基于BERT 模型的陆空通话语义校验方法的探究
2021-04-24钟山
钟山
(中国民用航空飞行学院,四川 广汉618307)
随着现代社会经济和科技的发展,民用航空迎来了高速发展,航空运输量也在不断地增加。飞行安全问题一直是民用航空的核心问题,飞行过程中的每一个细节都要注意。Cui Q 和Li Y 等学者提出了民用航空安全效率的概念[1]。有关机构的飞行事故统计报告指出无线电交流中的错误理解是导致操作错误的主要因素,其中很大一部分比例的操作错误又会导致复诵错误[2]。在特纳里夫岛空难中,其他地方的炸弹恐怖袭击使得特纳里夫岛的一个小型机场涌入了大量的飞机,荷兰皇家航空和美国泛美航空的飞机在机场跑道上相撞。事故调查结果中一个没有争议的重要原因就是荷兰皇家航空的飞行员和塔台交流中的理解出现了问题[3]。Shappell S 和Detwiler C 等学者分析了有关的航空飞行事故数据,得出飞行机组和环境方面因素是航空事故的主要原因[4]。由此可以看出陆空通话对于飞行安全的重要性,而陆空通话中发生的一些不经意的小错误就可能会导致飞行安全事故。为了保证陆空通话的正确进行会设置指令复诵环节,有关陆空通话的文件指出高度和速度等关键指令飞行员要全部复诵。陆空通话的指令复诵环节可以纠正飞行员听错指令以及空中管制员发出不正确的指令两种错误,同时飞行员通过指令复诵进一步避免操作失误[5]。指令复诵是为了避免陆空通话发生的错误,而指令复诵的正确与否同样值得关注。人工校验指令复诵会因为某些原因发生错误,所以为了更好地进行复诵指令的校验考虑引入自动校验指令复诵的方法。首先需要将指令的语音信息转化为文本信息,再通过自然语言处理完成指令复诵校验的任务,最后返回校验的结果。大规模语料训练形成的预训练语言模型是自然语言处理领域一个重要的进展,文章对BERT 预训练语言模型应用于陆空通话指令复诵校验的方法逐步展开分析。首先探讨指令复诵校验对应的自然语言处理任务类型,其次根据指令复诵校验任务的特点分析如何应用BERT 预训练语言模型,然后分析BERT 模型的训练步骤。
1 陆空通话语义校验的自然语言处理任务
以下是陆空通话指令复诵校验出现的错误情形。空中交通管制员发出指令:“某某雷达看到,下降到X 米保持”,飞行员复诵指令:“收到,下降到Y 米”,空中交通管制员校验复诵指令之后由于某种原因没有发现复诵错误[6]。此时就需要引入基于自然语言处理的陆空通话复诵校验方法来避免这种错误。指令和复诵的指令都可以看作是句子级别的文本,具体的任务是将两个句子级别的文本作比较核对关键信息是否有差异。对于上述文本任务有两种解决方法:第一种方法是分别用向量的形式表示两个句子的语义然后比较两个向量的相似度。第二种方法是将文本核对任务看作是句子对分类任务,当两个文本的关键信息有差异的时候句子对的联系判断为A,而当两个文本的关键信息一致的时候句子对的联系判断为B。
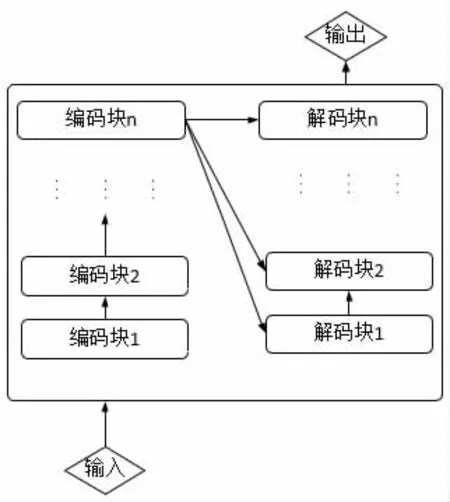
图1 Transformer 模型结构示意图

图2 BERT 模型结构示意图
指令和复诵指令的语义整体差异不大,主要区分的是关键信息,直接计算两个句子的向量相似度难以判断关键信息是否一致。所以将指令复诵校验任务看作是句子对分类任务,使用的模型是BERT 预训练语言模型。
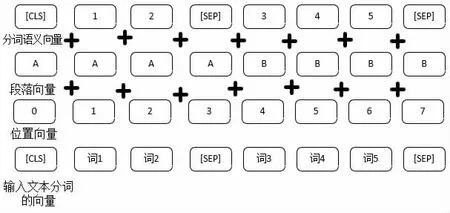
图3 BERT 模型输入向量示意图
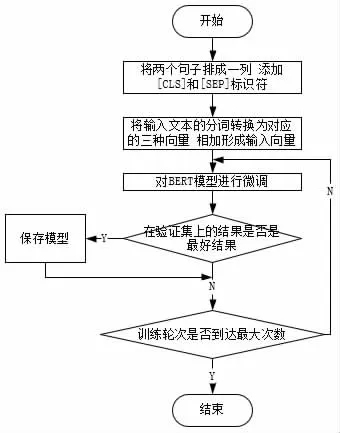
图4 BERT 模型训练步骤示意图
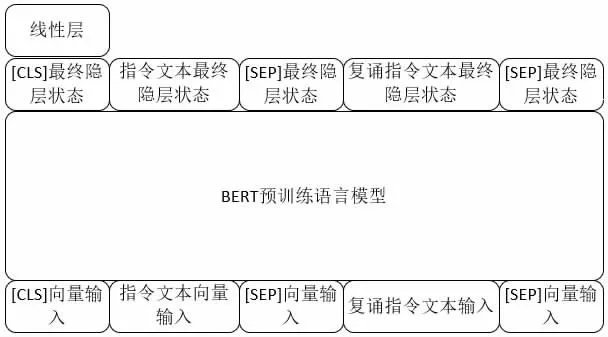
图5 对于陆空通话语义校验任务的BERT 模型结构示意图
2 BERT 模型在陆空通话语义校验中的应用
2.1 BERT 模型的介绍
BERT 模型是一种双向结构的预训练语言模型[7],在很多自然语言处理任务中都有着良好的效果。BERT 模型的内部组成单元是2017 年提出的Transformer 模型[8],Transformer 模型的结构如图1 所示。
BERT 模型采用了随机遮住输入文本部分单词的做法,并且对下一个句子的预测做了特别的设计[7]。所以BERT 模型适合于复诵校验任务,BERT 模型的结构如图2 所示。
2.2 BERT 模型应用于陆空通话语义校验的方法
对于指令和复诵的指令需要转换为向量形式作为输入,BERT 模型的向量输入形式并不仅仅是分词的语义向量而是一种复合向量。BERT 模型为了能够更准确地预测句子对分类结果,引入[SEP]标识符放在每个句子的句末。[CLS]标识符放在整个句子对的首位用于分类任务。将句子转换为输入的向量需要对句子进行分词,然后对分词进行向量化。分词的向量是位置向量、段落向量和分词语义向量三种向量形式之和,具体的细节如图3 所示。
对于BERT 模型的训练步骤,首先将指令和复诵指令的数据放在一列按照图三中的方式加入[CLS]和[SEP]标识符。接着将输入文本进行分词,确定出每个分词的位置向量、段落向量和分词语义向量,对这三种向量进行求和得到文本分词的向量。然后使用文本分词的向量对BERT 模型进行微调。在到达最大训练轮次之前,每一次模型训练完成之后都需要判断当前在验证集上的结果是否是最好的结果,如果是验证集上的最好结果就保存模型。对于陆空通话复诵校验任务的BERT 模型训练步骤如图4 所示。
语义校验的自然语言处理任务本质是一个分类任务,需要判断指令和复诵指令的关键信息是否一致,一致和不一致的情形分别输出不同的类别结果。所以使用[CLS]标识符的最后一层的状态来判断输出的类别结果,在[CLS]标识符的最后一层增加一个线性层就可以得到分类结果,如图5 所示。
文章分析了在自然语言处理中陆空通话语义校验的具体任务类型和BERT 模型对应的训练步骤,对应用于语义校验任务的BERT 模型结构进行了探讨。
