初始条件优化的正态分布区间灰数NGM(1,1)预测模型
2021-05-06丁圆苹
李 晔, 丁圆苹
(河南农业大学信息与管理科学学院,郑州 450002)
灰色系统理论自20世纪80年代创立以来,因其适用于“小样本、贫信息”特征的数据建模而受到学者们的广泛关注. 灰色预测模型是灰色系统理论的重要分支之一[1],由于其只需要少量数据便可实现预测的特点,已被广泛运用到工程、医疗、农业等多个领域[2-4].
传统灰色预测模型以实数作为研究对象,然而随着科学技术的迅速发展,人们面临的系统变得更加复杂,受认知程度所限,越来越多的数据不能以确切的数值表达,而区间灰数的表示方法则更符合人们对系统内数据的把握和认知[5]. 因此,建立面向区间灰数的预测模型已成为学者们的研究热点之一. 现有文献中,学者们利用“区间灰数白化”的思想,通过信息分解法[6-7]、几何坐标转换法[8-9]、灰色属性法[10-13]将区间灰数序列转化为实数序列,然后对实数序列建立灰色预测模型,再反推得到区间灰数上下界的模拟值和预测值. 但是,上述研究均是在灰数取值分布信息未知的前提下进行的.
在灰色系统理论中,作为描述一个灰数对其取值范围内不同数值“偏爱程度”的白化权函数,在区间灰数预测中受到了学者们的深入研究. 文献[14]定义了白化权函数已知的核与灰度,对已有研究中的核和灰度进行了拓展;文献[15]在典型白化权函数已知的前提下,将区间灰数序列所蕴含的信息转换为面积和中点坐标等实数序列,然后对实数序列建立灰色预测模型,有效解决了白化权函数已知的区间灰数预测问题;文献[16]在文献[15]的基础上对区间灰数的白化过程进行了优化,提出了含有遗传算法的白化权函数已知的区间灰数预测模型;文献[17]建立了三角白化权函数已知的区间灰数预测模型,并将其运用到黄河宁蒙河段巴彦高勒站的凌期日均流量预测;文献[18]以灰色异构序列为建模对象,提出了白化权函数已知的灰色异构数据预测模型,并将其运用到灾害应急物资需求预测. 前述文献均是白化权函数已知的区间灰数预测模型,运用白化权函数对区间灰数的分布信息进行了补充,有效提高了模型的预测精度.
现实生活中大量的不确定性信息符合某种规律分布,而正态分布是存在最为广泛的一种,具有普适性[19].由于其可以用来描述不确定信息的取值概率情况,可被视为一种特殊的白化权函数,并运用到区间灰数预测模型. 文献[19]通过正态分布随机函数实现区间灰数序列与实数序列的信息等效转换,然后对正态分布随机白化序列进行建模;文献[20]结合区间灰数上下界与正态分布参数之间的转换关系以及实数序列之间存在相互影响和相互制约的特点,建立区间灰数MGM(1,2)预测模型. 基于此,本文将以正态分布作为区间灰数的取值信息补充,构建正态分布区间灰数预测模型.
模型精度是判别建模有效性的标准之一,为提升灰色预测模型的建模精度,众多学者对模型初始条件的优化进行研究. 关于初始条件优化主要有三种方法:①设置不同的初始值. 文献[21]在传统灰色预测模型求解初始条件的基础上,增加修正项ε,对初始条件进行优化;文献[22]结合“新信息优先原理”,将x(1)(n)作为初始值从而求得优化的初始条件;文献[23]在文献[22]的基础上进行改进,以x(1)(n)+ε 作为初始值求解初始条件. ②构建目标函数. 文献[24-25]结合模型的时间响应式,构建误差平方和最小的目标函数,进而求得最优初始条件;为体现初始条件优化与模型精度检验的一致性原则,文献[26]建立了相对误差平方和最小的目标函数对初始条件进行优化. ③构建初始条件表达式. 文献[27]根据模型的时间响应式,结合“新信息优先原理”,假设拟合序列经过原始点x(1)(1)和x(1)(n),求得二者对应的初始条件表达式,并取其均值作为优化的初始条件. 前述文献中的初始条件优化方法在一定程度上提高了模型的预测精度,但均忽略了对系统数据的充分利用,对于已经具有灰信息的区间灰数序列造成了信息浪费,影响建模精度.
综上所述,本文基于不确定信息取值概率的正态分布,以非齐次指数形式变化的区间灰数序列为研究对象,建立正态分布区间灰数NGM(1,1)预测模型. 结合正态分布的参数特征,将区间灰数序列转化为实数序列,并对实数序列建立NGM(1,1)模型. 鉴于初始条件对模型精度的影响,受文献[27]中初始条件优化方法的启发,在充分利用数据信息的前提下,结合新信息优先原理对初始条件进行优化,最终反推区间灰数上下界的预测值.
1 基本概念
定义1[19]只知道取值范围而不知道确切取值的数称为灰数,既有下界xL又有上界xU的灰数称为区间灰数,记为⊗∈[xL,xU],xL<xU.
定义2[19]用来描述一个灰数⊗∈[xL,xU]在其取值范围[xL,xU]内对不同数值“偏爱”程度的函数,称为区间灰数的白化权函数. 若“偏爱”程度呈现正态分布特征,则称为正态分布白化权函数,如图1所示.
定义3[19]设连续型区间灰数⊗∈[xL,xU],若真实值d ∈[xL,xU]的取值概率服从正态分布,即d~N(μ,σ2),μ 为数学期望,σ2为方差,则称⊗∈[xL,xU]为正态分布区间灰数.
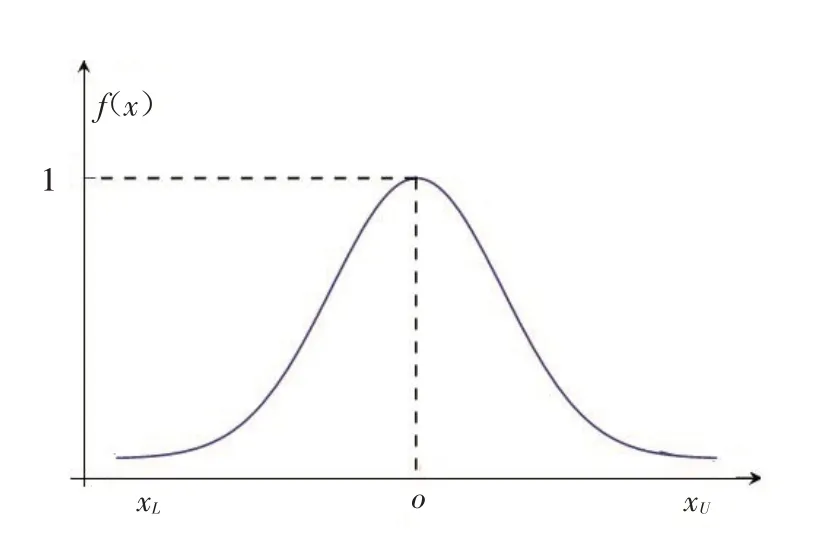
图1 正态分布白化权函数Fig.1 Whitening weight function of normal distribution
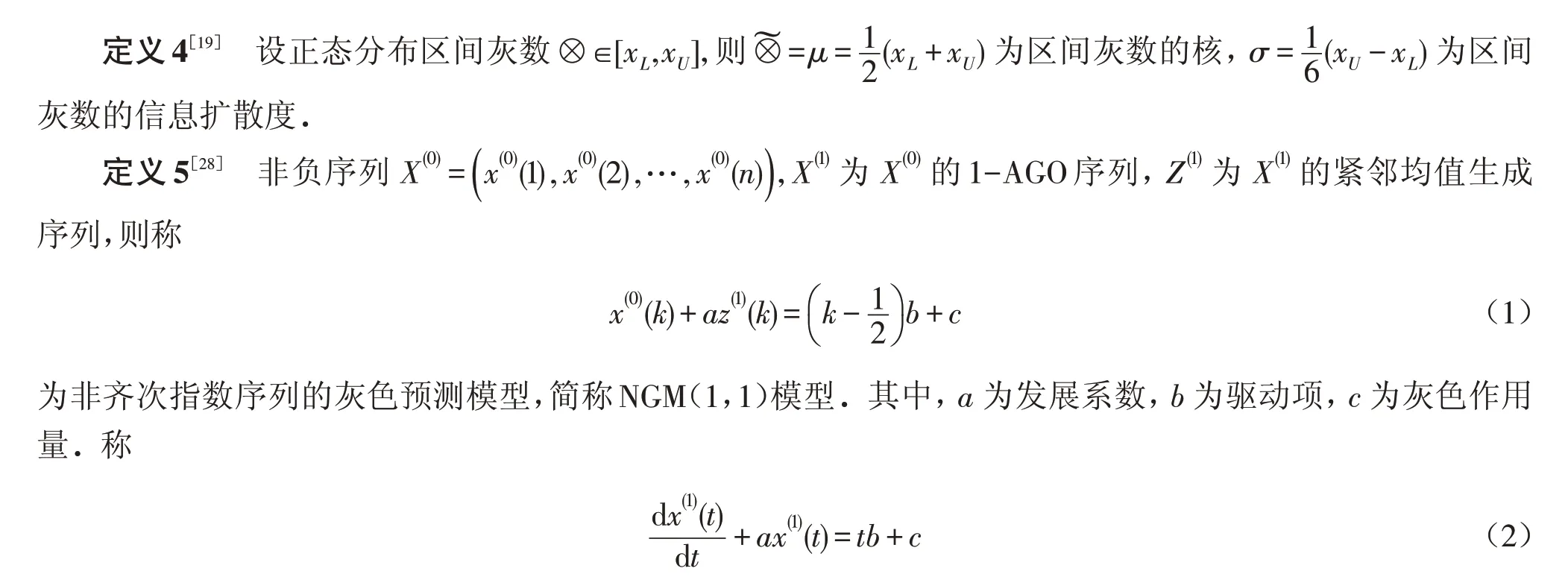
为NGM(1,1)模型的白化方程.

其中:a 为发展系数;b 为驱动项;c 为灰色作用量;D 为初始条件.
证明 根据式(2),在白化方程两侧同乘eat,并进行不定积分,即
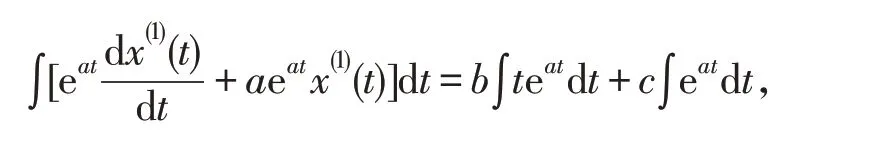
则白化方程的解为

则灰色微分方程的时间响应式函数为

由x^(0)(k)=x(1)(k)-x(1)(k-1)得累减还原式为

2 模型构建
以区间灰数在取值范围内的真实值取值概率呈正态分布作为信息补充,结合正态分布的参数特征,将区间灰数序列等效转换为核序列和信息扩散度序列,以NGM(1,1)模型作为基础模型对实数序列进行建模.由于模型精度受到初始条件的影响,在已有初始条件优化方法的基础上进行改进,充分利用所有的数据信息,求得各点对应的初始条件,并结合新信息优先原理对初始条件赋权,进而构建初始条件优化的正态分布区间灰数NGM(1,1)模型.
2.1 初始条件优化
为了充分利用数据序列信息,本文考虑1-AGO序列中各个分量对预测模型的影响,在假设拟合点与原始点重合的情况下,计算各点对应的初始条件. 此外,基于新信息优先原理,赋予新信息对应的初始条件较大的权重,旧信息对应的初始条件较小的权重,以初始条件的加权平均值作为预测序列优化的初始条件,进而提升模型的预测性能.
设第k 个初始条件对应的权重为α(k),其中

α(k)的变化满足α(1)<α(2)<…<α(n),与新信息优先原理下的权重设置原则一致,具有有效性.
命题1 综合考虑全部数据序列信息,可得优化的初始条件为
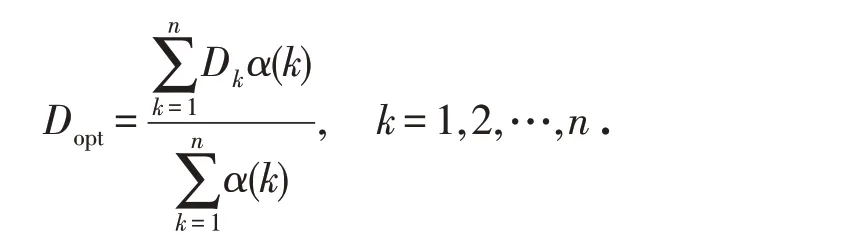
证明 根据式(4),可得
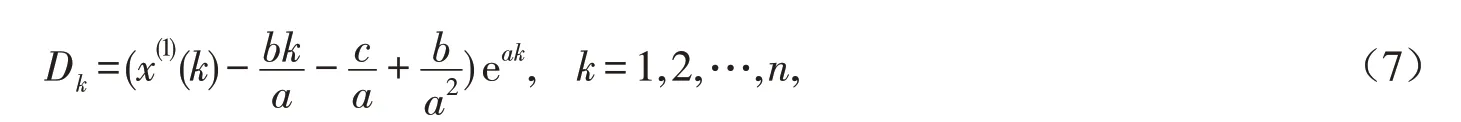
即

结合式(6)及新信息优先原理,优化的初始条件为

定理3 设B、Y 如定理1所述,则NGM(1,1)模型的白化方程在初始条件优化下的解为

则灰色微分方程的时间响应式函数为

累减还原式为

2.2 正态分布区间灰数NGM(1,1)模型
由定义4可知,结合正态分布的参数特征,对正态分布区间灰数白化时,可以实现区间灰数信息的等效转换. 因此,可将正态分布区间灰数序列转化为核序列和信息扩散度序列.
结合定义5,对实数序列分别建立初始条件优化的NGM(1,1)预测模型,可得其累减还原式分别为:

其中:Dopt、a 和b 为初始条件优化的核序列的NGM(1,1)预测模型的参数;D′opt、a′和b′为初始条件优化的信息扩散度序列的NGM(1,1)预测模型的参数.
根据定义4,推导还原得到区间灰数的上下界,即
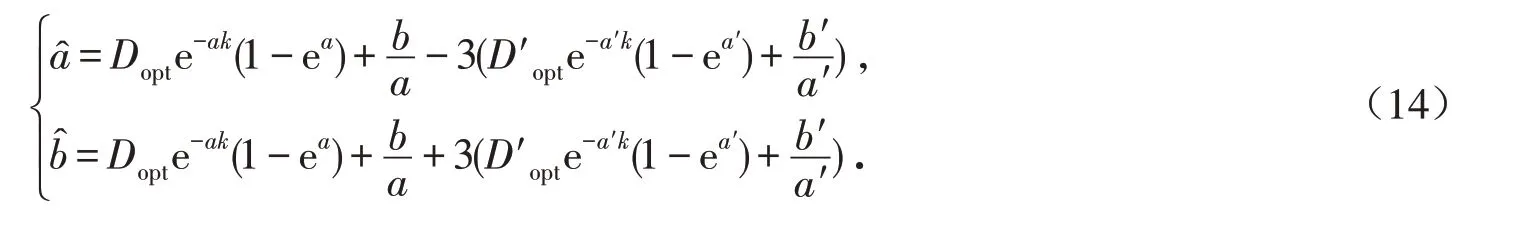
2.3 建模步骤
初始条件优化的正态分布区间灰数NGM(1,1)模型建模步骤如下:
Step1根据定义4,将区间灰数序列转化为核序列和信息扩散度序列;
Step2根据定义5,分别建立核序列和信息扩散度序列的NGM(1,1)模型;
Step3结合式(6)~(9),对所建立的两个NGM(1,1)模型的初始条件进行优化;
Step4 根据式(13)~(14),求得核序列和信息扩散度序列的模拟值并推导区间灰数上下界.
3 算例分析
为证明本文模型的有效性和实用性,利用所建立的初始条件优化的正态分布区间灰数NGM(1,1)模型对某航空公司2008—2018年的航空货运量进行模拟和预测,数据源于文献[29]. 为进一步检验模型的建模效果,同时利用文献[30]中的模型进行建模. 原始数据如表1所示.

表1 某航空公司2008—2018年航空货运量Tab.1 The Air cargo volumes of an airline from 2008 to 2018
以2008—2017年的数据进行建模,对2018年的数据进行预测,具体步骤如下:Step1根据定义4,将区间灰数序列转化为核序列和信息扩散度序列,得

Step2根据定义5,分别建立核序列和信息扩散度序列的NGM(1,1)模型,并结合式(8)~(11)对初始条件进行优化,得

Step3再根据式(13)~(14)推导区间灰数上下界的模拟值. 具体数据见表2.
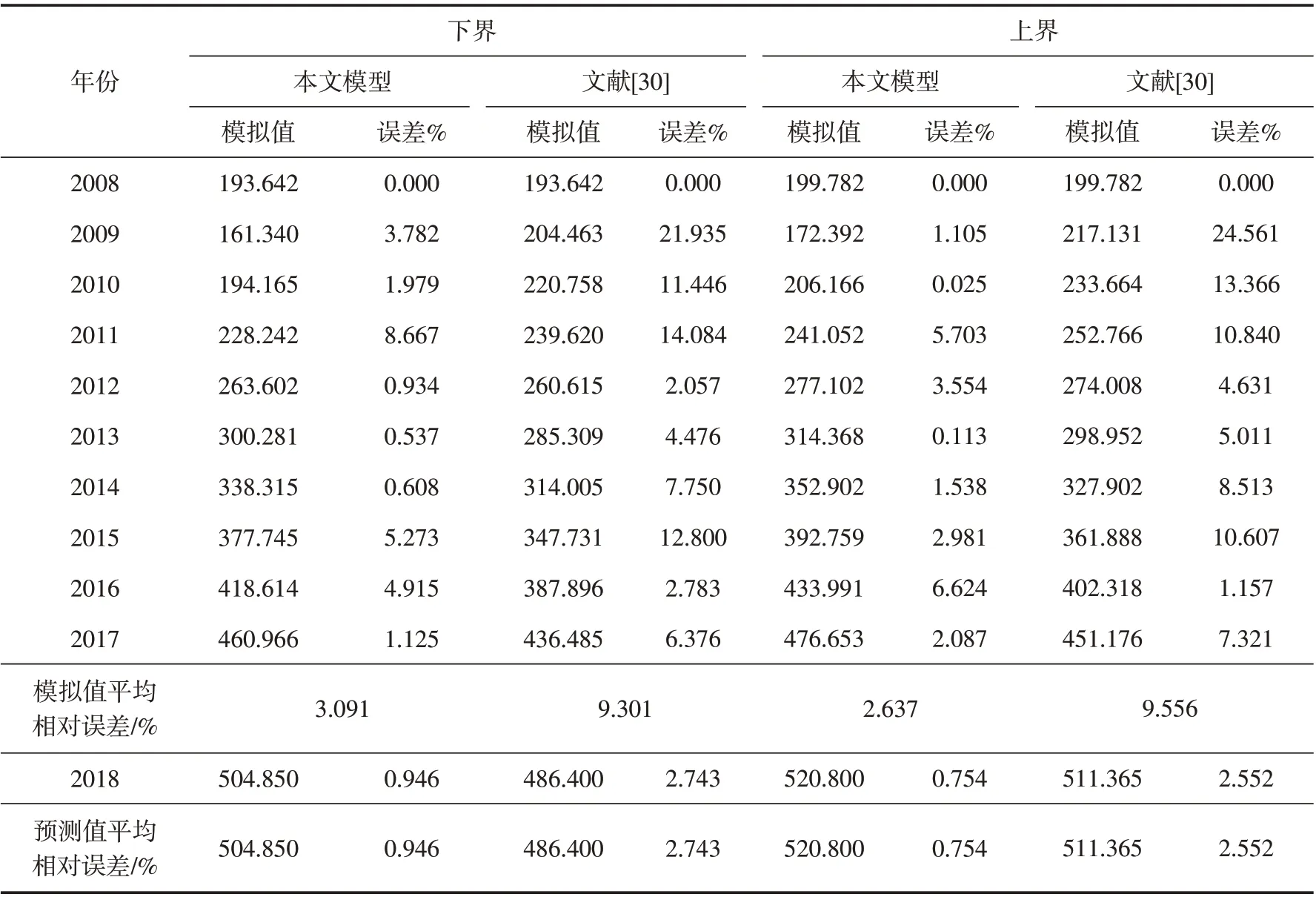
表2 航空货运量的模拟、预测值及误差Tab.2 Simulated values,forecast values and errors of the air cargo volumes
观察表2,本文模型的上、下界平均相对误差分别为2.637%和3.091%,预测误差分别为0.754%和0.946%,均明显优于文献[30]中的模型. 这主要是由于在建模方法方面,文献[30]在缺乏区间灰数取值分布信息的情况下将区间灰数白化为实数序列,而本文以“不确定信息广泛存在正态分布规律”作为区间灰数的取值信息补充,将区间灰数序列等效转化为实数序列,“正态分布”取值信息的补充降低了区间灰数的灰性,有利于模型精度的提升;在模型选择方面,文献[30]选用拟合齐次指数增长的DGM(1,1)模型,本文选用既适用于齐次指数增长,也适用于非齐次指数增长的NGM(1,1)模型,相比较而言,本文选用的模型具有普适性,有利于数据变化规律的挖掘和发展趋势的预测;在模型优化方面,文献[30]未对影响建模精度的初始条件进行优化,而本文结合新信息优先原理对初始条件进行优化,从理论上既能提高建模精度又遵循了灰色系统建模的新信息优先原则. 综上所述,本文的建模方法有利于提升模型预测性能.
4 结语
区间灰数是一种具有灰信息的数据,与实数建模相比,区间灰数建模更为复杂. 本文在不确定信息广泛存在正态分布的背景下,结合正态分布的参数特征,实现了区间灰数序列到实数序列的等效转换,并分别建立实数序列的NGM(1,1)预测模型. 鉴于初始条件对模型精度的影响,充分利用数据序列信息及新信息优先原理对其进行优化. 最后,将模型应用于某航空公司2008—2018年的航空货运量预测,结果表明本文所建立的初始条件优化的正态分布区间灰数NGM(1,1)模型具有有效性和实用性.
