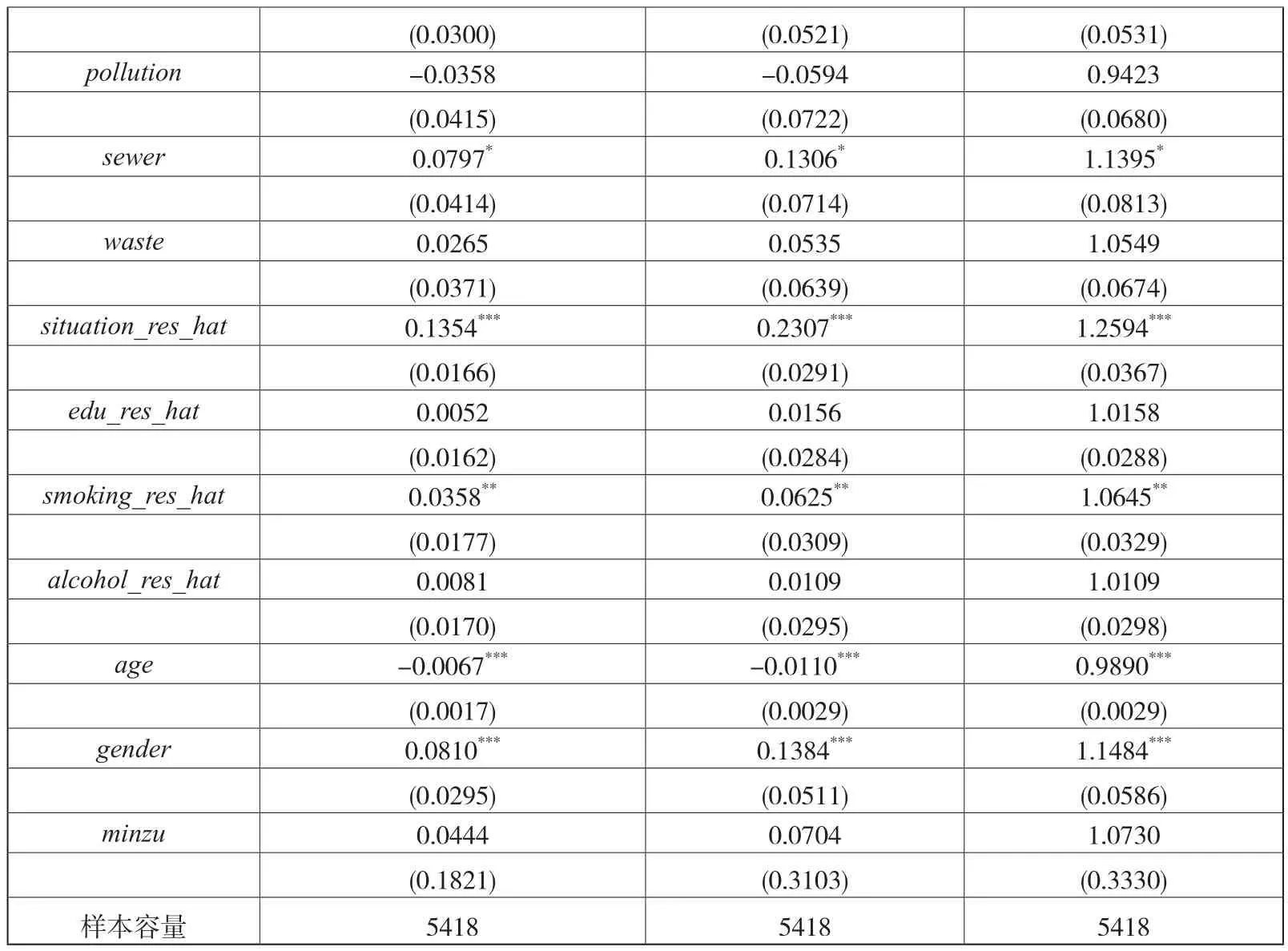
健康决定方程的估计包含两个步骤,首先估计辅助方程,辅助方程的因变量依次为受教育水平(edu)、是否抽烟(smoking)、是否喝酒(alcohol)、家庭生活水平(situation),以估计结果为基础可以得到广义残差项的估计值edu_res_hat、smoking_res_hat、alcohol_res_hat、situation_res_hat。其次,在考虑异方差的条件下,将四者与其他变量一起作为解释变量估计健康决定方程。由于自评健康为有序变量,因而可以采用Ordered Probit/Logit模型进行估计,辅助方程与健康决定方程的系数估计值如表7所示。基于Ordered Probit模型的估计结果可以得到变量的边际效应,而基于Ordered Logit模型可以得到变量的几率比,几率比能够给予估计系数估计值更为直观的现实含义,几率比的估计结果亦如表7所示。从系数估计值与显著性程度来看,两类模型的估计结果并无较大差异。由于广义随机扰动项的估计需以Ordered Probit模型为基础,故在健康机会不平等的测度中,以Ordered Probit模型的估计结果为基础。值得关注的是,在1%和5%的置信水平上,受教育程度、吸烟与否对方差存在显著影响。
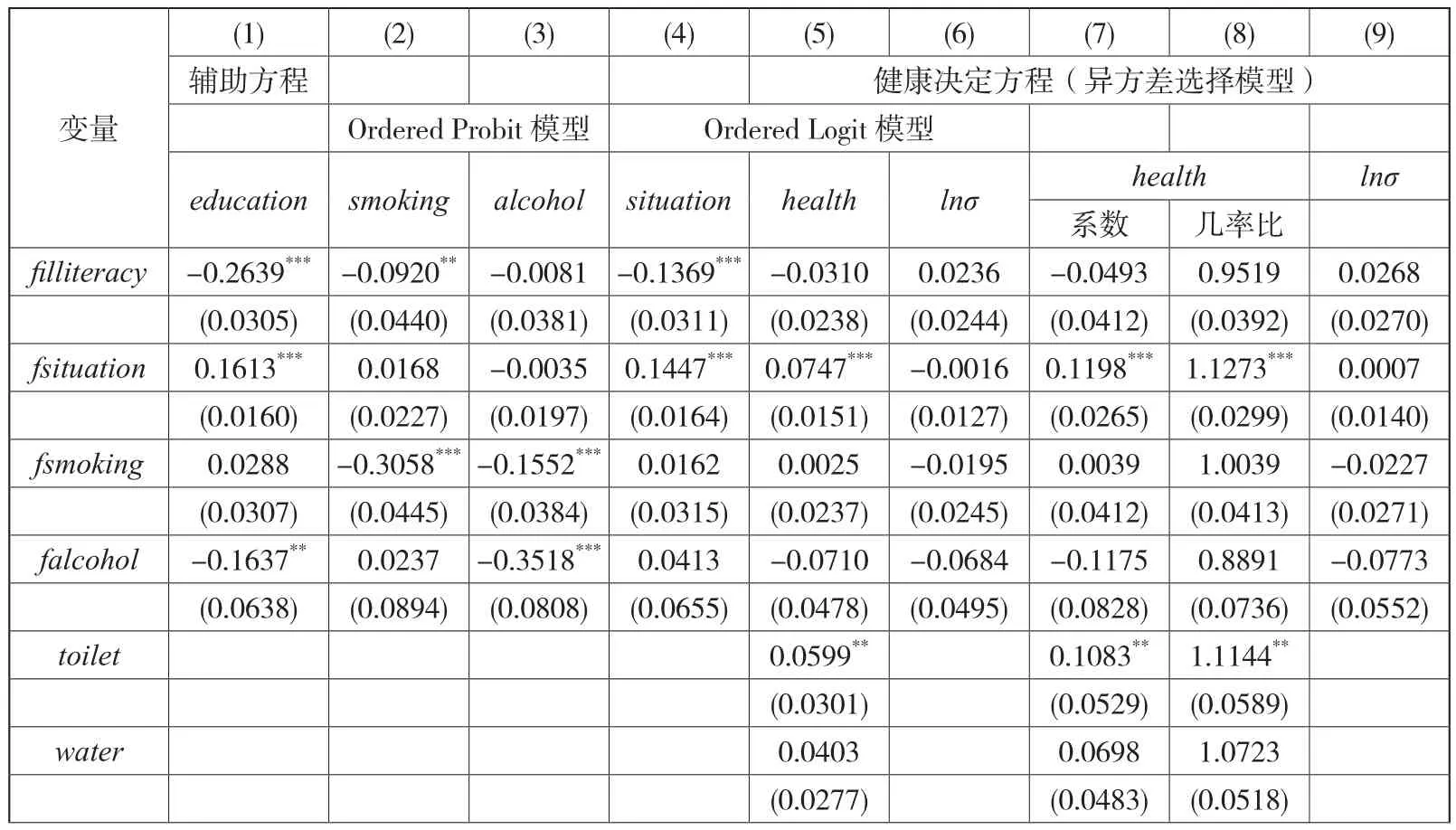
表7 健康决定方程的估计结果
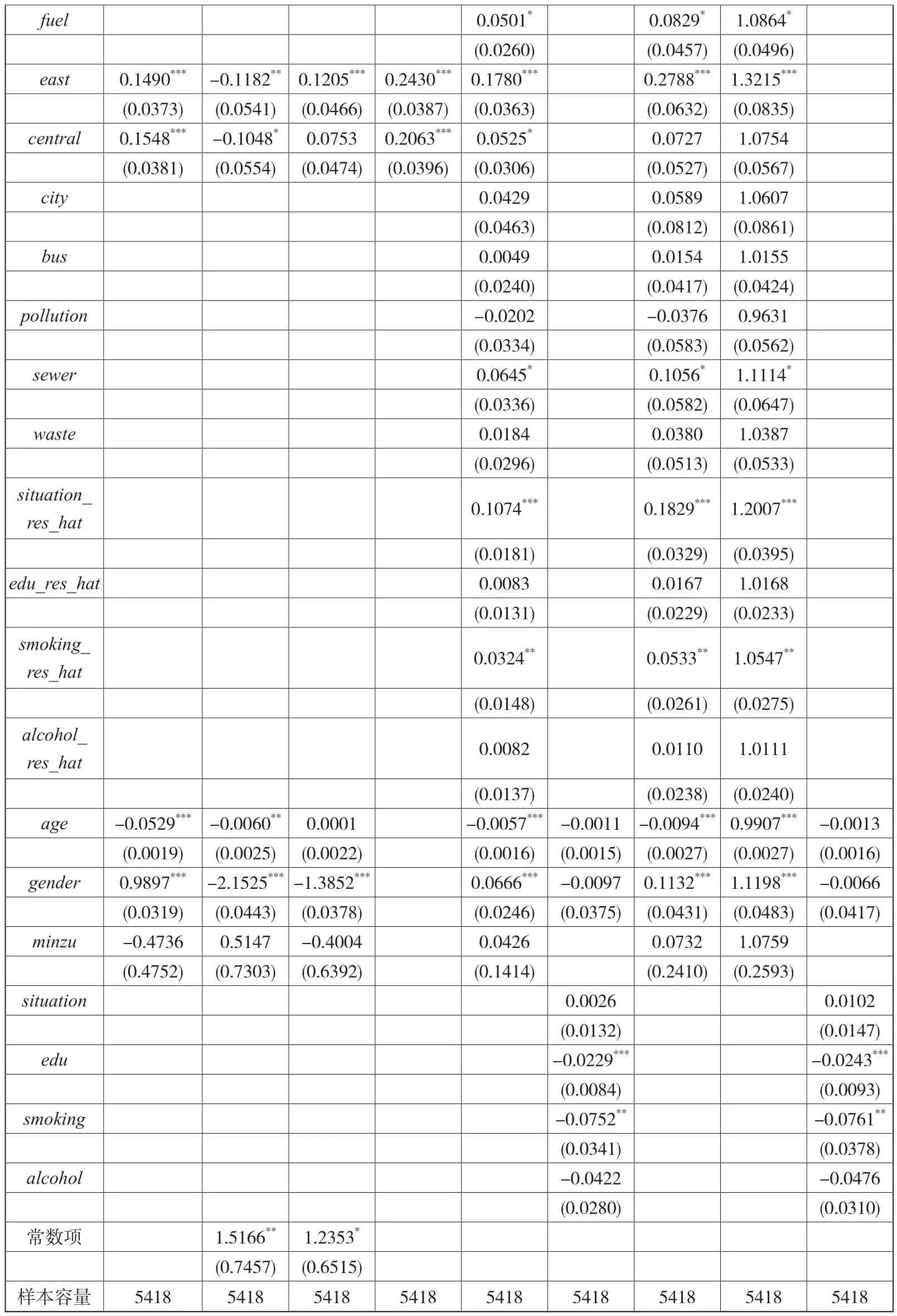
续表
由Ordered Probit模型的估计结果可知,在1%的置信水平上,原生家庭的经济状况、东部地区、剥离外生因素后的家庭生活水平、年龄和性别对自评健康存在显著影响;在5%的置信水平上,家中是否有冲水厕所、剥离外生因素后的是否抽烟亦是显著的;在10%的置信水平上,家用主要燃料类型、中部地区、是否有下水道也显著。由几率比的估计结果可知,在给定自评健康的条件下,原生家庭的经济状况增加一个单位,I{Hi>h}的几率比将增加12.73%;家中有冲水厕所,几率比将增加11.44%;主要燃料不是秸秆或者柴火,几率比将增加8.64%;如果受访人位于东部地区,几率比将增加32.15%;居住地有下水道系统,几率比将增加11.14%。对于剥离外生因素后的努力变量,调整后的家庭生活水平增加一个单位,几率比将增加20.07%;调整后的是否吸烟增加一个单位,几率比将增加5.47%。在身份变量中,年龄每增加1岁,几率比将降低0.93%;如果受访人是男性,几率比将增加11.98%。综上,众多外生环境因素变量对自评健康均存在显著影响,由此可见,对于农村居民而言,存在突出的健康机会不平等。
4.3 健康差距的分解与健康机会不平等的测度
以Ordered Probit模型的估计结果为基础可得I{Hi>h}的预测值,相应的基尼系数分别为0.0413、0.1113、0.1997、0.2618。由于在健康决定方程中共有21个解释变量,故在夏普利值分解中需进行209.72万次运算。进一步,采用本文给出的优化算法,对基尼系数进行夏普利值分解,分解结果如表8所示。
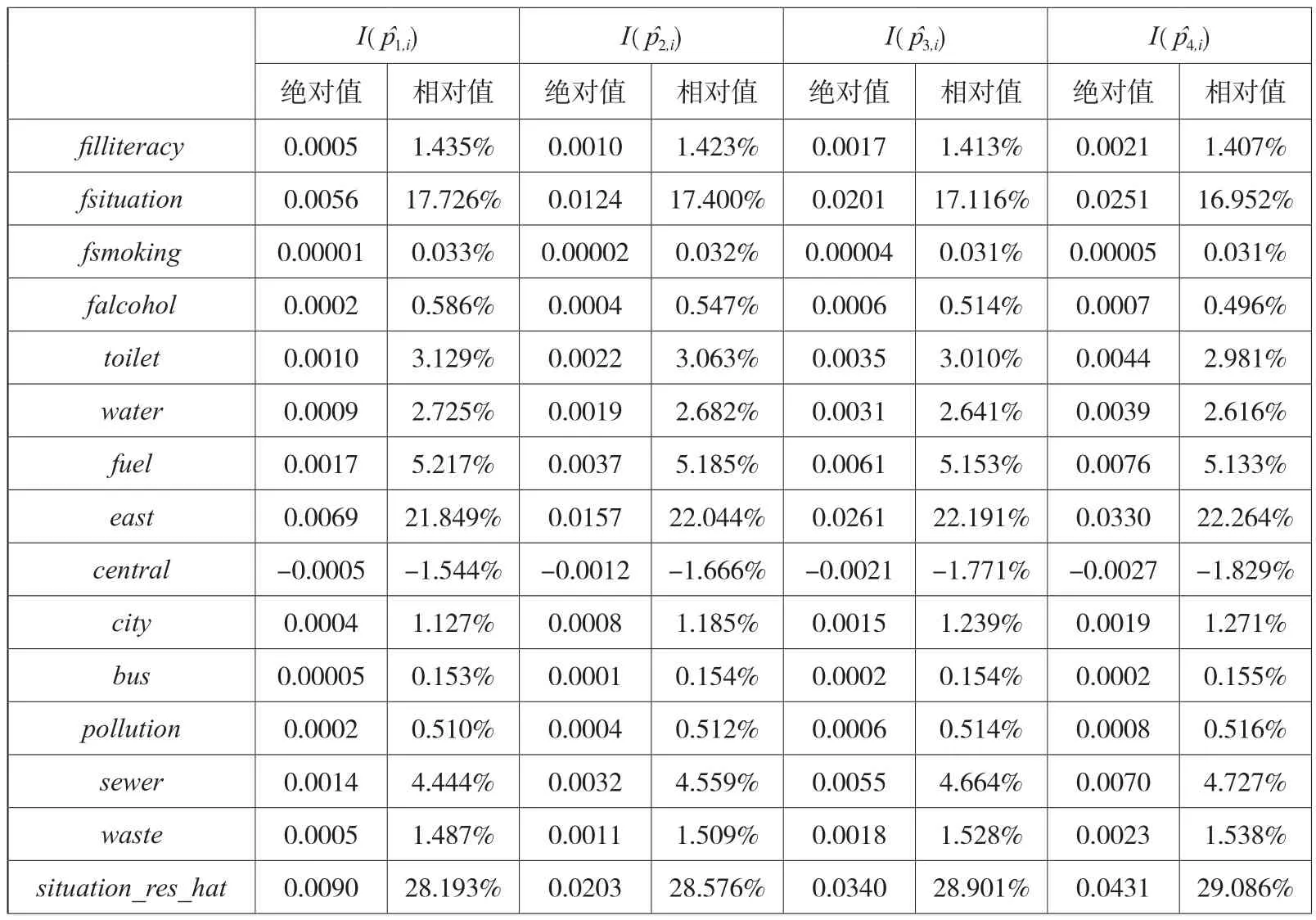
表8 夏普利值分解结果
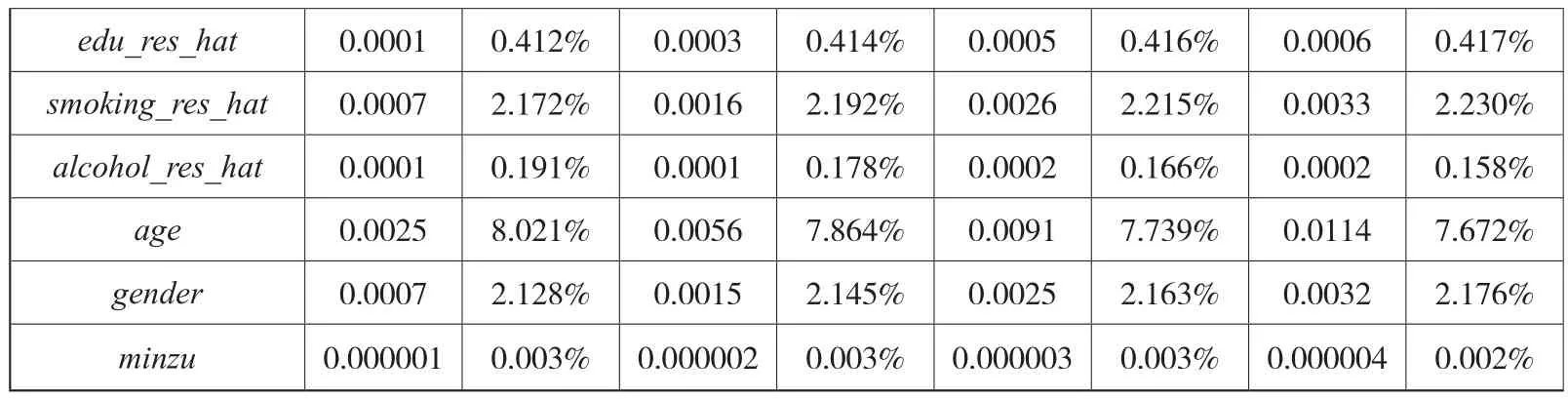
续表
其次,将变量的相对贡献度按类别汇总,努力因素的相对贡献度位列第一,为31.360%;社区环境次之,为28.297%;原生家庭环境位居第三,为19.401%;生活条件为第四,为10.930%;最后是身份变量,为10.012%。年龄差异导致的健康差距是合理的健康差距,将年龄与努力程度的相对贡献度加总,可知合理的健康差距在总的健康差距中占比为39.224%。除年龄之外的身份变量与环境变量导致的健康差距是不合理的健康差距——健康机会不平等,将年龄之外的身份变量与环境变量的贡献度加总,可得健康机会不平等对健康差距的相对贡献度为60.776%。
5 稳健性检验
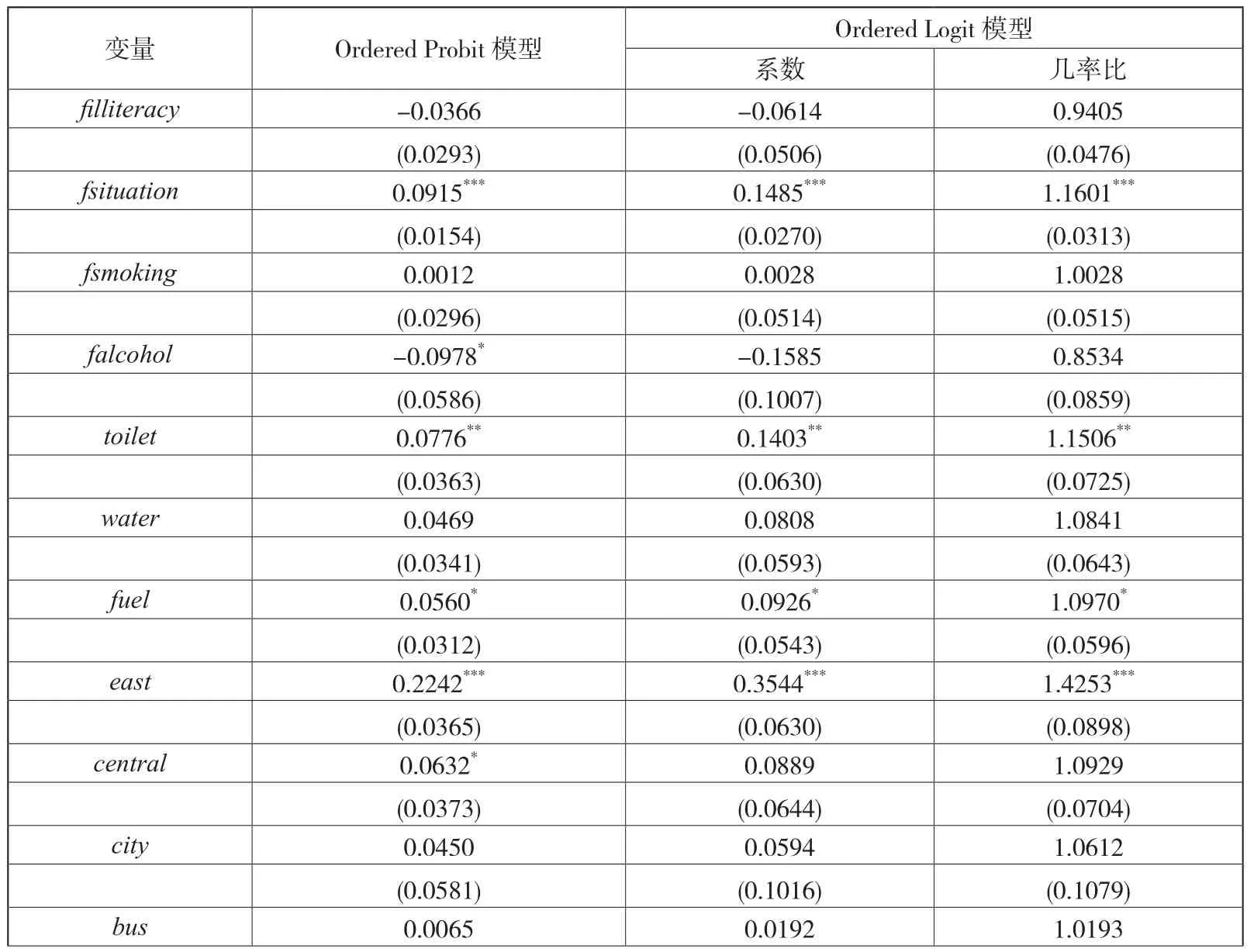
表9 Ordered Probit模型与Ordered Logit模型的估计结果
续表
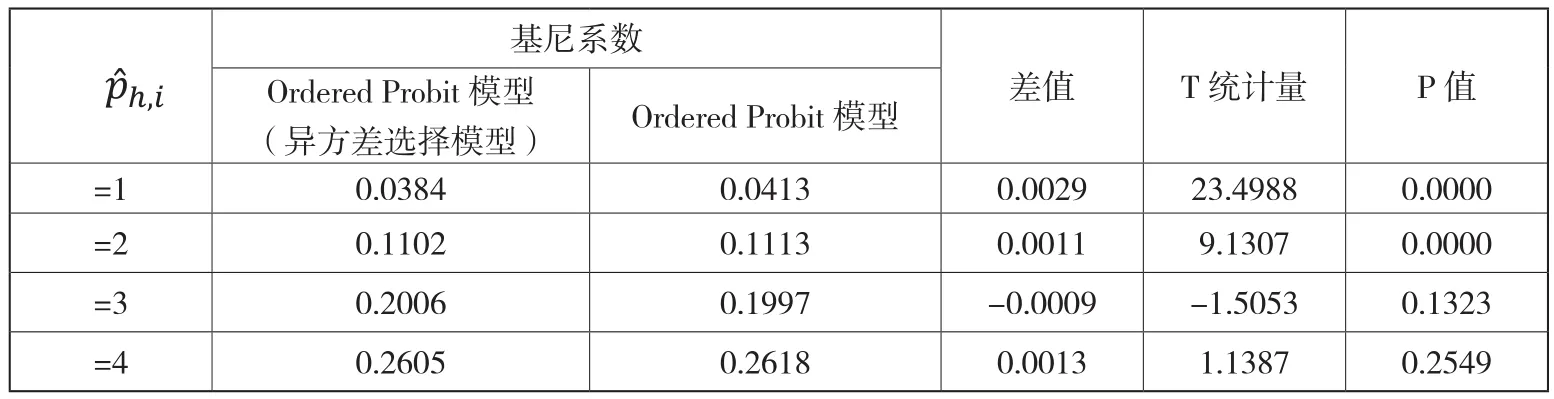
以Ordered Probit模型的估计结果为基础,首先估计n,i的基尼系数,分别为0.0384、0.1102、0.2006、0.2605。进一步检验该结果与基于异方差选择模型得到的基尼系数(0.0413、0.1113、0.1997、0.2618)是否存在显著性差异,检验结果表明,在5%的置信水平上,1,i、2,i的基尼系数在两类模型之间存在显著差异,而3,i、4,i的基尼系数在两组之间并不存在显著差异a。由此可见,环境变量、身份变量与努力程度变量是否存在相关性会显著影响n,i的基尼系数,间接凸显了在实证研究中采用异方差选择模型估计健康决定方程的必要性。调整估计方法后,n,i的基尼系数估计值在统计上并未完全改变,且两组基尼系数的数值差异甚小,可见n,i的估计值具有较好的稳健性。
进一步对基尼系数进行夏普利值分解,分解结果如表10所示。同样以的分解结果为例,剥离外生因素影响后的家庭生活水平、东部地区、17岁以前的家庭经济状况、年龄仍然是影响健康差距的主要因素。具体来看,在原生家庭环境变量中,父母受教育程度对健康差距的相对贡献度为1.315%,早期家庭经济状况为17.135%,父亲与母亲是否抽烟为0.011%,父亲是否酗酒为0.717%;在生活环境变量中,是否有冲水厕所对健康差距的相对贡献度为3.279%,是否有自来水为2.491%,主要燃料为4.518%;在社区环境变量中,经济区域(东部、西部)对健康差距的相对贡献度为21.118%,所在城市类型为0.972%,是否有公交车为0.169%,是否有工业污染为0.822%,是否有下水道系统为4.598%,垃圾处理方式为1.795%;在努力变量中,剥离外生因素影响后的家庭生活水平、受教育程度、是否抽烟与喝酒对健康差距的相对贡献度依次为29.522%、0.164%、1.775%、0.122%;在身份变量中,年龄差异对健康差距的相对贡献度为7.163%,性别为2.165%,民族为0.002%。
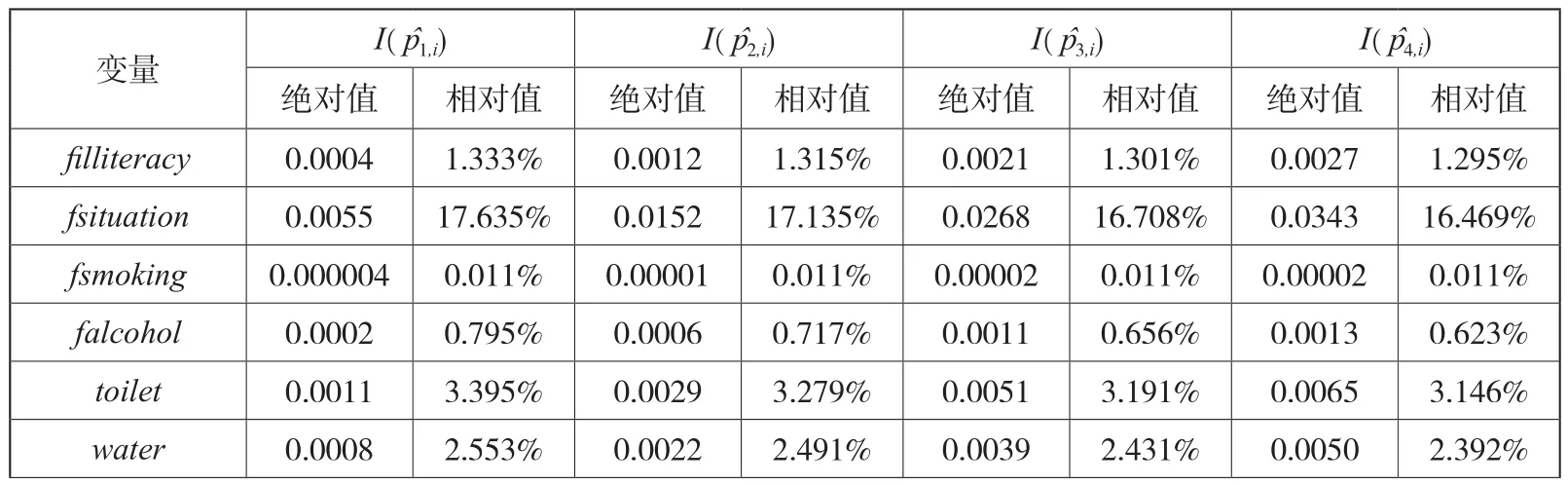
表10 基于稳健性检验的夏普利值分解结果
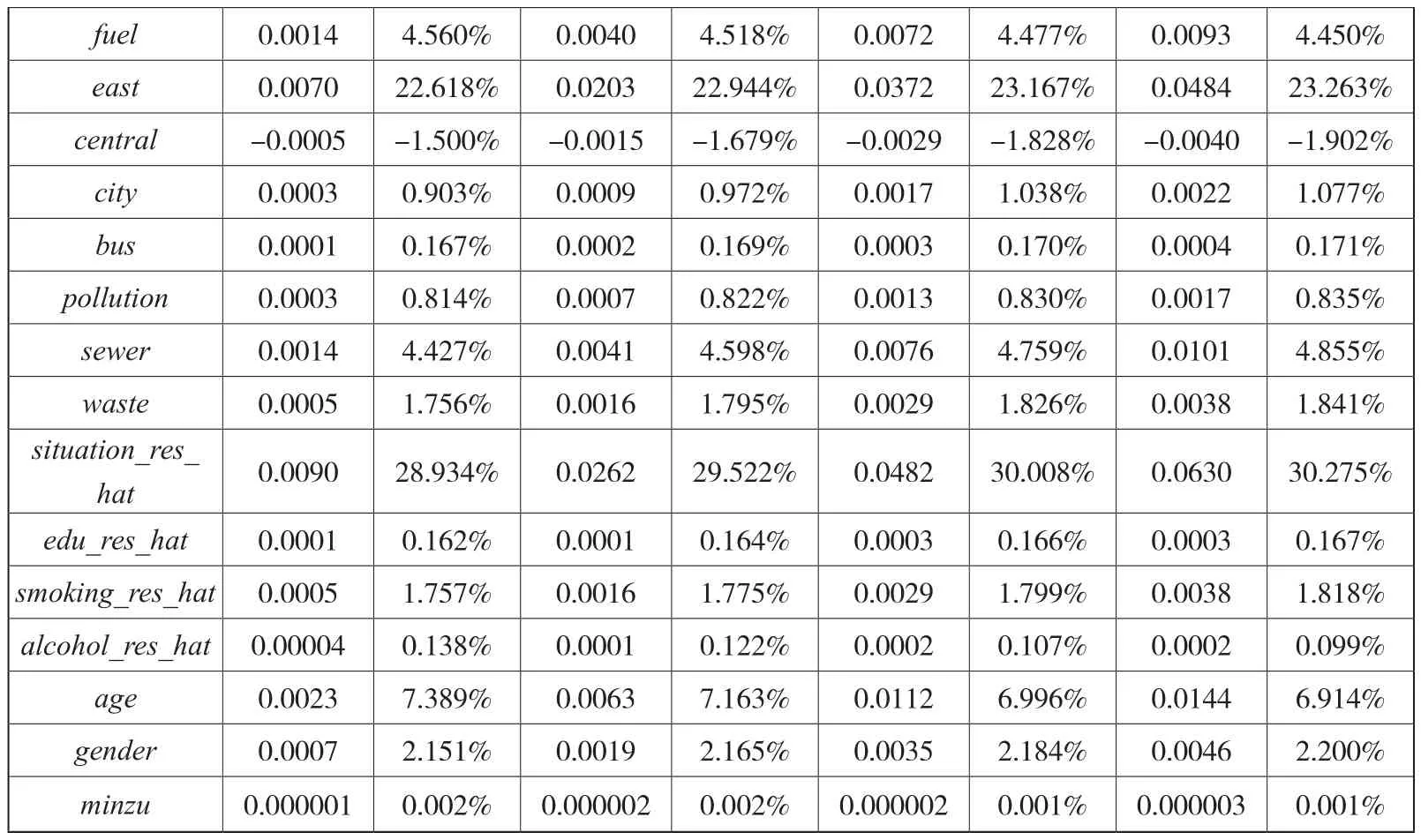
续表
以此为基础,按变量类别汇总相对贡献度,努力因素、社区环境、原生家庭环境、生活条件、身份变量的相对贡献度依次为31.582%、29.620%、19.179%、10.289%、9.330%。年龄差异与努力程度差异导致的健康差距是合理的健康差距,合理的健康差距在总的健康差距中占比为38.746%。年龄之外的身份变量与环境变量导致的健康差距是不合理的,两者的贡献度之和为61.254%,即按照Fajardo-Gonzalez的处理方式[12],在稳健性检验中,健康机会不平等对健康差距的相对贡献度为61.254%。
6 结论与展望
“生老病死”并非单纯的生物学事件,其中掺杂了诸多社会因素,遗传因素、膳食结构、作息习惯、医疗保健都会影响居民健康。居民健康既有遵从自然法则、合乎正义的一面,也有人为干预、有违机会公平的一面。本文的研究目标是在机会不平等的理论框架下,测度农村居民健康差距中的机会不平等,从农村居民健康差距中分解出不合理的健康机会不平等。在健康机会不平等中,已有文献并未在健康指标的选择上达成一致,本文认为健康不只包括客观上的身体健康,还应包括主观上的心理健康。本文对比了血检数据、抑郁得分与自评健康三项健康指标,对比发现自评健康不仅能够反映基于血检数据得到的健康风险程度,还能反映出基于抑郁得分得到的心理健康,自评健康能够综合反映出受访者的健康状况。因此,在本文的健康机会不平等的测度中,以自评健康为健康指标。
在考虑环境因素、身份变量、努力因素与随机扰动项存在相关性的条件下,以Ordered Probit/Logit模型与夏普利值分解为基础构建测度模型,并以CHARLS(2015)中的农村居民为样本数据进行实证研究。实证研究结果表明:①在本文选择的21个变量中,剥离外生因素影响后的家庭生活水平、东部地区、17岁以前的家庭经济状况、年龄是影响健康差距的主要因素,对健康差距的相对贡献度依次介于28.934%~30.275%、22.618%~23.263%、16.469%~17.635%、6.914%~7.389%;②将变量对健康差距的相对贡献度按变量所属类别汇总之后,原生家庭环境的相对贡献度介于18.398%~19.775%,生活条件的相对贡献度介于9.988%~10.507%,社区环境的相对贡献度介于29.185%~30.140%,努力因素的相对贡献度介于30.990%~32.358%,身份变量的相对贡献度介于9.116%~9.542%;③努力程度与年龄导致的健康差距是合理的差距,而除年龄之外的身份变量与环境变量导致的差距则是不合理的差距——健康机会不平等,将努力程度与年龄的相对贡献度加总,可得合理的健康差距在总的健康差距中占比为38.379%~39.273%,而将年龄之外的身份变量与环境变量的贡献度加总,健康机会不平等的相对贡献度介于60.727%~61.621%。由实证研究结果可知,努力程度差异是影响健康机会不平等首要因素,个人所在的社区环境次之,原生家庭环境位列第三。因此,保持健康的生活习惯、提升健康素养、加强社区基础设施建设、阻断健康不平等的代际传递是抑制健康机会不平等的主要着力点。鉴于此,本文认为可从以下三个方面入手缓解健康机会不平等问题:
首先,将健康知识教育纳入国民教育体系,提升国民健康素养。掌握必要的健康知识有益于居民养成健康的饮食习惯与作息习惯,对于疾病预防具有关键作用。从现实来看,中国农村居民的健康知识普遍比较缺乏,农村居民生活中的许多影响健康的成规陋习与缺乏健康知识紧密相关,因而有必要提升健康知识水平。一方面,可以将健康知识教育纳入教育体系,提升年轻一代的健康知识水平。另一方面,定期开展乡村健康知识普及活动,消除“成规陋习”,提升中老年人的健康知识水平。
其次,消除医疗空白点,增加医疗基础设施建设投入,合理布局基层医疗机构,充分发挥基层医疗机构功能。对于医疗空白点的乡村,加之交通与地理位置的制约,看病诸多不便。在合理布局基层医疗机构的前提下,尽可能地消除医疗空白点,有利于降低农村居民看病的时间成本与交通成本,化解看病难的问题。基层医疗机构应充分发挥预防、治疗和宣传功能,开展定期体检,监控居民健康状况,普及健康知识,消除生活陋习。
第三,通过政策干预阻断健康差距的代际传递,从婴儿、幼儿、儿童健康切入,提升国民健康水平。首先,大幅提升健康民生项目的覆盖面,加大遗传疾病、先天疾病的筛查力度,促进优生优育。其次,进一步增加免费疫苗种类,着力提升疫苗接种率,防范于未然。第三,定期开展营养、体能和心理检查,追踪成长状况。
