基于对抗补丁的交通标牌攻击*
2021-03-20葛万成
叶 斌,葛万成
(同济大学,上海 200092)
0 引言
深度神经网络在许多计算机视觉任务中取得了很好的性能,有时候其表现超过了人类[1-3]。基于这些良好的表现,深度神经网络开始越来越多地应用于自动驾驶[4-5]、无人机[6-7]以及机器人[8]等控制系统,其中自动驾驶技术的日趋成熟引起了研究人员的广泛关注。深度神经网络具有强大的特征提取能力,在图像分类和识别中能够达到很好的精度。自动驾驶的环境感知系统依赖于激光雷达技术、图像识别以及目标检测等前沿技术,其中基于深度神经网络的交通标牌识别是自动驾驶的重要技术之一。
虽然深度神经网络在图像识别上有着极好的性能,但最新的研究表明,深度神经网络在很大程度上容易受到对抗样本的攻击。这些对抗样本是攻击者精心选择的输入,会导致网络改变输出,且这些经过攻击者精心设计的对抗样本通过人眼是无法区分的[9-10]。攻击者可以通过使用一些优化策略只需对图像少量像素进行修改,即可得到所需要的对抗样本。通常的优化策略有L-BFGS[9]、FGSM[10]、DeepFool[11]以及PGD[12]等。其他攻击方法如基于Jacobian 的显著性映射[13]的攻击方法是寻找图像中需要修改的像素,以达到图像中所需要修改的像素最少。有些对抗样本已经被证实可通过物理打印机打印出来并在现实世界中起作用。Kurakin 等人[14]证明了对抗样本在打印之后,即使在不同的光线和方位情况下仍然能够误导模型的输出。Sharif 等人[15]研制出了一幅带有对抗扰动的“眼镜”,戴上这副眼镜可以躲过人脸识别系统或者将佩戴者识别成另一个人。
从先前的研究可以看出,对抗样本在数字领域是有着较强的攻击性。但是,在现实的物理世界中,对抗样本比较脆弱,主要存在于物理场景,面对一些挑战。例如:现实生活中的物理场景的背景是多变的,攻击者无法通过控制背景来攻击;在不同的光线、距离和角度的作用下,对抗扰动会失效;扰动太小无法使图像传感器进行捕捉。
自动驾驶的图像识别系统是保证自动驾驶安全性和可靠性的关键一环。当攻击者意图在真实的交通标志牌上添加扰动时,若成功攻击图像识别系统,将会造成巨大的安全隐患甚至灾难。针对对抗样本的物理挑战和对抗样本在自动驾驶领域中的应用,本文采用一种添加对抗补丁的方法来实现对交通标志识别模型的攻击。该方法属于白盒攻击,在熟知网络模型的结构参数时生成特定的补丁加入交通标牌的周围,使得识别器对原本的交通标志做出错误分类。
本文主要贡献如下:
(1)将对抗补丁的方法应用到交通识别牌识别系统上;
(2)对抗补丁的设计采用随机位置随机旋转的方式,使得生成的补丁不局限于图像的某个位置,忽略了背景的干扰;
(3)通过实验验证对抗补丁的方法在GTSRBVGG16 的效果,为后续的研究者提供参考。
本文第1 节主要介绍对抗补丁的方法,主要包括使用的数据集、GTSRB-VGG16 模型和对抗补丁生成的原理。第2 节主要是实验的设计和分析,验证了补丁方法在GTSRB-VGG16 的效果。第3 节对本文做出总结,分析对抗补丁方法在自动驾驶上应用的意义,并对未来的工作和挑战进行展望。
1 方 法
1.1 数据集GTSRB 介绍
The German Traffic Sign Benchmark(GTSRB)德国交通标志基准是2011 年国际神经网络联合会议(International Joint Conference on Neural,Networks,IJCNN)举办的多级单图像分类挑战。该数据集中包含43 个交通标志类,训练集中包含超过30 000多张图片,测试集中超过10 000 多张图片。图1 为部分数据集展示。数据集中包括的各类图片考虑了距离、光照以及模糊度等因素,第一行从左到右依次是限速20、限速30、限速70、限速60、直行左转,第二行从左到右依次是STOP、禁止通行、左转、直行和限速50。

图1 GTSRB 部分数据集展示
1.2 GTSRB-VGG16 模型
本文采用的是GTSRB-VGG16 模型。GTSRBVGG16 模型与原始的VGG16 模型的主要区别在于在每一层卷积层后加入了BN 层来加快模型的训练和防止模型训练过拟合,且最后一层全连接层为1×1×1 000 的修改为1×1×43,以契合GTSRB 的数据训练。GTSRB-VGG16 模型结构如图2 所示。将GTSRB 数据集的图像使用修改过的VGG16 模型进行训练得到干净的分类器,图像输入的尺寸为256×256×3,经过200 epoch 的训练GTSRBVGG16 在GTSRB 测试集上的准确率达到98.01%。GTSRB-VGG16 各层网络参数如表1 所示。
1.3 对抗补丁方法原理
产生对抗样本的传统策略:给定一些网络分类模型F(y/x),输入x∈Rn,某些攻击者需要攻击的目标类别y´和扰动ε,根据限定的扰动找到一个合适的输入x´使得F(y´/x´)最大化,并对扰动加以约束||x-x´||∞≤ε。在得出F(y/x)结果的过程中,能够访问模型的攻击者通过反向传播执行梯度下降的扰动,经过多次迭代找到合适的输入x´。这种方法可以产生很好的对抗样本,但是需要在原图像上进行修改。一般的攻击都是在整个图像上进行像素的修改,而且大多数交通标牌的攻击只集中在标牌上,如图3 所示。但是,在现实生活中放置的位置不是仅在交通标牌上,在交通标牌的周围也可能出现攻击者放置的补丁。

图2 GTSRB-VGG16 结构

表1 GTSRB-VGG16 各层参数
本文采用的是由TOM B 等人[16]提出的在现实世界中创建通用的、目标性的对抗图像补丁方法。经过实验证明了该方法在ImageNet 上确实有效,在添加占原图比20%大小的补丁后,在被测的数据集上能达到超过80%的攻击成功率。该方法通过设计一个掩膜使得生成的补丁具有任意的形状,在本文中只采用了方形掩膜。将掩膜提取的补丁加到原图像上训练各种图像,在训练过程中每个图像中的补丁加入随机位置随机旋转。TOM B 等人采用梯度下降进行优化,本文采用的是PGD[12]梯度下降方法进行优化。该方法的主要原理:对于一张给定的图像x∈Rw×h×c、补丁块p和补丁变换T(本文使用旋转、随机位置),定义补丁应用公式为M(p,x,T)。在向图像添加补丁之前,先将变换T应用到补丁上,对补丁进行随机的旋转和随机位置的确定,然后将补丁添加到图像上。

图3 交通标牌的攻击举例
为了获得训练有素的补丁,对补丁进行训练来得到攻击效果最佳的补丁,优化目标函数为:
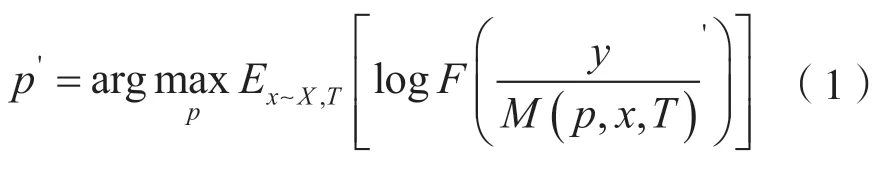
式中,X是图像的训练集,T是补丁变换的分布,有随机旋转、随机位置等多种情况。这样可以使得在训练过程中网络模型只关注于补丁,从而可以忽视补丁的背景和位置,得到可以忽视图像背景和补丁自身位置的补丁,从而达到扰动的通用性(因为它适用于任何背景)。在有些情况下,图像中包含了多个目标,但是分类器得出的结果只有一个目标标签,那么这个目标被认为是真实的。在分类器看来,这张图片对象只有这一个目标,并关注到此目标。因此,在加入补丁之后,补丁必须要学会让自己在网络分类中“突出”,让分类器关注到自己。本文中期望将限速80 补丁分类为限速80。
2 实验与分析
2.1 实验平台与实验数据集
采用的实验平台:Ubuntu18.04.5 LTS(操作系统),32 GB(CPU),GeForce RTX 3090 24 GB(GPU),Python3.6,Pytorch1.6.0(深度学习框架)。
在训练分类器时,采用的数据集是GTSRB 数据集,其中包含训练集39 209 张和测试集12 587 张。训练对抗补丁所采用的训练数据集是从GTSRB 训练集中每一类随机抽取20 张,去掉要攻击成的类,训练集共包含42 个类,共840 张图片。测试对抗补丁的测试数据集是从GTSRB 测试集中每一类随机抽取10 张,去除要攻击成的类,测试集共有420张图片。实验的数据集分布主要见表2。
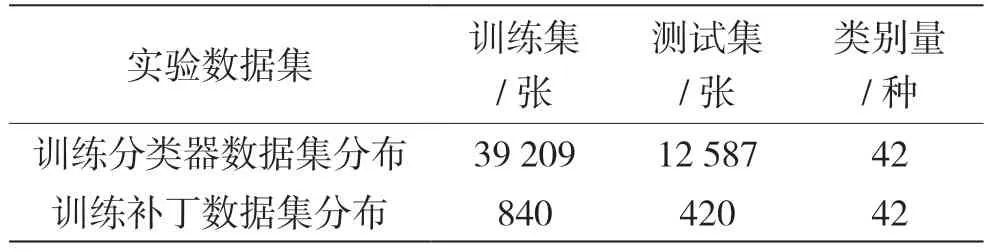
表2 实验的数据集分布
2.2 算法伪代码
对抗补丁算法伪代码说明如下。
输入:一张未加补丁的干净图片x,要攻击成的类target,当前迭代次数i,最大迭代次数c,攻击目标置信度conf
输出:具有攻击效果的对抗样本x´

2.3 实验结果分析
为了测试对抗补丁在GTSRB 上的攻击效果,本文做了被攻击模型泛化性测试实验、单个模型的白盒攻击实验和多个模型集成的白盒攻击实验。泛化性测试实验,一方面为了测试GTSRB-VGG16模型的泛化能力,另一方面是想与对抗补丁实验形成对比。单个模型的攻击实验主要采用GTSRBVGG16 来训练补丁。多个模型集成的白盒攻击实验主要是在原先单个白盒攻击的基础上加入GoogleNet和ResNet34 两个网络来联合训练,然后评估补丁在GTSRB-VGG16 的攻击效率。在训练和测试阶段,补丁会重新随机旋转和随机放置位置。
2.3.1 GTSRB-VGG16 泛化性测试实验
泛化性是指深度学习算法对新鲜样本的适应能力。神经网络通过在原有的数据集上训练学习到隐藏在数据背后的规律,对具有同一规律的数据集以外的数据,经过训练好的分类器也能得到正确的输出。
由于本文主要的目标攻击类是限速80,为了测试生成的补丁的聚焦效果,采用限速80 的交通标牌作为补丁加入图片,同时将限速80 的交通标牌进行尺寸占比的调整。本节主要采用的占图比(限速80 占原图比例)为5%、10%、20%和50%,由限速80 作为补丁加入到原图上的某一个位置作为输入数据集。衡量标准为ARSl80和UARSl80。其中,ARSl80是将该输入数据集识别成限速80 的成功率,类似于有目标的攻击成功率;UARSl80是指加入限速80 后分类器未能识别出原样本的成功率,类似于攻击中的无目标攻击。测试的数据集是2.1 节中介绍的训练和测试补丁的训练集和测试集。加入限速80 标牌后部分数据集如图4 所示。

图4 将限速80 标牌作为补丁加入原图
实验效果如表3 和表4 所示。根据表3 可以看出,直接加入限速80 的标牌不能够实现有效的带目的性的攻击。在占图比达到20%时,在训练集上识别成限速80 的只有2.74%。但是,从表4 可以看出,当占图比为20%时,在训练集上误分类率达到了35.48%,说明在添加未经训练占图比20%的限速80 补丁后,虽然不能达到目标性攻击,但能在一定程度上威胁到分类的准确度。由于加入的限速80 的标牌未经过分类训练,因此猜测这与GTSRBVGG16 的泛化性能相关。

表3 不同图占比下ARSl80结果

表4 不同图占比下UARSl80结果
2.3.2 单个模型的白盒攻击实验
本节主要使用2.1 节中介绍的训练补丁的数据集在GTSRB-VGG16 上训练补丁并进行测试。原图数据格式大小为256×256×3,训练的补丁占原图比率为5%~50%。图5 为部分生成补丁展示。
根据图6,在使用单个模型进行补丁训练时,通过训练生成的补丁在训练集和测试集上测试的效果并不是非常理想。在补丁的占图比达到20%时,在训练集上攻击的成功率是11.7%,在测试集的攻击成功率是14.3%;在补丁的占图比达到30%时,训练集上的攻击的成功率达到是43.56%,在测试集上的攻击成率是45.12%。随着补丁的尺寸变大,攻击的成功率逐渐上升,当补丁的占图比为40%时,攻击成功率已经超过80%,说明对抗补丁的方法在GTSRB 上有一定的效果。

图5 不同占图比的补丁展示

图6 不同占图比的补丁在训练集和测试的攻击成功率
2.3.3 多个模型集成的白盒攻击实验
根据2.3.2 章节给出的结果,单个模型训练的出来的补丁在GTSRB-VGG16上的攻击效果还有欠缺。因此,本节设计使用GTSRB-VGG16、GoogleNet 和ResNet34 这3 个模型联合训练补丁,验证由多个模型集成训练的补丁的攻击效果。图7 是由3 个模型训练得出的补丁在GTSRB-VGG16 模型上训练集和测试集的攻击成功率。图8 是由3 个模型联合训练得出的不同尺寸的补丁,可见由3 个模型联合训练的占图比为20%的补丁在GTSRB-VGG16 的训练集上的攻击成功率ASR20%l80(train)=18.69%,相比于单个模型训练出来的补丁的ASR20%l80(train)提高了6.99%。在测试集上的攻击成功率ASR20%l80(test)为21.54%,相比于单个模型的ASR20%l80(test)提高了7.24%。

图7 集成训练的补丁在GTSRB-VGG16 的攻击成率

图8 不同占图比的补丁展示
3 结语
本文验证了对抗补丁方法应用在交通识别模型中存在一定的威胁。产生的补丁可以忽略图像的背景和自身的位置,对模型产生了一定的攻击效果,生成的对抗补丁则具有一定的鲁棒性和通用性。对抗补丁的方法属于白盒攻击方法,但是对抗补丁的方法在GTSRB 数据集上的效果并没有在ImageNet上的攻击效果出众。
本文分别做了3 组大类实验,在每大类中又按补丁不同尺寸(占图比)做了4 类不同实验。通过泛化性的测试实验和单个模型的白盒攻击实验表明通过白盒训练的补丁更容易使模型关注到自己,通过多个模型集成实验表明集成训练的补丁比单个模型训练的补丁更有效果,鲁棒性更强。这对于后续研究者研究自动驾驶中深度神经网络的鲁棒性和对抗防御具有极大的参考价值和实践意义。
