面向多模态磁共振脑瘤图像的小样本分割方法
2021-04-20潘海为崔倩娜边晓菲王邦菊
董 阳,潘海为*,崔倩娜,边晓菲,滕 腾,王邦菊
(1.哈尔滨工程大学计算机科学与技术学院,哈尔滨 150001;2.华中农业大学理学院,武汉 430000)
0 引言
脑肿瘤是最常见的肿瘤之一,其年发生率占全身肿瘤的1%~3%,多发病于青中年群体,治疗致残率、致死率以及术后复发率高,对人类健康存在重大威胁。神经胶质瘤是一种最常见的原发性脑恶性肿瘤,具有不同的侵袭性,其中:高级胶质瘤是低分化胶质瘤,属于恶性肿瘤,患者预后较差;而低级胶质瘤的分化良好,虽不属于良性肿瘤,但预后较好[1]。
医学图像分割在研究和临床实践中起着重要作用,并且对于诸如疾病诊断、治疗计划、指导和手术等任务是必需的。研究人员已经为医学图像分割开发了各种自动化和半自动化方法[2]。脑肿瘤分割是医学图像分割任务中的一大难点。胶质瘤有着预后不同和组织学不同的子区域,包括整体肿瘤(Whole Tumor,WT)、肿瘤核心(Tumor Core,TC)和增强瘤(Enhancing Tumor,ET)。WT描述了病灶整体范围,包括肿瘤核心区域和肿瘤周围水肿区域;TC 描述需要切除的大部分瘤体,它包括坏疽区域、增强肿瘤核心和非增强肿瘤核心。这些子区域根据多模态磁共振(Magnetic Resonance,MR)扫描散布的不同强度分布所描述,例如WT 通过Flair 模态的高强度信号描述,TC 在T1ce 模态中,坏疽和非增强瘤区域较T1模态强度低,ET 区域则较T1 模态强度高。这反映了不同的肿瘤生物学特性。脑肿瘤不同子区域的标注如图1 所示。由于胶质瘤磁共振成像(MR Imaging,MRI)表型高度异质,其分割具有很大的挑战性[3]。

图1 神经胶质瘤的各个子区域Fig.1 Sub-regions of glioma
在过去的几年中,基于深度学习的语义分割方法一直提供最新的性能。更具体地说,这些技术已成功地应用于医学图像分类、分割和检测任务。自2012 年以来,已经提出了几种深度卷积神经网络模型,如AlexNet、VGG(Visual Geometry Group Network)、GoogLeNet、残差网络(Residual Network,ResNet)、密集连接卷积网络(Densely Connected Convolutional Network,DenseNet)等。其中AlexNet 由Krizhevsky 等[4]提出,利用两块GPU 进行计算,大幅提高了运算效率,证明了网络深度对网络性能存在影响,并提出了dropout 防止过拟合,但其结构复杂,且被指出局部相依归一化作用不大;VGG 由Visual Geometry Group[5]提出,其网络结构简单,因而VGG16被广泛应用,但它使用了更多参数,耗费大量计算资源;GoogLeNet 由Szegedy 等[6]提出,它的大小比AlexNet和VGG 小很多,参数也远少于这两者,而从实验结果看,它的性能却更优越,采用了模块化结构,方便了后续升级;ResNet 由He 等[7]提出,它主要针对因层数加深导致的过拟合与梯度爆炸等问题,而且结构简洁高效;DenseNet 是由Huang 等[8]提出的,它的思想与ResNet 一致,但它建立的是前面所有层与后面层的密集连接,并且通过通道级的特征连接实现了特征复用,使得其拥有着更优越的性能。基于深度学习的方法能够为分类、分割等任务提供优越性能的主要原因如下:首先,激活函数解决了网络的训练问题;其次,dropout 有利于规范网络;第三,有几种有效的优化技术可以用于训练卷积神经网络。计算机辅助治疗可以获得更快和更好的判断,以确保同时对大量患者进行更好的治疗;此外,无须人工干预的高效自动处理能够减少人为错误,并减少总体时间和成本。由于手动分割方法的缓慢过程和繁琐的性质,因此迫切需要无须人工干预即可快速、准确地进行分割的计算机算法。深度神经网络不仅有着很高的准确性,而且由于随时可用的GPU 加速计算例程,因此能够以快速有效的方式提供结果。到目前为止,已经创建了许多baseline 神经网络模型并针对各种分割应用进行了验证;然而由于分割任务中像素级注释的获取工作量较大,因此注释数据的稀缺性在语义分割中变得更具挑战性。在很多情况下,由于数据稀缺性等原因,无法获取到大量的训练标签(通常是数千个),因为对数据集进行标记需要这个领域的专家,花费高昂且需要大量的精力与时间。
小样本学习(few-shot learning)是近年来新兴的研究主题,受传统深度学习方法需要大量数据这一事实的推动。小样本学习是机器学习的一种特殊情况,它的确切目标是在数据集提供的有限监督信息下获得良好的学习性能。小样本学习利用先验知识可以完成有限监督信息的新任务,模仿了人类通过泛化和类比从很少的示例中获取知识的能力,被视为真正的人工智能的试验台。它可以帮助减轻收集大规模监督信息的负担,能够减少费力的数据收集和训练过程高昂的计算代价。小样本学习适用于人类很容易理解的应用,从而像人类一样充分学习[9]。应用小样本学习可以有效解决医学图像分割中由于带监督信息的数据量不足导致的过拟合问题,并且对于不同模态呈现的类别可以很好地泛化。目前已提出的小样本分割(few-shot segmentation)方法有基于注意力的多上下文引导网络(Attention-based Multi-Context Guiding network,A-MCG)、原型校准网络(Prototype Alignment Network,PANet)、不可知类分割网络(Class-Agnostic Segmentation Network,CANet)等,这些方法在通用数据集上取得了不错的效果。但由于脑瘤图像需要多模态特征结合才能获得完整分割,仪器差异、肿瘤类型、疾病状态等因素也会导致同一病人在同一部位的脑MRI 可能存在很大差异,并且由于肿瘤在图像中占比很小,存在类别不平衡问题,因而现有方法直接用于脑肿瘤图像数据集的效果并不好。
针对上述问题,本文根据深度学习和小样本学习理论提出基于U-net 的原型网络(Prototype network based on U-net,PU-net)模型,来执行多模态脑肿瘤MRI分割任务。
本文的主要工作如下:提出了一种有效的小样本分割模型,可以用于脑肿瘤多模态MRI 的分割;采用基于U-net 改进的特征提取器,利用少量训练数据就可以很好地提取特征;整体基于原型网络,可以用度量学习的方法利用少量监督信息完成新类别的分割。
1 相关工作
1.1 语义分割
语义分割是为图像的每个像素标记语义类标签的任务,目标是对各像素进行分类。在早期,卷积神经网络(Convolutional Neural Network,CNN)只用于分类任务,由卷积层和完全连接层组成。后来CNN 被首次用于分割任务时,Long 等[10]提出了全卷积网络(Fully Convolutional Network,FCN),大大提高了分割性能。FCN 的最大贡献在于建立了一个全是卷积层的网络,可接受任意大小的输入并产生有效输出。空洞卷积[11]也被广泛应用,能在不损失空间分辨率的情况下扩大感受野。后来针对医学图像分割,Ronneberger等[12]提出了U-net 模型,极大推动了医学图像分割的研究进程。U-net 由全卷积网络拓展而来,分为收缩路径和扩张路径,可同时获取低级语义信息和高级语义信息,能用少量数据训练模型,且分割准确率高、速度快,因而本文采用基于U-net进行改进的方法来提取特征。
1.2 小样本学习
小样本学习的模型大致可以分为三类:基于模型、基于度量和基于优化。其中基于模型方法旨在通过模型结构的设计快速在少量样本上更新参数,直接建立输入x和预测值P的映射函数;基于度量方法通过将支持集和查询集中样本投影到嵌入空间,计算它们的距离,借助最近邻的思想完成分类;基于优化方法认为普通的梯度下降方法难以在小样本情况下拟合,因此通过调整优化方法来完成小样本分类的任务[13]。Snell 等[14]提出了一种原型网络,可以用一个特征向量,即原型(Prototype)代表每个类别。这种结构简单有效,能减小数据过少导致的过拟合影响,因而本文的整体结构根据原型网络进行设计。
1.3 小样本分割
近年来小样本分割逐渐受到关注。Shaban等[15]首先提出了包含条件分支和分割分支的小样本分割模型OSLSM(One-Shot Learning for Semantic Segmentation),该模型从支持集生成一组参数,然后将其用于调整查询集的分割过程,这种双分支结构后被各小样本分割模型广泛使用。Siam 等[16]为了获得更好的原型提出了自适应掩膜代理模型AMP(Adaptive Masked Proxies for few-shot segmentation),在任务流中不断更新各个类别的原型。Zhang 等[17]提出使用掩膜平均池化的相似性指导单样本分割模型SG-one(Similarity Guidance for Oneshot segmentation),能从支持集中更好地提取目标特征向量,采用余弦相似度来度量支持集与查询集特征向量之间的距离,指导查询集分割。Dong 等[18]首次将N-wayk-shot 的语义分割问题进行了公式化,利用原型网络实现了分割。Hu等[19]提出了基于注意力的多上下引导网络(A-MCG),在传统双分支的基础上添加了特征融合分支,能够做到在支持分支和查询分支之间进行多尺度的特征融合,同时添加了空间注意力机制,能够在多尺度中突出上下文信息,增强自监督能力。Wang 等[20]提出了原型对齐正则化的PANet,充分利用了支持集知识学习原型,将每个像素与学习到的原型进行匹配来对查询图像进行分割。受此启发,本文采用对各个空间位置进行分类的方法,相当于使用用于分类任务的原型网络进行密集预测,能够通过度量学习直接获取分割,并根据脑肿瘤图像数据的特点进行结构设计。
2 基于PU-net的脑瘤图像分割方法
2.1 问题描述
本文的目标是针对多模态脑肿瘤MRI 建立一个模型,该模型可以快速学习脑肿瘤各分割类别的特征,并利用少量带有新类别掩膜(mask)的脑瘤图像进行分割[21]。本文采用下述方式对模型进行训练与测试。首先在数据集上构建训练集Dtrain和测试集Dtest,两个集合中图像的分割类别不同,如训练集分割的类别是肿瘤整体和肿瘤核心,测试集分割的类别是增强瘤,训练集和测试集的分割类别可以轮换。训练集与测试集分别包含各自的episodes,每个episode都包含支持集S和查询集Q,且都会实例化N-wayK-shot分割任务。同一episode的支持集和查询集具有相同的N个类,支持集的每个语义类别中有K个图像-掩膜对。模型首先从支持集中提取有关各类的知识,然后将学习到的知识应用于对查询集Qi进行分割。由于各个episode 包含不同的语义类别,因此模型经过训练可以很好地泛化。训练的目标是最小化像素级的交叉熵损失。从训练集获得分割模型后,在测试集上评估其小样本分割性能,对每个测试episode,在查询集上对分割模型进行评估。
2.2 PU-net模型框架
PU-net旨在为嵌入空间中的每个语义类别学习原型表示形式,再利用原型直接对图像进行分割。PU-net 的框架结构与2-way 1-shot任务的数据流如图2所示。支持集与查询集中的图像均为四通道灰度图像,各通道为同一病人在同一空间位置的各模态MRI切片。
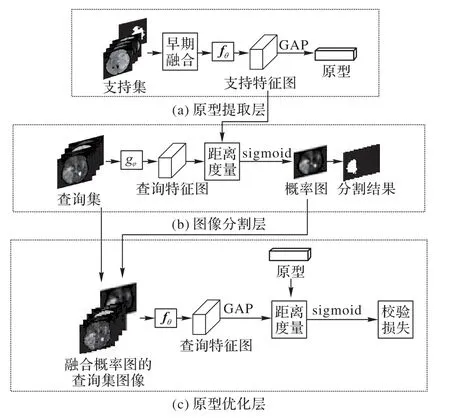
图2 PU-net整体框架与2-way 1-shot任务的数据流Fig.2 Overall framework of PU-net and data flow of 2-way 1-shot task
1)原型提取层。该层的特征提取器为fθ,其结构基于Unet 进行设计,具体结构如3.3 节所述。输入是与各类掩膜融合的支持集脑瘤图像,融合方法是逐元素相乘,目的是为了提取感兴趣区域,可以避免类别不平衡对原型提取带来的影响。对提取的特征图进行全局平均池化(Golbal Average Pooling,GAP)操作可以得到特征向量。假设Sc是支持集S中分割类别为c的子集,则类c的原型pc可通过下列公式计算:

其中:(xi,yi)是图像掩膜对;yi是各分割类别掩膜是各类对应的背景类掩膜。
2)图像分割层。该层的特征提取器是gφ,选取与fθ相同的结构,以保证输出特征图通道数与fθ相一致。向gφ输入查询集图像,得到查询特征图,利用原型提取层获取的原型对gφ提取的特征图的每个空间位置计算相似度,进而计算出每个像素属于各个类别的概率,得到各类概率图,从而执行像素级分类任务,完成分割。将分割结果与查询图像的真实分割掩膜进行比较,通过权重交叉熵计算像素级分类损失,即分割损失,利用减小损失函数对特征提取器gφ进行优化,从而更好地提取查询特征,获取更好的分割结果。具体过程如3.4 节所述。
3)原型优化层。将图像分割层得到的概率图作为掩膜与查询集图像融合,仍采用逐元素相乘的方法进行融合操作。将融合后的查询图像输入到fθ能够得到新的查询特征图,经过平均池化层后可以获取各类的校验特征向量,利用校验特征向量与已有的原型计算相似度,从而可以计算图像级的分类损失,通过最小化损失对fθ进行优化,可以促使原型提取层提取更好的原型,进而辅助图像分割层获得更好的分割。
2.3 特征提取器
PU-net 使用的特征提取器fθ与gφ均根据U-net 进行设计,分为收缩路径和扩张路径两部分,并且有连接两部分的跳跃连接结构,执行concatenation 级联操作,使得其可以结合深层信息和浅层信息,如图3所示。
特征提取网络共26层卷积层,9个卷积块,每个卷积块中包含两层卷积层,其中每层卷积层的卷积核的大小为3×3,步长为1。随后紧跟一个批规范化(Batch Normalization,BN)层和非线性激活ReLU(Rectified Linear Unit)层。每个卷积层对输入进行零填充操作,保证卷积操作后特征图尺寸不会发生变化,避免级联操作时因裁剪导致的信息损失。输入图像通道数为4,各通道是各模态相同位置的切片。经过第一个卷积块后,特征图通道数为64。收缩路径包含4 个卷积块和4次下采样,使用卷积层和ReLU 层来代替最大池化层,卷积层使用步长为2的2×2卷积核进行卷积,相对于最大池化操作可以减少下采样过程中损失的信息。每个卷积块都会使特征图的通道数翻倍,最终特征图通道数为1 024。扩张路径包含4个卷积块和4 次上采样,通过最近邻插值放大分辨率,随后紧跟卷积层、BN 层、ReLU 层以完成上采样操作。每个卷积块都会使特征图通道数减半,最终输出大小与输入图像一致、通道数为64的特征图。

图3 特征提取器结构Fig.3 Structure of feature extractor
2.4 度量学习
本文采用度量学习的方法学习最佳原型与分割图像。通过原型提取层获得原型后,可以计算出查询图像每个空间位置与各类原型的距离。由于整个肿瘤、肿瘤核心、增强瘤三个分割类别存在交集,故对上述距离应用sigmoid 激活函数,得到每个像素属于各个类别的概率,进而得到各类的概率图。查询图像xq在空间位置(m,n)处属于类c概率计算过程如下:

其中,d(·,·)是距离度量函数,本文使用余弦距离进行度量。各类概率图在相同位置进行比较,该像素属于值最大的类,由此得出预测的分割掩膜。根据度量学习得到的概率图,可以计算分割损失:

其中:H和W是查询图片xq的高和宽是指示函数,(m,n)位置像素类别为c时值为1,否则为0。α是自适应权重,能够缓解图像分割类别不平衡,计算公式为:
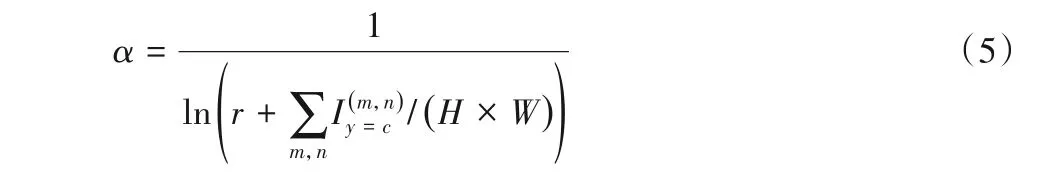
其中:r是超参数,设置为1.02,目标类别c的像素所占比例越大,其权值越小,减小了背景类对损失函数的影响。
原型优化层将查询图像xq与图像分割层得到的各类概率图融合,输入到fθ得到特征图,再经过平均池化层得到各类的校验特征向量,进而可以计算出各类特征向量与原型之间的距离,应用softmax激活函数可以得出:

它表示了与c类概率图融合的查询图像在图像级别被分类为c类的概率,其中yc表示c类的概率图,共有包括背景类在内的N+1个类别。进而可以得到原型校验损失:

3 实验与结果分析
3.1 数据集与预处理
本文使用的是BraTS 2018 数据集,分为胶质母细胞瘤(Glioblastoma,GBM)和低级神经胶质瘤(Low Grade Glioma,LGG),包含FLAIR、T1、T1ce、T2 四个模态的三维MR 图像以及一个GT 分割掩膜图像,每个模态的MRI 图像大小为240×240×155。在BraTS18 中,曾被使用的数据仅包括BraTS12-13的图像和注释,这些图像与注释在过去已被临床专家进行过了手动注释;BraTS14-16 中来自TCIA 的数据已被丢弃,原因是它们的描述混合了术前和术后的扫描,并且在BraTS12-13中排名靠前算法的分割结果注释了它们的GT标签;新加入的数据是完整的原始TCIA 神经胶质瘤集合,它们由专业医生进行放射学评估。总的来说,BraTS18 数据集包括BraTS13 的数据、来自CBICA的数据以及来自TCIA的数据。预处理主要分为如下三部分:对各模态图像进行标准化处理;对各模态图像及GT数据进行裁剪;对各模态图像及GT数据进行切片处理,丢弃无病灶切片,最后合并各模态切片。训练集由BraTS13与CBICA 的数据组成,共118例扫描数据,经预处理后的切片数据共有7 658 个;测试集使用TCIA 神经胶质瘤集合,共167例扫描数据,经预处理后的切片数据共有11 265个。
首先数据集中四个模态的序列对比度不同,故采用Z-Score 方式对各模态图像进行标准化,即将各个模态的数据标准化为零均值和单位标准差,GT 数据属于多标签二值掩膜,故不需要进行标准化,而其他各模态数据除了黑色背景以外的区域都要进行标准化。裁剪的目的是扩大肿瘤区域占比,避免数据类别不平衡,各模态数据裁剪至160 × 160 × 155。最后是切片与合并处理。由于本文提出的是2D 网络模型,所以需要进行切片以得到2D 数据。一个三维图像中有大量不包含病灶的切片,这些切片可以直接舍弃,这也可以缓解类别不均衡问题。针对多模态特点,将各个模态的切片组合成多通道,最终可得到160 × 160 × 4 的图像;GT 数据是多标签的,其中默认元素值为0、1、2、4,0 是背景,1是坏疽,2是浮肿,4是增强肿瘤。将GT数据分为三个通道,每个通道作为一个分割区域的掩膜数据,整体肿瘤WT 的掩膜1、2、4标签位置处值为1,肿瘤核心TC的掩膜1、4标签位置值为1,增强瘤ET 的掩膜4 标签位置处值为1,其余位置全部为0。
3.2 评价指标
为了定量评估模型的分割性能,本文采用下列5 个指标进行评价:
1)Dice 系数,也称作Dice 相似系数(Dice Similarity Coefficient,DSC)。用于计算两个样本相似程度,是一种几何相似度度量的指标。

2)阳性预测率(Positive Prediction Value,PPV),又名精确率,是预测出的所有阳性样例中真阳性所占比例。

其中:TP、TN、FP、FN分别代表真阳性、真阴性、伪阳性、伪阴性。
3)灵敏度(SEnsitivity,SE),即召回率。指所有阳性样例中预测出真阳性的样例所占比例,计算公式如下:

4)豪斯多夫距离(Hausdorff Distance)。用来衡量两个点集之间的距离,式(11)为点集A到点集B的豪斯多夫距离h(A,B),同理可得h(B,A),两者之间较大的值为双向豪斯多夫距离,它度量了两个点集之间的最大不匹配程度。

5)平均交并比(mean Intersection Over Union,mIOU)。用于计算预测值和真实值两个集合的交集与并集的比值。

3.3 分割结果
为了验证本文提出的PU-net 的有效性,利用TCIA(the Cancer Imaging Archive)神经胶质瘤切片数据构建测试样本,测试了该模型在各类分割区域的平均分割精度,如图4 所示。可以看出,利用该模型得到的分割结果与GT图像比较接近。

图4 模型分割结果对比Fig.4 Comparison of model segmentation results
为了验证PU-net在多模态脑肿瘤MRI分割问题上有效果提升,首先计算出其在测试集上各肿瘤分割子区域的各项指标,再选取两个最近提出的、效果较好的小样本分割模型进行对比:基于注意力机制的多重上下文引导网络A-MCG 和原型对齐网络PANet。采用1-way 5-shot 进行定量评估,PU-net 在各个肿瘤分割区域WT、TC、ET 的平均各项指标对比如表1所示。

表1 各个肿瘤子区域分割结果对比Tab.1 Comparison of segmentation result of tumor sub-regions
如表1 所示,增强瘤ET 区域相对于整个肿瘤WT 区域和肿瘤核心TC区域的分割精度较低,可能的原因是增强瘤区域的结构分布较为复杂,相较于整个肿瘤区域与健康脑白质、脑灰质的边界以及肿瘤核心区域与水肿区域的边界来说,肿瘤核心区域内增强瘤与坏疽区域、非增强瘤区域的边界更加难以区分。
为了验证PU-net的性能确实相较之前的小样本分割模型有所提升,使用A-MCG 和PANet 进行对比实验。PU-net 与其他两个模型的分割结果对比如表2所示。

表2 不同模型的肿瘤子区域分割结果对比Tab.2 Comparison of segmentation result of different models for tumor sub-regions segmentation
由表2 可知,本文提出的模型PU-net 除了召回率略低于PANet,其他各项精度均明显高于A-MCG 和PANet,这说明PU-net在多模态脑肿瘤MRI的小样本分割任务中具有更好的性能。然而,本文的方法是针对带标签数据较少的情况,与脑肿瘤分割比赛中排名靠前的算法相比,本文模型的分割精度仍有一定差距,这说明在数据量充足的情况下,小样本分割方法的分割精度有待提升。
4 结语
本文针对多模态脑肿瘤MRI 分割任务,根据带标注的多模态脑肿瘤MRI 难以获取的实际情况,提出了用小样本分割来解决的方案,并设计了一种原型网络结构PU-net。实验结果表明,该模型在脑瘤分割任务的性能较A-MCG 网络有很大优势,实验结果略优于PANet。这两个小样本分割网络模型的分割结果没有展现出与在通用数据集上一样好的性能,而且本文提出的PU-net的精度较数据充足的完全监督学习方法仍有一定差距,但其具有利用少量样本即可进行泛化的优势,稍加改进也可用于检测任务,如果对精度进一步提升则能大大增加实用价值。针对存在的问题,后续工作将围绕优化网络结构与将各个模态的相关特征进一步融合来进行,以实现更高精度的脑肿瘤小样本分割算法。
