多视角子空间学习研究进展
2021-04-21柳利芳马园园
柳利芳 , 马园园
(1.安阳师范学院 教育学院,河南 安阳 455000; 2.安阳师范学院 计算机与信息工程学院,河南 安阳 455000)
0 引言
信息技术的迅猛发展,使互联网上的信息呈现出指数级增长态势,一些与大数据相关的概念、理论、技术和方法应运而生。纵览与大数据研究相关的成果和项目不难发现其宗旨均在于:从海量数据中充分挖掘、提取知识性信息,进而为科学决策提供建议和支持[1-2]。大数据在对行业管理和技术带来革命性变化的同时,也对研究人员提出了更大的挑战。因大数据固有的“4V”属性,尤其是其种类繁多(Variety)的特性,仅依靠传统的技术和方法难以获取更加符合客观规律的知识和认识。因此,迫切需要开发多视角学习的方法以从多个维度、多个视角对多源异构数据进行充分挖掘和分析,并有效整合,从而提高对复杂事物认识的水平。
多视角学习是针对多源异构数据而设计的一整套信息融合框架和方法,通过有效的整合算法分析来之于同一对象集的不同特性的信息,从而得出更符合客观规律和事实的结论。许多学者提出了行之有效的信息融合策略[3],归纳起来,大致分为三类:1)前整合策略(Early Integration),即将来自不同视角的数据通过级联的方式合成一个独立的数据表示,然后将其用作模型的输入[4-5];2)中整合策略(Intermediate Integration),对多个视角的数据表示进行转化(如计算相似性矩阵),然后将转化后的矩阵通过相应的组合方式整合并用作模型的输入[6-7];3)后整合策略(Late Integration),分别对每个视角的数据进行学习并获得局部结果,然后基于某种准则融合这些局部结果并形成最终的联合判决[8]。
文章主要讨论子空间学习相关算法,并在此基础上进一步讨论这些方法在不同数据集上的表现,并给出了各自的优缺点;最后总结了多视角学习领域面临的挑战和未来的发展趋势。希望通过本文的分析,能够为多源数据的整合提供方法论上的有益借鉴和参考。
1 基本概念
多视角学习方法论体系中包含诸多分支,如协同训练[9]、多核学习[10]、子空间学习[11]等。协同训练其基本思想是利用少量带标记的样本,辅助未标记样本的分类,在训练过程中逐一选取具有最高置信度的样本并将其填充到标记样本训练集中,通过算法的迭代运行不断扩展训练集的范围从而达到对所有样本进行分类的目的[9];多核学习其基本思想是通过使用预先定义的核函数(Kernel function),在训练过程中学习这些核的最优组合参数,以形成一个能用以分类、回归等任务的合成核。多视角学习体系中的这些分支从学习任务上可将其大致归结为分类、聚类和回归,本文主要从聚类的角度来分析和讨论现有的基于子空间的多视角学习技术的发展、原理及趋势。
2 相关算法
基于子空间学习的多视角学习算法旨在通过某种准则(如最大相关系数、最小化目标函数等)来获得多个视角共享的潜在子空间表示,然后基于这个子空间执行聚类、分类、预测等任务,常应用于文本主题识别、生物信息挖掘、机器翻译、图像处理等领域。基于模型假设可将其分为线性子空间学习与非线性子空间学习,线性子空间学习以典型相关分析(Canonical Correlation Analysis, CCA)[11]、费舍尔判别分析(Fisher Discriminant Analysis, FDA)等为代表;非线性子空间学习以核CCA(Kernel CCA)[10-11]及图融合算法[6]为代表。基于多个视角共享子空间的形式可将其分为:最大相关子空间和隐子空间模型。
2.1 基于最大相关子空间的多视角学习模型
该类模型以CCA、Kernel CCA、FDA等为代表,CCA旨在通过最大化典型变量的相关系数(皮尔逊相关),将两个视角的特征数据映射到低维的子空间中去。
CCA将两个视角的数据分别投影到Φx1与Φx2上,在确定选择典型相关变量的数目后,即可在投影子空间中进行聚类、分类、可视化等操作。CCA适用于处理具有线性关系的数据,当原始数据不具备这种特性时,可用Kernel CCA模型来刻画。
2.2 基于低维子空间嵌入的多视角学习模型
文献[12-13]分别对多视角学习方法进行了调研和综述,其中提到子空间嵌入(Subspace embedding)的思想,其实质在于将多个视角的数据同时嵌入(Embedding)到一个共享的空间中,然后再对这个共享的空间降维,属于中整合的范畴。下面给出几种典型的算法。
2.2.1 聚类集成(Clustering ensemble,CE)
聚类集成思想[5]最初由Strehl等人提出,通过对每个源的数据进行聚类(局部聚类),然后将这些局部聚类组合起来形成一个中间类,再对这个中间类进行聚类,以生成最终结果。Greene[4]提出了一种基于矩阵分解的聚类集成方法。
该过程可解决多个视角数据不一致的情况,当样本在不同视角中属于不同的局部聚类时,集成聚类隐式地将不一致的分割融合为一个明确的聚类。
2.2.2 相似网络融合(Similarity network fusion,SNF)
该方法由王波等人于2014年提出[6],在疾病分型、文本聚类等任务中具有较好的表现。其思想在于:通过对不同视角的数据构建相似网络,在保证每个视角所携带的信息能够在其他视角中进行有效传播和利用的同时对这些相似网络进行融合,并形成最终的聚类。
2.2.3 其他模型
除了以上模型外,Han等人还提出了一种稀疏的无监督方法用于多视角学习[14],首先通过主成分分析(Principle component analysis, PCA)得到每个视角的低维子空间表示,然后将这些表示级联起来形成一个新的矩阵,再对这个矩阵进行分解得到最终的聚类指示矩阵。在这个过程中,为了使获得的解具有更好的解释能力,作者还对载荷矩阵(Loading matrix)的列与行分别施以L1范式和结构稀疏诱导范式(Structured sparsity-inducing norm)[15]。此外,相对熵也用于描述子空间中的概率分布,在图像检索和文本分类任务中取得不错的效果。
2.3 基于隐子空间(Latent subspace)的多视角学习模型
隐子空间学习模型假设同一数据集的不同视角间共享一个潜在的子空间表示,与低维子空间嵌入模型不同的是:低维子空间嵌入模型是对原始数据或经处理(如核化)后的数据进行整合,并获得各视角的一致表示矩阵,分类、聚类、回归等任务是基于中间的整合矩阵而进行的;而隐子空间方法在模型构建之初就假定存在一个共享隐子空间,随着模型训练完毕,自动获取该隐子空间的表示。核信息嵌入(Kernel information embedding, KIE)[16]是隐子空间模型的代表。KIE假定两个视角的样本来自一个分布(原始分布),其目的在于通过最大化各视角共享的低维分布和原始分布之间的互信息,来找到不同视角的隐子空间表示;SGPLVM同样假设两个原始的观测空间由一个共同的隐子空间衍生而来,其思想与KIE相同。
最近,基于非负矩阵分解的多视角学习模型也受到了日益广泛的关注,在图像处理、文本聚类、生物信息学等领域涌现出了很多代表性的理论和方法,下面对这些方法做一简单梳理。邻接的多视角非负矩阵分解(Joint Nonngative Matrix Factorization,JNMF)假设在不视角间存在一个共同的聚类模式(低维子空间表示),其默认不同视角的数据间存在一个共同的子空间表示,其缺陷在于不同视角的数据表示可能会因测量误差、环境等因素造成其潜在的结构模式不一致。基于以上考虑,文献[17]提出了一种一致的多视角非负矩阵分解模型(Multi-view Nonnegative Matrix Factorization, Multi-view NMF),该模型假设不同视角间存在一致的聚类模式,在信息融合的过程中,各视角潜在的聚类模式都趋近于这个一致的聚类模式。
文献[18-19]分别从近邻、加权的图近似的角度阐释了基于多图的多视角学习过程,基于多图的多视角学习模型其基本假设同JNMF,都默许各视角间存在一个共同的聚类模式;与JNMF不同的是,在多图融合模型中不仅用图来刻画数据之间复杂、微妙的关系,在矩阵分解和学习过程中还容许不同视角之间存在个性差异,把各个视角之间的共性和个性信息统一于模型的构建和训练之中,更有利于带来算法性能的提升。
2.4 其他多视角学习模型
除了以上多视角学习模型之外,还有许多其他代表性的方法,如基于对称非负矩阵分解的多视角聚类模型(Multi-view Symmetric Nonnegative Matrix Factorization,Multi-SNMF)[1, 7]、基于谱聚类的多视角学习模型(Multi-view Spectral Clustering,MSC)[20]等。损失函数联合优化模型采用同一目标函数同时对多个视角进行联合优化,在最后决策时可选择目标函数最小的视角生成的聚类模式作为最终的聚类。这类方法以协同聚类、协同正则化的多视角聚类等为代表。多视角谱聚类(Multi-view Spectral Clustering,MSC)采用谱方法的优良特性,对多个视角的数据进行协同学习等。
3 实验分析和讨论
为验证多视角学习方法在不同数据集上的性能,本节执行了大量对比实验,实验结果呈现在3.2节中。基于以上讨论,我们在两个公开的多视角数据集上对基准算法和最近几年涌现出的一些新算法执行了大量实验,比较了它们在精度(Accuracy,AC)和标准互信息(Normalized mutual information,NMI)两个指标上表现。
3.1 数据集
1.“Three-source”新闻故事数据集。收集来自BBC、Reuters和Guardian三个在线网站的新闻故事,共包含169个新闻故事。通过手工标注将这三个来源的新闻故事分为6个主题类型:商业、娱乐、健康、政治、体育和技术,更多细节可参见文献[4]。
2.“Human Microbiome Plan,HMP”数据集。该数据集来自“HMP”网站http://hmpdacc.org/,包含三个视角的成分数据:进化谱(phylogenetic profile)、丰度谱(Abundance profile)和代谢谱(Metabolic profile)数据,采自人体7个不同部位(肠道、鼻腔、产道、耳后折痕、牙菌斑、舌背和颊黏膜)的637个样本组成。
3.2 实验结果和讨论
本节实验比较的方法有:最优的单视角和最差的单视角(BSV;WSV);协同正则化的多视角谱聚类算法(MSC);协同训练的多视角谱聚类(Co-training multi-view spectral clustering,Co-training SC)[20];基于相似网络融合的方法SNF[6]、RSNMF[7];基于随机深林(Random forest,RF)和SNF而构建的一类多视角聚类方法(RSNF_Bi、RSNF_Unfm、RSNF_Adpt)[19];基于矩阵分解的方法Multi-view NMF[8]、JNMF、LJ-NMF、LJ-SNMF[17]等。
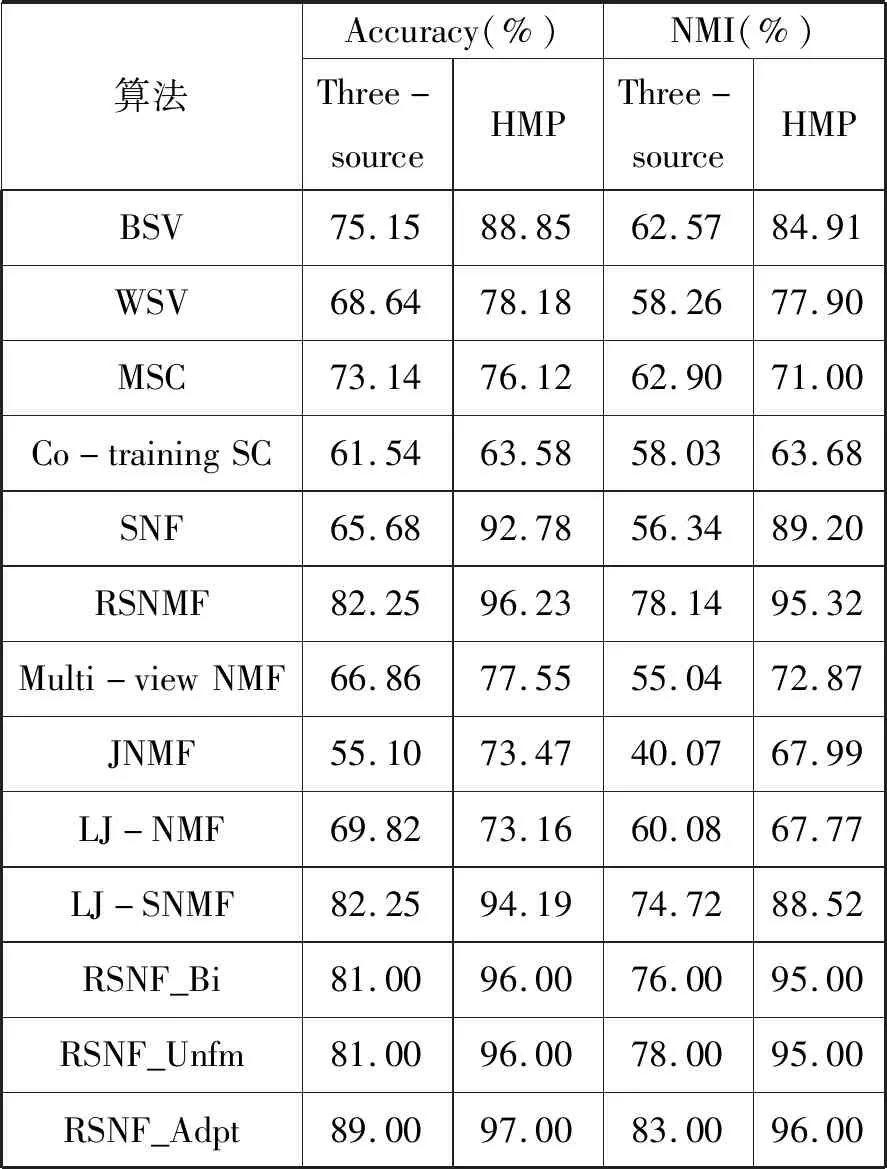
表1 真实数据集上的性能比较
如表1所示,RSNF_Adpt、RSNMF在两个指标上表现最好,说明了鲁棒的关联矩阵的构建会带来模型性能的显著提升;需要指出的是在利用RF生成相似矩阵时,训练模型所需的时间开销会随着树的数目的增多而急剧增加,而RSNMF方法效率相对会高出很多;对于Multi-view NMF、JNMF与LJ-NMF而言,在处理具有复杂关系的数据时(如HMP数据,人类微生物组会受到来自肠道环境、饮食和其他微生物物种的影响),用线性关系来刻画微生物数据的结构模式,效果往往不是十分理想;而对于MSC和Co-training SC,最后生成的子空间是正交的,因此每个特征向量都包含有负元素,造成其解释意义不强;在基于NMF的算法中,其生成的低维子空间中元素的值都是非负的,是一种“软聚类”方法,更符合客观世界中同一个对象具有多个角色的事实,如社交网络中同一个人可能拥有多重身份或社会任职、微生物网络中同一分类的微生物可能在不同的模块中行使不同的功能。
随着多源异构数据的日益增多,近年来涌现出许多新的整合理论和方法,如考虑不同视角间差异和共性的多视角聚类方法、异构网络融合方法等,限于篇幅,不再一一详述。需要注意的是在选择子空间学习算法时,应根据学习的任务和数据的特性选择或设计不同的算法。
4 结论与展望
多视角学习方兴未艾,在提高算法性能和结果可解释性方面尚有许多工作需要开展,主要表现在:
1.体现视角差异与共性的模型构建。不同视角的数据表示可能受测量工具、外在环境、主观因素等的影响,造成其潜在的聚类模式的差异。因此,应同时兼顾跨视角的共性信息和不同视角携带的个性信息,并将其统一于模型构建过程之中。
2.异构网络模块挖掘与关联[21-22]。多视角聚类在异构网络模块挖掘与关联中发挥了愈来愈重要的作用,然而,在异构模块数目的识别、关联与解释性方面中尚有许多工作有待解决,如在微生物互作用网络中如何确定微生物模块的数目;生成的微生物模块是否有聚类意义及如何判定是否显著等。
3.基于半监督的多视角子空间学习。在模型构建中,融入先验知识往往能带来算法性能的显著提升,如何充分利用任务相关的领域知识或背景信息,设计有效的基于半监督的多视角学习算法是研究人员需要考虑的一个问题,也是我们未来研究的一个主要思路。
