基于注意力机制的图像超分辨率重建
2021-03-18,*
,*
(1.贵州大学计算机科学与技术学院,贵阳 550025;2.贵州师范学院数学与大数据学院,贵阳 550018)
0 引言
图像在携带信息方面扮演着越来越重要的角色,高分辨率(High Resolution,HR)的图像越清晰,所蕴含的信息也越多。然而,由于成像设备以及天气、光线等环境因素和噪声的干扰,会获取到许多低分辨率(Low Resolution,LR)模糊的图像,如何提高图像的分辨率是非常有研究意义的。最直接有效的方法是改善图像捕捉设备,但是在实际应用中,改良硬件成本昂贵,对于小型企业或者个人研究者是不友好的,因此,超分辨率(Super Resolution,SR)重建技术由此而生,它通过改良算法来提高图像分辨率,成本极低,适用于任何研究者。图像超分辨率重建技术在军事、遥感、医疗影像[1-2]等领域都有着广泛的应用。
广为熟知的超分辨率重建方法大体分为三类:基于插值、基于重建的和基于学习[3-4]的方法。插值法通过某个像素点与其周围像素点对应的空间位置关系,利用数学公式来推导估计缩小和放大后的对应点的像素值。常见的插值法有双立方插值[5]、最近邻插值[6]和双线性插值[7],插值法的速度快,但是重建的图像细节纹理部分比较模糊。基于重建的方法利用图像的整体信息结合数学方法求解高分辨率图像的特征表达,然后重建出高分辨率图像,常见的重建方法有最大后验概率法[8]、迭代反向投影法[9]、凸集投影法[10]等。基于学习的方法利用大量的外部图像样本,结合数学公式的推导,学习LR与HR图像之间的映射关系,获取复杂的先验知识;然后在重建高分辨率图像时,能更好地放大图像细节部分,提高图像质量。早期的学习方法主要是机器学习,通过矩阵变换来求解高、低分辨率图像之间的映射关系。图像的稀疏编码(Sparse Coding,SC)就是其中的经典学习方法,它将LR 和HR 对应的特征图部分一一编码成字典,形成对应的映射关系,然后学习编码字典中元素的映射关系,重建高分辨率图像。Yang 等[11]提出的基于稀疏表达算法,通过训练高、低分辨率图像的块字典,使得其他的图像块都能够适用于这一字典稀疏表达,且同一个图像块对应的高、低分辨率图像字典的线性表达一致。
近年来,随着图形处理器(Graphic Processing Unit,GPU)的发展,基于深度学习的方法被广泛用于图像超分辨率重建领域,尤其是卷积神经网络(Convolutional Neural Network,CNN)能自动提取丰富的特征,学习LR和HR之间的复杂映射关系。2014年,Dong等[12]首次利用卷积神经网络来进行超分辨率重建任务,提出了超分辨率卷积神经网络(Super-Resolution Convolutional Neural Network,SRCNN)模型,采用端到端的训练方式,在当时大大提高了重建效果,开启了卷积神经网络处理超分辨率问题的时代。随后许多研究者在其基础上进行研究,致力于构建更好的模型。2016年,Kim等[13]将残差思想应用于超分辨率重建任务,提出了使用非常深的卷积网络超分辨率(Super-Resolution using Very Deep convolution network,VDSR)模型,同时将网络的深度增加到了20 层,证明了深层网络能提取出更多的特征,取得更好的重建效果。为了更注重视觉效果,Ledig等[14]提出了使用生成对抗网络的超分辨率(Super-Resolution using a Generative Adversarial Network,SRGAN)模型,利用感知损失和对抗损失来提升和恢复出图像的真实感,在当时取得了最逼真的视觉效果。Lim等[15]通过对残差网络的改进,提出了增强深度超分辨率网络(Enhanced Deep Super-Resolution network,EDSR)模型,通过移除批规范化处理(Batch Normalization,BN)操作,堆叠更多的网络层,提取更多的特征,从而得到更好的性能表现,并在同年的图像恢复与增强新趋势(New Trends in Image Restoration and Enhancement,NTIRE)大赛中取得了第一名的成绩。
尽管上述基于深度学习的SR 方法都取得了很好的重建效果,但是仍然存在一些问题:1)它们都没有对网络提取的特征加以区别。平等对待每个通道,限制了网络的表达能力,可能让网络在冗余的低频特征上浪费计算资源。2)深层网络所需要训练的参数更多,等待的时间更久,如何减少参数运算量、提高模型性能也是一个重要的问题。针对上述存在的问题,本文提出了一种基于通道注意力机制(Channel Attention mechanism,CA)和深度可分离卷积(Depthwise Separable Convolution,DSC)的网络结构,由浅层特征提取块,基于通道注意力机制的深层特征提取块和重建模块组成。首先,将低分辨率图像送入浅层特征提取块,提取原始特征;然后,在深层特征提取块中,在局部残差模块中加入通道注意力机制来提取深层的残差信息,由于使用通道注意力机制会增加计算开销,使得训练的参数增加,所以在局部残差模块中还采用深度可分离卷积技术来减少参数运算量;最后,在重建模块,将提取的深层残差信息和LR 的信息融合,重建HR 输出。本文的主要工作有以下三点:
1)提出了一种局部和全局的残差网络结构,有效缓解了梯度消失的问题,并且局部残差块能将图像原始的丰富细节传递到后面的特征层中,提取更丰富的细节特征。
2)在局部残差模块中融入了通道注意力机制,并将通道注意力网络模块的全连接层换成了卷积层,通过挖掘特征图通道之间的关联性,侧重提取关键特征信息。
3)在局部残差模块中融入了深度可分离卷积技术,能有效减少网络的参数。
1 注意力机制
注意力机制通过模仿人类对事物观察的方式来决定对输入的哪部分数据进行重点关注,然后从重点数据部分提取关键特征。注意力机制最早应用于机器翻译和自然语言处理方向,此后在各领域都有广泛的应用。
注意力机制一般分为硬注意力(Hard Attention)机制和软注意力(Soft Attention)机制。硬注意力机制是在所有特征中选择部分关键的特征,其余特征则忽略不计。例如,在Wang等[16]的数字识别任务中,在提取原始图像的特征时,只有含有数字的像素点是有用的,所以只需要对含有数字的像素点进行重点关注即可。因此,硬注意力机制能有效减少计算量,但也会丢弃图像的部分信息,而在超分辨率重建任务中,图像的每一个像素点的信息都是有用的,显然硬注意力机制不适用超分辨率重建任务。
软注意力机制不像硬注意力机制那样忽略某些特征,它对所有的特征设置一个权重,进行特征加权,通过自适应调整凸显重要特征。这样的方式适用于超分辨率重建任务,本文引入的通道注意力机制就属于软注意力机制的一种。图像经过每层网络时,都会产生多个不同的特征图,通道注意力机制通过对每张特征图赋予不同的权重,让网络从特征的通道维度来提取重要的特征。最早将通道注意力机制用于图像超分辨率重建任务的是Zhang 等[17]提出的残差通道注意力网络(Residual Channel Attention Network,RCAN),该模型证明了通过考虑通道之间相互依赖的特性,调整通道注意力机制,能重建出高分辨率的图像。随后Lu 等[18]提出多特征通道网络(Channel Attention and Multi-level Features Fusion Network,CAMFFN),将通道注意力机制和递归卷积网络结合,在每个递归单元的开始部分采用通道注意力机制,自适应地调整输入特征的重要通道特征,取得了良好的效果。Liu等[19]提出一种单一图像的注意力网络,该网络分为特征重建网络和注意力产生网络,特征重建网络采用稠密卷积网络(Dense Convolutional Network,DenseNet)结构,而注意力网络采用U-Net结构,最后将两个分支的结果融合,获得高分辨率的重建图像。
2 本文方法
通常认为网络层数越深,提取的特征越丰富;并且,越深的网络提取的特征越抽象,越具有语义信息。然而在实际应用中,简单地增加深度会出现退化问题,原因可能是经过多层特征提取之后,许多图像的边缘纹理等细节丢失了,因此,本文提出了一种基于注意力机制和深度可分离卷积的网络结构,通过引入全局和局部残差学习能有效解决网络退化问题。局部残差网络能将丰富的图像细节传到后面的特征层中,在局部残差模块中采用通道注意力机制和深度可分离卷积,前者通过调整各通道的特征图权重,让网络从特征的通道维度来提取比较重要的特征,后者则能极大降低模型的训练参数。同时,采用自适应矩估计(Adaptive moment estimation,Adam)优化器来加快整个模型快速收敛,缩短训练的时间。本文设计的网络模型如图1所示。
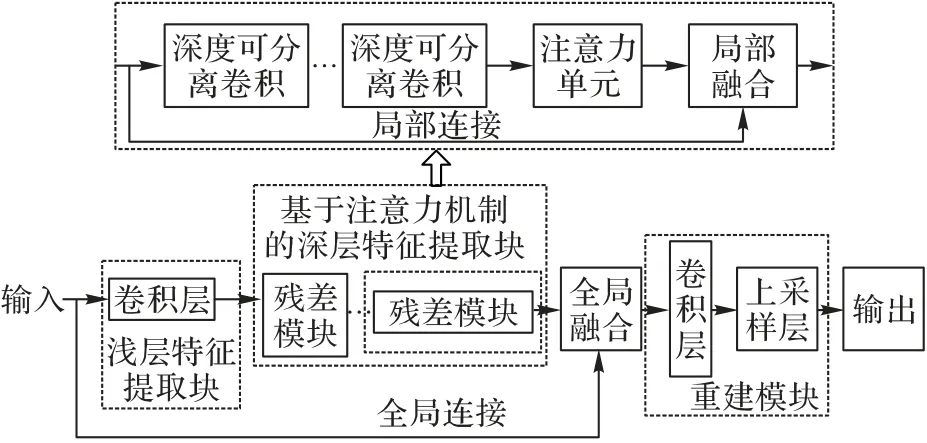
图1 本文提出的网络模型Fig.1 The proposed network model
整个网络模型大体分为三部分:第一层为浅层特征提取块,用于提取低水平特征;中间层为基于通道注意力机制的深层特征提取块,由若干个局部残差模块组成,用于学习高水特征;最后一层为重建模块,用于融合低水平特征和学习到的残差特征,重建高分辨率图像。
2.1 浅层特征提取块
浅层特征提取块由一个卷积层和激活层组成,用于从输入的低分辨率图像中提取特征,用Y和F0表示网络的输入与输出,该特征提取可用式(1)表示:

其中:*为卷积操作;W0为卷积核;b0为偏置;F0为从低分辨率Y中提取的特征;σ为激活函数,这里采用ReLU 作为激活函数。在进行卷积操作前,为防止卷积之后的特征图越来越小,此处在每次卷积之前都进行补零操作,这样能够确保每次卷积之后的图像依然是原来的大小。
2.2 基于通道注意力机制的深层特征提取块
在这一部分,经过浅层特征提取块后,获取了低分辨率图像的特征图,需要把这些特征映射到高维上继续提取有效的信息。这一模块由多个相同结构的残差模块组成,每个残差模块由若干个深度可分离卷积单元和一个通道注意力机制单元组成,接下来分别介绍这两个单元。
2.2.1 通道注意力机制
一般来说,注意力机制可以看作是一种信号导向,它将更多可用的资源分配给输入图像中信息最丰富的部分。每一张图像都能用RGB(Red-Green-Blue)三个通道表示出来,在卷积神经网络中,通过不同的卷积核对每个通道进行卷积,每个通道就会产生新的特征信息,每个通道的特征信息就表示该图像在每个卷积核上的分量,通常采用64 个卷积核对图像进行卷积,其中卷积核的卷积操作将每个通道的特征信息分解成64 个通道上的分量,由于图像中的高频信息是聚集的,那么在64 个通道上的关键信息其实是分布不均的,普通的卷积神经网络并没有把关键信息明显区别出来,如何对每个通道特征产生不同的注意是关键步骤。通常LR 图像具有丰富的低频信息和有价值的高频信息成分,低频信息一般比较平坦,而高频成分通常是在某一区域充满了边缘、纹理和细节。卷积核在对图像进行卷积时,有一个感受野的限制,只能对感受野内的信息提取特征,无法输出感受野之外的信息。因此,可以使用全局平均池化操作对全局空间内的信息转化为通道描述符,然后通道注意力机制通过给每个通道设置一个权重来表示通道与关键信息的相关性,权重越大,则该通道的信息越关键,输出的特征就越多,最后重建出来的图像分辨率就更高。通常通道注意力机制单元由一个池化层、两个全连接层组成,全连接层用于降低维度,控制模型的复杂性。这里将两个全连接层换成卷积层用以增加网络非线性,更好拟合通道复杂的相关性,并且还能减少一定的参数。改进的通道注意力机制单元如图2所示。
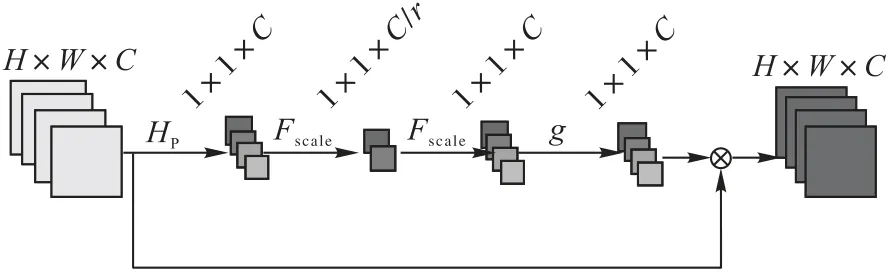
图2 通道注意力机制Fig.2 Channel attention mechanism
首先,池化层将大小为H×W的C个特征图转化为1×1大小的C个特征图,其计算方式如式(2)所示:
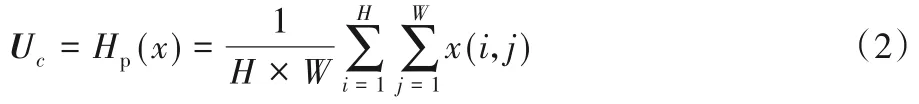
其中:x(i,j)表示C个特征x在位置(i,j)处的值;Hp(x)为全局池化函数,把每个通道内所有的特征值相加再平均;Uc为经过池化后的全局信息。
经过池化层之后,得到全局信息Uc,为了获取全局信息Uc和各通道的相关性,引入一个门控机制,来学习各通道之间的非线性交互作用。门控单元Sc的计算方式如式(3)所示:

其中:σ是ReLU 激活函数,而g是一个sigmoid 函数;W1和W2分别是两个卷积层的权重,通过每个局部残差块的两个卷积层训练学习,不断调整其对应的两个权重,得到一个一维的激励权重来激活每一层通道。最后将通过sigmoid 函数得到的特征值Sc重新调整输入Uc。

式(4)表示放缩过程,经过门控单元得到特征图后,需要将1×1 大小的C个特征图还原成H×W大小的特征图,每个通道和其对应的权重相乘,从而可以增强对关键通道域的注意力,其中Sc和Uc是第c个通道中的缩放因子和特征映射。这样通过通道注意力机制就可以自适应地调整通道特征来增强网络的表达能力。
2.2.2 深度可分离卷积
深度可分离卷积最早是用于语义分割方向,在实际应用中使用效果良好,后被广泛用于各领域。文献[20]将深度可分离卷积代替传统卷积提出了小巧而高效的移动端卷积神经网络(efficient convolution neural Networks for Mobile vision applications,MobileNets)模型,在没有降低准确率的情况下,大大减少了模型的参数,使得MobileNet 模型广泛应用于移动端。深度可分离卷积将标准卷积进行拆分,将输入数据的通道单独卷积,再使用点卷积整合输出,其计算式如下:

其中:*表示卷积操作;Hm为输出的特征图;F为输入特征图;K为卷积核;i,j为特征图中每个像素值的坐标;m为通道数。深度可分离卷积是一种可分解的卷积,是在标准卷积基础上改进的,它可以分解为两个更小的操作:深度卷积(Depthwise Convolution,DC)和逐点卷积(Pointwise Convolution,PC)两个阶段。DC是深度可分离卷积的滤波阶段,针对每个输入通道采用其对应的卷积核进行卷积操作。PC 是深度可分离卷积的组合阶段,整合DC 阶段的所有特征图信息,串联输出。标准卷积和深度可分离卷积的区别如图3、4所示。
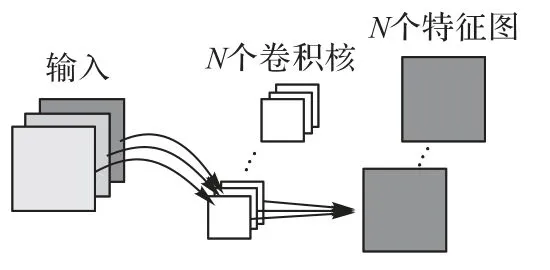
图3 标准卷积Fig.3 Standard convolution
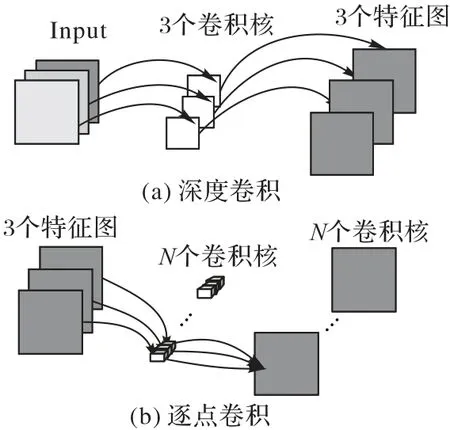
图4 深度可分离卷积Fig.4 Depthwise separable convolution
为了比较普通卷积和深度可分离卷积的参数运算量,假设输入M通道大小为H×W的特征图,经过D×D大小的卷积核进行卷积操作后,输出大小为H×W的N通道特征图。
则标准卷积参数运算量如式(6)所示:
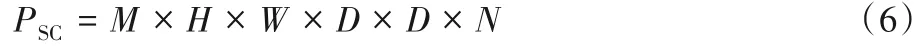
深度可分离卷积的参数运算量如式(7)所示:
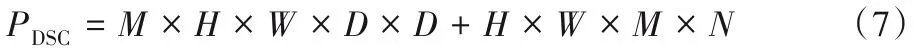
因此,两种结构对应参数运算量之比如式(8)所示:

从式(8)可以得出,与标准卷积参数运算量相比,使用深度可分离卷积能极大降低模型参数运算量,当两个网络模型的层数相同时,若深度可分离卷积全部使用3×3的卷积核,即D=3,则参数运算量能减少为原来的1/9左右。
2.3 重建模块
将前面深层特征提取块获取的输出降维到与初始低分辨率输入相同的维度,自适应地融合和保留之前学习到的特征,进行全局特征融合并输出,重建出高分辨率的图像。

其中:Y为图像初始输入;R为非线性映射学习到的高频特征信息;Fd表示局部特征融合层的计算操作;Gup表示上采样操作;Hhigh则为重建的高分辨率图像。
2.4 损失函数
超分辨率重建的任务是通过卷积神经网络一系列操作获取重建图像Hhigh,让Hhigh和原高分辨率图像Fhigh越相似越好。因此,需要一个函数来评价Hhigh和Fhigh之间的相似性,均方误差(Mean Square Error,MSE)函数可以通过计算Hhigh和Fhigh两幅图像的每个像素点的误差来评价Hhigh和Fhigh之间的相似性。误差越小,即表示两幅图像越相似。所以本文采用均方误差来作为损失函数(Loss Function),损失函数计算如式(10)所示:
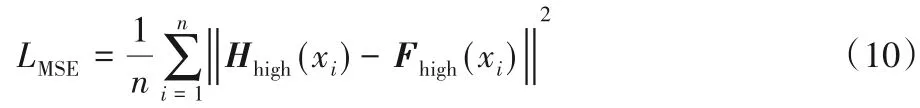
其中:i表示每个像素点;Hhigh为重建的高分辨率图像;Fhigh为原始高分辨率图像。通常在评价重建图像质量时,峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)是一个重要的评价指标,而在计算PSNR 时,MSE 越小,则PSNR 越大,表示重建的图像质量越好,与原始高分辨率图像越相似。因此,使用MSE作为损失函数可以获得比较大的PSNR。
3 实验与结果分析
3.1 数据集和评价指标
实验采用的数据集是图像超分辨率标准数据集BSD300[21],含有300 张图像,包含了自然界的各种景象,其中200 张用于训练,100 张用于验证。测试集采用Set5[22]、Set14[23]数据集,Set5 数据集包含5 张动植物的图像,Set14 数据集包含14 张自然景象的图像,比Set5 包含更多的细节信息。这些图像通常用于图像的重建。
本次实验采用两种国际通用的评判标准峰值信噪比和结构相似度(Structural SIMilarity index,SSIM)作为重建图像的质量评价指标。PSNR 通过计算重建的高分辨率图像与原始的高分辨率图像之间像素点的差值来衡量图像的质量,PSNR的单位是dB,数值越大,表示重建的图像越好,失真越小,与原始图像越相似,其计算如式(11)所示:
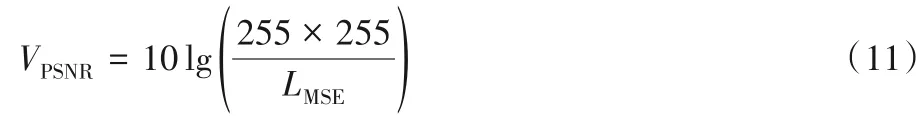
结构相似性以两幅图像的结构相似度为标准,从图像的亮度、对比度和结构三个方面进行评价,计算式如下所示:
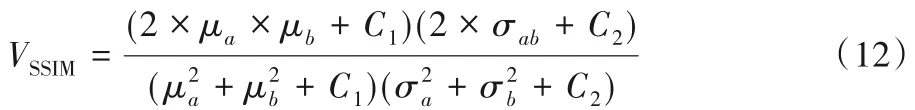
其中:μa和μb分别为图像A和B的均值,表示亮度;分别为图像A和B的方差,表示对比度;σab为图像A和B的协方差,表示结构;C1、C2为常数,C1=(k1×L)2,C2=(k2×L)2,通常取k1=0.01,k2=0.03,L=255。结构相似性的取值范围在0~1,结果越接近1,表示两幅图越相似。
3.2 实验设置
本实验使用4块GPU来训练各模型,型号都为Tesla-P40。由于目前许多研究的重构倍数都是2、3、4倍,因此本文实验的重构倍数也采取相同的倍数,方便比较。针对输入的彩色图像,通过下采样生成低分辨率的图像,然后将RGB图像转换至YCbCr颜色空间,将Y通道的信息送入本网络进行重建。网络优化器使用Adam优化器,初始动量设为0.9,Batchsize设置为32,基础学习率为0.001,之后每训练25个Epoch,学习率减小一半。滤波器的个数为64 个。整个模型中,在局部和全局的特征融合部分采用1×1的卷积核,其他卷积层则采用3×3的卷积核,并且进行卷积操作之前都采用0 填充边界,从而保证卷积之后的特征图尺寸不变。激活函数都采用ReLU激活函数。
3.3 实验结果
将本文提出的方法在Set5 和Set14 数据集上与Bicubic、SRCNN[12]、VDSR[13]、EDSR[15]、RCAN[17]等方法进行对比,表1为Set5 和Set14 数据集在不同模型中所取得的PSNR 均值和SSIM均值,表中加粗部分为本文模型的结果。

表1 不同模型的PSNR和SSIM均值Tab.1 PSNR and SSIM average values of different models
从表1 的实验结果来看,本文提出的模型和SRCNN、VDSR、EDSR、RCAN 相比,在Set5、Set14 数据集上的PSNR 和SSIM 均值都有所提升。在放大倍数较低时,本文的模型重建效果和RCAN 相比没有明显的提升,但在放大倍数较高时,本文的模型重建效果良好,PSNR均值也有较大的提升,表明本文的模型提取图像细节的能力比较强。从图5 中的睫毛图像也可以看出,本文的模型重建出来的图像更清晰,与原高分辨率图像更相似。一般而言,随着放大倍数的增大,图像重建的难度也会随之增大,在放大倍数为4 时,本文的模型相较RCAN模型在Set14 上的PSNR 均值提升了0.39 dB。在RCAN 的启发下,本文模型将特征图通道注意力机制应用于残差网络,带来了良好的重建效果,但是特征图通道注意力机制会带来巨大的参数量,增加计算开销。为了减少通道注意力机制带来的大量参数影响,本文还引入了深度可分离卷积来减少参数运算量,表2是各模型的参数运算量以及运算时间对比。
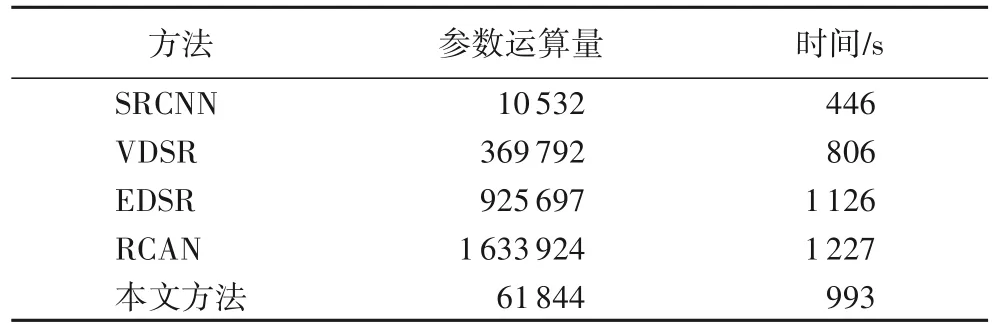
表2 不同模型的参数运算量和运算时间Tab.2 Parameter computing amount and computing time of different models
表2 给出了各模型产生的参数运算量和模型所用的时间对比,由于Bicubic 属于传统模型,所以这里没有把它与各模型比较。由于实验设备的限制,VDSR、EDSR、RCAN 和本文模型的每个残差块都只设置了10 层网络。从实验结果来看:本文的模型相较VDSR 模型,参数运算量是其1/6 左右;相较EDSR模型,参数运算量是其1/15左右;相较RCAN 模型,参数运算量是其1/26 左右。从各模型所运行的时间来看,SRCNN所运行的时间最短,因为SRCNN 模型的网络结构只有三层,参数少,所以训练的时间也越短;反观RCAN 模型,由于使用了通道注意力机制,使得参数增加,耗时也长;而本文的模型耗时比RCAN 模型的运行时间短,虽然也使用了通道注意力机制,但是在局部残差模块中使用了深度可分离卷积技术,减少了参数。这进一步证明使用深度可分离卷积技术能大大减少参数运算量,从而减少训练的时间,提高算法的性能。图5~8 都是在重构倍数为2 时,在Set5 和Set14 上重建的图像。为了方便看出效果,文中选取了各图像中容易辨别的细节特征,例如图5 中的眼睫毛部分,从图中可以明显看出本文的方法重建出来的图像更清晰,与原HR 图像几乎一致;图6 中的蝴蝶翅膀部分,从放大的图像来看,其他方法重建出来的图像在细节纹理部分都有一定程度的模糊,特别是传统的Bicubic方法,更是模糊不清,而本文方法重建出来的纹理部分比较清晰;图7 中胡须部分,从放大的图像来看,本文方法相较其他方法重建出来的图像,胡须根根分明,清晰可见;图8 从少女的头饰也可以看出本文方法在图像细节方面,处理得更好。
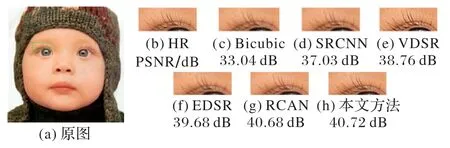
图5 baby图像主观对比结果Fig.5 Subjective comparison results of baby image

图6 butterfly图像主观对比结果Fig.6 Subjective comparison results of butterfly image

图7 baboon图像主观对比结果Fig.7 Subjective comparison results of baboon image

图8 comic图像主观对比结果Fig.8 Subjective comparison results of comic image
4 结语
本文设计了一种基于通道注意力机制和深度可分离卷积的网络结构,对单幅图像进行超分辨率重建。该方法通过在局部残差块中采用通道注意力机制来发掘特征图通道之间的相关性,提高网络提取关键特征的能力,使得重建的图像更清晰,并且在局部残差块中引入深度可分离卷积技术,减少训练的参数。实验结果表明本文的方法重建效果良好,而且也大大减少了训练的参数,提高了模型性能。本文研究的不足之处是每次训练的模型只能适用于一种重构倍数,因此下一步的工作是将多尺度重构倍数应用于网络模型中。
