基于噪声处理的网络搜索和QCR-HHT模型的九寨沟客流量预测
2021-04-27李晓炫
李晓炫,吴 奇
(1.阜阳师范大学 经济学院,安徽 阜阳 236037;2.阜阳师范大学 物理与电子工程学院,安徽 阜阳 236037)
0 引言
随着我国社会经济的日益发展,我国旅游行业发展速度逐步加快,各大旅游地的客流量均呈快速上升趋势.旅游产业的周期性强,不同月份之间的客流量差距大,休假制度设计不甚完善导致的节假日旅游需求集中释放现象较为明显.这种强周期性和波动性的客流量波动给景区和旅游目的地造成较大冲击,因景区超载、游客滞留等问题带来的安全隐患对游客出行体验和旅游产业的健康发展产生了诸多不良影响.对客流量的精准预测能够使得旅游经营和管理者提前通过合理调度和配置有限旅游资源的方式最大限度避免这种混乱局面的发生.搜索引擎作为网民信息搜寻的主要工具,捕捉并记录了海量线上信息搜集行为.已有大量研究基于网络搜索实现客流量预测[1-2]、股市价格监控[3]和汇率浮动[4]等.然而不管是旅游客流量还是网络搜索数据,数据统计和搜寻信息过程中都会受到外界噪声信号干扰,导致数据序列存在大量的噪声.这些噪声会影响对于真实游客行为和决策过程的理解并且降低网络搜索数据对社会经济的预测能力,因此噪声是阻碍精准预测旅游客流量的一大根源.
针对信号中噪声的处理方法,在物理学中常用频谱分析技术实现,如小波变化和傅里叶变换.傅里叶变换要求所处理的信号必须是平稳的,并且具有明显区别于噪声的谱特性.然而社会经济中序列信号大多是非平稳序列,因此傅里叶变换受到较大使用限制.小波变换基于傅里叶变换之上,凭借多分辨特性在合适的尺度下,对非平稳信号的有效成分也能识别出与噪声截然不同的谱特性,在获得信噪比增益的同时能够保持对突变信息的良好识辨,因此在处理非平稳信号时具有明显优势[5].HHT变换(Hilbert-Huang Transform)是最新发展起来的用于处理非线性非平稳信号的时频分析方法.它保留了小波变换多分辨的优势,同时克服了小波变换选择小波基的问题,近年来被广泛用于非平稳信号的滤波和去噪.笔者拟利用网络搜索实现对旅游客流量的预测,并具体分析滤噪技术的使用对于提高网络搜索预测精度方面的作用.
对搜索引擎数据的挖掘和分析能够最直接地得到人们的行为模式和决策过程.继2009年某搜索引擎预测美国流感爆发之后,网络搜索数据的预测能力被研究者广泛分析.王长琼等人[6]将神经网络和支持向量机引入,提出了结合网络搜索数据的组合预测模型,将电商网络订单量的预测精度提高了2.67%.李凤岐、李光明[7]在百度指数基础上利用PS方法自动挖掘网络指数与经济指标间的关系,分析了多源搜索数据的预测能力,并实现了网络搜索数据对CPI和CCI这类宏观经济指标的预测.Bangwayo-Skeete和Skeete[8]利用搜索词“酒店”和“机票”的搜索量,结合AR-MIDAS模型对旅游客流量进行预测,对比时间序列基准模型发现,加入网络搜索后的AR-MIDAS模型的预测精度显著提高.Höpken等人[9]预测瑞士山旅游客流量时,提取关键词环节改进了仅利用搜索引擎推荐的方法,选择在关注搜索词多语种表达基础上提取与目标词最相关的搜索词方法,再利用网络数据进行预测时发现预测效果明显优于时间序列模型.然而网络数据的预测并非总是有效的,Volchek等人[10]利用某搜索指数从微观层面对英国5个博物馆旅游客流量预测,分别利用简单线性回归、季节性回归,SARMAX等模型,发现在不同的数据频率上,没有一个模型可以优于其他模型的预测精度.Li等人[11]利用百度指数预测九寨沟旅游客流量时得到类似的结论,发现网络搜索数据的预测效果甚至与简单线性回归模型相差不大.这说明仅简单利用网络搜索数据进行预测,可能受到多种干扰,这些可能会导致网络数据的应用受限.
网络搜索数据的预测能力被很多学者证实,然而不管是搜索数据还是研究对象的统计数据都存在一定的噪声.这些序列信号中的噪声不可避免,而如何处理信号噪声则是在预测中面对的另外一大问题.考虑序列非平稳性非线性特征,HHT变换在处理社会经济数据时具有明显优势.HHT变换是由Hilbert和Huang提出的,主要包括经验模态分解(EMD)和希伯特变换(Hilbert Transform).该方法一经提出就开始在机械故障[12]和地球物理[13]等领域得到广泛的应用.最近开始有学者试图将HHT应用到经济管理中并且发现效果显著.李晓炫等人[14]利用百度指数,将EMD-BP组合预测模型应用于预测九寨沟旅游客流量时,发现EMD分解可以有效识别网络搜索数据中的噪声,相比于时间序列模型、网络搜索预测模型和BP神经网络模型,经过EMD分解后搜索数据预测能力显著提高.陆利军[15]利用张家界旅游客流量数据再一次验证了EMD对分离网络搜索数据噪声的有效性.
笔者拟在之前学者基础上,首先提出基于网络搜索用户搜索路径的关键词提取方法,结合使用HHT方法对搜索数据进行序列的过滤噪声处理,对九寨沟旅游客流量日度数据进行预测,比较滤噪对客流量预测精度的影响效果.
1 Hilbert-Huang 变换
HHT变换包括两个部分:Huang提出的经验模态分解(EMD)和Hilbert谱分析.EMD是针对非线性非平稳序列进行的一种自适应时间序列分解方法,原始序列经过EMD算法分解后,可以得到若干条彼此影响甚微的本征模函数(IMF)向量,这些分量具有不同的尺度,代表了不同频率的序列变动,从而简化了原始序列中不同尺度的特征信息之间的干涉或耦合.各条IMF分量较好满足Hilbert变换对于窄带条件的要求,可以进一步求得IMF分量的Hilbert瞬时频率和Hilbert功率谱,据此识辨出序列中的噪声.
EMD将一条时间序列分解为若干IMF分量和一条残波,每一条IMF分量包含着不同的时间尺度局部特征,并且必须满足两个基本条件:1)在整个事件序列范围内,局部极值个数(极大值和极小值)与过零点个数相差不超过1;2)在任何时间序列范围内,局部均值为0.分解步骤为:1)计算原序列的所有局部极值点.将所有极大值点连接生成上包络线U(t),所有极小值点连接得到下包络线L(t),求得上下包络线之间每一点的均值.用原序列减去均值,得到第一条分量IMF1;2)将上述步骤中求得的IMF1从原序列中分离出来得到剩余序列,重复整个步骤1并逐次得到剩余的各本征模函数IMFs,直到最终剩余的序列是常数或单调函数.
对EMD分解后的IMF分量(设为ci)构造解析信号:
(1)
其幅值函数、相位函数和瞬时频率分别为:
(2)
(3)
(4)
若省略残余分量Rn,原信号Y(t)可表示为:
(5)
(6)
其中,Re表示取信号的实部,式(6)为信号的Hilbert谱.Hilbert谱很好地反映了信号增幅在整个频率轴上随频率和时间变化的规律.
2 实证分析
2.1 数据来源
我国九寨沟在景区网络搜索排名中遥遥领先,成为游客关注的最著名景点之首.加上该地区不存在其他搜索信息干扰,搜索热词几乎跟九寨沟旅游本身密切相关,排除了当地人搜索和与旅游无关搜索的问题.九寨沟的旅游客流量数据来自其官方旅游局网站发布的定期数据,因考虑到2017年8月6日地震灾害导致九寨沟景区损毁重建至今,景区每日将客流量限制在2 000人,笔者截选2012年6月1日至2017年8月6日共1 893天旅游客流量数据.网络搜索数据取自百度指数网站,考虑到搜索的先行性,笔者取搜索数据时间提前于客流量一个月,截选2012年5月1日至2017年8月6日,共计1 924天数据.笔者综合考虑模型稳定性和九寨沟旅游淡旺季的特点,选择2012年6月1日至2016年10月31日为训练集(共1 614天,占样本量85%),2016年11月1日至2017年8月6日为预测集(共279天,占样本量15%).
2.2 QCR(Query Chain Retrieve)——合成搜索指数
百度指数发布的每一个搜索关键词搜索指数都是实际搜索量,笔者采用QCR搜索词条链对搜索数据进行指数合成.网民利用搜索引擎进行信息搜寻时,无法一次性完成所需信息的搜索和收集,往往需要进行一系列的点击和一连串的关联搜索来达到信息收集的目的.从搜索词条链中不仅可以看出网民的搜索轨迹,而且可以通过分析和文本挖掘发现网民的搜索意图和未来时期的决策方向,从而为分析和预测提供一个很好的思路和可能性.一般来说,最初的搜索词条是较为广义的搜索关键词或中心词,在此基础上逐渐通过扩展和修改搜索关键词的方式一步步确定和缩小搜索范围,进而满足自己对于多样化信息的收集.使用搜索引擎的网民数量庞大,而若以每个网民为单位研究搜索词条链,个体样本的选择极易造成样本有偏,进而导致研究和预测的偏差.因此本文的QCR方法是基于所有网民的群体智慧,利用搜索引擎中的全体搜索的来源相关词和去向相关词提取搜索词条链.
根据“百度指数”的定义,“来源相关词”用于反映用户在当前搜索词之前的搜索需求,通过过滤当前搜索词上一步搜索行为来源的相关词,按照相关程度排序得到;“去向相关词”类似,反映用户在当前搜索词之后的搜索需求.因此搜索词条链中每一轮搜索词的选择只依赖于与当前搜索词高度相关的来源词和去向词,即只选择与搜索词相关性最高的前10个来源相关词和去向相关词.具体步骤包括:
1)根据游客的决策目标,选择“九寨沟”为预测目标词,提取出其排名前10的来源搜索词和去向搜索词.网民在搜索“九寨沟”之前,搜索最多相关性最高的词条包括“旅游”“成都”和“九寨沟天气”等,之后搜索最多相关性最高的词条包括“九寨沟旅游”和“九寨沟旅游攻略”.表1所示为以“九寨沟”为中心词的来源和去向相关词.

表1 “九寨沟”的高度来源相关词和去向相关词
2)基于第一轮的选择,将来源相关词和去向相关词中明显与九寨沟旅游无关的搜索词剔除,剩余的搜索词在第二轮中作为中心词,提取出相应的前10个来源相关词和去向相关词,将已经存在的和重复的删除,最后剩余74个有效关键词.
3)分别计算每个搜索词与九寨沟客流量之间提前0~31期的Pearson相关系数.观察每个搜索词与九寨沟客流量相关系数最大的时期,确定为该搜索词相对于九寨沟客流量的提前期.将所有搜索词中提前期为0的剔除.考虑到相关系数阈值的确定对预测结果和噪声产生较大影响,阈值过低会使约束过松,降低搜索指数与客流量相关性并包含过多噪声,阈值过高会使约束条件过于节俭,有遗漏关键搜索词的风险.综合考虑,本文相关系数阈值确定为0.7,共保留28个关键词搜索词条,若将阈值提高到0.8则只剩下5个关键词搜索词条,而若将阈值降低至0.6,则有效关键词多达53个.由此可见过高或过低的阈值选择都不利于对搜索指数的有效筛选和提取.
4)将筛选后保留的28个搜索关键词进行加总,得到合成搜索指数Index7.图1中两个序列之间的变化趋势总体较为一致,吻合度较高,大略显示了利用合成搜索指数对旅游客流量预测的可能性.
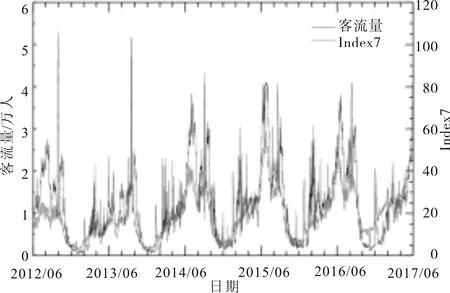
图1 九寨沟旅游客流量与Index7序列图
2.3 HHT变换噪声处理
根据HHT变换,首先利用R语言对合成搜索指数序列Index7进行EMD分解,该软件的EMD程序包主要根据Huang等的EMD算法编程.经过分解获得9条IMF函数序列和一条残差,如图2所示.
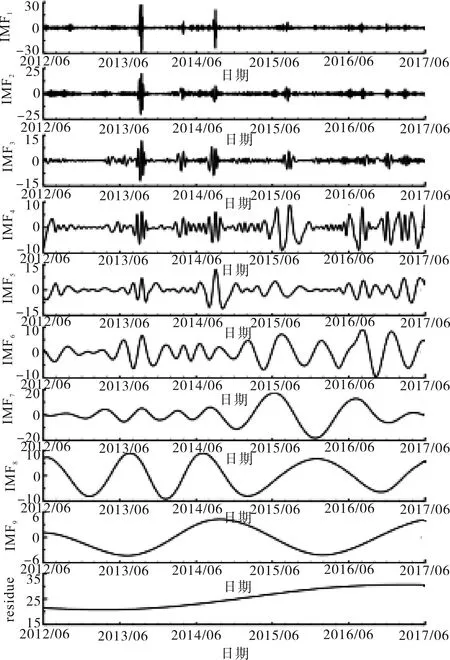
图2 合成搜索指数各IMF分量图
各分量中IMF1具有最高波动频率,接下来各分量的波动依次下降,残差则接近单调函数,表示合成搜索指数的长期变动趋势.在EMD分量分解基础上对各IMF分量作Hilbert谱分析,得到各分量的波动频率,如图3所示.
如图3所示,IMF1分量的瞬时频率在时间轴范围内无法变现出明显频率带,各数据点较为均匀地分布在整个高频区域,将该分量辨别为高频噪声.得到其余各分量与残波的有效信号部分,其加总之和作为HHT去除噪声后的有效序列,表示为Index7_hht.

图3 各分量Hilbert瞬时频率谱
2.4 模型设定和训练
笔者在考虑高频随机噪声干扰的基础上,经过HHT变换将高频随机噪声分离后,得到合成搜索指数的有效序列Index7_hht,对九寨沟旅游客流量进行预测.便于对噪声处理的有效性进行评价,笔者分别选择时间序列ARMA模型,未经噪声处理的网络搜索数据预测ARMAX模型和BP神经网络模型作为基准模型.
visitort=c+α1visitort-1+α2visitort-7+μt,
(7)
visitort=c+β1Index7t-2+μt,
(8)
visitort=c+γ1Index7_hhtt-2+μt.
(9)
其中:visitort代表t时期九寨沟旅游客流量,Index7t-2代表利用QCR搜索词条链合成的搜索指数,它相对于客流量有2天的提前期,Index7_hhtt-2代表经过HHT变换噪声处理后的合成搜索指数序列部分.ADF平稳性检验显示,九寨沟客流量和合成搜索指数序列在5%显著性水平下平稳,且Grager非因果检验显示两序列互为Granger原因.
从表2可以看出,基于网络搜索的M(2)拟合效果略优于时间序列模型,而经过HHT分解去噪后的有效网络搜索序列的M(3)拟合效果则比未分解的模型效果有进一步改善.所有的模型系数均在5%水平下显著.具体的模型拟合结果如式(10)~(12)所示:

表2 模型拟合结果
(10)
(11)
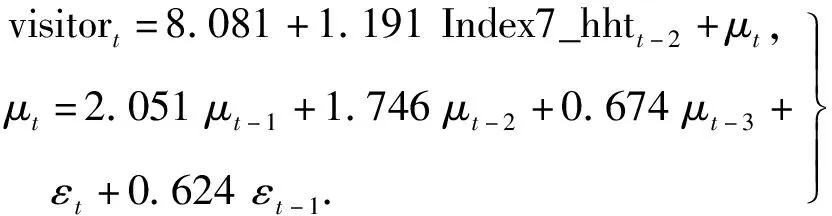
(12)
拟合结果显示,网络搜索与九寨沟客流量之间存在正向相关关系,网络搜索的增加会使未来时期内九寨沟客流量上升,这是因为搜索量的增加表明了网民对于目的地的关注增加,一方面可能是已经计划出行的游客在为即将到来的出行做准备,另一方面可能是受到外界影响开始关注九寨沟并有可能促成未来的实际出行.结果显示网络搜索增加1倍将会引起未来客流量增长约1.275倍,而在式(12)中这一影响效果有所减弱,降低为1.191倍,说明在式(11)中利用网络搜索解释未来客流量增加时,会有一定的高估效应,这与多年来一直讨论的“大数据傲慢”现象是一致的,即网络搜索在预测方面的高估问题.而经过HHT分解去噪后剩余的有效信号部分使得这一高估效应得到了一定的调整.
2.5 模型预测
通过上述的模型训练,发现经过HHT噪声过滤后的网络搜索数据预测模型效果明显优于其他两个模型.为了验证模型的预测效果,在此基础上对预测期内九寨沟客流量进行预测,并与基准模型进行对比.预测效果评估指数有很多,笔者选择MAPE(Mean Absolute Percentage Error)和RMSE(Root Mean Square Error)预测效果评估指数衡量QCR-HHT模型和基准模型的预测误差.基本测算公式如式(13)和(14)所示,相关测算值如表3所示,其中Pi代表预测值,Yi代表原值.
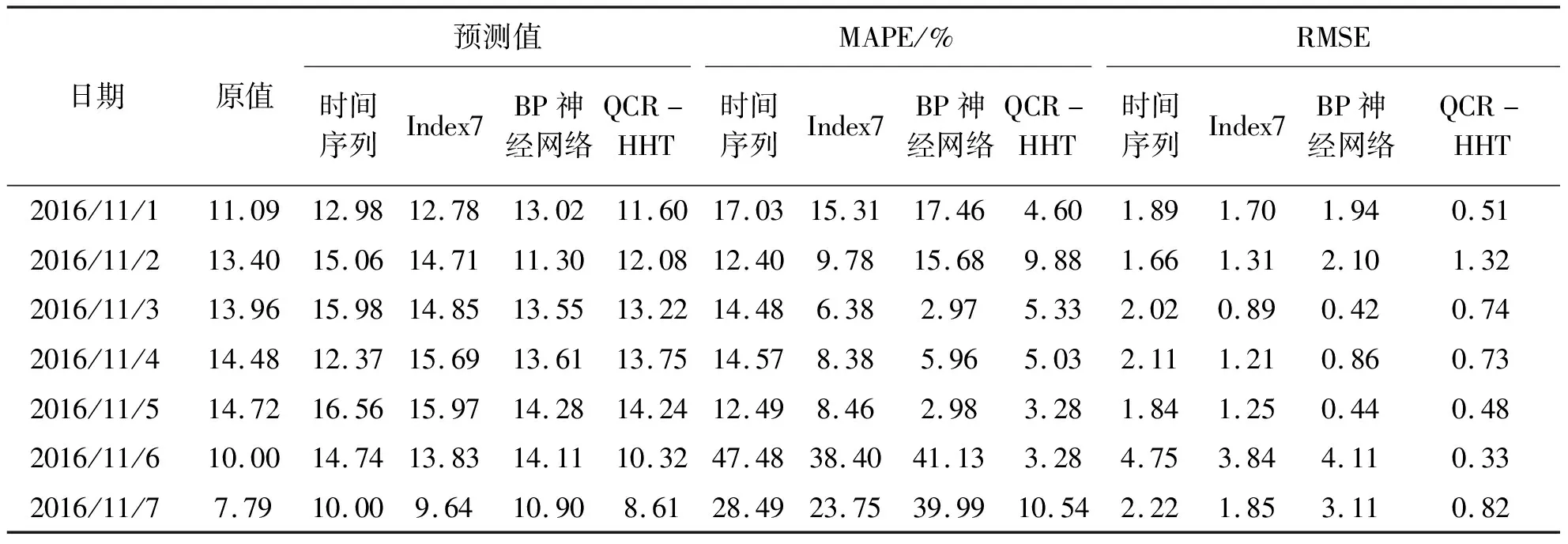
表3 未来7天预测结果和预测误差
(13)
(14)
从未来7期的预测结果和预测误差可知,时间序列的预测效果最差,整体预测误差较高且不稳定,加入网络搜索数据后的预测误差相对有所下降,但与BP神经网络相比,误差相当,说明与机器学习算法相比,网络搜索数据的预测能力并没有太大优势,这也说明了粗糙的大数据对预测应用的能力和提升作用有限.与以上3个基准模型相比,经过QCR-HHT处理的网络搜索数据预测效果有显著提升,未来7期的预测误差有明显下降.未来15期九寨沟客流量预测结果值如图4所示,基于QCR-HHT模型的整体预测值与原客流量序列之间的误差最小.
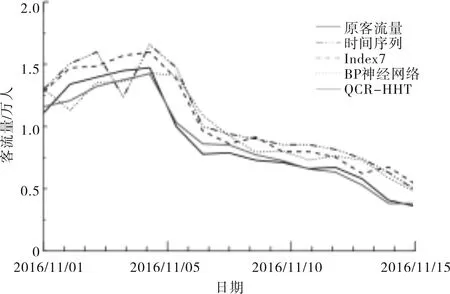
图4 未来15期预测值对比
本文预测期共包含279天,整体预测误差如表4所示.整体预测效果评价中,网络搜索数据预测的模型MAPE最高,其次为BP神经网络,说明在未来时期内搜索数据的预测效果最差,甚至劣于时间序列模型.明显地,利用搜索链和HHT噪声处理后,搜索数据的预测精度最高,279天整体预测误差控制在7.76%,相比于未处理噪声前的预测模型,预测精度提高64%,验证了本文方法可以较好提升网络搜索数据在九寨沟旅游客流量中的预测能力.
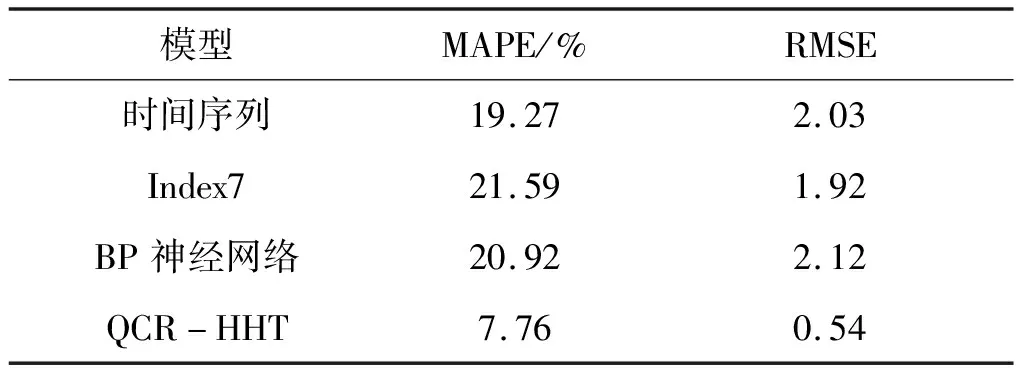
表4 整体预测效果评价
3 结论
笔者针对网络搜索数据在预测中噪声干扰的问题,提出了运用QCR搜索链这种根据网民需求图谱来提取预测词,并利用HHT对网络搜索数据进行噪声处理的方法.该方法一方面改进了传统利用推荐法提取搜索词的技术,另一方面结合EMD分解序列并根据Hilbert谱分析确定各分量序列的频率谱,识别高频噪声并分离.以九寨沟客流量预测为例,引入时间序列、传统网络搜索预测模型和BP神经网络模型作为基准模型,对客流量预测效果进行了实证检验和对比分析.
经过分析得到以下研究结论:1)搜索链技术以网民的搜索路径为关键词提取原则,相比于机器推荐,可以对预测目标有更高的相关性;2)网络搜索数据中由于用户本身搜索的特点,数据中包含大量噪声,这些噪声会影响网络搜索数据的预测效果,甚至导致预测失败;3)HHT变换可以很好地适用旅游客流量这种非线性非平稳数据,经过噪声处理,对网络搜索数据的预测效果有显著提升.
