3种用水量预测方法在京津冀地区的适用性比较
2021-03-29龙秋波
白 鹏,龙秋波
(1.中国科学院地理科学与资源研究所陆地水循环及地表过程重点实验室,北京 100101;2.湖南省水利水电勘测设计研究总院,湖南 长沙 410007)
用水量预测是水资源规划及管理的重要基础和依据,也是保证供水系统安全运行和科学管理的有效手段[1-3]。用水量预测的方法有很多,根据对数据处理方式的差异,用水量预测通常可分为时间序列法、结构分析法和系统分析法3类[4-6]。时间序列法主要是根据用水量周期性或规律性的变化特征进行统计分析,进而构建预测模型[7-9];结构分析法是通过分析城市用水量与各种相关因素(如人口、产值、粮食产量和气候等)之间的联系,构建用水量和关联因素之间的统计模型,进行用水量预测[10];系统分析法不追究个别因素的作用效果,削弱随机因素的影响,力求体现各因素对用水量规律的综合作用[11-12]。上述3种方法各有优势和不足,目前还无法建立一个确定性模型对区域用水系统的复杂性进行描述。相比于其他两种方法,时间序列法对用水系统外部复杂的影响因素进行简化,不需要对影响用水量的因素进行预测,只考虑历史用水量数据随时间内在变化规律,进而对整个系统的未来状态做出预测[7-9]。该类方法比较符合用水量序列的特点,因而在用水量预测工作中应用较为广泛。常见的时间序列预测法包括年增长率法、移动平均法、人工神经网络法和自回归模型法等[13-14]。多种用水量预测方法的比较研究有助于识别最优的方法,减少预测结果的不确定性。本文拟选择京津冀地区为对象,对3种常用的年用水量时间序列预测方法进行比较,分析3种方法在京津冀地区年用水量预测中的适用性,为促进京津冀地区水资源的高效管理和规划提供科学支持。
1 研究方法及数据来源
1.1 年增长率法
年增长率法是通过分析历史的城市年用水量增长情况,计算出区域年用水增长率,从而根据现状水平年的用水量预测出规划年的用水量。该方法计算简单,但需要收集长系列的历史用水量数据,在一些地区可能存在数据缺失、资料不全等问题[6]。年增长率法假定历史年用水量数据序列符合特定的函数分布(如幂函数),常用的计算公式为
Wt+1=W0(1+R)n
(1)
式中:Wt+1为第t+1年的用水量;W0为现状基准年用水量;R为城市用水量年平均增长率,本文中R的取值通过历史用水量数据进行参数拟合求得;n为间隔年数。
1.2 自回归模型法
当一个变量按时间顺序排列的值之间具有依赖关系或自相关性时,就可以建立该变量的自回归模型,并由此对其发展变化趋势进行预测[15]。需要指出的是自相关性是建立自回归模型的基础,只有具有显著自相关性的时间序列才可以建立自回归模型。城市年用水量变化一般都比较缓慢,轻易不会发生突变,符合自回归模型的构建基础,该方法的优点是所需资料少,可用自身变数数列进行预测。自回归模型的方法有很多,本文选取门限自回归模型进行研究。该模型能有效描述复杂的非线性动态系统,由于门限的控制作用,该模型具有很强的稳健性和适用性,常常被应用于在经济、环境、海洋、气象等领域[16]。门限自回归模型的基本思路是在观测时间序列{Xt}的取值范围内引入n个门限值Tj(j=1,2,…,n),根据延迟步长d将{Xt}按{Xt-d}值的大小分配到不同的门限区域内,再用自回归模型对不同区间内的{Xt}序列进行拟合,从而对时间序列进行非线性动态描述,模型的一般形式[17-18]为
(2)
式中:Tj为门限值;Ztj为第j个相互独立的正态白噪声序列;a0j为第j个门限自回归区间的自回归系数;mj为第j个门限区间自回归模型的阶数。
1.3 灰色神经网络法
区域年用水量变化影响因素众多,系统内部的变化机理复杂且各类影响因素之间相互作用。人工神经网络方法具有自适应性、容错性以及强大的映射能力,能够大规模处理高度非线性复杂问题,能够从大量的历史数据中进行训练,进而找出时间序列内在的变化规律,因此被广泛应用于区域的年用水量预测[19-20]。但是,人工神经网络方法内部参数较多,易陷入局部最优解,灰色预测方法可以很好地解决这些问题。灰色理论是一种研究既包含已知信息又包含未知信息的系统理论与方法,该理论以“小样本”、“离散”、“无规律”的数据为主要研究对象,将杂乱无章的原始数据序列通过一定的处理方法,使之变为比较有规律的时间序列[21-22],能够较好地弱化数据序列的波动性并处理随机扰动因素。但是,灰色预测方法缺乏自学习和自组织能力,尤其是在对复杂的非线性系统进行预测时,因非线性系统的数据随机性变化显著,会产生很大的误差。灰色人工神经网络充分利用了二者之间的差异性和互补性,充分发挥各自的优势[23]。二者结合的方式是利用神经网络对灰色模型GM(1,1)预测结果进行误差修正,从而构建神经网络模型和灰色模型GM(1,1)的串联式组合模型。本研究用到的神经网络模型为BP模型,隐含层个数为10。具体的计算步骤如下:①对时间序列进行归一化处理,建立GM(1,1)模型;②基于GM(1,1)模型进行时间序列的预测;③计算观测数据和预测数据的误差;④将模型预测误差序列作为神经网络模型的输入项,对网络进行训练,确定网络的权重和阈值,得到能够反映预测值和误差关系的网络结构;⑤分别基于GM(1,1) 模型和神经网络模型预测下一时刻(t+1)的预测值及其偏差,二者之和即为t+1时刻的预测值;⑥重复步骤④,得到t+2,t+3,…,t+m时刻的预测值(m是预测年数)。
1.4 研究区概况与数据来源
京津冀一体化是党中央、国务院做出的一项重大国家战略部署,是实现京津冀三地优势互补、促进环渤海经济圈发展、带动北方腹地发展的需要。京津冀地区可持续发展面临的重大问题之一是经济社会发展水平和水资源量不匹配[24]。该地区是中国北方经济规模最大、最具活力的地区,同时,也是我国缺水最严重的地区之一,人均水资源占有量约为全国平均值的1/9[25]。因此,京津冀地区的协调发展需要打破行政区域限制,以京津冀地区为统一体整体进行水资源规划和管理,甄别适用于该地区的年用水量预测方法显得尤为必要。本文的年用水量数据来源于京津冀三地的水资源公报,时间跨度均为1997—2018年(图1)。由图1可知,京津冀三地1997—2018年的用水量变化呈现出明显不同的趋势。北京市和天津市年用水量呈现先减少,而后缓慢增加的趋势,而河北省年用水量呈波动下降趋势。本文设置了不同的模型训练期T(表1),如模型训练年数为10,表示前10年数据用于模型训练,其余年份的数据用于模型的验证。预测结果评估指标为相对偏差,其正值表示模型高估年用水量,负值表示低估年用水量。不同训练期的条件下基于最小二乘法拟合的京津冀年用水量年平均增长率见表1。
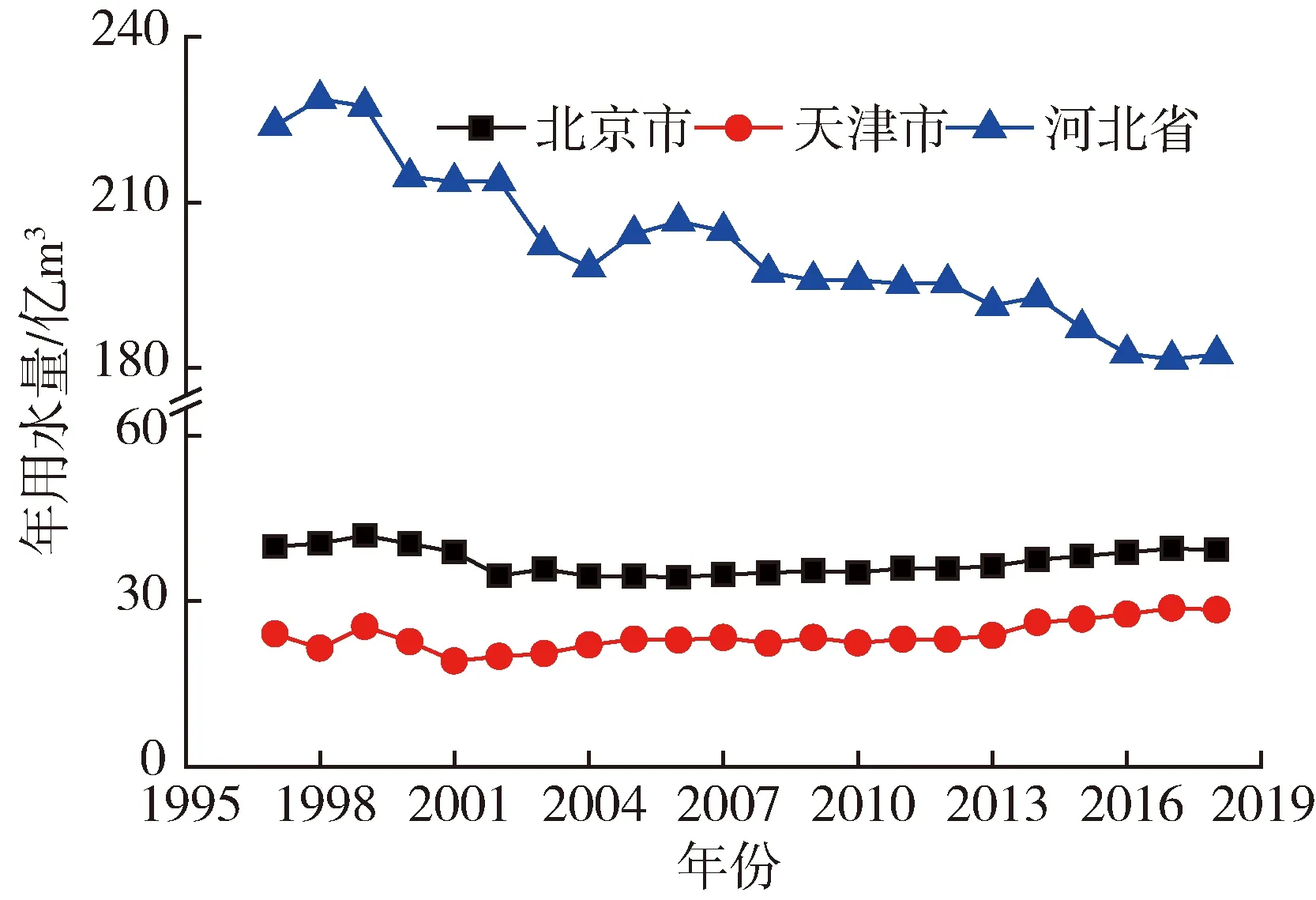
图1 京津冀地区1997—2018年用水量变化

表1 不同训练期下京津冀年用水量平均增长率

表2 不同训练期下各模型年用水量模拟的相对误差

表3 不同训练期条件下各模型验证期年用水量模拟的相对误差
2 结果和讨论
2.1 3种模型的比较
模型训练期和验证期,京津冀三地年用水量模拟的相对误差见表2、表3。由表2可知,模型的误差随训练期的增加而减少。以北京市为例,训练期由10 a增加到18 a时,年增长率法的相对误差由 -1.2%变为0.6%,自回归模型法的相对误差由3.4%减少到0.9%,灰色神经网络法的相对误差变化最大,由-6.4%变为1.7%。在模型训练期,年增长率方法在北京市明显优于其他两种方法,但在模型验证期,年增长率方法表现最差,可见训练期的模型模拟结果并不能反映模型真实的预测能力。因此,本文基于验证期的结果来评判3种模型的年用水量预测能力。由表3可见,3种模型的预测能力表现出明显的区域分异性。在北京市和天津市,灰色神经网络法表现最好,自回归模型法次之,而年增长率法表现最差。以18 a训练期模型的预测结果为例,北京市3种模型(灰色神经网络法、自回归模型法、年增长率法)预测结果的相对误差分别为 -2.2%、-4.7%和-14.9%;在天津市,3种模型预测结果的相对误差分别是-3.1%,-11.6%和-20.4%;在河北省,3种方法的预测误差要明显小于北京市和天津市。比较而言,灰色神经网络法略优于年增长率法,二者均优于自回归模型法。
图2为训练期为18 a(1997—2014年)条件下,京津冀三地年用水量验证结果。由图2可见,年增长率法模拟和预测的年用水量近乎一条直线,这与真实的年用水量数据变化不一致,实际的年用水量序列通常呈明显的年际波动。究其原因,可能是因为年增长率法采用单一的函数分布,很难有效地模拟年用水量的波动变化。自回归模型法的预测误差较大,而且与实际年用水量的变化趋势不一致。灰色神经网络法不仅预测误差较小且能够很好模拟年用水量的年际波动,在年用水量呈非线性变化的地区优势明显。灰色神经网络方法优于其他两种方法的原因可能在于其强大的非线性映射能力,使模型能够快速捕获时间序列中隐藏的趋势信息,并建立稳健的模型结构来进行趋势的预测。因此,灰色神经网络法在京津冀三地年用水量预测中表现最好,建议将其作为该地区年用水量预测的优选方法。

(a) 北京市
2.2 京津冀年用水量预测
利用灰色神经网络法,对京津冀三地2019—2025年用水量进行预测。模型训练数据均为1997—2018年的实际年用水量数据。模型预测结果见图3,可见2019年后北京市年用水量总量趋于平稳,将维持2018年的用水规模,年际波动很小,平均变化速率为0.06亿m3/a,2025年的用水量预测值为39.7亿m3。天津市的用水量仍维持增加趋势,但增速明显放缓,平均速率为0.17亿m3/a,2025年的用水量预测值为29.6亿m3。河北省的用水量则仍维持下降态势,平均的下降速率为-0.80亿m3/a,2025年的用水量预测值为176.8亿m3。

图3 京津冀2019—2025年年用水量预测结果
时间序列预测模型的预测结果往往具有一定的不确定性,这是由时间序列预测模型的计算原理决定的。时间序列预测法的基本原理是承认事物发展的延续性,通过对过去的时间序列进行统计分析,推求出事物发展的趋势,并采用数学方法消除时间序列中的随机干扰,从而进行预测。基于时间序列的预测模型依赖于事件发生的先后顺序,同样大小的值改变顺序后输入模型产生的结果是不同的。如果未来有不可预测的突发事件(如大尺度、持续性的干旱),预测结果也会出现很大误差,即如果各地实施有别于以往的产业结构调整、农业和生活节水措施,年用水量预测的结果可能有较大误差。即便如此,它仍然是一种简便且有效的年用水量预测方法。
3 结 论
a. 京津冀三地1997—2018年的年用水量呈现出不同的变化趋势,北京和天津地区的年用水量呈先减后增的非线性变化,而河北省年用水量呈波动递减的趋势。
b. 年增长率法、自回归模型法和灰色神经网络法3种年用水量预测模型的比较结果表明,灰色神经网络方法在京津冀三地表现性最好,可推荐为该地区年用水量预测的首选方法。
c. 基于灰色神经网络方法的京津冀三地年用水量预测结果表明:2019—2025年,北京市年用水量将保持平稳,年际变化不大;天津市的年用水量将缓慢增长;河北省的年用水量将继续下降。
