基于坐标逆映射的增强型车辆三维全景影像
2021-04-20谭兆一陈白帆
谭兆一,陈白帆
(1.中南大学自动化学院,长沙 410083;2.伦敦大学学院计算机科学系,伦敦WC1E 6BT,英国)
0 引言
随着汽车高级驾驶辅助系统(Advanced Driver Assistance System,ADAS)的发展,用于解决车辆盲区问题的车辆三维全景影像系统(下文简称为“三维全景影像”)越来越普及[1]。这类系统通过安装在车身四周的鱼眼相机来采集图像,经过鱼眼相机参数标定,利用合成算法将采集到的图像生成为虚拟场景,并允许驾驶员调整观察角度[2-7]。三维全景影像系统能够较好地弥补二维全景影像系统[8-10](又称“360 度倒车影像”,即合成一幅鸟瞰全景图)中观察角度有限、显示范围不够大、三维物体显示失真等问题。但由于三维全景影像使用的投影模型中还存在有“地面”部分,所以仍然会对靠近自身的三维物体如车辆和行人产生显示畸变,使驾驶员无法准确判断这些物体位置。而行车过程中,靠近自身的物体往往都具有较大安全隐患,对这些物体的显示不当实则会降低系统的实用性,如图1中箭头所示。

图1 三维全景影像系统对三维物体的显示畸变Fig.1 Display distortion of 3D objects in 3D surround view system
目前,有少量研究对此缺陷进行了改进。文献[11]预先建立了不同长宽比、不同大小的投影模型,后利用雷达感知车身周边环境深度信息,选取最符合当前场景的投影模型,使靠近自身的三维物体投影至模型的“墙面”上而不是“地面”上,从而减少对三维物体的显示畸变。但该方法只可粗略地估计车身周围环境,当环境中出现了多个三维物体时则无法对每个三维物体都做到显示优化。文献[12]结合雷达信息与双目测距原理,共同估计出精确的环境三维信息后,建立符合当前场景的专一性投影模型后进行投影。该方法可以更精确地解决每个大型三维物体的显示畸变问题,但由于需要动态改变投影模型形状导致实时性降低,且形状特殊的投影模型还可能会对其他景物造成投影畸变。
上述两种方法中,都是利用可变式投影模型来解决投影畸变问题,且共同使用了雷达传感器用于测量景深[13-14],这样不仅造成了系统成本的上升还使处理过程复杂化。通过分析可知,行车过程中驾驶员最关心的三维物体只有其他车辆和行人两类(下文将其二者合称为“感兴趣物体”),所以本文综合应用场景特点,提出了一种增强型三维全景影像的合成方法,结合物体检测和坐标升维逆映射,将提前预制的感兴趣物体的三维模型渲染显示在估计位置上,从而解决了上述问题。对比现有解决方案,本文方法具有以下优势:1)可以直观且突出地显示车身周围其他车辆及行人的位置;2)在显示感兴趣物体时不会对其他景物造成投影畸变,整体观感舒适;3)不需要借助其他深度传感器;4)由于可使用固定投影模型,故可利用查找表(Look Up Table,LUT)保证实时性;5)能最大化地在显示中保持地面道路的平直性。综合以上,本文方法具有较高的应用价值。
本文将首先介绍基础三维全景影像的合成算法并浅析其显示畸变成因,之后提出本文的增强型三维全景影像合成方法,最后通过实验验证本文方法的各项性能指标。
1 基础三维全景影像合成算法
基础三维全景影像的合成算法主要包括两大步骤:鱼眼相机标定和投影模型的映射。
1.1 相关参数
映射过程需要基于三个坐标系,分别是世界坐标系、相机坐标系和像素坐标系。先将世界坐标系下的点通过相机外参转换至相机坐标系,而后通过相机内参再转换至像素坐标系。通过两次坐标变换,建立真实世界中的位置坐标与图像中位置坐标的映射关系。
相机外参反映了相机的安装姿态,负责世界坐标系向相机坐标系的映射,映射过程实质为两个三维坐标系的平移旋转变换。变换关系如式(1)所示:

其中:下标w 表示世界坐标系;下标c 表示相机坐标系;[R|T]∈R3×4表示外参矩阵,由旋转和平移两部分构成。
广义的相机内参包括相机内参矩阵和相机畸变参数两部分,其反映的是相机内部光学结构,与相机自身的特性有关,主要负责相机坐标系向像素坐标系的映射过程,是三维到二维的映射过程,同时也是物理长度单位向像素长度单位转换的过程。鱼眼相机内参反映的变换如下:
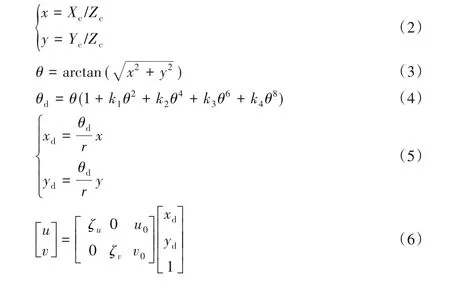
其中:下标c 表示相机坐标系;下标d 表示各变量在鱼眼相机畸变下的表示;k1~k4表示鱼眼相机畸变参数;(u,v)表示像素坐标系下的坐标点;ζu、ζv是在u轴与v轴方向上的长度单位转换因子;u0、v0表示坐标原点平移量,一般分别为图像长宽的一半。
基于上述转换原理,利用张正友标定法,借助相机标定棋盘格分别标定出四路鱼眼相机的内参、外参矩阵及畸变参数[15]。
1.2 投影模型映射
投影模型建立了一个虚拟的车身周边环境,其上的点作为世界坐标系下的点,通过上述映射关系得到对应的像素坐标(即四幅图像中的点),并将对应图像点的RGB(Red,Green,Blue)信息渲染在投影模型上即可完成基础三维全景影像的合成工作。投影模型一般为固定的“碗状”或“船形”模型,根据车辆行驶过程中周边环境的一般特点而建立,即车身四周较近区域为“地面”,而远离车身区域为立体的“墙面”,如图2 所示。使用这样的投影模型可以在多数情况下,能恰到好处地将路面投影至模型“地面”,将车辆等三维物体投影至模型“墙面”,保证物体投影关系正确从而不产生畸变。

图2 三维全景影像使用的投影模型Fig.2 Projection model used for 3D surround view
1.3 畸变分析
由于基础三维全景影像所使用的投影模型是预先按照经验建立的,不可能适应于所有场景,所以当车辆所处的真实三维环境和模拟创建出的投影模型不匹配时将导致显示畸变。畸变主要分为以下两类:第一类是将真实世界中的三维物体错误地映射至投影模型的“地面”区域引起的,从而导致三维物体的剧烈拉伸,如图3(a)所示;第二类是将真实世界中的地面错误地映射至投影模型的“墙面”而引起的,会改变地面道路的平直性,参考图3(b)中道路双黄线的显示弯折。

图3 两类畸变示意图Fig.3 Illustration of two types of distortion
简单地通过改变投影模型大小的方式往往难以同时优化这两类畸变。当扩大投影模型时可以缓解道路弯折畸变,但会让更多车辆及行人等三维物体落入投影模型的“地面”区域从而加重物体拉伸畸变;反之,缩小投影模型虽然可使多数三维物体投影在“墙面”上保证正确,但却无法保证地面道路的平直性,且在动态调整模型的过程中容易出现显示画面跳动,影响显示效果。
2 车辆增强型三维全景影像
由上述分析可知,自适应投影模型方法在解决畸变问题时往往容易“顾此失彼”,所以本文针对显示畸变问题和当前解决方案的不足,提出了一种增强型三维全景影像的合成方法,借助YOLOv4(You Only Look Once v4)检测网络和本文提出的坐标升维逆映射方法,在不动态改变投影模型的基础上,将车辆周边的三维物体以虚拟合成方式重新呈现出来。本文的研究重点将在于如何将感兴趣物体检出并通过图像估计出其准确的世界空间位置。步骤如下:首先把四路相机拍摄到的原始图像作为物体检测网络的输入,识别并框选出所有感兴趣物体;之后利用物体的像素坐标,通过本文提出的坐标升维逆映射方法估计出此物体在世界坐标系中的位置;而后对估计位置进行一系列数据处理后,得到精确的物体位置;最后再把提前建立好的车辆及行人通用模型放置并渲染在估计位置上,它将覆盖显示被错误映射在“地面”上的三维物体。总流程如图4 所示。本文方法可以在解决“物体拉伸畸变”的同时尽量削弱“道路弯折畸变”,在提供准确的物体位置信息的同时使显示更自然。

图4 车辆增强型三维全景影像合成方法流程Fig.4 Flowchart of enhanced vehicle 3D surround view synthesis method
2.1 感兴趣物体检测
近年来,卷经神经网络在物体检测任务中体现出了不可比拟的优势。其中YOLOv4 物体检测网络将物体检测与分类工作都放在一个神经网络中完成,同时很好地兼顾了大、中、小各种尺寸的物体的检测效果,在检测速度极快的同时也保证了极高的准确率与召回率[16]。
本文中,由于物体检测网络将应用在畸变较大的鱼眼相机图像中,因而需要针对鱼眼相机图像训练专一性的检测模型。训练类别分为行人和车辆两类。训练数据由直接采集和软件合成两部分组成。在使用神经网络对感兴趣物体进行预测时,只保留极高置信度的物体边界框,在损失一定召回率的基础上保证较高的检测准确率。将边界框记作其中(u1,v1)和(u2,v2)分别表示边界框左上角与右下角的像素坐标。而后将边界框位置信息送入下一阶段工作——世界位置估计。
2.2 基于坐标升维逆映射的世界位置估计
世界位置估计是本文的核心内容,它是由一系列坐标逆映射来完成的。由于成像过程中,从三维至二维的降维映射会造成信息损失,所以理论上无法完成从像素坐标系到世界坐标系的升维逆映射。但本文根据应用场景特点,利用感兴趣物体在多数情况下都符合“处于地面上”的特征,补充条件Zw=0(下标w 表示世界坐标系)从而使升维逆映射得以完成。
首先对应于补充条件,取检出边界框的下边缘中心点作为物体的“触地点”进行位置估计。触地点像素坐标(ug,vg)可由ug=(u1+u2)/2和vg=v2计算得出(下标g表示“触地点”)。
而后,根据式(6)的逆变换,将“触地点”像素坐标转换为xd与yd。此步骤是像素长度单位向物理长度单位的转换,同时也是坐标原点从图像左上角移动至图像中心的过程。转换如式(7)所示:

之后需要将畸变图像坐标转换至非畸变图像坐标,即将(xd,yd)转换为(x,y)。联立式(5)中两个等式,可计算出θd:

后将θd代入式(4)中。由于式(4)为关于未知量θ的一元高次方程,且为奇次方程,故存在一个实根,可通过二分法迭代求解出未知量θ[8]。而后结合式(3)、(5),完成向非畸变图像坐标系下的转换,如式(9)所示:

之后,将(x,y)代入式(2)继续求逆变换的过程中,如上所述,由于缺少景深信息Zc,使用数学方法则无法完成此步骤。而本文可通过补充的条件Zw=0 计算出Zc,从而完成从二维到三维坐标的逆映射。
由补充条件Zw=0 计算出Zc的过程是基于式(1)的逆运算完成的。为了求逆,先将非方阵形式的外参矩阵[R|T]补全为齐次矩阵表示为D,如式(10)所示:

之后对矩阵D求逆,将求逆结果记作矩阵A,则式(1)的逆过程如式(11)所示:

将已知条件Zw=0 代入,只观察式(11)中Zw的生成过程,可单独列写出如下方程:

结合式(2),可将式(12)继续改写为:

至此,关键附加条件Zc便可获得,而后便可获得此像素点在相机坐标系下的表示,如式(15)。升维逆映射工作完成。

在求得感兴趣物体中心“触地点”在相机坐标系下的表示后,最终通过式(11),可完成最后一步:从相机坐标系到世界坐标系的转换。通过上述步骤,最终可以利用像素坐标点初步估计出感兴趣物体在世界坐标系下的位置。
2.3 重影位置合并
当感兴趣物体同时出现在两相机的交叉视野中且被检出时,两相机会根据2.2 节的位置估计方法分别估计出一个对应的世界位置。由于鱼眼相机畸变及检测框不准确等原因导致两个估计位置一般不重合,则还需对同一物体的两个位置进行合并。
根据感兴趣物体类别,本文使用欧氏距离通过设定不同的距离阈值对小于阈值的两位置点进行合并。如车辆类,若场景中真实存在两辆汽车且被检出,则两个估计点的位置间距应至少大于车辆的长或宽,而小于车辆长宽的两位置点则大概率为重复估计点。所以对于车辆类,将车辆长宽平均值设置为合并距离阈值,对于小于阈值的两点通过计算二者平均位置进行合并,合并效果如图5(b)所示。图5(a)为前后左右四路鱼眼相机拍摄原图及检测结果,图5(b)是对应于图5(a)的感兴趣物体位置估计结果。图5(b)中,中央正方体表示本车,P1位置两圆点为车辆估计位置,两点之间的点为车辆合并位置,P2位置的点表示行人估计位置。由图5(a)可看出由于越野车模型同时在后方、右侧相机图像中被检出,因而有两个估计位置点,而两点位置过近,则需要合并。

图5 感兴趣物体的位置合并Fig.5 Position merging of objects of interest
2.4 路径滤波
在单帧进行估计位置合并后,便可得到连续帧中感兴趣物体的运动轨迹。由于检测网络在每一帧的表现差异,如在某些帧的漏检、误检,会造成同一物体点在帧与帧之间的位置跳动,因此设计一个路径滤波器对跳动点进行平滑滤波。
路径滤波器主要由两部分构成:数据预测和数据融合。
数据预测工作是建立在统计前n次物体位置的变化规律上的。在地面建立二维坐标系xoy,则预测值可由式(16)推导出:
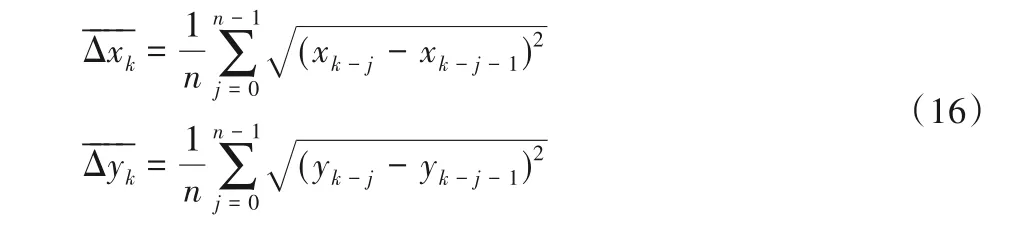
其中:k表示当前帧的序号;n是设定的平滑值数量,表示当前预测值需要依赖于前n帧的物体平均变换规律得出。数值越大,平滑效果越好,但预测的滞后性偏大。数值越小,会损失一定的平滑性但可以提高跟随性能,考虑到系统的实时性要求,设定n=3。之后利用变化量平均值预测下一点的位置,如式(17)所示:

把通过边界框估计出的位置记为测量值,将由前几帧变化趋势预测出的位置记为预测值,则需要在每帧权衡预测值与测量值之间的关系进行数据融合。参考卡尔曼滤波原理,使用动态权重方法来权衡输出值的构成比例。由于精度要求不高,将权重设为两档离散型。利用每帧测量值和预测值的欧氏距离作为衡量标准,并确定合适的阈值,当距离大于此阈值时,便认为测量值出现错误,动态调整测量值的权重为一个很小的值,使其对输出的影响降至最小;反之恢复正常权重比。阈值根据帧率按类别设定。如车辆类,若已知帧与帧间隔时间为t,车辆行驶平均速度估计为vˉ,则设定距离阈值为·t。
图6 展现了使用路径滤波器对物体运动轨迹进行滤波的效果。图6(a)为不使用路径滤波器对车辆及行人运动轨迹估计的结果,图6(b)为使用路径滤波器后的输出轨迹。结果显示滤波器对误检测点有很好的过滤作用,保证了感兴趣物体运动轨迹的连贯性。

图6 路径滤波器对两次运动轨迹的滤波结果Fig.6 Filtering results of two motion trajectories using path filter
2.5 模型放置与渲染
本文使用3ds Max 对需要虚拟显示的车辆和行人进行建模。由于四路鱼眼相机安装在车身四周且向外拍摄,则无法获取当前自身车辆的图像,因而需要提前建立本车模型并放置在场景中心以遮盖合成场景中图像信息缺失部分。而后,对其他车辆和行人两类物体建立通用模型,并结合上述估计出的位置将通用模型放置并渲染在三维场景中,用于更好地展现被错误映射而产生畸变的相应三维物体。
3 实验与结果分析
3.1 实验平台
本文方法在实现时共分为两大部分:对三维场景的生成和对神经网络的训练。笔记本电脑负责完成场景生成工作,硬件配置为CPU:i7-7500U,GPU:Nvidia GeForce 940MX 2 GB显卡,运行内存8 GB。台式服务器用于训练神经网络,配置为CPU:AMD Ryzen5,GPU:Nvidia RTX2080 8 GB显卡,运行内存16 GB。
软件配置方面,场景生成工作借助于OpenCV 和OpenGL共同完成。在OpenCV 中完成相机标定、相机图像读取、地面二维全景图像合成工作,在OpenGL 中借助OpenCV 生成的地面贴图和读取的四路相机图像完成三维环境的渲染工作,基于开发平台Visual Studio 2017,使用C++语言编写;神经网络训练基于PyTorch 框架,基于开发平台PyCharm,使用Python语言编写,并使用 CUDA(Compute Unified Device Architecture)加速。
鱼眼相机视场角为180°,使用分辨率640×480,帧率为30 frame/s。光屏传感器型号为CMOS 1/2.7,成像距离为2 cm至无穷远。
搭建了模拟道路为测试环境,使用长宽高分别为400 mm×300 mm×200 mm的箱子固定四路鱼眼相机,使用汽车和行人模型进行检测实验。如图7是搭建的实验环境。

图7 实验环境Fig.7 Experimental environment
3.2 模型训练
由于输入图像为鱼眼相机畸变图像,所以需要在YOLOv4 预训练模型的基础上微调训练以适应于本研究的应用场景。训练数据来源于两部分:一部分为采集到的四路鱼眼相机的视频流,以5 frame/s 帧率保存四路相机图片,最终共获得约860 张图片并进行手动标注;另一部分来源于计算机的自动生成。式(2)~(6)描述了从小孔相机模型至鱼眼相机模型的映射关系,因而可以将普通非畸变图像利用上式转换为鱼眼相机图像,并与多种背景相融合,可批量快速生成大量带有标注的训练数据,尤其适合在传统大型数据集的基础上快速生成大量鱼眼相机训练数据,如ImageNet、MS COCO(MicroSoft Common Objects in COntext)实验中通过此方法共生成约3 000 张图片。如图8 所示,无畸变的原始图片通过调整参数可分别获得具有不同畸变程度和不同畸变位置的鱼眼图像,从而模拟真实鱼眼相机拍摄到的图像。

图8 计算机自动生成的模拟鱼眼畸变图像Fig.8 Simulated fisheye distortion images generated by computer automatically
最终总计获得约3 800 张训练数据,将其以1∶10 比例分成验证集与训练集。实际训练代数(epoch)为200。由于物体检测不是本文的研究重点,同时也受限于微缩模型下车辆与行人种类少的因素,所以训练集数据量偏小,但最终模型检测效果达到要求。
3.3 主观评价指标
图9 对比了使用与没有使用本文方法时,在同一视角、同一场景下的显示效果。图9(a)为使用本文的增强型三维全景影像合成方法生成的画面,行人和车辆都通过三维模型在场景中清晰地呈现了出来,可以极大地方便驾驶员观察。图9(b)表示使用基础三维全景影像系统的显示效果,当车辆或行人处于投影模型的“地面”区域时,系统则会对这些物体造成投影畸变,使驾驶员无法准确获取车身周边物体的位置信息,甚至无法看清物体。

图9 同一场景下的两方法的显示效果对比Fig.9 Comparison of display effects of two methods in same scene
图10 对比了当其他车辆分别以不同距离经过本车侧边的显示效果。本文方法同样将这种距离的差别反映在了模型的位置上,验证了本文中位置估计方法的精确度和可靠性。

图10 其他车辆以不同距离经过车身侧面时的显示效果Fig.10 Display effects when another vehicle passing by vehicle body with different distances
同时,对比起现有解决方案[11],本文方法由于无须通过缩小投影模型的方法使三维物体显示正确,因此可以最大化地扩大模型中的地面部分,从而可以更好地削弱“道路弯折畸变”,即尽可能地保持路面的平直性。如图11 所示:图11(a)是使用本文方法的显示效果,投影模型大小设置为3 000 mm×3 000 mm,可通过观察路面双黄线得知道路基本平直。而现有解决方案(自适应模型法)只能通过缩小投影模型方法使三维物体映射在“墙面”上,如图11(b)所示。此时投影模型的大小为700 mm×700 mm,虽然对侧方车辆做到了良好的显示,但图像中明显对路面造成了极大的弯折。每幅图左下角为当前投影模型大小展示。
图12 进一步地探究了当本文系统工作于复杂环境时的表现。图12(a)为本文系统工作于多车辆复杂场景中的显示效果,图12(b)为与之对应的基础三维全景影像的显示效果,可知系统在处理多个车辆位置时也能够保证每个车辆位置估计的准确性。图12(c)、(d)为当系统工作在雨天环境下,摄像头上出现水滴时的物体检测情况。由于YOLOv4 算法中使用了例如模糊、透明叠加等多种数据增强方法,因而在多数情况下都能将车辆正确检出,如图12(c)中检出的两辆已经被水滴模糊的汽车;而在少数情况下,如图12(d)所示,由于水滴造成车辆形变过大,检测网络则无法检出,但当车辆动态行驶不断改变位置时,未被检出车辆仍有可能在前后帧中被检出。

图11 两方法在解决三维物体显示失真问题上的效果Fig.11 Display effect of two methods in solving 3D object display distortion problem

图12 本文系统在复杂场景下的表现Fig.12 Performance of proposed system in complex scenes
3.4 客观评价指标
由于需要在行车过程中实时显示车辆周边情况,所以要求画面不能出现卡顿现象,因此给本文影像生成方法的实时性提出了很高的要求,所以将首先验证本文方法的实时性。而后再对本文方法中物体检测及位置估计的准确性做定量测试。
在场景生成中共分为两部分:使用OpenCV 生成地面部分,使用OpenGL 渲染场景部分。前者在使用OpenCV 逐点生成“地面”时,使用查找表(LUT)方法,将映射关系的计算放在程序初始化时完成并保存,实时渲染时只需查表即可,从而降低了单帧处理时间。表1 显示了在不同“地面”分辨率下的相关生成时间。

表1 投影模型“地面”部分生成用时 单位:sTab.1 Time taken of generating“ground”part of projection model unit:s
而对于后者OpenGL 渲染三维场景部分,对比起基础三维全景合成算法,由于本文方法在场景渲染时需要额外渲染行人、其他车辆等模型,因而需要耗费更多时间。表2 为渲染时间对比,共随机选取5 帧。对比起基础算法的渲染时间,本文方法渲染时间确实有所增加,但渲染时间仍处于较低水平,不对实时性造成影响。

表2 渲染时间对比 单位:msTab.2 Comparison of rendering time unit:ms
最后,在300×300 的地面分辨率下,结合YOLOv4 网络检测时间、位置估计时间、数据处理时间及上述场景生成时间,本文方法单帧平均处理时间为0.033 9 s,帧率约为30 frame/s,满足实时性要求。
在实时性满足要求后,继续验证本文方法中物体检测与位置估计的准确性。物体检测由YOLOv4 网络完成,相较于前代YOLOv3 网络[17],在保证检测速度基本不变的同时提高了检测准确度。实验中使用相同训练数据分别训练了YOLOv4 与YOLOv3 网络,并选取50 帧图片,每帧图片中包含四幅图像与若干感兴趣物体,两个网络对感兴趣物体的检测效果如表3 所示。其中:晴天/雨天检出率等于正确检测出的物体次数除以物体出现总次数;晴天误检率为检测错误次数除以检出总数。

表3 YOLOv4与YOLOv3网络检测准确率对比 单位:%Tab.3 Comparison of network detection accuracy rates between YOLOv4 and YOLOv3 unit:%
之后测试本文方法位置估计的准确性,通过拉动模型车辆使其按照提前设定好的路径经过车身,然后计算整个过程中估计位置与实际位置的平均误差来实现。实验中,共测试了三条路径,并将三条路径的直线方程通过建立地面二维坐标系表达了出来,如图13 所示:每幅图中心长方形表示本车位置,离散的点为本文方法对模型车辆每帧的估计位置,图片下方的直线方程为上述模型车辆的实际运动轨迹。最终在三条测试路径下,位置估计的平均误差见表4,并按照误差比例计算出实际道路使用时的真实估计误差。

图13 本文方法对三条路径的估计结果Fig.13 Estimation results of three paths by using proposed method
表4 中:测试路径分别为图13(a)、(b)、(c)中的三条路径。误差比例等于估计值平均误差/模型车宽(300 mm),道路误差通过误差比例合理外推到真车比例,以普通乘用车宽(1 800 mm)乘以误差比例得到。考虑到本文方法中对其他车辆及行人的显示主要以辅助驾驶为目的,且小于10 cm的位置误差在高速行车时仍可忽略,因此在位置估计精度方面同样满足要求。

表4 三条路径中位置估计平均误差Tab.4 Average error of position estimation in three paths
4 结语
本文在现有车辆三维全景影像合成算法的基础上提出了一种基于坐标升维逆映射的增强型车辆三维全景影像合成方法,用于解决原系统中对周边三维物体的显示畸变问题。本文方法首先利用YOLOv4 网络检测每幅图像中的感兴趣物体位置,之后利用鱼眼相机标定参数结合补充条件推导出从像素坐标系转换到世界坐标系的坐标升维逆映射方法,从而初步估计出感兴趣物体在世界坐标系中的位置。而后对估计位置进行合并、滤波操作后得到最终估计位置,并将提前建立好的模型放置和渲染在对应位置完成增强显示。本文方法对比起现有解决办法,具有成本低、运算量少、显示效果好等诸多优点,同时生成速度满足实时性要求,位置估计也满足精确度要求。能够进一步提高车辆全景影像的显示质量和使用价值。后续可进一步将实验扩大至真实车辆,以测试此系统在真实道路上的显示表现。
