基于时空大数据挖掘的网络舆情研判方法研究
2021-05-12解仲秋
解仲秋
(西安航空职业技术学院,陕西西安 710089)
随着互联网的迅速发展,网络媒体作为一种新型的信息传播形式,正成为表达公众情感、畅通社会交流、凝聚公众智慧的重要渠道。互联网作为一种新型的媒体,由于具有自由、开放、互动等特点,比报纸、广播、电视及其他媒体更容易吸引公众参与舆论讨论。
对于热门话题与紧急情况,众多的互联网用户通过网络渠道表达其观点。新闻评论、BBS 与博客已成为互联网用户传播和表达公众信息的主要方式。当前,中国正处于社会转型的关键时期,网络舆情的影响力越来越大。若无法正确识别或引导出现偏见或负面舆论,将会构成极大的公共安全威胁。大学生是我国网民的主体,大学生对社会问题的参与度高,极易受到新思想的影响。因此,有效收集、监测与分析网络中大学生舆情成为亟待解决的重要问题[1]。
数据挖掘与机器学习作为动态处理大量数据的有效工具[2]。文中借助这两项工具研究了网络舆情热点检测,对各种民意的相互作用结构进行自然分组,并进行全面、及时的描述,实现了动态监测热点意见。
1 系统分析与架构
在网络环境下,舆情信息来源于评论、BBS、博客与各式聊天软件[3],不同的信息来源具有不同的特征。系统框架如图1 所示。首先,使用Web 搜寻器获取有关网络数据的最新信息,在删除重复的url后,将数据以Html 源文件的形式存储到硬盘中[4]。随后预处理源文件,将Html 文件转换为文本,提取信息主体与文件的网页地址,并发布时间、作者等信息[5]。在此基础上通过字典对提取的数据进行分析,得到文本信息的特征集合,提取关键词并统计关键词的出现频率[6]。使用专业词典与关键词进行比较,并提取相关事件,形成舆情信息数据库。最终,根据所需的类型、发布时间、源出处等实现对网络舆情的实时监控。

图1 舆情研判系统框架
该系统涉及的关键技术包括Web 爬虫技术[7]、主题词提取技术[8]、自动文本分类技术[9]。
1.1 Web爬虫技术
文中设计的Web 爬虫策略基于无主题搜索的广度优先[10]与深度优先策略[11]。基于深度优先策略,Web 爬虫程序搜索含有起始页面的所有页面。然后,选择一个链接页面,继续爬完此页面上的所有链接页面。基于深度优先策略,Web 爬虫程序从起始页面开始,遍历到所有链接的子链接,一直处理到网页目录尽头。随后,Web 爬虫程序继续跟随下一个起始页面。广度优先策略可以保证网络爬虫并行处理,提高数据搜寻效率;深度优先策略确保数据挖掘成本。文中根据需求混合使用两种网络爬虫的搜索策略,以提高链接的准确性,减少计算时空复杂性。
1.2 主题词提取技术
主题词提取技术的关键要点包括通用分词与POS 标记、识别与多词短语分组的新字符串、同义词与近义词的合并、基于结构和统计信息的关键词提取[12]。
文中使用中国科学院ICTCLIS 系统构建通用分词与POS 标记技术,并使用统计算法对关键词进行词频分析[13]。考虑到互联网语言中存在较多新词与未知词,文中通过计算相邻词组串的互信息,选择超过某个阈值的单词作为候选单词[14]。
2 数据挖掘算法构建
在上文建立的识别框架下,系统需提取舆情数据的特征。选择过程基于文档频率,通过互信息或信息增益的方法以减少单词的数量,从而获得有用的信息。在网络文本意见的分类过程中,将区分某种文本意见的重要单词提取出来(定义为功能单词),在检测网络意见热点时使用,这些词称为功能单词[16]。
功能单词有两种功能:全字功能与词干功能,全字功能从文中按原样提取,词干功能只提取词组的词干。考虑到舆情检测与分析的完整性和准确性,文中使用全字功能。通过使用常用术语加权TFIDF,结合术语频率(TF),乘以反向文档频率(IDF),用于衡量一个词组的信息性。文中使用K-means 聚类与SVM 分类器对Web 文本进行分类。
2.1 K-means聚类
K-means 是解决聚类问题时最朴素的无监督学习算法之一。其算法流程如图2 所示。
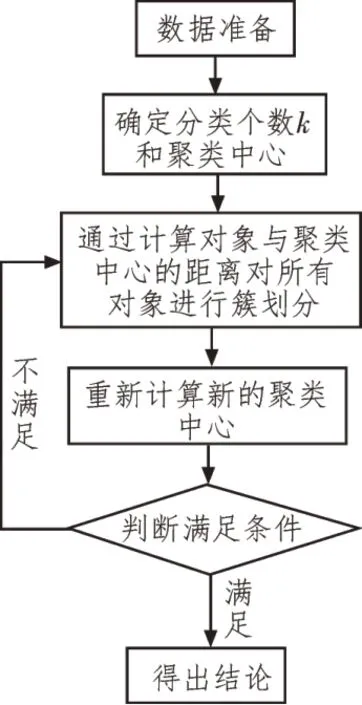
图2 K-means算法流程
算法通过预先设置的一定数量的聚类(假设k个聚类)对给定数据集进行分类。定义k个质心,这些质心随机存在于多维空间中。为保证聚类的准确性,将k个质心放置在尽可能远的距离。在一次迭代的基础上,重新计算k个新质心,将其作为上一步所产生簇的重心,然后依据相同数据集点与最近的新质心之间的距离重新进行运算。经过上述迭代,直至k个质心不再移动位置为止。文中使用的目标函数如式(1)所示。
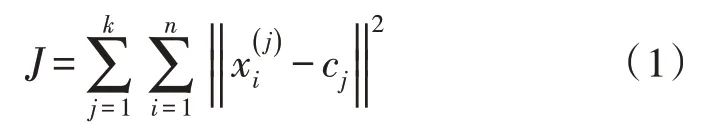
式中,J是在数据点与聚类中心之间的距离度量,表征了n个数据点到其各自聚类中心的距离度量。
运算周期内获得的互联网舆论,通过特征选择与降维,如式(2)所示。

其中,Di表示文本舆情,Ti表示特征,wj表示特征权重。式(2)用作K-means 聚类输入的数据集,该数据集将被聚集成k组,每个聚类的中心主题是最接近集群理论中心的热点。
2.2 SVM分类
由于网络舆论热点的数量尚不确定,因此是一个多分类问题。文中通过非线性函数将输入空间转化为高维空间。在高维空间中,构造线性判别函数以实现对原始文本空间的非线性判别,得到分类决策函数f(x)如式(3)所示。

其中,k(xi,x)为选择径向基函数,作为内积核函数,其形式如式(4)所示。

该节还使用SVM 来实现热点预测,为预测当前时间段的舆情热点分布,将最近时间段获得的历史数据输入到SVM 模型中。在此基础上,使用K-means 方法与当前时间段的聚类结果监督学习工具的SVM 输出。训练后的SVM 通过输入从当前数据中获得的数据,来对下一个时间段进行预测。假设当前时间段是si,输入si的表征向量,并将输出设置为K-means 的聚类结果。在此基础上训练SVM,最终得到si时刻的预测值。
3 实验验证
硬件体系结构如图3 所示。总体上分为服务器端与客户端,通过TCP/IP 协议进行通信。客户端主要搭载远程控制器应用程序,允许用户使用自然语言规范与鼠标等控件调用命令。此外,用户可以选择在客户端使用麦克风与扬声器,通过语音命令对系统进行调控。服务器端由Mentor 与Mitsubishi 服务器组成,Mentor 服务器使用Pentium III 450/ 128 Mb PC 直接控制,Mitsubishi 服务器使用Pentium II 400/128 Mb Windows NT PC。每个服务器可以共享一些模块,包含对象的数据库保存在单个计算机中,并由属于该项目的任何服务器共享。

图3 硬件系统结构
为了评估该方法对文本数据的分类结果,下面分别使用宏平均精度、宏平均召回率与宏平均F1 量度3个参数进行评价,其形式分别如式(5)~(7)所示。
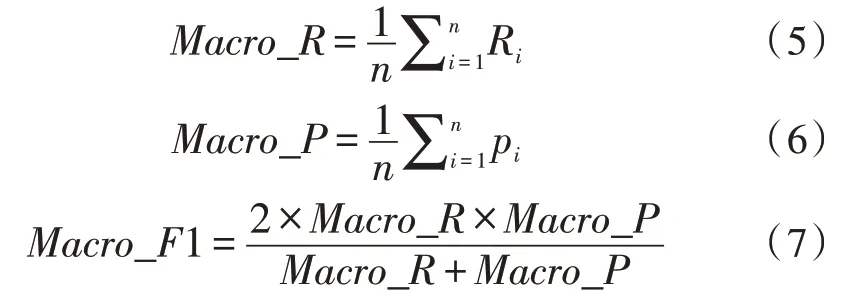
Macro_P是系统所有预测的正确分类占实际正确数据的比例,可由Macro_P=TP/(TP+FP)得出。Macro_R是预测的正确数据占所有实际正确数据的比例,可由Macro_R=TP/(TP+FN)得出。Macro_F1是精度与召回率的谐波平均值,可由式(7)得出。
3.1 K-means聚类验证实验
为验证K-means 的聚类效果,文中选取来自互联网论坛网站的数据,内容包括财经、人文、生活、娱乐等。
K-means 算法的一个不足是需要预设k。因此,文中的K-means 聚类分析针对一组k个值,计算出相同的向量空间模型所需的介于5~10 之间的k值。表1 给出了不同k值下的VSM(向量空间模型)值。分析表1 可知,该方法足以获得良好的准确性。在舆情监控的应用场景下,选取k=9 时以获得最佳聚类效果。K-means 聚类效果如表2 所示。
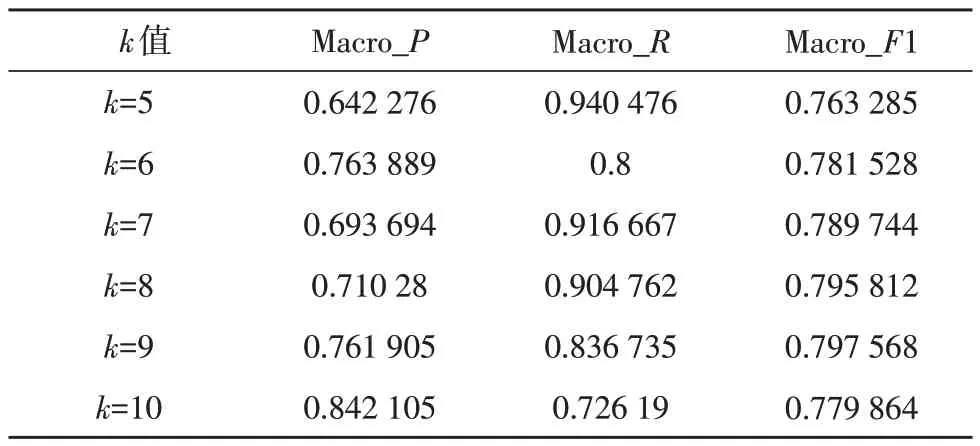
表1 不同k值下算法效果实验

表2 K-means聚类实验
3.2 K-means与SVM比较研究
文中从表3 给出的6 个不同类别Web 文本中选择1 000 个文档,通过筛选,使用其中692 个文档用于训练神经网络,120 个文档用于测试。

表3 分类测试的Web文本数据库
由于中文文本中单词之间未有明显的空格,因此,首先需要对文档加注标点符号。在删去停用词与辅助词减少了文本无用特征后,采用TFIDF 构建识别构架输入功能,得出表4 所示的特征维度。最终的分类实验结果如表5 所示。对比可知,5 类文本信息下SVM 的Macro_F1 度量优于K-means。

表4 文本特征维度
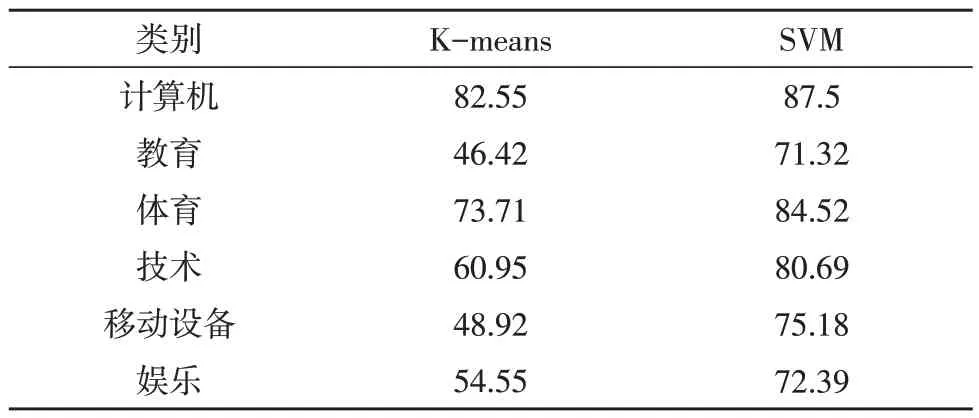
表5 两种方法的F1量度实验结果
4 结论
文中设计了一个互联网舆情研判检测与分析模型。根据网络舆情的文本属性,引入VSM来表达文本舆论。根据实际应用场景,从一些新网站中选取文本语料库。对收集的文本文档进行K-means 聚类与SVM 分类,通过实验结果证明了该方法的有效性。
此外,未来工作的研究方向如下:深入开展网络舆情检测研究,细化文中互联网舆情研判方法的每个步骤,以加强对高校舆情的引导,预防舆情危机的出现。建设动态监视技术,既能够实时监视网站,又可以省去时间、经济成本高昂的数据清理工作。此外,网络舆情检测不能止步于词频分析,如何确定聚类算法的最优k值、如何提高海量数据的处理速度,也是未来工作的主要研究内容。
