基于对偶单元法的三维集成微系统电热耦合分析*
2021-05-07曹明鹏吴晓鹏管宏山单光宝周斌杨力宏杨银堂
曹明鹏 吴晓鹏† 管宏山 单光宝 周斌 杨力宏 杨银堂
1) (西安电子科技大学微电子学院, 西安 710071)
2) (电子元器件可靠性物理及其应用技术重点实验室, 广州 510610)
随着三维集成微系统集成度和功率密度的提高, 同时考察电设计与热管理的多场耦合分析势在必行.本文面向三维集成微处理器系统, 通过改进的对偶单元法(dual cell method, DCM)实现了系统的快速电热分析.该方法通过引入泄漏功率、材料系数随温度的耦合, 相比于传统有限元法在更新以及组装本构矩阵上有更大的优势.仿真验证表明, 本文所采用的算法相比传统有限元法仿真速度提升了约30%.在考虑了材料系数以及泄露功率热耦合因素后, 系统热点温度相对于考虑耦合前上升了20.8 K.最后采用本文所提出算法对三维集成微处理器系统进行布局研究, 比较了硅通孔阵列常规布局和集中布局在处理器核心下方两种布局方式对上下层芯片热点温度的影响, 研究了功率不均匀分配对两种布局的影响.
1 简 介
目前三维集成技术是延续摩尔定律引领集成电路发展走向后摩尔时代的有力解决方案[1].三维集成微系统具有高集成度、微小型化、低功耗、高可靠性和高效率等优点, 在逻辑计算处理、成像传感和光集成等方面具有广阔的应用前景.但是三维集成技术同时导致了微系统内单位面积上产生的热功耗急剧增加.以处理器芯片为例, 目前CPU的功耗密度达到了100 W/cm2以上[2], 功率密度的增加和功率的不均匀分布共同导致了严重的热问题.而这些热问题反之对诸如泄露电流、电迁移、信号和电源完整性等电设计提出了诸多挑战.其中泄漏功率是目前处理器性能的最重要限制因素之一, 对于65 nm 及更先进的工艺节点, 泄漏功率占总功率的10%以上[3].泄漏功率与温度呈指数关系, 因此泄漏功率将导致处理器发热并进一步增加泄漏功率本身.随着温度的变化, 在传热过程中材料的热导率会发生改变, 从而对热点温度产生影响[4].综上所述, 对高功耗三维集成微系统在设计初期进行电热耦合分析在确保系统可靠性方面具有至关重要的作用.
有限元法(finite element method, FEM)由于在复杂几何形状、材料建模方面具有极好的适应性和精度, 因此常被用于电热耦合的分析研究[5−11].为了使该算法更适于三维集成微系统分析, 在算法改进方面开展了诸多研究工作.Lin 等[12,13]提出了一种芯片级泄漏感知方法, 采用交替方向隐式法结合芯片功率、工作频率和电源电压之间的各种电热耦合, 预测芯片热分布.该方法采用了等距网格,这虽然提升了计算速度, 但也同时导致精度下降.北京大学的Pi 等[14]提出了一种快速的3D-IC 热管理全芯片规模数值模拟方法, 该法同时考虑了横向和纵向散热的紧凑型热阻网络, 充分分析了硅通孔(through silicon via, TSV)、微凸块和再分布层中的高导热路径.然而该研究所用的热阻网络无法获得十分准确的温度场, 并且未考虑温度带来的耦合因素.Chai 等[15]开发了径向点插值法, 并对TSV 阵列进行了电热耦合特性研究, 提高计算效率并降低了存储成本, 加快了基于TSV 的3-D IC的电热设计.但是这项工作目前仅集中在TSV 模型上, 还无法对整个三维微系统进行分析.Wang等[16]提出了一种动态线性泄漏电流感知的全芯片热估计方法.该算法将非线性热模型转换为多个局部线性热模型, 并设计了一种自适应降阶法以提高效率.但线性泄露电流仅能运用于瞬态仿真迭代,无法在稳态迭代中使用.
针对以上研究中存在的问题, 本文提出了一种能够快速计算电热耦合的改进对偶单元法(dual cell method, DCM).该方法在考虑了泄漏功率、材料系数与温度的耦合关系的前提下, 将整体本构矩阵分解为常数矩阵和温变矩阵的乘积, 使得在每次温变迭代过程中只需计算温变矩阵.对比传统FEM 中的单元传热矩阵, 改进DCM 的温变矩阵拥有更低的阶数, 在计算量和整体矩阵的组装上有着显著优势.通过仿真验证了在相同自由度下, 改进DCM 比传统FEM 具有更快的计算速度.最后面向三维集成微处理器系统基于改进的DCM 对其进行了电热耦合分析, 并根据分析结果进行布局优化指导, 对三维集成微系统的设计优化具有一定的参考价值.
2 改进的DCM 算法
2.1 DCM 原理
对偶单元法是一种基于传统FEM 发展的代数方法, 通过FEM 的网格剖分, DCM 可以不通过微分方法而直接根据问题的物理场以及基本的几何和拓扑概念定义数值方案, 从而该算法更适用于实现快速计算[17,18].DCM 首先通过网格剖分得到初始单元, 并根据规则构造对偶单元.之后通过单元对应关系及本构关系分别构造拓扑矩阵和本构矩阵, 最后组成线性方程组进行求解.
DCM 求解传热问题的计算流程如图1 所示,单元节点上的温度T通过拓扑算子矩阵G表示成单元边上的温差γ.然后通过本构关系利用温差计算出对偶面上的热通量Φ, 最后再将热通量通过拓扑算子矩阵D转化成对偶体上的整体发热量q.
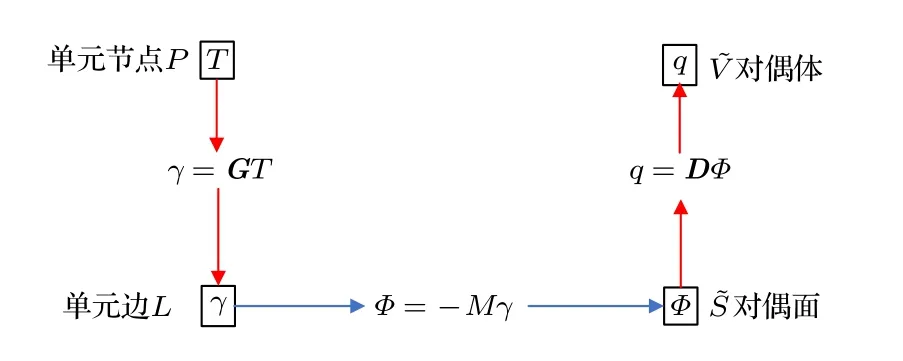
图1 DCM 求解传热问题流程图Fig.1.Flow chart of DCM solving heat transfer problem.
如图2 所示, DCM 根据四面体单元的重心、4 个面的重心和6 个边中点的连线构建对偶空间[19,20].在单个四面体中, 每条边对应着一个对偶面, 如e2 对应S2, 每个顶点对应三个对偶面, 如A对应S2,S3,S6.在单个顶点接触的所有四面体中, 对应该点的所有对偶面构成对偶单元.
对于传热问题的研究, 首先定义节点温度列阵T, 获得以节点温度之间的差值作为边ei的温差列阵.温差列阵γ可表示为

同时两个节点间的温差γ也可以由单元温度梯度g和边向量L表示:

根据傅里叶定律, 热通量Φ的表达式为

其中k为热导率;J为热流密度;表示对偶面的面积向量, 方向垂直于对偶面.结合(1)式、(3)式和(4)式可得四面体内部对偶面的热通量矩阵Φ为

图2 对偶单元构建过程Fig.2.The process of dual unit construction.

其中P为为边矩阵的分块阵;M为传热问题的本构矩阵.
对于整体网格来说, 将所有对偶面上的热通量相加即为整体节点载荷列阵q:

D为拓扑矩阵G转置的负矩阵即D=−GT.结合(1)式、(5)式和(6)式可得整体传热方程为

2.2 改进的DCM 耦合分析
随着功率密度不断增加, 芯片的整体温度不断上升, 所以对温度上升导致的耦合分析变得至关重要.
由下式可知泄漏功率与泄漏电流成正比, 其中泄漏电流Ileak分为亚阈值泄漏电流Isub和栅极泄漏电流Igate:

其中栅极泄漏电流Igate对温度并不敏感.
对于BSIM 4 的MOSFET 晶体管模型, 其亚阈值电流公式为(Vds≫Vt)
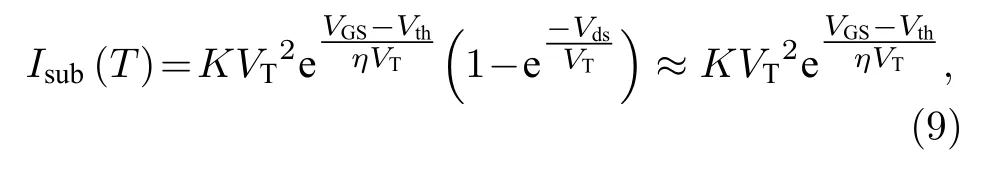
其中K和η为相关工艺参数;VT为热电压, 与温度成正比;Vth为阈值电压.
另外, 材料的热导率是与温度相关的函数, 同时材料的温度变化可以通过温度的插值函数表示,可得热导率公式如下:
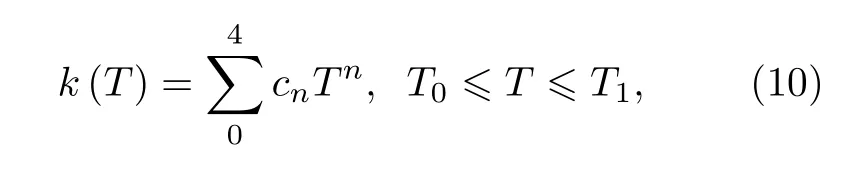
其中cn为插值系数, 具体数值参考文献[4,10].
引入耦合项Isub(T) ,k(T) 后, (7)式的整体传热方程可改写为与温度相关的形式:

由(11)式可知, 在每次温度迭代计算时, 需要重新计算每个单元的本构矩阵M(k(T)) 和载荷列阵q(Isub(T)) 并重新组装.对于DCM, 每个单元本构矩阵M为6 × 6 的矩阵, 相比于有限元4 × 4的传热矩阵K计算量更大, 组装时间更长.因此本文对DCM 的整体传热方程做了进一步的改进.(5)式中的本构矩阵M(k(T)) 可以分解为
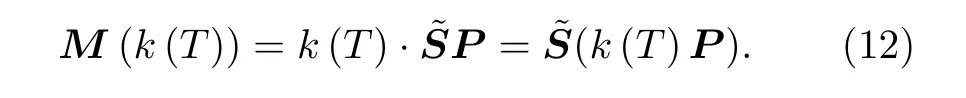
由(1)式可知在一个四面体单元中通过任意三条边的温差γ1,γ2,γ3可以计算得到另外三条边的温差.同时由(3)式可知, 求解列矩阵g3×1所需要的条件为矩阵L满秩, 所以只需要三个互不相关的边向量即可表示列阵g3×1

为了满足本构矩阵M的维度, 温差列阵γ可以由三个温差与三个0 元构成, 边矩阵L可由三个边向量和3 × 3 的零方阵表示:

此时矩阵P为有效数据减少为9 个.梯度阵g可表示为

最终可得整体传热方程为
基于野外调查,按代表性植被的分布在三处边坡中选取草本植被、草灌植被、草灌乔植被各两个样地,样地大小按1 m2(草本植被)、10 m2(草灌植被)和100 m2(草灌乔植被)设置,以S形在同一样地内采取5个样品。采集0~10 cm土层原状土,装入铝盒内带回实验室,风干后,沿土壤自然结构面人工剥成直径为10~12 mm的小土块,并剔除土中的植物根系及小石粒。

算法的整体耦合迭代流程如图3 所示, 首先根据划分的网格信息计算拓扑矩阵GS和G, 根据给定的初始温度计算初始状态下的亚阈值泄漏电流和热导率, 并带入计算本构矩阵Pk(T) 和节点载荷q(Isub(T)).下一步将本构矩阵和载荷带入传热方程计算出该迭代步的温度场分布Tnew.根据计算的温度场更新本构矩阵和节点载荷, 并带入传热方程计算新的温度场分布, 直到两步迭代的结果小于设定的迭代截止精度tol.

图3 迭代算法流程图Fig.3.Flow chart of Iteration scheme.
3 模型验证与分析
本节采用改进的对偶单元法研究三维集成微处理器系统在耦合情况下的温度分布, 讨论不同I/O 端口和TSV 阵列布局对叠层芯片热点温度的影响.图4 所示为参考三星DRAM 和Intel i7 处理器芯片构成的两层堆叠微系统结构示意图[21].两层芯片的尺寸均为10 mm × 10 mm, 衬底的尺寸为20 mm × 15 mm, 热沉的尺寸为40 mm ×35 mm.芯片层的厚度为100 µm, 带C4 凸块的TIM 层厚度为100 µm, 带微凸块的TIM 层厚度为40 um.初始温度和环境温度为293 K, 热对流系数为100 W·m–2·K–1.DRAM 和处理器的版图布局如图5 所示, 其中DRAM 被分为8 个Bank 区,处理器芯片由4 个Core 构成(从左到右分别记为Core1, Core2, Core3, Core4).在DRAM 芯 片 的I/O 区域中均匀分布了16 × 80 个TSV.为了能直观表征Core 区和Bank 区的温度, 选取如图5中所示的黑色虚线为观察芯片温度分布的基准线.根据DRAM 和处理器的典型工作状态, 本文在仿真中将DRAM 的工作功率设为2.82 W, 处理器工作功率设36 W, 其中四个核的总功率为26.5 W,整个微系统泄漏功率占比为12%[3,21].

图4 三维集成微处理器系统结构示意图Fig.4.Schematic diagram of the three-dimensional integrated microprocessor system.
3.1 改进的DCM 准确性验证
在保证精度的前提下为了降低仿真复杂度, 采用等效模型法对TSV 阵列进行了等效处理, 通过插值法获得等效区域各向异性的热导率[22].当处理器4 个核心功率均匀分布时, 处理器和DRAM芯片上观察基准线上的温度分布分别如图6 所示.当不考虑电热耦合时, FEM 求解得出的处理器和DRAM 芯片的热点温度分别为351.83 K 和346.64 K, DCM 求解得出的处理器和DRAM 芯片的热点温度分别为351.83 K 和346.63 K.改进的DCM 与FEM 获得的温度曲线几乎完全吻合,有着良好的一致性.在考虑电热耦合时, 发现用改进的DCM 与FEM 仿真得到的处理器芯片与DRAM 芯片的热点温度为分别为373.64, 374.07 K和365.87, 366.24 K, 改进的DCM 仿真相比于传统FEM 误差仅为0.53%和0.51%(仿真后温度与初始温度的差值进行误差计算, 下文同), 其精度满足应用要求.

图5 工作区域分布图 (a) DRAM 芯片; (b) Intel i7 处理器芯片Fig.5.Work area distribution map: (a) DRAM; (b) processor.

图6 不考虑耦合与考虑耦合时芯片温度分布 (a) DRAM; (b) 处理器Fig.6.Chip temperature distribution without considering coupling and considering coupling: (a) DRAM; (b)processor.
对比考虑电热耦合前后的仿真结果, 发现在考虑电热耦合因素之后两个芯片的平均温度均提高了约20 K.这是因为随着工作温度的上升, 芯片泄漏功率急剧增大, 这使得芯片发热量进一步增大,形成温度正反馈循环, 这是影响三维集成微系统工作温度的主要因素.同时材料的热导率会随着温度的升高而降低, 使得结构的导热性能变差, 从而使得温度再度升高, 因此在三维集成微系统的设计过程中, 综合考虑电热耦合对系统可靠性的影响是十分必要的, 否则存在低估系统工作温度的风险.

表1 FEM 与改进DCM 的仿真时间对比Table 1.Simulation time comparison between FEM and improved DCM.
3.2 三维集成微系统的布局分析

图7 两种不同的TSV 阵列布局 (a) 常规布局; (b) Core-布局Fig.7.Two different TSV array layouts: (a) Conventional layout; (b) core layout.
在三维集成电路中, 由于具有高热导率的TSV阵列是温度传导的重要路径, 因此I/O 端口中的TSV 阵列常被作为重要的散热手段, 而TSV 阵列的Core-布局方式通常被认为能够有效的降低系统的热点温度[23].Core-布局的具体布局方式如图7(b)所示, 即将DRAM 芯片中I/O 区域的TSV 阵列布局位置对应上层处理器芯片4 个Core 的位置.在以往的研究中采用Core-布局结构的上下层芯片功率相近, 使得两层芯片的温度变化连续, 因此能够使得上下层芯片的热点温度同时下降[23,24].而本文所考察的微处理器系统工作状态中处理器功率远大于DRAM 的功率, 并且上下层芯片的热点温度相差接近8 K, 因此有必要重新评估Core-布局的可行性.
为了比较两种布局的温度分布, 首先将处理器的四个Core 功率设置为均匀分布, 采用改进的DCM 对两种布局结构进行电热耦合仿真分析.如图8 所示采用Core-布局结构时, 处理器芯片的热点温度下降了2.20 K.而与此同时图9 所示DRAM芯片的热点温度为370.93 K, 相比3.1 节仿真得到的常规布局热点温度上升了4.30 K.这是由于TSV阵列作为重要散热路径, Core-布局结构会将处理器高功率Core 区域产生的热量传导到下层, 使得处理器芯片温度下降的同时让DRAM 芯片的整体温度上升.对比TSV 阵列常规布局的情况, Core-布局使得处理器芯片热点温度下降2.73%, 而使得DRAM 芯片的热点温度上升5.85%.考虑到高温会导致DRAM 的晶体管电荷损失加快, 使得数据丢失.因此在选择布局方式时, 需要综合考虑处理器芯片的降温情况与DRAM 芯片的升温情况.
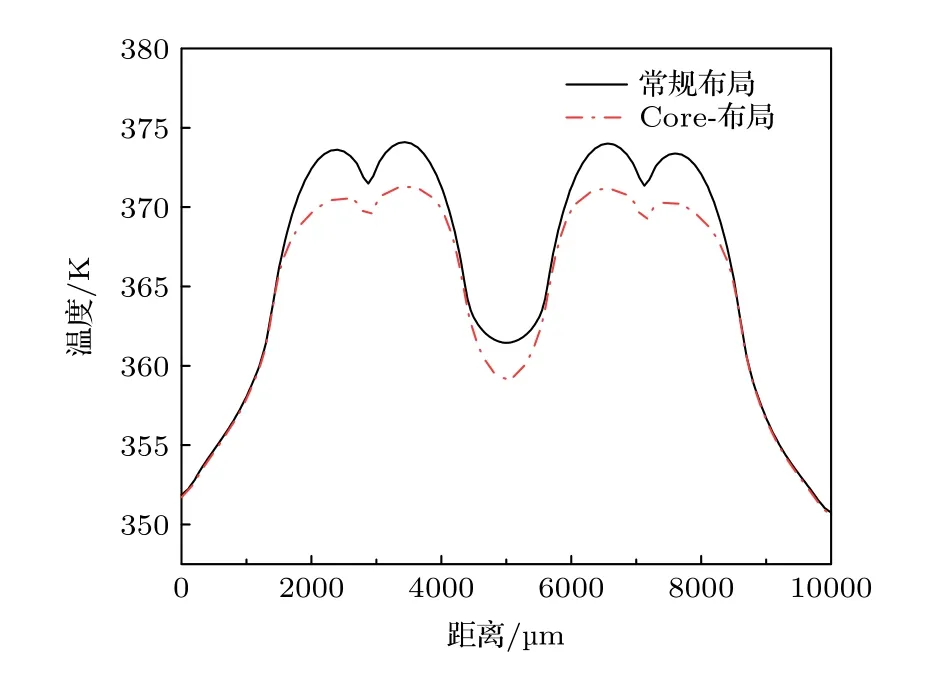
图8 两种不同TSV 阵列布局时处理器的温度分布Fig.8.Temperature distributions of processors with two different TSV arrays.

图9 Core-布局时DRAM 温度分布图Fig.9.DRAM temperature distributions in core-layout.

表2 不同功率分配时仿真时间Table 2.Improving simulation time of DCM and FEM with different power allocation.

表3 不同功率分配下Core-布局相比于常规布局的芯片温度变化Table 3.Chip temperature change of core layout compared with conventional layout under different power allocation.
在实际工作中, 多核处理器芯片在执行事务时各个Core 会工作在不同功率下, 因此有必要结合不同的Core 功率分配情况, 对两种布局结构的热分布对功率配比的敏感度进行分析.图10 给出了几种典型的Core 功率分配情况, 4 个Core 的总功率值保持为26.5 W, 其中Case1 为大功率事务集中在单侧两个Core, Case2 为大功率事务交错分布, Case3 为大功率集中在外侧Core, Case4 为大功率事务集中在中间两个Core, Case5 为外侧单个Core 大功率工作, Case6 为内侧单个Core 大功率工作.
基于本文所提出的改进DCM 对不同功率分配情况下的DRAM 和处理器芯片的热点温度进行了统计分析.几种情况仿真时间如表2 所列, 在对两种布局的仿真分析中, 改进的DCM 与传统FEM相比仿真速度提升了约30%.
结合图11 和图12 的统计结果, 发现处理器芯片在内侧核高功率的Case6 下热点最高, 功率均匀分配时热点温度最低.DRAM 芯片在Case1 下的热点温度最高, 功率均匀分配时的热点温度最低.由此可见在Core 功率分布不均匀时会加剧热点问题, 因此处理器工作时应尽量保持各核功率分布均匀能有效降低整个微系统的热点温度.同时发现单侧两个Core 处理大功率事务的Case1 以及单核处理大功率事务的Case5, Case6 情况下, 整个微系统的热点温度均会显著升高, 因此在系统设计时应尽量避免这种情况.
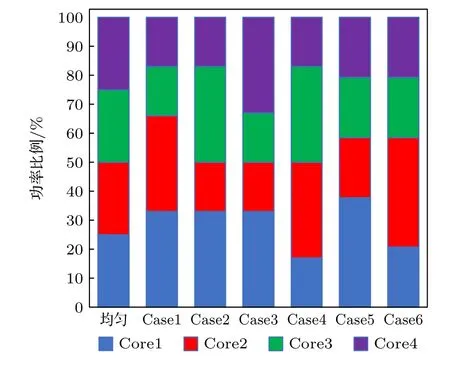
图10 典型Core 功率分配情况Fig.10.Typical core power allocation.
在不同功率配比的情况下, TSV 阵列Core-布局对比常规布局的处理器芯片降温与DRAM 芯片升温情况如表3 所列.可以看出当Core 功率不均匀分布时, Core-布局对处理器芯片的降温效果与功率均匀分布时相比有提升, 同时也加剧了DRAM芯片的升温.比较功率均匀分布与降温最多的Case5, 处理器芯片降温效果提升了42.27%, 而DRAM 芯片的升温上升了82.52%.因此Core-布局在功率不均匀分布时, DRAM 芯片会受到更大影响.在设计三维集成微处理器系统时, 若要降低整体系统的热点温度, 在采用Core-布局时需要考虑到DRAM 芯片能工作在容限温度内.若要降低DRAM 芯片热点温度, 则需要将TSV 阵列即I/O端口布局在远离Core 的区域.

图11 不同功率分配下处理器芯片最高温度Fig.11.Maximum temperature of processor chip under different power allocation.

图12 不同功率分配下DRAM 芯片最高温度Fig.12.Maximum temperature of DRAM chip under different power allocation.
4 总 结
本文针对三维集成微系统的电热耦合问题提出了一种改进的DCM 算法.基于三维集成微处理器系统对所提算法进行了仿真验证, 并对微系统的布局设计、功率分配进行了分析讨论.研究表明:本文提出的改进DCM 能快速准确地对三维集成微系统实现建模计算, 在分析电热耦合问题方面具有显著的时间优势; 在考虑电热耦合因素后, 微系统泄漏功耗上升, 材料热导率下降, 热点温度对比耦合前上升约20 K, 表明了对三维集成微系统进行电热耦合分析的必要性; 在微系统布局设计方面, TSV 阵列的Core-布局虽然能够降低处理器芯片的热点温度, 但却同时恶化了DRAM 芯片的热点问题, 在Core 功率不均匀分配时影响尤为严重.因此在系统设计时, 要综合考虑处理器和DRAM芯片的容限温度来确定TSV 阵列布局方案.综上所述, 本文提出的算法能快速分析三维集成微系统的电热耦合问题, 实现系统热点预测, 为微系统芯片布局设计提供理论指导.
