基于ResNet和注意力机制的花卉识别
2021-04-23张梦雨
张梦雨
(河海大学计算机与信息学院,江苏 南京 211100)
0 引 言
近年来,随着人工智能的不断发展,深度学习在图像分类、目标检测、图像分割领域所达到的效果优于传统的机器学习方法,基于深度学习的图像识别技术被广泛应用于缺陷检测、人脸识别、车牌识别、指纹识别等领域[1]。ImageNet竞赛中不断有优秀的网络模型在识别率上实现突破,AlexNet[2]、VGGNet[3]、GoogLeNet[4]相继被提出,并展现出网络层数越来越深的趋势。但通过实验发现简单地堆叠卷积层与池化层搭建的深层网络,会出现梯度消失、梯度爆炸、网络退化等现象,2015年何凯明团队提出的ResNet[5]较好地解决了这些问题。ResNet主要由残差块组成,通过残差块的堆叠可以搭建很深的网络,并且不会出现网络退化现象。
社会不断发展,人们物质生活得到满足,逐渐开始追求精神生活的充实,因此人们游览公园、景点频率提高,但花卉种类繁多,不免有些不认识的品种。随着互联网和智能移动设备的普及,使用设备进行拍摄照片并利用深度学习技术对花卉进行识别变得十分方便,因此花卉识别应用价值较高,同时基于深度学习的图像识别技术又具备很强的泛化能力。
传统的花卉识别方法泛化能力不强[6],随着深度学习成为研究热点,越来越多的学者尝试使用深度神经网络模型进行花卉识别。王丽雯[7]优化AlexNet网络结构和网络顺序后识别精度达到66.3%;刘德建[8]使用LeNet模型对116类花卉进行识别,达到了80%的识别率;林君宇等[9]使用多输入卷积神经网络对花卉及其病症分类,识别率为88.2%,使用迁移学习后识别率提升到94.4%;刘嘉政[10]提出一种基于Inception_v3的深度迁移学习模型的花卉图像识别方法,平均识别率达到93.73%;吴丽娜等[11]提出改进型LeNet-5卷积网络模型,使用随机梯度下降和Dropout相结合的算法将识别率提高到96.5%。
以上深度学习方法均在各类网络模型的基础上进行改进并取得了进步,但简单的浅层网络识别率较低,大型的深层网络模型训练难度大且不适合小型数据集,网络加深容易出现网络退化现象。本文在ResNet34模型中加入通道注意力机制、空间注意力机制,并使用在CIFAR-100数据集上训练好的网络参数进行迁移学习。与传统深度学习模型相比,在花卉数据集上,本文提出的模型识别效果更好。
1 相关技术
1.1 ResNet
深层卷积神经网络在图像分类、目标检测、图像分割领域都取得了良好的效果,随着深度学习的发展,优秀的模型不断涌现出来。但学者们发现并不是网络层数越深效果越好,伴随着网络层数的加深,出现了梯度消失、梯度爆炸、网络退化等问题[12]。为了解决以上问题,He等人[5]提出了ResNet, ResNet由一系列残差块(Residual Block)堆叠而成,并且可以达到成百上千层。
图1为ResNet使用的2种不同的残差块,残差块图1(a)多应用于网络层数较少的网络,残差块图1(b)多应用于层数较深的网络。图1(a)的结构,输入通过2个3×3的卷积层得到一个输出,右边有一个捷径(Shortcut)直接从输入连接到输出,主线经过卷积操作得到的输出通过捷径与输入相加,两者相加之后的结果再通过ReLU激活函数输出。

图1 2种残差块结构
残差块图1(b)主线有3个卷积层分别是1×1、3×3、1×1的卷积层,假设输入是深度为256的特征矩阵,第1层的1×1卷积层起到降维的作用,第3层的1×1卷积层起到升维的作用。这样设置卷积层的目的是为了节省参数,深层网络所使用的残差块越多节省的参数越多,所以图1(b)多用于深层网络。
既然要将主线卷积操作后的输出和捷径相加,那么必须保证主线与捷径的输出特征矩阵的高、宽、深度必须相同,当输入与卷积后输出的特征矩阵深度不同时,要在捷径上加卷积层使两者一致。如图2所示,虚线部分为捷径,捷径上有个1×1卷积层,卷积核个数为主线输出特征矩阵的深度。

图2 捷径带卷积层的残差块结构
假设残差块输入为x,残差块输出为H(x),捷径上的输出与输入一致也为x,模型只需学习残差函数F(x)=H(x)-x,最小化残差函数F(x)即可解决网络退化问题,增强网络性能。
除了使用残差结构来解决网络退化的问题,在ResNet中还使用了批归一化[13](Batch Normalization, BN)。在网络训练过程中,通过归一化使卷积层的输出都满足均值为0、方差为1的分布规律,使激活输入值落在非线性函数对输入比较敏感的区域,此时输入的小变化会导致损失函数较大的变化,让梯度变大,避免梯度消失问题产生。而且梯度变大意味着学习收敛速度快,能加快训练速度,也增强了网络的泛化能力[14]。因此ResNet的卷积层后都要设置一个BN层,通过该方法能够解决网络退化问题、加速网络的收敛并提升识别准确率。深度学习网络模型使用BN时,不需要再使用Dropout。
BN算法如下:
输入:一个批次的样本{x1,x2,…,xm},批大小为m
输出:
{yi=BNγ,β(xi)}

1.2 注意力机制
注意力机制(Attention Mechanism)已经是深度学习领域中一个重要的模块[15-16],注意力机制经常被使用在深度学习模型中以提升模型的分类、识别、预测的准确率。注意力机制是模仿人脑在进行阅读、识图任务时自动忽略低价值的信息,着重关注视觉内有价值的信息或是感兴趣的区域,对这些区域仔细观察,对其他区域进行模糊、忽略处理[17]。人脑利用这一机制可以高效合理地分配有限的资源,快速地从大量信息中定位有价值的目标区域,从而提升观察的效率和准确性[18]。
图像处理领域通常使用注意力机制完成图像识别、图像标注等各类任务,用于卷积网络的注意力机制主要分为2种[19]:空间注意力[20](Spatial Attention)和通道注意力[21](Channel Attention)。
空间注意力机制作用于每张特征图内。传统的卷积神经网络给予特征图的所有区域同等的关注,使用空间注意力机制可以根据特征图每个区域对分类任务效果的贡献程度为该区域进行赋权,特征图内各点的权重不同。空间注意力机制不关注各通道之间的差异,同一区域在各通道上的权重相同。空间注意力机制模型结构如图3所示。

图3 空间注意力机制模型
空间注意力机制下,对输入的特征图F先分别进行全局最大池化和全局平均池化,将两者结果拼接成特征图输入卷积层进行学习,卷积层卷积核大小为7×7、步长为3,最后进入Sigmoid激活函数输出,将激活函数输出结果与之前输入的F对位相乘就是生成的特征,将其记为Ms。用公式表示为:
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))
(1)
其中σ表示Sigmoid函数,f7×7表示卷积核大小为7×7的卷积操作,AvgPool表示全局平均池化,MaxPool表示全局最大池化。
通道间注意力机制作用于特征图之间。在传统的卷积神经网络中,卷积层、池化层等通常对所有通道的特征图进行相同的操作而不对通道进行特殊化处理,给予所有通道相同的关注,但不同卷积核所生成的特征图对识别任务贡献程度不同。因此可以通过通道间注意力机制对不同通道的特征图进行赋权,从而过滤各特征图中包含的信息,根据贡献程度对特征能力提取强的特征图赋予较大的权重,反之赋予较小的权重。图4为通道注意力机制模型结构。

图4 通道注意力机制模型
通道注意力机制下,对输入的特征图F各个通道先分别进行全局最大池化和全局平均池化,之后相加进入2个全连接层,后使用激活函数Sigmoid进行输出,将结果对位相乘加权到之前的特征通道上,更新各通道的特征权重,最终输出结果记为Mc。用公式表示为:
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))
(2)
其中σ表示Sigmoid函数,MLP为多层感知机,AvgPool表示全局平均池化,MaxPool表示全局最大池化。
1.3 迁移学习
迁移学习是利用在一个任务中学习到的知识或模型经过简单调整应用到一个新的任务中。迁移学习主要包含领域(Domain)和任务(Task)这2个重要概念,领域包括源域、目标域,源域指已有的知识,目标域是要学习的新知识,任务是指解决问题的学习系统或者模型[22]。
领域D包含特征空间χ和边缘分布P(X),X={x1,x2,…,xn}∈χ,D={χ,P(X)},源域用DS表示,目标域用DT表示。任务T包含学习函数f(·)和标签空间Y,T={Y,f(·)},通过对数据集{xi,yi}(xi∈χ,yi∈Y)的学习可以得到学习函数f(·),并使用f(·)预测x的标签f(x)。
给定包含标签的源域DS、源域任务TS、目标域DT、目标域任务TT,使用迁移学习就是借助DS、TS提高DT的学习函数f(·)对TT的学习效果,也就是提高识别、预测x的标签f(x)的准确率。
迁移学习按学习方式分类可分为以下4类:实例迁移、特征迁移、关系迁移、模型迁移。模型迁移为模型层面上的迁移学习,其余3类均为数据层面上的迁移学习[23]。图5为迁移学习的分类图。
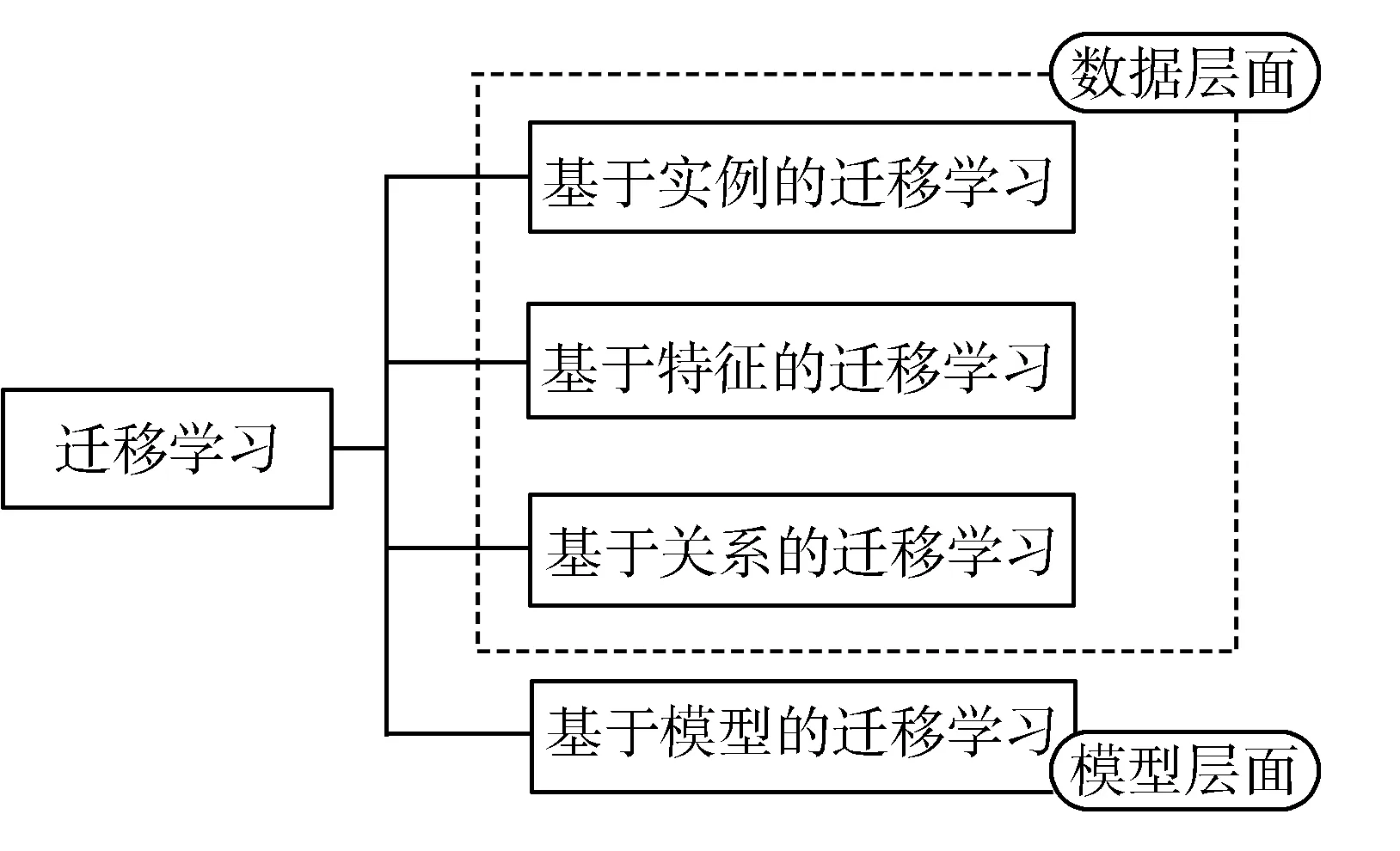
图5 迁移学习的分类
基于模型的迁移学习通过保存训练好的卷积神经网络模型再加上全连接层、分类器就形成新的网络模型[24]。使用基于模型的迁移学习首先保证使用迁移学习的网络结构与源模型一样,模型中数据预处理方式也要一样,这样才可以向卷积网络中载入源模型的权重偏置等参数。接着用适用于新任务的全连接层代替原本的全连接层,形成新的卷积网络模型,最后用新数据集训练新模型。
2 本文模型结构
2.1 在ResNet34中加入注意力机制
本文在ResNet中加入空间注意力机制和通道注意力机制,并将其应用在花卉识别上,使网络模型在训练过程中既关注图像的空间信息又关注通道信息,从而提高分类识别的准确率。基础网络模型使用的是34层ResNet,ResNet34的结构参数见表1。
ResNet34使用的残差结构为图1(a),block1、block2、block3、block4所对应的残差块个数为3、4、6、3,残差单元加起来一共有32层,加上Conv1的7×7卷积层和全连接层一共34层,这里不把池化层算为一层。
本文将通道注意力机制和空间注意力机制串联在一起,将串联的注意力模块应用在ResNet网络中每个残差块之后,还在Conv1卷积层后、池化层前加入注意力模块。加入通道和空间注意力机制的残差块结构如图6所示。

表1 ResNet34网络参数

图6 加入注意力机制的残差块结构图
本文使用的加入通道注意力机制和空间注意力机制的ResNet34网络结构图如图7所示。
图7中,虚线框内是使用不同通道数卷积层的残差块。每个残差块后都加了通道注意力和空间注意力机制,图中表示为CA+SA。虚线框右边为框内残差块的堆叠个数。
图8所展现的是花卉数据在ResNet34模型中类激活图,这种热力图将注意力可视化,注意力机制关注图像中花朵区域,颜色越深表明对识别的贡献越大。
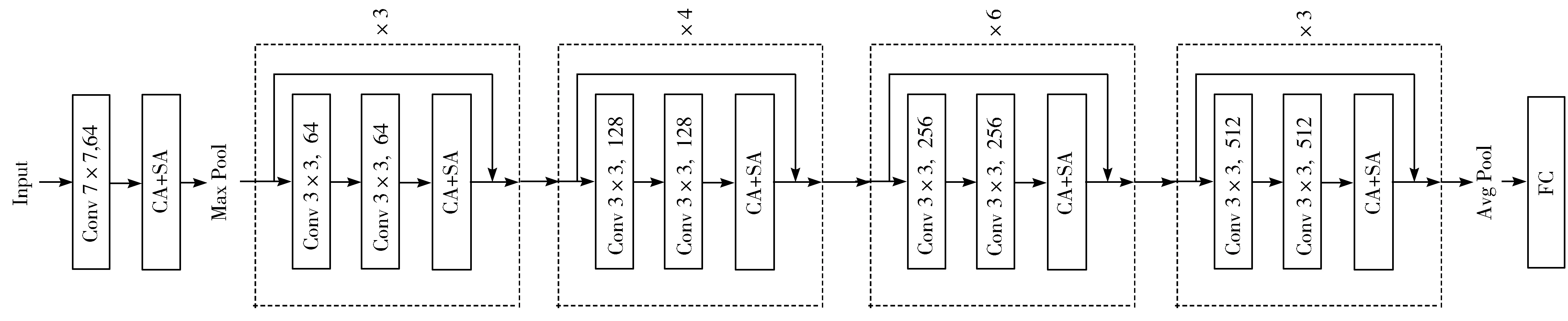
图7 加入注意力机制的ResNet34

图8 原图像与类激活图
2.2 基于模型的迁移学习
为了提高识别率,本文使用基于模型的迁移学习。使用加入注意力机制的ResNet34在CIFAR-100上进行训练,保存网络模型的参数权重等信息,使用花卉数据集对网络进行训练时可以加载在CIFAR-100上训练得到的网络模型参数,这样可以在迭代次数少的情况下取得不错的训练效果,同时提高识别率。在使用迁移学习时,要注意2个模型的预处理方式要一样、模型结构也要一样。迁移学习的大致过程如图9所示。

图9 迁移学习示意图
迁移学习具体步骤:
1)首先将源域数据CIFAR-100送入加入通道、空间注意力机制的ResNet34模型中进行训练,设置学习率为0.0001,批大小为16,迭代100次,设置保存网络模型参数信息的文件路径,训练结束后便可以得到模型权重偏置等参数的文件。
2)设置目标域任务,设置训练模型文件读取路径,源域任务是识别100类,目标域任务是识别5类,更改输出类别数。
3)在花卉数据集上训练模型,新的模型载入预训练模型中的权重偏置等参数,这些参数不包括全连接层,全连接层的参数选择随机初始化。
4)对目标域任务再训练,设置学习率为0.0001,批大小为16,迭代100次,预处理方式与源域任务一致,训练结束得到新的模型与参数。
3 实验与结果分析
3.1 实验数据
实验数据为5类花的3668张图像,数据集包括5个文件夹,分别对应5类花的图片,其中雏菊633张、蒲公英896张、玫瑰641张、向日葵699张、郁金香799张,使用脚本随机分割从各类花中取85%作为训练集、15%作为测试集,训练集共有3118张图像,测试集共有550张图像。
本文实验环境:Win10操作系统,Intel i7-9750处理器,NVIDIA GeForce RTX 2060显卡,Python版本为3.8.0,Pytorch版本为1.4.0,CUDA版本为10.2。
3.2 实验结果与分析
在参数设置方面,优化器选择计算高效的Adam优化器,损失函数选择常用的交叉熵损失函数,学习率设置为0.0001,批大小设置为32,迭代次数为200次。图像训练前进行预处理,包括随机裁剪、随机水平翻转。
先使用ResNet18、ResNet34、ResNet50在花卉数据集上进行训练并对比,实验结果见表2。

表2 不同层数ResNet实验对比
通过实验结果可以看出在本文所使用的花卉数据集上,ResNet34所取得的效果比较好。实验中也发现随着网络加深,每个epoch运行的时间也会随之变长,ResNet50每个epoch运行时间达到了80.4 s,而ResNet18只需40.1 s、ResNet34只需52.2 s。因为训练使用的数据集较少,无法完全展现深层网络的优势,所以ResNet50的效果不是很理想。
再将ResNet34与AlexNet、VGG-16、GoogLeNet等成熟的网络模型进行比较,结果如图10所示,发现ResNet34的准确率要明显高于其他网络。

图10 各模型准确率对比图
具体数值如表3所示。

表3 各模型准确率对比
AlexNet的模型较小,每个epoch训练时间比较短,但是准确率不高;VGG-16网络模型较大,训练每个epoch平均使用了117.2 s,虽然准确率比AlexNet、GoogLeNet高,但是效果没有ResNet34好。综上所述,综合考虑训练难度和识别准确率2方面,ResNet34要优于其余3种成熟并广泛使用的网络模型。
接下来将在ResNet34加入通道、空间注意力机制,并使用迁移学习,迭代训练200次后,最终结果与原模型进行比较。表4为4种模型的准确率对比。

表4 加入AM的ResNet34与原模型比较
使用迁移学习训练的网络模型效果明显要优于原模型,实验过程中在使用预训练权重偏置时,训练第一个epoch识别准确率就已经超过90%,所以迁移学习对于网络学习能力的提升很大。
图11所展现的是加入通道、空间注意力机制使用迁移学习的ResNet34模型与仅使用迁移学习的ResNet34模型在训练过程中每个epoch的准确率对比图。从图中可知,在epoch达到60前,两者识别准确率相差不多,在60个epoch后,加入注意力机制的模型准确率更高。

图11 ResNet34+AM+TL与ResNet34+TL准确率对比
4 结束语
为了提高花卉识别的准确率,本文将空间注意力机制和通道注意力机制加入ResNet模型中,并使用迁移学习,将在CIFAR-100数据集上训练好的模型参数迁移到本文模型中。综合考虑ResNet不同层数模型的分类准确率、训练时间等因素,选择ResNet34作为基础模型更合适,并且在本文使用的花卉数据集上ResNet34的分类效果要比AlexNet、VGG-16、GoogLeNet好。本文提出的加入注意力机制并使用迁移学习的ResNet34模型的识别准确率比原模型提高了6.1个百分点,比仅使用迁移学习的原模型提高了1.1个百分点。
虽然准确率提高了,但是加入注意力机制会导致网络训练过程中参数的增加,因此会增加训练时间,接下来可以研究如何改变模型降低网络参数,在不影响网络性能的前提下,减少因增加注意力机制而增加的参数数量,也可对模型的卷积层进行改进。
