分支预测技术对性能影响研究
2021-04-20徐永新
徐永新
(华为技术有限公司 江苏省南京市 210012)
为了提升处理性能,现代CPU 采用多级流水线机制,经典的五级流水线分成取指,译码,执行,访存,写回等几个阶段。流水线机制可以有效提升指令的并行度,但是存在一些流水线冲突的场景,造成流水线效率的降低。这样的流水线冲突包括结构冲突,控制冲突和数据冲突。
流水线的控制冲突也称为分支冲突。程序执行过程中有许多分支跳转的情况,流水线遇到分支跳转时,并不知道后面要真正执行的指令在哪里,因为分支跳转的目标地址还没有被计算出来。这个时候流水线就需要采用某种策略,来预测后面将要执行的分支。如果预测对了,那么流水线的效率将能维持在较好的水平。反之,预测错了,则错误的流水线处理结果都会被丢弃,重新从正确的目标地址取出指令重新执行,这将严重影响流水线的执行效率。
1 分支预测技术
1.1 静态分支预测器
静态分支预测是一种实现简单的方法,比如预测永远不发生跳转,取指单元总是按顺序取指,直到发现错误才丢弃不正确的中间状态,重新取指。
静态分支预测特点是实现简单,但是预测的精度不高,在早期的CPU 设计中会使用这种方式。
1.2 动态分支预测器
现代处理器使用较多的是动态分支预测器,该类预测器能够记录分支的历史跳转信息,来预测将要执行的分支跳转行为。如果由于程序执行的行为发生改变,预测器也会根据执行情况自动调整,从而拥有较好的预测准确度和自适应性。
动态分支预测使用分支历史表BHT 来记录最近一次或者几次的执行情况。两位饱和计数器是最常用的方向预测器。当计数值为11 时,分支转移则计数器值保持不变,当计数值为00 时,分支不转移则计数器保持不变,其他情况分支转移则计数器加1,分支不转移则计数器减1。根据饱和计数器来预测当前跳转行为,并根据实际分支转移情况更新饱和计数器的值。
将分支跳转的指令地址和跳转的目标地址都记录下来的缓冲区叫做分支目标缓冲器BTB。程序计数器PC 值和BTB 中的分支指令地址进行比较,如果相等则表明当前是分支指令,如果同时预测会发生分支跳转,则可以把BTB 中的目标地址作为下一条取指地址。
基于BHT 和BTB 的结构,衍生出一些改进的分支预测器,比如Gshare 预测器,Agree 预测器,Bi-Mode 预测器等等。
1.3 基于神经网络的预测器
分支预测本质上是机器学习问题,神经网络是一种比较有效的机器学习方法。神经网络的输入层是当前分支的地址所对应的分支历史寄存器状态,每个分支历史状态有相应的历史权重,根据神经网络算法得出输出层的值,用来表示当前是跳转还是不跳转。如果预测成功对应的权重会增加,预测失败则权重减少。基于神经网络的预测器可以边训练边预测。
基于神经网络的预测器的特点是经过充分的训练之后预测准确度比较高,但是训练的过程耗时较长,并且由于需要做矩阵运算,其算法存在一定的时延问题。
2 分支预测对比实验
为了展示分支预测机制对性能的影响,笔者设计了一组实验,分别让分支预测机制失效,分支预测机制成功,以及没有分支指令等几种情况作为对比,并测量出相应的性能数据。
在实验中,程序的目标是统计出数组中的奇数数量,并计算出所有的奇数之和。元素个数为k 的数组内有n 个奇数,m 个偶数,被测程序需要遍历数组统计奇数个数,并计算出所有奇数之和。循环查找的前后分别获取cycles 值,其差值表示执行循环所消耗的cycle 数。其部分代码片段如下:

上述代码使用C++编译器按照下面的编译选项,编译出可执行程序来验证。

表1:实验对比数据
g++ -O2 -g test.cpp -o test
2.1 分支预测成功实验
为了保证分支预测成功,在初始化数组的时候,把数组的前n个元素都初始化成奇数,后m 个元素都初始化成偶数,这样有规律的排列,可以保证分支预测机制能准确预测出分支的跳转。代码片段中需要注释掉fisher_yates 函数。
初始化完毕之后的数据排列如下:

基于上述的规律数据,CPU 在执行条件判断语句if ((data[i]% 2)== 1)时,将很快学到其规律,分支预测基本上是成功的。
2.2 分支预测机制失效实验
为了让分支预测机制失效,需要将有规律的数组变成一个随机排列的数组。Fisher-Yate 算法是用来将一个有限集合生成随机排列的算法。在随机化奇数偶数排列之后,分支预测器将无法预测分支跳转,从而让分支预测机制失效。随机化之后的数据排列呈现无规律的状态:

基于上述的无规律数据,CPU 在执行条件判断语句if ((data[i]% 2) == 1)时,无法通过历史数据来判断分支跳转的规律,分支预测极大概率是失败的。
2.3 无分支指令实验
为了避免分支指令对性能造成的影响,编程中可以采用技巧,避免使用条件判断语句。判断奇数可以看数据的最低位是否为1,使用位运算来代替条件判断。比如可以把循环里面的代码改成如下的方式:

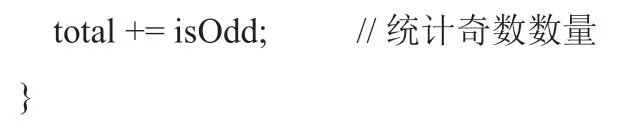
3 实验数据
笔者在AMD Ryzen 5 4600H CPU 上运行测试程序,改变循环次数,分别针对无规律数据分支预测失败,有规律数据分支预测成功,无规律数据无分支指令,有规律数据无分支指令这四种情况,测量出了一组执行时间cycle 值的对比数据。
表1中第一行表示数组大小,即循环次数分别为10000 到50000 次,其余的数字表示测得的对应情况的cycle 数。由实验数据可知,分支预测失败的情况下的执行时间基本上是预测成功的4.2倍左右。而没有分支指令的情况下,有规律的数据和无规律的数据,对执行时间没有影响,两者对比数据没有显著的差别。
4 结语
通过对分支预测机制的介绍,以及实验数据的展示,我们可以得出下面的结论:
(1)现代CPU 往往都有设计良好的分支预测机制,如果某段程序执行路径不是关键瓶颈,则不必花时间去做精细的分支优化,交给CPU 和编译器去做优化处理即可。
(2)如果某段程序代码属于关键执行路径,则在大规模循环中需要优化分支判断,让分支条件的判断是有规律的,这样才能有效利用CPU 的分支预测机制。
(3)如果可以使用运算技巧来避免分支判断,也可以消除无规律的分支判断给流水线带来的效率影响。
