基于粗糙集理论的不完备数据分析方法的混合信息系统填补算法
2021-03-18,2*
,2*
(1.成都信息工程大学软件工程学院,成都 610225;2.西南交通大学信息科学与技术学院,成都 611756;3.成都大学计算机学院,成都 610106)
0 引言
近年来,由于数据来源广泛且复杂、人类认知的局限性,以及硬件故障、手工录入错误、编程错误等,导致数据产生一定比例的缺失,使得知识的有效获取变得愈来愈困难;如何科学地处理缺失数据、提高数据质量是当下数据挖掘领域的研究难点之一。现实生活中描述数据的形式多种多样,缺失机制也各不相同,使得基于粗糙集理论的不完备数据分析方法(ROUgh Set Theory based Incomplete Data Analysis Approach,ROUSTIDA)[1]无法满足所有数据的需求。本文立足于混合信息系统,即包含离散型(如整型、字符串型、枚举型)、连续型(如浮点数表达)、缺失型属性的信息系统,研究分析发现,混合属性将严重影响ROUSTIDA 对数据之间相似性的度量,从而使得填充效果不理想。为了解决该问题,本文在定义混合距离的基础上结合近邻思想与等价类划分原则,提出了一种基于粗糙集理论的混合信息系统缺失值填补方法(Rough Set theory based Hybrid Information System for Missing data Imputation Approach,RSHISMIA)。本文的主要工作包括5 个方面:
1)使用了混合距离量化样本间相似度。
2)定义了混合距离矩阵,剔除不具备填补能力的数据。
3)采用决策属性等价类划分思想,有效地改善了可能存在的决策属性冲突问题。
4)引入最近邻思想,减轻噪声数据的影响。
5)使用UCI 数据集与4 种填补算法进行对比实验,结果表明RSHISMIA 在查准率和查全率方面显著优于ROUSTIDA,填补后的分类准确率相较4 种对比算法也有所提高。
1 相关工作
自1970 年来,国内外陆续提出的缺失数据的处理方法大致可以分为以下3类。
1)直接删除法:简单地将存在缺失属性值的实例删除,从而得到完备的信息系统。但当信息表中信息较少、存在缺失属性值的实例较多时,会严重影响信息系统中的信息量。
2)特殊值法:该途径将缺失属性值作为一种特殊的属性值来处理,它不同于其他任何属性值,从而不完备信息系统就成为完备信息系统。
3)填补法:按照特定方式对缺失数据进行估计,使用估计值替换缺失数据,从而得完备信息系统,该方法也是最常用的方式。
目前,对缺失值的填补包含基于机器学习算法和基于粗糙集理论等的方法。其中,基于机器学习算法的方法需要利用完备信息系统训练模型,从而对缺失值进行预测,如一种基于支持向量机(Support Vector Machine,SVM)的缺失数据填补算法[2],该方法使用支持向量回归填补含有缺失信息的基因表达数据,通过正交化编码输入方案,把缺失数据映射到更高维空间,从而填补缺失数据。Stekhoven 等[3]提出了基于随机森林的数据填补(Random Forest Imputation,RFI)算法,该算法适用于类别型属性较多且样本数量较小的数据集。Dixon[4]提出了K 近邻填补(K Nearest Neighbor Imputation,KNNI)算法,该算法首先在数据集中找到与缺失数据样本的k个最相似样例,然后利用这k个样例相应的属性值对缺失值进行填补。Ranjbar等[5]通过使用未知对象的估算评级来提高基于矩阵分解(Matrix Factorization,MF)算法的性能,该算法可以改善数据稀疏性和过拟合问题。而由波兰学者Pawlak[6]提出的粗糙集理论及其扩展模型为不完备信息系统的处理奠定了良好的基础。该理论能够在保持信息系统分类能力不变的前提下,无需提供问题所需处理的数据集合之外的任何先验信息。在此基础上,最具代表性的离散型数据填补算法是Zhu 等[7]提出的基于容差关系的ROUSTIDA。针对该算法所存在的缺陷,许多学者进行了广泛的研究。蒋亚军等[8]在模糊相似关系的基础上,针对具有连续属性的不完备信息系统提出了Rough 集的扩展模型,在模糊关系的基础上给出了不完备信息表的上近似和下近似的定义;利用基于欧氏距离的贴近度法计算模糊相似度,构造相似矩阵,实现了对论域的划分。朱小飞等[9]根据扩充后的量化容差关系提出VTRIDA(Valued Tolerance Relation based Incomplete Data Analysis)算法,实现一次直接补齐缺失值,减少了计算开销。刘文军[10]针对不同的属性类型给出了条件属性相似度,就不同条件属性类型的决策表给出了相应的补齐算法,并给出了τ相似度的概念,但该参数τ的选取没有合适的方法。王国胤[11]提出了基于限制容差关系的扩展粗糙集模型,该模型结合了容差关系和非对称关系的优缺点。霍忠诚等[12]根据极大相容块中的元素之间具有最高的相似度的性质,提出了一种改进算法,提高了ROUSTIDA 对离散型不完备数据的填充能力。丁春荣等[13]提出了基于决策独立原则的改进算法,有效地解决了原算法可能存在的噪声问题。关莹等[14]针对数据稀疏度大的信息系统提出了一种基于序数属性相似度的不完备数据分析方法,该算法使用差值替代等值的方式改进扩充差异矩阵,改善了其他改进方法对序数属性处理不准确的缺点。为了克服ROUSTIDA 在无差别对象属性值发生冲突情况下无法对相同属性进行补齐的缺陷,并改善VTRIDA 算法对容差关系不合理的量化定义,Bai等[15]提出了综合量化容差关系和限制容差关系的数据填充方法VLTA(Valued and Limited Tolerance Algorithm)。Prieto-Cubides 等[16]结合了广义非对称相似度关系和广义分辨矩阵,提出适合缺失率较大的填补(Agreements based on Rough Set Imputation,ARSI)算法,但是该算法仅能处理离散型数据。樊哲宁等[1]提出了一种针对具有关键属性的重复数据的改进算法,考虑了目标属性重复性的同时分析了关键属性对填补效果的影响。然而上述研究基本是针对具有单一离散属性或连续属性的不确定系统进行的,无法处理具有离散属性、连续属性和缺失属性的混合信息系统。因此,本文提出了一种基于粗糙集理论的混合信息系统缺失值填补方法RSHISMIA。
2 ROUSTIDA
2.1 基本定义
ROUSTIDA 采用粗糙集理论实现不完备信息系统的缺失数据填补。该算法的基本思想是:缺失数据的填补应使具有缺失数据的对象与信息系统的其他相似对象的属性值的差异尽可能保持一致,使填补前后属性值之间的差异尽可能保持最小。
定义1信息系统S[7]。
S=论域U={x1,x2,…,xm}是一组包含m个对象的非空有限集合。A是有限个属性的非空有限集合,设有n个属性,则表示为A={a1,a2,…,an},对每一个ak∈A,ak:U→是属性ak的值域。其中,值域可能包含使用特殊符号“*”表示的数据缺失值,此时该信息系统记为不完备信息系统;且A可以进一步划分为两个不相交的子集合:条件属性C和决策属性D,满足A=C∪D且C∪D=∅,此时的信息系统称为决策系统,其中D一般只包含一个属性。
定义2扩充差异矩阵M[7]。
S=论域U={x1,x2,…,xm},属性集A=C∪D,条件属性集C,决策属性D,ak(xi)是样本xi在属性ak上的取值。Mij表示经过扩充的差异矩阵中第i行、第j列的元素,则扩充差异矩阵元素Mij定义为:
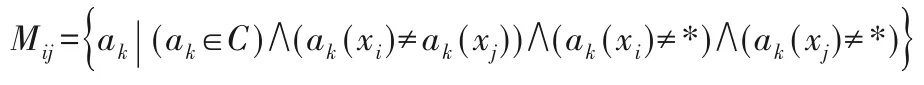
其中:i,j=1,2,…,m,k=1,2,…,n,m=|U|,n=|A|,*表示缺失数据。矩阵M中的元素为属性的集合,且该矩阵为m×n的方阵。
定义3对象xi缺失属性集MASi(Missing Attributes Set)。
对象xi缺失属性集MASi是包含k(1 ≤k≤n)个属性且满足下列条件的有限集合:

定义4无差别对象集NSi。
对象xi无差别对象集是包含j(1 ≤j≤m)个对象且满足如下条件的集合:

定义5缺失对象集MOS。
信息系统S缺失对象集MOS(Missing Objects Set)是满足如下条件的集合:

2.2 算法描述
基于上述的定义,不完备数据分析算法ROUSTIDA 描述如下:
算法1 ROUSTIDA。


根据上述算法描述可分析得到,ROUSTIDA 存在如下问题:
1)填补过程中未区分决策属性D和条件属性C,可能会导致填补后的信息系统出现决策冲突现象,即两个样本的条件属性值相同而决策(分类)属性值不同。
2)当对象xi的NSi=∅,即没有其他对象与xi相似时,无法填补xi的缺失数据;或当对象xi存在多个相似对象,且多个相似对象能够给予填充的属性值不一致时,也无法进行填充。
3)该算法仅考虑对象间的相似关系,忽略了对象是否具备填补能力的判断,可能导致NSi中部分相似对象实际上不能对缺失数据进行填补。
3 RSHISMIA
根据上述原算法ROUSTIDA 存在的问题,本文提出了一种改进的针对不完备混合信息系统的缺失数据填补方法(RSHISMIA)。
3.1 距离矩阵
为了改进算法,引入Zeng等[17]给出的如下定义6。
定义6混合信息系统HIS。
HIS=C∩D=∅,U为论域,Vd={d1,d2,…,dm}为决策属性的值域,C=Cr∪Cb∪Cc,Cr是数值属性集合,Cb是布尔属性集合,Cc是类别属性集合,且Cr∩Cb=∅,Cr∩Cc=∅,Cb∩Cc=∅。若包含使用特殊符号“*”所表示的缺失数据时,该信息系统记为不完备混合信息系统。
如表1为一个不完备混合信息系统。其中,D表示决策属性,c1、c2、c3、c4为条件属性,“*”表示缺失数据,“Temperature”为数值属性,“Degree of headache”“Degree of muscle pain”为类别属性,在预处理过程中需要对具有序数关系的类别属性使用Géron[18]给出的One-hot Encoder(独热编码)进行转换,对不具有序数关系的类别属性使用Label Encoder(标签编码)转换。“Cough”为布尔属性,仅包含“yes”和“no”两个取值,不具备序数和大小关系。此外,布尔属性遵循Bernoulli分布,而类别属性遵循离散概率分布,因此,需要对不同类型的属性进行相应的处理。目前,为了量化混合信息系统对象间的相似度,He等[19]给出了样本间的混合距离(定义7)和针对属性类型不同而给出的布尔属性距离(定义8)。为了更合理量化不完备混合信息系统中样本的距离,在上述工作的基础上,修改定义了类别属性(定义9)和数值属性(定义10)的距离计算方式,并给出了距离矩阵(定义11)。

表1 不完备混合信息系统Tab.1 Incomplete hybrid information system
定义7混合距离HD。
HIS=U={x1,x2,…,xm},∀xi,xj∈U,∀c∈C,c(xi)、c(xj)分别表示样本xi和xj在条件属性c上的取值,样本xi和xj之间距离定义如下:

其中d(c(xi),c(xj))的定义如下:

定义8布尔属性距离db。
HIS=U={x1,x2,…,xm},∀xi,xj∈U,∀c∈C,c是布尔属性,c(xi)、c(xj)分别表示样本xi和xj在条件属性c上的取值,样本xi和xj之间距离定义如下:

定义9类别属性距离dm。
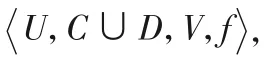
HIS=U={x1,x2,…,xm},∀xi,xj∈U,∀c∈C,c是类比属性,c(xi)、c(xj)分别表示样本xi和xj在条件属性c上的取值,样本xi和xj之间距离定义如下:
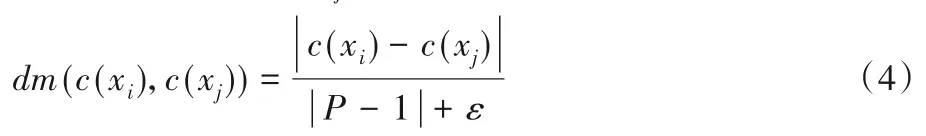
其中:P为类别属性c的取值个数;ε取值为10-5,防止分母为0。此外若使用One-hot Encoder,|c(xi)-c(xj)|=
定义10数值属性距离dr。
HIS=U={x1,x2,…,xm},∀xi,xj∈U,∀c∈C,c是数值属性,c(xi)、c(xj)分别表示样本xi和xj在条件属性c上的取值,样本xi和xj之间距离定义如下。

其中δr为数值属性c的标准差,ε取值为10-5。
在缺失数据填补过程中,不仅需要使用混合距离度量对象之间的相似关系,还需要将它们可互相填补的能力纳入考虑范围之内。故本文在使用混合距离基础上,还增加定义了距离矩阵DM。
定义11距离矩阵DM。
HIS=U={x1,x2,…,xm},条件属性集C={c1,c2,…,cn-1},c(xi)是样本xi在条件属性c上的取值。距离矩阵DM的元素DMij(第i行第j列的元素)表示样本xi和样本xj的距离,其定义如下:
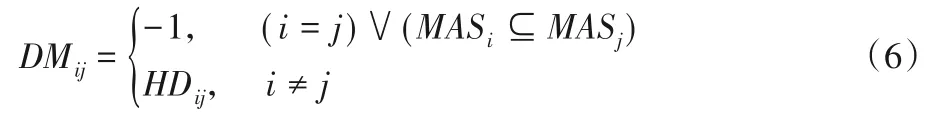
由于HDij取值为[0,+∞],-1取值是合理的。
根据上述定义可得DM是一个非对称的m×m方阵,其表征的对象相似度考虑了填补能力因素。特别是当对象xj不具备填补对象xi的能力时,不论二者的距离(相似程度)为多少,都将DMij定义为-1。
3.2 算法描述
根据上述定义,RSHISMIA 描述(算法2)如下。首先,依据等价类划分思想,依据决策属性值Vd={d1,d2,…,dm}将不完备混合信息系统HIS划分为子系统HIS1,HIS2,…,HISl,且满足HIS=HIS1∪HIS2∪…∪HISl。对每个子系统HISk(k=1,2,…,l)进行缺失数据填补。最后将填补后的所有子系统HISk融合为一个混合信息系统,若仍存在缺失数据,则使用GRZYMALA-BUSSE 等[20]给出的 CMC(Condition Most Common)方法进行辅助填补,即对于类别属性使用众数填补,对于数值属性使用平均值填补。
算法2 RSHISMIA。


3.3 实例分析
将RSHISMIA 与ROUSTIDA 的填充结果进行对比。一个不完备混合信息系统如表1 所示,通过RSHISMIA、ROUSTIDA 填补后的效果分别如表2、3 所示。ROUSTIDA 出现无法填补的条件属性较多,填补效率低,且重新计算无差别矩阵时计算较复杂,同时还出现了x2与x3决策规则冲突的情况。决策规则冲突的原因是因为在补齐x2和x3时,选择的补齐对象是从整个不完备决策表中去寻找无差别对象,在完成决策表的循环计算后条件属性仍无法补齐,采用CMC 进行补齐从而导致决策规则冲突。文中所用的决策属性等价类划分思想由于分别考虑了同一决策子系统和不同决策子系统中最相似的对象对填补的不同影响,较好地避免了冲突。同时,在计算混合距离矩阵时,由于每次循环只需要计算该矩阵中值不为-1 的元素,所提RSHISMIA 较ROUSTIDA 的无差别矩阵的计算更为简单。
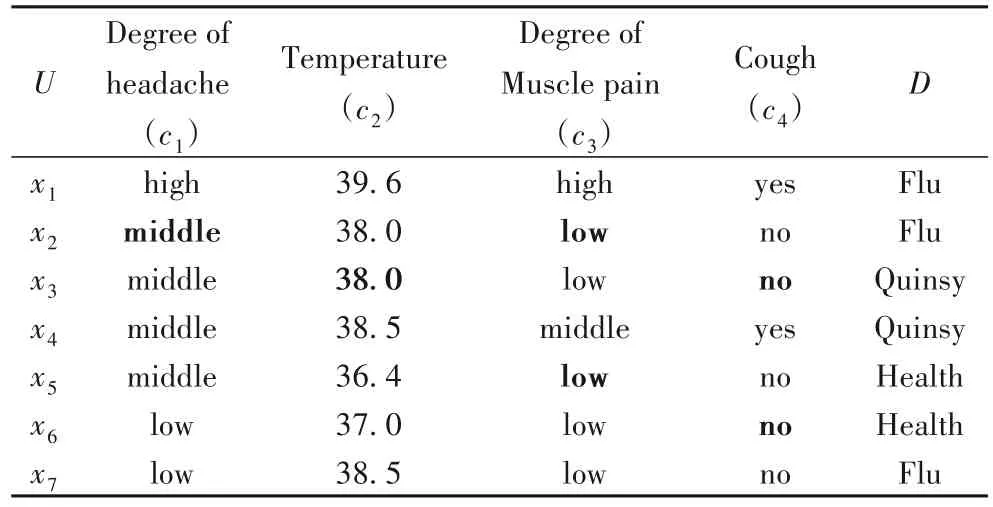
表2 ROUSTIDA填补结果Tab.2 Imputation results of ROUSTIDA
3.4 算法时空复杂度分析
算法2中,步骤3)~5)的复杂度主要取决于计算距离矩阵DM。假设论域被划分为U=U1∪U2∪…∪Ul,分析可得,Ul所有对象两两相互比较,则需要比较|Ul|*|Ul|/2 次,并且任意两个对象需要对所有条件属性进行比较,比较次数为|C|。因此,DM矩阵计算的复杂度为O(|C||Ul|2)。步骤6)~16),计算复杂度主要取决于缺失数据的个数,为常数数量级。综上,算法2填补过程的复杂度为O(|C|(|U1|2+|U2|2+…+|Ul|2);由算法1 可得,使用ROUSTIDA 对整个论域空间建立扩充差异矩阵,所有对象相互比较,需要比较|U|(|U|-1)/2 次,并且任意两个对象需要对所有属性进行比较,比较次数为|A|,因此计算矩阵的复杂度为O(|A||U|2)。
此外,使用改进后的距离矩阵存储空间由原本的O(|A||U|2)降低到O(|C|(|U1|2+|U2|2+…+|Ul|2)。对于|U|大于600 或|C|大于10 的数据集而言,空间复杂度降低效果较明显。
4 实验结果与分析
在本章中,使用ROUSTIDA 和本文提出的缺失数据填补算法RSHISMIA 以及目前较流行的缺失数据填补算法KNNI、MF、RFI 进行对比实验。以下所有实验均使用Windows 10 64 位操作系统,Intel i7-7500U CPU 2.7 GHz,8 GB RAM,Python 3.6进行编程。
4.1 评价标准
缺失数据的填补标准一般分为3 种:周志华[21]给出的查全率(Recall)用于评估填补能力和查准率(Precision)用于衡量填补的准确度,以及Dauwels 等[22]给出的归一化均方根误差(Normalized Root Mean Square Error,NRMSE)用于检验填补结果与真实值的差异度,具体公式定义如下:

其中:m表示数据集样本个数;TP(True Positive)表示缺失数据填补正确个数;FP(False Positive)表示缺失数据填补错误个数;FN(False Negative)表示未填补的缺失数据个数;xi表示原始值,xi'表示填补值,xmax和xmin分别为最大值和最小值。
交叉验证是一种用于测试模型预测新数据能力,预防过拟合或选择偏差等问题,并提高模型泛化能力的统计方法。将数据集W划分成k个大小相似的互斥子集,即W=W1∪W2∪…∪Wk,Wi∩Wj=∅(i≠j)。每个子集Wi都从W中分层采样得到,从而尽可能保持数据分布的一致性。然后,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就可获得k组训练/测试集,从而可进行k次训练和测试,最终返回的是这k个测试结果的均值。显然,k的取值很大程度上影响了交叉验证法评估结果的稳定性和保真性,为强调这一点,通常交叉验证法称为“k折交叉验证”,k最常用的是10。本文使用10 次交叉验证可以减少与随机抽样相关的偏差。
4.2 数据集
本文在Dua等[23]给出的10个标准UCI数据集上验证所提出的方法。其中,包含3个类别型数据集(Lymphography、SPECT、Balance Scale);7 个混合型数据集(Acute Inflammations、Contraceptive、Heart、Liver、Zoo、German、Abalone)。下面从数据集大小和数据特点等方面分别介绍这10 个数据集(如表4 所示)。以下数据集均不存在缺失数据,数据集的样本个数变化范围为101~4177,属性个数范围为4~22。
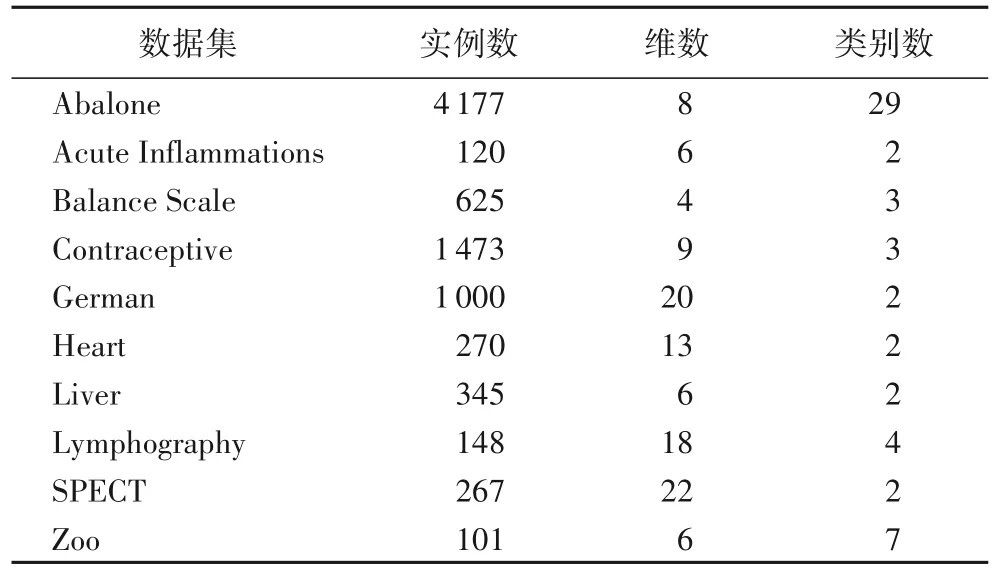
表4 数据集描述Tab.4 Dataset description
4.3 实验设置
本节中描述了所完成的3 个实验来验证所提出的缺失数据填补算法RSHISMIA 的可行性和有效性。首先对数据集Abalone 使用Alexksander[24]提出的Rosetta 的Equal Frequency Scaler 函数对数据集中连续属性数据进行离散化处理。上述数据集均不存在缺失数据,因此,本文采用Alfons[25]给出的R语言SimFrame 库的随机数据生成器确定缺失数据的位置,然后删除相应的属性值,生成不完整的信息系统。对条件属性使用10 个不同的随机数作为种子,随机产生5%、10%、15%、20%、25%、30%比率(α)的缺失数据,分别得到6 × 10 × 10 个(6种缺失率,每种缺失率10次随机缺失,10个数据集)不完备的信息系统。然后,使用RSHISMIA、ROUSTIDA、KNNI、MF和RFI 5种算法分别进行填补,最后将填补后得到的完整信息系统看作一个决策系统。使用Cortes等[26]提出的SVM算法进行10 次10 折交叉准确率验证后取平均值。其中SVM 使用径向基函数(Radial Basis Function,RBF)核函数,并使用Hsu等[27]提出的交叉验证网格搜索寻找最优参数(C,Y)。此外,为防止样本中不同特征数值大小相差较大影响分类器性能,采用Zheng 等[28]给出的标准化处理方式进行数据集处理。相关填补模型和分类模型参数设置如表5所示。

表5 相关填补和分类模型参数设置Tab.5 Parameter setting of related imputation and classification models
第1 个实验是通过改变RSHISMIA 近邻个数k的取值,判断k取何值时算法的NRMSE 可以达到最优值。参考KNN 算法的k值选取,Lall 等[29]提出了一种可选择的方式,即k=(m≥100),这里m为样本个数。由于数据集的特性不同,没有关于最优k的先验信息,所以k的最优值将根据所提RSHISMIA 的实验结果来设定。这里k值取值范围为1、3、5、10、15、20。
第2 个实验,对RSHISMIA 和ROUSTIDA 进行查全率、查准率和NRMSE的比较。
第3个实验,对RSHISMIA 和ROUSTIDA 无法填补的缺失数据使用CMC 方法辅助填补,并将辅助填补后得到的混合信息系统与KNNI、MF、RFI 等3 种算法分别填补后的混合信息系统使用SVM算法进行分类预测。
4.4 结果分析
实验1 结果表明,对于样本个数较小的混合型数据集(≤350)而言,k的取值为3 的NRMSE 较小。对于样本个数较少的类别型数据集(≤350)而言,k的取值为10 较优。对于样本个数较大的混合型和类别型数据集(≥350)而言,k取20 可以使得NRMSE 的值较小。此外,对于大部分数据集而言,NRMSE 不会随着k波动太大,基本稳定不变。因此,综合分析,本文选取k值为15作为后续对比实验的基准。
实验2 结果表明RSHISMIA 对10 个数据集的查全率均高于ROUSTIDA(见表6),平均提高了约81 个百分点,这是因为使用近邻样本,扩大了可用于填补的相似样本的选择范围。依据数据集的不同,查准率(见表6)较ROUSTIDA 在所有缺失率情况下也有所提高,如数据集Acute Inflammations 平均提高了23个百分点,数据集Zoo平均提高了29个百分点,SPECT数据集平均提高了5 个百分点。此外,对于RSHISMIA,大部分数据集的NRMSE 相较ROUSTIDA(见表6)也有所减小,如数据集Liver 的NRMSE 减少了0.002~0.006,数据集Balance Scale 平均减小了约0.02。数据集Zoo 的NRMSE 减小了0.06~0.12。
实验3结果为同一数据集在同一缺失比例下使用SVM 算法进行10 次十折交叉验证分类准确率取平均后的结果(如图1 所示)。可以观察到,算法RSHISMIA 对数据集Lymphography、Heart、Liver、German 所有缺失率的情况下分类准确率都最高,分别为91.97%、89.22%、71.46%、79.81%。而数据集SPECT 和Zoo 在缺失率为10%~25%的情况下,填补算法RSHISMIA 的表现较好,最高分别达到了75.19%、97%,其次是KNNI,相差在1%~3%左右。此外,对于Balance Scale和Acute Inflammations、Contraceptive 这三个数据集而言,RSHISMIA 较大多数算法的表现都好,仅次于RFI。在缺失率为15%~25%时,RSHISMIA 在数据集Abalone 上效果仅次于KNNI,甚至在缺失率为30%时超过了KNNI达到最优,可以达到32.41%。
综上,使用RSHISMIA 填补包含混合属性的信息系统是有效可行的,更适合填补数据量小且缺失率高的混合信息系统,且对样本量较大的混合填补效果也基本与最优算法持平。

表6 不同数据集不同缺失率的实验结果Tab.6 Experimental results on different datasets with different missing rates
5 结语
针对传统ROUSTIDA 无法有效处理包含不同属性类型的混合信息系统,本文提出了RSHISMIA 填补算法。该算法既继承了粗糙集理论的优点,对数据的先验性要求不高,又通过对决策属性进行等价类划分,解决可能出现的决策规则冲突问题;定义不同属性的距离公式度量样本的相似度,得到比容差关系更适合作为寻找最相似对象基础的混合距离;定义混合距离矩阵筛选更具填补能力的样本;最后结合了近邻的思想,扩大了待填补数据的相似对象的选择范围。实验结果表明,本文提出的缺失数据填补算法RSHISMIA,在10个标准数据集上的查全率、查准率、NRMSE 相较ROUSTIDA 都取得了更好的性能指标,分类准确率较其他填补算法也有提升。
综上,本文所提的RSHISMIA 可以合理有效地处理样本量小、缺失率高的不完备混合信息系统,且处理结果具有客观性,有一定的借鉴意义;但要求数据的决策属性不存在缺失,具有一定的局限性。因此,未来需要对决策属性存在缺失数据的填补方法进行研究。

图1 不同算法在不同数据集上随缺失率变化的分类准确率Fig.1 Classification accuracies of different algorithms with change of missing rate on different datasets
