基于马尔科夫随机场的电信欺诈用户检测方法
2021-04-09高雅诗李静林
高雅诗,李静林
(北京邮电大学 计算机学院,北京 100876)
0 引言
近年来,频发的电信欺诈犯罪给百姓造成了巨大的财产损失,为此,司法机关和电信企业采取各种措施来防范电信欺诈,从大数据技术方面入手,运用人工智能方法以求遏制电信欺诈行为。
早期欺诈检测使用基础机器学习的算法进行用户通话特征分析[1-2],之后又引入自然语言处理,通过用户通话内容进行欺诈预测[3]。一些学者还使用了神经网络与其他相关模型相结合来完成欺诈检测[4]。以上方法均可以有效地帮助识别电信欺诈用户,但主要使用用户的通话内容,所需的数据存在特征维度大、需求时间跨度长等问题。
如今,对于欺诈的预测逐渐利用到了社交网络。目前,基于社交网络结构的方法可以分为2类:基于随机游走(Random Walk,RW)的方法和基于循环置信传播(Loopy Belief Propagation,LBP)的方法。RW主要是以边权对边缘概率的相对重要性(信任等级)建模[5-8];LBP则是用边权模拟共享相同标签的趋势[9-11]。RW一般无法同时鉴别正常异常,LBP一般不可扩展,不能保证收敛。
目前,大部分电信欺诈行为检测主要针对用户的通话数据特征进行检测,少有利用用户社交关系进行分类的情况,且后者大多利用用户社交网络的拓扑关系划分社区的方法,忽略了用户自身的数据特征。
面对大规模的电信用户欺诈行为预测分析,仍存在以下挑战:① 通信社交网络的建立。通信用户节点多,网络拓扑结构复杂,计算复杂度随之指数型增加,需要找到合适的网络数据计算方法。② 将概率理论与社交网络结合。主流的电信欺诈检测利用有监督的分类器进行二分类分析,生成离散型结果,误差影响较大,需要利用概率方式在社交网络中计算电信欺诈用户的欺诈概率,形成半监督式分类模型。③ 将用户数据的统计特征与社交网络结合。社交网络的相关算法主要利用了社交网络的拓扑关系,忽视了数据本身的特征,需要将用户的数据特征置入到社交网络中,帮助优化预测模型。
针对以上问题,可以用概率图模型来尝试解决。利用概率图模型中的马尔科夫随机场(Markov Random Field,MRF)对通信用户社交网络进行建模,根据通话用户的欺诈行为特征设计相关的图结构及相应的概率分布关系,对用户的行为特征与用户间亲密度关系加以描述,最终利用相关算法进行分析预测。
1 基于MRF的电信用户欺诈行为建模
MRF是概率图模型中的一种生成式模型[12],利用概率论中的贝叶斯原理,建立数据间的概率分布关系。根据电信用户的社交特点,利用MRF模型来设计相应的逻辑结构,搭建电信用户欺诈行为的概率分布,以辅助完成对欺诈行为的分析预测。电信用户的MRF可设为G(V,E),节点V表示通信网络中的各个用户,拥有各自的数据特征,设为先验概率;边E表示各个节点间的相关关系,利用整体社交网络关系,形成MRF的联合概率,从而构成整体的概率分布。由此在随机场中传递节点的特征信息,获得各节点的后验概率来判断最终的分类预测结果。电信欺诈检测流程如图1所示。

图1 电信欺诈检测流程Fig.1 Telecom fraud detection flow
1.1 电信用户的特征情况分析
社交网络中,一般存在5种用户的相关特征:属性特征、网络特征、内容特征、活动特征与辅助特征[13]。本文使用电信通话用户的通话数据,根据电信用户的通话情况,可以提取出如下特征:
属性特征:基于用户的长期用户详单,可以据此分析用户的日常通话行为,作为代表用户属性的特征。
网络特征:利用用户间的通话关系,可以构建出电信用户的通信社交网络,并在网络中总结出相关网络特征,例如度、中心性和聚类系数等。
活动特征:根据用户间的通信活动情况,例如用户间通话时长、通话频次和呼损原因,作为活动特征计入在特征范围内。
根据以上特征可以为节点特征、节点间特征添加对应的计算因子,最终通过信度传播来更新联合概率,推算出节点的预测值。
1.2 用户节点先验概率的设计
MRF中节点的先验概率一般由该节点的特征来表示,此模型利用电信用户的属性特征来进行计算。将节点u的分类情况设为Xu,当Xu=1时,该用户为正常用户;反之,该用户为欺诈用户。同时,将电信用户的长期特征设为cu,主要包括通信用户的通话频度、通话平均时长和通话时间区间等,作为行为向量特征。在此基础上,使用逻辑回归来进行先验概率的计算:
(1)
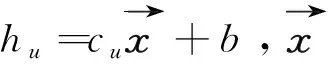
在社交网络中,用户间存在相互影响的相互关系。可设置根据前期对电信用户的调研工作,总结以下基本情况:
① 双向:经常相互通信的用户双方有相似的通信特征,存在同构相似,符合社交网络中社区集中的特点。
② 单入:欺诈用户通常不会作为被叫用户接到正常用户的通话,所以一般情况下,欺诈用户的主叫用户为欺诈用户。
③ 单出:正常用户通常不会主动与欺诈用户通话,所以一般情况下,正常用户的被叫用户为正常用户。
根据此情况,可以设计出在邻居用户影响下,节点u的先验概率的情况。根据社交网络中的有向边情况,设置节点u的双向邻居集合N(u)、单向被叫邻居集合I(u)、单向主叫邻居集合O(u),每一个邻居都对节点有不同影响力设为Yuv。据此可根据邻居节点不同情况,设计不同的先验概率计算方法。
面对双向通话的用户,二者间存在相互影响,会将自身的信誉度传播给其邻居,使其逐渐同质化,由此可得:
(2)
面对单向被叫用户,如果邻居为正常用户,则可以推出该用户大概率为正常用户;反之,则不能确定该用户是否为欺诈用户。所以,单向被叫用户只受正常用户的信誉度影响。面向单向主叫用户,如果邻居为欺诈用户,则可以推出该用户大概率为欺诈用户;反之,则不能确定该用户是否为欺诈用户,所以,单向主叫用户只受欺诈用户的信誉度影响。据此可以得到,根据邻居影响的用户节点的先验概率分布φu(xu)为:
(3)

1.3 用户关系连接边的势函数设计
MRF中节点的先验概率确定后,再考虑边的表达方式。网络中的边表示的是用户之间的相关关系,在传导过程中根据之前确定的欺诈用户与正常用户之间的关系,可以设计用户间的势函数。由文献[15]中的双向边势函数可推导出单向边的势函数为:
(4)
式中,wuv为两用户节点间的亲密关系程度。根据社交网络的情况,可以利用二者的相似关系来确定二者的亲密度关系,本文使用了皮尔森相似度来进行计算:
(5)
基于上述设计电信用户的MRF,G=(V,E)中先验函数φu(xu)与势函数φuv(xu,xv),可以求得MRF中的联合概率分布:
(6)

2 利用循环置信传播推导后验概率
置信传播算法利用节点与节点之间相互传递信息更新当前整个MRF的标记状态,是基于MRF的一种近似计算。该算法是一种迭代的方法,可以解决概率图模型概率推断问题,而且所有信息的传播可以并行实现。经过多次迭代后,所有节点的信度不再发生变化,就称此时每一个节点的标记即为最优标记,MRF也达到了收敛状态,从而得到最优的联合概率,最终求出节点的后验概率,作为该节点的欺诈预测概率。
2.1 置信传播算法
置信传播算法一般分为sum-product和max-product两种传播模式,本文使用max-product进行相关计算。
具体消息传播公式为:
(7)
式中,包含所有其他传入节点u的消息乘积;L(v)/u表示节点v的MRF一阶邻域中排除目标节点u的邻域;mvu(xu)可以通过网络中的消息传播不断迭代,用自身上次迭代的消息结果结合节点u自身的先验概率和节点u与邻居v之间的势函数,计算出此次迭代mvu(xu)的结果。理想情况下,当节点间的消息传递不再变化,则达到完全收敛,此时会得到MRF的最优联合概率分布。根据联合概率分布求得各个节点的后验概率:
(8)
式中,zu为归一化函数。在具体实验过程中,循环置信传播不能保证在有限次循环之后能够完全收敛,所以设置收敛线α∈[10-4,10-7],2次消息变化较小时,则可以认为该过程已实现收敛。
2.2 循环置信传播的优化
为简化最终的函数表达方式,算法中设pu表示Pr(xu=1),qu表示φu(xu=1),mvu表示mvu(xu=1)。因为归一化不影响先验概率的计算和消息传递的效果,所以φu(xu=1)+φu(xu=-1)=1,mvu(xu=1)+mvu(xu=-1)=1,化简后为:
(9)
置信传播算法中,仍存在可扩展性不足,主要是因为算法中在社交网络图的每一个边缘都在进行信息上的维护,其关键原因在于2个节点不能同时向对方传递消息,实质上是当用户节点v向其邻居节点u准备消息时,它排除了邻居节点u发送给用户节点v本身的消息。文献[15]指出,计算节点(v,u)间消息传递mvu中没有排除邻居节点u给用户节点v的消息,并不影响MRF的收敛性。算法优化时,消息传播可以允许当v为u准备消息时,u发送给v的消息。消息传播公式变换为:
(10)
3 实验分析
3.1 实验数据分析
本模型采用运营商的真实数据集,其中记录了从2019年5月27日-6月8日所有的cdr呼叫详单,共计4 582 674条数据,欺诈行为数据82 133条,并且数据集中仅包含在采样期内活跃的用户。具体用户特征如表1所示。

表1 用户特征
在实验前,首先进行数据预处理,了解数据的分布情况,对数据进行清理工作。对通话记录按照时间长度进行数据划分并特征提取,将整合处理后的数据分为3类。目前,将特征分为3部分:一是单条数据下的通话特征,例如通话时间区间、通话时长和呼损原因等,用于2节点间的关系计算;二是单个主叫用户在单日的通话特征,通话次数、通话平均时长,通话高频区间等,用于该节点的主要属性特征计算;三是单个主叫用户的长期的通话特征,其时间跨度较长,后期可加入时间特征进行迭代更新。此外,对数据集进行随机采样处理,其中70%数据用于训练,10%数据用于验证,20%数据用于测试。
3.2 用户亲密度的计算方式对比
在设置MRF势函数的过程中,主要利用了节点间的亲密度关系进行计算。计算用户间的亲密度主要利用用户间的相似关系或者社交关系,例如余弦相似性、欧氏距离相似性和皮尔森相似性等;或利用用户间的信任度计算,其中,直接信任度计算主要通过节点的关联关系进行,在网络G中若u和v有直接联系,则u对v有直接信任关系,直接信任度T(u,v)为1,否则为0。归一化处理后得到的直接信任度:
(11)
本文就以上几种方式进行对比,各相似度关系计算结果对比如图2所示。

图2 各相似度关系计算结果对比Fig.2 Comparison of similarity relationship calculation results
仅利用节点间的社交关系,在归一化后结果差距不明显,导致最终结果欠佳。皮尔森与优化余弦相似性算法相同,只是归一化方法不同,3种相似性准确度结果差距不明显,仅仅在召回率上有较小差别。利用欧氏距离相似性计算用户间的亲密度,效果更好。
3.3 模型分类结果对比
实验中采用基础的分类器模型进行比较:
逻辑回归:对数几率模型,使用其固有的logistic函数估计概率,完成二分类任务。
决策树:决策分类树,利用树节点代表数据属性特征,进行分类决策。
随机森林:多个决策树的分类器。
XGBoost:提升树模型,boosting算法中的一种,将许多CART回归树模型集成在一起,形成一个强分类器。
MRF:先验函数为用户标签,势函数均为常数值>0.5。
LR+MRF:利用逻辑回归方式将用户特征转换为用户节点的先验概率,将用户间的亲密关系程度作为用户间的势函数。
将用户详单数据置入各模型中,结果如表2所示。
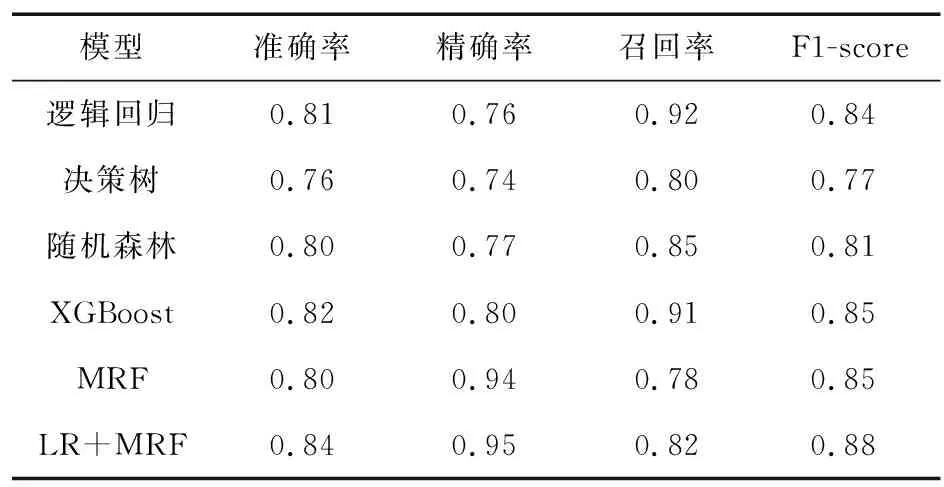
表2 各模型分类结果
由表2可以看出,基于MRF的欺诈用户分析模型可以有效地对存在欺诈行为的用户加以区分。其中,精确率较基础分类模型有了较大提高,主要是因为模型将用户的基本特征和用户间关系特征利用概率图算法连接起来,从而提高了模型的精确率。而模型的召回率较低,主要原因在于数据中的欺诈用户占比较小,分布较为分散,欺诈用户二者间连通性较弱,导致召回率比没有利用网络关系的模型低。综上,通过基于MRF的社交网络模型,能够对用户欺诈行为进行较好的预测。
4 结束语
提出了一种基于MRF的电信欺诈行为分析模型,在此随机场中利用逻辑回归对用户节点赋特征值,设计节点间亲密度表示节点间的关联关系,之后利用循环置信传播方式计算MRF的消息传播得到最终的后验概率,完成欺诈用户行为的预测判断。通过将真实数据集置入MRF模型中,与其他欺诈检测方法进行比对,对本文模型进行评估。实验证明,利用概率图MRF与逻辑回归相结合对电信欺诈行为进行检测,能够获得较优的结果。之后的研究中,可以通过引入更多的通话特征,对具体算法进一步优化,以更好地完成电信欺诈行为的预测。
