基于生成对抗网络的破损老照片修复
2021-04-23陈圆圆刘惠义
陈圆圆,刘惠义
(河海大学计算机与信息学院,江苏 南京 211100)
0 引 言
老照片作为一段时期的特定影像记录,承载着宝贵的记忆,它有着不可替代的意义。然而老照片由于年代久远、当时技术的不成熟或者保存不当等因素,或多或少出现发黄、折痕、磨损,甚至表层还会出现不规则剥落及破洞现象,需要对这些老照片进行图像修复。图像修复是指在一张图片中存在局部区域破损或缺失,需要利用已有的边缘信息来将这些破损区域进行修复或补全的技术[1-2]。该技术被广泛用于修复受损的图片、文物以及去除不需要的遮挡物等方面[3-4]。
传统的图像修复算法主要包括偏微分算法[5-6]和纹理合成算法[3,7],由于仅利用原图中存留的周边信息,局限性明显。当待修复区域包含复杂、非重复结构时,修复效果不尽人意。
近年来,深度学习在计算机视觉和图像处理领域的研究不断取得进步,使用海量图片对网络进行训练,使得训练好的模型可以具备大量的先验知识,为图像修复提供了另外一种思路[8]。尤其是生成对抗网络[9]的提出,在图像修复领域取得了很好的效果。Pathak等人[10]使用简单的编码解码器作为图像修复的主网络,通过编码部分得出低维特征图,解码部分使用提取到的特征来修复缺损区域并还原整个图像,并使用判别器监督使得修复区域尽可能地和原始图像接近,但是由于通道全连通层的信息瓶颈,使得输出图像的修复区域往往含有视觉伪影,表现出模糊的特征,修补痕迹明显。Denton等人[11]提出了以上下文为条件的对抗网络(CC-GAN),使用编码解码器作为生成器,VGG[12]网络作为判别器,同时加入上下文损失项,使修复痕迹不那么明显。随着研究的深入,Iizuka等人[13]提出了全局和局部双判别器,并通过用空洞卷积[14]代替全连接通道进一步解决了该问题,改善了修复图像的整体性。但是其掩膜专为规则孔洞设计,不适应于破损区域位置不定,且形状不规则的情况。为解决该局限,Liu等人[15]使用非规则化卷积的操作,实现了使用卷积神经网络的方法对非规则化破损区域的修复。但是由于其忽略了上下文之间的连贯性,往往产生语义错误、修复边缘不连续等问题。Yu等人[16]在第二阶段修复网络编码器中加入了注意力层,将图像特征加权平均后输入到解码器中,提升了网络性能。Li等人[17]专门针对人脸图片进行训练,表明了专门针对某一类图片进行训练和网络设计可以让模型较好地学习到该领域的语义信息。此外,Yang等人[18]遵循了图像风格化[19-20]的思想,将图像修复作为一种优化问题,得到的修复区域在内容和风格上有很好的一致性。
标准卷积网络将所有像素当作有效值去计算,造成色彩不协调、模糊等问题,且主要关注图像中心附近的矩形区域,不适应于非规则的情况。本文网络模型中,生成器基于U-net网络的编码解码器架构,采用局部卷积[15]代替所有的卷积层,通过掩膜更新机制仅针对有效区域进行卷积操作,可以合理地处理不规则破损区域。同时,在生成网络解码阶段加入了上下文注意力模块,通过显式地关注远处位置上的相关特征块,更好地捕获长期注意力,从而保持语义连贯性、生成高频纹理细节。判别器采用SN-PatchGAN判别器[21],针对输入图像的不同位置和不同语义(以不同通道表示),直接在输出特征图上的每一点计算损失。此外,借鉴了风格迁移中损失函数的设计,与对抗损失相结合,以此优化生成网络生成图像的细节。
1 局部卷积
Liu等人[15]提出的局部卷积对不规则破损图像的修复表现出了优异的效果。其核心思想如图1所示,每一个局部卷积层包含卷积操作和掩膜更新操作2个部分。掩膜用于控制特征图的处理过程,实现对非规则受损区域的处理。首先,将经掩膜处理后的特征图进行卷积操作,进而更新特征图。在每次完成卷积操作后,掩膜要进行一轮更新。然后,将更新后的掩膜和特征图输入到下一个局部卷积层中,重复以上过程。

图1 局部卷积操作图
在一个卷积窗口的处理中,卷积结果计算如下:
(1)
其中,W与b分别表示卷积的权重和偏置,X为当前卷积窗口的特征值。M为对应该卷积窗口的二元掩膜,1表示有效像素,0表示无效像素。⊙为X与M对应元素的点乘,sum(M)为该窗口下掩膜中像素值为1的像素点个数总和,I与M具有相同的形状,但是所有的元素值都为1。可知,卷积操作仅针对掩膜非0部分对应的图像像素值进行处理,更新的特征图中的值仅取决于非掩膜区域。所以掩膜为0的部分越小,卷积可以获得的信息就越多。在每次卷积操作之后,网络对掩膜进行一次更新,不断缩小掩膜为0的部分,更新方法为:

(2)
掩膜更新同样通过卷积操作实现,如果在一个卷积窗口中,该窗口掩膜值之和大于0,则卷积后的掩膜值置为1,否则仍置为0。通过每次在卷积过程中更新掩膜的方法,在经过多层卷积操作之后,最终掩膜将会全部置为1。
2 上下文注意力机制
卷积神经网络通过卷积核一层一层处理图像特征,无法有效地从图像较远的区域提取信息,往往导致在修复区域会产生扭曲的结构和模糊的纹理,Yu等人[16]提出的上下文注意力很好地克服了这一问题。本文引入该注意力机制,使得模型在生成整幅图像时,不仅考虑边缘部分的约束,而且也考虑了远距离的特征依赖,从而使修复的图像在视觉上更加真实。
如图2所示,上下文注意力的核心思想是首先将输入特征分为目标前景特征(缺失无效区域)和周围背景特征(有效区域),然后从背景特征中提取3×3的背景块,通过维度变化把它们重塑为卷积核,与前景特征执行卷积操作,得出相似度。然后通过Softmax来权衡相关性,最后利用相关性反卷积得到精细的修复区域。

图2 注意力模块
图2中,使用余弦距离计算出前景特征每个位置与每个背景块的相似度。相似度越高,背景特征越有用。
(3)


3 网络模型
如图3所示,生成器网络采用编码解码器结构,包含16个卷积层,编码器8层,解码器8层。将不完整图像和掩膜输入其中,输出生成图像。将生成图像对应掩膜区域的部分与原始真实图像结合以创建Completion图,使缺失部分用预测部分的图,未缺失部分继续用原始的图。将生成的Completion图输入到判别器网络中来判别图片的真假。此外,将生成图像和原始真实图像输入到VGG16特征提取网络中,计算风格损失和感知损失。
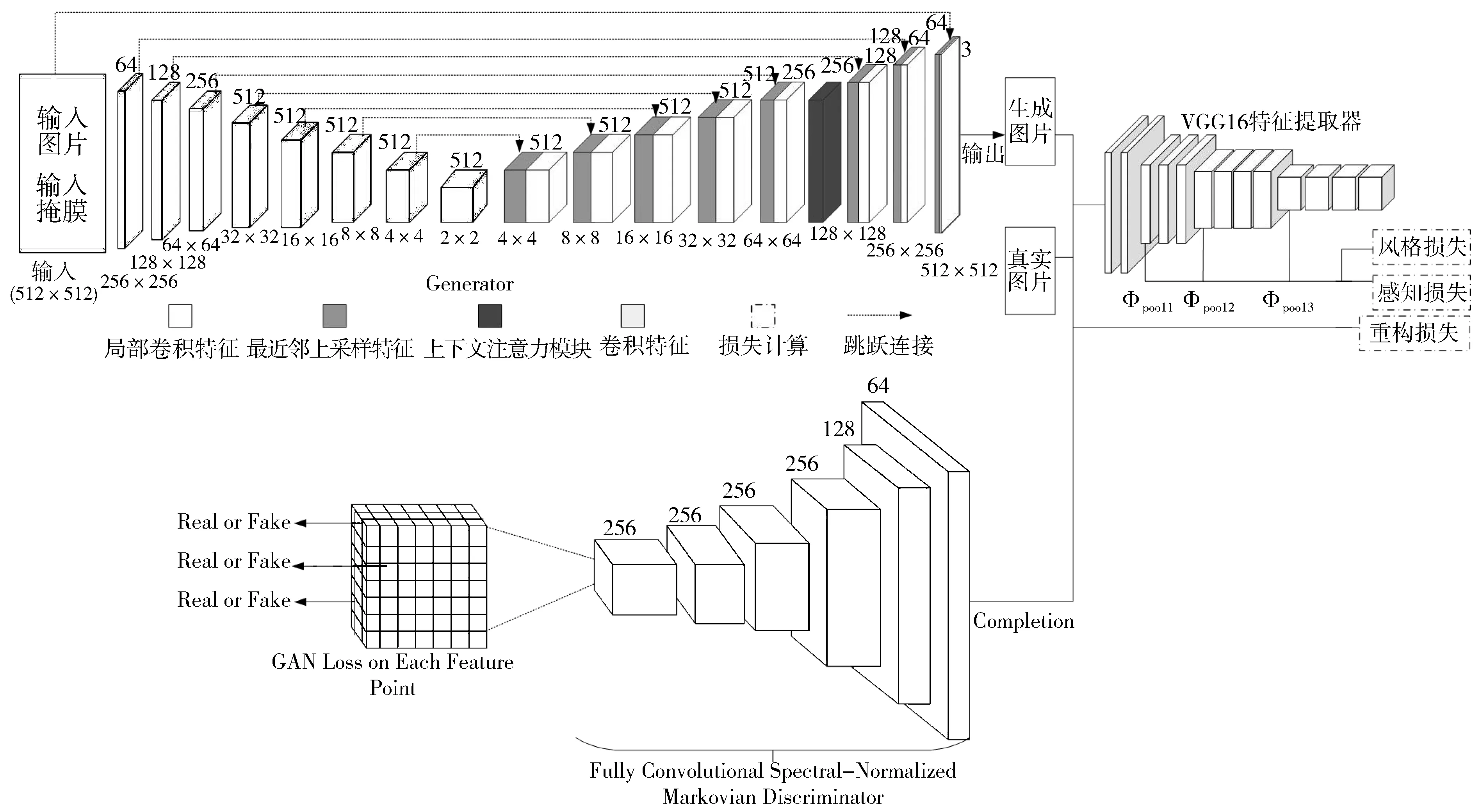
图3 网络模型
3.1 生成器
生成器采用与带有跳跃连接的能够将低级特征直接连接到网络较高层的U-net网络[22]类似的结构,将掩膜与待处理图像同时作为网络的输入,采取端到端的方式进行训练,通过跳跃连接允许与具有相同空间分辨率的上一层连接。此外,网络中所有的卷积层用局部卷积替代。在编码阶段第一层使用大小为7×7的卷积核,在解码阶段都使用大小为3×3的卷积核,其中在解码阶段每一卷积层之前都使用最近邻上采样。跳跃连接分别连接2个特征图和2个掩膜,将最近邻上采样结果与编码阶段中相应的卷积结果连接起来,作为下一个局部卷积层的输入,然后进行局部卷积操作。最后一个局部卷积层的输入包含原始输入图像和掩膜与上采样结果的拼接。除网络的第一层不加批量规范化(Batch Normalization, BN)[23]处理外,其他层都加入BN处理。同时,在编码阶段使用ReLU激活函数,解码阶段最后一层使用tanh激活函数,其余层使用Leaky-ReLU激活函数。
上下文注意力模块以编码后的特征为输入,首先对特征图进行重构,然后解码生成更高质量的修复结果。注意力层过深可能会导致信息细节丢失,为了避免注意力模块误用来自背景特征图的错误信息,输入和掩膜区域应足够大,故将注意力层放在解码阶段倒数第4层之后,其中特征图的大小为64×64。生成器的输出是一个与输入大小相同(512×512)的图像。
3.2 判别器
传统的全局和局部判别器不仅针对图像整体的连贯性,而且关注局部区域的纹理,可是局部判别器只能处理方形且尺寸固定的缺失区域。老照片破损特点往往为折痕,以及于任意位置出现的不规则缺失、磨损等,故以往针对一般规则缺失区域的判别器不再适用。为解决这一问题,受到Markovian GANs[24]、spectral-normalized GANs[25]的启发,采用SN-PatchGAN判别器,将判别器的输出特征图划分为像素级块,直接在特征图的每一像素级特征块上计算对抗损失。由于该判别器对每个具有不同感受域的特征块分别进行分类,因此可针对图像的不同区域分别判别真假,从而可以更好地处理各种可能出现在图像中任意位置、任意大小的破损区域。图3中,判别器由6层卷积层组成,卷积核大小为5×5,步长为2。除了最后一层,每一卷积层后都使用Leaky-ReLU激活函数,此外,为了进一步提高生成对抗网络训练的稳定性,每一卷积层都使用权重归一化技术即谱归一化[25]。
3.3 损失函数
考虑风格一致性和细节水平,损失函数除了对抗损失,同时引入风格损失、感知损失、内容重构损失。感知损失和风格损失使用在ImageNet上预训练过的VGG16作为特征提取网络,比较生成样本和真实样本的深层特征之间的不同,用来生成合理可信的风格。
在原始的生成对抗网络中,生成器的梯度容易消失,因此会导致修复效果不佳。为了解决该问题,采用铰链损失作为目标函数来判别真假,即:
LDsn=Ε[(1-Dsn(Igt)]+Ε[1+Dsn(Icomp)]
(4)
(5)
Icomp=Igt⊙M+G(Iin,M)⊙(1-M)
(6)
其中,Dsn表示谱归一化判别器,G是图像修复网络。Igt、Iin和M分别为真实图像、输入的图像和掩膜。
一般采用归一化L1距离作为重构损失,内容重构损失的计算见式(7)和式(8),分为2个部分:一部分是掩膜对应图像的L1重构损失,另一部分是掩膜之外图像的L1重构损失,即:
Lrec1=‖(1-M)⊙(G(Iin,M)-Igt)‖1
(7)
Lrec2=‖M⊙(G(Iin,M)-Igt)‖1
(8)
对于感知损失,将生成的图像放进预训练过的VGG16特征提取网络中,将pool1、pool2、pool3的特征图与真实样本对应的特征图进行对比。在公式(9)中,H、W、C分别表示高、宽和特征图的通道数,N为VGG16特征提取网络生成的特征图数,即:
(9)
感知损失有助于捕获高级结构,但仍然缺乏保持风格一致性的能力。为解决该问题,本文进一步使用风格损失,从而可以从背景中学习总体风格信息。风格损失的计算同样依赖于从预训练好的VGG16卷积神经网络中提取到的特征以及格拉姆矩阵的计算,计算公式如下:
(10)
(11)


(12)
4 实验结果与分析
4.1 掩膜设计
针对老照片破损部分形状的特点,为了达到更好的修复效果,需要对训练过程中使用的掩膜进行专门的设计,而不再是像以往通过随机移除图像中的矩形区域来在数据集中产生破损区域。掩膜图像是通过使用手动标记的方法对收集到的老照片图像进行粗略的破损区域提取得到,并将提取得到的掩膜图像进行分割、旋转、对称变换、膨胀腐蚀等形态学操作进行扩充。但是由于收集到的破损老照片图像有限,尽管经过大量的变换操作,仍无法得到与大规模的训练数据集的数据规模相匹配的掩膜数量,因此需要对掩膜进行扩充。Liu等人[15]创建了一个随机掩膜数据集,本文从中获得部分掩膜,如图4(i)和图4(j)所示。为了更好地贴合老照片大面积磨损的特点,采取了另一种方法进行扩充,即先随机选取一个点,然后对点周围的受损区域逐渐进行大面积扩展,如图4(k)和图4(l)所示。图4(e)~图4(h)分别为从图4(a)~图4(d)提取得到的掩膜图像。用于训练和测试的掩膜尺寸与图像大小相同,均为512×512。

图4 掩膜示例图
4.2 实验过程
在老照片修复领域,现存的老照片在数量上相对较少,并且不同种类的老照片之间风格和色彩等相差很大。本文建立相应数据集进行训练,以便让模型更好地学习到该领域的语义信息。以往老照片大多为黑白照片,通过图像灰度化算法以及高斯模糊算法对CelebA-HQ数据集进行预处理,生成低分辨率的黑白图像数据集。随机选取27000张图片用来训练,3000张用来测试。此外,在输入到网络之前,将图像大小调整为512×512。

图5 实验结果

图5是在制作的老照片数据集上测试的结果。
针对不同类型、不同破损程度的真实老照片图像进行修复,得到的结果如图6所示。
图像修复质量好坏的评价标准是多方面的,为了充分评估老照片修复的效果,除了视觉上的主观评价外,还结合了客观评价标准。如表1所示,本文采取峰值信噪比(PSNR)和结构相似度(SSIM)这2个指标对不同掩膜率下的修复图像进行定量评估。PSNR是基于误差敏感的图像质量评价,SSIM从亮度、对比度、结构3个方面度量图像相似性。PSNR和SSIM值越高,表示修复效果越好。

图6 修复结果
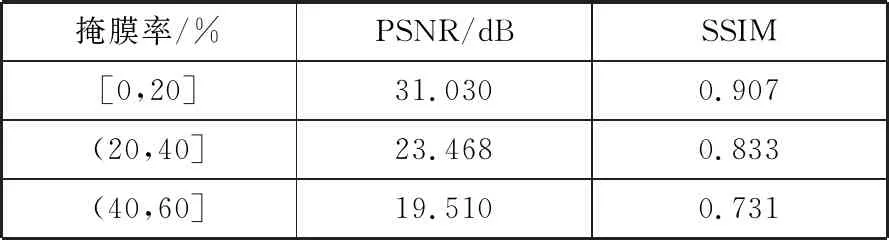
表1 不同掩膜率下的PSNR和SSIM
从以上实际观测效果和图片度量指标中可以看出,本文模型对不同破损情况下的老照片均可以取得较好的修复效果,掩膜所覆盖的非规则破损区域在纹理结构、风格和语义上得到与原图较为相符的修复结果。
5 结束语
本文使用深度学习及生成对抗的方法对老照片进行虚拟修复,取得了较好的修复效果,且不受破损情况的限制,在损失信息极大的情况下仍可以恢复出一个语义上完整的结果图。但对于本身极为模糊的老照片,使用本文模型得到的修复图仍较为模糊,且只能针对黑白照片的破损区域进行修复。如何提高严重模糊图片的修复结果图的清晰度以及赋予其色彩,让斑驳的老照片焕然一新、让记忆中的黑白照更加鲜活,将是下一个研究重点。
