基于云遗传BP神经网络的黄淮海旱作区土壤有机质预测精度分析
2021-03-23徐清风于茹月勾宇轩赵云泽黄元仿
徐清风 于茹月 勾宇轩 赵云泽 李 勇 黄元仿*
(1.中国农业大学 土地科学与技术学院,北京 100193;2.自然资源部农用地质量与监控重点实验室,北京 100135;3.农业农村部华北耕地保育重点实验室,北京 100193)
土壤有机质是指进入土壤中的各种有机物质,包括来源于动植物、微生物分解残体和以及人类活动产生的还田秸秆等[1]。其作为陆地生态系统中碳循环的重要源和汇,是土壤的重要组成部分之一,影响土壤的肥力与生产力,并能够抑制土壤中重金属污染物的活性[2]。土壤受人类活动影响愈来愈频繁,其有机质成分和结构易受到农业生产活动和土地利用变化等因素的影响,具有高度的空间异质性[3-4]。因而探索不同土层土壤有机质空间变异规律,对农业生产管理及生态环境保护均具有重要意义。Campbell等[5]于1978年首先将地统计学方法应用于土壤特性空间变异研究中之后,Burgess等[6]、Webster等[7]运用普通克里金插值等地统计学方法对土壤各类属性值的空间变异进行了大量研究,推动了土壤属性空间变异研究的进展。虽然克里金插值在土壤属性的预测上得到了广泛的应用,但由于克里金插值的平滑效应与不同土层土壤属性值的复杂多变相悖,因此使用普通克里金插值研究不同土层土壤空间变异性质的准确性并不理想。后BP神经网络逐渐被应用于土壤属性空间变异研究,其结果与普通克里金插值结果相比,预测的准确性得到了一定提高[8-10]。BP神经网络采用沿梯度下降的算法,也存在着对初始权值敏感、易陷入局部极小等问题[11],在此基础上,一些研究运用遗传算法优化BP神经网络的权值计算过程[12],原因是遗传算法训练神经网络对其初始权值不敏感,因而非常适用于神经网络参数优化,然而,其交叉与变异概率随机生成,易破坏优良个体结构、限制弱势个体进化速度,故仍存在精度不高的问题[13]。
黄淮海平原作为我国重要的粮食生产基地,年粮食总产量为近2亿t,提高土壤有机质预测精度对评估其未来生产潜力具有重要意义。本研究拟以黄淮海旱作区为研究对象,利用云模型云滴的随机性和稳定倾向性的特点[14],将云模型与遗传算法相结合,采用云发生器优化遗传算法中的交叉、变异操作构建基于云遗传模型的BP神经网络,探究基于云遗传BP神经网络、BP神经网络和GABP神经网络3 种方法对不同土层的土壤有机质预测能力,对比得出具有较高预测精度的方法,为调整耕地管理措施及提高土壤质量水平等方面提供依据。
1 材料与方法
1.1 研究区概况
黄淮海旱作区的界定以地形坡度<5°,1 km2网格内旱地占耕地比>40%作为划分依据,共包括北京、天津、河南、山东、河北与安徽6 个省市的274个区县,面积总计28.12万km2。黄淮海旱作区属大陆性温带季风气候,年均温度14~16 ℃年降雨量在400~1 100 mm,主要降水时间多集中在夏季,主要土壤类型为潮土、棕壤及褐土等。
1.2 数据采集及处理
采样布点的方案设计采用网格布点与分层抽样相结合,抽样时综合考虑面积大小和集中程度,每种主要土类至少布设20 个采样点,每个亚类尽量布设有采样点,尽量保证每个黏粒等别上均有采样点,每个区县尽量保证有1 个采样点。根据上述布设和抽样规则,共确定265 个采样点。采样时间为2017年(不同区县采样时间上略有差异),利用GPS定位在半径5 m范围内采集3~5 点不同土层(0~40 cm)土样混合,四分法取1.0~1.5 kg土样进行分析,采用重铬酸钾外加热法计算样点土壤有机质的值。
为了检验神经网络对土壤有机质的预测精度,将265 个采样点随机划分,随机将其中80%作为训练样点、20%为验证点[15],使得训练样本与测试样本空间分布均匀(图1)。
1.3 研究方法
1.3.1云模型
云模型是由李德毅院士在模糊数学和概率论两者的基础之上,通过特定的结构算法所形成的定性概念与其定量表示之间的转换模型[16]。主要反映了客观事物中概念的模糊性和随机性,为定性与定量相结合的信息处理提供了有力手段[17]。
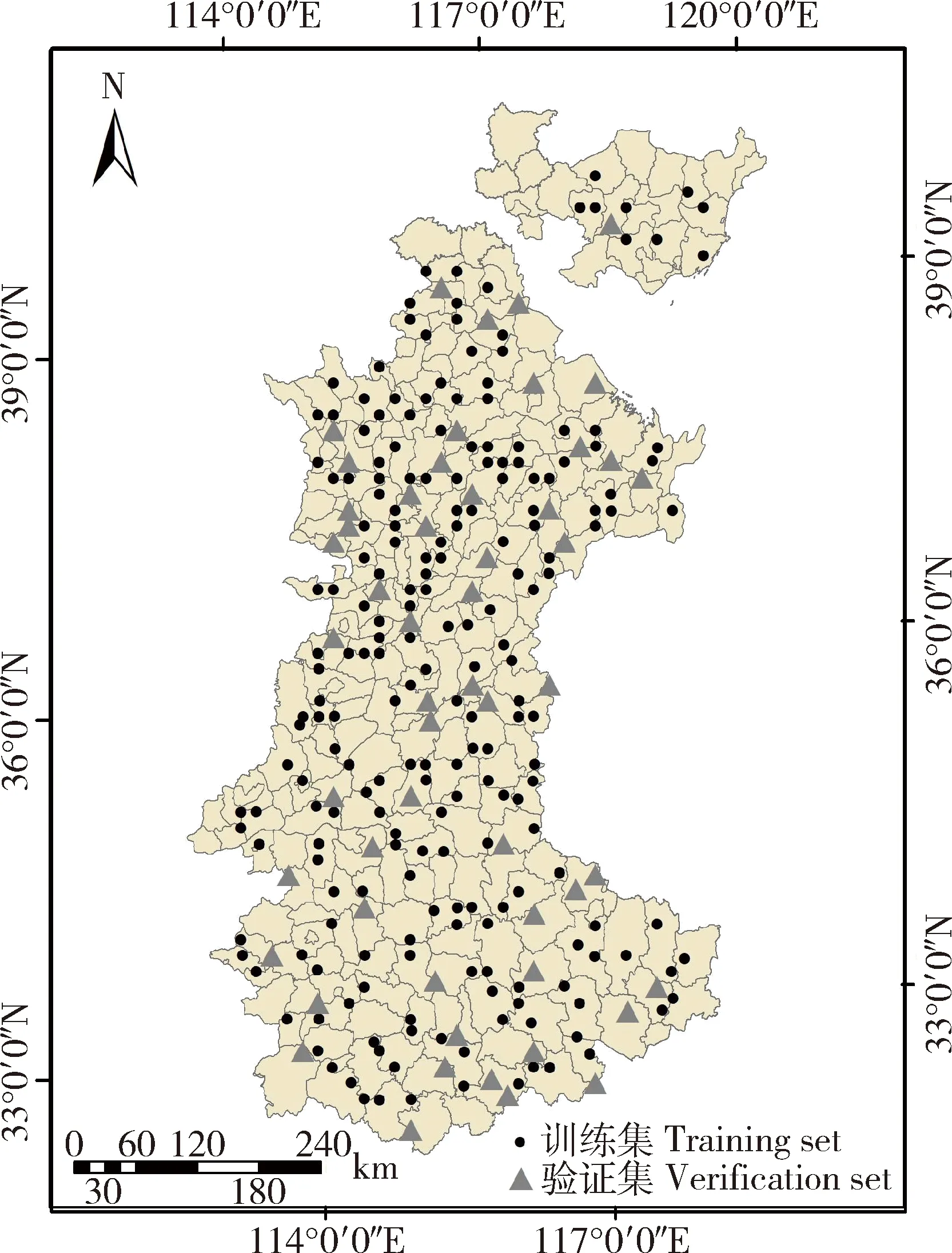
图1 研究区训练样点和检验样点分布图Fig.1 Distribution of training samples and test samples in the study area
1.3.2基于云遗传BP神经网络的构建
基于BP神经网络的土壤有机质空间预测以空间自相关理论为基础,根据已知采样点对曲面进行拟合,所求的函数表达式为:
z=f(x,y,A1,A2,…,An)
(1)
式中:z为预测样点的土壤有机质质量分数;x与y分别为预测样点的经度与纬度;A1,A2,…,An依次为距预测样点距离最近的土壤样点所测得的土壤有机质质量分数;参考已有研究经验[26],选取n的数值为5。
基于云模型与遗传算法优化的BP神经网络法首先采用标准BP神经网络试探得到最佳的隐层结点数,沿用传统遗传算法的初始化种群、选择操作,后基于正态云模型X条件云生成算法实现对遗传算法中交叉与变异方法的优化,经过不断迭代选择生成最优个体。根据得到的最优个体对BP神经网络的权值和阈值进行赋值,从而得到具备全局最优解的BP神经网络预测值。
1)随机产生一个初始群体,编码方法采用实数编码,每个个体的基因位编码长度由输入层神经元、隐藏层神经元与输出层神经元个数决定,其中的每一个实数均视为1 个基因位。
2)分别将每个个体作为BP神经网络的初始权值与阈值,使用训练数据训练BP神经网络得到预测输出值,根据预测输出值与实际值间的误差平方和的倒数作为适应度函数,个体适应度F计算公式如下:
(2)
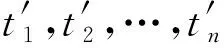
3)选择操作采用轮盘赌方式进行,每个个体被选择遗传至下一代的几率与其自身的适应度大小成正比,每一代中染色体的总数保持不变。
4)相较于原始的不同个体随机交叉,云模型优化后的交叉概率pc由2 个个体间的最大适应度所决定,其计算公式为

(3)
式中:f1、f2分别为2 个个体的适应度值;f为每代个体中的平均适应度值;fmax为每代个体的最大适应度值,En与He分别为每代个体的熵与超熵;En′为以En为期望;He为标准差的正态随机数;c1为控制云陡峭程度的常数,根据“3En”原则,通常取值为3,c2为控制云层厚度的常数,通常取值为10[11]。k1、k2可取0~1的常数,实验过程中可根据具体情况调节参数的值,从而避免高适应度个体的基因因交叉操作丢失、增加低适应度个体的交叉几率以改善神经网络的预测精度。执行交叉操作时,双方个体随机选择一段相同长度的染色体互换。
5)变异操作与交叉操作同理,变异概率由2 个个体间的最大适应度所决定,计算方法与交叉概率算法相同。执行变异操作时,每个个体随机改变1个基因位。
上述过程均在Matlab2018中借助其神经网络工具箱实现。
1.3.3预测精度评价
通过比较土壤有机质预测值与实际值的平均绝对误差(MAE)和均方根误差(RMSE)来进行预测精度评价。其中平均绝对误差反映估计值的实测误差范围,均方根误差主要反映预测值的极值效应,其计算公式为
(4)
(5)
式中:yi为样点土壤有机质实测值;xi为对应样点土壤有机质的预测值;n为参加检验的土壤样本点总数。
2 结果与分析
2.1 不同土层土壤有机质描述统计结果
运用Excel软件进行研究区265个采样点不同土层土壤有机质描述性统计分析,结果表明:研究区0~10 cm土层土壤有机质的变幅最大,变幅在4.96~38.95 g/kg;研究区不同土层土壤有机质含量的平均值随着土壤深度增加而降低,0~10、10~20、20~30、30~40 cm土层土壤有机质平均值分别为20.38、14.73、9.93、8.01 g/kg;数据分布方面,各土层土壤有机质含量偏度与峰度均大于0,数据分布与正态分布相比存在着不同程度的向右偏移,研究区不同土层土壤有机质的变异系数在32.20%~43.18%,均属于中等程度变异[27](表1)。
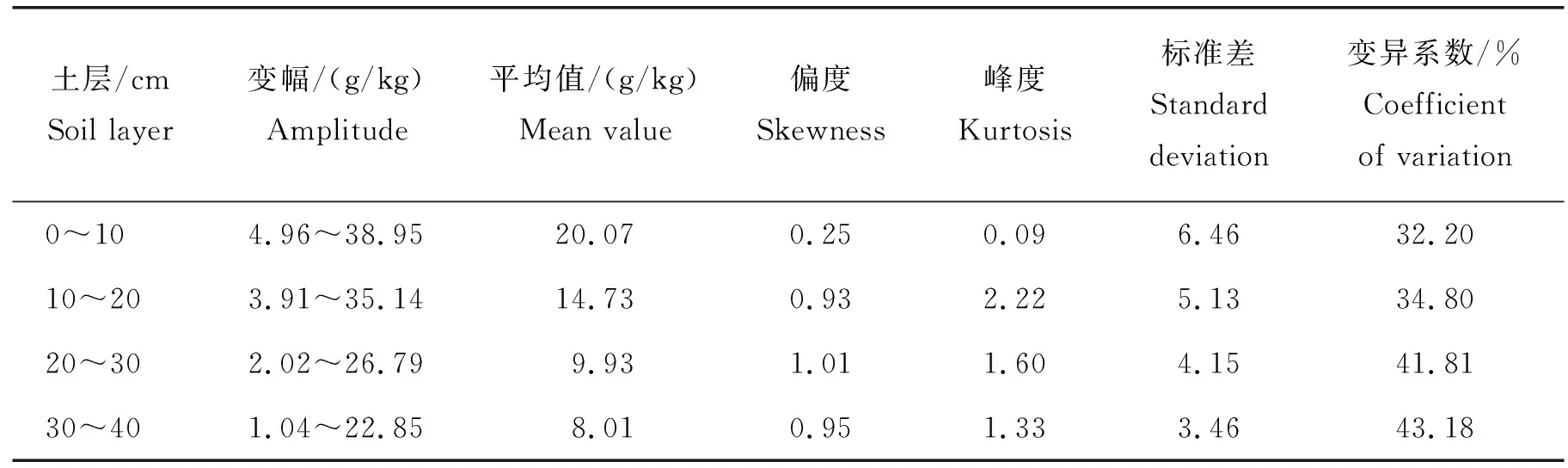
表1 黄淮海旱作区不同土层土壤有机质描述统计Table 1 Description of soil organic matter in different soil layers in Huang-Huai-Hai dry farming area
2.2 不同土层土壤有机质地统计学参数分析
运用GS+7.0软件对研究区不同土层土壤有机质地统计学参数分析,以决定系数接近于1、残差趋向于0为最佳标准选择,不同土层土壤有机质的最优理论模型均为指数模型,结果见表2。由表2可见:不同土层土壤有机质指数模型的决定系数在0.79~0.93,表明模型拟合均具有较高的合理性[28];不同土层土壤有机质均具有较高的块金值与基台值,表明研究区不同土层土壤有机质存在着一定程度的空间变异,不同土层土壤有机质块基比的值在46.96%~51.19%,则进一步说明结构因素(如土壤母质等)与随机因素(如土壤耕作培肥等人为措施)的影响程度对空间变异的影响基本一致[29]。不同土层土壤有机质变程值在1.17~9.56 m,变程较低,表明其空间自相关性较弱[30]。
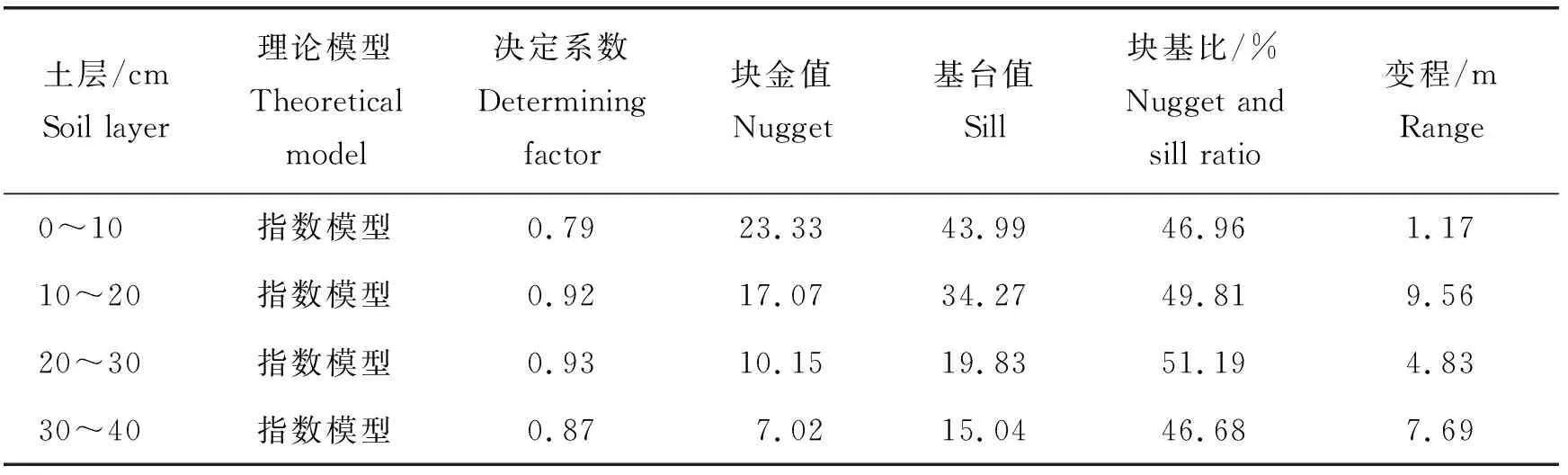
表2 研究黄淮海旱作区不同土层土壤有机质地统计学参数Table 2 Results of soil organic matter statistical parameters in different soillayersin Huang-Huai-Hai dry farming area
2.3 基于云遗传-BP神经网络与其他BP神经网络预测能力对比
首先将BP神经网络调至最佳参数,后分别使用云遗传模型BP神经网络、普通BP神经网络和遗传优化的GABP神经网络3 种方法对研究区土壤有机质含量分别进行30 次预测,对各方法的土壤有机质预测值与实际值的平均绝对误差(MAE)与均方根误差(RMSE)进行方差分析,结果见表3。
结果表明:云模型与遗传算法结合的BP神经网络对变异系数最小的0~10 cm土层土壤有机质的预测优化效果最为明显,其预测结果的平均绝对误差与均方根误差与其余二者相比均有显著下降(P<0.05),具有最高的预测精度。BP神经网络的平均绝对误差与均方根误差值均为最大,预测精度相对较低;结合遗传算法的BP神经网络的平均绝对误差与均方根误差值相对BP神经网络有所降低,未与BP神经网络的各项预测误差值相比未有显著下降(P>0.05)。云模型与遗传算法结合的BP神经网络对10~20 cm土层与20~30 cm 土层的土壤有机质预测优化效果次之,其预测结果的均方根误差与BP神经网络相比显著下降(P<0.05),但与结合遗传算法的BP神经网络相比各项计算误差未有显著下降(P>0.05)。而在变异系数最大的30~40 cm土层土壤有机质预测方面,云模型与遗传算法结合的BP神经网络预测结果的平均绝对误差与均方根误差与其余二者相比均未有显著下降(P>0.05),未有显著的优化效果。
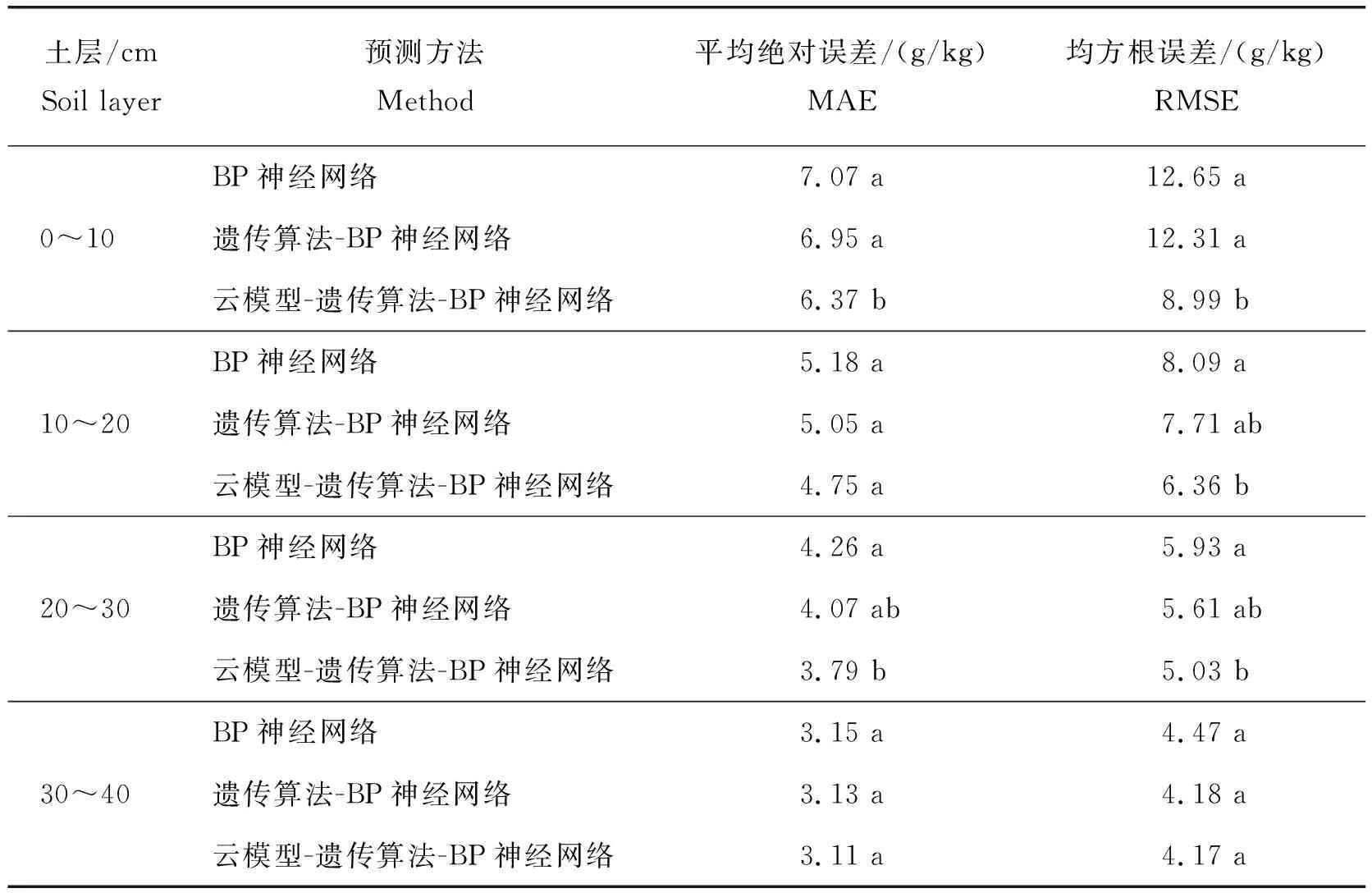
表3 基于云遗传-BP神经网络与其他BP神经网络预测能力对比Table 3 Comparison of forecasting ability between cloud genetic-BP neuralnetwork and other BP neural networks
3 讨论与结论
相较于传统遗传算法中交叉概率与变异概率随机生成,由X条件云发生器生成的自适应交叉概率和变异概率,能够一定程度上避免适应度大的个体结构遭到破坏,同时加快适应度较低的个体的进化速度,从而拥有更佳的预测能力,这与吴立锋、张琛等人的预测结果相一致[13,31]。
在土壤有机质的预测研究方面,未来综合考虑成土母质、土地利用类型等影响不同土层土壤有机质值的非定量环境因子及其他辅助变量因子将会成为提高神经网络预测精度的重要突破口;而在云模型与遗传算法对神经网络的性能优化方面,可以从数据的变异系数、数据分布方式等方面进一步探讨其适用范围,从而为进一步提高神经网络的预测精度提供思路。
本研究运用云模型结合遗传算法对BP神经网络进行优化,以黄淮海旱作区为例,探究黄淮海旱作区不同土层土壤有机质分布状况,并分析结合云模型与遗传算法的BP神经网络对黄淮海旱作区不同土层土壤有机质分布的能力,结论如下:
1)研究区不同土层土壤有机质值的数据分布与正态分布相比具有不同程度的向右偏移,顶峰较为陡峭、两尾分布更广,均属于中等程度变异。
2)研究区不同土层土壤有机质的半方差函数最优拟合模型均为指数模型,研究区不同土层土壤有机质的结构因素与随机因素对空间变异的影响大小基本一致,空间分布趋向于破碎。
3)结合云模型与遗传算法的BP神经网络对0~10、10~20、20~30 cm土层土壤有机质的预测精度均得到了一定提升,而对30~40 cm土层土壤有机质的预测精度没有明显的提升,这可能是由于30~40 cm土层土壤有机质变异系数超过了一定范围造成的。
