基于性别和年龄因子分析的鲁棒性人脸表情识别
2021-04-01廖海斌
廖海斌 徐 斌
1(湖北科技学院计算机科学与技术学院 湖北咸宁 437100) 2(江西省智慧城市产业技术研究院 南昌 330096)
(liao_haibing@163.com.cn)
人脸表情识别与人脸身份识别一样,是一个热门的研究领域[1],具有广泛应用场景.如,可应用于安全驾驶、智能教室、视频会议、虚拟现实和认知科学等[2-4].人脸表情识别系统一般由两大部分组成[5]:1)特征提取;2)分类器设计.其中,特征提取是从人脸图像中提取出可鉴别特征.目前两大常用的特征提取方法为基于几何结构的特征提取和基于表观的特征提取.基于几何结构的特征提取方法首先需要精准定位出人脸关键点,然后基于关键点构建人脸几何距离和角度等结构特征向量[6-7].基于表观的特征提取方法主要是利用图像的纹理信息进行人脸表情识别[8-9],具有简单有效的特性,但缺乏对遮挡和光照等变化的鲁棒性.在自然场景中,人脸的姿态、遮挡和低分辨率等变化因素都会对人脸特征提取带来较大影响.所谓的分类器设计就是基于提取的人脸特征构建出一种能对表情进行分类的识别系统.其中,k-最近邻(k-nearest neighbor, KNN)和支持向量机(support vector machine, SVM)是2种经典的分类器.最近,热门的卷积神经网络(convolutional neural network, CNN)图像识别方法能提供一种端到端的人脸表情识别方案[2,10-11],其将人脸特征提取和分类识别融合到一种框架内.然而,CNN需要大量的训练样本和高性能计算GPU支持[11-12].另外,其框架内采用Softmax分类器也并非最优的选择.有关实验表明:在利用深度学习提取特征后,采用联合贝叶斯分类器或SVM分类器会取得更好效果[13].

Fig. 1 Facial expression images under different attributes图1 不同属性下的人脸表情图像
早在20世纪,Ekman等人[14-15]基于跨文化、跨区域研究,设计了6种基本情感(愤怒、厌恶、恐惧、高兴、悲伤和惊讶),他们指出不同文化背景的人类具有同样的基本情感表达方式.然而,2012年神经科学和心理学高级研究表明:人类的6种基本情感表达是与特定文化背景相关的,不具有普适性[16].与此同时,本文作者发现不同性别和年龄的人表现出不同的表情表现模式,如图1所示,小孩和成年人就有着不同的悲伤表情,即人脸的性别和年龄等属性对人脸表情识别有着重要影响.因此,本研究组提出了一种基于人脸性别约束的随机森林人脸表情识别方法[17],此方法充分考虑人脸性别因子对人脸表情识别的影响,获得了较好的效果,从侧面证明了文献[16]的结论.本文在前期工作的基础上做了进一步深入研究,与前期工作相比,其创新性和改进点如下:
1) 整体思路和框架.提出基于人脸属性因子分析的人脸表情识别框架.前期工作只考虑了人脸性别因子的影响;而在本文中,不仅考虑到人脸性别因子,还考虑了人脸年龄因子.这是因为在后来的研究中发现,不同年龄段的人群有不同的表情表现方式,因此在原来性别的基础上增加了人脸年龄属性,综合考虑人脸性别和年龄共同作用下的人脸表情问题.实验证明,加入人脸年龄因子后,效果得到明显提升.
2) 人脸特征提取.提出基于多示例注意力机制的特征提取方法.在后来的研究中发现,针对人脸表情识别问题,不同的人脸示例块对最终人脸表情识别的贡献度是不一样的.比如,对人脸表情识别问题,人脸嘴巴区域就比人脸额头区域更重要,人脸眼睛区域比人脸面颊区域更重要等.前期工作直接将各示例特征串接,并没有考虑各示例块的权重问题.另外,本研究组发现EfficientNet[18]比GoogLeNet网络模型性能更优.因此,在本文中,采用EfficientNet进行各示例特征提取,然后利用注意力机制自动学习不同示例块的权重,最后进行各示例特征的融合.
3) 人脸表情分类器设计.提出基于人脸性别和年龄约束的多条件随机森林人脸表情识别方法.前期工作只是进行2类别的条件随机森林分类器设计,而本文则是进行了8类别(排列组合不同性别和年龄类别形成8类)条件随机森林分类器设计.本文创新性地将人脸性别和年龄进行排列组合以生成不同的人脸属性类别,解决了人脸性别和年龄交叉影响问题;另外,在多条件随机森林分类器设计时,避免了对人脸性别和年龄进行多层级判别的问题,只需要一次进行8选1即可.
综上,本文利用深度学习优良的特征提取特性,提出一种多示例注意力学习的特征提取方法;同时,利用随机森林良好的分类性能,提出一种基于人脸属性的多条件随机森林人脸表情分类器设计方法.
1 基于属性因子分析的人脸表情识别模型
图2为基于人脸性别和年龄双属性因子分析的人脸表情识别框架,主要包括人脸特征提取、人脸双属性估计和人脸表情识别三大部分.
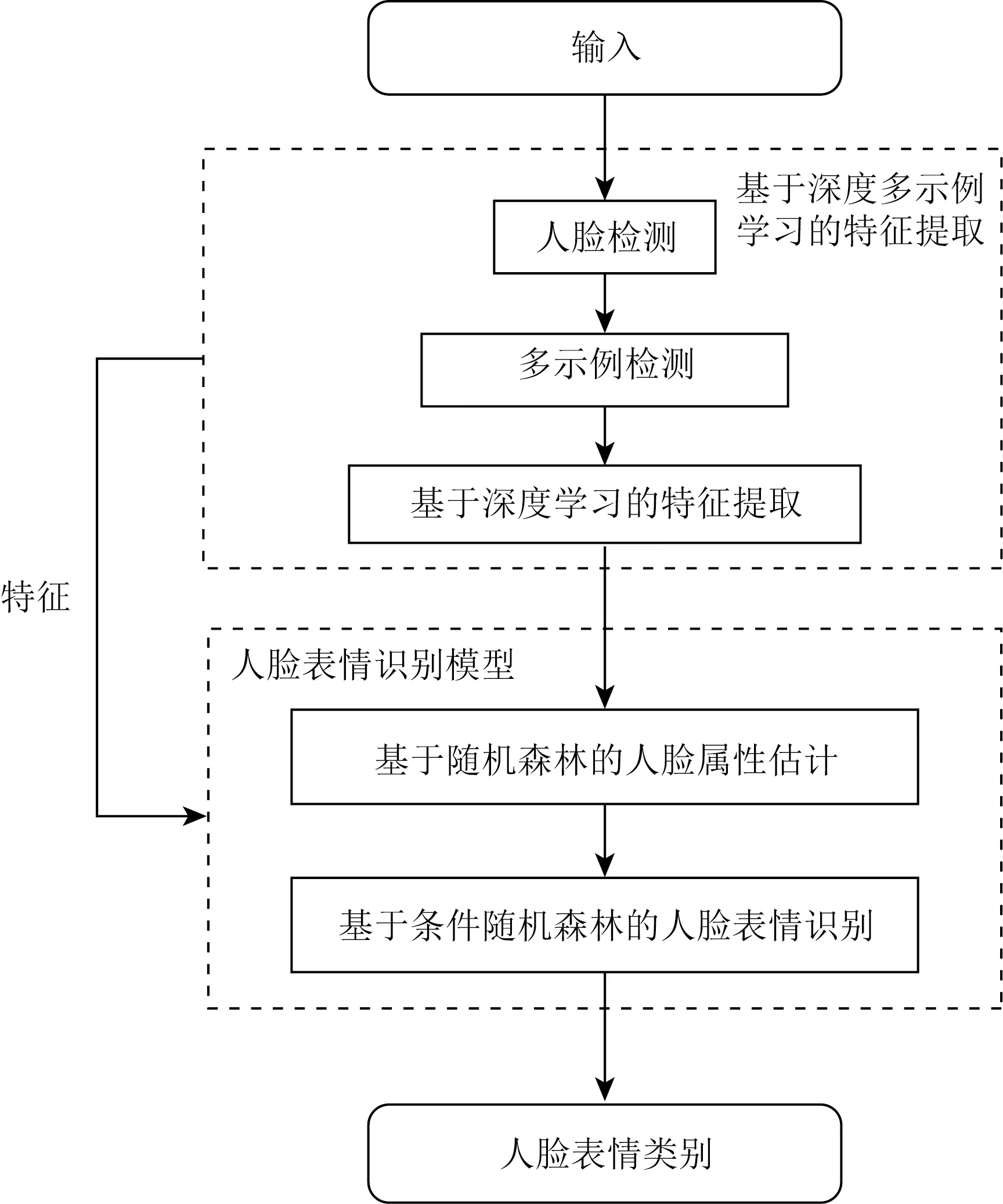
Fig. 2 Face expression recognition model framework图2 人脸表情识别模型框架
1.1 基于多示例注意力机制的特征提取
基于多示例注意力机制的人脸特征提取包括多示例选取、多示例特征提取和多示例特征融合3部分:
1) 人脸多示例选取
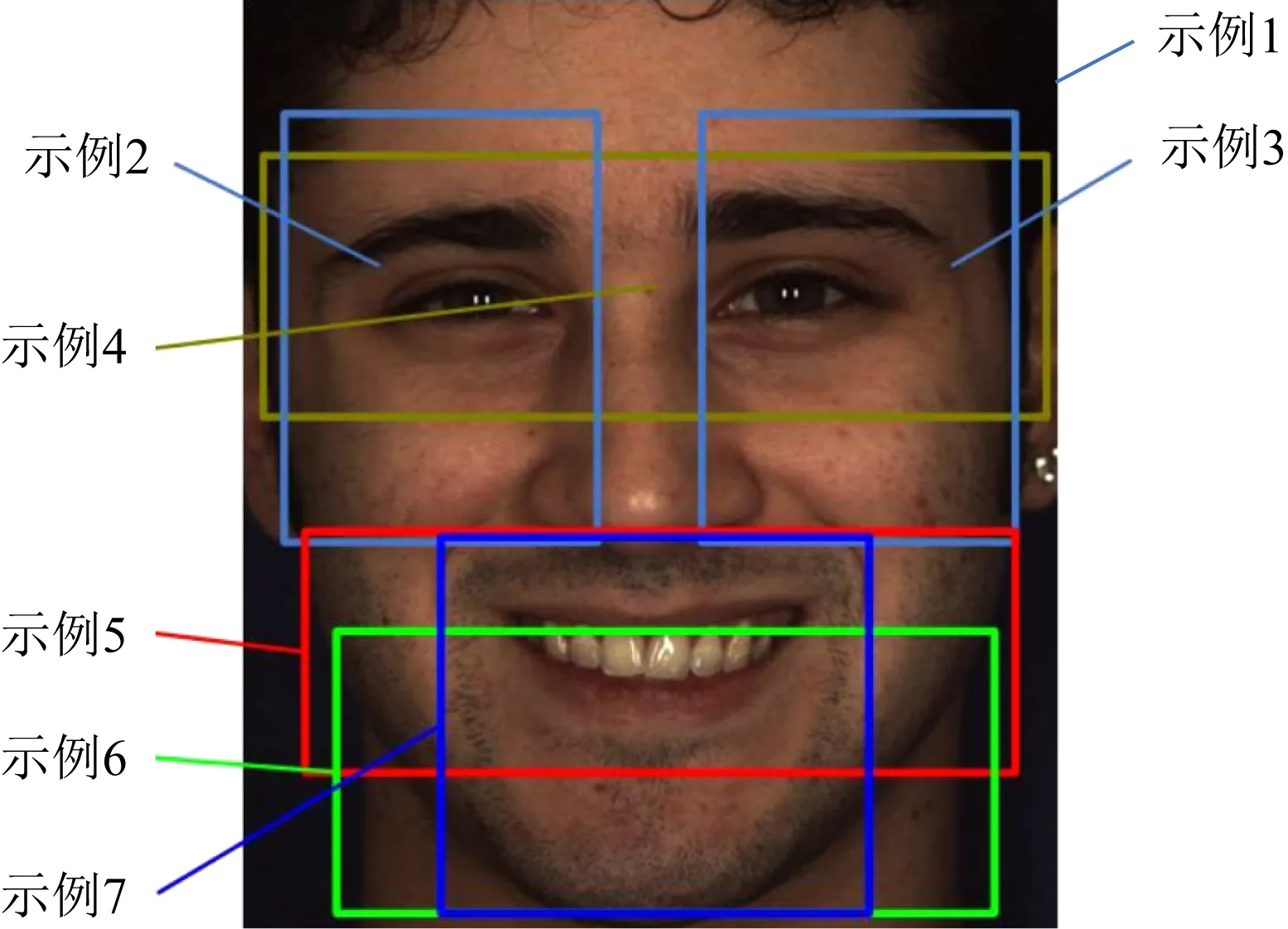
Fig. 3 The multi-instance example of facial expression图3 人脸表情多示例
研究中发现:人脸表情变化主要集中在眉毛、眼睛、嘴巴等关键区域.因此,本文参考示例密集采样[19]和图像块显著性检测方法[20],配合人脸的“三眼五庭”结构特性,选取如图3所示的7个人脸分块作为人脸表情示例.因此,7个人脸示例依次为:整个人脸图像、左眼区域块、右眼区域块、眼部区域块、嘴部区域块1、嘴部区域块2和嘴部区域块3.
2) 基于EfficientNet的多示例特征提取
利用EfficientNet-B3网络模型对上步选取人脸表情示例进行特征表示学习.EfficientNet通过LFW(labled faces in the wild)和YTF(youtube faces in the wild)人脸库进行预训练,使其具有高层语义信息表示能力.
3) 基于注意力机制的多示例特征融合
由于人脸不同示例对人脸表情识别的重要性是不一样的;另外,由于人脸遮挡和噪声等因素影响也会导致不同示例对最终识别的贡献度不一样.因此,本文利用注意力机制进行示例权重学习,提出一种基于注意力机制的多示例特征融合方法,如图4所示:
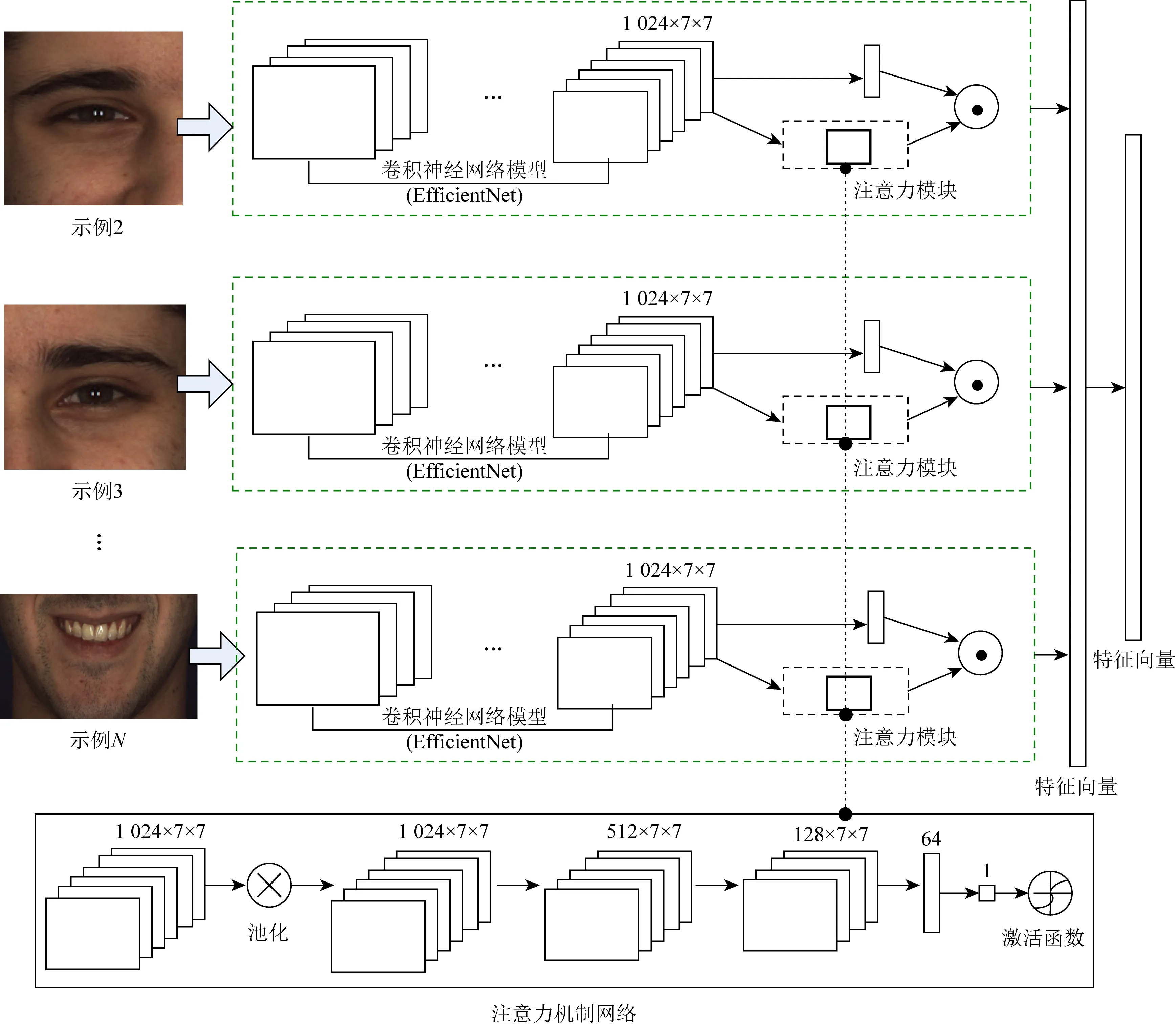
Fig. 4 Multi-instance fusion network based on attention mechanism图4 基于注意力机制的多示例融合网络
在EfficientNet的最后一层加入注意力模块,将注意力模块输出的权重乘以EfficientNet输出的向量,作为示例最后的特征向量.注意力网络如图4底部所示,其输入为EfficientNet最后一层的特征图,输出是一个概率值.假设基于EfficientNet的人脸示例特征向量提取为
yi=xiw+b,
(1)
其中,yi表示最后的特征输出,xi表示第i个示例在最后一层中的特征图,w是权值项,b为偏置项.假设注意力机制网络的输出为
αi=Φ(xi),
(2)
其中,αi是第i个示例的权重值,Φ表示注意力网络操作.因此,利用αi对yi进行加权可得
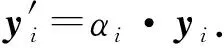
(3)
然后,多示例融合特征可以通过将各示例特征串连而得到
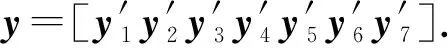
(4)
最后,在深度学习网络模型中增加一个全连接层对式(4)得到的多示例特征y进行降维处理.
1.2 属性约束人脸表情识别
不同性别和年龄属性下的人脸表情图像所在的特征空间具有多样性,如果不考虑人脸性别和年龄因子,很难找到一个合适的分类曲面将人脸表情特征进行空间划分.本文利用人脸性别和年龄属性作为隐含条件进行人脸表情特征空间划分,提出一种属性约束人脸表情识别模型.
1) 人脸属性估计
将人脸属性根据性别和年龄组合情况分为8类:

(5)
首先,训练生成一个基于人脸性别和年龄属性分类的随机森林TA.并利用如下不确定性测度:
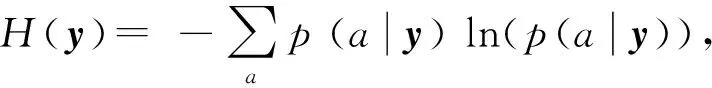
(6)
其中,a表示人脸属性类别(a∈{Ω1,Ω2,…,Ω8}).不确定性测度引导各节点选择最优策略不断将当前节点分裂为不确定性降低的2个子节点.
然后,基于多示例注意力提取的人脸特征y,采用随机森林TA进行人脸属性分类.每个叶子节点l上的人脸性别和年龄属性概率为
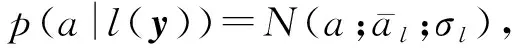
(7)
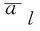
最后,融合所有叶子节点概率值,得到最终的人脸属性类别:
(8)
其中,lm为决策树对应的叶子节点,M为决策树的数量.
2) 条件随机森林训练
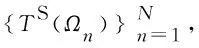
3) 人脸表情识别
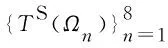
在人脸属性a∈Ωn已知的条件下,y的表情类别由最大概率p(e|Ωn,y)决定:
(9)
其中,M为决策树的数量,lm为第m棵决策树上y达到的叶子节点.在人脸属性a未知的条件下,y的表情类别为
(10)
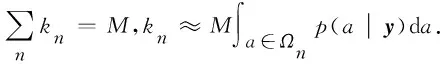
2 实验分析
2.1 实验数据和参数设置
为了验证本文方法的有效性,在公开的Cohn-Kanade(CK+)[21],ExpW[22],RAF-DB[23],AffectNet[24]人脸库上进行实验验证.CK+是经典的人脸表情库,因此将使用其来验证本文方法的性能.但是,此库人脸图像都是在可控环境下采集的,并不能充分说明算法的优越性.为了验证算法在非可控环境下的性能,利用ExpW,RAF-DB,AffectNet这3个表情库构建了自然场景下的人脸表情组合库:
首先,根据人脸性别和年龄属性将ExpW,RAF-DB,AffectNet人脸库合并后分成8类.
然后,从每类中挑选出1.2万张人脸表情图像,共9.6万(9.6=1.2×8)张人脸表情图像作为组合库.当从每类中挑选出1.2万张人脸表情图像时,采用均匀采样的方式尽可能使6种表情均衡.由于ExpW,RAF-DB,AffectNet人脸库中老年人表情图像比较少,作者通过学生自愿的方式收集了一部分学生爷爷奶奶等老年表情图像样本,以弥补老年人表情图像样本较少的缺陷.
最后,将得到的9.6万张人脸表情库分为3个数据集:训练集7.6万张;验证集1万张;测试集1万张.
由于ExpW,RAF-DB,AffectNet人脸库都是来自于互联网上传的自然场景人脸图像,因此组合库可以很好地验证算法在真实环境下的性能.
实验采用pyTorch深度学习构架实现Efficient-Net和多示例注意力人脸特征提取.在训练阶段采用随机旋转和镜像的方式进行数据增广.模型训练中关键参数设置:学习率采用动态调整方法,初始设置λ=0.001,epochs=6 000,分裂迭代次数为1 500,树深度为20.
2.2 人脸属性估计实验
本节利用CK+和组合库进行人脸属性估计实验,人脸属性估计样例如图5所示,表1给出本文方法、CNN[25]、RoR[26]的人脸属性识别比较结果.其中,CNN采用AlexNet网络结构获得了85.6%准确率;RoR采用基本块和瓶颈块的方式构建残差网络获得了93.45%准确率;本文方法获得了最高的准确率95.03%,另外0.5的方差也表明了其鲁棒性.

Fig. 5 Examples of different face databases and their facial expression recognition results图5 不同人脸库样例及其表情识别结果
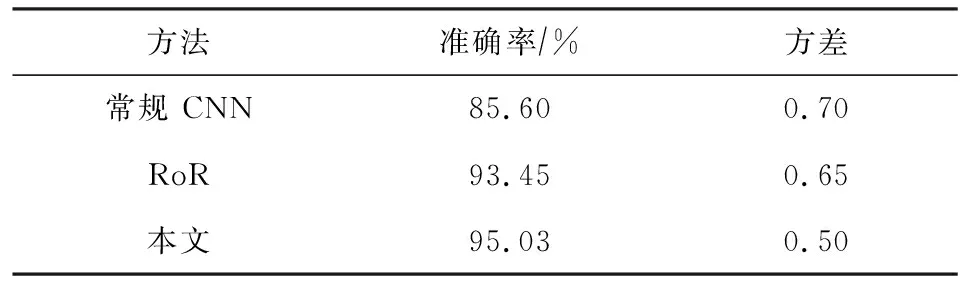
Table 1 Comparison of Face Attribute Estimation Results表1 人脸属性估计结果比较
2.3 消融实验
1) 特征提取影响分析
为了验证本文提出的多示例注意力特征的有效性,将其与EfficientNet-B3特征、文献[17]提出的特征(Multi-instances+GoogLeNet)、SIFT(scale-invariant feature Transform)、HOG(histogram of oriented gradient)、几何结构特征进行比较分析.表2给出了不同特征在组合库上的人脸表情识别结果.从表2中可以看出,多示例注意力特征在非常难的自然场景下取得了最好识别率70.52%,比第2名(前期工作)高出了6%左右,表明了多注意力机制和EfficientNet的有效性.其次,多示例GoogLeNet特征比单独EfficientNet-B3特征识别率提高2%左右,表明了多示例学习的有效性.另外,从表2中还可看出本文分类器比SVM分类器具有更优性能.
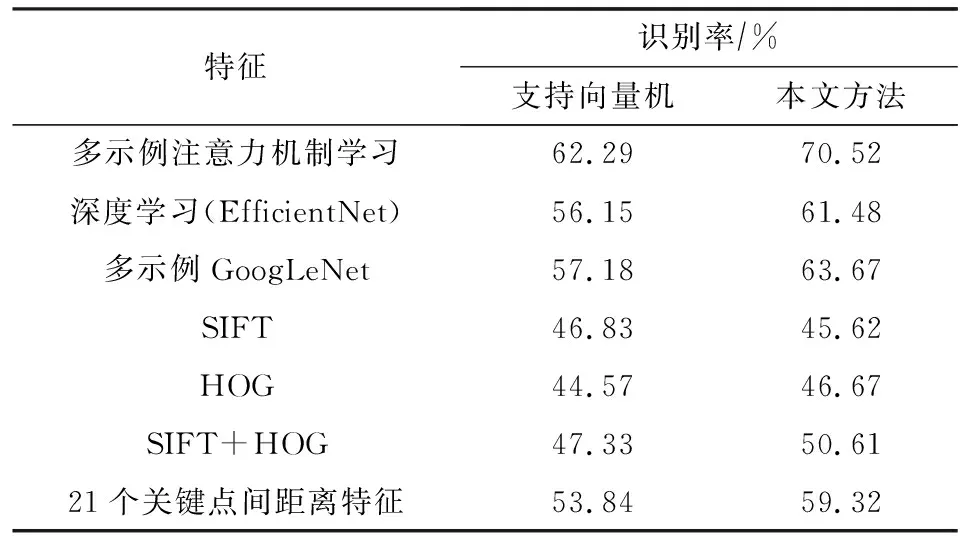
Table 2 Comparison of Facial Expression Recognition Results Under Different Features
2) 人脸属性因子影响分析
为了验证人脸性别和年龄属性对人脸表情识别的影响,图6给出了基于人脸性别和年龄双属性多条件约束、基于人脸性别单条件约束和无人脸属性条件约束下的人脸表情识别结果比较.从图6中可见,基于人脸性别和年龄双属性多条件约束的人脸表情识别方法要高于仅使用人脸性别单属性的方法,而基于人脸性别约束的人脸表情识别要高于无人脸属性条件约束的方法.由此可得出,人脸性别和年龄属性是人脸表情识别的一个重要影响因子,组合使用两种属性比单独使用性别一种属性效果要好(在组合人脸库上识别率提高了5%左右).
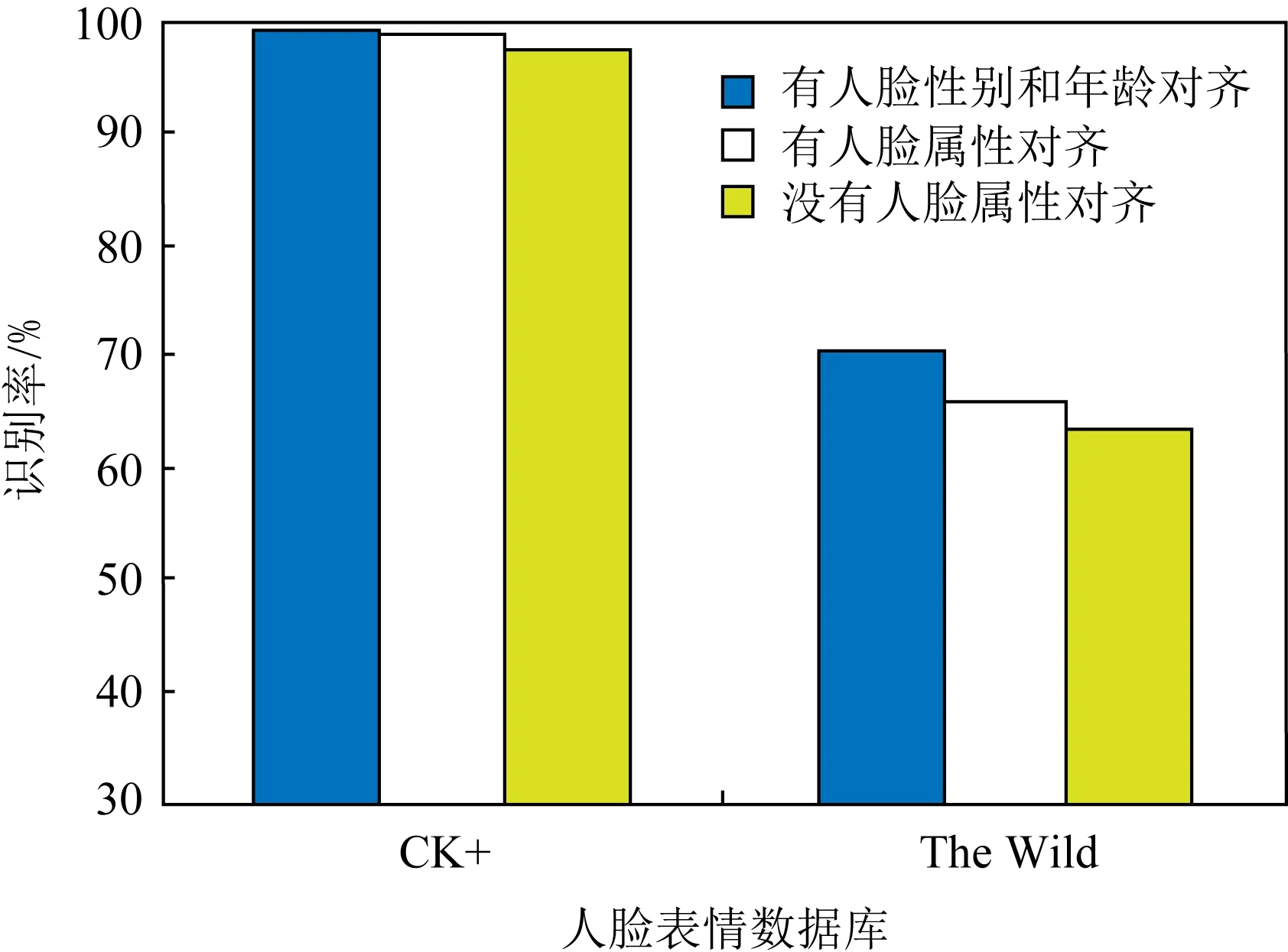
Fig. 6 Comparison of facial expression recognition based on facial attributes constraint图6 基于人脸属性约束的人脸表情识别比较
3) 综合分析
表3给出了在组合人脸表情库上,不同特征和分类器组合的识别率比较结果.从表3中可以看出,多示例注意力特征比经典的CNN(如GoogLeNet)特征高出7%左右;另外,基于人脸属性分析的条件随机森林(CRF)分类器比传统的支持向量机(SVM)和随机森林(RF)分别高出了7%和5%左右.

Table 3 The Recognition Results by Different Featuresand Classifiers Combination
2.4 人脸表情识别实验
1) 基于组合库的实验
表4给出了本文方法基于组合库的人脸表情识别混淆矩阵,从表4中可以看出平均准确率达到了70.52%,高兴表情达到了最高准确率88.7%,紧跟其后的分别是惊讶、害怕和悲伤表情,都超过了67%的准确率,最低的厌恶表情也获得了59.5%的准确率.
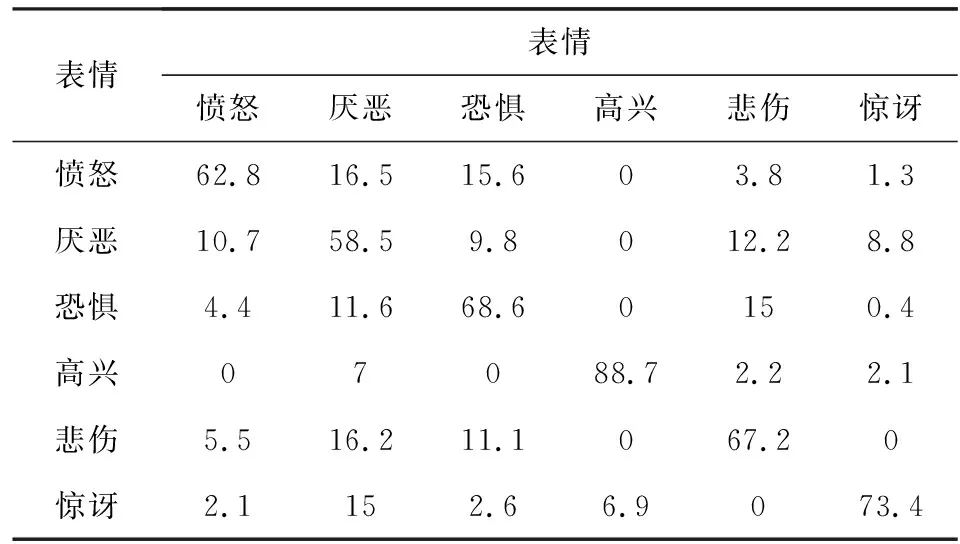
Table 4 Facial Expression Recognition Confusion MatrixBased on Combinatorial Database
2) 基于CK+的实验
CK+是经典的人脸表情库,为了完整性,本节同时也在此库上验证本文方法的有效性.实验遵循此库公开的训练测试规则,利用CK+中的训练集对模型进行微调,利用测试集进行测试.表5给出了基于CK+库的人脸表情识别混淆矩阵,从表5中可以看出所有表情的识别率都超过了97%,平均识别率达到了99.25%.
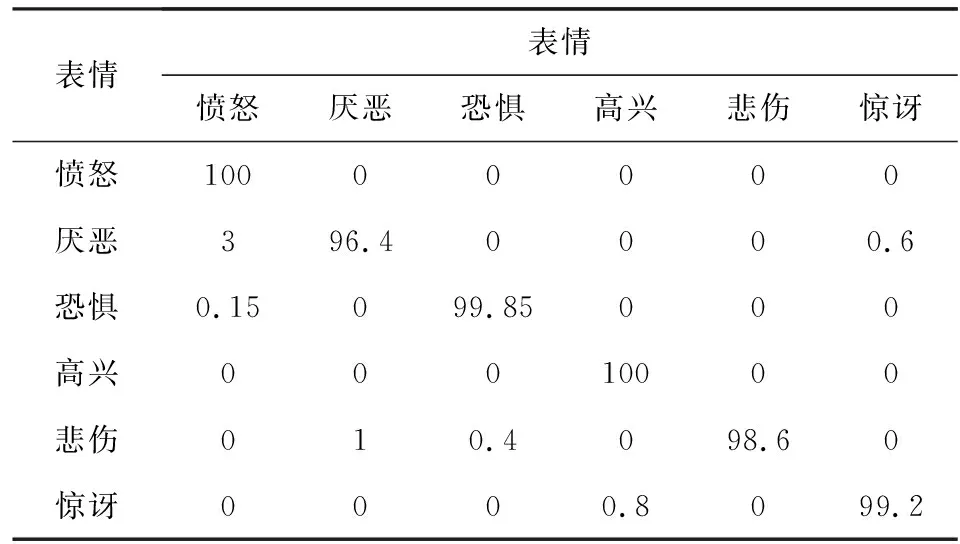
Table 5 Facial Expression Recognition Confusion MatrixBased on CK+ Database
3) 比较实验
为了进一步验证本文方法的有效性,将其与目前先进的方法进行比较实验,实验结果如表6所示.
从表6中可见,基于深度学习的人脸表情识别方法,如文献[11]采用Resnet18+separate loss+Softmax loss的方法在CK+和组合库上分别获得了97.2%和66.83%的识别率;而混合深度学习方法,如C-CNN[31]在CK+上获得了96.67%的识别率.另外,基于Gabor特征的SVM方法在CK+和组合库上分别获得了88.61%和43.79%的识别率;而基于Gabor特征的RF方法在CK+和组合库上分别获得了90.06%和47.35%的识别率.本文方法在CK+和组合库上分别获得最好识别率99%和69.72%.由此可见:①深度学习方法比较传统的Gabor+SVM或RF方法效果要好;②在表情分类中,RF分类器比SVM分类器优秀;③采用人脸性别和年龄双属性约束比仅使用性别约束效果要好.④本文采用的多示例注意力特征和属性多条件随机森林方法具有最好效果.
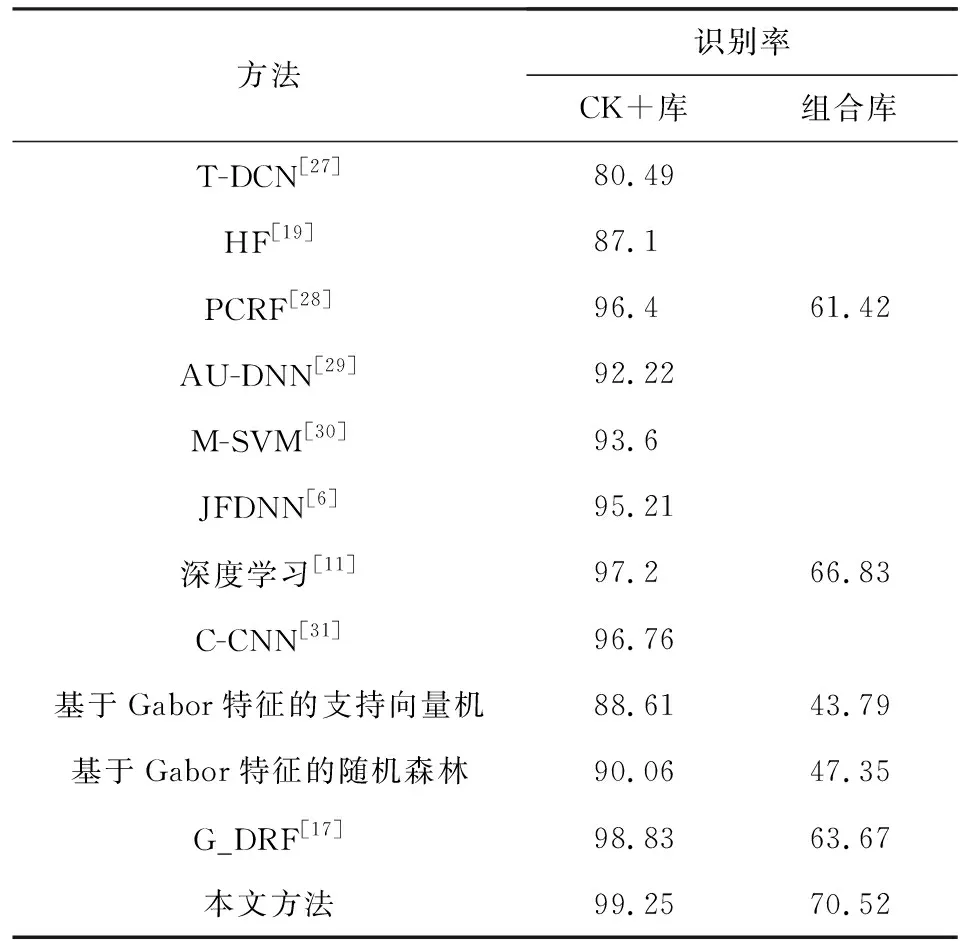
Table 6 Comparison Results of Different Methods Based onCK+ and Combined Database
表7给出不同方法在CPU和GPU上的训练和测试时间比较结果.实验机器CPU:i7-6700 4 GHz 32 GB,GPU:NVIDA GeForce GTX 1080.其中RF和SVM方法仅使用CPU进行训练和测试,
Table 7 Comparison of TrainTest Time of Different Methods表7 不同方法的训练测试时间比较 s
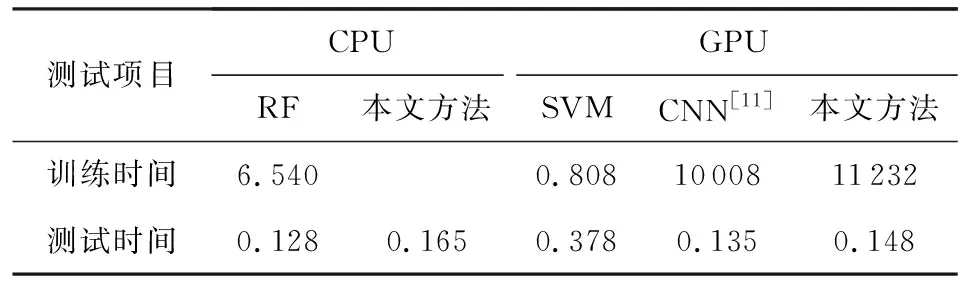
Table 7 Comparison of TrainTest Time of Different Methods表7 不同方法的训练测试时间比较 s
测试项目CPUGPURF本文方法SVMCNN[11]本文方法训练时间6.5400.8081000811232测试时间0.1280.1650.3780.1350.148
本文方法和CNN使用GPU进行训练和测试.从表7中可以看出本文方法与最近的CNN[11]相比,训练时间多出不到0.5 h,测试时间基本相当,但精度却高出3%左右.
2.5 鲁棒性实验
为了验证本文方法对人脸遮挡、噪声和分辨率变化的鲁棒性,本节随机从CK+中选取1 000张人脸图像进行人为加遮挡、噪声和下采样处理,以便生成低质量人脸图像,如图7所示,并将本文方法与CNN,SVM,RF方法进行比较实验.其中,CNN采用GoogLeNet网络结构进行人脸特征提取,SVM和RF方法采用Gabor特征.

Fig. 7 Examples of facial occlusion, noise, and resolution variation图7 人脸遮挡、噪声和分辨率变化样例
1) 遮挡实验
通过随机放置黑色方块的方式人为生成遮挡比例为20%~80%的遮挡图像,如图7(a)所示.图8给出了不同遮挡比例下不同方法的识别结果.从图8中可以看出,本文方法具有最好的遮挡鲁棒性:在遮挡达到60%时,依然能达到65%以上的识别率.另外,在50%遮挡范围内,其性能退化缓慢,当超过50%界限时才开始急剧下降.
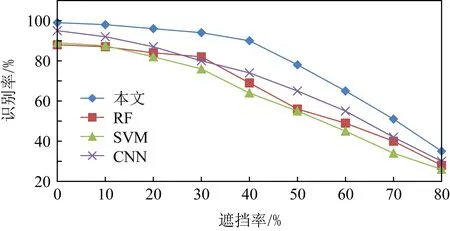
Fig. 8 The recognition rate under different occlusion intensities图8 不同遮挡强度下的识别率
为了进一步验证本文方法对遮挡的鲁棒性,本节选取了一些真实的遮挡人脸图像进行实验,如图7(a)所示,部分定性实验结果如图9所示,其中图9(a)为传统深度学习[32]方法,图9(b)为本文方法,图9(c)为真实情况.从图9可以看出,本文方法对真实的遮挡图像同样具有优秀的鲁棒性.

Fig. 9 The facial expression recognition results under real occlusion images图9 真实遮挡人脸图像表情识别结果
2) 噪声实验
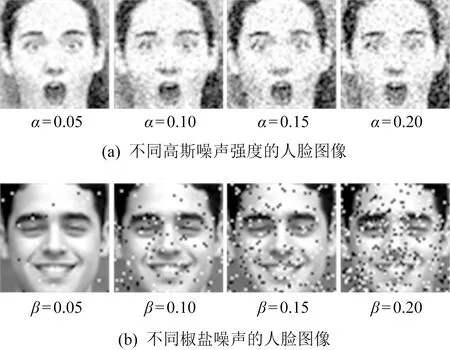
Fig. 10 Examples of Gaussian noise and salt and pepper noise图10 高斯噪声和椒盐噪声图例
为了验证本文方法对噪声的鲁棒性,本节对测试人脸图像人为添加高斯噪声α和椒盐噪声β,二者噪声添加强度分别为0.05,0.1,0.15,0.2,如图10所示.表8给出了不同噪声强度下不同方法的识别率.从表8中可见,随着噪声强度的增加,所有方法性能都有所下降,但是本文方法下降的幅度最小.对于高斯噪声,其识别率平均高出第2名5%左右;对于椒盐噪声,其识别率平均高出第2名9%左右.
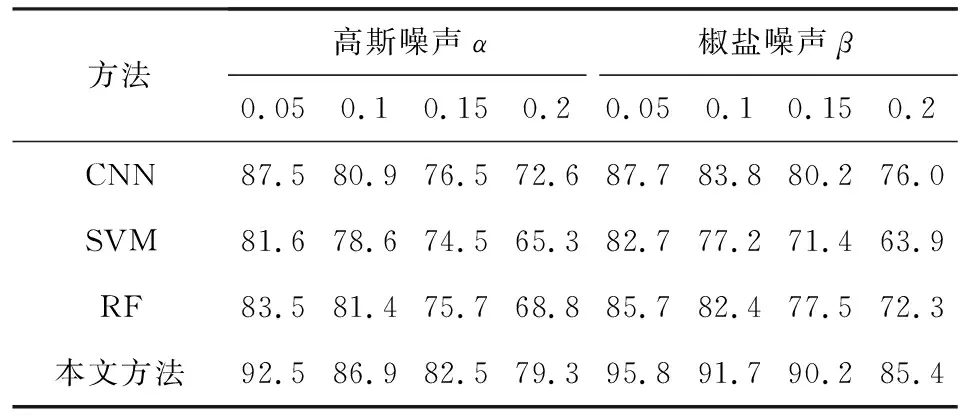
Table 8 Facial Expression Recognition Comparison UnderDifferent Noise Intensities
3) 分辨率变化实验
为了验证本文方法对分辨率变化的鲁棒性,本节对测试人脸图像进行12和14下采样处理以生成不同分辨率人脸图像.不同分辨率下的识别率如表9所示.从表9可以看出,本文方法在所有分辨率下识别率一直保持在94%以上,分辨率变化对其影响不是很大;而RF和SVM方法对分辨率变化却非常敏感.
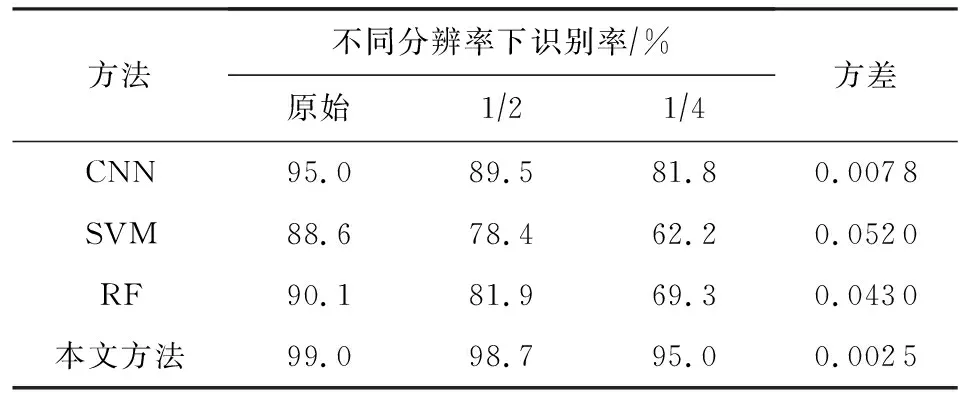
Table 9 Facial Expression Recognition ComparisonUnder Different Resolution Variations
3 总 结
为了缓解人脸表情识别中类内变化和类间变化难题,提出一种基于人脸性别和年龄双属性因子分析的随机森林人脸表情识别方法.通过多示例注意力机制提取鲁棒性人脸特征解决人脸遮挡、噪声和分辨率等变化问题;通过属性条件随机森林分类器设计解决人脸性别和年龄等属性因素影响问题.通过广泛实验表明,本文方法与先进的深度学习方法相比具有先进性,对人脸遮挡、噪声和分辨率变化具有鲁棒性.
