基于特征融合和动态多尺度空洞卷积的超声甲状腺分割网络
2021-03-18*
*
(1.山西省医学影像与数据分析工程研究中心(中北大学),太原 030051;2.中北大学大数据学院,太原 030051;3.山西省医学影像人工智能工程技术研究中心(中北大学),太原 030051)
0 引言
甲状腺是人体内分泌系统的腺体,也是最大的内分泌腺体之一,甲状腺的分割对于诊断甲状腺相关疾病至关重要。现如今人们主要通过超声影像来确定甲状腺结节的位置和大小[1]。伴随着计算机视觉技术的发展,计算机辅助诊断技术也逐步应用于广大现实医疗场景中。语义分割是计算机视觉中一项重要但具有挑战性的任务,通过对图像中每个像素分配类别标签从而区分不同目标区域。目前医学图像分割主要有两种思路:一种是依靠启发式先验(例如颜色、纹理和对比度)分析图像各像素值间的差异性来划分区域分割线;另一种是采用深度神经网络捕获图像高级语义关系和上下文信息,从而划分图像前背景信息。Quan 等[2]将归一化切割(Normalized cuts,Ncut)方法应用于合并过分割的区域,处理超声图像的强噪声、斑点及弱边缘问题。Zhuang 等[3]采用基于超声的模糊增强技术与分数布朗运动(Fractional Brownian Motion,FBM)模型相结合,增强其超声图像的对比度与分割效果;但仅依据纹理信息可能导致最终分割结果并不完整,并且由于超声影像反馈的斑点强度并非唯一的随机模式,采用启发式先验的方法对于复杂场景还不够健壮。Alom 等[4]将U型网络(U Network,U-Net)、残差网络结构与循环神经网络结构结合,提出了残差U-Net(Residual U-Net,RU-Net)和循环残差U-Net(Recurrent Residual U-Net,R2U-Net),并使用该网络进行了视网膜图像中的血管分割、皮肤癌分割和肺损伤分割。Nandamuri等[5]通过一种全卷积神经网络SUMNet实现对超声甲状腺的快速分割。迟剑宁等[6]融合深度网络和浅层纹理特征诊断甲状腺结节癌变情况。这些模型采用编码器-解码器结构,其结构简单且计算效率高。编码器通常由预先训练的分类模型组成,例如残差网络(Residual Network,ResNet)和超分辨率测试序列(Visual Geometry Group,VGG),该编码器可以提取出不同语义级别的多个抽象特征。在解码器中,提取的特征被组合生成图像中的目标响应区域。就超声甲状腺图像来说,甲状腺组织分布于肌肉和支气管之间的组织间隙,因其超声扫描时通常是采用手持式扫描仪对甲状腺进行扫描,导致其在超声影像中大小、形状及周边组织存在明显差异,同时甲状腺组织周边复杂器官干扰使得图像分割不理想。
针对甲状腺超声图像中甲状腺组织差异性大以及图像非显著性目标分割不明确的问题,探究深度学习技术对于甲状腺超声影像分割方面的准确性,根据卷积神经网络高低维特征的信息量不同以及增强感受野获取多尺度语义特征的方法,本文设计动态多尺度空洞卷积模块(Dynamic Multi-Scale Dilated Convolution,DMDC)与特征融合注意力模块(Fusion Attention Module,FAM),能较好地处理超声图像复杂目标多尺度变化及显著性分割问题。本文的主要工作有以下几点:
1)设计动态多尺度空洞卷积模块,利用多尺度空洞卷积获取的不同感受野的语义特征,采用动态卷积模块,处理形态大小差异较大的目标区域,增强网络提取不同尺度目标特征的语义信息,有效解决分割目标形态差异性较大的问题。
2)设计混合上采样模块(Hybrid UpSampling Module,HUSM),根据神经网络高低维度特征所包含的信息量不同,在解码器中对于高维度信息还原时增强其位置信息,对于低维度信息则增强其空间语义信息,提高网络分割效果。
3)设计特征融合注意力模块,针对浅层网络提取特征背景冗余特征干扰及高低维度特征统计差异较大,采用空间注意力机制激活响应低维度特征中的显著性目标区域,弱化背景信息,同时采用高低维度特征融合的方式,增强高低维度特征的重要特征、摒弃冗余噪声,大幅度提升网络对于前背景区域的分割能力。
1 相关工作
1.1 高低维度特征分析
基于医学图像的语义分割主要是通过深度卷积层不断抽象图像的高级语义特征,再逐步还原图像细节及边缘信息,最终达到前背景分离的效果。对于卷积神经网络来说,文献[7-8]提出不同深度的特征对于图像内容的抽象程度不同,随着卷积神经网络层数的增加,特征逐渐由低级表示演化成高级表示。对于低维度特征来说,主要包含了图像的纹理信息及空间位置信息;而对于高维特征来说,将特征降维可视化后可获取目标区域的近似范围,表明图像的语义信息和内在含义。采用解码器-编码器的U型结构,通过自上而下抽象图像语义再由下而上地还原细节特征,同时采用跳层连接的方式用低维度的特征引导细化高维信息特征还原。这种方式对于医学影像的语义分割任务能起到很好的效果。如图1 所示,低维特征在提供丰富细节信息的同时也充满了背景噪声,导致在由深至浅的过程中,来自深层的信息会逐步被来自浅层的信息所淹没。如果无法对模型中的特征进行一定的筛选控制,某些冗余的特征(包括来自低层的噪声和高层的粗糙边界)将可能导致图像分割效果性能下降。使用注意力引导网络来选择和提取补充特征并将其集成来增强显著性目标区域[9]。对于低维度特征来说,应对对象的位置信息进行筛查过滤,尽可能关注响应目标区域,弱化其他非目标区域的噪声干扰。对于高维度信息来说,应弥补不断下采样而缺失的空间位置信息以及忽略降维时引入的冗余特征。高低层特征应在保留自身有效信息的同时相互细化并摒弃冗余信息,便于对高维特征解码降维时降低其他噪声的干扰。
1.2 多尺度特征提取
由图1 可以看出,对于同一个超声甲状腺数据集来说,因甲状腺组织的分布位置及超声扫描的问题,其目标区域在图像中的尺寸、形态及数量上有明显差异。由于物体在复杂场景中有大规模的变化,因此有必要采用多尺度特征提取来准确有效地分割像素级图像[10]。设计Encoder-Decoder 模块[11]来融合不同层级间的特征,整合不同接受场的不同网络层的结果从而捕获不同的比例特征[12],这些方法忽略了不同比例尺上特征的一致性。空洞空间卷积池化金字塔模块(Atrous Spatial Pyramid Pooling,ASPP)[13]并行采用不同膨胀率的空洞卷积(如图2 所示),融合不同感受野下的特征获取多尺度的特征信息。金字塔场景解析网络(Pyramid Scene Parsing Network,PSPNet)[14]采用池化金字塔模块对不同尺寸图像执行池化操作,这些操作在一定程度上会稀疏图像特征信息,导致无法捕获相邻信息和图像的详细信息。因此,使用不同膨胀率的空洞卷积在获取不同感受野下的图像语义特征时,还可捕获与输入特征相关的不同比例尺下的特征信息来弥补因空洞卷积而缺失的细节信息。
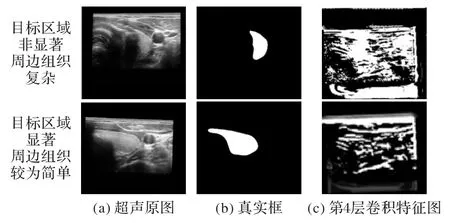
图1 甲状腺超声影像及特征提取图Fig.1 Thyroid ultrasound images and feature extraction images
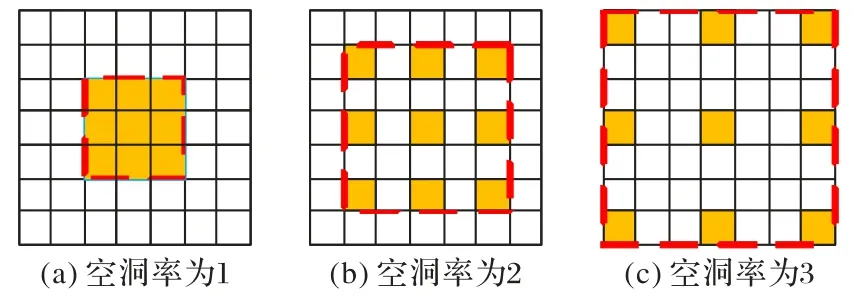
图2 不同空洞率的空洞卷积感受野对比Fig.2 Comparison of receptive fields of dilated convolutions with different dilation rates
2 特征融合和动态多尺度空洞卷积网络
2.1 网络架构
本文提出的超声图像分割模型整体结构如图3 所示。整体为编码-解码的U 型结构。采用ResNet34 的预训练模型作为网络编码器,利用迁移学习的方法提取图像纹理信息及空间信息特征;同时在编码器和解码器中添加动态多尺度空洞卷积模块,获取不同尺度下的特征信息和不同感受野下的全局信息。解码时根据高低维度特征所包含的信息量不同,采用混合上采样模型,弥补高维特征的位置信息及低维特征中像素点间的上下文信息。在U-Net 的跳层结构中添加特征融合注意力模块,细化高低维度信息特征减少冗余信息干扰,增强目标区域的显著性,再用编码器的抽象特征引导解码器特征还原,获取较为完整和精准的目标区域。本文网络主要包含3 部分结构:动态多尺度空洞卷积模块、混合上采样模块和特征融合注意力模块。动态多尺度空洞卷积模块采用空洞卷积和动态卷积获取不同感受野下的特征信息和不同比例下的区域特征信息,采用信息融合的方式获取多尺度的特征信息,增强网络对于多尺度目标的分割能力;混合上采样模块采用最大上池化和反卷积的方式,增强不同维度特征信息的空间信息及语义信息,提高网络的分割准确性;特征融合注意力模块采用特征融合方法优化高低维度特征信息摒弃冗余信息,同时采用注意力机制增强网络对于关键信息的获取,提升网络对于显著性目标区域的分割能力。
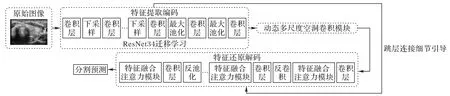
图3 网络总体结构Fig.3 Overall network structure
2.2 动态多尺度空洞卷积
在深度卷积网络中具有不同接受场的过滤器可以捕获不同比例的物体,如果感受野只能覆盖目标区域的一小部分,可能会导致分割结果不一致;如果感受野远大于小规模的目标区域,使得网络对背景信息关注更多,导致小物体分割不理想。可以使用多种不同感受野的卷积来捕获尺寸变化范围较大的对象。空洞卷积在扩大感受野的同时不需要增加额外的参数和计算成本,通过对空洞卷积膨胀率的设置即可获取不同感受野下的特征信息。ASPP 通过采用并行不同膨胀率的空洞卷积来捕获多尺度信息,整合不同感受野下的特征信息来处理图像多尺度问题。该方法在一定程度上可以处理尺寸变化,但因采用不同扩张率的卷积无法衡量其对目标尺度变化范围,这样稀疏采样的方式也可能丢失图像像素间的关联性,使用较大扩张率的卷积也可能导致网格化伪影,该结构对于图像尺寸较为敏感,可能导致小尺寸目标边界效应甚至分割退化[14]。因此,本文结合ASPP 结构的优缺点,提出了动态多尺度空洞卷积模块,通过动态滤波器生成不同尺度区域大小的过滤器获取不同尺度下的特定图像特征,与该感受野下的特征信息相融合,降低网络对于图像尺寸的敏感度,同时避免网格化和边界消失的问题。如图4 所示,对于动态多尺度空洞卷积模块来说,其主体分为两条支路:第一条采用空洞卷积获取全局不同感受野下的特征,第二条根据输入图像的区域上下文动态生成不同尺寸的卷积核,捕获输入图像的内部变化及高级语义特征,最后采用融合的方法将全局信息与内部变化进行融合,获取更为准确有效的多尺度目标信息。
对于输入特征x∈RW×H×C,首先采用空洞率为k、卷积核为3×3的空洞卷积获取不同感受野下的全局特征fk,同时对输入特征采用自适应平均池化层(Adaptive Average Pooling,AAP)获取区域大小为k×k的上下文信息,再采用1×1 卷积整合上下文感知区域特征gk,然后与不同感受野下的全局特征使用1×1 的深度卷积来融合两者的特征信息,获取该特定比例下的特征信息。本文k选取为1、3、5,因特定比例下特征信息的尺寸大小并未发生改变,最后将不同比例下的特征在通道维度上拼接,获取通道数扩张4 倍的特征向量,最后采用卷积压缩通道数至原始输入大小,所获特征即为捕获图像多尺度内容。

其中:Fk为空洞率为k、卷积核为3×3 的空洞卷积与1×1 卷积;Gk包含一个自适应平均池化层(AAP)、1×1 卷积和k×k的卷积核;⊗为深度卷积;hk采用1×1的卷积融合特征通道信息。对于原始图像而言,输入尺寸大小为256×384,经过6 个编码器后,其输出特征尺寸为8×12,对于空洞率为k=1、3、5的空洞卷积来说,可分别获取3、7、11 大小的感受野信息,该感受野的大小基本近似于全局特征的尺寸大小。同样选用卷积核大小为1、3、5 的过滤器,也能更好地获取不同卷积大小下的特定目标区域信息。因此,该模块能较好地获取全局特征下的不同感受野下的特征和不同尺寸下的详细特征信息,降低对于图像目标区域形态、大小尺寸的敏感性。
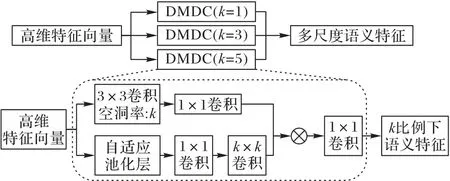
图4 动态多尺度空洞卷积Fig.4 Dynamic multi-scale dilated convolution
2.3 混合上采样模块
在深度神经网络中,随着网络层的不断加深,特征逐渐由低级可视纹理信息逐步抽象为高级全局语义信息。对于低维度特征信息来说,其主要获取的是图像的纹理信息及细节信息,但也包含了较多的背景特征及噪声信息,所以对低维度特征信息应该增强图像全局信息获取,同时弱化图像噪声干扰。对于高级语义信息来说,在网络不断下采样的过程中,高级信息具有丰富的语义但也逐渐缺乏原始图像的空间位置信息。为了弥补因不断下采样而缺失空间信息特征的高维信息以及降低维度特征还原时噪声干扰,本文设计了混合上采样模块,通过采用最大反池化上采样及反卷积上采样两种方式处理解码层中特征还原细节信息。构建解码器时,对于高维度特征,获取其在编码器进行最大池化操作而传输的池化索引,根据最大池化索引来引导还原高维特征信息进行上采样,增强特征的空间信息特征。对于低维度特征上采样时,为增强其全局信息的特征,采用膨胀率为3 的反卷积对图像进行上采样,弱化图像的复杂纹理信息同时增强图像的全局特征信息。本文网络采用编码器-解码器结构,编码器中采用ResNet34 的前4 个提取块作为特征提取器,其采用卷积进行下采样获取图像抽象信息,经过4 次下采样后图像的位置信息和纹理信息已明显抽象化,对于其高维特征的下采样应更多关注其位置响应的变化,故再添加两个提取块,采用最大池化的下采样方式提取特征中的显著位置特征,并保存该位置信息。因此对于解码器来说,本文沿用U-Net 的对称结构,采用与编码器对称的上采样方式,即对于较高维度的前2 个解码器中的特征通过对应的最大池化索引坐标采用最大上池化的方式进行上采样,增强特征还原时位置信息的引入;其余解码器的特征还原则主要采用反卷积的方式,还原特征全局的信息。
2.4 特征融合注意力模块
在编码器-解码器网络中,跳层结构可视为远程的残差块结构,使用解码器中抽象特征逐步引导还原高维语义特征的细节纹理信息。对于网络前几层而言其更多获取的是边界纹理特征,如果跳层结构仅是简单地采用元素相加来合并高级语义信息和低级信息特征,也会传递杂乱和嘈杂的背景和噪声信息,降低图像分割效果。随着卷积神经网络层数的增加,图像特征通道数不断增加而尺寸逐步缩小,特征也逐步由低维空间特征转换为高维语义特征,高维语义特征包含了全局的内在含义,尽管丢失了较多的详细信息,但其本身还是有一致的语义和背景信息,高低维特征之间还是存在较大的统计差异。因此,为了能更好地缓解高低维度特征间的差异性,使之能够在保留自身重要特征的同时抑制特征中的冗余信息以避免特征间相互污染。本文在空间注意力的基础上进一步分析特征融合的方法,设计特征融合注意力模块,将高低维特征融合与空间注意力机制相结合,增强低维信息关键区域的获取以及优化高低维特征信息的重要特征,提升网络划分前背景信息和图像显著性目标检测的能力。
如图5 所示,为关注特征图中的目标区域,降低其他复杂环境下其他显著性目标区域的影响,同时增强图像边缘的信息和特征本身的边界信息,本文采用增强图像边界信息和感兴趣区域的空间注意力模块。在注意力机制中,通常采用全局平均池化或是全局最大池化的方式来获取图像的显著性目标响应,但是全局平均池化将位置响应赋予相同的权重值可能高估目标区域,而全局最大池化仅响应图像中最大响应位置无法拓展完整对象。现有注意力结构通常采用将两者并联或串联来激活响应图像特征,但两者均未对图像边界信息进行考虑,因此本文在原有全局最大池化的基础上进一步增加对图像的显著性边缘的关注。对于低维特征信息fl∈RW×H×C采用全局最大池化(Global Max Pooling,GMP)获取关键位置的响应区域fGMP,同时为了拓宽图像完整对象信息,采用1×k和k×1的卷积核获取图像中的关键边缘信息和关注点[15]。为弥补因1×k卷积而丢失图像某一维度上的信息,采用k×1和1×k的卷积核作为信息补充,融合两个特征向量即可获取图像中的关键边缘信息和关注点,再通过叠加融合响应区域和边缘信息获取增强边缘的显著性目标特征,最后采用Sigmoid激活函数归一化激活响应映射,最终获取增强的低维特征fl'。其中,σ表示Sigmoid 激活函数,conv1和conv2分别表示1×k和k×1卷积层,在实验中设置k=5。
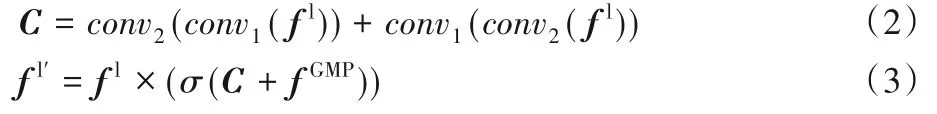
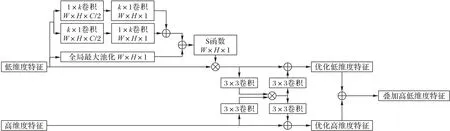
图5 特征融合注意力模块Fig.5 Feature fusion attention module
为减少特征之间的差异性,优化其中的一致性特征信息,本文将显著性激活的低维信息与高维信息通过逐个元素相乘融合不同级别的特征,与加法和串联方式的区别在于,相乘的方法可以抑制冗余信息并增强一致性的重要特征,从而完善高低维度特征。采用3×3 卷积层分别提取高维特征信息fh∈RW×H×C和显著性激活低维特征fl'∈RW×H×C,再通过乘法进行特征融合,融合的特征则包含了清晰的边界和一致的语义信息,最后将统一的增强信息采用3×3 卷积还原图像信息再添加至原来的特征用以细化高低维特征信息。
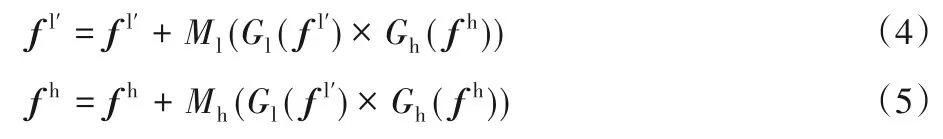
其中:M、G均由卷积层、归一化层和激活层组成,采用3×3 卷积来压缩和还原图像信息,增强高低维特征融合的泛化能力,避免高低维特征直接相乘而导致公共部分提取有误以及直接将公共部分添加至原有特征而引入的不必要的误差。将fl'的细节信息添加到fh中从而锐化高维特征边界信息,使用fh过滤fl的噪声信息。
2.5 损失函数
图像分割任务主要是判断各个像素点是否为目标像素点,也就是说分割问题是分类问题在像素点间的演化。现如今大多数模型均是采用交叉熵损失函数来衡量图像各个像素点的分割效果。但是就超声甲状腺图像而言,其分割边界所占图像整体比例较小,图像前背景多尺度差异性大,如果采用交叉熵损失判断图像前景像素的损失可能被背景的损失所稀释[16],同时它仅考虑各个像素本身的损失结果,平等地对待每个元素而忽略了图像整体的结构性。对于不用的像素应具有不同的权重,同时对于图像目标多尺度差异性大的问题,也应关注图像分割目标整体的差异性损失。因此本文采用加权交叉熵损失(Weighted Binary Cross Entropy,WBCE)和结构相似损失(Structural SIMilarity,SSIM)[17]设计了一个评估边界分割效果的损失函数,如下所示,定义的损失L为:

其中:超参数α为平衡系数,用于平衡细节损失及轮廓损失对最终结构的影响,在本文中选取α=0.6;LWBCE与LSSIM分别定义为加权交叉熵损失和结构相似损失。
加权交叉熵用于评估像素的重要性,通过为每个像素分配权重,重要像素分配较大权重,而简单像素将分配较小的权重。根据中心像素与其周围环境之间的差异计算像素对于周边环境的影响因素。
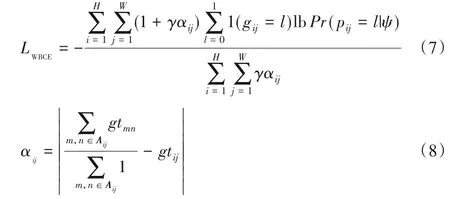
其中:1(⋅)为指标函数;γ为超参数;l∈{0,1}定义为像素前背景标签值;gij与pij分别表示像素的预测值与真实值;Pr(pij=l|ψ)表明网络的预测概率;ψ为模型中所有参数;Aij代表像素的周边区域;αij∈[0,1]定义为像素的权重值,如果值较大说明该像素与周边环境区别大,可能为边缘像素点应更加关注,相反若值较小,则可较少关注。
SSIM 损失通过分配较高权重给边界邻域,使得边界的损失权重增加,使边界上的预测概率与前景其余部分相同。让x={xj:j=1,2,…,N2}与y={yj:j=1,2,…,N2}为从预测图像S和二值真实图像G分别裁取的两个相关的区域(大小N×N),有:

图6 不同方法分割组织结果对比Fig.6 Comparison of issue segmentation results of different methods
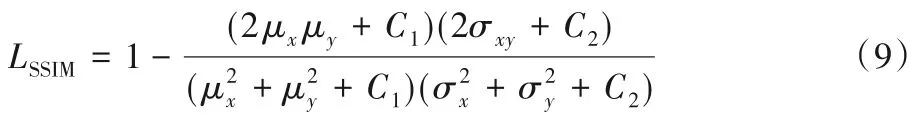
其中:μx、μy和σx、σy分别为x、y的均值和标准方差;σxy为它们的协方差;C1、C2为设置的常量参数。
3 实验与结果分析
本文采用的数据集为公开数据集[18],该数据集是以11~16 MHz 探针成像的16 个手绘标记的甲状腺超声图像扫描序列图像。在本次实验中主要采用3 423 张标注轮廓信息完整的超声甲状腺图像,因其图像为序列图像,故选用其中两个超声扫描图像为测试集(约350~400 张图像)。为符合实际医学图像的知识,图像数据增广方式仅采用左右随机对称的形式。训练时采用1 台NVIDIA P100 图形处理器(Graphic Processing Unit,GPU),本文采用ResNet34预训练网络作为编码器抽象图像高维语义特征,通过Fine-tune 的方法调整特征提取参数,在第5 个epoch 时冻结编码器的网络参数,最终网络训练约8 个epoch 时可以达平稳效果,总训练时长约100 min。本文采用以下定量指标来说明分割的准确度及精度:准确率(Accuracy)、召回率(Recall)、精准率(Precision)、Dice 分数(Dice coefficient)。本文设计以下的方法对比实验及网络消融实验证明网络结构的合理性。
3.1 方法对比实验
将本文提出算法与其他医学图像分割算法进行性能对比,采用传统基于ResNet34 为特征提取器的U-Net 作为实验基准,在多种医学图像分割泛化能力较强的CE-Net[19]以及在目标分割和边缘细化任务相对具有代表性的BASNet[20]和针对超声甲状腺分割的SUMNet[5]作为实验效果对比,结果如表1所示。
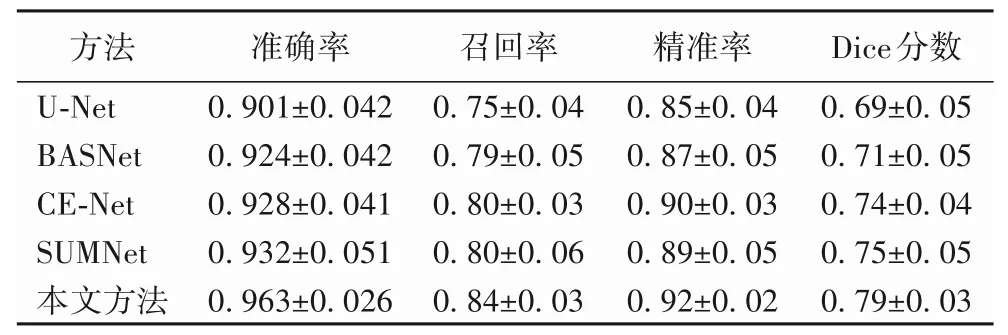
表1 不同方法的实验结果对比Tab.1 Comparison of experimental results of different methods
相较其他方法,本文方法在各项评估指标下均有较好的提升,尤其在召回率上,本文算法在分割超声图像的精准度较高。如图6不同算法分割组织结果对比所示。
对于甲状腺组织较为显著且有明显的分界边界,所选网络均能划分出甲状腺组织的大致区域,U-Net 和BASNet 更多关注于明显边界的分割结果导致分割结果受周边边界纹理信息影响较大,而CE-Net、SUMNet 和本文算法在分割结果明显更接近于真实框。但对于甲状腺组织小尺寸且周边干扰因素较大的图像,所选对比网络均存在将相似区域误认为是目标区域的情况,而本网络能较好地区分前背景信息从而能无误地分割目标区域;对于分割的目标区域而言,由于目标形态、尺寸差异性大,本算法的分割精度较其他网络对于关键区域的分割精度有所提升。因此对比其他网络,本网络对于超声甲状腺图像分割问题有较好的解决效果。
3.2 消融对比实验
本文采用消融对比实验说明本文结构的合理性与有效性,所有实验训练配置均相同。针对本文设计的动态多尺度空洞卷积模块(DMDC)、混合上采样模块(HUSM)与特征融合注意力模块(FAM)采用以下的消融对比实验,验证该结构在实验中的有效性。设计如下消融对比实验,在编码器-解码器连接处添加动态多尺度空洞卷积模块否则直接将编码器特征传给解码器模块作为实验对比;因上采样时如果仅采用反池化进行上采样可能会导致图像网格化严重,故对解码器上采样仅采用反池化或是混合上采样方式作为实验对比;解码器特征采用跳层连接的方式引导编码器还原细节信息时使用特征融合注意力模块否则仅采用特征叠加的方式作为实验对比。图7 为本文消融相应模块后的分割结果图,通过与未消融的网络分割结果图对比,动态多尺度空洞卷积对尺度变化明显的目标图像有较好分割效果,混合上采样能进一步优化网络分割结果,特征融合注意力能有效地避免冗余信息增多。
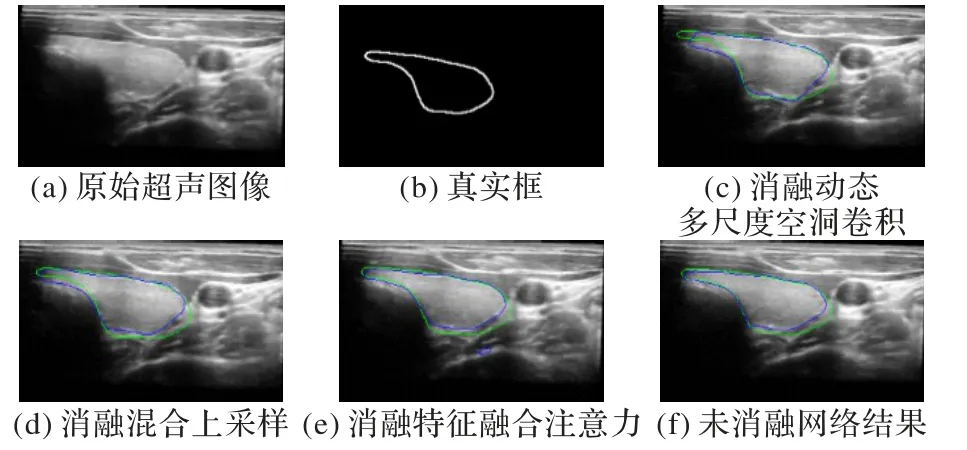
图7 消融实验模块对比Fig.7 Comparison of ablation experimental modules
为进一步说明网络各个模块的有效性,本文采用十折交叉验证选用随机的2 个超声序列作为测试集验证各个模块的合理性。如表2 所示,特征融合注意力模块可以明显地提升网络分割性能;动态多尺度空洞卷积增强图像对于多尺度特征获取可能会降低分割结果的精准率,若只关注不同尺度下的特征可能会导致图像冗余信息增多,通过特征融合注意力块筛选过滤特征中的冗余信息,能进一步提升网络的分割精度与准确性;混合上采样模块对于原始分割网络有一定的提升,在一定程度上能细化网络的分割结果。通过消融实验证明本文所设计的模块能有效地提高网络分割的准确性和精准度。
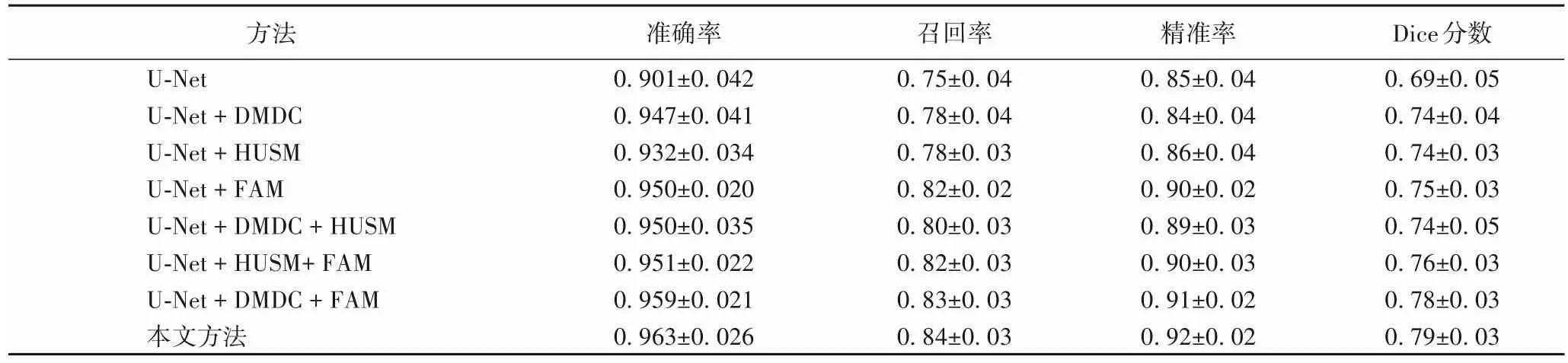
表2 网络结构消融结果的对比Tab.2 Comparison of network structure ablation results
4 结语
本文根据高低维度特征对图像抽象信息不同的特点,采用高低维特征信息相互融合的方法,保证高低维特征在保留自身的同时相互细化,摒弃冗余信息对网络的干扰;同时,采用动态多尺度空洞卷积层来获取不同形态、大小的目标区域特征,减少图像数据源间差异性对网络的影响。本文方法实现了端到端的训练和预测,并在标准的数据集中实现了0.963±0.026的准确率,0.84±0.03的召回率,0.92±0.02的精准率以及0.79±0.03的Dice系数;并且本文方法灵活简单,可以用于其他非显著性目标分割任务中。此外,考虑医学图像领域图像复杂其目标不明确的情况,我们将继续尝试将该方法拓展至其他的医学任务中,以获取更为广泛的应用。
