基于情报大数据的目标活动规律分析∗
2021-04-06
(武汉市江夏区藏龙北路1号 武汉 430205)
1 引言
目标关键信息的获取是进行后续目标识别的重要步骤,而目标活动规律的分析在目标信息获取中占有关键的地位,对目标航迹的提取、处理、分析可以使我们有效把握目标的行进方向与意图。传统的目标活动分析采用对目标利用相关传统算法进行计算,推理,很难通过单独利用这些信息对目标进行预测,识别等操作,随着大数据行业的兴起,利用大样本推算同类样本的趋势成为一个广泛的研究方向,并且在各行各业取得了较好的效果,本文采用传统与大数据相结合的思想,对目标的航迹规律从不同的维度进行拟合、分类分析,然后又阐述了一种基于深度学习与大数据结合的目标航迹预测方法。通过大数据的应用,使我们能从目标的既往航迹样本中分析找出该目标的活动规律,对目标的航迹做出合理预测。
2 曲线拟合及基于k-means聚类的目标活动轨迹分类分析方法
2.1 曲线拟合
2.1.1 RANSAC算法及改进
RANSAC算法全称Random Sample Consensus(随机抽样一致)算法,该算法可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数,去除数据集中的“局外点”(噪声点),而留在其中的局内点则是符合模型的最佳点的集合。RANSAC算法因为简单可行,以及对噪声点鲁棒性强的特点受到广泛的应用。该算法的步骤如下:
1)在数据集C中随机选取几个点设为局内点集S;
2)设置合适的数据模型M;
3)把其他点加入到模型中,根据阈值T判断其是否属于局内点集,属于则加入局内点集;
4)记录下局内点集数量;
5)对步骤1)~4)进行N次重复迭代,则生成N个模型i(1,2,3,…,n),判断这N个模型中局内点数量最多的模型则为最优模型。
该模型能够有效去除数据集中的噪声点,但是该算法在数据点选取上的随机性使得该算法样本之间的距离可能很小,从而使数据不具备代表性,进而影响精度。改进的RANSAC算法首先对抛物线进行分段,分成N段数据集,在对每段数据集利用RANSAC算法进行采样时,同样对每段数据集分成数段,对每段数据进行随机采样,从而形成最终的数据集随机样本数据,这样可以有效避免样本数据的集中,提高算法精度。
2.1.2 抛物线拟合算法
由最小二乘法的原理可知,最小二乘法是从全局求得最优解,以此获取对全局最优的二次曲线,没有有效考虑噪声点的影响,本文采用最小二乘法与RANSAC相结合的方式来对目标数据进行抛物线拟合,以此达到更好的拟合效果。
具体步骤如下:
1)获取点数据集(y1,y2,y3…yn),其对应的时间数据为(x1,x2,x3…xn),对数据以时间集为x轴平均分为3个数据集Y1=(y1,y2,y3…yt1),Y2=(y1,y2,y3…yt2),Y3=(y1,y2,y3…yt3)。这样可以避免算法在某一块重复选点造成效率降低。
2)设置迭代次数K,对每个数据集用改进的RANSAC算法进行k次迭代。使迭代获取的数据集中的最大数据集的数据个数Y'≥0.8*Yi(1≤i≤3)时迭代才能结束,这样可以有效保证模型结果的正确性。
3)若采用步骤2)不能得到正确的数据集,则采用原有的数据集。
4)根据上述步骤得到迭代计算后的高度数据集 H=(y1,y2,y3…ym)。
5)对新的数据集H重新利用最小二乘法进行曲线拟合。
此算法结合了RANSAC与最小二乘法的优点,可以获得更好的抛物线拟合效果。
2.2 基于k-means聚类思想与曲线相似度的曲线分类建模方法
随着大数据技术的发展与应用,大数据预测与分析技术正在逐渐成熟,本文采用适用于大数据的聚类k-means算法与曲线相似度相结合的方法对相关类型的数据进行分类分析。
2.2.1 曲线相似度
首先我们设定两条曲线 S1=(x1,x2,x3…xm),S2=(y1,y2,y3…yn)的距离为

由此我们可知两条曲线的距离是两条曲线对应点距离的最大值,该值越小,则表明这两条曲线越是相似。
设定一个曲线类集合C=(S1,S2,S3,...Sm),其中Si=(yi1,yi2,...yin)代表集合中的一条曲线,曲线类C的相似度记为
当引入一条新的曲线后,曲线集合C则变成C′,对应的类相似度重新计算变为D′,我们需要判断D′是否大于D。
为了分析曲线分类的质量,我们设定曲线类质心 ,假 如 曲 线 集 合C=(S1,S2,S3,...Sm) ,其 中Si=(yi1,yi2,...yin),设置曲线类的质心为

标准差是反映一组离散数据离散程度最常用的量化形式,设有曲线类C=(S1,S2,S3,...Sm),其中Si=(yi1,yi2,...yin),其质心,则该曲线在x时刻的标准差为

其中σn越大,则该类集合曲线的差异性越大,其质心的效果也越差,反之该值越小,则集合的差异性越小。
对于曲线集合C=(S1,S2,S3,...Sm)基于曲线相似度的曲线自动分类方法步骤如下:
1)设定曲线的相似度阈值为T;
2)计算曲线集合中每条曲线之间的距离,选取距离最大的两条曲线中的一条记为S;
3)设置曲线类C1,把曲线S归入到曲线类C1,设置C=C-C1;
4)在集合C中计算每条曲线到C1的距离,得到最小距离所对应的曲线记为A,记曲线类C1M=C1+A;
5)计算类C1M的相似度D(C1);
6)若D(C1)>T,则跳转到第2)步开始执行,否则把曲线A归入到曲线类C1,记C1=C1+A,C=C-C1,然后跳转到第5)继续执行;
7)当数据集C中没有数据时停止计算。
2.2.2 k-means聚类算法
聚类是指将数据集中在某些方面相似的数据成员进行分类组织的过程,聚类就是一种发现这种内在结构的技术,聚类技术经常被称为无监督学习。
k-means聚类算法也被称为K均值聚类算法,是一种比较常见的聚类分析方法,其是一种迭代求解的聚类分析方法。具体步骤如下。
1)随机选取K个点作为聚类中心,形成K个数据聚类;
2)计算每个点到这K个聚类中心的聚类,选取最近的聚类加入;
3)重新计算每个聚类的质心;
4)重复迭代直到聚类质心不在变化或达到设定的迭代次数。
2.2.3 基于曲线相似度与k-means算法的其他维度曲线分类方法
曲线自动分类算法可以有效地对数据进行分类,其缺点是每增加一个数据,都要重新对曲线进行分类,这样虽然可以达到很好的分类效果,但是在后期如果数据量巨大的情况下,则需要进行多次重复计算,耗费大量计算工作,不适用于数据量巨大的数据分类。我们采用曲线自动分类与K聚类相结合的思想对大批量曲线数据进行分类。
该方法采用聚类思想,利用曲线的相似度概念对曲线进行分类分析,具体步骤如下:
1)获取样本数据(数据量越大,越能有较好的分类效果);
2)对样本数据利用曲线自动分类方法分成K类,获取K个聚类,进而确定了K值;
3)对后续非样本数据采用k-means算法使其归属到具体的某个类别中。
该算法结合了曲线自动分类与k-means聚类的思想,继承了它们的优点,使得确定的分类种类良好,而且对后续加入的数据也能进行自动归类,省去重复计算的时间。
目标活动规律建模方法如下:
1)根据目标的类型对目标分成不同的类别;
2)对每类目标的数据进行分类管理;
3)对目标活动规律提取相对高度,相对距离,相对速度,相对方位等特征数据;
4)对特征比较类似抛物线的曲线数据可以采用抛物线拟合的方式规律分析,对于其他类型的数据利用k-means与曲线相似度相结合的方式进行特征数据的分类;
5)得到目标各维度数据的分类结果;
6)依据分类结果对每类数据进行分类管理;
7)对于后续加入数据,依据上述分类算法进行类别归属的判别。
起降数据分类建模流程图如图1所示。

图1 起降数据分类建模图
3 基于LTSM的目标活动规律预测分析
3.1 LTSM神经网络算法模型
3.1.1 RNN神经网络
RNN神经网络,即循环神经网络,是对DNN神经网络改进的一种神经网络计算模型,其有输入层、隐藏层、输出层三层组成,RNN每个时刻隐藏层的输出都会把当前隐藏层的内容传递给下一时刻,因此每个时刻的网络都会保留一定的来自之前时刻的历史信息,因此该网络模型可以存储一定时刻的历史信息,使其具有一定的记忆能力,在RNN中,神经元的输出可以在下一个时间段直接作用到自身,即当前层神经元在当前时刻的输入,除了上层神经元在该时刻的输出外,还包括其自身在上一时刻的输出,但是RNN模型也有明显的缺点,就是可能会引起梯度消失或梯度爆炸现象。
3.1.2 LSTM神经网络
LSTM全称长短期记忆人工神经网络(Long-Short Term Memory),是对RNN的变种,传统RNN对短期输入很敏感,LSTM在其中加入一个单元状态来记忆较长时间内的信息。这种基于单元状态的信息传递方式可有效克服传统RNN的上述缺点,对RNN模型起到了完善作用。
LTSM模型通过引入遗忘门,输入门与输出门来保存与记忆信息。这些门可以打开或关闭,用于判断模型网络的记忆态在该层输出的结果是否达到阈值从而加入到当前该层的计算中,这些门的引入使得我们可以灵活地控制与管理对于历史信息的运用。
遗忘门,其计算公式如下:

其中Wf是遗忘门的权重矩阵,[pt-1,xt]表示把两个向量链接成一个更长的向量,bf为遗忘门的偏置量,σ为sigmoid函数。
输入门,公式如下:
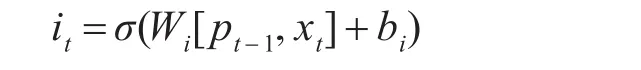
根据上次的输出与本次的输入可以更新当前单元的输入状态mt:
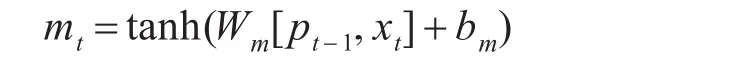
根据 ft,it,mt可以对当前时刻 nt进行更新,计算如下:
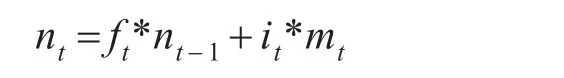
输出门确定我们当前的输出值pt,计算如下:

3.2 目标活动规律预测算法
利用上述LTSM算法的特征,结合大批量历史数据及目标的多维度特征可以对目标在一定时间内的目标轨迹进行行为预测。在LTSM的基础上,提出基于大批量数据的目标活动规律预测算法,具体预测算法步骤如下。
1)获取目标的多维度特征
为了对目标的活动轨迹进行预测,需要首先建立目标活动规律数据库,存储该目标的相对速度,相对距离,相对水平x方向、水平y方向,垂直方向等特征,把这些特征数据作为多维度样本进行输入。
2)数据预处理及归一化
我们拿到的上述多维度数据都是没有进行处理的,所以首先需要对这些数据进行处理,例如空值补充等,预处理后需要对数据进行归一化,由于神经网络激活函数的限制,需要将数据进行数据映射等处理。
3)模型的建立
模型的建立在轨迹预测中起到核心作用,根据LTSM模型,把上述特征输入该模型中,设置时间窗口,激活函数,利用TensorFlow框架对模型进行快速搭建。
4)模型的训练
根据建立的模型,输入训练样本数据对该模型进行训练,然后用准备的测试数据对模型进行评价,最终训练出具有良好效果的网络模型。
5)轨迹预测
根据训练好的模型,利用数据对目标的特征进行预测与分析。
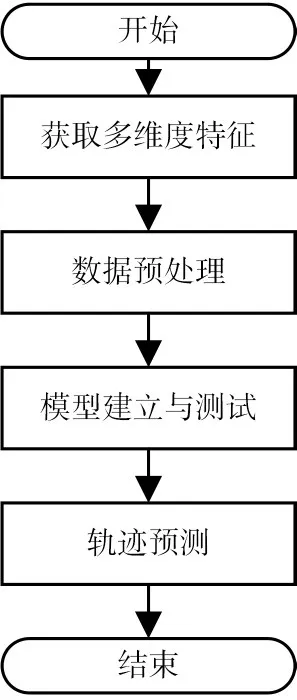
图2 轨迹预测流程图
图3为通过上述模型对若干目标进行预测与实际结果的对比图。
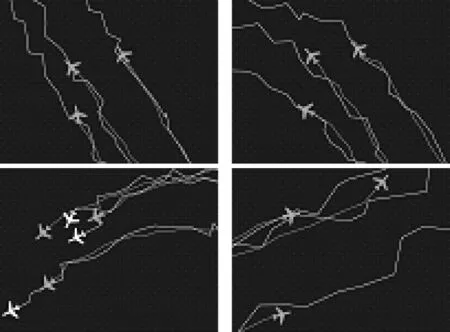
图3 预测与实际结果对比图
4 结语
本文针对目标的活动规律分析,主要进行了两个方面的研讨,首先针对目标活动规律数据的曲线的不同类型介绍了抛物线拟合分类算法及基于曲线相似度与大数据k-means均值聚类算法结合的曲线分类算法,这些算法可以有效地对目标的不同维度的活动数据进行分析。然后本文介绍了一种依托大数据,基于LTSM的目标活动轨迹预测算法,根据该算法模型能够有效对目标的活动规律行为进行预测与分析。
