融入领域短语知识的专利主题提取
2021-03-30刘硕马建红
刘硕 马建红

摘要 在对专利文本进行提取主题时,存在大量语义丰富的短语被拆分的问题,导致生成的主题难以理解。已有的将相似性约束的短语融入主题模型中的方法,没有考虑不同领域间短语的区别。因此,根据专利文本的特点,提出了一种融入领域短语知识的主题模型,通过序列化标注的方式抽取专业术语,句法分析的方法抽取功能短语,构建领域短语表。用语义相似度计算的方法对领域短语表进行扩展,将其作为先验知识融入到主题模型中,使用GPU模型(Generalized Pólya urn)强化领域短语,同时缓解领域短语带来的稀疏性,提高主题质量。在中文专利文本上的实验结果表明,融入领域短语知识的主题模型有效地解决了领域短语被拆分和主题可解释性差的问题。
关 键 词 专利文本;专业术语;功能短语;主题模型;Generalized Pólya urn模型
中图分类号 TP391.1 文献标志码 A
Abstract In the process of topic extraction of patent texts, a large number of semantically rich phrases are segmented, which makes the generated topic difficult to understand. The method of incorporating similarity-constrained phrases into the topic model ignores the differences in phrases in different fields. To solve the problem, according to the characteristics of patent texts, a topic model of fusion domain phrase knowledge is proposed. Technical terms are extracted by serialization annotation model, functional phrases are extracted by parsing method, and domain phrase table is constructed. The domain phrase table is extended by using the method of semantic similarity calculation. The Generalized Pólya urn model is used to enhance the domain-related phrase, alleviate the sparsity brought by the phrase, and improve the quality of the topic. The experimental results on Chinese Patent Texts show that the model effectively solves the problem of domain phrase segmentation and poor interpretability of topics.
Key words patent texts; technical terms; functional phrases; topic model; Generalized Pólya urn model
0 引言
随着时代的快速发展和科学技术的不断革新,专利的数量迅速上升,对专利文本进行分析变得越来越重要。对大规模的专利文本进行分析研究,归纳出专利语料库中所蕴含的语义信息,有助于专利分析人员在海量专利中快速了解某领域的概况。研究者们将LDA(Latent Dirichlet Distribution)主题模型应用在专利文本的研究中。
传统的主题模型是基于“词语袋”的模型,没有考虑单词的顺序,但是在文本挖掘任务中,语序和短语往往是分析文章的关键,短语相比于单个的词更容易让人们理解。最早的基于短语的主题模型是Wallach等[1]提出的BTM模型,它将双语模型和基于主题的方法相结合。Wang等[2]提出的n-grams主题模型扩展了BTM模型,但该方法复杂性过高。El-Kishky[3]和张琴等[4]通过挖掘频繁短语,将同一短语下的单词设定为同一主题,抽取主题短语。孙锐等[5]在二元主题模型的基础上引入了三元组事件作为主题表示的基本单元。主题模型在对文本进行分析时产生的主题不易被程序解释,研究者们将先验知识融入到主题模型中[6-7]。SRC-LDA模型[8]根据语义相似性构建了must-link和connot-link的语义关系图,利用语义关系图对题-词的分配进行约束。AMC算法[9]和LTM算法[10]与人类的终身学习算法相似,从过去的学习中挖掘可靠的先验知识,帮助未来的学习。在此基础上,Xu等[11]提出了潜在嵌入结构的终身学习模型,利用潜在的词嵌入挖掘单词相关知识辅助主题建模。Xu等[12]提出的KTP模型,将短语知识和短语相关知识结合用于短语建模和主题建模。虽然构建基于短语和更高阶语义单元的主题模型在一定程度上提高了主题的可解释性,但是容易造成稀疏性。Fei等[13]将Generalized Pólya urn模型引入到主题模型中,通过Generalized Pólya urn模型将短语和组成短语的内容自然地连接起来,在主题推理过程中提高短语的概率。彭敏等[14]提出了具有文档-主题和词汇-词汇双GPU语义强化的DGPU-LDA模型,利用GPU模型来强化词汇的主题分配采样过程。
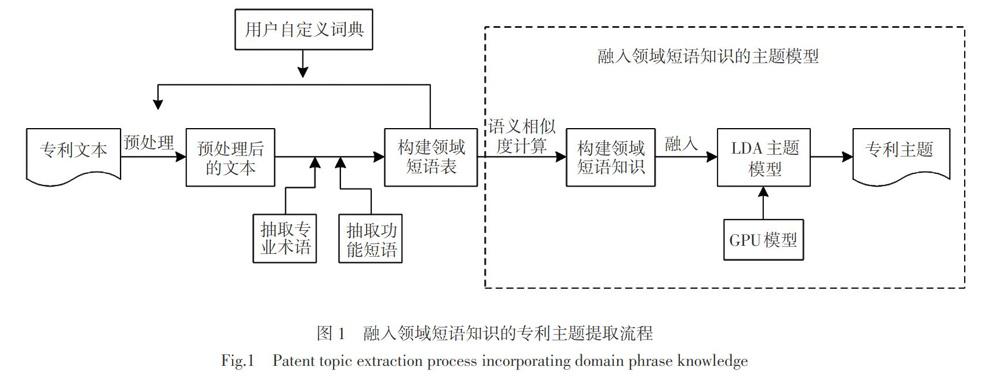
专利文本中隐藏着技术信息,包含大量领域短语,它们是专利文本中的关键组成部分,描述了该领域中最重要的知识。将主题模型应用在专利文本中,领域短语往往被拆分,在对文本建模时产生的主题不易于被理解。将相似性约束的短语融入到主题模型中的方法,忽略了不同领域间短语的区别。因此,本文对专利文本进行分析,针对专利文本所属的领域构建领域短语表,避免领域短语被拆分,然后通过语义相似度计算扩展领域短语表,将其作为先验知识融入到主题模型中,并使用Generalized Pólya urn模型强化领域短语在专利文本中的作用,缓解领域短语带来的稀疏性,最后结合LDA模型提取专利主題。
1.4 模型构建过程
将领域短语知识融入到主题模型中,结合GPU模型可以提高领域短语的概率,还能提高相关短语的概率,有利于解决领域短语在专利文本中的稀疏性问题。模型图如图5所示。
融入领域短语知识的主题模型中符号含义如表1所示。
融入领域短语知识的主题模型生成过程如下:
1)根据[θd~Dirα]生成第[d]篇文本的主题分布[θd];
2)根据[φk~Dirβ]生成主题-词分布[φk];
3)对于第[d]篇文本中的第[i]个短语[Cd,i],当[n=1]时,短语[Cd,i]等同于[wd,i,1]表示为单个的词,在领域短语知识[P]的作用下,增强词或短语的概率。经过词向量训练后,短语向量表示为组成短语的所有词的词向量的累加,如下所示:
在GPU模型作用下用如下两种形式来增强短语的概率:
1)相关短语。一个词被分配给某个主题时,在领域短语知识里查看该词对应有哪些短语,当对这个词进行统计计数时,小比例的增加该单词对应的相关短语的计数。
2)相关的词。当一个短语被分配给某个主题时,在领域短语知识里查看该短语对应的有哪些词和短语,当对这个短语进行统计计数时,小比例的增加该短语对应的词和短语计数。
2 实验
2.1 实验设计
本文研究的对象是中文专利文本,目前没有公开标准的专利文本语料库,所以将专利检索网上下载的新能源汽车领域专利文本2 143篇作为实验数据。为了验证本文提出的方法是有效的,本文将3种主題模型进行比较,第1是在词的基础上构建模型,称为LDA(word)。第2是将整个短语作为单独术语考虑,称为LDA(phrase)。第3是将同义词林作为外部知识,构建知识词库后建模,称为LDA(knowledge)。本文提出的方法称为LDA(domain-phrase)。在所有的实验中,将狄利克雷超参数设置为:[α=50/K],[β=0.1]。
2.2 构建领域短语表的准确性
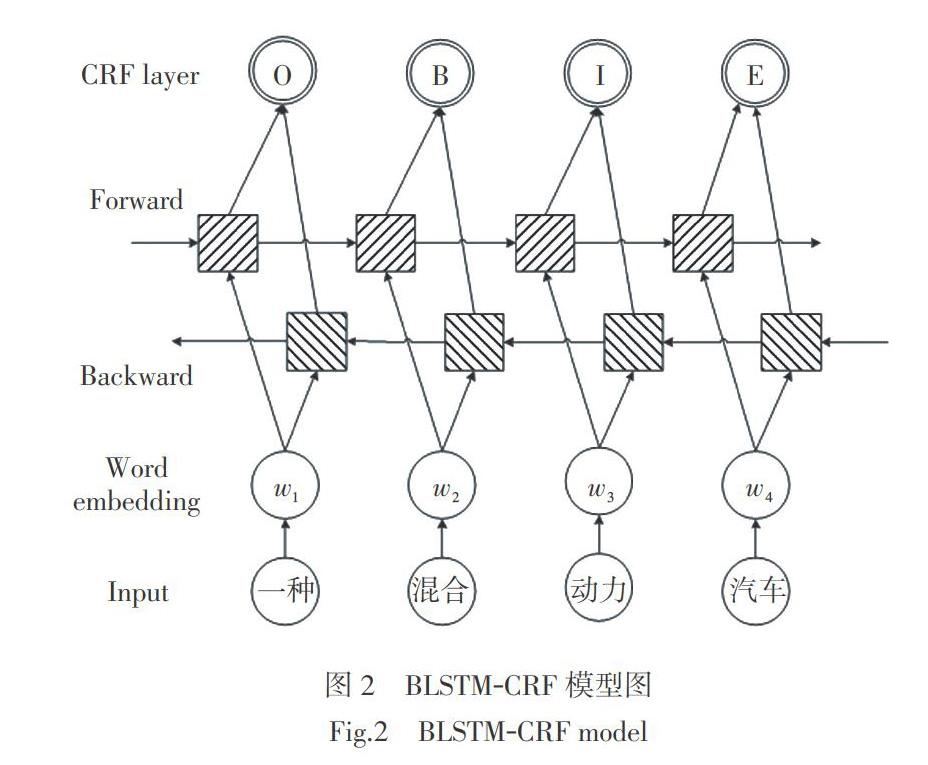
专利文本的专业术语分布在整篇文章中,所以提取专业术语时分析整篇专利。实验标注了新能源汽车领域专利文本1 500篇,643篇作为测试集,结果共获得专业术语18 348个,把它作为jieba分词时自定义词典。对于功能短语的抽取,对2 184篇专利的摘要进行分析,人工标注出含有线索词的单句5 541句,含有功能词对4 028个。
构建的领域短语表的准确性用抽取的领域短语的准确率来表示,准确率[Pw]公式为
[Pw=自动抽取和人工分析相符的短语数量自动抽取的短语数量×100%] 。 (8)
表2是专业术语和功能短语抽取的验结果,表明短语表能够覆盖大部分的领域短语。
2.3 领域短语知识构建结果
根据得到的领域根据得到的领域短语表,使用python的gensim工具包进行词向量训练,选择skip-gram模型,进行词向量训练时主要涉及参数为词向量维度和滑动窗口值。对比不同参数取值对结果产生的影响,结果如图6所示。
2.4 主题提取结果及分析
困惑度是评价主题模型常用的评价标准之一,对于文章[d],提出的模型对[d]属于哪个topic的不确定程度即为困惑度,困惑度越低表示模型越好。计算公式为式中:[Dv]表示包含词项[v]的文档频率;[Dv,v′]表示词项[v]和[v′]同时存在的文档频率;[Vt=vt1,???,vtM]表示主题[t]下的概率最大的[M]个词项。[TCt;Vt]的计算结果为负值,取值范围为[-∞,0],所以越接近0效果越好,即[Dvtm,vtl]和[Dvtl]越接近。
困惑度随主题数[K]的变化曲线如图7所示。由图7可以看出,当K = 20时,该模型的困惑度趋向平稳,表明当K = 20时模型最好。
各个模型的主题一致性对比实验如图8所示。在图中可以看出LDA(word)模型的主题一致性最差。对比LDA(word)模型和LDA(phrase)模型的主题一致性结果,LDA(phrase)模型在一定程度上优LDA(word)模型有所提高,因为LDA(word)模型没有考虑词与词之间的顺序和上下文语义间的关系,导致专利文本中短语被拆分,从而影响了主题的可解释性。对比LDA(knowledge)和LDA(word)模型可以发现,LDA(knowledge)模型的主题一致性高于LDA(word)模型,表明融入外部知识在一定程度上提高了主题的可解释性。总体来看,本文提出的模型LDA(domain-phrase)的主题一致性最高,因为模型考虑了领域短语被拆分的问题,并通过GPU模型解决了短语带来的稀疏性,所以主题一致性明显高于其他模型。
为了更直观地表现本文提出的方法提高了主题的可解释性,对新能源汽车领域的专利文本提取的主题词或短语进行了对比。部分主题下的top10主题词或短语的结果如表4所示。
根据表4看出, LDA(word)模型中,类似于“系统”“装置”“连接”等词语是与主题无关的词,但是由于在文中出现的频率较高,出现在结果中,但实际意义不大。像LDA(knowledge)模型中的 “包”“汽车”“电压”这类词范围太广,在不同的领域会有不同的含义,出现在结果中不易于理解。在LDA(phrase)模型中,虽然提取出来了一些短语,相比于LDA(word)模型更易于人们理解,但由于短语的稀疏性,造成类似于“所述”“连接”等词语概率较大,导致具有主题意义的“充电装置”“动力系统”等短语的作用不明显。本文提出的模型,能够较好的解决这两个问题,比如在主题1的结果中,能够提取出 “动力电池”“电池系统”“驱动电机”等短语,并且这些短语都是新能源汽车领域中的短语,能够较好的突出专利主题。
3 结语
本文考虑到专利中领域短语对专利主题的影响,通过构建领域相关短语表,对传统主题模型进行改进,提出了融入领域短语知识的主题模型,对专利文本进行主题提取。实验结果表明,该模型避免了领域短语被拆分,并且提高了领域短语在文本主题中的作用,提取的专利主题有较好的可解释性。在整个实验过程中,涉及较多的人工标注与分析的过程,下一步将尽量减少人工工作量。并且不同领域专利间的差异还需要进一步探究。
参考文献:
[1] WALLACH,HANNA M. Topic modeling:beyond bag-of-words[J]. Nips Workshop on Bayesian Methods for Natural Language Processing,2006:977-984.
[2] WANG X R,MCCALLUM A,WEI X. Topical N-grams:phrase and topic discovery,with an application to information retrieval[C]//Seventh IEEE International Conference on Data Mining (ICDM 2007). Omaha,NE,USA:IEEE,2007:697-702.
[3] EL-KISHKY A,SONG Y L,WANG C,et al. Scalable topical phrase mining from text corpora[J]. Proceedings of the VLDB Endowment,2014,8(3):305-316.
[4] 張琴,张智雄. 基于PhraseLDA模型的主题短语挖掘方法研究[J]. 图书情报工作,2017,61(8):120-125.
[5] 孙锐,郭晟,姬东鸿. 融入事件知识的主题表示方法[J]. 计算机学报,2017,40(4):791-804.
[6] CHEN Z,MUKHERJEE A,LIU B,et al. Discovering coherent topics using general knowledge[C]// CIKM '13:Proceedings of the 22nd ACM International Conference on Information & Knowledge Management. 2013:209-218.
[7] 马柏樟,颜志军. 基于潜在狄利特雷分布模型的网络评论产品特征抽取方法[J]. 计算机集成制造系统,2014,20(1):96-103.
[8] 彭云,万常选,江腾蛟,等. 基于语义约束LDA的商品特征和情感词提取[J]. 软件学报,2017,28(3):676-693.
[9] CHEN Z Y,LIU B. Mining topics in documents:standing on the shoulders of big data[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining-KDD '14. New York,USA:ACM Press,2014:1116-1125.
[10] CHEN Z Y,LIU B. Topic modeling using topics from many domains,lifelong learning and big data[C]//ICML'14:Proceedings of the 31st International Conference on International Conference on Machine Learning. 2014,32:II-703-II-711.
[11] XU M Y,YANG R X,HARENBERG S,et al. A lifelong learning topic model structured using latent embeddings[C]//2017 IEEE 11th International Conference on Semantic Computing (ICSC). San Diego,CA,USA:IEEE,2017:260-261.
[12] XU M Y,YANG R X,RANSHOUS S,et al. Leveraging external knowledge for phrase-based topic modeling[C]//2017 Conference on Technologies and Applications of Artificial Intelligence(TAAI). Taipei,Taiwan,China:IEEE,2017:29-32.
[13] Fei G,Chen Z,Liu B. Review topic discovery with phrases using the Pólya Urn model[C]//COLING. 2014.
[14] 彭敏,杨绍雄,朱佳晖. 基于双向LSTM语义强化的主题建模[J]. 中文信息学报,2018,32(4):40-49.
[15] 王密平. 汉语专利术语抽取及应用研究[D]. 南京:南京大学,2017.
[16] 费晨杰,刘柏嵩. 基于LDA扩展主题词库的主题爬虫研究[J]. 计算机应用与软件,2018,35(4):49-54.
