基于图挖掘扩展学习的增强需求跟踪恢复方法
2021-04-09王丹丹
陈 磊 王丹丹 王 青,2,3 石 琳
1(中国科学院软件研究所互联网软件技术实验室 北京 100190)2(计算机科学国家重点实验室(中国科学院软件研究所) 北京 100190)3(中国科学院大学 北京 100049)
在软件开发中,需求跟踪是连接开发阶段中重要活动的链条[1],可以辅助软件开发生命周期中很多活动的执行,比如软件维护[2]、变更影响分析[3]、需求验证[4]、需求重构[5]、需求复用[6]、测试用例生成[7]和源代码理解[8]等.因此获得软件工程师及其公司的重点关注[9].然而,建立和维护需求跟踪关系是一件耗时而且繁琐的事情,特别是对于一个大型和(或)复杂、周期长的系统,手工创建和维护准确的跟踪链接是需要耗费大量人力、时间而且容易出错[2,9].大量的实践经验表明:成本及效率问题是制约需求跟踪使用的根本原因.
为解决该问题,研究人员提出了各种不同的解决方案,以自动化技术为手段辅助开发人员建立和维护需求跟踪关系,从而降低成本.其中最常用的是基于信息检索(information retrieval, IR)[10-14]的方法.该方法利用IR模型计算需求文本与软件制品文本之间的文本相似度,并按照文本相似度的大小进行排序,通过设置阈值筛选需求与软件制品之间的跟踪链接.通常需求与软件制品之间的文本相似度越大,它们之间的跟踪关系就越有可能是正确的,反之则越有可能是错误的.虽然基于信息检索的方法能够有效地恢复需求与软件制品之间的跟踪链接,但是由于不同的软件制品通常遵循不同的规范并使用不同的术语[15],忽视了自然语言中语法对于准确语义表达的影响,尤其是词序信息的缺失.这就容易造成不同制品之间出现术语匹配错误的问题,因此建立跟踪关系的精确率和召回率往往低于预期.为了解决这个问题,研究人员利用深度学习技术来自动学习软件制品的语义表示,并使用该语义表示来建立跟踪关系[9].与信息检索方法相比,深度学习方法可以获得较高的跟踪精确率和召回率.然而,这些深度学习方法是有监督的学习方法,需要依赖大量标注数据来训练有效的神经网络模型,而获取标注数据是非常费时费力的事情,这限制了它们在实际工作中的应用.
为此,研究人员探索无需标记训练数据生成跟踪链接的无监督学习方法.其中,词向量模型[16]通过建模术语的上下文来捕获软件制品的语义,一定程度上解决术语不匹配问题,在无监督生成跟踪链接中获取了不错的性能.但是针对这些无监督的学习方法,为学习制品更加准确和完整的语义,需要在此基础上同时解决2个问题.
1) 需求的粒度在软件开发过程中是不断变化的.比如从粗粒度(例如高等级需求(high-level requirements, HL)和用例(user cases, UC)到细粒度(例如低等级需求(low-level requirements, LL)、交互图(interaction diagrams, ID)、测试用例(test cases, TC)和代码类文件(code classes, CC),这是一个粒度由粗到细的过程.粗粒度制品和细粒度制品之间描述因粒度差异导致缺乏或没有相同主题词的关联,也就是同一语境的词共现分布信息,从而出现关联制品无法匹配的问题.例如,表1所示的2个制品应该有一个跟踪关系,但是由于它们之间大部分的词是不同的,很容易被错误链接.

Table 1 A Sample Terms of Artifacts Matching表1 一个制品词匹配样例
2) 制品文本中的词序信息通常被忽略了.例如,有2个需求描述为“…,Persons can be assigned to work on tasks”和“…provide ability to assign persons to tasks”,在实际语境中,它们是没有跟踪关系的,但可能会被错误地关联在一起.因为基于词袋模型的信息检索方法和词向量模型均不考虑词序.
为了解决这2个问题,本文提出了一种基于图挖掘扩展学习的增强方法——GeT2Trace,用来生成需求跟踪链接.该方法利用图网络模型,构建项目级和制品级2个不同粒度的文本网络,根据项目级的文本网络挖掘项目内的共现词信息,同时根据制品级的文本网络挖掘制品内的词序信息;然后,GeT2Trace利用已挖掘的共现词信息和词序信息对制品文本信息进行扩展,增强制品的语义表示,并将其输入无监督神经网络向量学习模型中进行学习;最后,根据学习结果对制品间的跟踪关系进行恢复.
本文的主要贡献有3个方面:
1) 利用词图模型(graph-of-word, GoW)的方法将软件制品转换为文本网络表示,然后基于图挖掘的共现词和词序信息增强制品的语义表示;
2) 提出了GeT2Trace方法,该方法通过扩展共现词和词序信息来增强制品文本的表示,并将其输入无监督神经网络向量学习模型中学习和恢复相关软件制品的跟踪关系;
3) 在5个公共数据集进行了评估,实验结果表明GeT2Trace在精确率、召回率和F2上优于VSM,LSI,WQI,S2Trace和PV-DM-CoT这5种基线方法.
1 相关工作
在本节中,我们讨论之前的相关研究工作和方法,以及与我们研究工作的不同之处.
1.1 基于信息检索的方法
信息检索是一种最为广泛的用于解决需求跟踪问题的无监督方法.典型的模型包括:向量空间模型(vector space model, VSM)[12]、潜语义索引模型(latent semantic indexing, LSI)[11,13]和潜在狄利克雷分配模型(latent Dirichlet allocation, LDA)[14].然而,由于软件制品间存在术语不匹配的问题,因此通过信息检索建立的跟踪链接结果并不是很理想.为解决该问题,一些研究人员通过向文档的向量空间模型中添加新信息和特征来提高其跟踪性能.Hayes等学者[10]利用同义词典方法来处理制品中的同义词,以此减小软件制品之间的术语不匹配带来的影响.Capobianco等学者[12]提出通过词性标注来提高信息检索方法的性能.Zou等学者[17]提取制品中的关键短语,并使用项目术语表给最重要的术语赋予更高的权重.此外,Dietrich等学者[18]提出采用查询扩展策略,通过将用户反馈扩展到查询中,再合并到跟踪检索过程以提高生成的跟踪链接的质量.王金水等学者[19]利用句法分析抽取制品中具有代表性的动词和名词术语,以减轻噪音数据的负面影响.虽然以上研究在一定程度上缓解了制品间术语不匹配带来的问题,改进了基于信息检索方法建立跟踪关系的性能,但是这些方法都没有考虑软件制品的语义.
1.2 基于本体的方法
本体是表示指定领域中存在的实体及其形式化规范,它在语义级别明确和关联软件制品的概念和关系,帮助解决需求跟踪中软件制品之间术语不匹配的问题[20].Guo等学者[21]利用句法解析来提取特定本体,并建立启发式策略来对本体概念之间的语义关系进行推理,以创建准确的跟踪链接.Li等学者[22]将来自通用领域本体和特定领域本体的信息合并到跟踪过程中,提出根据本体中概念之间的距离对跟踪链接进行加权,从而更为准确地恢复跟踪链接.Rao等学者[23]提出了一种基于规则的语义本体选择方法,用来生成源制品与目标制品之间的链接.其核心思想是在词网(WordNet)的辅助下建立修饰语与关键词的启发式规则,并对关键词进行语义选择和调整.然而以上方法在标注本体的过程中会受到现有语法解析工具对复杂长句的解析不准确的影响,并且都需要手工建立合理有效的本体和启发式推理规则,这是一个复杂而繁琐的过程.
1.3 基于机器学习和基于深度学习的方法
机器学习和深度学习作为近些年应用于需求跟踪领域的技术,经过大量实践表明是解决需求跟踪问题的有效途径之一.Guo等学者[9]提出了一种基于深度学习的神经网络架构,使用一组来自大型工业数据集预训练的词向量和递归神经网络(recurrent neural network, RNN)来自动生成跟踪链接.Zhao等学者[24]提出了一种基于词向量的方法WQI,该方法采用预先训练的软件工程领域的词向量和逆文档频率(inverse document frequency, IDF)权重的查询扩展来改进制品间文本相似度算法.Wang等学者[25]使用Doc2vec模型学习制品的语义表示,并作为特征输入到有监督的机器学习算法中,预测制品之间的语义相关性.Chen等学者[26]提出了一种最先进的无监督方法S2Trace,该方法结合了序列模式挖掘和Doc2vec模型来生成软件制品的文档向量,借助软件制品中的词序信息为构建准确的跟踪链接提供额外的帮助.然而,以上方法没有同时解决由于不同粒度的制品术语不匹配和缺乏词序信息的问题,导致学习到的制品语义往往不精确和不完整.另外,有监督的机器深度学习方法需要大量的数据标注才能训练有效的预测模型,这限制了它在实际工作中的应用.
2 背 景
在本节中,我们主要介绍基于图的文本表示和文档向量表示及其应用,并且将基于文本网络的图挖掘和文档向量的概念引入需求跟踪的研究中.
2.1 基于图的文本表示
在自然语言处理领域中,传统词袋模型的文本表示方法假设文本中的词与词之间是相互独立的,忽略了词与词之间顺序的依赖关系来进行语义表示.但是,由于词作为表示文本语义的最小单元,一个词的语义通常是由它的上下文决定的,换句话说,词的语义受到其周围词的影响,所以词与词之间的顺序和位置在表示句子或文档语义时是重要的信息.
为了克服传统词袋模型的缺点,Rousseau等学者[27]提出了一种基于词共现的文本网络模型,称为词图模型(GoW).基于2个词的距离越接近,词与词之间的相关性越强的假设,该模型将纯文本转化为带结构信息的文本网络,借助丰富的结构信息捕获词之间的语境(即上下文)依赖和词序信息.根据文本挖掘的需要,词图模型通过设置滑动窗口大小、边方向、边权重3个参数来生成不同的文本网络,其中滑动窗口大小作为词图模型最重要的参数,用来控制构建文本网络语境的范围.例如,1)在一个滑动窗口内同时出现一个或多个词的无向图,这些词作为目标词的上下文来丰富该词的语义表示,换句话说,窗口内共现的词构成了目标词的语境.2)表示词序信息的有向图,边的方向表示文本流的方向,符合人们对文本信息的阅读习惯和理解方式.3)用一个加权图表示滑动窗口中的词之间的关系,边的权重大小表示词与词之间关系的强弱,换句话说,关系越强的词越有可能在同一语境中.在以往的研究中,词图模型被用来提高信息检索[27]、关键字提取和文本分类[28]的性能.因此,我们利用词图模型将软件制品转换为文本网络表示,挖掘有意义和有区别的文本特征.据我们所知,在需求跟踪领域中,词图模型尚未应用于制品表示的构造上.
2.2 文档向量表示
Doc2vec[29]作为对Word2vec的扩展,是一种无监督的浅层神经网络学习模型,能够联合学习词向量和文档向量.与Word2vec相比,Doc2vec使用固定长度的向量表示任意长度的句子、段落和文档,所包含的信息更加丰富多样.Doc2vec模型分为2种变体:分布式内存段落向量(distributed memory paragraph vectors, PV-DM)模型和分布式词袋段落向量(distributed bag of words paragraph vectors, PV-DBOW)模型.PV-DM考虑了词序在语义表示的作用,在一个文本窗口内,通过句向量和词向量的首尾相接来预测下一个词.而PV-DBOW则不把上下文中的词作为输入,而是强制模型在输出中从句子中随机抽取词汇来进行预测.例如,PV-DBOW利用文档向量来预测文档中包含的词向量.具体地说,D={Doc1,Doc2,…,Docn},目标文档Doct∈D,需要学习其向量表示f(Doct)={Word1,Word2,…,Wordm},PV-DBOW的训练目标是预测文档Doct中出现的某个词的最大对数概率:
(1)
Pr(Wordi|Doct)也由softmax函数定义:
(2)
其中,wi和Dt分别是词Wordi和文档Doct的向量,V是D中所有文档中所有词的个数.Doc2vec中学习得到的文档向量可以计算相似文档在向量空间中的聚类距离,也可以将其输入到有监督的机器学习模型中学习分类器.
3 本文方法
在本节中,我们主要介绍GeT2Trace方法的实现步骤,并且将词图概念引入软件制品文本网络建模中.GeT2Trace的概述如图1所示.其主要思路是通过挖掘制品的文本网络中的语义特征来增强制品文本的语义表示,然后利用Doc2vec模型来学习和比较制品的语义相似性.我们的方法分为6个步骤.
1) 构建文本网络.对于需要建立跟踪链接的制品,首先通过词图模型将其转换为2个不同粒度的文本网络:在项目级别,构建一个加权无向图;在制品级别,为每个制品构建一个无加权的有向图.
2) 挖掘共现词.基于项目级文本网络,挖掘粗粒度制品的共现词(co-occurrence terms, Co -Terms),用于弥补粗粒度制品与细粒度制品之间的术语不匹配的问题.

Fig. 1 Overview of GeT2Trace图1 GeT2Trace方法概述
3) 挖掘频繁子图.基于制品级文本网络,挖掘每个制品的频繁子图(frequent subgraphs, FSGs),获取制品的词序信息.
4) 扩展制品特征.将原始软件制品的文本进行扩展,分别添加步骤2得到的对应的共现词到粗粒度制品中和步骤3得到的频繁子图到对应的粗粒度和细粒度制品中.
5) 学习增强的制品表示.基于步骤4中扩展的制品表示,构建一个Doc2vec模型来学习每个软件制品的文档向量作为其语义表示.
6) 跟踪链接恢复.通过计算2个扩展制品向量之间的余弦相似度来恢复跟踪链接.
3.1 构建文本网络
使用词图模型将软件制品从纯文本文档转换为文本网络.构建文本网络之前,我们首先进行制品文本的预处理:
1) 删除无意义的字符.对所有文本执行标记化(tokenization)操作,删除非字母字符、标点符号、停用词、无意义的术语.
2) 分词.从制品中的标识符中提取有意义的单词.标识符是连接2个或多个单词(或缩写)或任何其他分隔符(如下划线)的复合词.采用骆驼拼写法拆分复合词.
3) 词干提取.制品中的每个单词都使用Snow-ball(1)https://snowballstem.org/词干器进行词干处理.
在对制品文本进行预处理后,我们将制品文本信息输入词图模型构建2个不同级别的软件制品文本网络.
3.1.1 项目级文本网络
项目级文本网络是由词图模型将一个项目的全部制品转换成一张加权无向图,定义为Gp=(Vp,Ep).Gp捕获术语的共现关系,Vp是项目中所有软件制品中提取的一组术语,eij∈Ep是一个加权边,表示节点vi和vj共同出现在滑动窗口中.将节点vi与vj之间边的权重wij定义为Jaccard系数:

(3)
其中,Oi和Oj是分别包含出现术语vi和vj的制品的数量.通过设置滑动窗口的大小控制每个术语的上下文范围,较小的窗口大小,词与词的关系越紧密越有意义,反之词与词的关系越疏远,变得没有意义[27].共现频率高的词对,它们之间的Jaccard系数也高,代表越相似.图2给出了一个项目级文本网络的例子,如果在一个项目中有3个制品(如图2的左边所示),所构建的项目级文本网络Gp将显示在右边,滑动窗口的大小被设置为3.
3.1.2 制品级文本网络
制品级文本网络是由词图模型将每个制品单独转换为无加权有向图,定义为Ga=(Va,Ea).对于每个制品,Ga捕获术语之间的词序,Va是术语的集合,Ea是有向边的集合.eij∈Ea表示术语vj在滑动窗口中出现在术语vi之后.为了所捕获的术语之间的词序信息更有意义和区别性,在构建制品文本网络时限制2个相邻术语之间的距离是必要的[28],因为在下一步的频繁子图挖掘中,距离较近的词可能在同一语境中,而距离较远的词可能分别在2个不同的上下文中.另一个原因是它可以减少冗余带来的噪声信息.例如,当滑动窗口的大小设置为3时,将软件制品表示为图3中给出的无加权有向图.
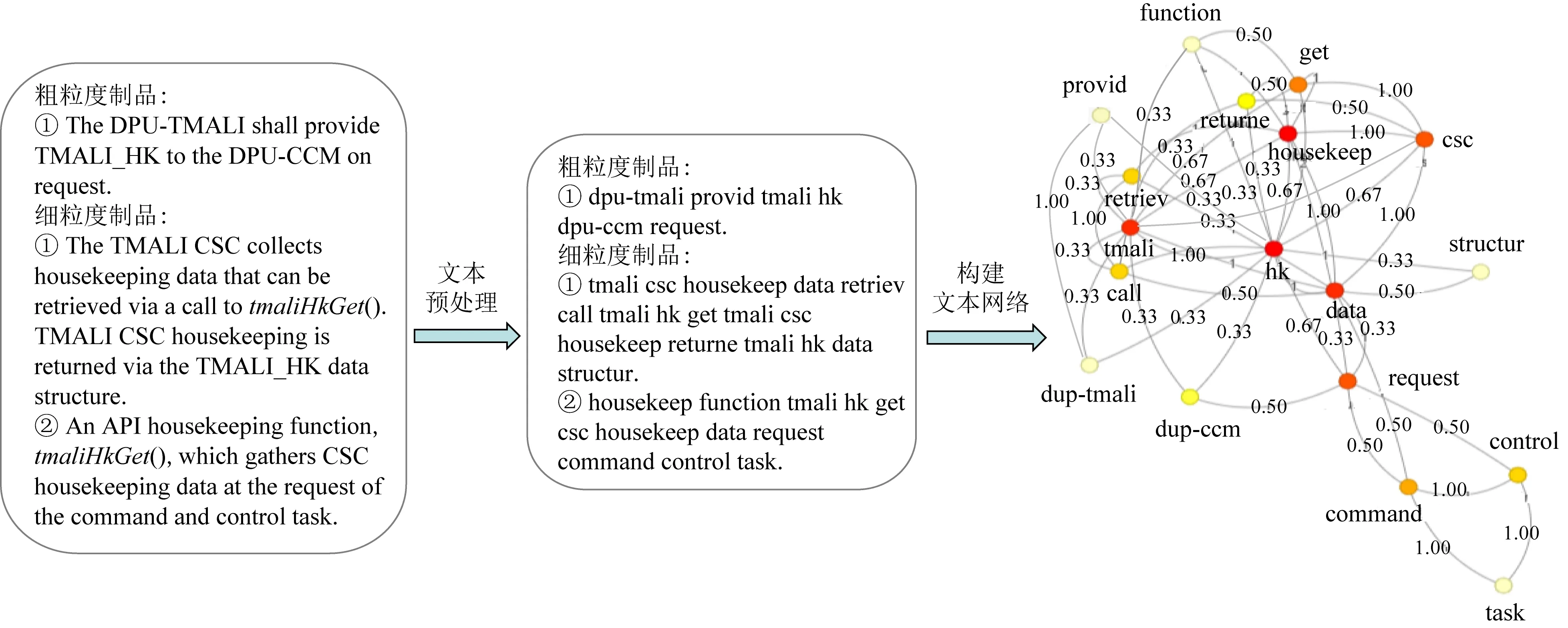
Fig. 2 An example of the project-text network图2 一个项目级文本网络例子

Fig. 3 An example of the artifact-text network图3 一个制品级文本网络例子
3.2 挖掘共现词
正如我们之前提到的,粗粒度制品和细粒度制品的描述存在词汇差异,导致缺乏共享信息来构建相应的需求跟踪链接.我们通过能提供丰富信息的跨制品文本的共现词来扩展粗粒度制品.通过3.1.1节构建的项目级文本网络,已经将每个术语和与之对应的上下文连接起来,我们挖掘该文本网络中共现词构建粗粒度制品和细粒度制品之间的相关性,其共现信息里还包含语境信息,换句话说,共现词与相应的粗粒度制品的语境密切相关,具体定义和操作为:
对于粗粒度制品中的每一个术语Vi,以Vi为中心节点,构建词共现子图(co-occurrence subgraphs,SGco),定义为SGco=(Vi,Vco,Eco),其中SGco∈Gp,Vco为Vi相邻词的集合,Eco为边的集合,为每个vj∈Vco.eij∈Eco为Vi与vj之间的边.边的权重wij为Vi与vj之间的Jaccard系数.Vco中的词表示为Vi的共现词.共现词作为扩展粗粒度制品中术语Vi的候选术语.例如,以图2中粗粒度制品(粗粒度制品-1)为例,图4显示“tmali”词的共现子图和“tmali”的所有共现词及其权重,表2中列出了从粗粒度制品包含的所有词的共现子图中提取的共现词及其权重列表.

Table 2 Co-Terms List表2 共现词列表
3.3 挖掘频繁子图
如引言所述,词序信息通常被忽略,这导致只能捕获软件制品的部分语义,从而生成不准确的跟踪链接.为了解决这个问题,我们通过挖掘频繁子图(FSGs)来解决这一问题,频繁子图相当于制品中的短语或词与词的序列,所包含的词序信息有助于制品精确语义的表示.通过3.1.2节构建的制品级文本网络(即制品图),我们使用基于深度优先搜索算法gSpan[30]来挖掘频繁子图,该算法保留了从制品图中发现的词序信息.因为gSpan可以通过深度优先搜索策略有效地枚举所有的频繁子图,在频繁子图的挖掘过程中,gSpan通过支持度参数来控制挖掘的频繁子图的数量.支持度定义为
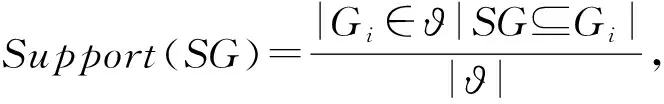
(4)
其中,制品图Gi在图集合ϑ中,制品图Gi包含子图SG.
在确定频繁子图时,需要设置一个最小支持度,如果某一子图的支持度大于或等于最小支持度,则该子图表示为频繁子图,用于对制品特征进行扩展.如图5左图所示制品图集合ϑ={G1,G2,G3},该集合ϑ包含3个制品图.如果我们将最小支持度设置为0.5,gSpan从集合ϑ中挖掘出3个子图SG1,SG2,SG3,如图5右图所示.由于SG1,SG2,SG3的支持度均大于或等于最小支持度,SG1,SG2,SG3是我们所需要的频繁子图.每个频繁子图将被分配唯一的编码作为其标识.当扩展特征时,编码将用于表示频繁子图.
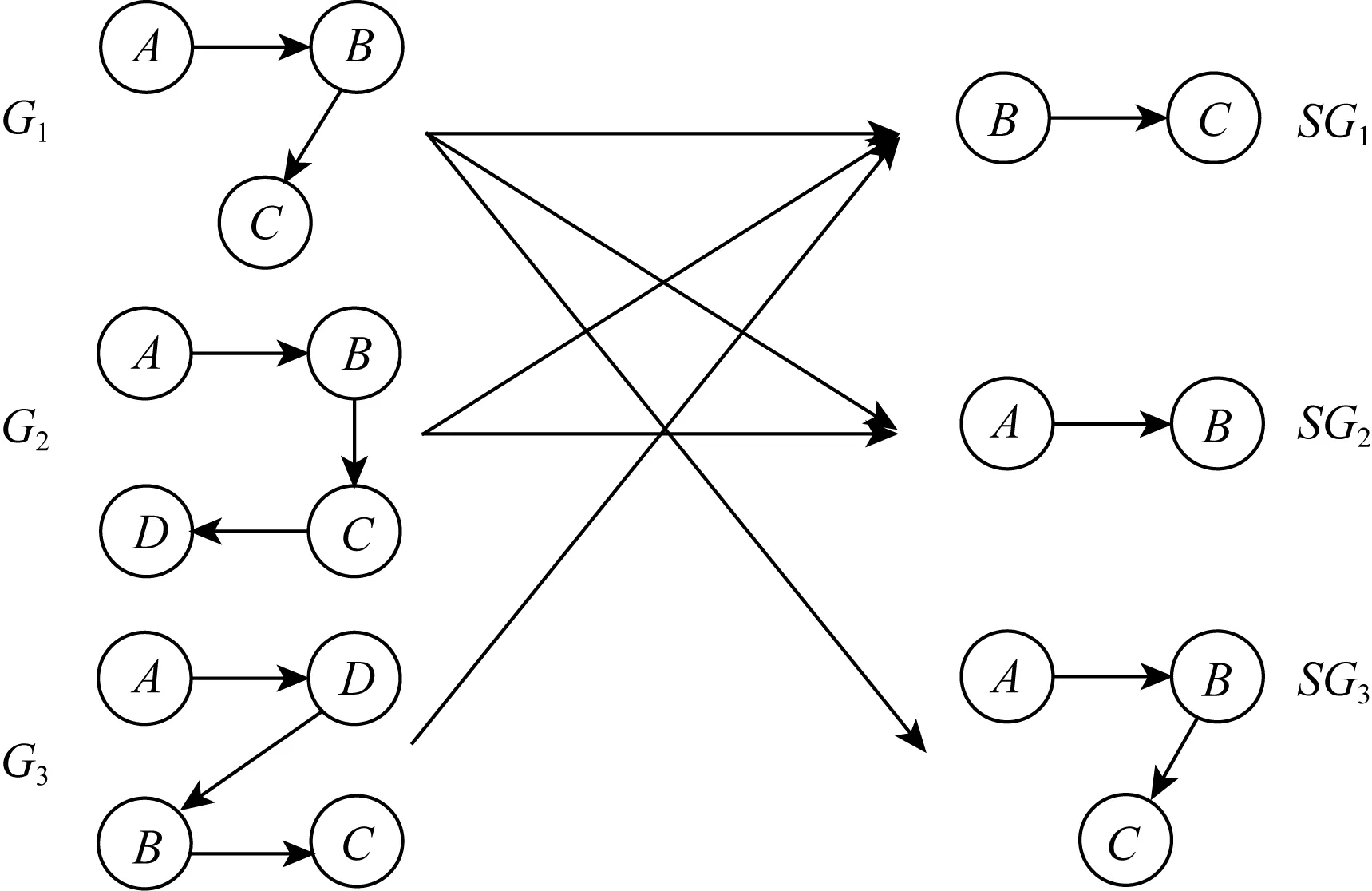
Fig. 5 An example of FSGs mining by gSpan algorithm图5 通过gSpan算法挖掘频繁子图的例子
3.4 扩展制品特征
通过3.1~3.3节中步骤挖掘出的共现词(Co -Terms)和频繁子图(FSGs)用于扩展制品可以增加制品新特征空间的语义表达能力,因为它们是单一特征集上的非线性特征组合.在机器学习领域,从单一特征到非线性特征的映射得到了广泛的应用.但是共现词和频繁子图可能存在数量较多的问题,为了保留更有意义和区别的特征用于扩展制品,同时减少噪声对模型的影响,我们通过权重意识的方法选择共现词和Elbow方法过滤频繁子图,具体操作如3.4.1和3.4.2节所述.
3.4.1 为粗粒度制品扩展共现词
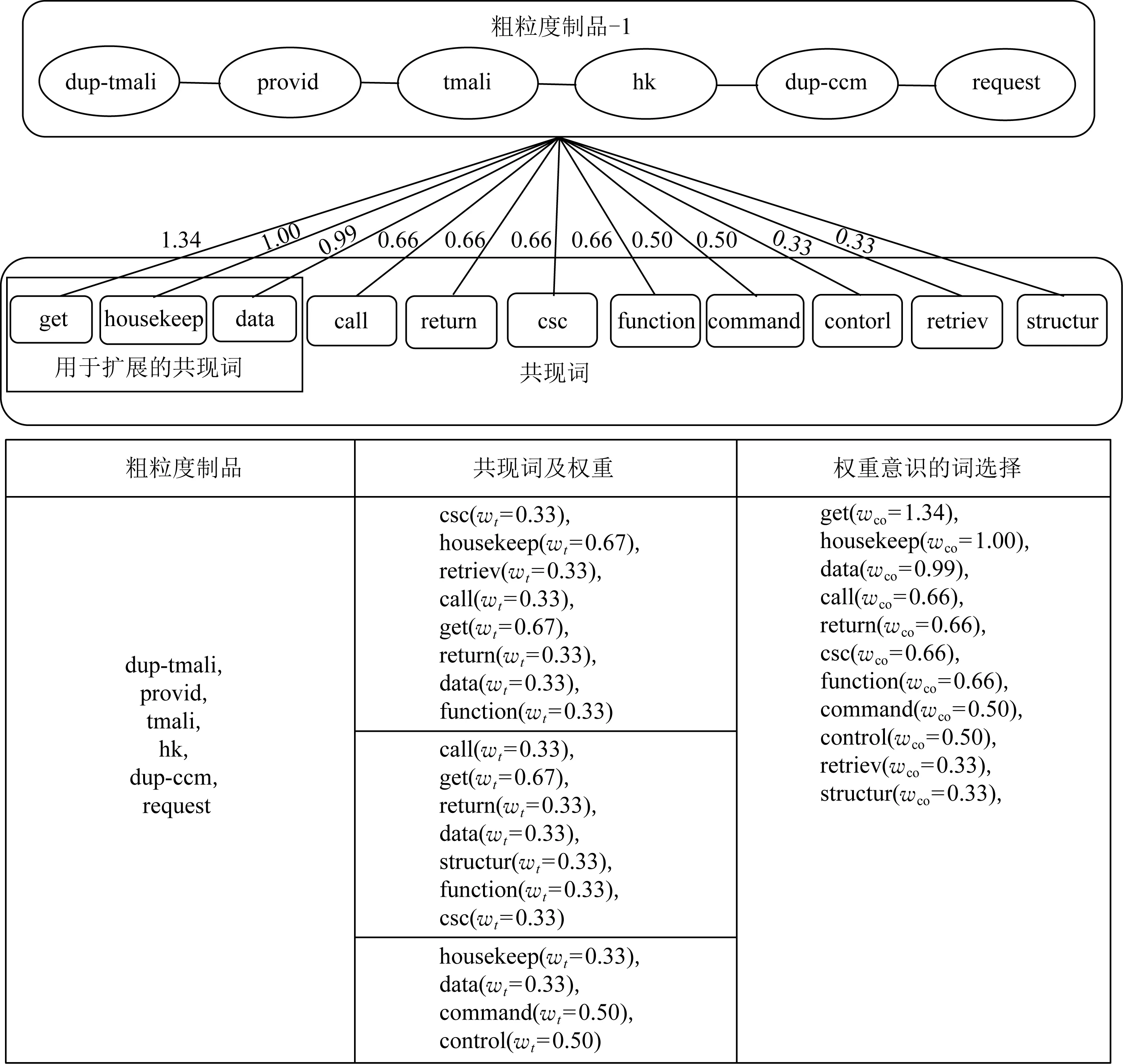
Fig. 6 An example of weight-aware terms selection图6 权重意识选择共现词的例子
在3.2节中,我们通过从项目级文本网络抽取词共现子图SGco,从中挖掘出所有粗粒度制品包含的词汇所对应的共现词,且对于每个共现词都有其对应的权重.
为了对粗粒度制品进行扩展,我们提出权重意识的方法选择共现词.其核心思路是基于2个词的距离越接近,共现频率越高,词与词之间的相关性越强的假设.将每一个粗粒度制品所有组成词看作一个语境,选择与该语境密切相关的共现词用于扩展.为了判定共现词与粗粒度制品的相关程度我们将该共现词的权重系数求和,计算得到该共现词与对应的粗粒度制品的最终权重:
(5)
其中,wt(s)是粗粒度制品中包含的术语的SGco中存在某一共现词s的Jaccard系数权重,t为粗粒度制品与某一共现词的共现边的数量,wco(s)为粗粒度制品与某一共现词s的最终权重.
高权重(即高共现频率)的词与粗粒度制品属于同一主题的概率也高,最后将高权重的词扩展到粗粒度制品中.设置扩展规模来限制扩展到粗粒度制品共现词的最大数量,最终选择权重值最大的前N个词来扩展粗粒度制品.对粗粒度制品的扩展规模N的取值将在4.4节进一步讨论.
此外,我们提出下面的规则来辅助权重意识的共现词选择方法:如果2个共现词的最终权重wco相等,则优先选择与粗粒度制品存在更多边的共现词s.
图6给出了权重意识选择共现词的例子.继续以图2中粗粒度制品-1为例,假设扩展规模N=3.对于“get”,权重是1.34(wco=0.67+0.67).粗粒度制品经过扩展之后,单词“get”“housekeep”和“data”被添加到粗粒度制品-1中,例如“dup-tmali,provid,tmali,hk,dup-ccm,request,get,housekeep,data”.以上扩展的词建立起了相似语境下术语的关联,从而缓解了粗粒度制品和细粒度制品之间的术语不匹配问题.
3.4.2 为每个软件制品扩展词序信息
在3.3节中,我们挖掘了保留词序信息的频繁子图,并将每个频繁子图与包含该频繁子图的软件制品相关联来解决软件制品词序语义缺失的问题.以图7为例,如图7(a)所示,当最小支持度设置为0.5时,在图7(a)中挖掘出3个频繁子图,每个频繁子图将被赋予唯一编码.因此,每个制品可以根据图5所示的制品图关联一组频繁子图,关联结果如图7(b)所示.相应的频繁子图编码将被视为扩展每个制品的新特征.

Fig. 7 An example of expanding artifacts by FSGs图7 一个通过频繁子图扩展制品的例子
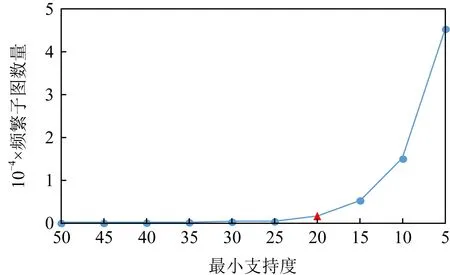
Fig. 8 An example of the minimum support threshold setting via Elbow method图8 通过Elbow方法设置最小支持度阈值的例子
在频繁子图挖掘过程中最小支持度不同,挖掘出的频繁子图数量也是不相同的.我们需要选择合适的最小支持度来确定频繁子图范围,并将与包含该频繁子图的制品相关联.我们根据Elbow方法[28]设置最小支持度过滤并保留用于扩展的频繁子图.图8所示CM1数据集中的Elbow方法.从图8可以看出,当最小支持度减小时,频繁子图数量略有增加,直至频繁子图数量显著增加时,该最小支持度为最小支持度阈值,在图8中是实心三角形突出显示.
3.5 学习增强的制品表示
我们利用Doc2vec来学习每个制品的增强表示.Doc2vec与Word2vec具有相同的分布假设,即可以通过上下文来推断句子的语义.因此,如果2个句子在2个段落中出现在相同的位置,它们在语义或句法上都是非常相关的.在我们的研究中,我们采用PV-DBOW方法,因为它取得了比PV-DM更好的效果.我们也比较了PV-DBOW和PV-DM的性能,并将在4.5.1节中进一步讨论.
在我们的模型中,制品向量被直接学习来预测上下文术语和频繁子图,因为它们的向量在制品之间是共享的.术语和频繁子图的语义向量在不同制品的上下文中捕获,而制品向量的学习是通过相似制品生成上下文术语和频繁子图,并同时捕获软件制品中术语和频繁子图之间的潜在关系.此外,制品向量被嵌入到与术语及频繁子图向量相同的语义空间中,因此,我们期望一个制品向量中包含多个潜在语义.
图9给出了利用PV-DBOW模型学习制品向量表示的过程,按照2.2节中相同的过程进行.我们提出将制品术语和频繁子图结合起来学习软件制品的语义向量.换句话说,我们将各制品术语与对应的频繁子图连接起来作为PV-DBOW模型的输入,直接学习制品的语义向量.当制品向量包含相似的术语和频繁子图时,2个制品的向量在语义空间中是相互接近.

Fig. 9 Learning artifact representations by PV-DBOW图9 通过PV-DBOW模型学习制品表示
3.6 恢复跟踪链接
为了恢复软件制品之间的跟踪链接,我们计算制品向量之间的余弦相似度,并采用比例阈值ε[31]来识别跟踪链接:
ε=c×simmax,
(6)
① http://www.coset.org
其中,c为比例阈值系数(0≤c≤1),simmax是所有制品对的最大余弦相似度.当制品对的相似度大于或等于ε,则建立它们之间的跟踪链接.由于每个数据集都有不同的特征,所以ε在不同的数据集中也是不同的.
4 实验和讨论
在本节中,为验证本文GeT2Trace方法的有效性,本文实验主要围绕3个研究问题展开:
研究问题1. GeT2Trace是否优于现有的需求跟踪关系恢复方法?
研究问题2. 共现词和词序信息是否提高了GeT2Trace的性能?
研究问题3. 参数设置是否影响GeT2Trace的性能?
4.1 数据集
本研究选择了5个实验数据集来验证我们的方法:CM1,GANTT,eTour,iTrust和EasyClinic.这5个数据集均来源于CoEST①公共数据集,并被广泛用于需求跟踪的研究.CM1是NASA项目中一个公共需求的子集,用于分析科学数据.GANTT用于创建项目管理甘特图,并执行管理项目的资源和进度.eTour是使用Java开发的为游客提供电子导航服务的系统.iTrust作为提供病人和医生之间的电子服务系统,它是用Java和JSP编写的.EasyClinic是一套自动化医院管理软件系统,也是用Java开发的.
实验数据集来自4个不同的应用程序领域,包括航空航天、软件工程、旅行娱乐和医疗保健领域,使得需求跟踪任务更加多样性,并且包含6种基本软件制品类型:高等级需求HL、低等级需求LL、用例UC、交互图ID、测试用例TC和代码类文件CC.实验数据集中制品间的跟踪类型涉及软件开发过程中典型的需求跟踪应用场景.实验数据集具体的详情见表3.
4.2 基 线
为了进行综合比较,我们选择了5个基线,主要分为基于信息检索的方法和基于机器学习的方法这2组.
1) 基于信息检索的方法
向量空间模型(VSM)[12]和潜语义索引(LSI)[11,13]:最为广泛用于解决需求跟踪问题的无监督学习方法.

Table 3 Detail of Experiment Datasets表3 实验数据集详情
2) 基于机器学习的方法
① WQI[24].该方法受到Ye等学者[32]研究的启发,采用预先训练好的软件工程领域的词向量和逆文档频率(IDF)权重的查询扩展,通过改进需求文档相似度算法提升需求跟踪的性能.
② S2Trace[26].这是最新的基于Doc2vec的方法,它利用PV-DBOW模型来学习文档向量.S2Trace是第1个提出了通过无监督学习方法嵌入序列模式(sequential patterns, SPs)来生成跟踪链接,并取得了最好的性能.S2Trace主要包括3个步骤:序列模式挖掘和文档向量学习,最后通过主成分分析(principal components analysis, PCA)优化文档向量.
此外,我们考虑使用Doc2vec的另一个变体,即PV-DM,因为它也考虑了在采样窗口中文本的词序信息.我们通过扩展共现词来增强PV-DM作为基线,并将这种基线方法命名为PV-DM-CoT.该方法首先从制品的项目级网络中提取共现词,然后将相应粗粒度制品与共现词连接起来,作为PV-DM模型的输入.
除VSM和PV-DM-CoT外,LSI,WQI和S2Trace这3种基线方法也在我们选择的5个公共数据集上进行了实验.因此,我们采用对应论文的实验结果来进行比较[24,26].
表4从3个方面展示了5个基线和我们的GeT2Trace方法之间的差异:语义、扩展和词序.1)语义.单词级和文档级的语义信息提供了对软件制品的深入理解,减少了语义差距.例如Word2vec和Doc2vec模型,它们克服了信息检索方法存在的不足.2)扩展.粗粒度制品作为短文本,不能提供足够的词共现信息来捕获已学习特性上的重叠,制品扩展技术弥补了不同粒度制品词汇差距,并有助于在粗粒度制品和细粒度制品之间进行映射.3)词序.词序信息包含重要的词级或短语级的序列语义,词序的变化可能会产生歧义,影响制品语义的准确表达.相比之下,只有我们的方法GeT2Trace和基线方法PV-DM-CoT同时考虑了影响软件制品之间语义表示的3个主要因素,我们期望从中得到更多的帮助来生成精确的需求跟踪链接,并将在4.5.1节和4.5.2节中进一步讨论.

Table 4 Comparison of Artifact Representation of
对应特征.
注意,我们在基线的选择中排除了深度学习模型,因为该方法需要大量的标记数据以训练一个有效的预测模型,否则会产生过拟合的问题.例如,Guo等学者[9]对769 366个标记制品对进行了调优跟踪网络的实验.在我们的研究中,实验数据集中的数据量不能满足深度学习模型的要求.
4.3 评价指标
为了评价GeT2Trace的性能,采用需求跟踪研究领域中最基本、最广泛的3个指标:精确率(precision)、召回率(recall)和F-measure对实验结果进行分析.我们对每个数据集重复实验过程10次,并报告平均精确率、召回率和F-measure.精确率和召回率分别计算为

(7)

(8)
F-measure是精确率和召回率的调和平均值:
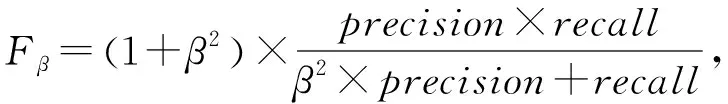
(9)
其中,当β=2时,自动跟踪方法强调召回率比精确率[10]更重要.因此,我们选择F2来比较方法的性能指标.
4.4 参数初始化
GeT2Trace方法是一种无监督学习方法,它有4个参数:用于构建文本网络(Gp和Ga)的滑动窗口的大小、用于扩展粗粒度制品的扩展规模、挖掘频繁子图的最小支持度阈值以及建立跟踪链接的比例阈值系数.
对于滑动窗口的大小,我们尝试设置不同的滑动窗口大小,通过实验分析当滑动窗口的大小设置为4时获得最佳或接近最佳的整体性能.这与文献[28]研究中对文本网络窗口建议大小一致.对于扩展粗粒度制品的扩展规模,我们尝试不同数量的前N个共现词,通过实验分析选择前20个共现词扩展粗粒度制品,获得最佳或接近最佳的整体性能.对于挖掘频繁子图的最小支持度阈值,通过Elbow启发式方法确定,具体方法请参见3.4.2节.对于比例阈值系数,尝试设置不同的系数大小,通过实验分析当系数设置为0.7时获得最佳或接近最佳的整体性能.为了进行公平的比较,我们设置与基线S2Trace一样的Doc2vec模型参数,向量维度为128,迭代次数为60.
我们使用基于Python的主题建模Gensim库来训练Doc2vec模型(2)https://radimrehurek.com/gensim/models/doc2vec.html,该库提供了Doc2vec模型的API来学习制品的文档向量.针对需要初始化的4个参数对GeT2Trace方法的潜在影响,我们也将在4.5.3节中进一步讨论参数敏感性.
4.5 实验结果和讨论
4.5.1 研究问题1:GeT2Trace是否优于现有的需求跟踪关系恢复方法?
为了验证GeT2Trace方法的有效性,我们将GeT2Trace方法与5个基线方法的实验结果进行比较,比较结果如表5所示.从表5中看出,GeT2Trace在大多数实验数据集上明显优于5个基线方法.
1) 与基线方法VSM和LSI比较
GeT2Trace在所有数据集上都优于信息检索模型VSM和LSI.GeT2Trace的精确率和召回率分别提高了18.78%,25.60%和14.81%,16.64%.
由于VSM和LSI只考虑了基于数学统计的术语共现信息,而忽略了由于软件制品词汇的稀疏性和不均衡性而导致的术语不匹配问题、语义及词序信息,导致只能捕获软件制品的部分语义.相比之下,我们的GeT2Trace可以通过神经网络将共现术语和频繁子图的语义联合建模,从而获取更准确和完整的制品语义.实验结果表明,GeT2Trace方法通过选择有效的特征和适用的模型学习到的软件制品语义表示为生成准确的跟踪链接提供了额外的帮助.
2) 与基线方法WQI比较
GeT2Trace在除EasyClinic(用例→测试用例)之外的所有数据集上的性能都优于WQI.在CM1,GANTT,eTour和iTrust这4个数据集上,相较WQI,GeT2Trace在F2上分别提高25.28%,6.98%,5.93%和17.10%.
WQI和GeT2Trace有2个共同的优点:1)WQI利用领域语料库训练词向量来获得词的语义,而GeT2Trace方法通过文档向量学习来建模词的语义.2)WQI使用基于软件工程领域的词向量和术语IDF共同筛选扩展词.GeT2Trace采用权重意识的共现词选择方法,从项目级文本网络中提取高权重的共现词.WQI和GeT2Trace的不同之处在于:WQI不捕获制品底层的词序语义,而GeT2Trace通过文本网络挖掘技术从频繁子图学习词序的序列语义.实验结果进一步证明了利用词序信息在需求跟踪中的必要性.

Table 5 Compare Results of Five Baselines表5 比较5个基线方法的结果
在EasyClinic(用例→测试用例)中,WQI可以获得比GeT2Trace更好的性能.通过手动分析之后,我们发现检索到的不正确的跟踪链接包含同义词,比如“book”和“reserve”“cancel”和“delete”,以及制品文本中词的分布对词序不敏感.WQI可以利用预先训练好的词向量模型对同义词进行识别,并通过IDF提取重要的词扩展制品.换句话说,WQI利用词向量更好地建模和区别软件制品的语义表示.
另外,WQI需要外部知识来学习词向量,例如软件工程的领域语料库.构建领域语料库首先需要花费大量精力和时间收集相关语料资源,如果在收集过程中使用其他领域的语料,则很容易造成学习到的词向量语义的偏差.相比之下,GeT2Trace所采用的Doc2vec对领域知识不是很敏感,只利用制品内部知识学习制品语义表示.
3) 与基线方法S2Trace比较
在精确率、召回率和F2方面,GeT2Trace方法显著优于S2Trace.
S2Trace和GeT2Trace都关注语义和词序对制品语义学习的影响.首先,它们采用相同的Doc2vec对词的语义建模,然后在训练过程中学习制品的文档级语义表示.其次,S2Trace通过序列模式挖掘技术学习序列语义,而GeT2Trace利用频繁子图挖掘方法来发现软件制品的序列语义.然而,S2Trace并没有考虑到相关术语在制品之间的不均衡分布问题,而GeT2Trace则通过建立项目级文本网络,再将粗粒度制品的共现词从对应的共现子图提取出来弥补这一短板,从而GeT2Trace可以捕获更完整的制品语义.实验结果进一步证明了扩展粗粒度制品在需求跟踪中解决术语不匹配问题的重要性.

Fig. 10 Evaluation of the benefit from Co-Terms and FSGs图10 共现词和频繁子图贡献评估
4) 与基线方法PV-DM-CoT比较
GeT2Trace在所有数据集上的性能都优于PV-DM-CoT.GeT2Trace的精确率和召回率分别提高20.14%和24.46%.
尽管GeT2Trace和PV-DM-CoT都考虑了影响需求跟踪领域中制品语义表示的3个因素(参见4.2节),但是基于PV-DBOW的GeT2Trace的性能要优于基于PV-DM的PV-DM-CoT.一种可能的解释是,我们将共现词和频繁子图结合到每个制品的特征中,由于它们是非线性特征的无序性扩展,PV-DBOW不仅通过预测其相关术语,还通过预测其频繁子图来学习每个制品在语义空间的向量表示.通过这样做,PV-DBOW比PV-DM利用了更多的有意义和区别的特征信息.而PV-DM所学习到的词序信息非常有限,不能充分利用扩展的共现词捕获制品间的语义关联.这表明GeT2Trace从频繁子图学习词序信息比PV-DM-CoT从制品中学习更加有效,并且充分利用了扩展的共现词带来的上下文关联信息.
总之,不同类型软件制品抽象层次及文本表达方式之间存在较大差异,为了恢复跟踪链接需要面对的问题有:1)不同软件制品之间术语不匹配的问题.这会导致与主题相关的软件制品在其文本内容中显示出很大程度的差异,从而无法建立跟踪关系.2)不同软件制品之间复杂的语义关系问题.这会导致一个粗粒度制品和一个细粒度制品,组成两者的术语部分或大部分完全相同,却表达不同的语义.为了缓解以上2个问题带来的挑战,GeT2Trace方法通过挖掘制品中隐藏的语义特征:1)挖掘同一语境中的共现词缓解不同软件制品之间术语不匹配的问题;2)挖掘软件制品之间频繁子图捕获不同软件制品之间复杂的语义关系问题,并将制品向量嵌入到与共现词及频繁子图向量相同的语义空间中,增强了软件制品准确语义的表示,获得了比所有基线方法更好的性能.
4.5.2 研究问题2:共现词和词序信息是否提高了GeT2Trace的性能?
为了回答这个问题,我们使用消融测试进行对比,通过忽略部分特征将3个子方法与GeT2Trace进行比较,然后评估需求跟踪的性能.1)GeT2Trace-NONE.该方法是指只从原始的制品中学习制品向量而不需要扩展任何特征的方法.2)GeT2Trace-CoT.表示从原始制品和共现词特征中学习制品向量的方法.3)GeT2Trace-FSG.表示从原始制品和频繁子图包含的词序特征中学习制品向量的方法.4)GeT2Trace.该方法从原始制品、共现词和词序特征中学习制品向量.对于每个子方法,设置相同的默认参数.
如图10所示,我们可以看到:1)GeT2Trace-CoT和GeT2Trace-FSG在所有数据集上都优于GeT2Trace-NONE.这意味着这2种特征扩展都是有效的.通过挖掘共现词的共现信息和频繁子图的词序信息,可以捕获更多的制品之间的潜在语义关系.在这个意义上,共现词和频繁子图可以帮助挖掘潜在的语义,进一步提高跟踪性能.2)以GeT2Trace作为融合特征模型,其性能明显好于分别从共现词和频繁子图中学习的特征.这意味着共现词和频繁子图是必不可少的.这是因为共现词和频繁子图为构建跟踪链接提供了额外的信息,这在4.5.1节中已经得到了证明.3)特别是在大多数情况下,GeT2Trace-FSG的性能优于GeT2Trace-CoT,这意味着包含词序信息的频繁子图对于软件制品语义的学习更为重要.
4.5.3 研究问题3:参数设置是否影响GeT2Trace的性能?
为了回答这个问题,我们分别研究了滑动窗口大小、扩展规模、最小支持度阈值和比例阈值系数这4个参数是如何影响GeT2Trace在实验数据集上的性能.当检查当前参数时,其他3个参数在实验中被设置为默认值(参见4.4节).图11~14为改变参数值时F2走势图.
1) 滑动窗口大小的影响

Fig. 11 Impact of sliding window size图11 滑动窗口大小的影响
图11显示用于构建文本网络的词图模型滑动窗口大小从2增加到10时F2的结果.我们看到滑动窗口大小对GeT2Trace的性能有影响:滑动窗口设置为4时GeT2Trace的性能到达或接近最佳;在滑动窗口大小为4之前GeT2Trace性能逐步提高,超过4之后GeT2Trace性能都有所降低或保持短暂平缓.因此,通过设置滑动窗口大小为4是可以有效地捕获中心术语的上下文信息,为后续基于文本网络的共现词和频繁子图的挖掘打下良好的基础.
2) 扩展规模的影响
图12显示粗粒度制品扩展规模从5增加到40时F2的变化曲线.我们可以看到,扩展规模对GeT2Trace的性能是有影响的,从F2走势图可以看出,扩展规模在20附近达到或接近最佳性能.此外,GeT2Trace性能在扩展规模到达20之前时逐步增加的,扩展规模超过20后下降或保持短暂平缓.因此,本文选择20作为扩展规模的阈值,进而通过对扩展规模的控制,限制共现词数量以减少噪声的影响.
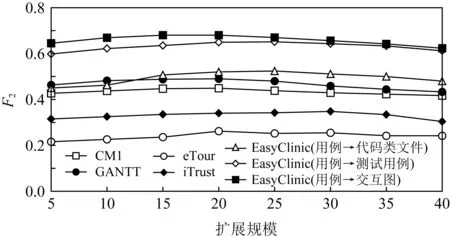
Fig. 12 Impact of expanding size图12 扩展规模的影响

Fig. 13 Impact of minimum support图13 最小支持度的影响
3) 最小支持度阈值的影响
图13显示最小支持度设置为5~50时F2的变化曲线,实心三角形表示每个数据集Elbow方法选取的最小支持度数值.我们可以观察到,每个数据集达到最好性能时的最小支持度是不同的,这导致手动设置的困难.而在采用Elbow方法选择的最小支持度时,GeT2Trace在大多数情况下都达到或接近最佳性能.因此,使用Elbow方法选择合适的最小支持度比手动设置最小支持度或通过经验设置为一个固定的值更加方便和高效.
4) 比例阈值系数的影响
图14显示比例阈值系数从0.1~0.9时F2的结果.我们看到比例阈值系数大小对GeT2Trace的性能有影响.比例阈值系数设置为0.7时,GeT2Trace在大多数情况下可以达到或接近最佳性能.因此,通过比例阈值法可以比较有效地自动确定构建跟踪链接的相似度阈值,但是在实际应用中还是应该在项目分析的基础上进行经验评估.因为不同特性的项目可能会造成比例阈值系数的漂移,从而影响恢复跟踪链接的性能.

Fig.14 Impact of scale threshold coefficient图14 比例阈值系数的影响
5 结 论
本文提出了基于图挖掘扩展学习的增强需求跟踪恢复方法GeT2Trace,该方法为解决制品所包含词汇信息的稀疏性和不平衡性造成的术语不匹配问题和忽视了自然语言中语法对于准确语义表达的影响,特别是词序信息缺失的问题.通过挖掘构建的制品文本网络中词共现和词序的语义特征,利用这些有意义和区别的语义特征学习更准确和完整的制品语义,以辅助生成准确的跟踪链接.为了验证我们提出方法的有效性,我们提出了3个研究问题,并在5个公共数据集上进行了评估.结果表明:GeT2Trace在精确率、召回率和F2上优于所有的对比基线VSM,LSI,WQI,S2Trace和PV-DM-CoT;从项目级和制品级文本网络中提取词共现信息和词序信息2个扩展特征是必要的和有效的;此外,我们还讨论了模型参数对GeT2Trace方法性能的影响,为参数的设置提供了一些实用的建议.
在未来的工作中,一方面,我们会收集更多的数据集来验证该方法的有效性;另一方面,我们将整合基于文本网络模型语义特征和词向量模型,旨在提高大型工业数据集的需求跟踪性能.
