循证视角下文献证据检索的饱和度与冗余度研究:基本理论与基础数据*
2021-04-19魏志鹏周文杰杨克虎
魏志鹏 周文杰 杨克虎
(1.兰州大学基础医学院循证医学中心 甘肃兰州 730000)
(2.兰州大学循证社会科学研究中心 甘肃兰州 730000)
(3.西北师范大学商学院 甘肃兰州 730070)
作为循证研究与证据转化的基本工具,系统评价(systematic review)和元分析(meta-analysis)的科学性都高度依赖于原始研究证据的检索质量。显然,只有原始研究的证据得到了全面检索,基于此而展开的系统评价和元分析才能最大程度控制偏差,从而得到更高层次、更接近于真实效应的科学证据。
长期以来,在文献信息的检索领域,研究者一直将查全率和查准率作为衡量检索科学性的基本评价标准。然而,由于“相关文献总体”是一对理想中的估计值,因此查全率和查准率在实际检索中几乎无法真实测量。为保证循证研究的科学性,有必要对传统的查全率和查准率指标加以优化,使其更具有测量上的可操作性,从而为全面获取原始研究证据提供有效支撑。
本文基于查全率和查准率这对传统的检索效率评价概念,着眼于证据检索全面性的评判,提出了饱和度和冗余度这一对评价指标,并以CNKI 为研究样本,就不同检索渠道和方式在证据检索的科学性方面的实际状况做出评估。 立足饱和度和冗余度的文献证据检索质量评估,有助于对查全率和查准率评价方式做出补充,为循证研究(特别是系统评价和元分析)中证据的整合和真实效应的发掘提供参照。由于饱和度和冗余度的评价涉及的因素众多,因此本研究将这部分研究主要分为两部分:第一部分基本理论加以阐释并对基础数据集的构建过程进行介绍;第二部分在第一部分基础上,以饱和度和冗余度为检索质量评价指标展开实证检验。因篇幅所限,本文为本研究第一部分研究成果。
1 文献回顾与理论基础
1.1 查全率与查准率
20 世纪60 年代,美国学者Perry 和Kent 最早提出了查全率和查准率的概念。 同年,美国学者C.M.Cleverdon 在他著名的Granfieid I 试验中首次将查全率与查准率作为信息检索效率的评价指标,又在他的Granfield II 试验中发现了查全率与查准率之间的互逆关系。至此,查全率与查准率便成为文献信息检索和评价的重要指标。
查全率(Recall Ratio)是指检索出来的相关文献与所有应该检索出来的文献的比率,主要是用来衡量在一次检索中检索出相关文献的能力。 如果我们能够识别所有相关文献并且可以检索到所有对口径的文献,那么查全率总是100%。尹舒力认为查全率“是一个不实际的概念”,其理由主要是由于查全率分母的值是一个无法确定的值。在实际检索过程中,由于研究者几乎永远无法得知“全部相关文献”的总数,因此查全率是一个不可能精确测量的指标,只是一个理想中的、不可用的估计值。查准率(Precision Ratio)以百分比表示检索出来的相关文献与实际检索出来的文献的比率。 查准率实际上衡量的是检索中拒绝不相关文献找到真正相关文献的能力。 假设拥有的总文献量为N;总文献中所有相关文献量为X;被检出文献总量为M;被检出的相关文献量为W;查全率R 在数值上等于W 与X 的比例;查准率在数值上等于W 与M 的比例(见图1)。
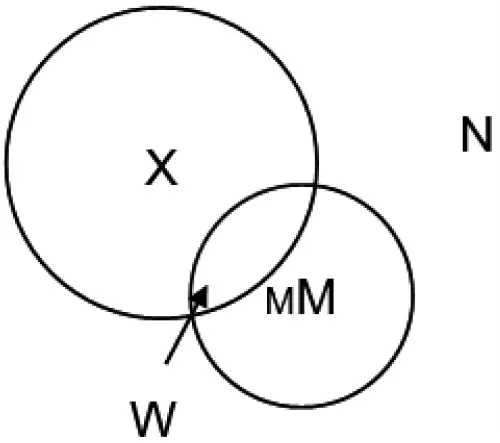
图1 查全率与可准率的关系示意图
实际上,大多数文献检索人员都想获得更高的查准率,他们倾向于在判断过程中阅读相对较少的文献,从而选择较少数量的文献输出。在这种情况下,信息搜索者可以尽量节约时间。而系统评估者和元分析研究人员对文献证据的检索要求更接近查全率。这是因为,由于无法确定相关研究的集合是否代表关于该主题的全部现有研究,而搜索尽可能多的现有研究可以很好地避免这种情况。系统评价中文献检索的主要目标是不遗漏重要文献,找到尽可能多的研究以确保分析结果无偏。 这意味着搜索策略倾向于强调查全率,更愿意牺牲查准率来换取较高的查全率。
总之,查全率和查准率这一对指标在一定程度上反映了文献检索的质量,但也存在很多问题。一个问题是查全率无法精确测量,只能得到一个估计值。同时,当检索者使用查准率来拒绝不相关文献时,也很有可能会错误地去除大量本应该相关的文献。 另一个问题是,查全率与查准率二者有较为明显的互逆趋势,因此无法同时优化。 这些问题的存在,都给检索质量评价带来了比较大的困难。
1.2 证据的生态系统
不同的文献会报道质量不同的研究,并非所有的文献证据都有同样的价值。为了评估证据的质量,研究者发展了一个证据的层次结构,称为“证据金字塔”(见图2),旨在为不同的证据来源匹配不同层次的价值。
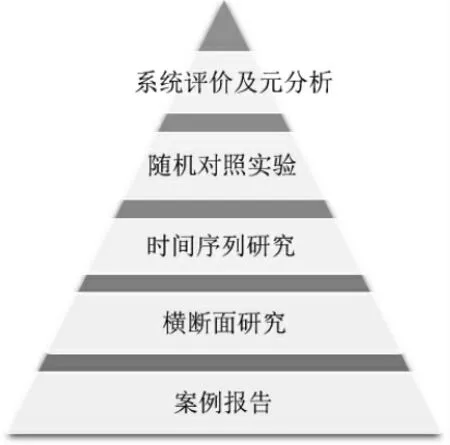
图2 证据金字塔
“证据金字塔”所呈现的层级结构对于证据质量的评价有着极其重要的意义,但在循证研究中,当面对数量庞大的证据时,如果实践者没有及时完成证据分级或对新的研究成果检索不及时,则很可能会造成证据资源的浪费。 为此,Pervandvik, Linn Brandt等在2011 年成立了MAGIC 组织并首次提出了证据生态系统(evidence ecosystem),目的是推动证据从产生、整合、实践传播到应用过程的转化。
在证据生态系统中,证据的产生、整合、实践到应用的过程类似于石油产口的开发过程(开采、提纯、加工、运输并提供给用户使用)。 因此,在生态系统中证据的来源就是原始研究的开展,证据的整合就是对原始研究证据的收集、遴选与总结后,形成符合传播条件且可以解决问题的最佳证据;证据的实践传播就是构建实践指南以及决策辅助;证据应用是指应用和评价证据的效果。这一过程如同生态系统,应实现无缝连接与转化,减少证据资源的浪费与转化过程中的“泄露”,推动证据从产生到使用的可持续、动态循环,实现证据生态系统的良性、高效运作。
好的研究证据应该是从原始研究的初级证据到经过整合的高级证据,具有若干层级。尽管在众多证据等级标准中,系统评价和Meta 分析类论文都被列为最高级别,但这实际上都取决于检索质量。显然,如果检索质量很差、文章的质量和级别也不会很高,甚至研究结果会存在较大偏倚或者会误导后续研究者做出错误的判断。通过检索获得全面且可靠的原始研究,是后续证据整合、开展系统评价和元分析的基础。
1.3 证据的整合与转化
1.3.1 整合
系统评价和Meta 分析旨在综合不同研究的结果以达到对问题的全面理解,因此,证据整合对科学研究的进展至关重要。Meta 分析是一种对不同研究结果进行定量综合的方法,可以对解决看似矛盾的结果加以综合分析,得到更加真实的效应值,从而对科学领域产生了深刻的影响。格拉斯(Glass)在1976年首次提出了Meta 分析这个术语,他指出,Meta 分析是“综合现有个体研究成果的综合统计分析方法”。早在一百多年前,卡尔·皮尔逊为了确定疫苗的有效性,第一次对不同来源的信息进行组合,从五个不同的样本中对接种疫苗和死亡率之间的相关性进行了平均估计。现代统计科学发展中的另一位重要人物罗纳德·费舍尔描述了一种结合来自不同研究的概率方法。在20 世纪30 年代末,威廉·科克伦和他的同事弗兰克·耶茨描述了与现代固定效应和随机效应模型基本相同的方法,这些模型经过推广后,心理学家吉恩·格拉斯和玛丽·史密斯发现,不同实验的结果测量可以是标准化并且放到同一尺度上进行比较。至此,Meta 分析的影响力逐渐开始展现。
系统评价和Meta 分析都用来完成研究结果的综合(research synthesis)。不同的是,系统评价是一种研究类型而Meta 分析是一种统计学方法,Meta 分析属于系统评价的一部分。 关于系统评价的发展要追溯到1971 年,Kenneth Feldman 发表了一篇名为《利用他人的工作》(Using the Work of Others: Some Observations on Reviewing and Integrating)的文章,其中他首次提到“系统地回顾和整合……一个领域的文献可以被认为是一种研究类型,即使用一套具有特点的研究技术和方法”。 他描述了系统评价过程中的四个步骤:抽样主题和研究,制定索引和编码材料的方案,整合研究,并撰写报告。 系统评价将定性和定量分析方法相结合,全面整合证据,严格评价所纳入的研究,这种公开且透明的方法是筛选科学真实信息的最有效途径。
1.3.2 转化
在循证实践中,研究者需要用实践指南为决策提供依据,即科学严谨地合成可用的最佳证据,公开透明地形成推荐意见,最终制定出可信度高的指南。其中,推荐意见是指南最重要的部分,也是指导实践的重点,如何使证据转化成明确的推荐意见对决策者有着直接的影响。
目前,已经有很多学术组织提出了适用于证据转化的框架和在线工具,但对于如何将证据形成推荐意见的标准却不尽相同。2004 年,GRADE 工作组提出“(证据)评估、发展和评价的推荐等级(Grades of Recommendations Assessment,Development and Evaluation)”,对于推荐强度给出了清晰的定义,但并未给出具体的判断标准。因此,在基于GRADE 系统的基础上建立了Etd 框架,提供一种结构化的方法,对若干项标准进行考虑和判断,描述其判断细则,帮助决策者更加清晰明确的做出判断。 Guideline Development Tool(GRADEpro GDT)是GRADE 工作组在2013 年正式推出的一款在线的循证实践指南制定工具,主要作用是在制定指南过程中进行数据整合。 近几年来,该在线工具在录入结局指标,产生证据推荐表格等方面都进行了更新。
综上所述,无论是检索质量的评价还是证据生态系统构建和转化过程,都高度依赖于证据检索的质量,只有原始研究证据进行全面的检索,才能得到更高级的科学性证据,从而转化成推荐意见,为实践提供决策。检索的重要性毫无置疑,但是检索存在的问题层出不穷。着眼于证据检索全面性的评判,本文及后续一篇文章构建以CNKI 为研究样本, 提出了饱和度和冗余度这一评价指标,就不同的检索方式对证据检索的实际情况做出评估检验,以便为文献证据检索的科学性评价提供基础。
2 证据检索的饱和度和冗余度评价指标
2.1 概念界定
饱和度和冗余度都侧重于测量一个文献数据集合中,通过特定检索方法与途径得到的检索结果在不同状态下的“穷尽(exhaust)”检索中占的比重。 穷尽检索主要是指应用特定检索方法(如滚雪球或多重替代方式检索)而实现无法再检索到新的文献时的状态;当达到穷尽检索时构成总文献数据集包括所有相关文献量和被检出文献总量之和。总文献数据集中文献与检索词的相关程度必然有高低之分,因此研究者依据相对应的分级标准判定总数据集中的文献相关度,分为高度相关、中度相关和低度相关。
饱和度是指检索中不再有新的文献被纳入的状况,而冗余度是指检索过程中检索到不相关文献的情况。本文将饱和度分为纯净饱和度和一般饱和度。其中,纯净饱和度是指采用特定检索方式检索结果涵盖总文献数据集中高相关文献的程度,具体计算方法是:采用单项或者组合检索时与总数据集中高度相关文献的重合率,在数值上等于检索出的高度相关文献量与穷尽状态下高度相关文献总量的比值,这一指标反映了特定检索途径是否能够准确定位高度相关研究证据的能力;而一般饱和度指特定检索结果涵盖整体数据集中中度及中度以上相关文献的程度,在数值上等于检索出中度及中度以上相关文献量与穷尽状态下的中度及中度以上相关文献总量的比值,这一指标反映了特定检索是否能够准确定位中度以上相关研究证据的能力;冗余度是指通过特定检索途径获得的与研究主题不相符的文献在穷尽检索数据集低相关文献中所占的比重,冗余度这一指标反映了特定检索方式检索出不相关文献的情况。
饱和度这个概念与查全率比较接近,但有区别。查全率主要是用来衡量在一次检索中检索出相关文献的能力,和饱和度相比,两者都是查找检索出的相关文献和穷尽所有相关文献之间的比值;但是两者的区别是,相对于查全率来说,饱和度更加具有可操作性, 我们能够通过应用滚雪球或者其他检索方法识别增加所有相关的文献、可以检索到所有对口径的文献并且不再有新文献被纳入时,在一定程度上可以无限接近总文献中所有相关文献量。并且通过引入纯净饱和度和一般饱和度指标能够体现文献查找的相关性,而这一点是查全率做不到的。查全率只能得到相关文献的比例,而体现不出文献相关程度。 饱和度同时也能进一步体现文献检索的准确性(类似查准率),纯净饱和度和一般饱和度反映了特定检索方式是否能够准确定位高度相关研究证据或中度及中度以上相关文献的能力。由此可以看出,饱和度既汲取了查全率中的合理成分,又能更加准确地衡量查准率。
2.2 检验逻辑
在数据库中进行基本检索后,运用滚雪球方法对于参考文献进行迭代,再继续改变检索方式使用代表性作者检索迭代,当不再有新的文献被纳入时,就达到了穷尽检索状态。
本研究中,基础数据集的具体构建过程为:首先在CNKI 数据库中检索特定检索词,检索资源范围选择总库,同义词扩展;时间范围选择发表自特定时间段的数据。 运用逻辑运算符OR 来对知网中能选择的检索方式进行全面具体的检索,采用检索式:(主题=特定检索词)OR(全文=特定检索词)OR(篇名=特定检索词)OR(关键词=特定检索词)OR(摘要=特定检索词)。 限定语言为中文;第二步是对于上一步得到的数据集进行深入分析、扩充。具体步骤是利用滚雪球法对每篇文献进行浏览,判定文中所提供的研究证据是否与要检索的内容相关。如相关,则进一步将其参考文献的题录信息导入endnote,并保留其中发表于特定时间段的中文文献。 对新补充的文献重复上述过程,直到不再出现新的文献为止;第三步是改变检索方式,采用代表性作者检索迭代。应用通配符及布尔逻辑运算符,对各检索项添加和社会认识论有关的代表性作者进行补充检索,将新检索到的文献增补到数据集中。 同时将新检索到的文献继续利用滚雪球法来增补文献,不断重复此过程,直到饱和。 至此,在穷尽状态下的总数据构建完毕。
数据集构建完毕后,研究者依据相对应的分级标准判定总数据集中的文献相关度后,逐次对照主题、题名、关键词、摘要和全文各单项及组合检索项与总数据集的重合比率,据此对各分项及各种组合检索的饱和度做出排序。同时,通过对检索到无关文献的分析,得出冗余度。
3 基于CNKI 的证据检索饱和度检验
基于CNKI 数据库对证据检索的实际情况做出评估检验,按照饱和度的检验逻辑,进行基本的探索性检索后,以确定一个文献数量比较适合分析,具有鲜明的跨学科特征为检索词。本文最终选择以“社会认识论”为检索词。这一检索词具有明显社会科学特征并跨越了哲学、社会学、图书情报学等多个领域。确定检索词后,本文的正式检索式如下:(主题=社会认识论)OR(全文=社会认识论)OR(篇名=社会认识论)OR(关键词=社会认识论)OR(摘要=社会认识论),以具有扩检意义的or 连接各种检索方式进行系统性检索。检索范围包括CNKI 和其相关文章的参考文献列表,检索时间为发表于2010 年1 月1 日至2020 年1 月1 日之间的中文文献。
3.1 参考文献迭代
首先对基于CNKI 数据库检索到的1544 篇文献进行初步清洗去重,去除英文文献及重复文献,导入endnote 后共有文献1529 篇。进而,应用“滚雪球”法对参考文献进行迭代,以实现对清洗后的数据集的补充。 具体过程是:针对检索到的每篇文献的标题、摘要、关键词、参考文献进行浏览,判定文中所提供的研究证据是否与社会认识论相关。如相关,则将其相关文章的参考文献也纳入到endnote 中。由于相关文章的参考文献范围较为广泛,因此将补充的参考文献进行全文浏览,剔除与社会认识论不相关文献后增添到总数据集中。
在第一轮滚雪球后,初步共补充文献358 篇,对358 篇文献再次进行全文浏览,剔除和社会认识论不相关文献118 篇,将240 篇文献导入总的文献中,有38 篇和总文献数据集中重复,至此第一轮补充文献202 篇。 基于第一轮202 篇补充文献,第二轮参考文献迭代共保留2010 年1 月1 日到2020 年1 月1 日之间的中文文献50 篇,对保留的50 篇进行全文浏览,去除不相关文献8 篇,将42 篇补充文献导入总文献中, 剔除重复4 篇, 至此, 第二轮补充文献38篇。继续对滚雪球第二轮新增38 篇文献对每篇文献的标题、摘要、关键词、参考文献进行浏览,判断是否相关。第三轮共保留2010 年1 月1 日到2020 年1 月1 日之间的中文文献23 篇,对这23 篇继续进行全文浏览去除不相关文献3 篇,至此第三轮滚雪球共纳入20 篇文献。 继续对滚雪球第三轮新增20 篇文献进行浏览,第四轮共保留符合要求的中文文献9 篇,全文浏览后全部相关,导入总文献数据库后一篇重复,第四轮共纳入8 篇。 滚雪球第五轮时补充5 篇全部相关。滚雪球第六轮时仅找出1 篇,导入总文献数据库中重复,至此没有新文献的产生,参考文献滚雪球结束。
参考文献迭代六轮后总共新增文献273 篇。 对于目前总文献数据集进行手动检索,去除同一篇文章在不同期刊发表的不符合标准的10 篇文章(保留其中书籍和期刊文章同名文献),再次浏览数据库中所有文献,删除不符合时间段内的3 篇文章,最终纳入文献1789 篇。
3.2 代表性作者迭代
虽然通过上述对参考文献“滚雪球”的方法,有效提升了文献数据集的完整性,但为确保没有文献被遗漏,本文进行对代表性作者进行了补充检索。具体检索策略是:应用布尔逻辑运算符,对各检索项添加和“社会认识论”有关的代表性作者进行补充检索,并且文献检索时尽可能多的列举出“社会认识论”的同义词、近义词,并用逻辑“or”连接成检索式。如群体认识论,群体知识论、社会认识论。 将新检索到的文献增补到数据集中。 并对新补充的文献进行参考文献“滚雪球”式迭代,直到饱和。
通过查阅找出系列核心文献后,进行提取、分类后,找到如下社会认识论领域的代表性作者:卡尔·曼海姆(Karl Mannheim)、玛格利特·伊丽莎白·伊根(Margaret Elizabeth Egan)、杰西·豪克·谢拉(Jesse Hauk Shera)、斯图尔特·科享(Stewart Cohen)、哈利·科恩布李斯(Hilary Kornblith)、弗里德利科F.施密特(Frederick F. Schmitt)、肯斯·赖诺尔(Keith Lehter)、艾文·高曼(Alvin Goldman)、史蒂夫·富勒(Steve Fuller)、玛格瑞特·吉尔伯特(Margaret Gilbert)。 本文分别用以上作者中英文名字展开检索。如玛格利特·伊丽莎白·伊根的检索式如下:
中文检索式:((SU=(' 社会'+' 群体')* (' 认识论'+' 知识论')OR TKA=(' 社会'+' 群体')*(' 认识论'+' 知识论')OR TI=(' 社会'+' 群体')*(' 认识论'+' 知识论'))and(SU=' 玛格利特' OR TI=' 玛格利特'OR TKA=' 玛格利特'OR FT=' 玛格利特'OR CO='玛格利特'OR RF='玛格利特')
英文检索式:((SU=(' 社会'+' 群体')* (' 认识论'+' 知识论')OR TKA=(' 社会'+' 群体')*(' 认识论'+' 知识论')OR TI=(' 社会'+' 群体')*(' 认识论'+' 知识论'))and (SU='Margaret Elizabeth Egan'OR TI ='Margaret Elizabeth Egan' OR TKA ='Margaret Elizabeth Egan'OR FT='Margaret Elizabeth Egan' OR CO ='Margaret Elizabeth Egan' OR RF ='Margaret Elizabeth Egan')
添加代表性作者检索后,初次检索到142 篇,在总文献数据库中去除重复73 篇,对剩下的69 篇文献再次进行全文阅读去除不相关14 篇,初次检索共得到55 篇相关文献。 对于得到的55 篇相关文献继续进行第一步参考文献迭代。对这55 篇文献每篇的标题、摘要、关键词、参考文献进行浏览,判定文中所提供的研究证据是否与社会认识论相关。如相关,保留其参考文献。 通过“滚雪球”,第一轮共补充文献23 篇,对补充的23 篇文献再次进行全文浏览,剔除与社会认识论不相关文献10 篇。 至此第一轮“滚雪球”结束,共纳入13 篇补充文献。
将第一轮纳入的13 篇文献的标题、摘要、关键词、参考文献进行浏览判定后,第二轮“滚雪球”共补充文献5 篇,导入总库后有1 篇重复,第二轮纳入4篇补充文献。以同样的方法对数据集进行扩充,第三轮新纳入4 篇补充文献,第四轮新纳入1 篇,第五轮新纳入0 篇。 基于代表性作者的“滚雪球”结束。
最终,本文使用代表性作者检索方式共新增文献77 篇,纳入到总文献数据集中有10 篇重复(不同期刊发表的同一篇文章,报纸偏多),最终总文献数据集中有1856 篇。 此时,通过两种方式的检索,研究者确认,针对“社会认识论”的检索已达到了穷尽状态。
4 穷尽检索文献证据数据集的相关度分级
基于前述检索过程,本文已构建了一个穷尽检索的“社会认识论”文献数据集。 这一数据集中的文献既包括通过改变检索式检索到的文献,也包括和社会认识论有关的作者所发表的相关文献。然而,尽管上述检索是针对“社会认识论”而展开的,但总数据集中文献与“社会认识论”的相关性必然有高低之分。 如(主题=社会认识论)OR(全文=社会认识论)OR(篇名=社会认识论)OR(关键词=社会认识论)OR (摘要=社会认识论)检索式能检索出在全篇文章中出现过“社会认识论”一词的文献,但这篇文献内容却与“社会认识论”可能没有关系。 这一类文章不是我们所需要的,却被检索了出来。 因此,本文依据所构建的文献相关度分级标准(见表1),对于总文献数据集中1856 篇文献与“社会认识论”的相关度进行判定,实现了对总数据中文献进行相关度分级的目标。

表1 文献相关度分级标准
依据上述分级标准,由两名研究者背对背对总数据集中的全部文献进行全文阅读,并分别从高度相关、中度相关和低度相关三个层次判定每一篇文献与“社会认识论”的相关程度。
经过初级分级评判,两名研究者判定一致的文献有1559 篇,其中53 篇为高度相关,148 篇为中度相关,1358 篇为低度相关。 对于剩余298 篇判断不一致的文献,两人在进行第一轮讨论后重新进行判定,形成一致结果。其中,123 篇低相关,105 篇中相关,22 篇高相关。剩下48 篇两名研究者的判断仍然存在分歧,为此,邀请了本领域专家参与第二轮讨论,与两名研究者共同判定剩下的48 篇中4 篇为低相关,16 篇为中相关,28 篇为高相关。最终,本研究共确定103 篇高相关文献,269 篇中相关文献,1484 篇低相关文献。
至此,文献的检索与分级全面完成。本阶段所构建的数据集就文献数量而言,实现了对CNKI 中十年来文献的穷尽检索,为评价查全率及相关指标提供了参照;从分级情况看,通过研究者的分类分析判断,实现了对文献相关程度的评判,为评价查准率等相关指标打下了基础。本项目后续研究的展开,正是基于这样一个穷尽检索且具有明确分级标准的文献数据集展开。
5 结语
本文基于循证视角,提出了文献证据检索的饱和度与冗余度,并对其相关的理论特征进行了描述。基于这种理论界定,本文构建了一个基础数据。
从文献证据检索基本理论的角度看:一方面,无论是证据转化还是检索评价,这些都离不开检索的质量。 但衡量文献信息检索效果的传统指标——查全率与查准率,存在诸多问题。如查全率无法精确测量,只能得到一个估计值,而查准率则很有可能会去除大量本应该相关的文献,从而导致研究发表偏倚。进而,查全率和查准率存在互逆趋势,因此无法同时优化。 凡此种种都表明,循证研究中,查全率和查准率并非文献证据检索的最佳指标。着眼于此,本文提出了饱和度和冗余度这对评价指标。 饱和度和查全率相比更加具有可操作性。具体而言,本文通过改变各种检索方法及“滚雪球”等方面,识别增加所有相关的文献,达到了穷尽检索的目标。为进一步细分数据分析,本文区别了“纯净饱和度”和“一般饱和度”,用来体现所检索到文献的相关性。此外,本研究提出冗余度指标,用来反映不同检索方式检索出不相关文献的情况。总之,通过饱和度和冗余度这对评价指标,能够更好的衡量文献检索的质量和效率。
基础数据集的构建方面,本文首先在数据库中进行基本检索后,运用“滚雪球”的方法对参考文献进行数轮迭代。进而,使用代表性作者进行补充检索和迭代,确保达到穷尽检索状态。 同时,本文通过相应的分级标准对总数据集中文献进行相关度分级,为下一步计算饱和度和冗余度提供了完善的数据基础。 后续研究将在本文所述的基本理论和基础数据之上展开。
