基于改进EAST算法的地质图像文本检测
2021-04-09韩定良黄鸿亮王茂发盛炎平
韩定良,黄鸿亮,王茂发,盛炎平
(1.北京信息科技大学 理学院,北京100192;2.吉林大学珠海学院 公共基础与应用统计学院,珠海 519041;3.桂林电子科技大学 计算机与信息安全学院,桂林 541004)
0 引言
我国历史上形成的海量栅格地质图像包含了大量的地理、地质信息,对矿床发现、石油勘探、储量估计、地理坐标定位等有着重大意义。栅格地质图中的信息呈现形式以文本字符为主,所以图像中的文本识别、定位研究就显得尤为重要。传统的通过人工识别特征和手动录入数据信息的地质图像检索方式工作量大、重复性高,已经无法满足需要。随着深度学习技术的不断发展,通过计算机自动识别和处理图像文本信息可以大大提升工作效率。文本检测算法主要通过计算机自动框定出文本在地质图像中的范围[1-2],作为后续文本识别过程的先行条件,在地质图像的检索和信息提取中起着举足轻重的作用。
从特定的场景中检测文本来进行场景理解是计算机视觉研究的一个重要分支。目前基于深度学习的文本检测算法主要分为两类,一类是基于预选框的文本检测算法,另一类是使用全卷积网络直接预测目标。文献[3]提出一种快速而准确的直接预测目标的检测算法,它通过直接预测完整图像中任意方向和四边形形状的单词或文本行,消除使用单个神经网络的不必要的中间步骤,在各种公开的数据集中取得了良好的效果。然而,在处理包含有大量复杂文本的地质图像时,受图像中阴影背景以及各种化学符号的干扰,EAST算法整体性能受限,通常也只能检测到部分有效文本。
为解决这一问题,本文基于文献[3]提出一种改进EAST(an efficient and accurate scene text detector)算法的地质图像文本检测方法,通过减少易提取样本的权重策略改进损失函数,运用多尺度[4]的方法进行背景和文本的分割,然后按不同比例尺切割图像训练样本,使得算法在地质图像上的检测准确率更高。
1 改进EAST算法设计
传统的文本检测方法[2]和一些基于深度神经网络的文本定位方法由若干组件构成,包含多个步骤且在训练时需要对其分别进行调优,耗费时间较多。这些方法的准确率和效率不能满足地质图像文本检测的需求。因此本文选取EAST这种快速而准确的场景文本检测方法作为基础检测算法。该算法的优势在于消除传统算法中间冗余而又慢速的步骤,只包含两个主要流程:一是使用全卷积网络[5](fully convolutional networks,FCN)模型直接生成单词或文本行级别预测;二是将生成的文本预测(可以是旋转的矩形或四边形)输入到非极大值抑制NMS[6](non-maximum suppression)中以产生最终结果。本文对EAST算法进行改进,以提升检测效果。
改进后的EAST算法主要包含5个部分:算法神经网络结构、基于focal-loss[7]优化的损失函数、倾斜的局部感知非极大值抑制网络(NMS)、基于可变尺度的图像分割优化、按比例尺切割训练样本。
1.1 算法神经网络结构
改进后的神经网络结构如图1所示。由3部分组成:特征提取分支、特征合并分支和输出层。
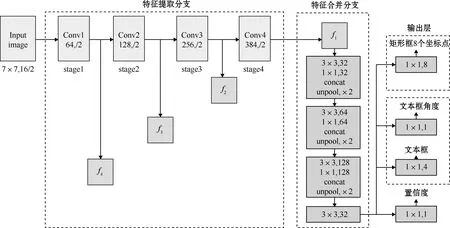
图1 EAST算法网络结构
特征提取分支是从ImageNet数据集上预训练的卷积网络中选取4组卷积层Conv1、Conv2、Conv3、Conv4。分别从中提取4个级别的特征图,表示为f1、f2、f3、f4。其图像大小分别为输入图像的1/32、1/16、1/8、1/4。
在特征合并分支,原算法在每个合并阶段,将来自最后一个阶段的特征图输入到反池化层(unpool)中以使其大小加倍,然后与当前特征图合并,这一步操作会产生一部分计算代价。为提升算法效率,本文直接通过Conv1×1的卷积层减少通道的数量并且减少计算量,接着是一个Conv3×3的卷积层,它融合了局部信息产生这个合并阶段的输出。在最后一个合并阶段之后,使用Conv3×3卷积核合并所有的特征图并将其输入到输出层。
输出层分为3个部分:置信度、文本区域和文本区域旋转角度、包含8个坐标的矩形文本区域。最终的输出结果是1×1的卷积提取特征。
1.2 优化损失函数
EAST算法的损失函数为
L=Ls+λgLg
(1)
式中:Ls为图像背景和图像文本的置信度的分类损失,文本区域所在的部分为1,非文本区域的背景部分为0;像素点的分类损失Lg为对应文本区域的像素点所组成的矩形框和矩形框角度的回归损失;λg为两个损失之间的相关性,在原EAST算法中将λg设置为1。
为了简化训练过程,分类损失使用平衡的交叉熵[9],图像背景和图像文本的分类损失:
(2)

(3)
由于是二分类,所以y的值是正1或负1,p的范围为0~1。当真实标签是1,也就是y=1时,假如某个样本x预测为1这个类的概率p=0.5,则损失为-log2(0.5),需注意这个损失是大于等于0的。如果p=0.8,则损失就是-log2(0.8),所以p=0.5时的损失要大于p=0.8时的损失。
为了加快收敛速度,本文引入focal-loss[8]损失函数作为分类损失函数,用来表示图像分割预测值和真实值的相似度。γ为focusing parameter[9],pt表示预测类别的概率,改进后的图像背景和图像文本的分类损失Ls为
Ls=-(1-pt)γlog2(pt)
(4)
focal-loss函数的收敛速度更快,效果优于交叉熵损失函数的效果。其本质是不断学习,使文本检测区域的交并比越来越大。
图2为使用交叉熵损失函数和focal-loss损失函数在训练过程中的损失值曲线。当γ=0时,曲线为交叉熵损失函数的收敛过程,速度较慢。当γ>0时,曲线为focal-loss损失函数的收敛过程,从图中可以看出随着参数γ的增大,网络的收敛速度加快。

图2 focal-loss与交叉熵损失函数对比
Lg为文本框矩形的几何损失,是AABB损失和旋转角度损失Lθ的加权和:
Lg=LAABB+λθLθ
(5)
式中:LAABB为从像素位置到文本矩形的上下左右4个边界距离的损失:
(6)
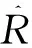
Lθ为旋转角度损失:
(7)

地质图像中文字尺度变化较大,且尺度不同的文本目标在回归损失中的权重不同,导致网络在文本检测中出现漏检的问题。Lg为公式(1)中的文本区域回归损失,本文利用动态调整权重的策略对Lg进行改进,使Lg中的权重对不同比例尺的地质图像中各个尺度的文字保持一致。对于一张比例尺为1∶N的地质图像,同一批次训练样本中的文本区域都包含相同的权重wi:
(8)
式中:S为图像中总像素的个数;Si为文本区域中实际的文字像素的个数。图像中的像素点i应该满足公式(8)。当图像样本中Si的数量增加时,损失的权值会受到抑制;当图像样本中Si的数量减少时,尺度较小的文本区域权值会变大,尺度较大的文本区域权值会相应变小,权重会相对一致,有利于文本目标的检测。改进后的回归损失为
(9)
将面积大于或小于某个阈值的文本框设置为困难样本,式中yhard即困难样本的数量。这些样本训练起来较为困难,所以减少这些样本的权重可使文本检测定位效果有明显提升。
1.3 局部感知非极大值抑制网络
非极大值抑制简称NMS,简单理解就是局部最大搜索,在目标识别、数据挖掘、目标跟踪等计算机领域有重要作用。在目标检测中,经过分类器识别后,会产生多个预测框,每个预测框都会有一个分数,但是绝大多数预测框会出现交叉或包含的情形,所以就需要通过NMS来获得邻域里得分最高的预测框,同时抑制分数低的预测框,得到最终结果。
标准NMS是直接取分数最高的预测框,而局部感知NMS则是基于邻近几个多边形是高度相关的假设,在标准NMS的基础上增加权重覆盖,就是将2个IoU(intersection over union,交并比即重叠区域面积比例)高于某个阈值的输出框,进行基于得分的合并。合并后的输出框的坐标数值介于两个合并的输入框之间,这样可以将所有回归出的框的坐标信息都利用起来,有助于减少位置误差。
由于两个矩形文本框重叠的部分可以是任意多边形,计算重叠区域面积的难度较大。所以局部感知NMS一般采取简化的计算方式,将相交部分近似为一个矩形,每计算一次相当于计算矩形的顶点和坐标轴组成的梯形的面积。图3中有色区域的面积为
S=(S1+S3)-(S2+S4)
(10)
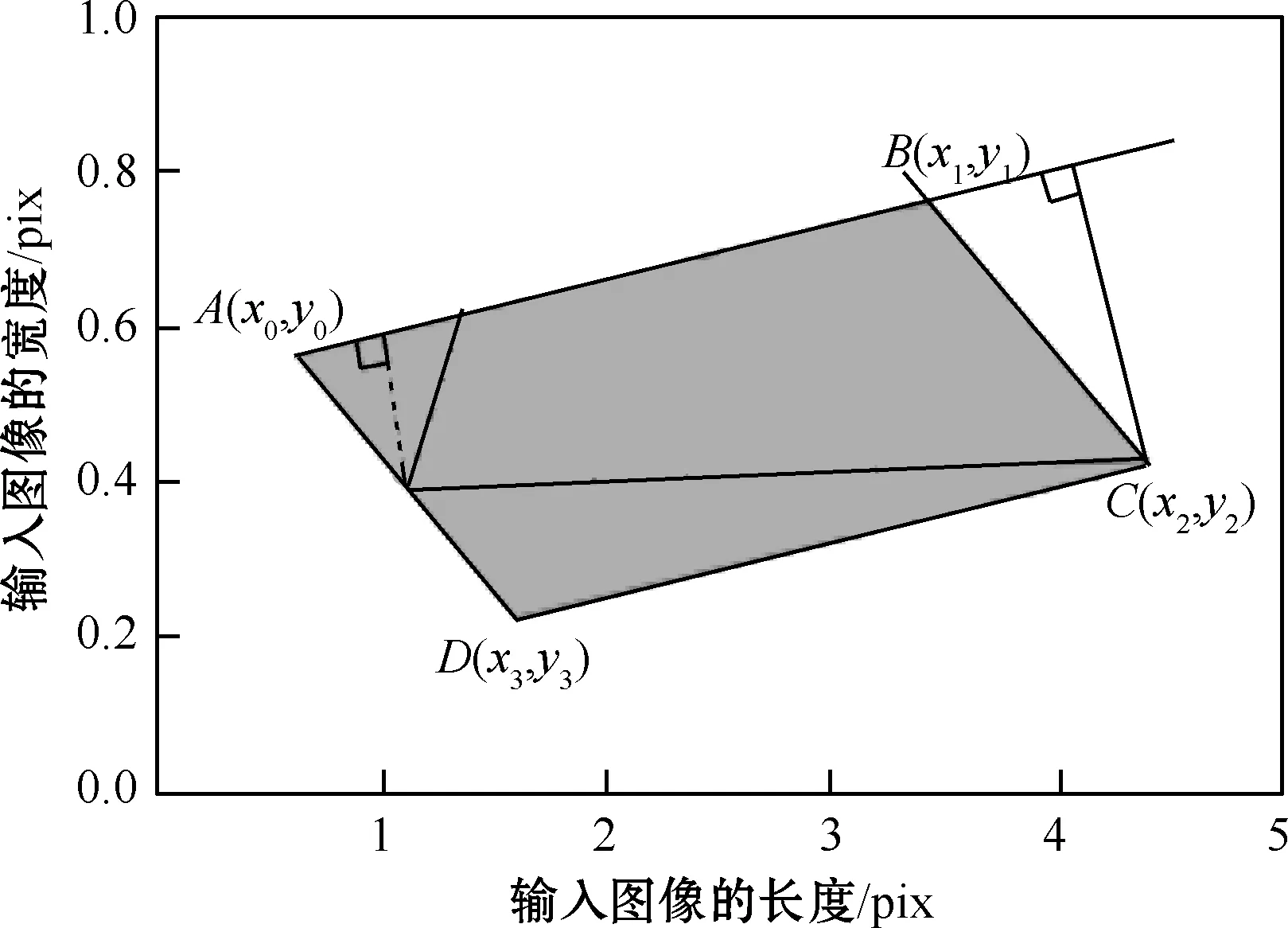
图3 重叠区域面积计算过程
式中:S1为顶点A、D和横坐标轴组成的梯形的面积:
S1=((x3-x0)(y3+y0))/2
(11)
S2为顶点A、B和横坐标轴组成的梯形的面积:
S2=((x1-x0)(y1+y0))/2
(12)
S3为顶点B、C和横坐标轴组成的梯形的面积:
S3=((x2-x1)(y2+y1))/2
(13)
S4为顶点C、D和横坐标轴组成的梯形的面积:
S4=((x2-x3)(y3+y2))/2
(14)
本文使用的地质图像数据集中包含有大量的倾斜文本(文本与水平形成夹角),所以本文在局部感知NMS的基础上增加了倾斜的NMS来处理这些倾斜文本,其基本步骤如下:
1) 对网络输出的旋转矩形文本检测框按照得分进行降序排列,并存储到一个降序列表里。
2) 依次遍历上述的降序列表,将当前的文本框和剩余的其他文本框进行交集计算得到相应的相交点集合。
3) 判断相交点集合组成的凸多边形的面积,计算每两个文本检测框的IoU;对于大于阈值的文本框进行过滤,保留小于阈值的文本框。
4) 得到最终的文本矩形检测框。
1.4 基于可变尺度的图像分割优化
地质图像具有范围广、文本尺度多样的特点。对于其中文本目标的检测,由于背景十分复杂,文本目标和背景交叉覆盖,文本特征难以提取,检测较为困难。在进行图像分割时,必须要考虑这些因素。文献[10]中提出两种利用特征的方式进行图像分割:一是将图像转化为不同尺度,在各个尺度的图像上提取特征,在不同的特征上分别进行预测,该方法增加了时间复杂度;第二种方式是从不同的网络层中提取特征:提取图像最后一层的特征进行预测,如SPP-Net[11],Faster R-CNN[12]等;或从多个网络层提取不同尺度特征图做预测,如SSD算法[13]。
提取地质图像的文本区域,首先要对图像背景和图像文字的像素点做一个分类,实际上就是一个图像分割的过程。训练时,文字区域所在部分表示为1,非文字的背景部分表示为0,这样就能得到分类任务的groundTruth[14](即有效的正确数据)。
但对于图4(a)中的情况,当文本和背景的颜色无法区分开时,相对于图4(b),文本区域的检测并不准确。为了对边界像素点更好地分类,本文改进方法对图4(a)中原有的检测框做了一点收缩,如图中黄色虚线框收缩为绿色实线框,这样边界像素点可以分类得更准确。
图4 文本和图像背景
在文本检测过程中地质图像的标准框中会存在一些非目标信息,通过对边界像素点的缩进可以减少这些信息对目标区域的影响,提高网络检测的准确性[15],如式(15)所示。每个顶点向内收缩的参考长度为
(15)
式中:pi为矩形的4个顶点;D(pi,pj)为两个顶点之间的相对长度。首先缩短四边形的两条较长边,然后缩短两条较短的边。对于四边形的每条边D(pi,pimod4+1),通过将两个顶点沿着边缘分别向内移动Nri和Nri(imod4)+1的长度。这里的N是一个超参数,针对不同比例尺的图像将N(0.0~1.0)设置为不同的值,可以优化检测结果。
1.5 按比例尺切割训练样本
地质图像中地质文本受到比例尺的影响,不同尺度图像上的地质文本尺度差异较大。在训练过程中,未改进的EAST算法使用固定尺寸的图像进行训练[16],因此对于不同比例尺的地质文字图像,对文本区域的漏检情况比较多。本文采取多尺度的训练方法,对于一张比例尺为1∶N、大小为M×M的地质图像,在训练阶段为每张图像设置的尺度为X×X×X,其中X=[M/N]。然后每张图像选择对应比例尺的尺度组成多尺度图像训练集。实验证明多尺度训练能够提高算法对不同比例尺的地质图像文本检测的泛化能力。
2 实验环境及预处理
2.1 实验环境
本实验在Win10系统下进行,使用的显卡为NVIDIA GTX1060Ti,内存为16 G。基于深度学习框架Tensorflow和Keras,使用Python编程实现算法模型。
2.2 数据集
本文所要检测的地质图像数据来自中国国家地质调查局,语言为中文。为了提高算法对地质文本检测的泛化能力,使用阿里巴巴“图像和美”团队联合华南理工大学共同举办ICPR MTWI 2018 挑战赛公开的基于网络图片的中英文数据集进行预训练。该数据集数据量充分,涵盖数十种字体,几个到几百像素字号,多种版式,较多干扰背景[17]。其图像背景复杂性和地质图像较为类似。另外本实验采用了地质调查局的135张大型地质图像,按比例尺分割为4 000多个训练样本构成文本检测训练集。并且根据模型训练需要,使用红色文本框对地质图像区域中的中文编码进行标注,其中每张图像对应一个text标签文件,包含了所标注的文本区域的8个坐标点。如图5所示。

图5 标注图像数据
2.3 模型训练
为了获得比较好的文本检测泛化能力,实验先在ICPR MTWI 2018挑战赛的中英文数据集上进行训练,获得预训练权重。为了加快训练速度,使用随机梯度下降法SGD[18](stochastic gradient descent)进行训练优化。批训练数量(batch-size)为32,默认的动量(pixel_threshold)为0.9,权重衰减系数为0.000 5,初始学习速度为0.01,每50 000次迭代以后学习速度减少为原来的0.1,学习速度到0.000 000 1后不再减少。
3 实验结果与分析
为了评估改进前后的算法对地质图像文本检测的准确性,实验使用准确率P(precision),召回率R(recall)、漏检率(1-recall)、得分值(F1)评价算法对文本检测的准确性。
(16)
式中:tp、fp、fn分别为正确预测的文本区域的数量、错误预测的文本区域的数量和漏检的文本区域数量。检出率等于召回率,用F1值来评估算法的准确率。
3.1 算法改进前后检测效果对比
使用3 000张按比例尺分割后的地质图像对EAST算法和结合损失函数优化图像分割优化、按比例尺切割训练样本的改进EAST算法进行训练,然后将训练好的模型在剩余的1 000张地质图像测试集(包含4 186个标注的文本区域)上进行测试。改进前后的算法效果对比如表1所示。
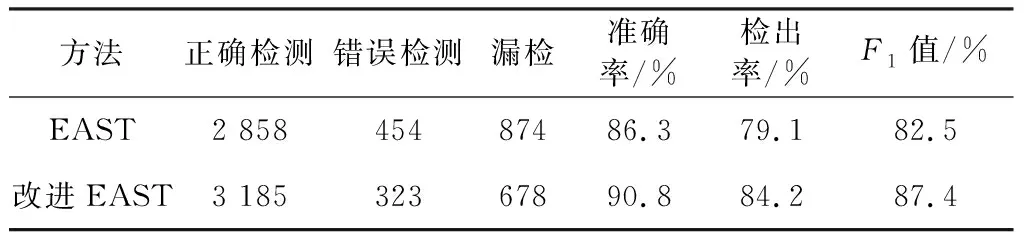
表1 两种算法检测效果对比
从表1可以看出,改进EAST算法在检测准确率上提高了4.5%,准确检测到文本框的概率提高了5.1%,F1值提高了4.9%。
图6(a)为EAST算法效果图,图6(b)为改进EAST算法的检测效果图。可以看出改进的EAST算法能够准确检测出较多的地质图像文本区域,而EAST算法漏检的文本区域较多,改进的EAST算法检测效果优于原EAST算法。
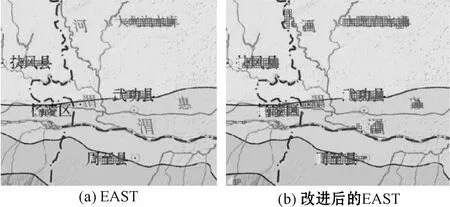
图6 实际检测效果对比
3.2 不同优化方法文本检测效果对比
表2列出了使用不同优化方式对准确率的影响,表中用T表示采用了该优化方法,用F表示没有采用该优化方法。由于优化了图像分割方式,方法2比方法1的漏检率降低了4.1%。由于按比例尺切割训练样本增加了网络对不同尺度图像的适应性,方法3比方法1的漏检率降低了1.4%。方法5和方法1对比发现,使用focal-loss损失函数替代交叉熵损失函数,优化损失函数后的方法漏检率降低了5.1%。由表可知,实验中3种优化方法均能降低漏检率,提高文本检测准确率。
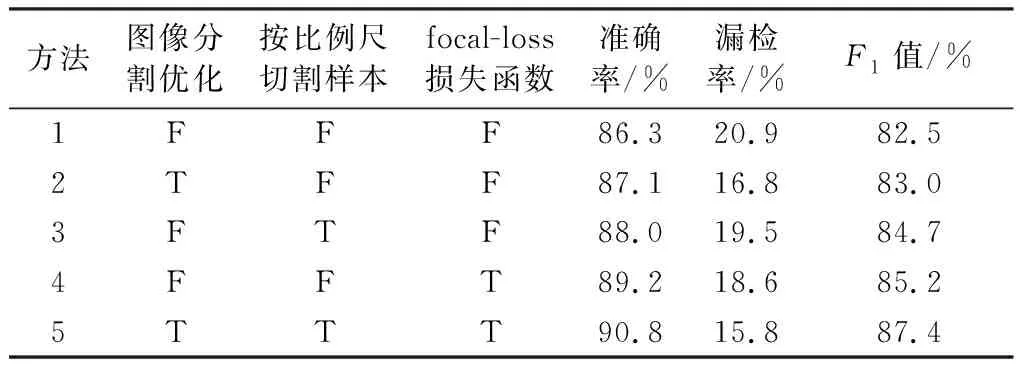
表2 不同优化方法效果对比
3.3 多种地质图像检测效果
本文作者测试了多种地质图像下改进EAST算法的文本检测效果,如图7所示。红色检测框标定了文本的出现位置。
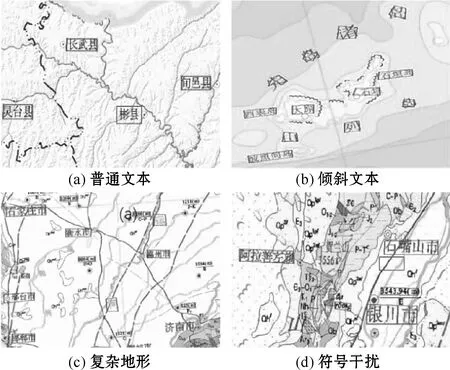
图7 多场景检测效果对比
检测结果表明,对于不同的地质图像,文本检测算法的泛化性较好。
4 结束语
地质图像文本检测、识别对于矿床发现、石油勘探、地理坐标定位具有重大意义。针对大比例尺地质图像文本检测准确率不够高的问题,本文提出一种基于改进EAST算法的地质图像文本检测方法,运用focal-loss函数改进模型损失函数,采用难、易检测文本目标权重动态调整策略来改进文本目标漏检的问题。同时采用多尺度对象分割算法进行图像背景和图像文本的分割,并结合比例尺方法切割训练样本。实验验证了本文提出的算法具有检测准确率较高、对不同的地质图像的适应力较强等优点。
改进后的EAST算法对于大比例尺、文本尺度多样的地质图像中的文本检测更加准确。但仍然存在一些问题,如化学符号、地质符号特别密集的区域检测准确率较低。需继续优化网络结构,进一步提升检测算法的准确性和适应性。
致谢
本文相关实验得到了中国地质调查局发展中心的数据支持,特别感谢中心李景朝、王成锡、郑啸老师在模型构建、评估标准上的业务指导和大力支持!
