基于深度信念网络的文本分类研究综述
2021-04-07石媛媛裴志利姜明洋
石媛媛,裴志利,姜明洋,3
(1.内蒙古民族大学数理学院,内蒙古通辽028043;2.内蒙古民族大学计算机科学与技术学院,内蒙古通辽028043;3.吉林大学计算机科学与技术学院,吉林长春130012)
在互联网信息时代的高速发展下,信息数据陡然增长,而信息的承载途径最主要的就是文本,于是文本分类成为近些年的研究热点.文本分类(text categorization,TC)技术的任务是预先给定文本集的类标,根据文本的内容自动确定该文本所属类别的过程.文本分类主要用于信息检索、文本审核、情感分析和广告过滤等领域.传统的机器分类模型有朴素贝叶斯算法(Naive Bayesian Classifier,NBC)[1]、支持向量机算法(Support Vector Machine,SVM)[2]、决策树算法(Decision Tree,DT)[3]、BP 神经网络算法(Back Propagation,BP)[4]、K-最近邻算法(K-Nearest Neighbor,KNN)[5]等,这些模型容易出现维数灾难和局部最优,而且有些聚类算法并不完全适合实际情况中的深度问题[6],在实际复杂的分类需求下建模能力仍很有限.针对上述问题,Hinton 在2006 年提出深度学习(Deep Learning)[7],其包含的深度信念网络(Deep Belief Network,DBN)[8]具备突出的特征学习优势,且可以通过“逐层初始化”克服训练难度,使训练时间大大缩短,从而实现高效分类.深度信念网络已于手写体识别、图像识别以及语音识别等领域被广泛使用.目前,乔俊飞等[9]提出一种基于自适应学习率的DBN 算法,缩短了训练时间,且明显优于固定学习率对网络的影响;徐毅等[10]将惩罚正则项引入到DBN 中,通过控制隐层节点不同的稀疏水平,使整个网络有更好的稀疏性能,提高分类的准确率;李兰英等[11]将DBN 和CNN 相结合,提出一种应用于脱机手写汉字识别的算法,大大提高了传统DBN 算法的识别效果.本文将简述深度信念网络以及几种基于深度信念网络的文本分类模型.
1 深度学习
深度学习是深层的机器学习方法,算法自身会挖掘出蕴藏在数据中复杂隐喻的特征,从而实现高准确度分类.深度学习依赖于无监督特征学习和大量训练数据,利用构建多隐层模型的方式,逐步学习到更有价值的特征.而DBN算法作为深度学习的方法之一,通过贪婪逐层训练的方式,避免针对多隐层训练时梯度下降算法效果不佳,有效地优化深度学习的问题.
2 深度信念网络文本分类模型
2.1 深度信念网络结构
DBN是一种概率生成模型,各层网络之间的权重与偏置是在网络运行的过程中不断被训练的,根据最大概率让网络拟合训练样本[12].DBN 的网络结构相对简单,其基础是受限玻尔兹曼机(Restricted boltzmann machine,RBM)[13],由若干个串联堆叠的受限玻尔兹曼机RBM和一个反向传播BP网络构成,其结构如图1所示.

图1 深度信念网络结构Fig.1 Deep belief network structure
DBN的网络学习过程分为两个阶段,首先对RBM进行无监督自底向上的逐层预训练,再利用有监督的BP网络对整个网络进行调优.
2.1.1 受限玻尔兹曼机 受限玻尔兹曼机(Restricted boltzmann machine,RBM)[14]是由一个可视层v和一个隐含层h组成的随机神经网络,这两层神经元之间的连接特点是层内无连接,层间全连接.其结构为图2.

图2 受限玻尔兹曼机结构Fig.2 Restricted Boltzmann machine(RBM)structure
RBM是一种能量函数,对于给定的状态(v,h),定义能量函数为
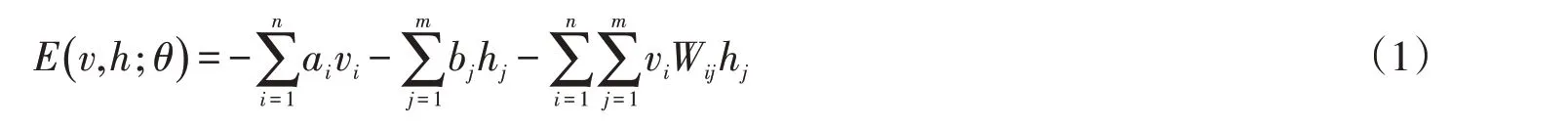
其中,θ=(Wij,ai,bj)表示RBM的参数.
根据能量函数,给出状态(v,h)的联合概率分布

根据RBM的结构特点可知,在给定可见层(隐含层)节点状态的情况下,隐含层(可见层)节点的激活概率是条件独立的.由贝叶斯公式可推导可见层节点和隐含层节点的激活状态:

其中σ(x)为sigmoid激活函数.
RBM在训练过程中最重要的任务就是不断调整参数θ,使网络的概率分布最大程度地拟合样本.根据最大似然学习法,通过最大化对数似然函数求得参数θ.

而求解Z(θ)的运算难度较大,于是为了能快速训练RBM,Hinton提出对比散度算法(Contrastive Divergence,CD)[15],其中只需执行k=1步的Gibbs采样,即可得到更新的各项权值.
2.1.2 BP神经网络 DBN完成预训练的同时也完成了初始化整个网络的参数,此时BP网络的输入就是最后一层RBM的输出,算法将利用预训练得到的输出与标签之间的误差,微调网络的权值与偏置,使误差达到最小,分类效果最佳[16].更新后的DBN各层权值为

其中,为第l个隐层第i个节点的输出值,η为学习率.
2.2 深度信念网络文本分类模型
根据DBN和文本分类流程,给出DBN的文本分类模型如图3所示.主要经过三个阶段,首先,进行文本预处理;其次,进行特征选择与特征提取;最后,将文本输入到DBN文本分类模型中分类.

图3 深度信念网络文本分类模型Fig.3 Deep belief network text classification model
3 基于深度信念网络的两种文本分类问题
3.1 稀疏深度信念网络分类问题
由于DBN网络的相对复杂性,一旦出现特征同质化的问题,网络将影响分类的效果.为了防止过拟合和分布中的不变形问题的发生,在网络中加入稀疏项进行约束是非常有效的办法之一.
文献[17]采用的是无均值高斯函数的稀疏正则项,利用无均值高斯函数趋于l0范数所达到的稀疏效果,表达式为:

其中,σ为方差因子,用来调整与l0范数的近似度.实验中,在分类效果上G-DBN分别于NS-DBN与SP-DBN作对比,G-DBN网络在实验过程中有稳定且更高的稀疏性.
文献[10]则在RBM的训练过程中引入拉普拉斯函数稀疏正则项,利用位置参数来调整稀疏力度,调节隐藏单元的稀疏性.给定一个训练集,稀疏优化模型如下:


于是网络的目标函数为:

拉普拉斯分布是与正态分布相类似的连续分布,但比正态分布的尾部更加平坦,通过改变位置参数来产生不同的分布曲线,从而控制隐藏节点的稀疏性.在与相同条件下的自动编码器、ANN 算法进行比较:文中提出的基于稀疏性的DBN 分类模型有更好的挖掘文本中隐藏的深层特征能力,有稳定的鲁棒性,分类准确性也有所提高.
DBN网络引入适当的稀疏项虽然有比无稀疏正则的DBN网络更具优势,且能够对网络进行有利压缩,但过当的稀疏性也会给网络造成影响,如降低网络的稳定性,使模型的泛化能力下降.引入稀疏项后依然能保证网络的稳定性和解决有效信息的丢失等问题仍旧是学者们需要研究的.
稀疏DBN作为一种预训练技术,可对权值进行快速初始化以及对特征向量进行快速获取.文献[18]提出了一种新的非监督学习算法——基于模糊神经网络的稀疏深度置信网络(SDBFNN),网络将SDBN的预训练技术和FNN的高效监督学习进行了结合.文献中加入两个稀疏项R1和R2,来惩罚隐层神经元的平均激活概率,对数似然函数进行更新如下:

其中,

FNN中的BP算法不是连续且逐层进行的,这样可以消除DBN微调中BP算法造成的梯度扩散问题,从而实现高效的监督学习和建模.实验结果发现,SDBFNN算法比DBN算法有更高的精度,在使用稀疏表示的情况下,准确率并不总是和训练时间成反比,它强调了利用稀疏表示进行快速有效的训练,避免了复杂的密集表示,达到了较高的精度.
虽然,SDBFNN在一些工程应用中有着很好的应用前景,但是它的性能还有进一步提高的空间.
3.2 深度信念网络结合其他网络进行文本分类问题
为了提高分类问题的准确率,多数学者的研究不仅仅只限于单独使用DBN网络,而是将其他网络与DBN网络进行融合,将不同网络的优势结合起来,改掉各自的缺点,从而更加高效地解决实际问题.
文献[19]将DBN 和DBM 结合起来,提出混合深度信念网络(HDBN).实验在网络的底层设置两层DBM,进行降维的同时尽可能多地保留数据的原始信息;根据DBN网络的特点,可以在原始的浅层特征中学习到更加复杂且具体可分的深层文本特征,于是结合了DBN,同时进行又一次的降维.
由于RBM是能量函数,而求能量函数的过程就是最小化能量值的过程,文献[17]提出自由能量函数:

于是似然函数的表达式为:

HDBN 网络与DBN 网络的结构有相似之处,DBN 在网络的训练初期易于出现过拟合的现象,所以HDBN先利用DBM给原始数据进行特征提取,也进行降维、降噪;然而DBN却可以在高层的网络结构保持稳定的性能,再利用DBN 进行微调,进行高精度的分类.实验证明HDBN 网络的分类效果优于DBN 网络,HDBN网络中的低维表示比DBN网络中的更详细,对于网络参数的调整更具轻松性.
文献[20]则对DBN初始值进行优化,将改进的和声搜索(IHS)融合在DBN中,提出一种IHS-DBN模型.HS算法是现代较新颖的优化算法,通过不断调整解向量,进行迭代与收敛直至找到函数最优解.它的优点在于:网络思路易懂、网络的参数相对较少、实现对最优解的搜索等,于是将HS算法结合到DBN中,利用自身的优势,使得更加高效地优化整个网络的参数以及加快对分类的收敛过程.
IHS算法选定DBN算法中的重构误差函数作为优化目标函数,在网络训练中,IHS算法会尽可能增加解向量的最优性,得到DBN网络的最优初始值.IHS-DBN算法中优化目标函数公式为:

其中,为显示层节点的真实值,为RBM 的重构值.通过IHS 算法不断迭代,最终得到全局最优解,并由此初始化DBN 网络中的第一个RBM 的各项参数与权值,最后利用梯度下降法对整个网络进行调优.
实验结果表明,IHS-DBN算法的分类精度高于传统的DBN网络.DBN网络通过设定较小的随机值确定网络初始值,并不适合的网络参数可能会致使出现局部最优的情况,通过IHS算法对此的优化,不仅避免了传统DBN初始值的问题,还能缩短整个网络训练时间,加快得到全局最优解和收敛速度.
文献[21]为了使DBN模型的输入更加低维且有效,将变分自编码(VAE)与DBN相结合,提出VAEDBN模型.由于VAE的结构,被看做是特征提取的模型,在实验中完成对数据的重构,通过重构误差结束初始特征学习,无监督的特征提取来得到低维优良的特征,将其输入到DBN 网络中再次分类亦更适合DBN网络的工作机制,可大大降低错误分类的情况发生.VAE-DBN算法的目标函数为:

VAE 的学习目的就是使输出数据在误差尽可能小的情况下与输入数据表示相同,由于算法增加了噪音,使输出数据与输入数据在保持相同分布的情况下产生了多样性.实验证明,经过VAE处理后,数据增强了稳定性,DBN有较强的数据挖掘能力进行数据的二次处理,改进后的目标函数也提高了得出全局最优分类结果的概率,比单独使用DBN网络有更好的分类结果.
文献[18]将模糊学习框架与DBN网络的预训练阶段相结合,在最后一个隐层中保留训练得到的有效特征向量,最后利用误差函数进行调优.传统DBN网络的监督阶段效果有限,于是选择FNN算法来代替逐层BP算法.这种结合方式的优越处在于DBN的预训练技术可以得到一个更有效的数据表示,将其作为模糊神经网络的输入,稀疏表示可以增强SDBN对外界波动的容忍度,提高其鲁棒性.
4 深度信念网络在情感分类问题中处理复杂特征的优势
文本情感的分类工作具有非常高的实际意义,DBN对于此类任务也有良好的结果.同时,选择不同的特征也影响着分类结果.
文献[22]中在对文本进行预处理之后,选取一、二元词,依存关系等特征输入到DBN网络中,实验结果证明,当输入特征选定为三元组依存关系时,网络有更好的分类结果.三元组依存关系特征可以看作是一条“主—谓—宾”构成的记录,相较于一元词、二元词有更高的客观情感色彩和依存关系,且具有复杂充分的文本信息.所以文本情感的分类工作选择在DBN网络中运行更具有优越性,且复杂的特征更能提高分类准确度.
针对文献[22]实验所用网络单一的问题,文献[23]分别将一元词、二元词和LDA提取到的浅层特征输入到DBN 网络与SVM 网络中,基于DBN 无监督的预训练阶段是特征提取的过程,可以学习到更加复杂且具象可分的深层特征,更有利于文本的分类,实验结果证明DBN不仅能提取出深层特征,而且能利用深层特征参与分类,且比在同等条件下的SVM网络分类结果更优.并且将LDA选择出来的特征输入到DBN网络与SVM网络中,分类结果都优于将一元词、二元词作为特征进行输入得到的分类结果.这是由于LDA 是由三层结构组成的生成模型,即“词—主题—文档”,能够表达出深刻的文本信息,而后输入到DBN网络中将继续挖掘更加复杂的信息,更优地完成分类任务.
文献[24]则将特征选择和DBN相结合,提出一种新的文本分类算法,即FSDBNF.文献将文本进行四种方法的特征选择后的数据分别输入到FSDBN、DBN、HDBN等分类器中,对比实验结果得出结论:改进的FSDBN相较于DBN不仅略提高了分类准确率,还明显缩减了训练时间.因此,FSDBN在情感分类任务上有着较其他分类器良好的优越性.这是因为将原始数据分别按照上述四种特征选择的方法约减剔除一些无用的特征进行降维,通过实验结果可以说明处理后的数据集留下更加有意义的特征,特征与特征之间的关联性更大,这些优秀的特征能使DBN网络得出更加优异的分类结果.
文献[25]考虑到情感分类问题对标签的依赖程度采用弱监督学习的方式,提出IGEF-DBN 网络.文献从信息几何角度指导模糊模型从特征分布中吸收信息,将改进的模糊c均值(FCM)聚类算法中的模糊规则嵌入到IGEF-DBN中以提高模糊深度信念网络的性能,最后IGEF-DBN网络应用于情感分类任务中.实验将IGEF-DBN与TSVM和FDBN的分类性能进行了比较.IGEF-DBN在5个数据集的测试精度与性能都优于其他网络.然而FCM聚类算法在某类样本基数很大,当出现新样本时,该样本中K个邻点在样本基数大的类别中权重类型占大多数,说明这类样本与目标样本距离较远,会导致样本的不平衡,而且其计算量也较大.
5 结束语
DBN的训练过程既包括无监督训练阶段也包括有监督训练阶段,它有着稳定的网络性能,克服传统的文本分类方法出现维数灾难、局部最优等问题.DBN对复杂问题具有良好的特征挖掘能力和普适性,对经过处理而保留有用特征的数据集有非常优秀的分类能力.但是网络中参数的选取多数是通过大量的实验得到,同时网络的函数较为复杂且需要迭代的次数较多,进而训练时间则较长.希望在未来的发展中,能进一步优化DBN使其解决上述问题.
