混合粒度多视图新闻数据聚类方法
2021-04-12代劲,胡艳
代 劲,胡 艳
(重庆邮电大学 软件工程学院,重庆 400065)
1 引 言
网络技术的飞速发展,对网络新闻的分析和监督无疑对社会和政府有着极大的作用.多视图数据是指从不同的源头采集或由不同属性的特征进行描述的数据,例如网络新闻数据通常通过文本、图片以及多媒体信息等特征进行描述,可以按照特征所属的不同类型划分为不同的视图.目前,多视图聚类算法在无人驾驶、异常点检测、生物医学分析等领域中都得到了充分的应用.
文献[1]中,首次提出了以协同训练为基础的多视图聚类方法.文献[2]基于核的思想,将每个视图表示为图,将多个图融合后进行谱聚类.文献[3]结合多视图K-均值算法和集成技术,提高了聚类的性能.文献[4]将共正则化和非负矩阵分解结合,然后再进行聚类.文献[5]利用正则相关性分析从多个视图特征中选取最相关的视图作为视图数据的唯一表示,然后再用传统的聚类方法.
上述方法都默认不同视图对簇结构的贡献程度一样大.但是,在现实世界的聚类问题中,某些视图包含不同数量的信息,同时当某些视图已经被噪声破坏导致聚类效果较差的时候,平等的看待各个视图会影响最终的聚类结果.文献[6]提出通过结合先验知识粗略地计算权重,这种方法是人工干预的.文献[7]以拉普拉斯秩约束为基础,通过引入超参数来学习视图间的权重.文献[8]提出的TW-K-means方法可以学习视图和样本特征的权重.文献[9]提出的WMCFS算法,可以选取特征和给视图加权,但是目标函数中的两个超参数均依赖先验知识.文献[10]从不同样本间存在的差异出发,提出SWMVC算法,它能自适应确定不同视图中样本的权重,但没有考虑关注不同视图对簇结构的贡献.
当前关于新闻数据的聚类分析中,大多数是基于新闻文本的,忽略了新闻图片和新闻视频等多媒体信息.详细地分析当前的网络新闻结构,可以看到新闻内容除了直接的文本信息之外,通常还使用高度语义概括后的标签信息对新闻中出现的图片、音频视频等多媒体信息进行描述,直接导致新闻内容中的文本、图片和视频视图的特征的粒度和语义不在同一个层次.若不经过粒度和语义层次的统一操作而将直接的文本特征与标签特征进行分析或学习,将严重影响新闻数据挖掘性能.本文首先在网络新闻不同视图上分别进行特征选择,使得各个视图的特征均统一到标签的粒度上.然后在此基础上构建视图间的自适应权重方法,提出了一种混合粒度新闻数据的多视图聚类算法(multi-view clustering of multi-granularity news data,MVCN),可以较优的融合新闻各个视图的数据,反映不同视图对聚类簇结构的贡献程度,以此来提升聚类效果.
2 相关理论
2.1 多视图K-means聚类
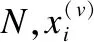
(1)

2.2 信息熵(Shannon Entropy,简称熵)
“熵”主要是用来衡量不确定的程度的大小.对于随机变量X,其熵取值如下:
(2)
其中,n是X可能的取值类别总数,P(x)表示x发生的概率.
3 混合粒度多视图新闻数据聚类存在的问题分析
通过分析网络新闻的特性,本文发现新闻内容除了由词粒度特征构成的文本信息之外,通常还使用高度语义概括后的标签粒度特征对新闻中出现的图片、音视频等多媒体信息进行描述.其结构如图1所示.
1)不同视图中不同标签粒度的统一:标签抽取
通过图1看到,图片和多媒体(音视频)视图中的数据特征由几个高度语义概括后的词条(标签粒度)组成,而文本视图中的数据特征则由成百上千的词条(词粒度)组成.如果将新闻文本、图片和视频等不同粒度层次的视图当作同一粒度层次进行处理,在逻辑上有所欠缺考虑,难以体现出由各种粒度特征表示的视图的区别.同时文本视图词粒度得到的特征向量空间维度过高,导致特征数较少的视图(图片和视频等多媒体信息)在聚类中的作用可能会被弱化.本文通过不同的标签生成方法来探讨混合粒度视图的粒度统一化.

图1 网络新闻结构示例Fig.1 Network news structure example
首先,由于新闻图片和多媒体视图中的数据特征通常是由几个高度语义概括后的词条组成,所以本文直接提取图片和多媒体信息视图中的数据特征,作为图片和多媒体视图的标签.
考虑到文本视图中是由成百上千的词粒度特征组成,本文首先在新浪新闻的基础上调用百度AI文章标签生成接口获得文本的标签,各视图的特征数量变化如表1所示.

表1 新浪新闻特征变化情况1Table 1 Sina news features changes 1
百度AI生成的标签会在一定程度上受到语料库的影响,进一步会影响标签质量.由于TF-IDF值可以用来评估某个词条的重要程度,所以本文将通过经典的TF-IDF提取新闻文本视图的关键词作为文本视图的标签特征.当新浪和网易新闻数据集的文本视图分别进行单独的聚类时,聚类效果随着关键词个数text_features取值的不同而变化,如图2所示.其中,横纵坐标分别指文本视图中的text_features取值和各评价指标的百分比.

图2 新浪和网易新闻单独的文本聚类效果Fig.2 Effect of separate text clustering on Sina andNetEase news
通过图2可以看出,当新浪和网易新闻的text_features取30时各聚类指标均表现较好,故本文提取文本视图TF-IDF值前30的关键词作为各新闻数据集文本视图的标签特征.其中,新浪新闻各视图的特征数量变化如表2所示.

表2 新浪新闻特征变化情况2Table2 Sina news features changes 2
2)视图间的融合处理
接下来,本文分析了新闻数据中不同视图单独聚类的效果.当单独对新浪新闻文本、图片和视频视图进行K-均值聚类20次时,结果如表3所示.
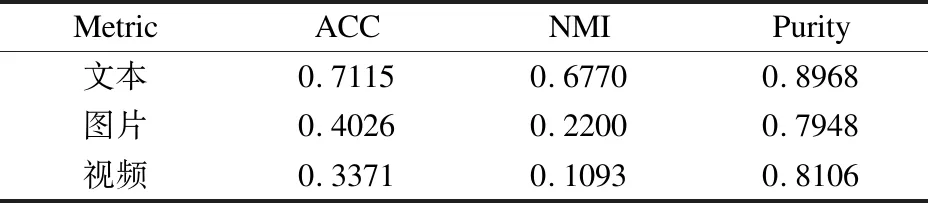
表3 单独的新浪文本、图片和视频数据聚类结果Table 3 Individual clustering results of Sina text,picture and video data
然后,简单融合新浪新闻各视图的特征后再进行聚类,得到的结果如表4所示.

表4 简单融合新浪新闻3个视图特征的聚类结果Table 4 Clustering result of simple fusion of three view features of Sina News
通过表3的结果可以分析出,图片和视频视图的数据对聚类结果有一定的作用.同时,新闻数据由于采样的特征空间的不同,造成了各视图样本并不一定均具有良好的聚类特性.通过表4中简单融合各个视图特征的聚类结果与表3单独的文本聚类结果对比,ACC、NMI和Purity分别降低了0.1986,0.3140,0.0843.实验结果说明在新闻数据各个视图特征的简单融合中,某些簇结构划分不清晰的特征的视图(文本、图片或视频视图)在整个多视图聚类的过程中的作用较弱,甚至会起到不好的作用,因此应减弱这种视图在聚类中的作用.
4 混合粒度多视图新闻数据聚类方法
针对上面提出的网络新闻每个视图特征的粒度不统一,各个视图对最终的簇结构的贡献程度不一样等问题,本文提出了一种混合粒度多视图新闻数据聚类方法(multi-view clustering of mixed-granularity news data,MVCN).首先通过TF-IDF提取出各个视图的特征作为视图的标签,使得文本、图片和多媒体信息等视图的特征统一为标签.同时,考虑到各个视图对最终的簇结构的贡献程度不一样,本文借助信息熵确定视图间的自适应权重.技术路线如图3所示.

图3 混合粒度多视图新闻数据聚类方法技术路线Fig.3 Technical route of mixed-granularity multi-view news data clustering method
4.1 各视图混合粒度信息统一为标签
本文通过特征选择使得各视图混合粒度特征统一到相同的标签粒度,减小了特征数较少的视图在聚类中被弱化的程度,最终提高聚类的效果.
首先,本文在第3部分简单的分析了文本视图中特征数量text_features的取值,在文本视图上采用词频-逆文本频率提取TF-IDF值前30的特征作为文本视图的标签信息.
本文中各个多视图新闻数据样本中特征的重要程度通过TF-IDF值来确定,图片和视频视图的特征数量分别由picture_features和video_features表示,本文设置各个视图特征数量取值在[5,50]区间,步长设为5,特征选取了之后再单独聚类,选取聚类性能最优的特征数量作为图片和视频视图的特征数量取值.
4.2 基于熵的视图间的自适应权重确定
考虑到各个视图对最终的簇结构的贡献程度不一样,本文借助熵确定视图间的自适应权重.具体的符号含义如表5所示.

表5 符号含义Table 5 The meaning of symbol
4.2.1 视图间自适应权重的确定
本文将权重看作概率分布,用熵来描述各个视图的权重.则视图权重可表示为:
(3)
通过将上述的加权项引入到多视图K-均值聚类中,则目标函数如下:
(4)
目标函数由两部分组成:首先是在标准的多视图K-均值算法上进行聚类,使各个视图的信息相互补充.同时,增加了视图权重参数w(v),引入超参数θ来控制各个视图的权重.最终的聚类效果与θ的取值有较大的关系,本文通过网格贪心搜索方法获取.
4.2.2 MVCN模型建立及参数求解
本文引入拉格朗日算子τ进行极值求解,构造拉格朗日目标函数L对公式(4)进行优化求解,函数构造形式及求解过程如下:
(5)
通过对公式(5)中w(v)求偏导,得到:
(6)

(7)
(8)
固定视图权重w(v),推导出各个视图的簇中心:
(9)
4.3 MVCN算法
混合粒度多视图新闻数据聚类方法(multi-view clustering of mixed-granularity news data,MVCN)的详细步骤如下所示:
算法1.MVCN算法
输入:数据X={x1,x2,…,xV}∈RN×Dv,V是视图总数,N为样本总数,Dv是视图v的特征维度,超参数θ,最大迭代更新的次数t.
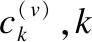

1.不同粒度信息的视图进行统一的标签生成处理
步骤1.分别提取各个视图的第n_sample个样本的TF-IDF值前text_features、picture_features和video_features的特征;
步骤2.n_sample=n_sample+1;
步骤3.如果n_sample>N,则文本视图标签生成处理结束,跳出循环,返回新的数据样本X;否则,跳回步骤1.
2.视图间自适应权重的确定
步骤1.利用公式(8)更新各个视图的权重w(v)
步骤3.n_run=n_run+1;
步骤4.当n_run>t时,则最终权重确定,结束循环;否则跳回步骤1.
本文提出的MVCN方法与多视图K-均值在时间性能上相似,为Ο(N×k×t×V).其中,N,k,t以及V均为上述MVCN算法描述中所示.
5 实验结果与分析
5.1 数据集
本文通过网络爬虫获得新浪和网易在2019年07月01日至12月01的新闻数据作为实验数据集.其中新浪新闻由3个视图组成,分别是词粒度特征构成的文本视图、高度语义概括后的标签粒度特征构成的图片和视频视图.网易新闻则由两个视图组成,分别是词粒度特征构成的文本视图和标签粒度特征构成的图片视图.
同时,本文还选用了UCI经典的Digits(手写数字图片)多视图数据集,由6个视图构成.
本文的混合粒度多视图新闻数据是通过TF-IDF来进行特征选择,使得各个视图统一为标签粒度,但Digits数据集则是通过卡方检验.设置特征数量取值在[2,50]区间变化,步长设为2,和新闻文本、图片以及视频视图一样,选取最优的特征数量作为最终的取值.上述的新浪、网易以及Digits的详细信息如表6所示.

表6 数据集详细信息Table 6 Details of the dataset
5.2 聚类有效性评价指标
本文选取常用的聚类有效性评价指标进行验证,分别为准确率(Accuracy,简称ACC)、归一化互信息(简称NMI)和纯度(Purity).具体定义如下:
1)ACC:它用来衡量聚类算法精确性.计算公式定义为:
(10)
其中,num表示聚类正确的样本数,N是样本总数.
2)NMI:利用熵计算聚类结果相似度.计算公式定义为:
(11)
其中,I(m,n)是互信息,H(m)和H(n)是信息熵.
3)Purity:其计算公式定义为:
(12)
其中,k是簇的数量,ni,j表示簇i和j的样本交集数.
上述3个指标的取值均在[0,1]区间,且越接近1越好.
5.3 对比方法
为了全面评估本文提出的MVCN多视图聚方法,对比算法的简要信息描述如下:
1)Pair-wise CoNMF算法:该算法是文献[4]中提出的一种通过成对共正则化,使得从两个视图中学到的系数矩阵可以在分解过程中相互补充的方法.
2)Cluster-wise CoNMF算法:该算法是文献[4]中提出的另一种方法.
3)PwMC算法:由文献[7]提出,基于拉普拉斯秩约束,通过引入超参数γ来学习权重,本文设置γ=0.6.
4)SwMC算法:该算法是文献[7]中通过分析PwMC算法的不足而提出的另一种新的完全自加权的多视图聚类方法.
5)SWMVC算法:由文献[10]提出,其实验效果与其样本重要度正则项参数λ有关,本文设置λ=0.5.
5.4 实验对比结果
MVCN是本文提出的混合粒度多视图新闻数据聚方法,其中参数θ的取值通过网格寻优方法获得,在新浪新闻和网易新闻两个新闻数据集以及Digits上均设为0.5.MVCN和其他方法20次实验的均值如表7、表8和表9,以及图4、图5和图6所示.
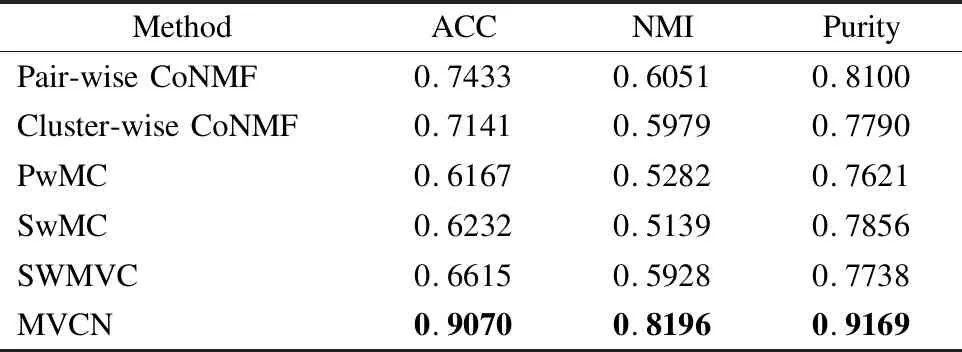
表7 不同聚类方法在新浪新闻数据集上的实验结果Table 7 Clustering results of different clustering methods on different multi-view news datasets

表8 不同聚类方法在网易新闻数据集上的实验结果Table 8 Clustering results of different clustering methods on different multi-view news datasets

表9 不同聚类方法在Digits数据集上的实验结果Table 9 Clustering results of different clustering methods on different multi-view Digits datasets

图4 不同聚类方法在新浪新闻数据集上的聚类结果Fig.4 Clustering results of different clustering methods on the Sina news dataset

图5 不同聚类方法在网易新闻数据集上的聚类结果Fig.5 Clustering results of different clustering methods on the NetEase news dataset

图6 不同聚类方法在Digits数据集上的聚类结果Fig.6 Clustering results of different clustering methods on the Digits news dataset
5.5 实验结果分析
由表7和表8可以得到,本文提出的方法在各个新闻数据集中的聚类效果有较好的提升,分析其主要原因是:1)Pair-wise CoNMF、Cluster-wise CoNMF、PwMC、SwMC和SWMVC并未考虑不同视图之间特征的差异,本文前几节一直强调新闻内容中,出现了不同语义层次、不同粒度的内容概念(直接的文本特征与标签特征)描述.本文通过特征选择,使得各个视图的特征均由标签粒度表示,不仅可以减少特征维度,而且能得到更好的聚类效果;2)Pair-wise CoNMF和Cluster-wise CoNMF是在假设各个视图的重要性程度一样的基础上进行的实验,未考虑视图的权重.
通过表9可以分析出本文提出的方法MVCN在Digits数据集上表现较弱,分析其根本原因是Digits各个视图的特征均由图像特征组成,并未出现不同语义层次、不同粒度的内容概念描述,且视图间互补的信息较少.
5.6 视图权重分析
为了进一步验证本文提出的MVCN方法,本文通过主成分分析法(简称PCA)将原始的高维数据(新浪和网易)降到二维,并在图7和图8进行了可视化展示.

图7 新浪新闻原始数据集Fig.7 Sina news raw dataset
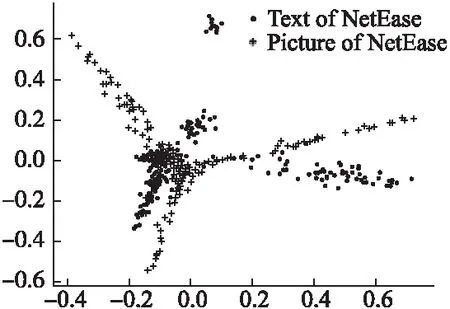
图8 网易新闻原始数据集Fig.8 Netease news raw dataset
通过图7和图8可以看到新闻文本视图和其他视图是互补的,但具有不同程度的噪声,文本视图的噪声相对于图片和视频视图要低一点.
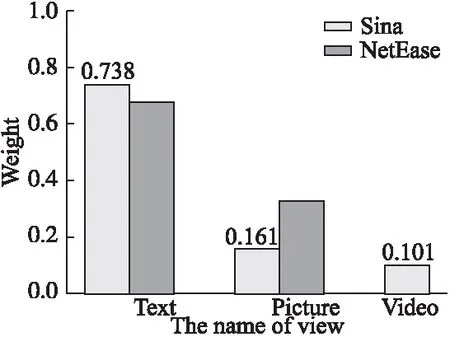
图9 MVCN在新浪和网易新闻数据集中学习到的各视图权重Fig.9 View weights learned by MVCN in sina and netease news datasets
然后,本文在图9展示了MVCN方法在两个新闻数据集Sina和NetEase上学到的视图权重.其中,横纵坐标分别是视图的名称和权重.
由图9可以看出,在新浪新闻数据集中,文本图片和视频视图权重分别约为0.74,0.16和0.10.在新浪和网易新闻数据集中,文本视图所占权重均大于其他的视图,和在图7和图8初步观察的结果相吻合,即文本视图更能反映数据的特性.同时,新闻图片和视频视图同样也包含一定的信息量.
6 结论与下一步工作
本文初步的研究了如何融合新闻文本、图片和视频等多媒体信息来对混合粒度多视图新闻数据进行聚类,这对于新闻聚类有了显著的效果.在混合粒度视图中针对不同粒度进行统一的标签生成处理中,本文通过对各个视图进行特征选择,使各个视图的特征统一到相同的粒度.同时,本文借助信息熵确定视图间的自适应权重,将3个视图更优的融合起来,然后再进行聚类操作.实验表明,本文提出的MVCN方法在新闻数据上的性能较好.
尽管本文的实验数据集各个视图的数据都是完整的,但视图间数据缺失的情况却不可避免.所以接下来将致力于解决各视图数据有所缺失的聚类问题.
